AI项目二十一:视频动态手势识别
若该文为原创文章,转载请注明原文出处。
一、简介
人工智能的发展日新月异,也深刻的影响到人机交互领域的发展。手势动作作为一种自然、快捷的交互方式,在智能驾驶、虚拟现实等领域有着广泛的应用。手势识别的任务是,当操作者做出某个手势动作后,计算机能够快速准确的判断出该手势的类型。本文将使用ModelArts开发训练一个视频动态手势识别的算法模型,对上滑、下滑、左滑、右滑、打开、关闭等动态手势类别进行检测,实现类似隔空手势的功能。
在前面也有使用mediapipe实现类似功能。具体自行参考。
本文章参考CNN-VIT 视频动态手势识别【玩转华为云】-云社区-华为云
二、环境
使用的是AUTODL,配置如下:
镜像:PyTorch 1.7.0 Python 3.8(ubuntu18.04) Cuda 11.0
GPU :RTX 2080 Ti(11GB) * 1升降配置
CPU12 vCPU Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50GHz
三、环境搭建
1、创建虚拟环境
conda create -n cnn_hand_gesture_env python=3.82、激活
conda activate cnn_hand_gesture_env3、安装依赖项
conda install cudatoolkit=11.3.1 cudnn=8.2.1 -y --override-channels --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
pip install tensorflow-gpu==2.5.0 -i https://pypi.doubanio.com/simple --userpip install opencv-contrib-python
pip install imageio
pip install imgaug
pip install tqdm
pip install IPythonpip install numpy==1.19.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install matplotlib==3.6这里需要注意的是numpy版本和matplotlib版本,tensorflow2.5版本对应的numpy版本是1.19.3
如果版本过高会一直出错错误。
四、数据下载
下载数据使用的是华为云,可以自行下载或联系我。
import os
import moxing as moxif not os.path.exists('hand_gesture'):mox.file.copy_parallel('obs://modelbox-course/hand_gesture', 'hand_gesture')五、算法简介
视频动态手势识别算法首先使用预训练网络InceptionResNetV2逐帧提取视频动作片段特征,然后输入Transformer Encoder进行分类。我们使用动态手势识别样例数据集对算法进行测试,总共包含108段视频,数据集包含无效手势、上滑、下滑、左滑、右滑、打开、关闭等7种手势的视频,具体操作流程如下:
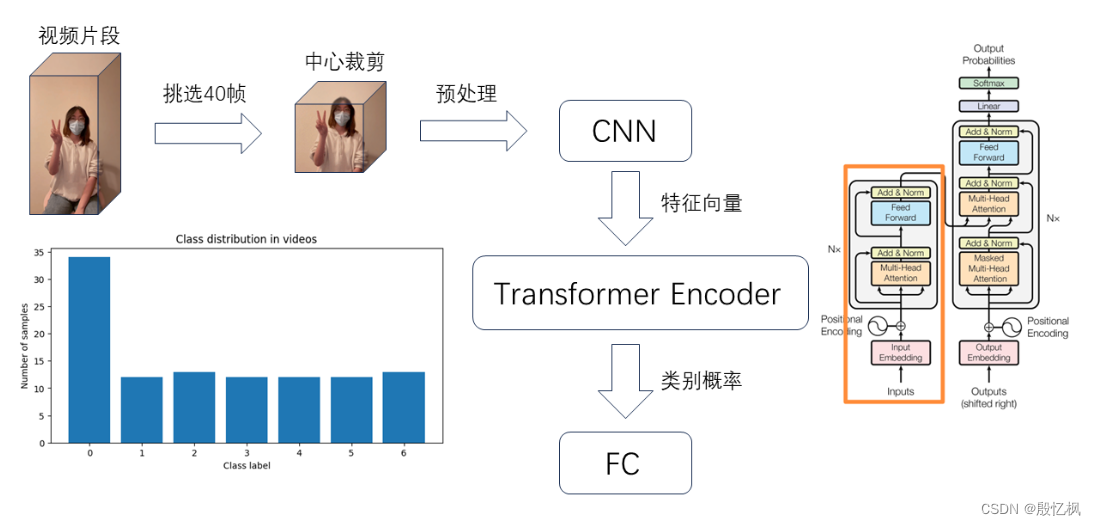
六、流程
1、将采集的视频文件解码抽取关键帧,每隔4帧保存一次,然后对图像进行中心裁剪和预处理
2、创建图像特征提取器,使用预训练模型InceptionResNetV2提取图像特征
3、提取视频特征向量,如果视频不足40帧就创建全0数组进行补白
4、创建VIT Mode
5、视频推理
6、加载VIT Model,获取视频类别索引标签
7、使用图像特征提取器InceptionResNetV2提取视频特征
8、将视频序列的特征向量输入Transformer Encoder进行预测
9、打印模型预测结果
七、测试

Autodl自带有JupyterLab, 直接运行一遍。
代码解析:
1、创建视频输入管道获取视频类别标签
videos = glob.glob('hand_gesture/*.mp4')
np.random.shuffle(videos)
labels = [int(video.split('_')[-2]) for video in videos]
videos[:5], len(videos), labels[:5], len(videos)2、视频抽帧预处理
def load_video(file_name):cap = cv2.VideoCapture(file_name) # 每隔多少帧抽取一次frame_interval = 4frames = []count = 0while True:ret, frame = cap.read()if not ret:break# 每隔frame_interval帧保存一次if count % frame_interval == 0:# 中心裁剪 frame = crop_center_square(frame)# 缩放frame = cv2.resize(frame, (IMG_SIZE, IMG_SIZE))# BGR -> RGB [0,1,2] -> [2,1,0]frame = frame[:, :, [2, 1, 0]]frames.append(frame)count += 1return np.array(frames) 3、创建图像特征提取器
def get_feature_extractor():feature_extractor = keras.applications.inception_resnet_v2.InceptionResNetV2(weights = 'imagenet',include_top = False,pooling = 'avg',input_shape = (IMG_SIZE, IMG_SIZE, 3))preprocess_input = keras.applications.inception_resnet_v2.preprocess_inputinputs = keras.Input((IMG_SIZE, IMG_SIZE, 3))preprocessed = preprocess_input(inputs)outputs = feature_extractor(preprocessed)model = keras.Model(inputs, outputs, name = 'feature_extractor')return model4、提取视频图像特征
def load_data(videos, labels):video_features = []for video in tqdm(videos):frames = load_video(video)counts = len(frames)# 如果帧数小于MAX_SEQUENCE_LENGTHif counts < MAX_SEQUENCE_LENGTH:# 补白diff = MAX_SEQUENCE_LENGTH - counts# 创建全0的numpy数组padding = np.zeros((diff, IMG_SIZE, IMG_SIZE, 3))# 数组拼接frames = np.concatenate((frames, padding))# 获取前MAX_SEQUENCE_LENGTH帧画面frames = frames[:MAX_SEQUENCE_LENGTH, :]# 批量提取特征video_feature = feature_extractor.predict(frames)video_features.append(video_feature)return np.array(video_features), np.array(labels)5、编码器
# 编码器
class TransformerEncoder(layers.Layer):def __init__(self, num_heads, embed_dim):super().__init__()self.p_embedding = PositionalEmbedding(MAX_SEQUENCE_LENGTH, NUM_FEATURES)self.attention = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim, dropout=0.1)self.layernorm = layers.LayerNormalization()def call(self,x):# positional embeddingpositional_embedding = self.p_embedding(x)# self attentionattention_out = self.attention(query = positional_embedding,value = positional_embedding,key = positional_embedding,attention_mask = None)# layer norm with residual connection output = self.layernorm(positional_embedding + attention_out)return output6、训练模式
history = model.fit(train_dataset,epochs = 1000,steps_per_epoch = train_count // batch_size, validation_steps = test_count // batch_size, validation_data = test_dataset,callbacks = [checkpoint, earlyStopping, rlp])7、测试
# 视频预测
def testVideo():test_file = random.sample(videos, 1)[0]label = test_file.split('_')[-2]print('文件名:{}'.format(test_file) )print('真实类别:{}'.format(label_to_name.get(int(label))) )# 读取视频每一帧frames = load_video(test_file)# 挑选前帧MAX_SEQUENCE_LENGTH显示frames = frames[:MAX_SEQUENCE_LENGTH].astype(np.uint8)# 保存为GIFimageio.mimsave('animation.gif', frames, duration=10)# 获取特征feat = getVideoFeat(frames)# 模型推理prob = model.predict(tf.expand_dims(feat, axis=0))[0]print('预测类别:')for i in np.argsort(prob)[::-1][:5]:print('{}: {}%'.format(label_to_name[i], round(prob[i]*100, 2)))#return display(Image(open('animation.gif', 'rb').read()))8、源码
import cv2
import glob
import numpy as np
from tqdm import tqdm
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as pltfrom collections import Counter
import random
import imageio
from IPython.display import Imagefrom tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau#%matplotlib inlineMAX_SEQUENCE_LENGTH = 40
IMG_SIZE = 299
NUM_FEATURES = 1536# 图像中心裁剪
def crop_center_square(img):h, w = img.shape[:2]square_w = min(h, w)start_x = w // 2 - square_w // 2end_x = start_x + square_wstart_y = h // 2 - square_w // 2end_y = start_y + square_wresult = img[start_y:end_y, start_x:end_x]return result# 视频抽帧预处理
def load_video(file_name):cap = cv2.VideoCapture(file_name) # 每隔多少帧抽取一次frame_interval = 4frames = []count = 0while True:ret, frame = cap.read()if not ret:break# 每隔frame_interval帧保存一次if count % frame_interval == 0:# 中心裁剪 frame = crop_center_square(frame)# 缩放frame = cv2.resize(frame, (IMG_SIZE, IMG_SIZE))# BGR -> RGB [0,1,2] -> [2,1,0]frame = frame[:, :, [2, 1, 0]]frames.append(frame)count += 1return np.array(frames) # 创建图像特征提取器
def get_feature_extractor():feature_extractor = keras.applications.inception_resnet_v2.InceptionResNetV2(weights = 'imagenet',include_top = False,pooling = 'avg',input_shape = (IMG_SIZE, IMG_SIZE, 3))preprocess_input = keras.applications.inception_resnet_v2.preprocess_inputinputs = keras.Input((IMG_SIZE, IMG_SIZE, 3))preprocessed = preprocess_input(inputs)outputs = feature_extractor(preprocessed)model = keras.Model(inputs, outputs, name = 'feature_extractor')return model# 提取视频图像特征
def load_data(videos, labels):video_features = []for video in tqdm(videos):frames = load_video(video)counts = len(frames)# 如果帧数小于MAX_SEQUENCE_LENGTHif counts < MAX_SEQUENCE_LENGTH:# 补白diff = MAX_SEQUENCE_LENGTH - counts# 创建全0的numpy数组padding = np.zeros((diff, IMG_SIZE, IMG_SIZE, 3))# 数组拼接frames = np.concatenate((frames, padding))# 获取前MAX_SEQUENCE_LENGTH帧画面frames = frames[:MAX_SEQUENCE_LENGTH, :]# 批量提取特征video_feature = feature_extractor.predict(frames)video_features.append(video_feature)return np.array(video_features), np.array(labels)# 位置编码
class PositionalEmbedding(layers.Layer):def __init__(self, seq_length, output_dim):super().__init__()# 构造从0~MAX_SEQUENCE_LENGTH的列表self.positions = tf.range(0, limit=MAX_SEQUENCE_LENGTH)self.positional_embedding = layers.Embedding(input_dim=seq_length, output_dim=output_dim)def call(self,x):# 位置编码positions_embedding = self.positional_embedding(self.positions)# 输入相加return x + positions_embedding# 编码器
class TransformerEncoder(layers.Layer):def __init__(self, num_heads, embed_dim):super().__init__()self.p_embedding = PositionalEmbedding(MAX_SEQUENCE_LENGTH, NUM_FEATURES)self.attention = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim, dropout=0.1)self.layernorm = layers.LayerNormalization()def call(self,x):# positional embeddingpositional_embedding = self.p_embedding(x)# self attentionattention_out = self.attention(query = positional_embedding,value = positional_embedding,key = positional_embedding,attention_mask = None)# layer norm with residual connection output = self.layernorm(positional_embedding + attention_out)return outputdef video_cls_model(class_vocab):# 类别数量classes_num = len(class_vocab)# 定义模型model = keras.Sequential([layers.InputLayer(input_shape=(MAX_SEQUENCE_LENGTH, NUM_FEATURES)),TransformerEncoder(2, NUM_FEATURES),layers.GlobalMaxPooling1D(),layers.Dropout(0.1),layers.Dense(classes_num, activation="softmax")])# 编译模型model.compile(optimizer = keras.optimizers.Adam(1e-5), loss = keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics = ['accuracy'])return model# 获取视频特征
def getVideoFeat(frames):frames_count = len(frames)# 如果帧数小于MAX_SEQUENCE_LENGTHif frames_count < MAX_SEQUENCE_LENGTH:# 补白diff = MAX_SEQUENCE_LENGTH - frames_count# 创建全0的numpy数组padding = np.zeros((diff, IMG_SIZE, IMG_SIZE, 3))# 数组拼接frames = np.concatenate((frames, padding))# 取前MAX_SEQ_LENGTH帧frames = frames[:MAX_SEQUENCE_LENGTH,:]# 计算视频特征 N, 1536video_feat = feature_extractor.predict(frames)return video_feat# 视频预测
def testVideo():test_file = random.sample(videos, 1)[0]label = test_file.split('_')[-2]print('文件名:{}'.format(test_file) )print('真实类别:{}'.format(label_to_name.get(int(label))) )# 读取视频每一帧frames = load_video(test_file)# 挑选前帧MAX_SEQUENCE_LENGTH显示frames = frames[:MAX_SEQUENCE_LENGTH].astype(np.uint8)# 保存为GIFimageio.mimsave('animation.gif', frames, duration=10)# 获取特征feat = getVideoFeat(frames)# 模型推理prob = model.predict(tf.expand_dims(feat, axis=0))[0]print('预测类别:')for i in np.argsort(prob)[::-1][:5]:print('{}: {}%'.format(label_to_name[i], round(prob[i]*100, 2)))#return display(Image(open('animation.gif', 'rb').read()))if __name__ == '__main__':print('Tensorflow version: {}'.format(tf.__version__))print('GPU available: {}'.format(tf.config.list_physical_devices('GPU')))# 创建视频输入管道获取视频类别标签videos = glob.glob('hand_gesture/*.mp4')np.random.shuffle(videos)labels = [int(video.split('_')[-2]) for video in videos]videos[:5], len(videos), labels[:5], len(videos)print(labels)# 显示数据分布情况counts = Counter(labels)print(counts)plt.figure(figsize=(8, 4))plt.bar(counts.keys(), counts.values())plt.xlabel('Class label')plt.ylabel('Number of samples')plt.title('Class distribution in videos')plt.show()# 显示视频label_to_name = {0:'无效手势', 1:'上滑', 2:'下滑', 3:'左滑', 4:'右滑', 5:'打开', 6:'关闭', 7:'放大', 8:'缩小'}print(label_to_name.get(labels[0]))frames = load_video(videos[0])frames = frames[:MAX_SEQUENCE_LENGTH].astype(np.uint8)imageio.mimsave('test.gif', frames, durations=10)print('mim save test.git')#display(Image(open('test.gif', 'rb').read()))#frames.shapeprint(frames.shape)feature_extractor = get_feature_extractor()feature_extractor.summary()video_features, classes = load_data(videos, labels)video_features.shape, classes.shapeprint(video_features.shape)print(classes.shape)# Datasetbatch_size = 16dataset = tf.data.Dataset.from_tensor_slices((video_features, classes))dataset = dataset.shuffle(len(videos))test_count = int(len(videos) * 0.2)train_count = len(videos) - test_countdataset_train = dataset.skip(test_count).cache().repeat()dataset_test = dataset.take(test_count).cache().repeat()train_dataset = dataset_train.shuffle(train_count).batch(batch_size)test_dataset = dataset_test.shuffle(test_count).batch(batch_size)train_dataset, train_count, test_dataset, test_countprint(train_dataset)print(train_count)print(test_dataset)print(test_count)# 模型实例化model = video_cls_model(np.unique(labels))# 打印模型结构model.summary()# 保存检查点checkpoint = ModelCheckpoint(filepath='best.h5', monitor='val_loss', save_weights_only=True, save_best_only=True, verbose=1, mode='min')# 提前终止earlyStopping = EarlyStopping(monitor='loss', patience=50, mode='min', baseline=None)# 减少learning raterlp = ReduceLROnPlateau(monitor='loss', factor=0.7, patience=30, min_lr=1e-15, mode='min', verbose=1)# 开始训练history = model.fit(train_dataset,epochs = 1000,steps_per_epoch = train_count // batch_size, validation_steps = test_count // batch_size, validation_data = test_dataset,callbacks = [checkpoint, earlyStopping, rlp])# 绘制结果plt.plot(history.epoch, history.history['loss'], 'r', label='loss')plt.plot(history.epoch, history.history['val_loss'], 'g--', label='val_loss')plt.title('VIT Model')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.plot(history.epoch, history.history['accuracy'], 'r', label='acc')plt.plot(history.epoch, history.history['val_accuracy'], 'g--', label='val_acc')plt.title('VIT Model')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()# 加载训练最优权重model.load_weights('best.h5')# 模型评估model.evaluate(dataset.batch(batch_size))# 保存模型model.save('saved_model')print('save model')# 手势识别# 加载模型model = tf.keras.models.load_model('saved_model')# 类别标签label_to_name = {0:'无效手势', 1:'上滑', 2:'下滑', 3:'左滑', 4:'右滑', 5:'打开', 6:'关闭', 7:'放大', 8:'缩小'}# 视频推理for i in range(20):testVideo()运行后会训练模型

并保存模型测试,
测试结果


如有侵权,或需要完整代码,请及时联系博主。
相关文章:
AI项目二十一:视频动态手势识别
若该文为原创文章,转载请注明原文出处。 一、简介 人工智能的发展日新月异,也深刻的影响到人机交互领域的发展。手势动作作为一种自然、快捷的交互方式,在智能驾驶、虚拟现实等领域有着广泛的应用。手势识别的任务是,当操作者做出…...

浅拷贝与深拷贝面试问题及回答
1. 浅拷贝和深拷贝的区别是什么? 答: 浅拷贝(Shallow Copy)仅复制对象的引用而不复制引用的对象本身,因此原始对象和拷贝对象会引用同一个对象。而深拷贝(Deep Copy)则是对对象内部的所有元素进…...

推荐算法顶会论文合集
SIGIR SIGIR 2022 | 推荐系统相关论文分类整理:8.74 https://mp.weixin.qq.com/s/vH0qJ-jGHL7s5wSn7Oy_Nw SIGIR2021推荐系统论文集锦 https://mp.weixin.qq.com/s/N7V_9iqLmVI9_W65IQpOtg SIGIR2020推荐系统论文聚焦: https://mp.weixin.qq.com/s…...

组合模式(Composite)——结构型模式
组合模式(Composite)——结构型模式 组合模式是一种结构型设计模式, 你可以使用它将对象组合成树状结构, 并且能通过通用接口像独立整体对象一样使用它们。如果应用的核心模型能用树状结构表示, 在应用中使用组合模式才有价值。 例如一个场景…...
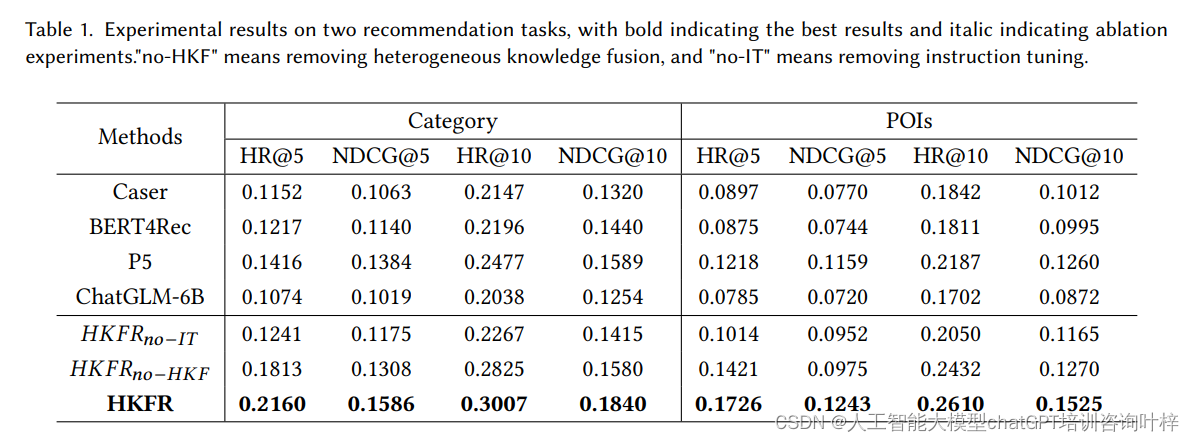
利用大模型提升个性化推荐的异构知识融合方法
在推荐系统中,分析和挖掘用户行为是至关重要的,尤其是在美团外卖这样的平台上,用户行为表现出多样性,包括不同的行为主体(如商家和产品)、内容(如曝光、点击和订单)和场景࿰…...

Dockerfile 里 ENTRYPOINT 和 CMD 的区别
ENTRYPOINT 和 CMD 的区别: 在 Dockerfile 中同时设计 CMD 和 ENTRYPOINT 是为了提供更灵活的容器启动方式。ENTRYPOINT 定义了容器启动时要执行的命令,而 CMD 则提供了默认参数。通过结合使用这两个指令,可以在启动容器时灵活地指定额外的参…...

腾讯的EdgeONE是什么?
腾讯的EdgeONE是一项边缘计算解决方案,具有一系列优势: 边缘计算能力强大:EdgeONE利用腾讯云在全球范围内的分布式基础设施,提供强大的边缘计算能力,可以实现低延迟和高可用性的服务。 智能化和自动化:Edg…...
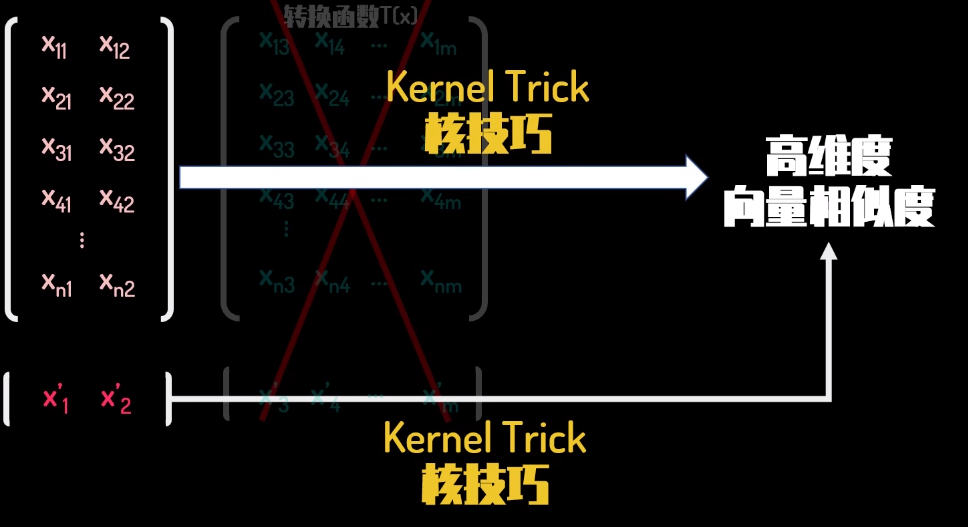
SVM直观理解
https://tangshusen.me/2018/10/27/SVM/ https://www.bilibili.com/video/BV16T4y1y7qj/?spm_id_from333.337.search-card.all.click&vd_source8272bd48fee17396a4a1746c256ab0ae SVM是什么? 先来看看维基百科上对SVM的定义: 支持向量机(英语:su…...
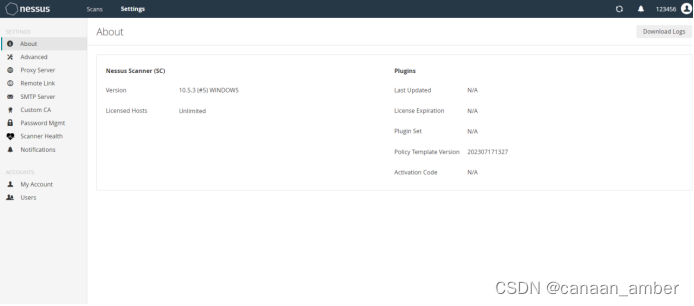
Nessus 部署实验
一、下载安装https://www.tenable.com/downloads/nessus 安装好之后,Nessus会自动打开浏览器,进入到初始化选择安装界面,这里我们要选择 Managed Scanner 点击继续,下一步选择Tenable.sc 点击继续,设置用户名和密码 等…...
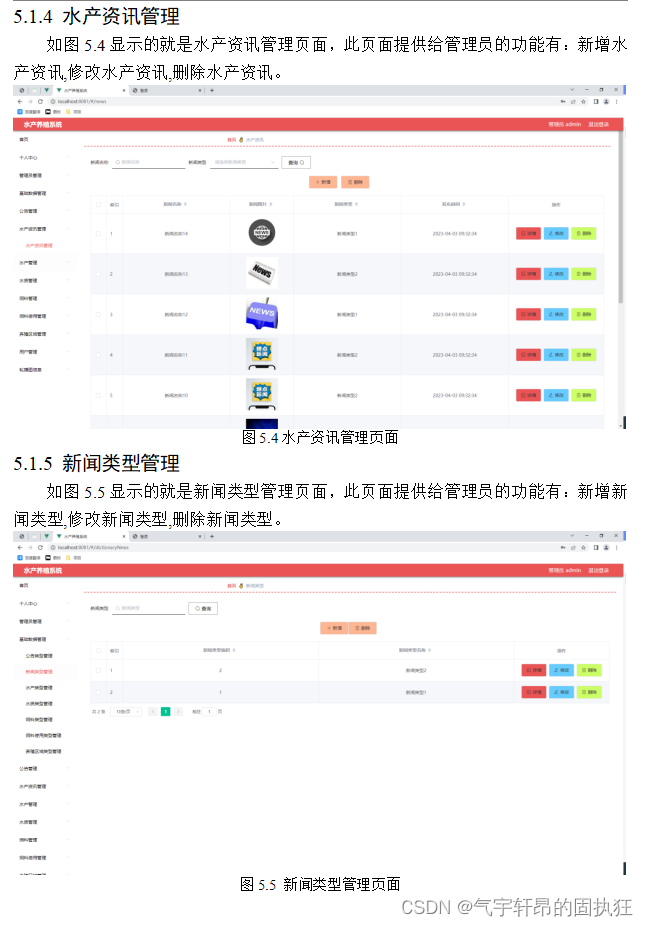
基于Springboot的水产养殖系统(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的水产养殖系统(有报告)。Javaee项目,springboot项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构&…...
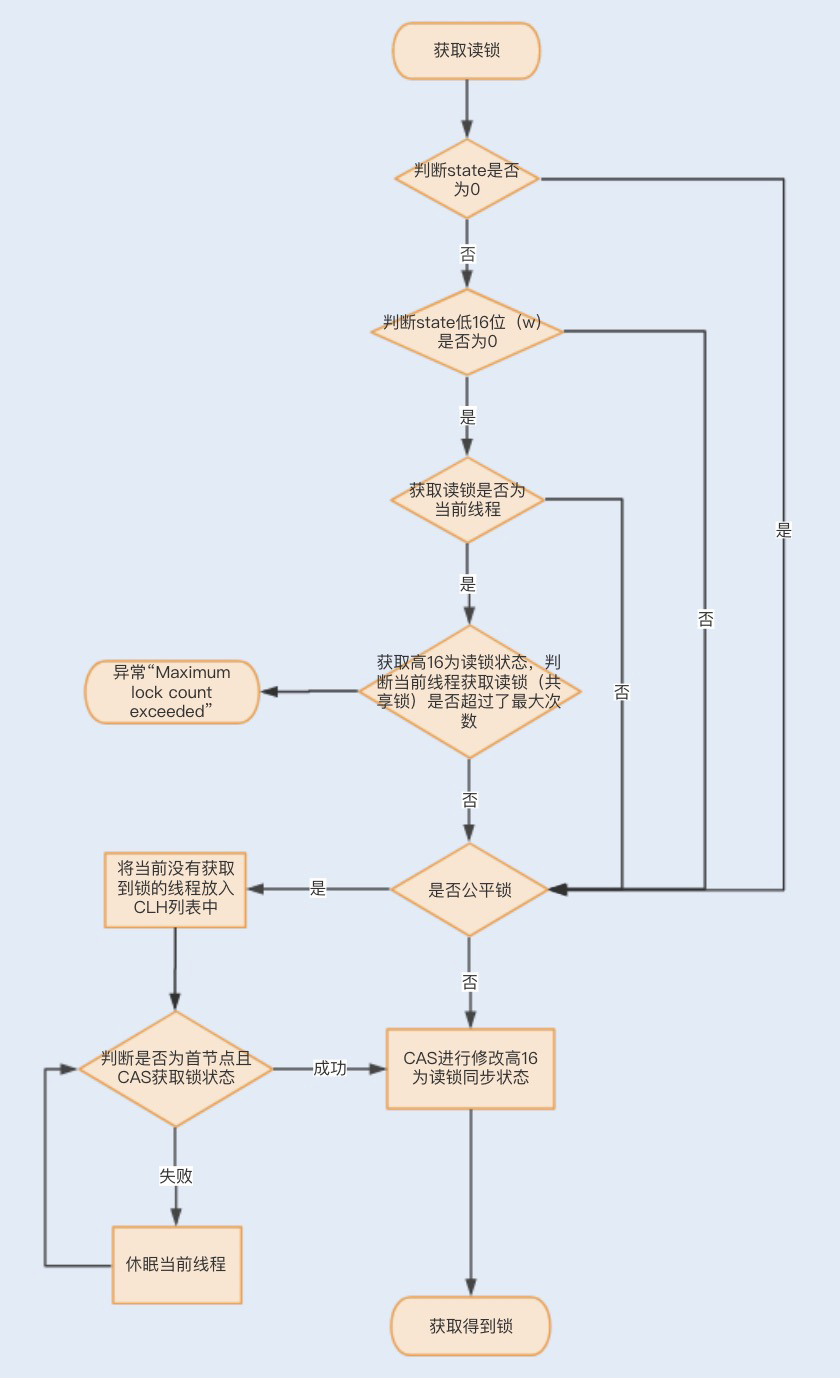
Java性能优化(五)-多线程调优-Lock同步锁的优化
作者主页: 🔗进朱者赤的博客 精选专栏:🔗经典算法 作者简介:阿里非典型程序员一枚 ,记录在大厂的打怪升级之路。 一起学习Java、大数据、数据结构算法(公众号同名) ❤️觉得文章还…...
 中 Attribute(属性)和 Property(属性))
WPF (Windows Presentation Foundation) 中 Attribute(属性)和 Property(属性)
在 WPF (Windows Presentation Foundation) 中,Attribute(属性)和 Property(属性)是两个相关但不同的概念。 Attribute(属性)是一种元数据,用于给类型、成员或其他代码元素添加附加…...
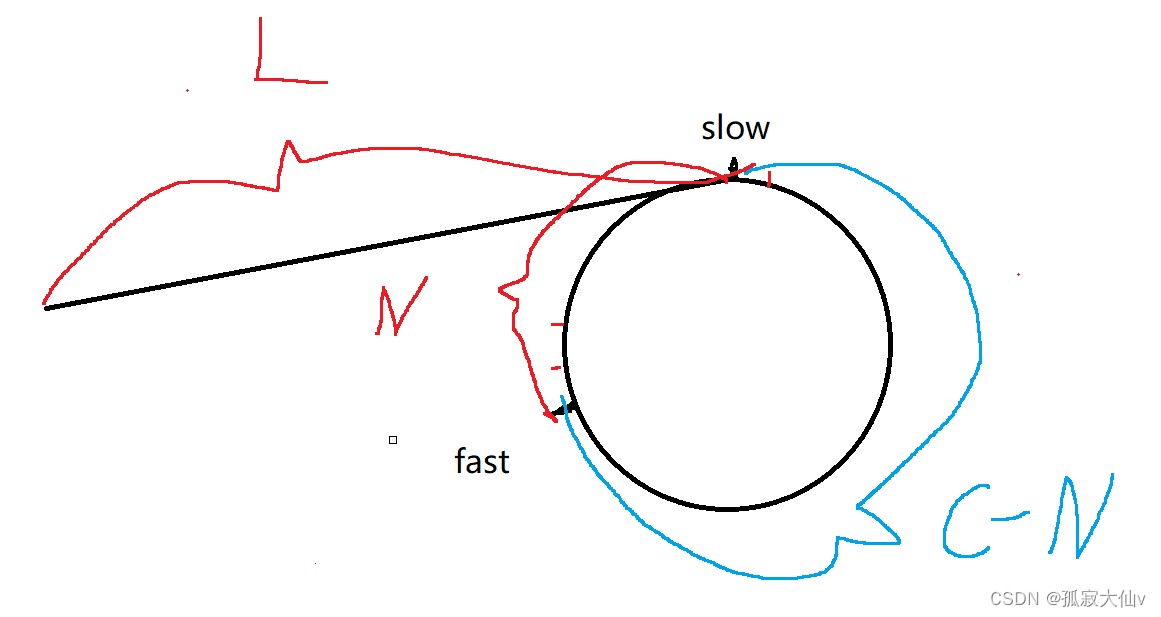
环形链表理解||QJ141.环形链表
在链表中,不光只有普通的单链表。之前写过的的一个约瑟夫环形链表是尾直接连向头的。这里的环形链表是从尾节点的next指针连向这链表的任意位置。 那么给定一个链表,判断这个链表是否带环。qj题141.环形链表就是一个这样的题目。 这里的思路是用快慢指…...

java本地锁与分布式锁-个人笔记 @by_TWJ
目录 1. 本地锁1.1. 悲观锁与乐观锁1.2. 公平锁与非公平锁1.3. CAS1.4. synchronized1.5. volatile 可见性1.6. ReentrantLock 可重入锁1.7. AQS1.8. ReentrantReadWriteLock 可重入读写锁 2. 分布式锁3. 额外的3.1. synchronized 的锁升级原理3.2. synchronized锁原理 1. 本地…...

【每日刷题】Day33
【每日刷题】Day33 🥕个人主页:开敲🍉 🔥所属专栏:每日刷题🍍 🌼文章目录🌼 1. 20. 有效的括号 - 力扣(LeetCode) 2. 445. 两数相加 II - 力扣(…...
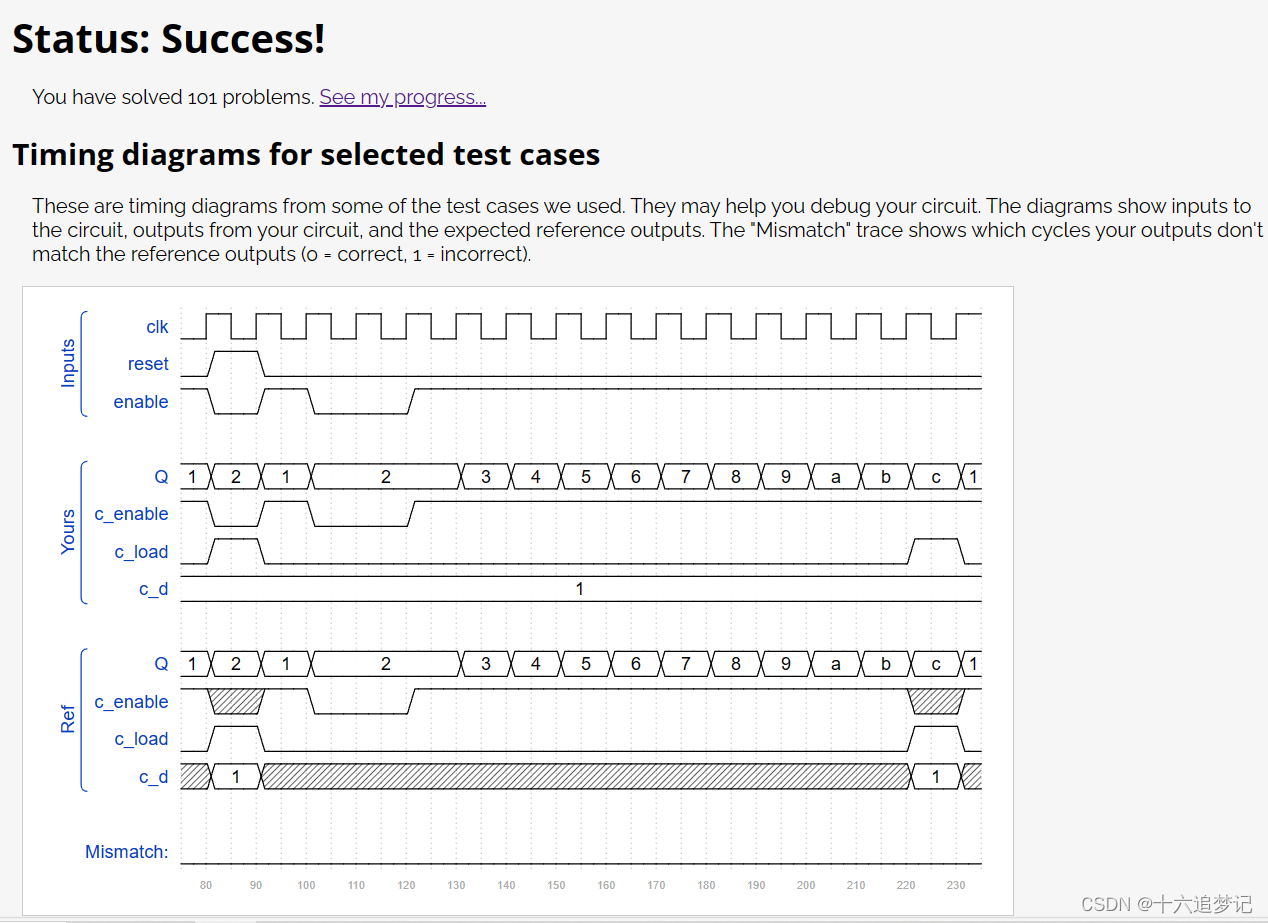
vivado刷题笔记46
题目: Design a 1-12 counter with the following inputs and outputs: Reset Synchronous active-high reset that forces the counter to 1 Enable Set high for the counter to run Clk Positive edge-triggered clock input Q[3:0] The output of the counter c…...

网络基础——校验
网络基础——校验 网络通信的层次化模型(如OSI七层模型或TCP/IP四层模型)中,每一层都有其特定的校验机制来确保数据传输的正确性和完整性。 物理层 校验方式 不直接涉及校验和,但会采用信号编码技术(如曼彻斯特编码…...

SparkSQL与Hive整合 、SparkSQL函数操作
SparkSQL与Hive整合 SparkSQL和Hive的整合,是一种比较常见的关联处理方式,SparkSQL加载Hive中的数据进行业务处理,同时将计算结果落地回Hive中。 整合需要注意的地方 1)需要引入hive的hive-site.xml,添加classpath目录下面即可…...
)
K8s: Helm搭建mysql集群(2)
搭建 mysql 集群 应用中心,mysql 文档参考https://artifacthub.io/packages/helm/bitnami/mysql 1 )helm 搭建 mysql A. 无存储,重启数据丢失 添加源 $ helm repo add mysql-repo https://charts.bitnami.com/bitnami安装 $ helm install…...

matlab期末知识
1.期末考什么? 1.1 matlab操作界面 (1)matlab主界面 (2)命令行窗口 (3)当前文件夹窗口 (4)工作区窗口 (5)命令历史记录窗口 1.2 matlab搜索…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...