Hadoop3:集群搭建及常用命令与shell脚本整理(入门篇,从零开始搭建)
一、集群环境说明
1、用VMware安装3台Centos7.9虚拟机
2、虚拟机配置:2C,2G内存,50G存储
3、集群架构设计
从表格中,可以看出,Hadoop集群,主要有2个模块服务,一个是HDFS服务,一个是YARN服务

二、搭建集群
1、安装3台Centos7.9虚拟机
安装教程:VMware安装Centos7详细教程及初始化配置
1.1、修改三台主机名
三台虚拟机固定IP:192.168.31.102、192.168.31.103、192.168.31.104
三台主机的hostname分别修改为,hadoop102,hadoop103,hadoop104
vim /etc/hostname
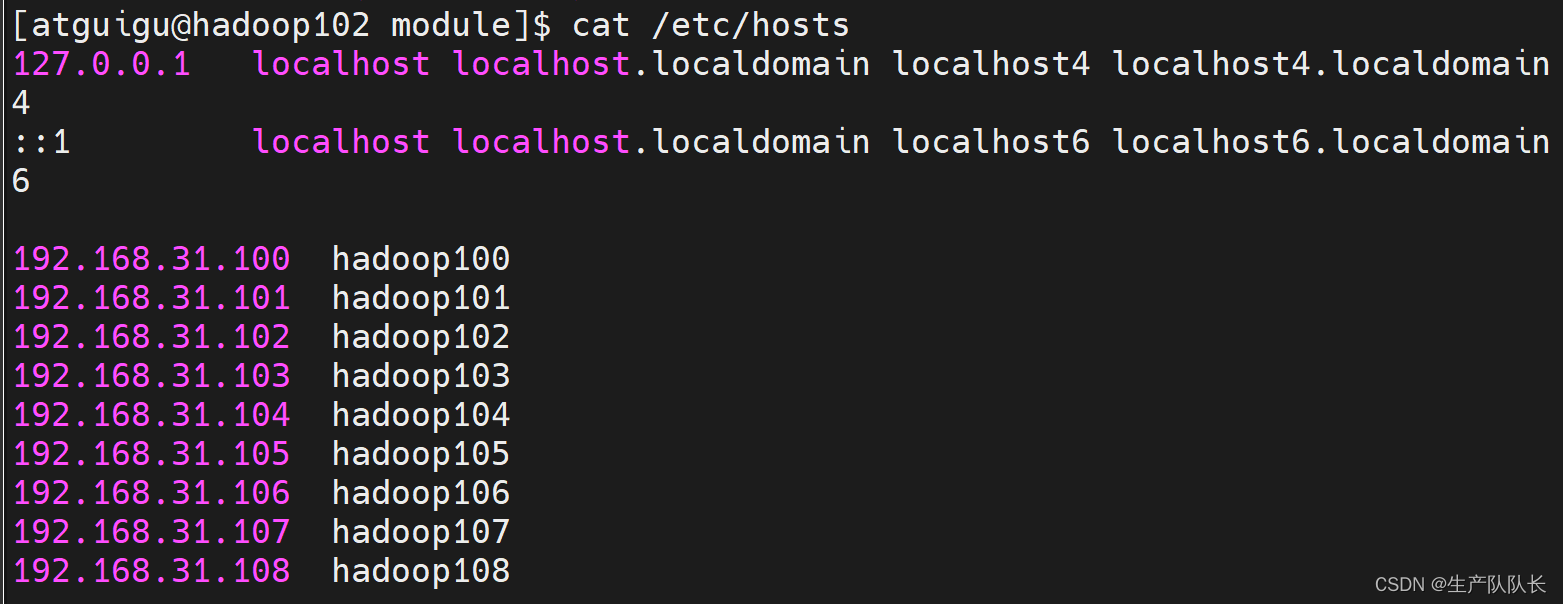
1.2、配置三台主机hosts文件
vim /etc/hosts192.168.31.100 hadoop100
192.168.31.101 hadoop101
192.168.31.102 hadoop102
192.168.31.103 hadoop103
192.168.31.104 hadoop104
192.168.31.105 hadoop105
192.168.31.106 hadoop106
192.168.31.107 hadoop107
192.168.31.108 hadoop108
1.3、三台机器创建账号
创建atguigu账号,并设置密码为123456
useradd atguigu
echo 123456|passwd --stdin atguigu;
配置atguigu账号root权限
visudo末尾添加
atguigu ALL=(ALL) NOPASSWD:ALL
1.4、三台机器间配置atguigu账号免密登陆
用102配置到103免密登陆为例
cd 进入当前账号家目录
ssh-keygen 连续三次回车
ssh-copy-id 192.168.31.103 复制公钥到hadoop103服务器,这样,102的atguigu就可以免密登陆hadoop103服务器
参考:服务器间配置免密登陆
1.5、同步集群时间(针对内网环境的集群,公网集群可以跳过)
找一个机器,作为时间服务器,所有的机器与这台机器的时间进行定时的同步

1.5.1、root账号配置102机器的ntp服务
1、查看ntp服务,并设置开机自启动
systemctl status ntpd
systemctl start ntpd
systemctl enable ntpd
如果命令报 Unit ntpd.service could not be found,则需要安装ntp服务
rpm -q ntp 查看服务是否安装
yum install ntp 安装服务
2、修改ntp.conf文件
vim /etc/ntp.confserver 127.127.1.0
fudge 127.127.1.0 stratum 10
restrict 后面的IP,写你们自己的IP,我的是192.168.31.0网段的
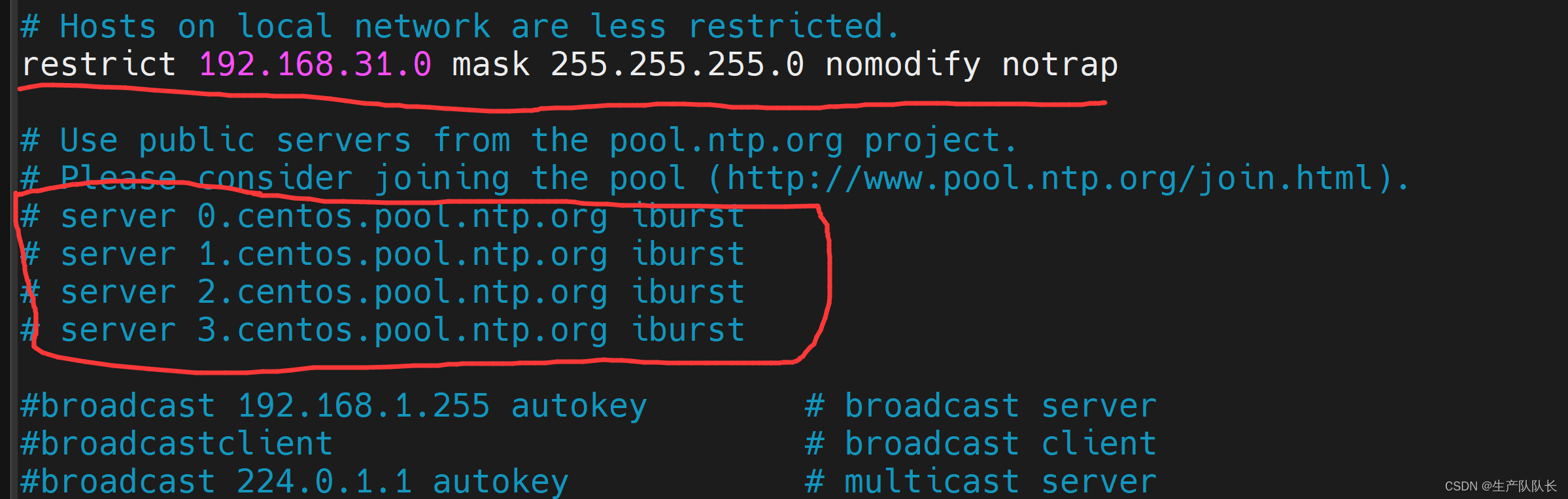
当该节点丢失网络连接,依然可以采 本地时间作为时间服务器,为集群中的其他节点提供时间同步

3、修改/etc/sysconfig/ntpd文件
作用:让硬件时间和系统时间一起同步,这样更精确
vim /etc/sysconfig/ntpdSYNC_HWCLOCK=yes
4、重启ntp服务
systemctl status ntpd
systemctl stop ntpd
systemctl start ntpd
systemctl enable ntpd检查配置
systemctl status ntpd
systemctl is-enabled ntpd
1.5.2、root账号配置103及104机器,同步102的时间
1、关闭ntp服务
systemctl stop ntpd
systemctl disable ntpd
2、创建定时任务,定时同步102时间
crontab -e*/1 * * * * /usr/sbin/ntpdate hadoop102
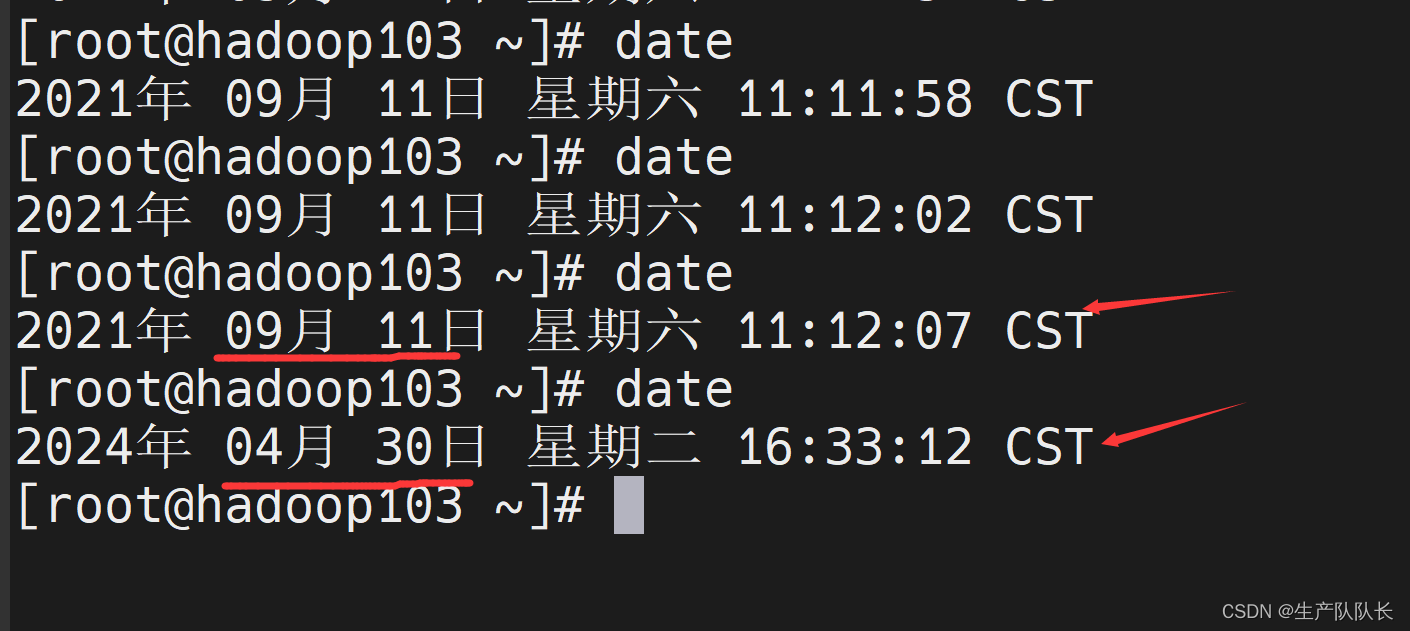
3、测试同步功能
修改时间
date -s "2021-9-11 11:11:11"
1分钟后,查看时间
date
2、三台虚拟机都安装JDK,并配置环境变量
2.1、卸载系统自带的OpenJDK
2.1.1、查看openJDK
[root@CFDB2 ~]$ rpm -qa|grep java
tzdata-java-2018e-3.el7.noarch
java-1.8.0-openjdk-1.8.0.171-8.b10.el7_5.x86_64
java-1.7.0-openjdk-headless-1.7.0.181-2.6.14.8.el7_5.x86_64
java-1.7.0-openjdk-1.7.0.181-2.6.14.8.el7_5.x86_64
javapackages-tools-3.4.1-11.el7.noarch
python-javapackages-3.4.1-11.el7.noarch
java-1.8.0-openjdk-headless-1.8.0.171-8.b10.el7_5.x86_64
2.1.2、卸载openJDK
rpm -qa | grep -i java | xargs n1 rpm -e --nodeps
2.2、安装JDK8
tar -zxvf jdk-7u79-linux-x64.tar.gz -C /usr/local/jdks/
cd /usr/local/jdks/vim /etc/profile.d/java.sh#!/bin/bash
#
export JAVA_HOME=/usr/local/jdks/jdk1.8.0_211
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
--------------------------
source /etc/profile #执行该命令
java -version #查看java是否安装成功
3、三台虚拟机都安装Hadoop3,并配置环境变量
1、准备Hadoop3安装包
 2、三台机器上准备两个目录
2、三台机器上准备两个目录

3、将hadoop3安装包上传到software目录下

4、解压并配置环境变量
解压安装
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
配置环境变量
进入目录cd /etc/profile.d/创建文件,并添加如下内容
vim hadoop.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin重新加载环境变量,这样新配置的hadoop环境变量才会生效
source /etc/profile
检查hadoop安装是否成
hadoop version
4、hadoop的4个自定义配置文件及workers配置
1、准备一个同步文件的脚本
参考:服务器同步文件脚本
这样,在102上配置好后,用该脚本同步到另外两台机器上即可。
2、core-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
完整配置内容如下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration>
<property><name>fs.defaultFS</name><value>hdfs://hadoop102:8020</value><description>指定 NameNode 的地址</description>
</property><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value><description>指定 Hadoop 数据的存储目录</description>
</property>
</configuration>
3、hdfs-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
完整配置内容如下
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value><description>nn web 端访问地址</description>
</property><property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value><description>2 nn web 端访问地址</description>
</property>
</configuration>
4、mapred-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml
完整配置内容如下
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>mapreduce.framework.name</name><value>yarn</value><description></description></property><property><name>mapreduce.jobhistory.address</name><value>hadoop102:10020</value><description>历史服务器端地址</description></property><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop102:19888</value><description>历史服务器 web 端地址</description></property>
</configuration>5、yarn-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
完整配置内容如下
<?xml version="1.0"?>
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>指定 MR 走 shuffle</description></property><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value><description>指定 ResourceManager 的地址</description></property> <property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value><description>系统环境变量的继承</description></property><property><name>yarn.log-aggregation-enable</name><value>true</value><description>开启日志聚集功能</description></property><property><description>设置日志聚集服务器地址</description><name>yarn.log.server.url</name><value>http://hadoop102:19888/jobhistory/logs</value></property><property><description>设置日志保留时间为 7 天, -1 表示不保存日志</description><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property></configuration>
6、配置workers
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
完整配置内容如下
hadoop102
hadoop103
hadoop104
7、使用xsync同步脚本,将配置文件同步到103、104
cd /opt/module/hadoop-3.1.3/etc/hadoopxsync core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml workers
5、102上启动HDFS服务
1、第一次启动的准备工作
需要在hadoop102上格式化 NameNode(后面重启hadoop集群,无需这一步操作)
cd /opt/module/hadoop-3.1.3
hdfs namenode -format

2、启动HDFS服务
cd /opt/module/hadoop-3.1.3
sbin/start-dfs.sh

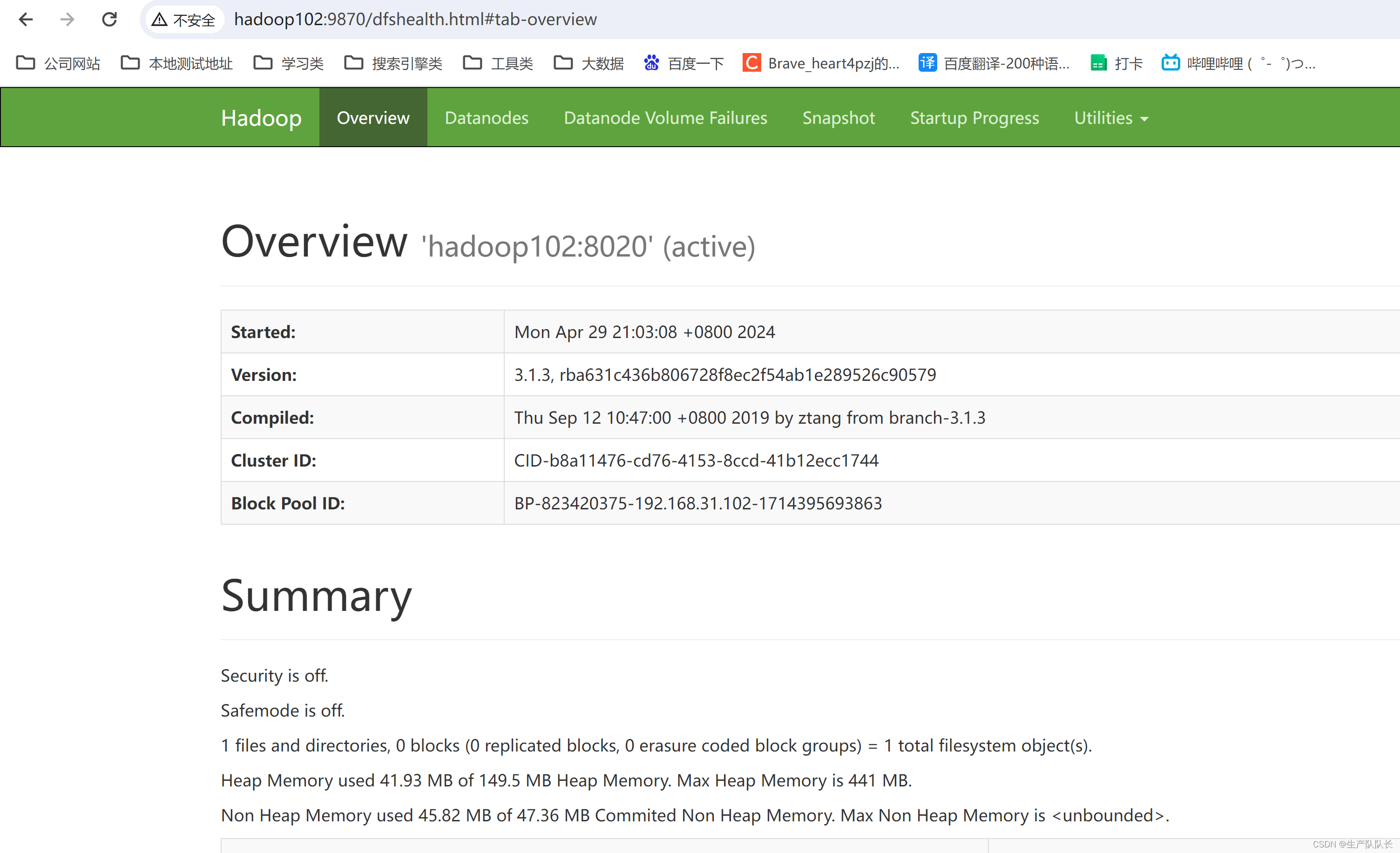
3、访问web页
http://hadoop102:9870
6、103上启动YARN服务
1、启动YARN服务
cd /opt/module/hadoop-3.1.3
sbin/start-yarn.sh

2、访问web页
http://hadoop103:8088

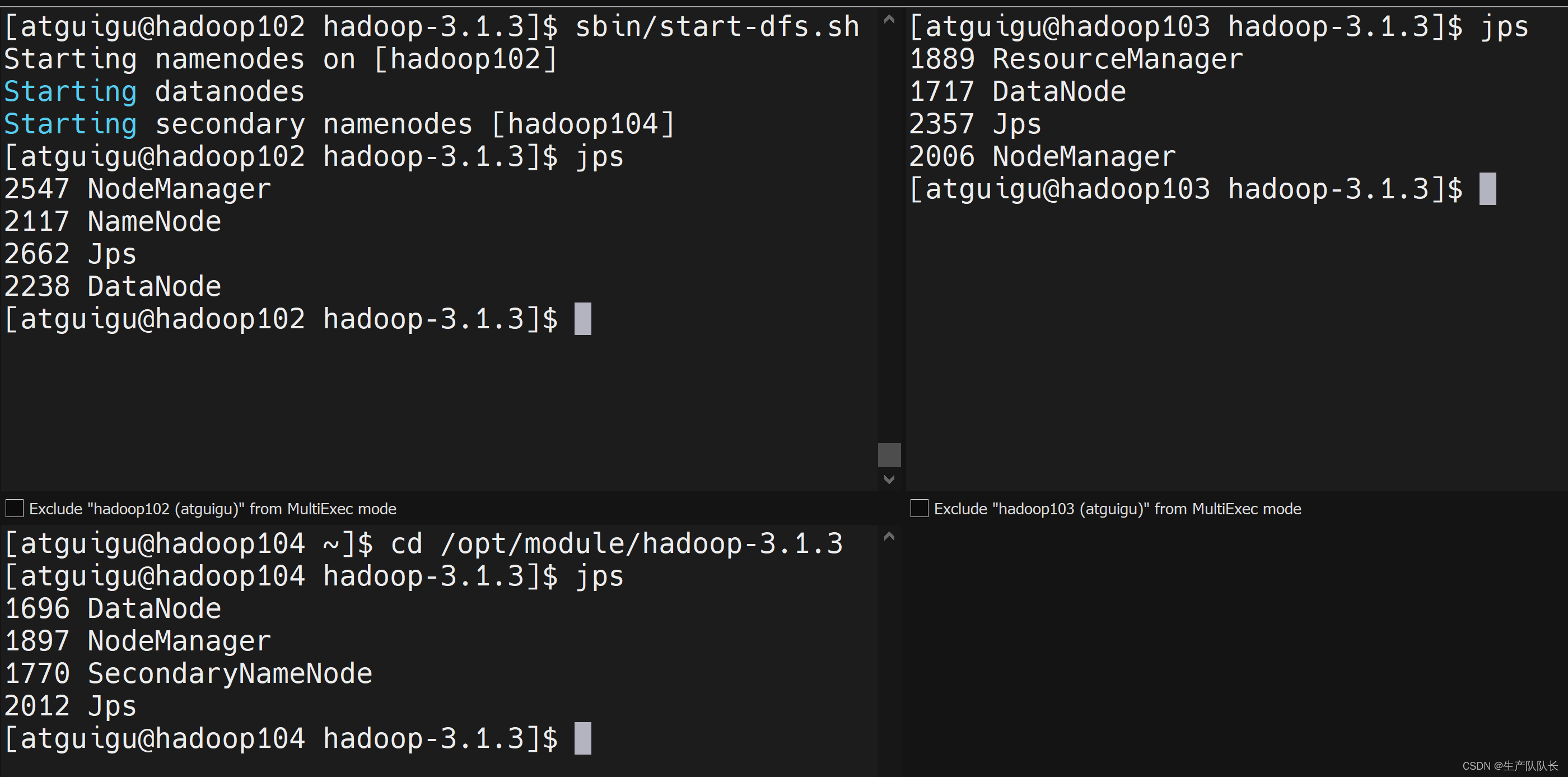
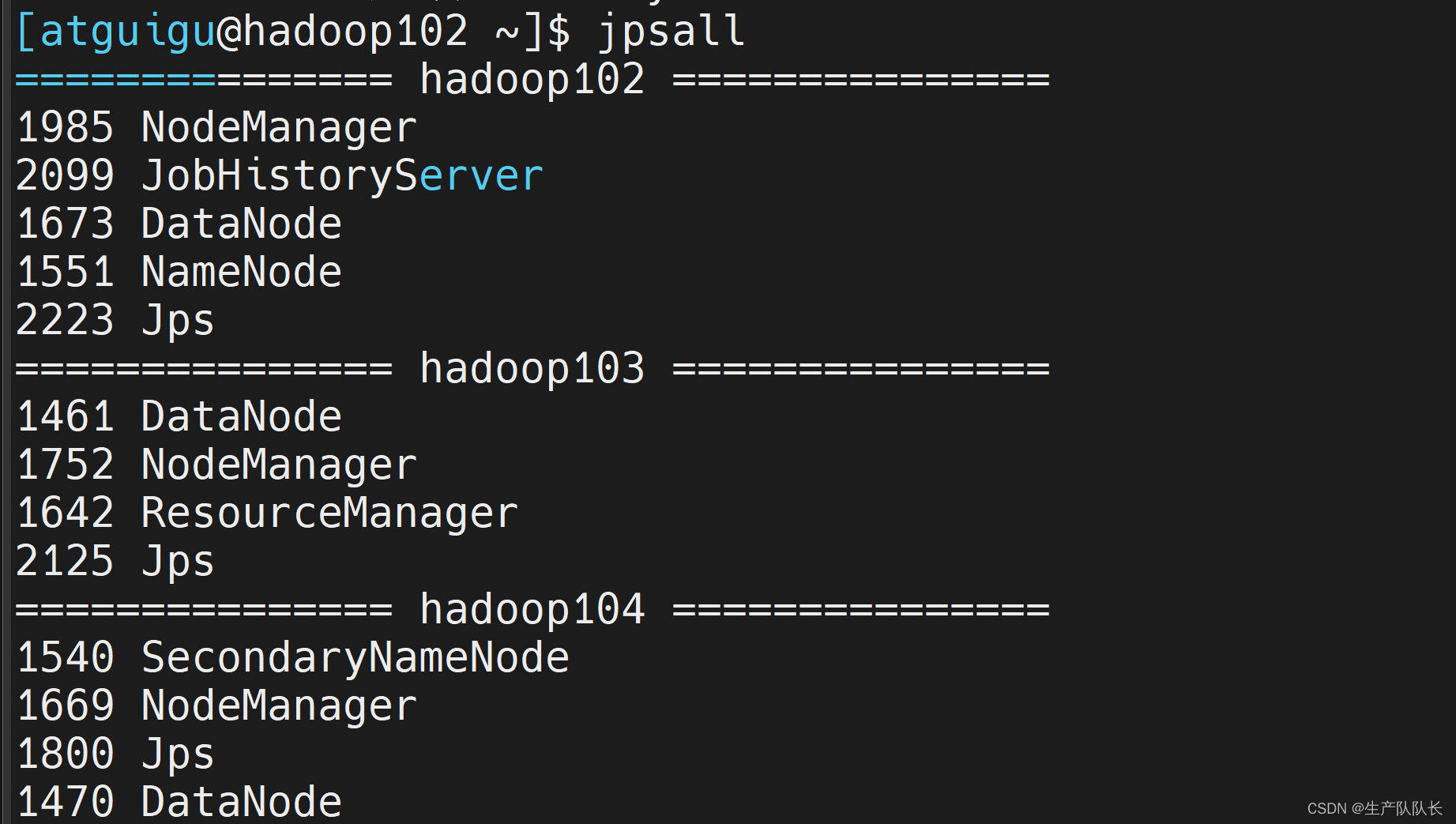
7、检查各个集群节点服务
从图中可以看出,和我们设计的集群架构完全匹配
8、在102上开启YARN的历史任务查询服务
cd /opt/module/hadoop-3.1.3
bin/mapred --daemon start historyserver

9、集群启动与停止方式总结
1、整体启动或停止HDFS或YARN服务
102上,启动或停止HDFS服务
cd /opt/module/hadoop-3.1.3
sbin/start-dfs.sh
sbin/stop-dfs.sh
103上,启动或停止YARN服务
cd /opt/module/hadoop-3.1.3
sbin/start-yarn.sh
sbin/stop-yarn.sh
2、各个服务组件独立启动或停止
分别启动或停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
分别启动或停止YARN组件
yarn --daemon start/stop resourcemanager/nodemanager
3、编写脚本,一键启动或停止器群并检查服务脚本
1、一键启动或停止脚本
cd /home/atguigu/bin/
vim myhadoop
脚本内容
#!/bin/bashif [ $# -lt 1 ]
thenecho "No Args Input..."exit ;
ficase $1 in
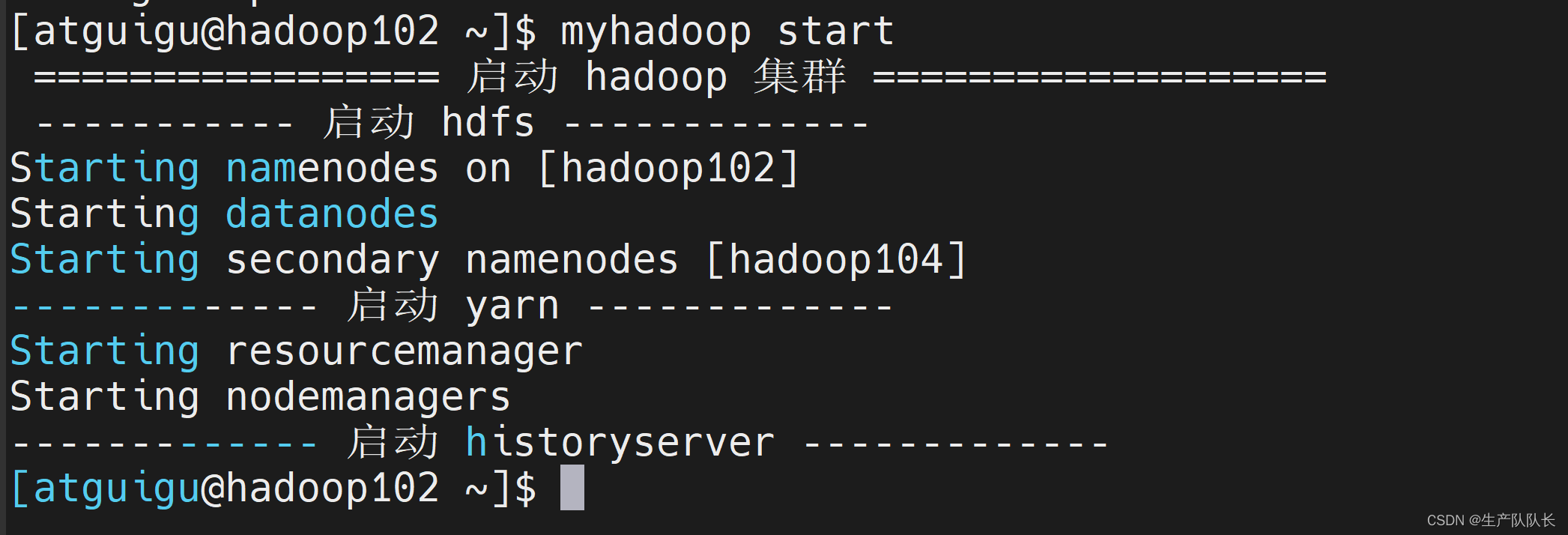
"start")echo " ================= 启动 hadoop 集群 ===================" echo " ----------- 启动 hdfs -------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo "------------- 启动 yarn -------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"echo "------------- 启动 historyserver -------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")echo " =================== 关闭 hadoop 集群 ===================" echo "------------- 关闭 historyserver -------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"echo "------------- 关闭 yarn -------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo "------------- 关闭 hdfs -------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*) echo "Input Args Error..."
;;
esac
脚本用法
myhadoop start/stop
2、一键检查服务脚本
cd /home/atguigu/bin/
vim jpsall
脚本内容
#!/bin/bashfor host in hadoop102 hadoop103 hadoop104
doecho =============== $host ===============ssh $host jps
done
脚本用法
jpsall
10、简单测试集群功能
1、命令行上传文件及HDFS web端查看
上传小文件
创建文件
mkdir /opt/module/hadoop-3.1.3/wcinput
cd /opt/module/hadoop-3.1.3/wcinput
vim word.txt
ss ss
cls cls
banzhang
bobo
yangge
上传文件
hadoop fs -mkdir /input 创建hdfs目录
hadoop fs -put $HADOOP_HOME/wcinput/word.txt /input 上传文件到input目录
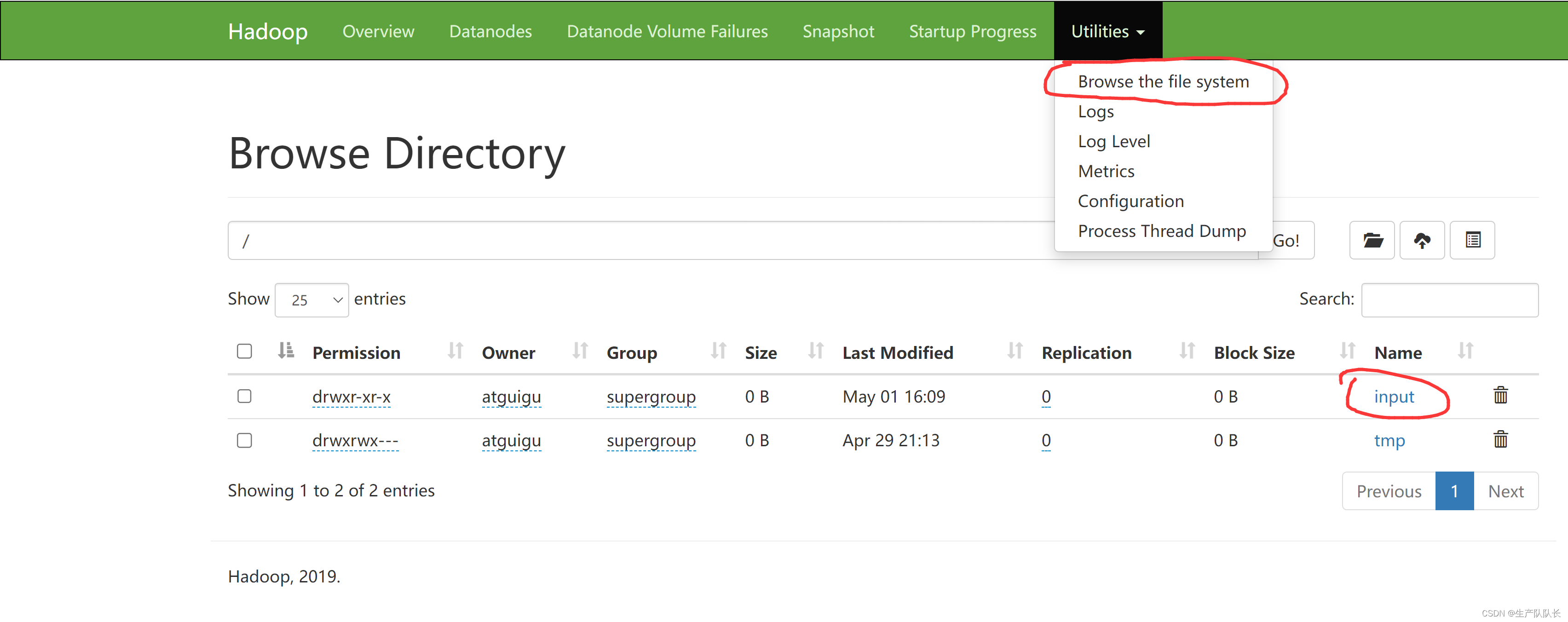
HDFS WEB页查看
这里的input就是-mkdir创建出来的
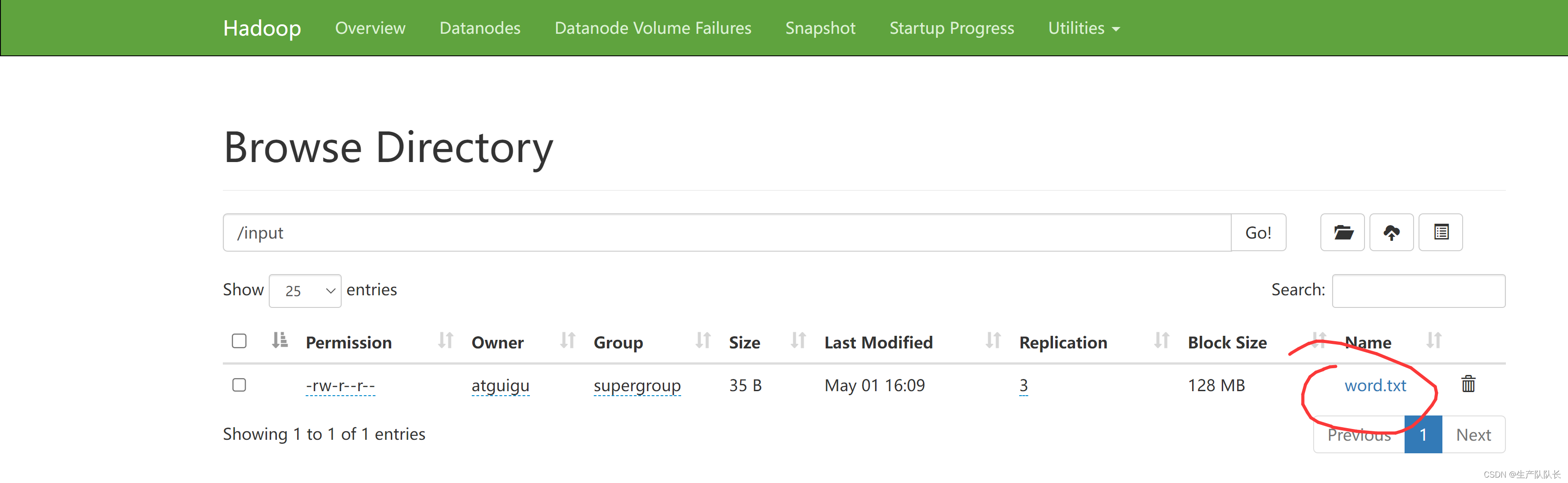
这个word.txt就是-put上传的
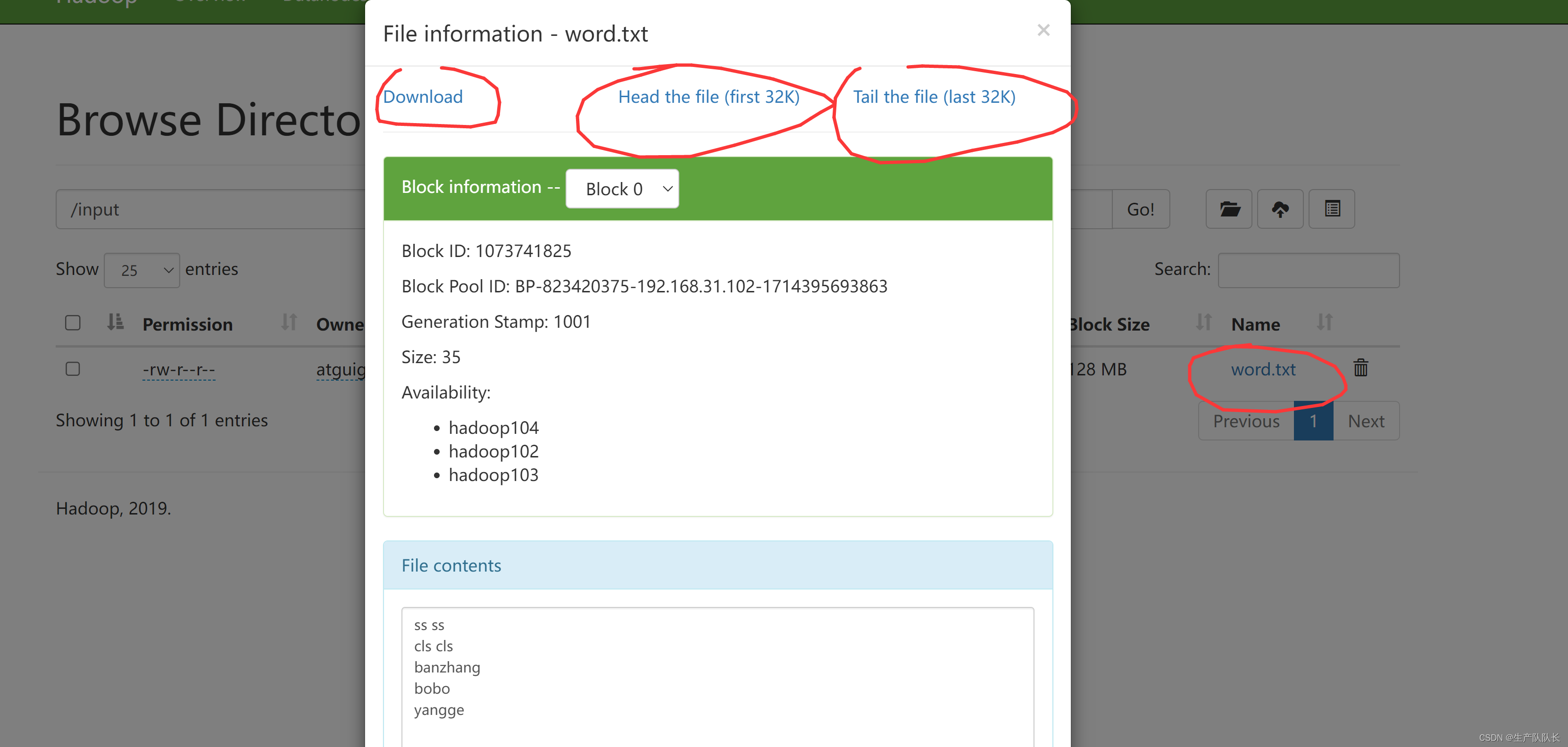
第一个下载、第二个查看文件前32K内容、第三个查看文件末尾的32K内容
上传大文件
上传文件
上传jar包到hdfs根目录
hadoop fs -put /opt/software/hadoop-3.1.3.tar.gz /
HDFS WEB页查看
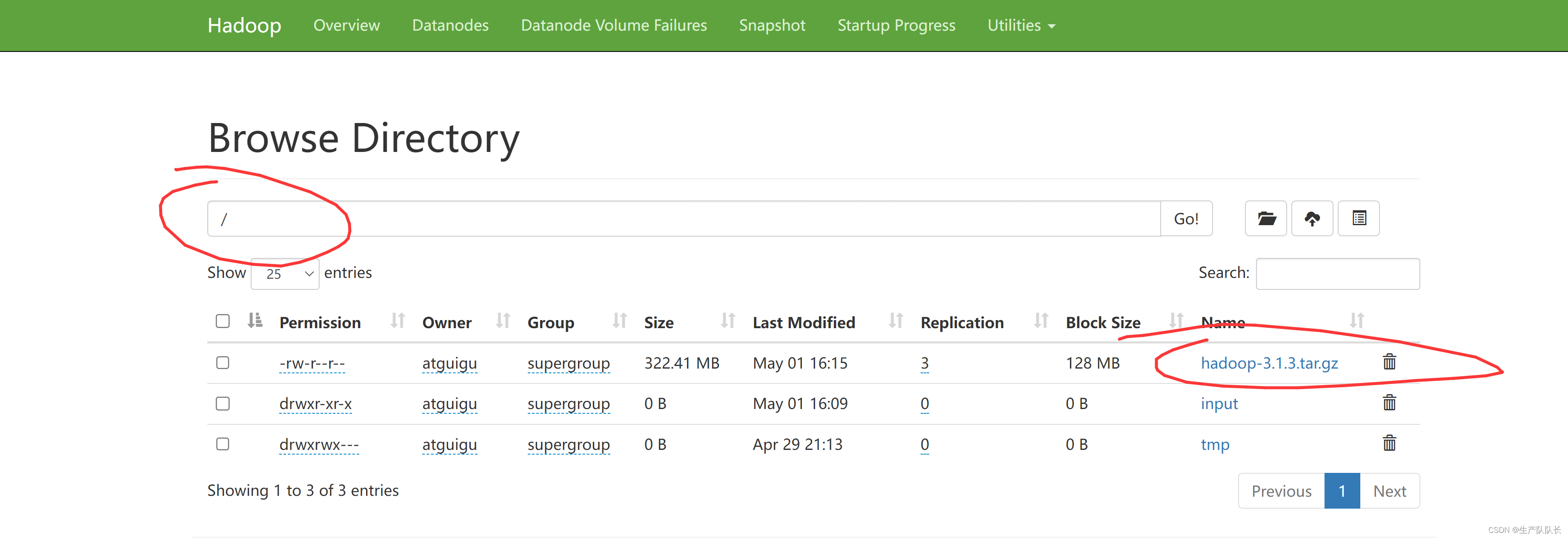
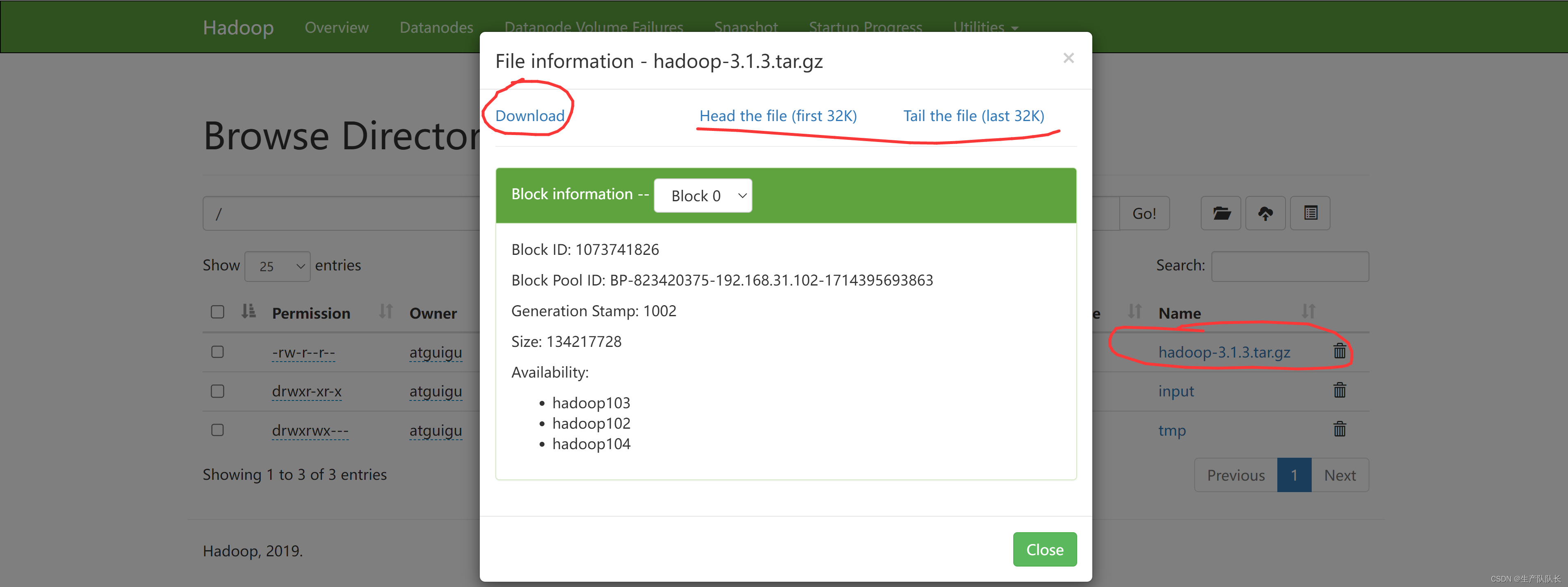
2、HDFS系统中查看上传的文件位置及文件内容
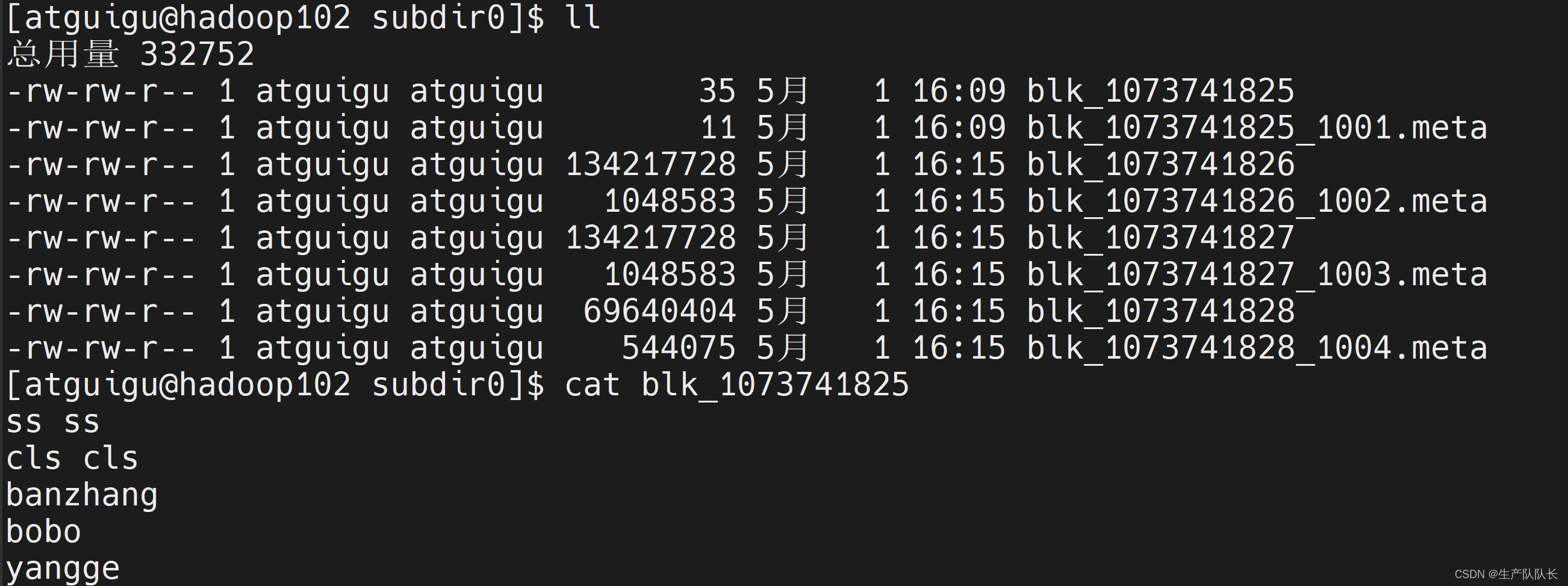
服务器上查看
txt文本文件查看方法
可以直接cat命令查看
cd /opt/module/hadoop-3.1.3/data/dfs/data/current/BP-823420375-192.168.31.102-1714395693863/current/finalized/subdir0/subdir0
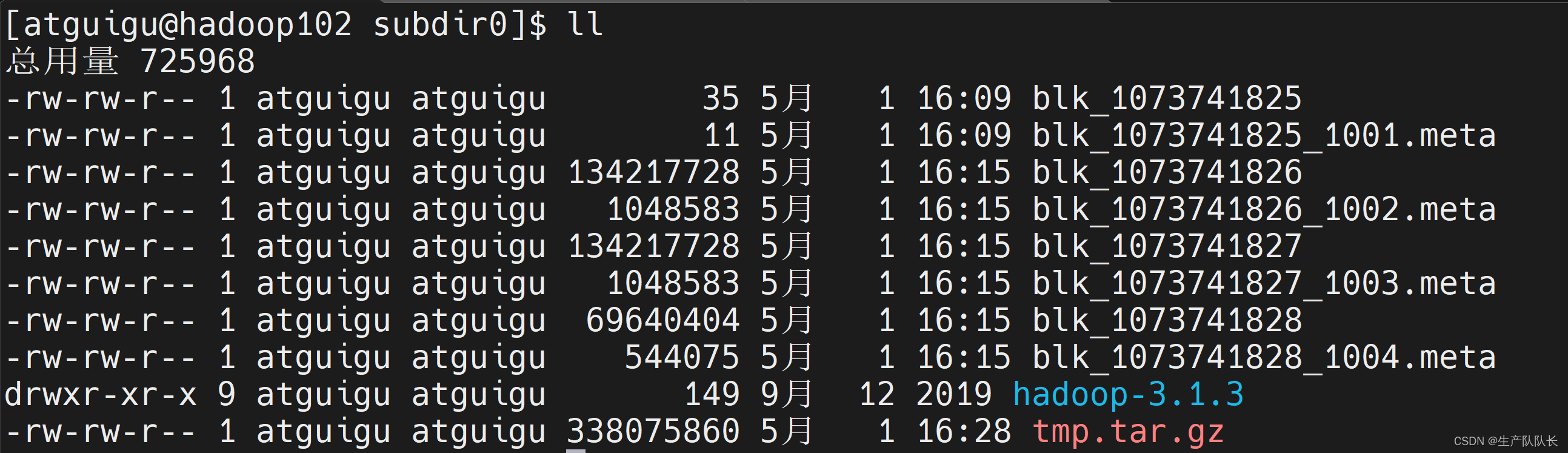
jar包文件查看方法
cd /opt/module/hadoop-3.1.3/data/dfs/data/current/BP-823420375-192.168.31.102-1714395693863/current/finalized/subdir0/subdir0cat blk_1073741826 >> tmp.tar.gz
cat blk_1073741827 >> tmp.tar.gz
cat blk_1073741828 >> tmp.tar.gztar -zxvf tmp.tar.gz
ll
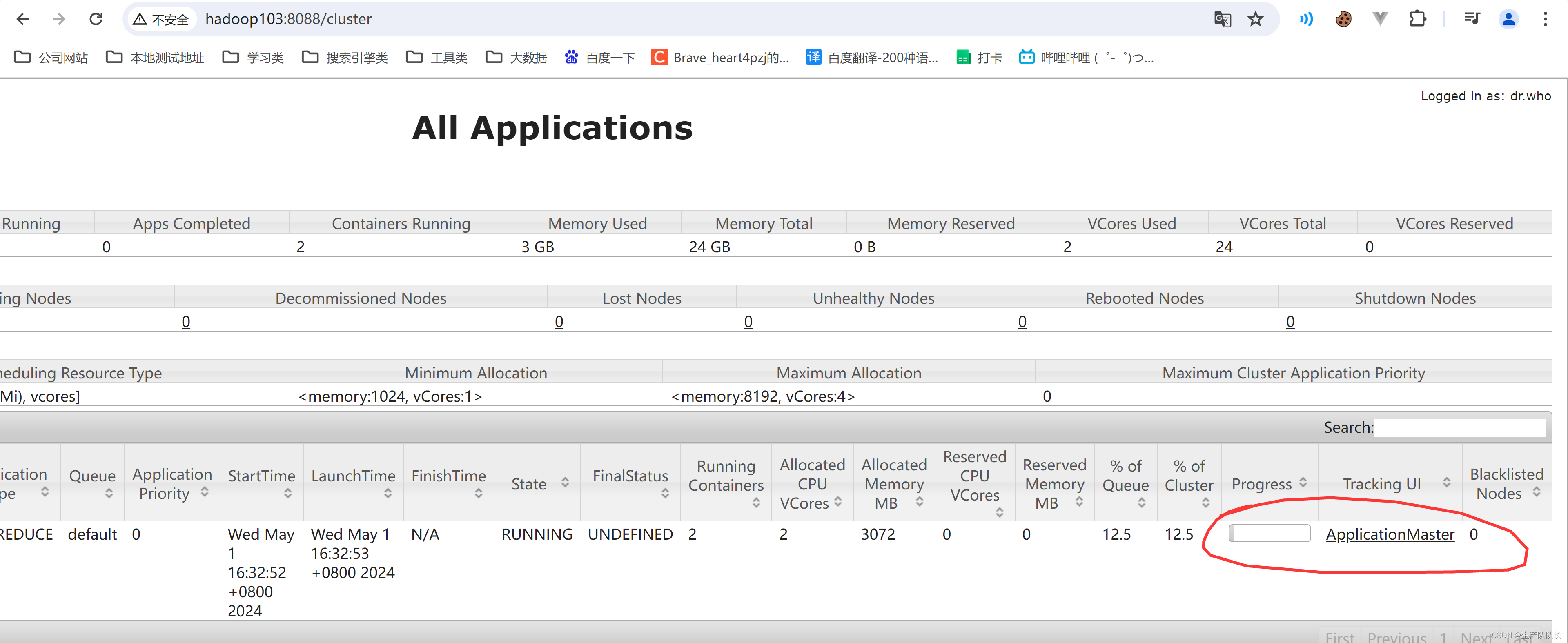
3、命令行执行MapReduce任务及YRAN web端查看任务
命令行执行MapReduce任务
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
YRAN web页查看任务
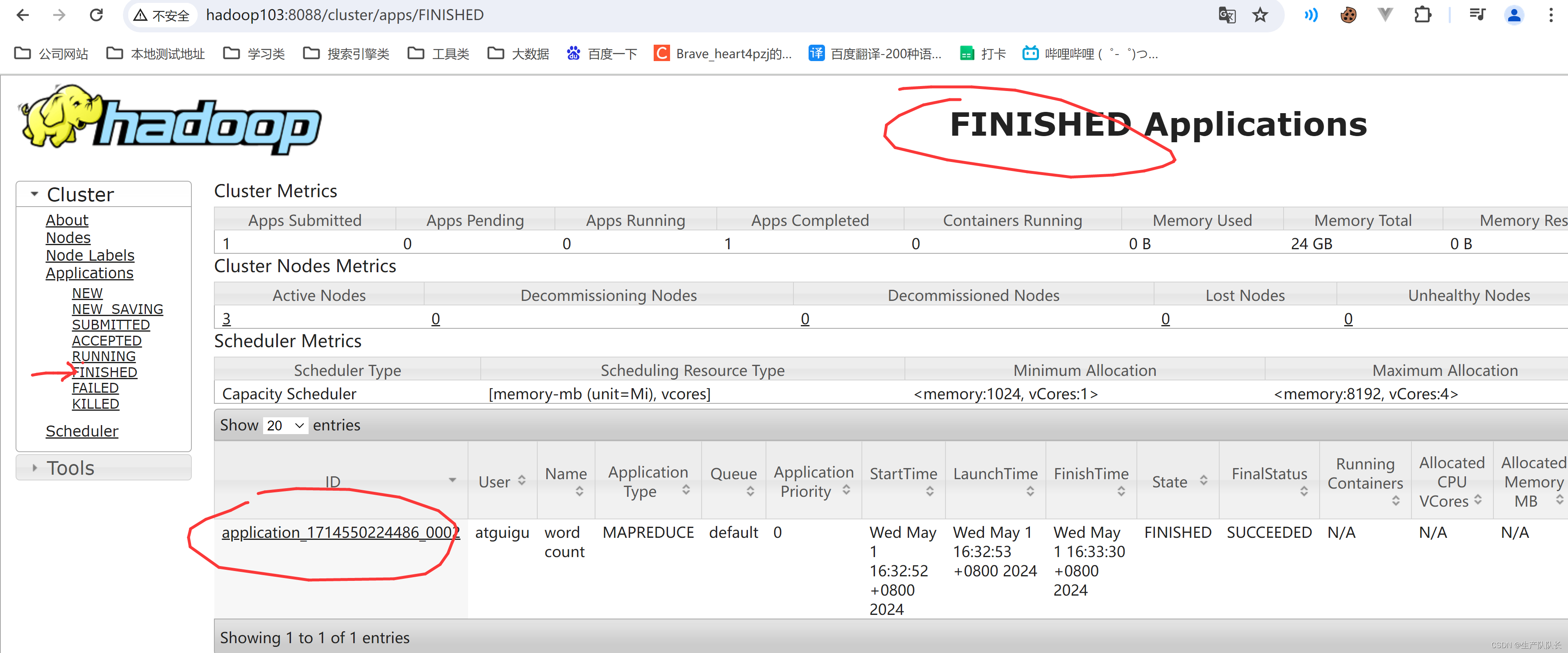
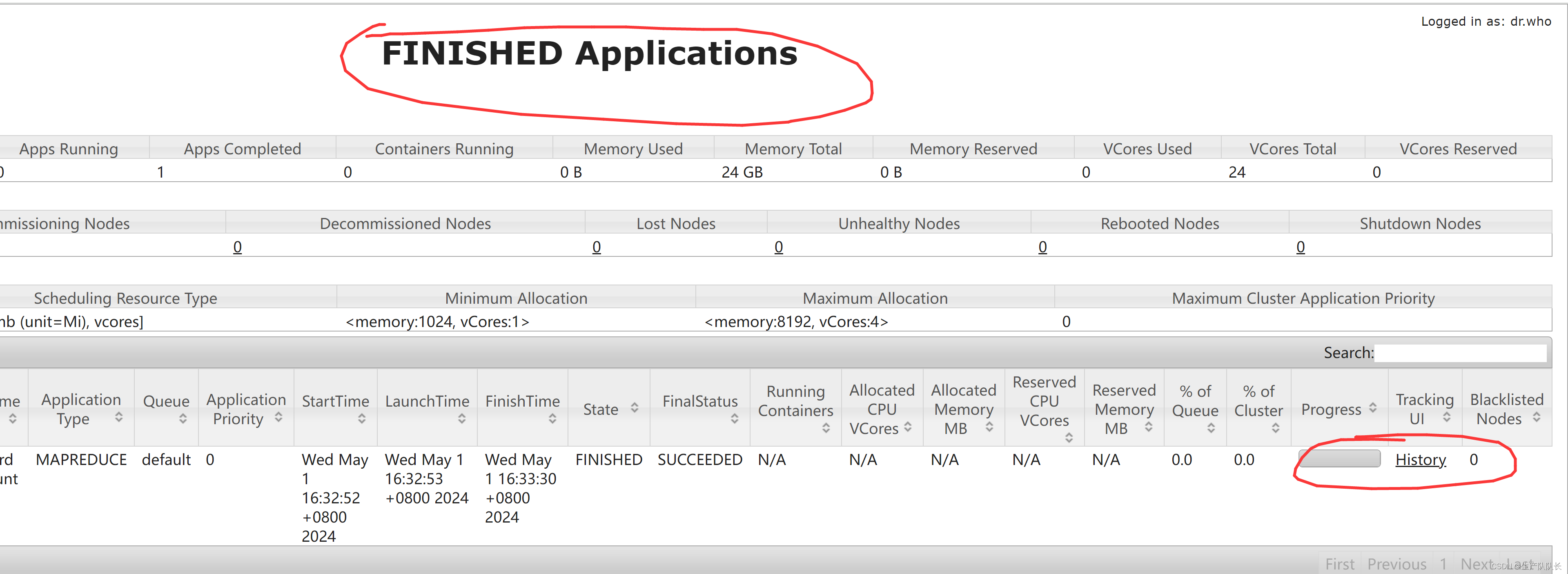
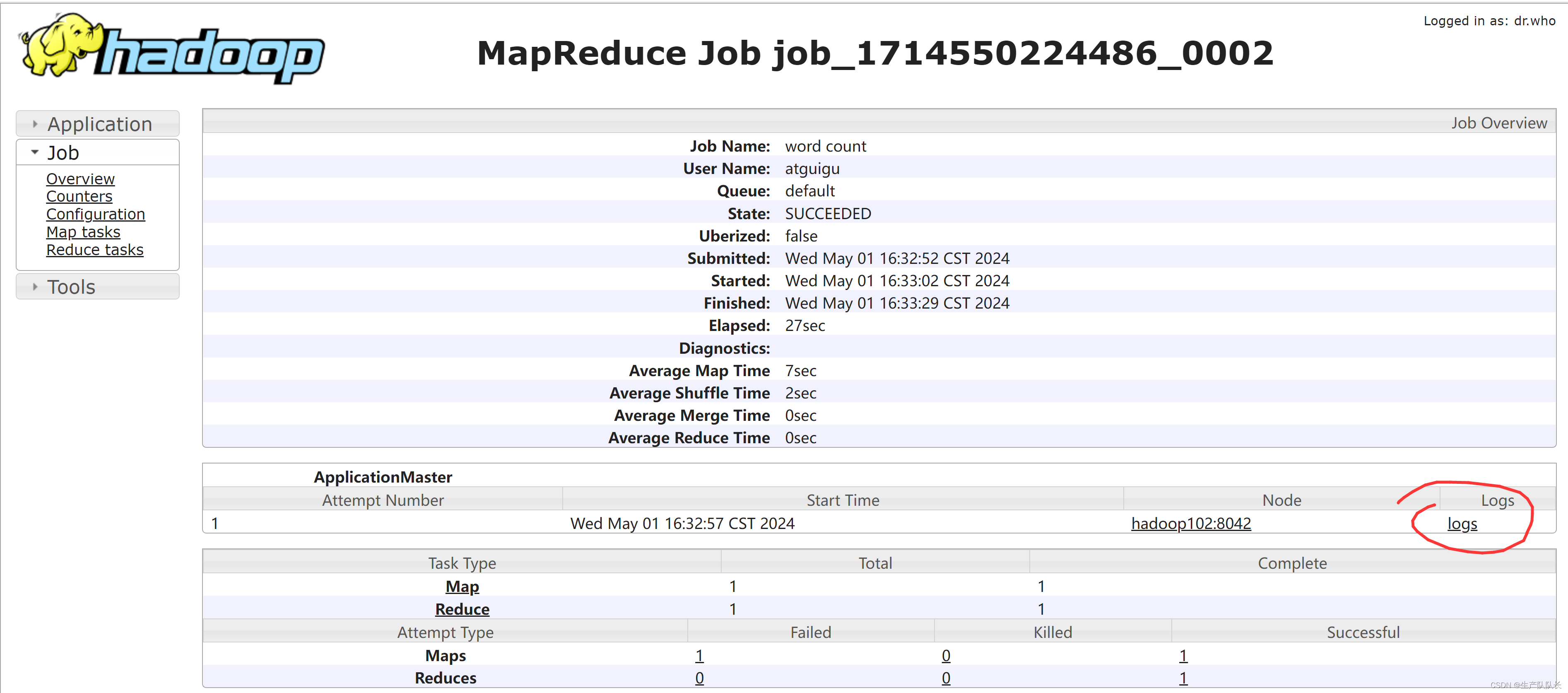
4、YRAN web页面查看历史任务
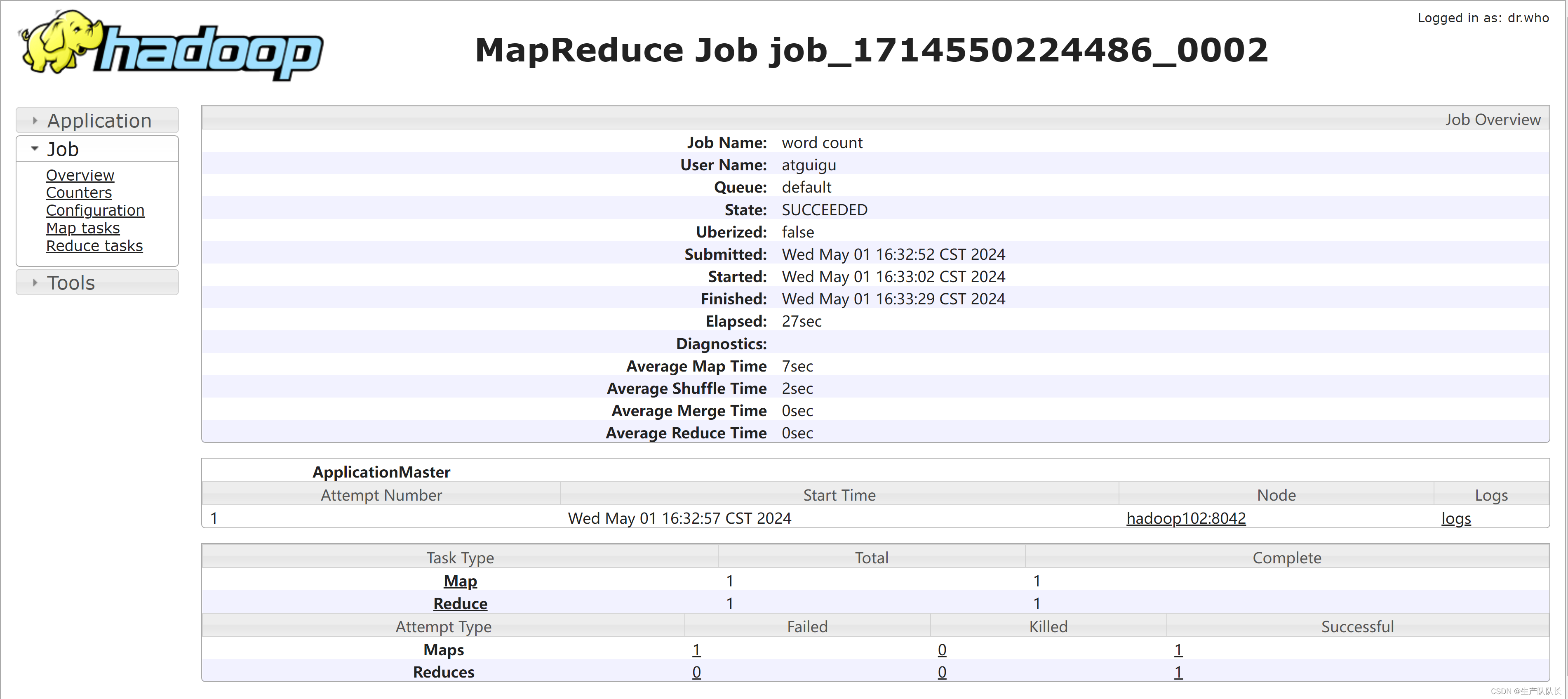
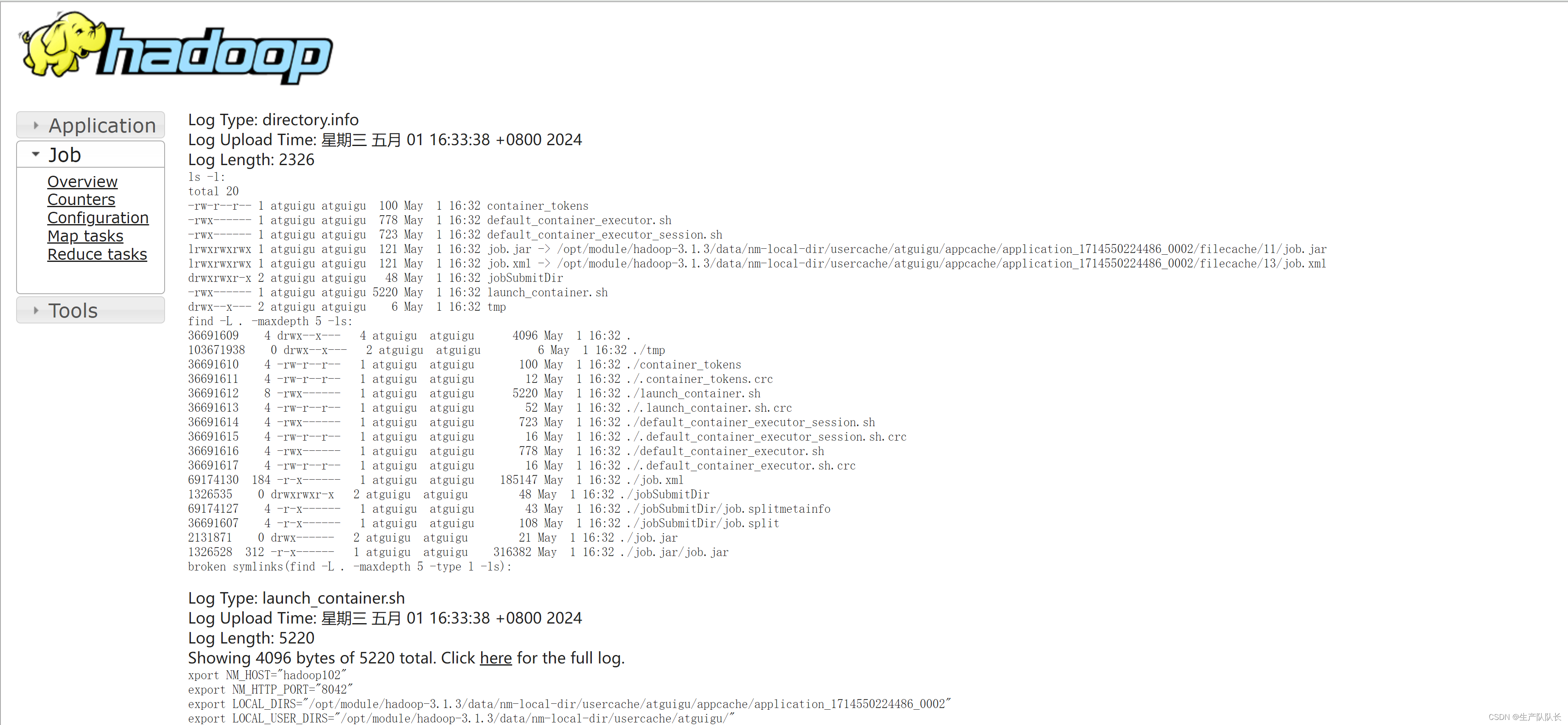
5、YRAN web页查看任务执行的日志
相关文章:
Hadoop3:集群搭建及常用命令与shell脚本整理(入门篇,从零开始搭建)
一、集群环境说明 1、用VMware安装3台Centos7.9虚拟机 2、虚拟机配置:2C,2G内存,50G存储 3、集群架构设计 从表格中,可以看出,Hadoop集群,主要有2个模块服务,一个是HDFS服务,一个是…...

yolo-world:”目标检测届大模型“
AI应用开发相关目录 本专栏包括AI应用开发相关内容分享,包括不限于AI算法部署实施细节、AI应用后端分析服务相关概念及开发技巧、AI应用后端应用服务相关概念及开发技巧、AI应用前端实现路径及开发技巧 适用于具备一定算法及Python使用基础的人群 AI应用开发流程概…...

vue3 + ts 快速入门(全)
文章目录 学习链接1. Vue3简介1.1. 性能的提升1.2.源码的升级1.3. 拥抱TypeScript1.4. 新的特性 2. 创建Vue3工程2.1. 基于 vue-cli 创建2.2. 基于 vite 创建(推荐)vite介绍创建步骤项目结构安装插件项目结构总结 2.3. 一个简单的效果Person.vueApp.vue …...

vue2实现面包屑功能
目录 1. store/index.js 2. router/index.js 3. Header.vue 在Vue 2中实现面包屑导航是一种常见的前端实践,它可以帮助用户了解当前页面在网站结构中的位置,并快速导航到上一级或根目录。以下是使用Vue 2实现面包屑导航的基本步骤: 1. st…...

helm安装 AWS Load Balancer Controller
1、创建AmazonEKSLoadBalancerControllerRole角色 亚马逊文档 创建文档 2)、使用 eksctl 创建 IAM 角色 a、安装eksctl eksctl安装文档 使用以下命令下载并提取最新版本的 eksctl curl --silent --location "https://github.com/weaveworks/eksctl/releases/l…...

贪吃蛇大作战(C语言--实战项目)
朋友们!好久不见。经过一段时间的沉淀,我这篇文章来和大家分享贪吃蛇大作战这个游戏是怎么实现的。 (一).贪吃蛇背景了解及效果展示 首先相信贪吃蛇游戏绝对称的上是我们00后的童年,不仅是贪吃蛇还有俄罗斯⽅块&…...

谷歌确认:链接并不那么重要
谷歌的 Gary Illyes 在最近的一次搜索营销会议上证实,谷歌只需要很少的链接,这为出版商需要关注其他因素提供了越来越多的证据。Gary 在推特上证实了他确实说过这些话。 排名链接的背景 20 世纪 90 年代末,搜索引擎发现链接是验证网站权威性…...

python基础--修饰器
修饰器(语法糖) 在python中函数实际上就是一个对象 def outer(x):def inner(y):return x yreturn innerprint(outer(6)(5))def double(x):return x * 2 def triple(x):return x * 3def calc_number(func, x):print(func(x))calc_number(double, 3) calc_number(triple, 3)函…...

6. Z 字形变换
题目描述 给你一个字符串s和行数numRows,把s字符串按照z字形重新排列。 再从左往右进行读取,返回读取之后的字符串。 本题是找规律,但是没有找出来 解题思路 要想解出来该题,在进行z字变换的时候,我们把字符串的下…...

shell常用文件处理命令
1. 解压 1.1 tar 和 gz 文件 如果你有一个 .tar 文件,你可以使用以下命令来解压: tar -xvf your_file.tar在这个命令中,-x 表示解压缩,-v 表示详细输出(可选),-f 后面跟着要解压的文件名。 如果你的 .tar 文件同时被 gzip 压缩了(即 .tar.gz 文件),你可以使用以下…...

从Paint 3D入门glTF
Paint 3D Microsoft Paint 3D是微软的一款图像编辑软件,它是传统的Microsoft Paint程序的升级版。 这个新版本的Paint专注于三维设计和创作,使用户可以使用简单的工具创建和编辑三维模型。 Microsoft Paint 3D具有直观的界面和易于使用的工具࿰…...
数据库(MySQL)—— DQL语句(基本查询和条件查询)
数据库(MySQL)—— DQL语句(基本查询和条件查询) 什么是DQL语句基本查询查询多个字段字段设置别名去除重复记录 条件查询语法条件 我们今天进入MySQL的DQL语句的学习: 什么是DQL语句 MySQL中的DQL(Data Q…...

如何根据索引删除数组中的元素,并保证删除的正确性
使用 splice() 方法来删除这些索引处的数据 var array [1, 2, 3, 4, 5]; var indexesToDelete [1, 3]; // 需要删除的索引// 将需要删除的索引按照从大到小的顺序排序,以避免删除元素后索引发生变化 indexesToDelete.sort((a, b) > b - a);// 遍历需要删除的索…...
Shell编程规范与变量
目录 一、shell脚本概述 Shell脚本的概念 Shel脚本应用场景 1、shell的作用 2、shell编程规范 Shell脚本的编写 Shell脚本的运行 3、重定向与管道 交互式硬件设备 重定向操作 管道操作符号"|" 二、shell脚本变量 变量的作用 变量的类型 1、自定义变量…...

武汉星起航:策略升级,亚马逊平台销售额持续增长显实力
武汉星起航电子商务有限公司,一家致力于跨境电商领域的企业,于2023年10月30日在上海股权托管交易中心成功挂牌展示,这一里程碑事件标志着公司正式踏入资本市场,开启了新的发展篇章。公司董事长张振邦在接受【第一财经】采访时表示…...
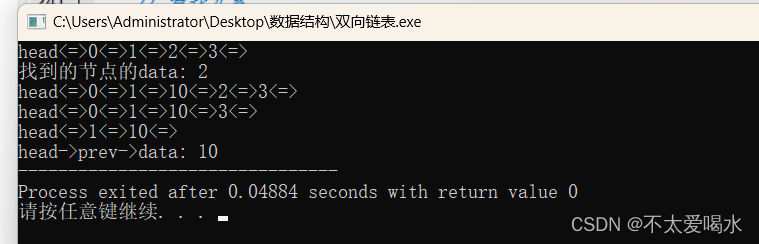
循环链表 -- c语言实现
#pragma once // 带头双向循环链表增删查改实现 #include<stdlib.h> #include<stdio.h> #include<assert.h>typedef int LTDataType;typedef struct ListNode {LTDataType data;struct ListNode* next;struct ListNode* prev; }ListNode;//双链表申请一个新节…...
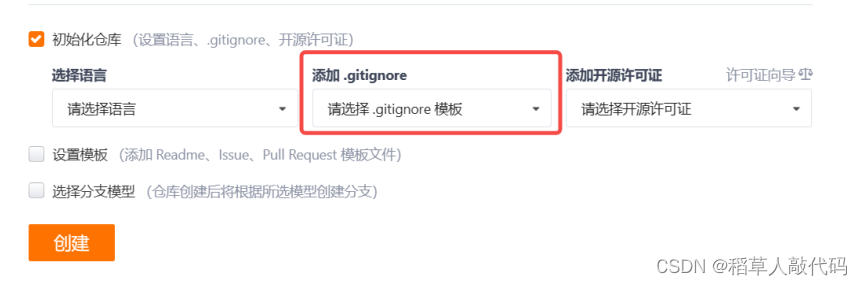
如何使git提交的时候忽略一些特殊文件?
认识.gitignore文件 在生成远程仓库的时候我们会看到这样一个选项: 这个.gitignore文件有啥用呢? .gotignore文件是Git版本控制系统中的一个特殊文件。用来指定哪些文件或者目录不被Git追踪或者提交到版本库中。也就意味着,如果我们有一些文…...
如何保证Redis双写一致性?
目录 数据不一致问题 数据库和缓存不一致解决方案 1. 先更新缓存,再更新数据 该方案数据不一致的原因 2. 先更新数据库,再更新缓存 3. 先删除缓存,再更新数据库 延时双删 4. 先更新数据库,再删除缓存 该方案数据不一致的…...

HarmonyOS实战开发-如何实现查询当前城市实时天气功能
先来看一下效果 本项目界面搭建基于ArkUI中TS扩展的声明式开发范式, 数据接口是和风(天气预报), 使用ArkUI自带的网络请求调用接口。 我想要实现的一个功能是,查询当前城市的实时天气, 目前已实现的功能…...
(三)JSP教程——JSP动作标签
JSP动作标签 用户可以使用JSP动作标签向当前输出流输出数据,进行页面定向,也可以通过动作标签使用、修改和创建对象。 <jsp:include>标签 <jsp:include>标签将同一个Web应用中静态或动态资源包含到当前页面中。资源可以是HTML、JSP页面和文…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...