机器学习实践:超市商品购买关联规则分析
第2关:动手实现Apriori算法
任务描述
本关任务:编写 Python 代码实现 Apriori 算法。
相关知识
为了完成本关任务,你需要掌握 Apriori 算法流程。
Apriori 算法流程
Apriori 算法的两个输人参数分别是最小支持度和数据集。该算法首先会生成所有单个物品的项集列表。接着扫描交易记录来查看哪些项集满足最小支持度要求,那些不满足最小支持度的集合会被去掉。然后,对剩下来的集合进行组合以生成包含两个元素的项集。接下来,再重新扫描交易记录,去掉不满足最小支持度的项集。该过程重复进行直到所有项集都被去掉。
所以 Apriori 算法的伪代码如下:
while 集合中的项的个数 > 0:构建一个由 k 个项组成的候选项集的列表确认每个项集都是频繁的保留频繁项集并构建 k+1 项组成的候选项集的列表从整个算法的流程来看,首先需要实现一个能够构建只有一个项集的函数,代码如下:
# 构建只有一个元素的项集, 假设dataSet为[[1, 2], [0, 1]. [3, 4]]# 那么该项集为frozenset({0}), frozenset({1}), frozenset({2}),frozenset({3}), frozenset({4})def createC1(dataset):C1 = set()for t in dataset:for item in t:item_set = frozenset([item])C1.add(item_set)return C1有了从无到有之后,接下来需要从 1 到 K 。不过需要注意的是,这个时候需要排除掉支持度小于最小支持度的项集。代码实现如下:
# 从只有k个元素的项集,生成有k+1个元素的频繁项集,排除掉支持度小于最小支持度的项集# D为数据集,ck为createC1的输出,minsupport为最小支持度def scanD(D, ck, minsupport):ssCnt = {}for tid in D:for can in ck:if can.issubset(tid):if can not in ssCnt.keys():ssCnt[can] = 1else:ssCnt[can] += 1numItems = len(D)reList = []supportData = {}for key in ssCnt:support = ssCnt[key]/numItemsif support >= minsupport:reList.insert(0, key)supportData[key] = support#reList为有k+1个元素的频繁项集,supportData为频繁项集对应的支持度return reList, supportData这就完了吗?还没有!我们还需要一个能够实现构建含有 K 个元素的频繁项集的函数。实现代码如下:
#构建含有k个元素的频繁项集#如输入为{0},{1},{2}会生成{0,1},{0, 2},{1,2}def aprioriGen(Lk, k):retList = []lenLk = len(Lk)for i in range(lenLk):for j in range(i+1, lenLk):L1 = list(Lk[i])[k:-2]L2 = list(Lk[j])[:k-2]if L1 == L2:retList.append(Lk[i] | Lk[j])return retList有了这些小功能后,我们就能根据 Apriori 算法的流程来实现 Apriori 算法了。
编程要求
根据提示,在右侧编辑器 Begin-End 补充代码,实现 Apriori 算法。
测试说明
平台会对你编写的代码进行测试,若与预期输出一致,则算通关。
def createC1(dataset):C1 = set()for t in dataset:for item in t:item_set = frozenset([item])C1.add(item_set)return C1def scanD(D, ck, minsupport):ssCnt = {}for tid in D:for can in ck:if can.issubset(tid):if can not in ssCnt.keys():ssCnt[can] = 1else:ssCnt[can] += 1numItems = len(D)reList = []supportData = {}for key in ssCnt:support = ssCnt[key]/numItemsif support >= minsupport:reList.insert(0, key)supportData[key] = supportreturn reList, supportDatadef aprioriGen(Lk, k):retList = []lenLk = len(Lk)for i in range(lenLk):for j in range(i+1, lenLk):L1 = list(Lk[i])[k:-2]L2 = list(Lk[j])[:k-2]if L1 == L2:retList.append(Lk[i] | Lk[j])return retListdef apriori(dataSet,minSupport):# 首先找出最开始的数据项集C1 = createC1(dataSet)D = list(map(set,dataSet))# 把只有一个项集的支持率算出来L1,supportData = scanD(D,C1,minSupport)L = [L1]# 设置关联数k = 2while(len(L[k - 2]) > 0):# 然后开始循环找Ck = aprioriGen(L[k - 2], k)Lk, supK = scanD(D,Ck,minSupport)supportData.update(supK)L.append(Lk)k += 1return L,supportData第3关:从频繁项集中挖掘关联规则
任务描述
本关任务:编写 Python 代码,实现挖掘关联规则的功能。
相关知识
为了完成本关任务,你需要掌握:关联规则挖掘算法流程。
从频繁项集中挖掘关联规则
要找到关联规则,需要从一个频繁项集开始。我们知道集合中的元素是不重复的,但我们想知道基于这些元素能否获得其他内容。例如某个元素或者某个元素集合可能会推导出另一个元素 。从小卖铺的例子可以得到,如果有一个频繁项集
{薯片,西瓜},那么就可能有一条关联规则薯片->西瓜。这意味着如果有人购买了薯片,那么在统计上他会购买西瓜的概率较大。但是,这一条反过来并不总是成立。也就是说,即使
薯片->西瓜统计上显著,那么薯片->西瓜也不一定成立。(从逻辑研究上来讲,箭头左边的集合称作前件,箭头右边的集合称为后件。)那么怎样挖掘关联规则呢?在发现频繁项集时我们发现的是高于最小支持度的频繁项集,对于关联规则,也是用这种类似的方法。以小卖铺的例子为例,从项集
{0, 1, 2, 3}产生的关联规则中,找出可信度高于最小可信度的关联规则。(PS:Apriori 原理对于关联规则同样适用。)所以,想要根据上一关发现的频繁项集中找出关联规则,需要排除可信度比较小的关联规则,所以首先需要实现计算关联规则的可信度的功能。代码实现如下:
# 计算关联规则的可信度,并排除可信度小于最小可信度的关联规则# freqSet为频繁项集,H为规则右边可能出现的元素的集合,supportData为频繁项集的支持度,brl为存放关联规则的列表,minConf为最小可信度def calcConf(freqSet, H, supportData, brl, minConf = 0.7):prunedH = []for conseq in H:conf = supportData[freqSet]/supportData[freqSet - conseq]if conf >= minConf:brl.append((freqSet - conseq, conseq, conf))prunedH.append(conseq)return prunedH接下来就需要实现从频繁项集中生成关联规则的功能了,实现如下:
# 从频繁项集中生成关联规则# freqSet为频繁项集,H为规则右边可能出现的元素的集合,supportData为频繁项集的支持度,brl为存放关联规则的列表,minConf为最小可信度def ruleFromConseq(freqSet, H, supportData, brl, minConf = 0.7):m = len(H[0])if len(freqSet) > m+1:Hmp1 = aprioriGen(H, m+1)Hmp1 = calcConf(freqSet, Hmp1, supporData, brl, minConf)if len(Hmp1) > 1:ruleFromConseq(freqSet, Hmp1, supportData, brl, minConf)编程要求
根据提示,在右侧编辑器 Begin-End 补充代码,将所有知识全部串联起来,实现关联规则生成功能。
测试说明
平台会对你编写的代码进行测试,若与预期输出一致,则算通关
代码:
from utils import apriori, aprioriGendef calcConf(freqSet, H, supportData, brl, minConf = 0.7):prunedH = []for conseq in H:conf = supportData[freqSet]/supportData[freqSet - conseq]if conf >= minConf:brl.append((freqSet - conseq, conseq, conf))prunedH.append(conseq)return prunedHdef ruleFromConseq(freqSet, H, supportData, brl, minConf = 0.7):m = len(H[0])if len(freqSet) > m+1:Hmp1 = aprioriGen(H, m+1)Hmp1 = calcConf(freqSet, Hmp1, supporData, brl, minConf)if len(Hmp1) > 1:ruleFromConseq(freqSet, Hmp1, supportData, brl, minConf)def generateRules(dataset, minsupport, minConf):'''生成关联规则,可以使用apriori函数获得数据集中的频繁项集列表与支持度:param dataset:数据集,类型为list:param minsupport:最小支持度,类型为float:param minConf:最小可信度,类型为float:return:关联规则列表,类型为list'''digRuleList = []L, supportData = apriori(dataset, minsupport)for i in range(1, len(L)):# freqSet为含有i个元素的频繁项集for freqSet in L[i]:H1 = [frozenset([item]) for item in freqSet]if i > 1:# H1为关联规则右边的元素的集合ruleFromConseq(freqSet, H1, supportData, digRuleList, minConf)else:calcConf(freqSet, H1, supportData, digRuleList, minConf)return digRuleList第4关:超市购物清单关联规则分析
任务描述
本关任务:编写 Python 代码,挖掘出超市购物清单中潜在的关联规则。
相关知识
为了完成本关任务,你需要掌握:将知识运用到实际数据中。
超市购物清单关联规则分析
这里有一份超市的购物清单数据,数据的特征只有 3 个,分别为:交易时间,交易 id 和商品名称。如下图所示:
可以看出,在挖掘关联规则之前,我们需要整理一下数据,即根据交易 id 来将商品信息聚合起来,将数据变成我们关联规则分析算法所需要的形式。
当数据处理好之后,我们就可以使用之前编写的代码,来挖掘该数据的关联规则了。
编程要求
根据提示,在右侧编辑器 Begin-End 处补充代码,实现超市购物清单数据的关联规则挖掘功能。要求如下:
1.将所有商品名称转换为数字,转换关系如下:
{'yogurt':1, 'pork':2, 'sandwich bags':3, 'lunch meat':4, 'all- purpose':5, 'flour':6, 'soda':7, 'butter':8, 'vegetables':9, 'beef':10, 'aluminum foil':11, 'dinner rolls':12, 'shampoo':13, 'mixes':14, 'soap':15, 'laundry detergent':16, 'ice cream':17, 'toilet paper':18, 'hand soap':19, 'waffles':20, 'cheeses':21, 'milk':22, 'dishwashing liquid/detergent':23, 'individual meals':24, 'cereals':25, 'tortillas':26, 'spaghetti sauce':27, 'ketchup':28, 'sandwich loaves':29, 'poultry':30, 'bagels':31, 'eggs':32, 'juice':33, 'pasta':34, 'paper towels':35, 'coffee/tea':36, 'fruits':37, 'sugar':38}2.关联规则列表中的商品必须是转换后的数字。
注意:数据文件为
.csv文件,字段名分别为:date,id,good。测试说明
平台会对你编写的代码进行测试,判题程序将自动将数字转换为商品名称:
测试输入:
{'min_support':0.2,'min_conf':0.7}预期输出:
eggs->vegetables:0.8378378378378379juice->vegetables:0.780885780885781cereals->vegetables:0.7849223946784922individual meals->vegetables:0.7593457943925235laundry detergent->vegetables:0.8167053364269142butter->vegetables:0.7708830548926013ice cream->vegetables:0.7599118942731278yogurt->vegetables:0.8310502283105023代码:
from utils import generateRules import pandas as pddef T(x):m = {'yogurt': 1, 'pork': 2, 'sandwich bags': 3, 'lunch meat': 4, 'all- purpose': 5, 'flour': 6, 'soda': 7, 'butter': 8,'vegetables': 9, 'beef': 10, 'aluminum foil': 11, 'dinner rolls': 12, 'shampoo': 13, 'mixes': 14, 'soap': 15,'laundry detergent': 16, 'ice cream': 17, 'toilet paper': 18, 'hand soap': 19, 'waffles': 20, 'cheeses': 21,'milk': 22, 'dishwashing liquid/detergent': 23, 'individual meals': 24, 'cereals': 25, 'tortillas': 26,'spaghetti sauce': 27, 'ketchup': 28, 'sandwich loaves': 29, 'poultry': 30, 'bagels': 31, 'eggs': 32, 'juice': 33,'pasta': 34, 'paper towels': 35, 'coffee/tea': 36, 'fruits': 37, 'sugar': 38}return m[x]def aprior_data(data):basket = []for id in data['id'].unique():a = [data['good'][i] for i, j in enumerate(data['id']) if j == id]basket.append(a)return basketdef genRules(data_path, min_support, min_conf):# *********Begin*********#data1 = pd.read_csv(data_path)data1['good'] = data1['good'].apply(T)data2 = aprior_data(data1)rult = generateRules(data2, min_support, min_conf)return rult #*********End*********#
相关文章:
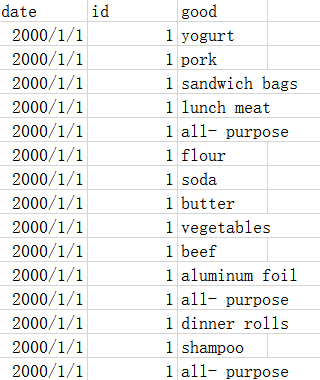
机器学习实践:超市商品购买关联规则分析
第2关:动手实现Apriori算法 任务描述 本关任务:编写 Python 代码实现 Apriori 算法。 相关知识 为了完成本关任务,你需要掌握 Apriori 算法流程。 Apriori 算法流程 Apriori 算法的两个输人参数分别是最小支持度和数据集。该算法首先会生成所…...

自动化图像识别:提高效率和准确性的新途径
自动化图像识别是人工智能领域中的一项关键技术,它通过算法自动解析图像内容,为各种应用提供准确的信息。随着技术的不断发展,自动化图像识别在提高效率和准确性方面展现出新的途径。 一、深度学习技术的应用 深度学习是自动化图像识别领域…...

根据最近拒包项目总结,详细讲解Google最新政策(上)
关于占比最多的移动垃圾软件拒审问题 移动垃圾软件(Mobile Unwanted Software)特征表现1> 具有欺骗性,承诺其无法实现的价值主张。2> 诱骗用户进行安装,或搭载在用户安装的其他程序上。3> 不向用户告知其所有主要功能和重要功能。4> 以非预期方式影响用户的系统…...

【Qt之OpenGL】01创建OpenGL窗口
1.创建子类继承QOpenGLWidget 2.重写三个虚函数 /** 设置OpenGL的资源和状态,最先调用且调用一次* brief initializeGL*/ virtual void initializeGL() override; /** 设置OpenGL视口、投影等,当widget调整大小(或首次显示)时调用* brief resizeGL* param w* para…...

如何判断代理IP质量?
由于各种原因(从匿名性和安全性到绕过地理限制),代理 IP 的使用变得越来越普遍。然而,并非所有代理 IP 都是一样的,区分高质量和低质量的代理 IP 对于确保流畅、安全的浏览体验至关重要。以下是评估代理 IP 质量时需要…...
)
2023-2024年Web3行业报告合集(精选13份)
Web3行业报告(精选13份) 2023-2024年 来源:2023-2024年Web3行业报告合集(精选13份) 【以下是资料目录】 2023Web3产业发展现状分析及国内外落地实践报告 2023模块化区块链承载Web3.0应用的新模式 2023年AI应用需求…...

CSS中文本样式(详解网页文本样式)
目录 一、Text介绍 1.概念 2.特点 3.用法 4.应用 二、Text语法 1.文本格式 2.文本颜色 3.文本的对齐方式 4.文本修饰 5.文本转换 6.文本缩进 7.color:设置文本颜色。 8.font-family:设置字体系列。 9.font-size:设置字体大小。…...
线性回归-20240507)
tensorflow学习笔记(2)线性回归-20240507
通过调用Tensorflow计算梯度下降的函数tf.train.GradientDescentOptimizer来实现优化。 代码如下: #!/usr/bin/env python3 # -*- coding: utf-8 -*- #程序作用: #线性回归:通过调用Tensorflow计算梯度下降的函数tr.train.GradientDescentOptimizer来实现优化。import os …...

【JavaScript】作用域
作用域是指在程序中定义变量的区域,决定了这些变量在哪里可以被访问和使用。JavaScript 中的作用域有全局作用域、函数作用域和块级作用域。 1. 什么是作用域? 作用域是代码中定义变量的区域,它决定了变量的可见性和生命周期。作用域规定了…...
C++程序设计教案
文章目录: 一:软件安装环境 第一种:vc2012 第二种:Dev-C 第三种:小熊猫C 二:语法基础 1.相关 1.1 注释 1.2 换行符 1.3 规范 1.4 关键字 1.5 ASCll码表 1.6 转义字符 2.基本框架 2.1 第一种&…...
修改Ubuntu远程登录欢迎提示信息
无论何时登录公司的某些生产系统,你都会看到一些登录消息、警告或关于你已登录服务器的信息,如下所示。 修改方式 1.打开ubuntu终端,进入到/etc/update-motd.d目录下面 可以发现目录中的文件都是shell脚本, 用户登录时服务器会自动加载这个目录中的文件…...
暗区突围pc端下载教程 暗区突围pc端怎么下载
暗区突围pc端下载教程 暗区突围pc端怎么下载 《暗区突围》是一款刺激的第一人称射击游戏。目前pc版本要上线了,即将在5月正式上线。在这款游戏里,我们会在随机的时间、地点,拿着不一定的装备,跟其他玩家拼个高低,还需…...

大数据技术原理与技术简答
1、HDFS中名称节点的启动过程 名称节点在启动时,会将FsImage 的内容加载到内存当中,此时fsimage是上上次关机时的状态。然后执行 EditLog 文件中的各项操作,使内存中的元数据保持最新。接着创建一个新的FsImage 文件和一个空的 Editlog 文件…...
Mybatis的简介和下载安装
什么是 MyBatis ? MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的…...
大历史下的 tcp:一个松弛的传输协议
如果 tcp 是一个相对松弛的协议,会发生什么。 所谓松弛感,意思是它允许 “漏洞”,允许可靠传输的不封闭,大致就是:“不求 100% 可靠,只要 90%(或多或少) 可靠,另外 10% 的错误可检测到” or “…...
加州大学欧文分校英语中级语法专项课程03:Tricky English Grammar 学习笔记
Tricky English Grammar Course Certificate Course Intro 本文是学习 https://www.coursera.org/learn/tricky-english-grammar?specializationintermediate-grammar 这门课的学习笔记 文章目录 Tricky English GrammarWeek 01: Nouns, Articles, and QuantifiersLearning …...

AI项目二十一:视频动态手势识别
若该文为原创文章,转载请注明原文出处。 一、简介 人工智能的发展日新月异,也深刻的影响到人机交互领域的发展。手势动作作为一种自然、快捷的交互方式,在智能驾驶、虚拟现实等领域有着广泛的应用。手势识别的任务是,当操作者做出…...

浅拷贝与深拷贝面试问题及回答
1. 浅拷贝和深拷贝的区别是什么? 答: 浅拷贝(Shallow Copy)仅复制对象的引用而不复制引用的对象本身,因此原始对象和拷贝对象会引用同一个对象。而深拷贝(Deep Copy)则是对对象内部的所有元素进…...

推荐算法顶会论文合集
SIGIR SIGIR 2022 | 推荐系统相关论文分类整理:8.74 https://mp.weixin.qq.com/s/vH0qJ-jGHL7s5wSn7Oy_Nw SIGIR2021推荐系统论文集锦 https://mp.weixin.qq.com/s/N7V_9iqLmVI9_W65IQpOtg SIGIR2020推荐系统论文聚焦: https://mp.weixin.qq.com/s…...

组合模式(Composite)——结构型模式
组合模式(Composite)——结构型模式 组合模式是一种结构型设计模式, 你可以使用它将对象组合成树状结构, 并且能通过通用接口像独立整体对象一样使用它们。如果应用的核心模型能用树状结构表示, 在应用中使用组合模式才有价值。 例如一个场景…...

水光仪专用屏四大核心优势:防刮耐腐、快交付、高性价比、全流程服务!
水光仪作为当下家用护肤、院线皮肤管理领域的热门智能设备,已成为精细化护肤的核心工具,无论是便携家用款,还是院线商用款,显示屏都是设备的核心人机交互窗口,承担着档位调节、模式切换、用量计时、耗材提醒、状态监控…...

WSL2+Ubuntu18.04远程桌面终极指南:从VNC配置到内网穿透全流程
WSL2Ubuntu18.04远程桌面终极指南:从VNC配置到内网穿透全流程 在开发者和系统管理员的日常工作中,能够随时随地访问开发环境已成为刚需。微软推出的WSL2(Windows Subsystem for Linux 2)让Linux环境与Windows无缝集成,…...

Elasticsearch数据写入后秒级延迟?3种刷新策略性能对比与实战选择
Elasticsearch数据写入延迟优化:3种刷新策略的深度性能解析与工程实践 当你刚刚完成一笔重要订单的数据录入,却发现前台搜索迟迟不显示最新库存——这种"数据写入后搜索不到"的尴尬,正是Elasticsearch近实时(NRT)特性带来的典型挑战…...

OpenClaw 技能推荐
OpenClaw 技能推荐 用了 OpenClaw 一段时间后,我发现它的技能系统是个宝藏。只要装对技能,AI 助手能帮你处理各种实际需求,从写文档到查天气,从浏览器自动化到开发辅助,都能覆盖。 这篇文章整理了我和身边人用下来觉得…...

MGeo地址结构化模型企业应用:挪车报警系统中的精准定位提效实践
MGeo地址结构化模型企业应用:挪车报警系统中的精准定位提效实践 1. 引言:从“说不清地址”到“一键精准定位” 想象一下这个场景:深夜,你接到一个挪车报警电话,电话那头的人焦急万分:“我的车被堵了&…...

AI时代全栈天花板!TypeScript生态实战宝典:终结碎片化,从入门到部署一步到位
前言 在AI浪潮席卷开发圈的今天,全栈开发的门槛正被重新定义。AI工具虽能简化编码、自动生成片段,但许多开发者的“全栈焦虑”并未消失,反而愈发凸显: 前端开发者懂React,却不会借助AI优化后端接口逻辑;后…...

从‘一次性‘到‘长期‘:微信小程序订阅消息模板全解析与 wx.requestSubscribeMessage 实战配置
从一次性到长期:微信小程序订阅消息模板全解析与 wx.requestSubscribeMessage 实战配置 在微信小程序的生态中,消息推送一直是连接用户与服务的重要桥梁。随着微信官方对消息推送机制的不断优化,订阅消息系统逐渐取代了早期的模板消息&#x…...

Clawdbot入门指南:Qwen3-32B代理网关CORS配置与前端跨域调用安全实践
Clawdbot入门指南:Qwen3-32B代理网关CORS配置与前端跨域调用安全实践 1. 引言:为什么需要关注CORS配置? 如果你正在使用Clawdbot这样的AI代理网关,并且在前端调用时遇到了跨域问题,那么这篇文章就是为你准备的。跨域…...
)
VS Code搭配Fitten Code:提升开发效率的10个隐藏技巧(附实战截图)
VS Code搭配Fitten Code:提升开发效率的10个隐藏技巧(附实战截图) 在当今快节奏的软件开发环境中,效率工具的选择往往能决定一个开发者的产出质量。VS Code作为最受欢迎的代码编辑器之一,其强大的扩展生态让开发者能够…...

MogFace人脸检测模型跨平台部署:从Windows开发到Linux生产环境
MogFace人脸检测模型跨平台部署:从Windows开发到Linux生产环境 你是不是也遇到过这种尴尬?在Windows电脑上用着顺手的PyCharm或者IDEA,吭哧吭哧把代码调通了,模型跑得也挺欢。结果一到要上线,生产服务器是Linux系统&a…...