【机器学习】集成方法---Boosting之AdaBoost
一、Boosting的介绍
1.1 集成学习的概念
1.1.1集成学习的定义
集成学习是一种通过组合多个学习器来完成学习任务的机器学习方法。它通过将多个单一模型(也称为“基学习器”或“弱学习器”)的输出结果进行集成,以获得比单一模型更好的泛化性能和鲁棒性。
1.1.2 集成学习的基本思想
集成学习的基本思想可以概括为“三个臭皮匠顶个诸葛亮”。通过将多个简单模型(弱学习器)的预测结果进行组合,可以得到一个更强大、更稳定的模型(强学习器)。这种组合可以有效地降低单一模型的偏差和方差,从而提高整体的预测性能。
1.1.3 集成学习的分类(Bagging vs Boosting)
集成学习方法主要分为两大类:Bagging和Boosting。
Bagging:Bagging(Bootstrap Aggregating)是一种并行式的集成学习方法。在Bagging中,各个弱学习器之间没有依赖关系,可以同时进行训练和预测。Bagging通过自助采样法(Bootstrap Sampling)从原始数据集中随机抽取样本生成多个子数据集,然后基于这些子数据集分别训练出多个弱学习器。最后,通过投票或平均的方式将这些弱学习器的输出进行组合,得到最终的预测结果。
Boosting:与Bagging不同,Boosting是一种串行式的集成学习方法。在Boosting中,弱学习器之间存在依赖关系,需要依次进行训练。Boosting算法会根据前一个弱学习器的预测结果来调整样本的权重,使得后续弱学习器能够更加注重前一个弱学习器预测错误的样本。通过这种方式,Boosting能够逐步优化模型的性能,最终将所有弱学习器的输出进行加权组合,得到更准确的预测结果。AdaBoost是Boosting算法中最具代表性的一种。Boosting的原理图如下所示:
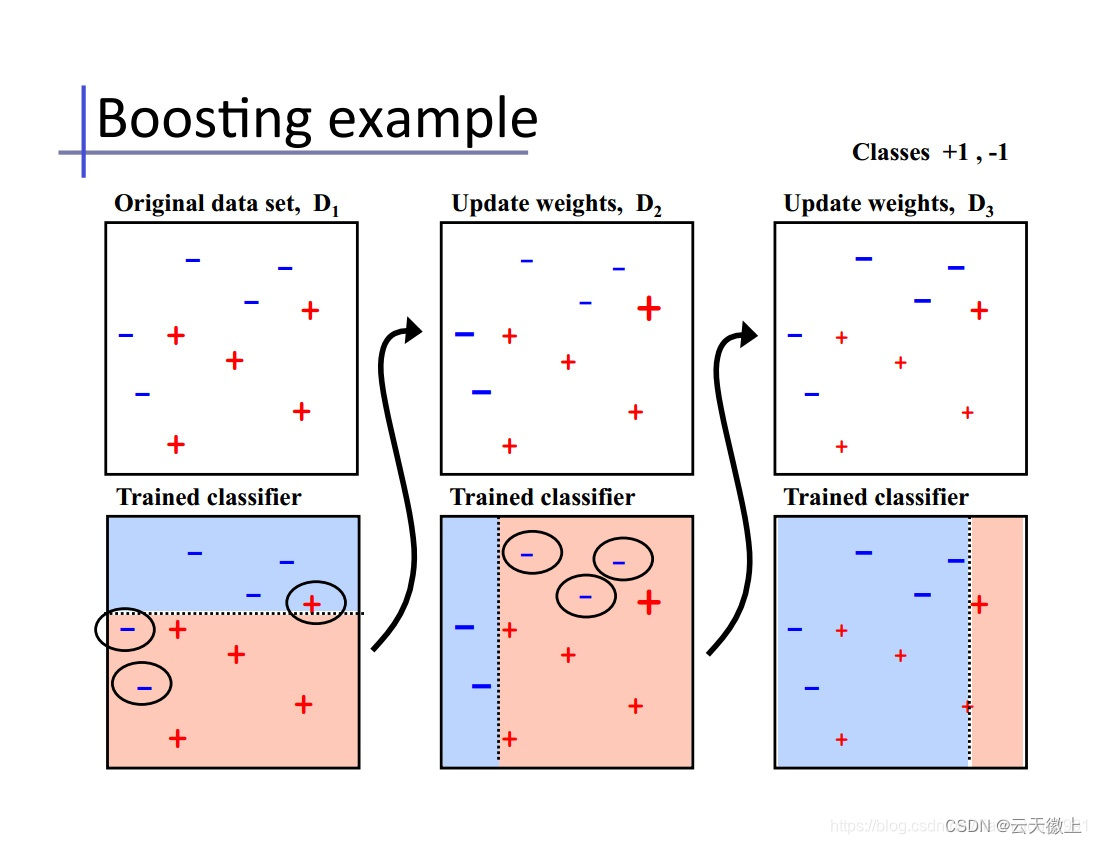
1.2 Boosting的基本原理
1.2.1 Boosting的核心思想
Boosting的核心思想是通过迭代训练多个弱学习器,并将它们进行加权组合,以形成一个强学习器。在每次迭代中,Boosting都会根据前一个弱学习器的预测结果来调整样本的权重,使得后续弱学习器能够更加注重前一个弱学习器预测错误的样本。通过这种方式,Boosting能够逐步优化模型的性能。
1.2.2 Boosting的串行化学习过程
Boosting的学习过程是串行的。在每次迭代中,Boosting都会根据当前的样本权重训练出一个新的弱学习器,并根据该弱学习器的预测结果来更新样本权重。这个过程会不断重复进行,直到达到预设的迭代次数或者满足其他停止条件为止。最终,Boosting会将所有训练得到的弱学习器进行加权组合,形成一个强学习器来进行预测。
1.2.3 Boosting的权重调整策略
Boosting算法中的权重调整策略是其核心机制之一。在每次迭代中,Boosting都会根据前一个弱学习器的预测结果来调整样本的权重。具体来说,如果某个样本在前一个弱学习器中被预测错误,那么它在后续迭代中的权重就会增加;反之,如果某个样本在前一个弱学习器中被预测正确,那么它在后续迭代中的权重就会减少。通过这种方式,Boosting能够使得后续弱学习器更加注重前一个弱学习器预测错误的样本,从而逐步优化模型的性能。
1.3 Boosting与其他集成方法的比较
1.3.1 Boosting与Bagging的区别
a. 样本选择:Bagging通过自助采样法随机抽取样本生成多个子数据集进行训练;而Boosting则是根据前一个弱学习器的预测结果来调整样本权重进行训练。
b. 弱学习器权重:Bagging中各个弱学习器的权重通常是相等的;而在Boosting中,每个弱学习器都有一个与之对应的权重,这个权重是根据该弱学习器的性能来计算的。
c. 并行与串行:Bagging是一种并行式的集成学习方法,各个弱学习器可以同时进行训练和预测;而Boosting则是一种串行式的集成学习方法,弱学习器需要依次进行训练。
1.3.2 Boosting在实际应用中的优势
a. 性能提升:通过迭代训练和权重调整策略,Boosting能够逐步提升模型的性能,使得最终得到的强学习器具有更高的预测精度和鲁棒性。
b. 适应性强:Boosting算法可以适应不同的数据分布和特征空间,因此在处理复杂问题时具有较好的灵活性。
c. 可解释性强:由于Boosting算法中的每个弱学习器都具有一定的解释性(如决策树),因此最终的强学习器也具有较强的可解释性,便于理解和分析模型的预测结果。
二、AdaBoost原理
2.1 AdaBoost算法概述
2.1.1 AdaBoost的起源与发展
AdaBoost(Adaptive Boosting)算法是一种自适应的Boosting方法,起源于Robert Schapire和Yoav Freund在1995年发表的一篇论文。AdaBoost算法通过对一系列弱学习器进行自适应加权,将它们组合成一个强学习器,以达到提高分类器精度的目的。AdaBoost算法在机器学习领域具有广泛的应用,尤其是在处理分类问题时表现出色。
2.1.2 AdaBoost的核心特点
AdaBoost算法的核心特点在于其自适应性和加权机制。首先,AdaBoost算法能够根据前一个弱学习器的分类结果自适应地调整样本权重,使得后续弱学习器能够更加注重那些被错误分类的样本。其次,AdaBoost算法为每个弱学习器分配一个权重,该权重反映了该弱学习器在最终分类器中的重要性。通过加权组合多个弱学习器的预测结果,AdaBoost算法能够显著提高分类器的性能。
2.2 AdaBoost算法流程
2.2.1 初始化样本权重
在AdaBoost算法的开始阶段,需要为所有样本分配一个相同的初始权重。通常,这个初始权重被设置为1/N,其中N是样本总数。
2.2.2 迭代训练基学习器
AdaBoost算法通过迭代训练多个基学习器(也称为弱学习器)来构建最终的强学习器。在每次迭代中,算法都会根据当前的样本权重训练一个基学习器,并使用该基学习器对训练集进行预测。
2.2.3 计算基学习器的权重
在得到基学习器的预测结果后,AdaBoost算法会计算该基学习器的误差率(即被错误分类的样本权重之和)。然后,根据误差率计算基学习器的权重。误差率越低的基学习器将获得更高的权重,反之则获得较低的权重。
2.2.4 更新样本权重
接下来,AdaBoost算法会根据基学习器的预测结果更新样本权重。具体来说,被正确分类的样本权重会降低,而被错误分类的样本权重会增加。这样,在后续迭代中,算法会更加注重那些被前一个基学习器错误分类的样本。
2.2.5 线性组合形成最终模型
经过T次迭代后,AdaBoost算法将得到T个基学习器及其对应的权重。最后,算法将这些基学习器进行加权组合,形成一个强学习器。在预测新样本时,该强学习器会输出所有基学习器的加权预测结果的平均值或加权投票结果。
2.3 AdaBoost的数学推导
假设一个二分类训练数据集 T = { ( x 1 , y 1 ) , . . . , ( x N , y N ) } , y i ∈ { − 1 , + 1 } T=\lbrace(x_1,y_1),...,(x_N,y_N)\rbrace,y_i \in \lbrace-1,+1\rbrace T={(x1,y1),...,(xN,yN)},yi∈{−1,+1}.
2.3.1 初始化权重分布
在AdaBoost算法中,初始状态下,我们假设训练数据集上的权值分布是均匀的,这意味着每个训练样本在第一个基分类器的学习过程中都具有相同的重要性。具体来说,我们用 D 1 D_1 D1来表示第一轮学习的数据权值分布,
D 1 = ( w 11 , . . . , w 1 i , . . . , w 1 N ) D_1 = (w_{11}, ..., w_{1i}, ..., w_{1N}) D1=(w11,...,w1i,...,w1N)
其中 w 1 i w_{1i} w1i代表第 i i i个训练样本在第一轮学习中的权重,并且初始时所有样本的权重都是相等的,即 w 1 i = 1 N w_{1i} = \frac{1}{N} w1i=N1,这里 N N N是训练样本的总数。
2.3.2 对 m = 1 , 2 , . . . , M m = 1 , 2 , . . . , M m=1,2,...,M,进行以下步骤
a)、学习得到基本分类器 G m ( x ) G_m(x) Gm(x)
使用具有权重分布 D m D_m Dm的训练数据集进行学习,得到基本分类器 G m ( x ) G_m(x) Gm(x), G m ( x ) G_m(x) Gm(x)可以根据输入给出+1或者-1的输出;
b)、计算 G m ( x ) G_m(x) Gm(x)的分类误差率 e m e_m em
e m = ∑ i = 1 N P ( G m ( x i ) ≠ y i ) = ∑ i = 1 N e m i I ( G m ( x i ) ≠ y i ) e_m = \sum_{i=1}^NP(G_m(x_i) \neq y_i) = \sum_{i=1}^Ne_{mi}I(G_m(x_i) \neq y_i) em=i=1∑NP(Gm(xi)=yi)=i=1∑NemiI(Gm(xi)=yi)
其中, I I I 是指示函数,当后面括号里的式子成立就取1,不成立就取0。所以 e m e_m em 就是把所有分类错误的样本权重加起来,如果初始权重相等,那么5个样本分错2个,错误率就是0.4,如果权重是[0.5,0.1,0.1,0.1,0.1,0.1],而权重为0.5的样本分错了,最后错误率就是0.5。因此这个设计使得,将权重高的样本分类正确能显著降低分类误差率。
c)计算 G m ( x ) G_m(x) Gm(x)的系数 α m \alpha_m αm
α m = 1 2 l o g ( 1 − e m e m ) \alpha_m = \frac{1}{2} log(\frac{1-e_m}{e_m}) αm=21log(em1−em)
其中 α m \alpha_m αm相当于基本分类器的权重,前面说误差率低的分类器要有较大的权重,我们这里先介绍 α m \alpha_m αm的这种形式能够实现我们的需求,后面会进一步介绍这是有严格的推导的,它为什么刚刚好就是这种形式。
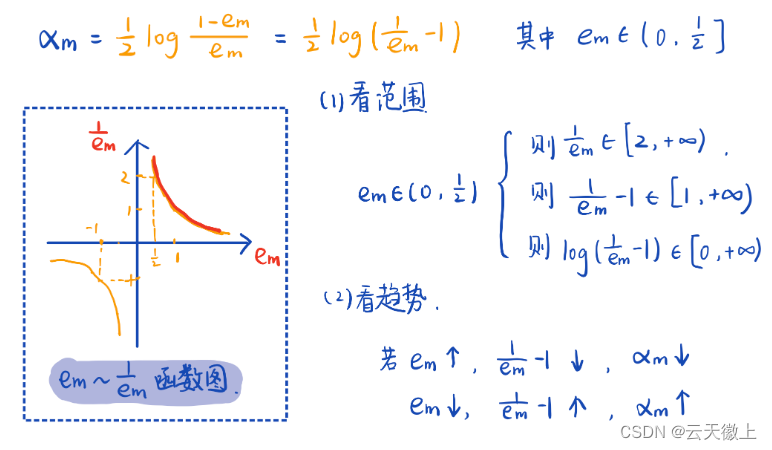
从上图不难看出, α m \alpha_m αm取值在0到正无穷,且 e m e_m em大的 α m \alpha_m αm小, e m e_m em小的 α m \alpha_m αm大,是符合我们的逻辑的。这里解释一下分类误差率 e m e_m em为什么小于等于1/2. 因为对于二分类问题,错误率超过0.5的话,只要进行简单的完全反转就可以使其降到0.5以下。举例来说,若 分类结果为 [1,1,1,-1] 错误率0.75,那么只要改成 [-1,-1,-1,1] 错误率就只有0.25了。(另一种想法是随机分类的错误率是0.5,弱学习器虽然弱,正确率也是要略高于随机分类的。
d)更新训练数据集权值分布
D m + 1 = ( w m + 1 , 1 , . . . , w w + 1 , i , . . . , w m + 1 , N ) D_{m+1} = (w_{m+1,1},...,w_{w+1,i},...,w_{m+1,N}) Dm+1=(wm+1,1,...,ww+1,i,...,wm+1,N)
w m + 1 , i = w w i Z m e x p ( − α m y i G m ( x i ) ) w_{m+1,i} = \frac{w_{wi}}{Z_m}exp(-\alpha_m y_i G_m(x_i)) wm+1,i=Zmwwiexp(−αmyiGm(xi))
Z m = ∑ i = 1 N e x p ( − α m y i G m ( x i ) ) Z_m = \sum_{i=1}^{N}exp(-\alpha_m y_i G_m(x_i)) Zm=i=1∑Nexp(−αmyiGm(xi))
这里的公式看起来很复杂,其实思想是很简单的,我们一步步看。首先, Z m Z_m Zm是规范化因子,它将 w m + 1 , i w_{m+1,i} wm+1,i映射到0~1的范围内,使之成为一个概率分布。 Z m Z_m Zm的值其实就是将所有的 w m + 1 , i w_{m+1,i} wm+1,i进行求和。
然后再看 w m + 1 , i w_{m+1,i} wm+1,i,我们就可以先忽略掉 Z m Z_m Zm 去理解。如果分类器 G m ( x ) G_m(x) Gm(x)将一个样本分类正确,说明要么真实值 y i y_i yi为1 预测结果 G m ( x i ) G_m(x_i) Gm(xi)也为1,要么真实为-1 预测也为-1,它们总是同号的,此时 y i G m ( x i ) = 1 y_iG_m(x_i)=1 yiGm(xi)=1,如果分类错误则 y i G m ( x i ) = − 1 y_iG_m(x_i)=-1 yiGm(xi)=−1.所以可以将原来的式子写成 (先忽略 Z m Z_m Zm) :
w m + 1 , i = { w m i e − α m , G m ( x i ) = y i w m i e α m , G m ( x i ) ≠ y i w_{m+1,i} = \left\{ \begin{array}{c} w_{mi}e^{-\alpha_m} , G_m(x_i)=y_i\\ w_{mi}e^{\alpha_m} , G_m(x_i) \neq y_i \end{array} \right. wm+1,i={wmie−αm,Gm(xi)=yiwmieαm,Gm(xi)=yi
可以看出,当分类正确,会在原来的权重基础上乘上 − α m -\alpha_m −αm, − α m -\alpha_m −αm是小于0的,于是权重被进一步缩小,而错分样本的权重会放大,且被放大了 e 2 α m = 1 − e m e m e^{2\alpha_m}=\dfrac{1-e_m}{e_m} e2αm=em1−em 倍。
2.3.3 得到最终的分类器 G ( x ) G(x) G(x)
f ( x ) = ∑ m = 1 M α m G m ( x ) f(x) = \sum_{m=1}^{M}\alpha_mG_m(x) f(x)=m=1∑MαmGm(x)
G ( x ) = s i g n ( f ( x ) ) = s i g n ( ∑ m = 1 M α m G m ( x ) ) G(x)=sign(f(x))=sign(\sum_{m=1}^{M}\alpha_mG_m(x)) G(x)=sign(f(x))=sign(m=1∑MαmGm(x))
其中, s i g n sign sign是符号函数,若括号内取值小于0则输出-1,大于0则输出1。对 M M M个基本分类器进行加权表决,系数 α m \alpha_m αm表示了分类器的重要性,最终输出值的符号表示类别,绝对值代表了确信度。
算法描述到这里就结束了,总结一下就是:首先初始化权值分布,然后进入迭代,在每一轮中,依次计算分类器 G m ( x ) G_m(x) Gm(x),分类错误率 e m e_m em,系数 α m \alpha_m αm,并改变得到下一轮的权值分布 D m + 1 D_{m+1} Dm+1,当满足迭代停止条件则退出,对得到的若干基分类器进行加权求和,得到最终的分类器 G ( x ) G(x) G(x)。
2.4 AdaBoost算法的优点与不足
2.4.1 AdaBoost算法的优势
AdaBoost算法具有显著的优势。首先,它通过自适应加权机制提高了分类器的性能,使得最终得到的强学习器具有更高的分类精度和鲁棒性。其次,AdaBoost算法对噪声数据和异常值具有一定的容忍度,能够在一定程度上减轻它们对模型性能的影响。此外,AdaBoost算法还具有较强的可解释性,因为每个基学习器(如决策树桩)本身都具有一定的解释性。
2.4.2 AdaBoost算法的局限性
AdaBoost算法也存在一些局限性。首先,它对弱学习器的选择有一定的要求,需要确保弱学习器的性能不能太差。如果弱学习器的性能太差,那么即使通过加权组合也无法得到性能良好的
三、AdaBoost应用
3.1 AdaBoost在分类问题中的应用
AdaBoost作为一种有效的集成学习方法,在分类问题中发挥着重要作用。下面我们将探讨AdaBoost在分类问题中的几个典型应用。
3.1.1 AdaBoost与决策树桩的结合
AdaBoost算法通常与简单的基学习器(如决策树桩)结合使用,以形成强大的分类器。决策树桩是一种仅包含一个决策节点的决策树,也被称为单层决策树。由于决策树桩的复杂性较低,因此它们作为弱学习器在AdaBoost中表现良好。通过AdaBoost的迭代训练和加权机制,这些简单的决策树桩可以被组合成一个性能强大的分类器。
3.1.2 AdaBoost在文本分类中的应用案例
在文本分类领域,AdaBoost算法被广泛用于处理各种文本数据。例如,在垃圾邮件过滤中,AdaBoost可以帮助我们区分正常邮件和垃圾邮件。通过将邮件文本转换为特征向量,并使用AdaBoost算法进行训练,我们可以得到一个能够准确识别垃圾邮件的分类器。此外,AdaBoost还可以用于情感分析、新闻分类等文本分类任务。
3.1.3 AdaBoost在图像识别中的应用案例
在图像识别领域,AdaBoost算法同样具有广泛的应用。例如,在人脸识别中,AdaBoost算法可以帮助我们识别出图像中的人脸区域。通过提取图像的Haar特征或LBP特征等,并使用AdaBoost算法进行训练,我们可以得到一个能够准确检测人脸的分类器。此外,AdaBoost还可以用于图像分割、目标检测等图像识别任务。
3.2 AdaBoost处理不平衡数据集的策略
在实际应用中,我们经常遇到不平衡数据集的问题,即某一类别的样本数量远多于其他类别。这种情况下,传统的分类算法往往会偏向于数量较多的类别,导致对数量较少的类别的识别性能较差。AdaBoost算法在处理不平衡数据集时具有一定的优势。
-3.2.1 不平衡数据集的问题
不平衡数据集是指数据集中各类别样本数量差异较大的情况。这种不平衡性会导致分类器在训练过程中过于关注数量较多的类别,而忽视数量较少的类别。因此,在测试阶段,分类器对于数量较少的类别的识别性能往往较差。
3.2.2 AdaBoost在不平衡数据集上的表现
AdaBoost算法在处理不平衡数据集时表现出较好的性能。由于AdaBoost算法在迭代过程中会根据基学习器的预测结果调整样本权重,使得后续基学习器更加注重被前一个基学习器错误分类的样本。这种机制有助于平衡不同类别之间的权重,使得分类器对于数量较少的类别也具有较好的识别性能。
3.2.3 AdaBoost与其他不平衡数据集处理方法的比较
与其他处理不平衡数据集的方法相比,AdaBoost算法具有以下优势:
无需对原始数据集进行复杂的预处理操作,如过采样、欠采样或重采样等。
能够自适应地调整不同类别之间的权重,使得分类器对于数量较少的类别也具有较好的识别性能。
可以与各种基学习器结合使用,具有较强的灵活性和可扩展性。
3.3 AdaBoost的调参与优化
在AdaBoost算法中,参数的选择对模型的性能具有重要影响。通过调整这些参数,我们可以优化模型的性能,使其在训练集和测试集上都取得较好的效果。下面我们将详细探讨AdaBoost中的重要参数、参数调整对模型性能的影响以及AdaBoost的调参策略与优化方法。
3.3.1 AdaBoost中的重要参数
AdaBoost算法中有几个关键参数需要调整,包括:
1、n_estimators:弱学习器的数量。这个参数决定了AdaBoost算法中集成的弱学习器的数量。增加弱学习器的数量可以提高模型的性能,但也会增加计算成本。
2、learning_rate:学习率。这个参数控制每个弱学习器在最终模型中的权重。较小的学习率意味着每个弱学习器的权重会更小,模型的训练速度会变慢,但可能会得到更好的性能。
3、base_estimator:基学习器。AdaBoost算法允许使用任何分类器作为基学习器,如决策树桩、支持向量机等。选择合适的基学习器对AdaBoost的性能至关重要。
3.3.2 参数调整对模型性能的影响
1、n_estimators:增加n_estimators的值可以提高模型的性能,因为更多的弱学习器可以捕获更多的数据特征。然而,当n_estimators过大时,计算成本会显著增加,并且可能导致过拟合。因此,需要找到一个合适的平衡点。
2、learning_rate:learning_rate的值决定了每个弱学习器在最终模型中的权重。较小的learning_rate会使模型更加关注误分类的样本,从而提高模型的泛化能力。然而,过小的learning_rate会导致模型训练速度变慢,并且可能需要更多的弱学习器才能达到较好的性能。
3、base_estimator:选择合适的基学习器对AdaBoost的性能至关重要。不同的基学习器具有不同的特点,适用于不同的数据集和任务。因此,需要根据具体的应用场景和数据集来选择最合适的基学习器。
3.3.3 AdaBoost的调参策略与优化方法
在调整AdaBoost的参数时,可以采用以下策略和优化方法:
1、网格搜索(Grid Search):通过穷举所有可能的参数组合来找到最优参数。可以设定一个参数网格,并使用交叉验证来评估每种参数组合的性能。这种方法虽然计算成本较高,但可以找到全局最优解。
2、随机搜索(Random Search):在参数空间中随机采样一定数量的参数组合,并评估它们的性能。这种方法在参数空间很大或者不是所有参数都对模型性能有显著影响时非常有用。
3、贝叶斯优化(Bayesian Optimization):基于贝叶斯定理的参数优化方法,通过构建目标函数的后验分布来找到使目标函数最大化的参数。这种方法可以更有效地在参数空间中搜索最优解。
4、交叉验证(Cross-Validation):使用交叉验证来评估模型的性能,从而确定合适的参数组合。交叉验证通过将数据集划分为训练集和验证集来评估模型在未见过的数据上的性能。
在调参过程中,还需要注意以下几点:
避免过度调参:过度调参可能导致模型过拟合或欠拟合。因此,在调参时需要保持谨慎,并避免对模型进行过多的调整。
验证集的使用:在调参过程中,需要使用验证集来评估模型的性能。验证集应该与训练集和测试集保持独立,以确保评估结果的准确性。
模型的复杂度与性能之间的平衡:在调整参数时,需要平衡模型的复杂度和性能之间的关系。过于复杂的模型可能会导致过拟合,而过于简单的模型则可能无法充分捕获数据的特征。因此,需要找到一个合适的平衡点来优化模型的性能。
四、基于AdaBoost的案列实现
我们将使用AdaBoost算法来解决一个分类问题。假设我们有一个手写数字识别的数据集(如MNIST数据集),我们将使用AdaBoost算法结合决策树桩作为基学习器来进行分类。
4.1 数据准备
由于MNIST数据集较大,为了简化演示,我们将使用其子集或类似的简单数据集。但在这里,我们将以MNIST数据集为例进行说明。
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
import numpy as np# 加载数据集(这里使用MNIST的子集作为示例)
mnist = fetch_openml('mnist_784', version=1, return_X_y=True)
X, y = mnist# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 初始化基学习器
base_estimator = DecisionTreeClassifier(max_depth=1, random_state=42)# 初始化AdaBoost分类器
ada_clf = AdaBoostClassifier(base_estimator=base_estimator, n_estimators=50, learning_rate=1.0, random_state=42)
4.2 交叉验证
我们将使用交叉验证来评估AdaBoost模型的性能。
# 交叉验证
scores = cross_val_score(ada_clf, X_train, y_train, cv=5)
print("Cross-validation scores:", scores)
print("Average cross-validation score:", np.mean(scores))
模型交叉验证的结果如下:

4.3 模型训练与评估
在交叉验证后,我们将使用整个训练集来训练AdaBoost模型,并在测试集上评估其性能。
# 训练模型
ada_clf.fit(X_train, y_train)# 预测测试集
y_pred = ada_clf.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy on test set:", accuracy)
模型的准确率如下:

- 结果可视化
为了更直观地展示模型的性能,我们可以绘制混淆矩阵或分类报告。
from sklearn.metrics import confusion_matrix, classification_report # 预测测试集
y_pred = ada_clf.predict(X_test) # 混淆矩阵
cm = confusion_matrix(y_test, y_pred) # 可视化混淆矩阵(例如,使用seaborn)
import seaborn as sns
import matplotlib.pyplot as plt plt.figure(figsize=(10, 7))
sns.heatmap(cm, annot=True, fmt="d", cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('Truth')
plt.show() # 分类报告
print("\nClassification Report:")
print(classification_report(y_test, y_pred))
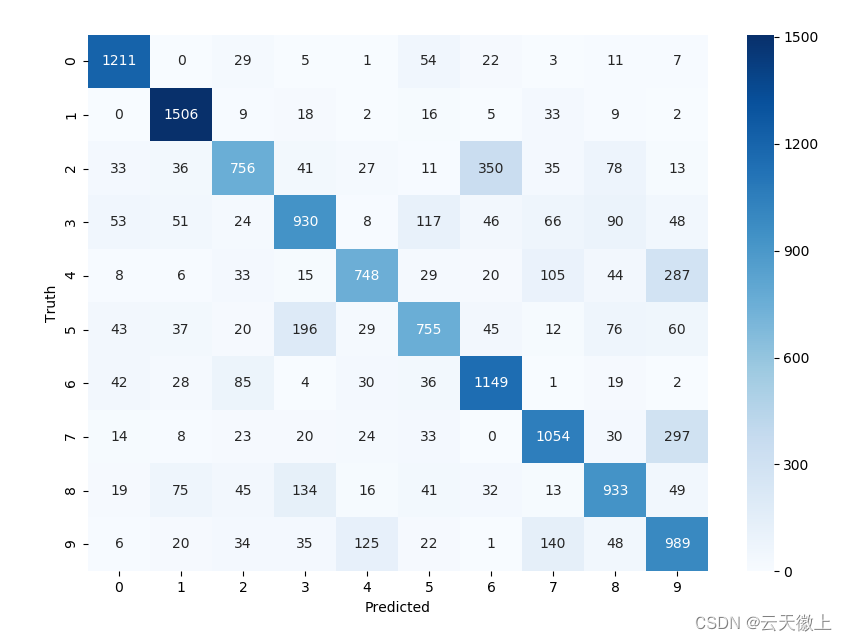
模型评估的混淆矩阵如下:
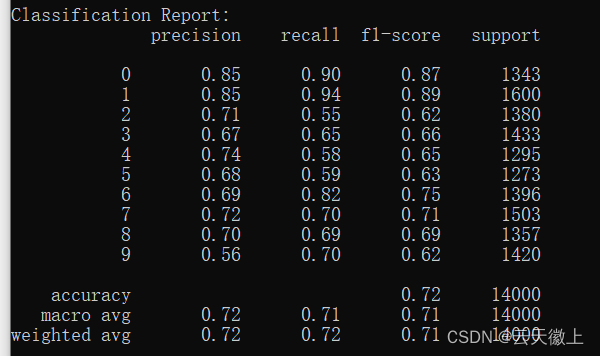
模型的分类报告如下:
五、AdaBoost的适用场景
5.1 AdaBoost的最佳应用场景
- AdaBoost在处理不平衡数据集时表现优异,因为它能够自适应地调整样本权重,从而更多地关注被错误分类的样本。
- 当基学习器的性能相对较弱时,AdaBoost能够通过集成多个基学习器来提升整体性能。
- AdaBoost对于噪声和异常值具有较好的鲁棒性。
5.2 AdaBoost在哪些情况下可能不适用
- 当数据集过大时,AdaBoost可能需要更多的计算资源,因为每个弱学习器都需要在加权后的数据集上进行训练。
- 如果基学习器对数据集已经表现出很好的性能,那么集成多个这样的基学习器可能不会产生太大的提升。
六、AdaBoost的未来发展趋势
-
AdaBoost算法在机器学习领域的发展趋势
- 随着大数据和云计算技术的发展,AdaBoost在处理大规模数据集方面的能力将得到进一步提升。
- AdaBoost与其他机器学习算法的结合将产生更多新的变种和应用场景。
-
AdaBoost与其他新技术(如深度学习)的结合潜力
- AdaBoost可以与深度学习模型结合,通过集成多个深度学习模型来提升整体性能。
- AdaBoost的样本权重调整机制可以应用于深度学习模型的训练中,以提高模型对噪声和异常值的鲁棒性。
七、总结与建议
7.1 AdaBoost算法的核心价值
- AdaBoost通过将多个弱学习器集成为一个强学习器,提高了模型的泛化能力和鲁棒性。
- AdaBoost的自适应样本权重调整机制使其在处理不平衡数据集和噪声数据方面表现出色。
7.2 使用AdaBoost算法的注意事项与建议
- 在选择基学习器时,应考虑其复杂度和性能,避免选择过于复杂或过于简单的基学习器。
- 调整AdaBoost的参数(如弱学习器数量、学习率等)时,应使用交叉验证等方法来评估模型的性能。
- 注意AdaBoost在处理大规模数据集时的计算成本问题,并根据实际情况选择合适的优化方法。
7.3 对AdaBoost算法学习和研究的建议
- 深入了解AdaBoost的原理和变种算法,掌握其优缺点和适用场景。
- 探索AdaBoost与其他机器学习算法的结合方式,以拓展其应用领域和提升性能。
- 关注AdaBoost在大数据和云计算环境下的应用和发展趋势,以及与其他新技术的结合潜力。
参考:
https://blog.csdn.net/codelady_g/article/details/122571189
相关文章:
【机器学习】集成方法---Boosting之AdaBoost
一、Boosting的介绍 1.1 集成学习的概念 1.1.1集成学习的定义 集成学习是一种通过组合多个学习器来完成学习任务的机器学习方法。它通过将多个单一模型(也称为“基学习器”或“弱学习器”)的输出结果进行集成,以获得比单一模型更好的泛化性…...

AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
系列篇章💥 AI大模型探索之路-训练篇1:大语言模型微调基础认知 AI大模型探索之路-训练篇2:大语言模型预训练基础认知 AI大模型探索之路-训练篇3:大语言模型全景解读 AI大模型探索之路-训练篇4:大语言模型训练数据集概…...

鸿蒙内核源码分析(工作模式篇) | CPU的七种工作模式
本篇说清楚CPU的工作模式 工作模式(Working mode) 也叫操作模式(Operating mode)又叫处理器模式(Processor mode),是 CPU 运行的重要参数,决定着处理器的工作方式,比如如何裁决特权级别和报告异…...

5月6(信息差)
🌍一次预测多个token,Meta新模型推理加速3倍,编程任务提高17% https://hub.baai.ac.cn/view/36857 🎄 LeetCode 周赛超越 80% 人类选手,推理性能超 Llama3-70B。 ✨ 我国量子计算机实现“四算合一” 实现通算、…...

Qt在任务栏图标和系统托盘图标上显示红点
在任务栏图标上显示红点 关键类:QWinTaskbarButton #include <QWinTaskbarButton>QPointer<QWinTaskbarButton> taskbarBtn nullptr; if (!taskbarBtn) {taskbarBtn new QWinTaskbarButton(window);taskbarBtn->setWindow(window->windowHand…...
springboot拦载器
1、拦载器 package com.Interceptor;import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import org.springframework.web.servlet.HandlerInterceptor; import org.springframework.web.servlet.ModelAndView;import javax.security.auth.login.Log…...

知道创宇安全服务实习
自我介绍攻防演练讲一下,我讲到了内网利用,用到了frp/nps这种nps直接扫不会有被发现吗?cs搭建在vps,有做什么隐藏吗,(端口或者cdn之类的)域前置了解吗cs上传的木马免杀了吗问了linux怎么查看进程…...

SGP.22-V.3.1-安全1
有任何关于GSMA\IOT\eSIM\RSP\业务应用场景相关的问题,欢迎W: xiangcunge59 一起讨论, 共同进步 (加的时候请注明: 来自CSDN-iot). 2.6.4.4 Command TLV MACing and Encryption 在提供的文件 "RSP Technical Specification Version 3.1 Final" 中&a…...
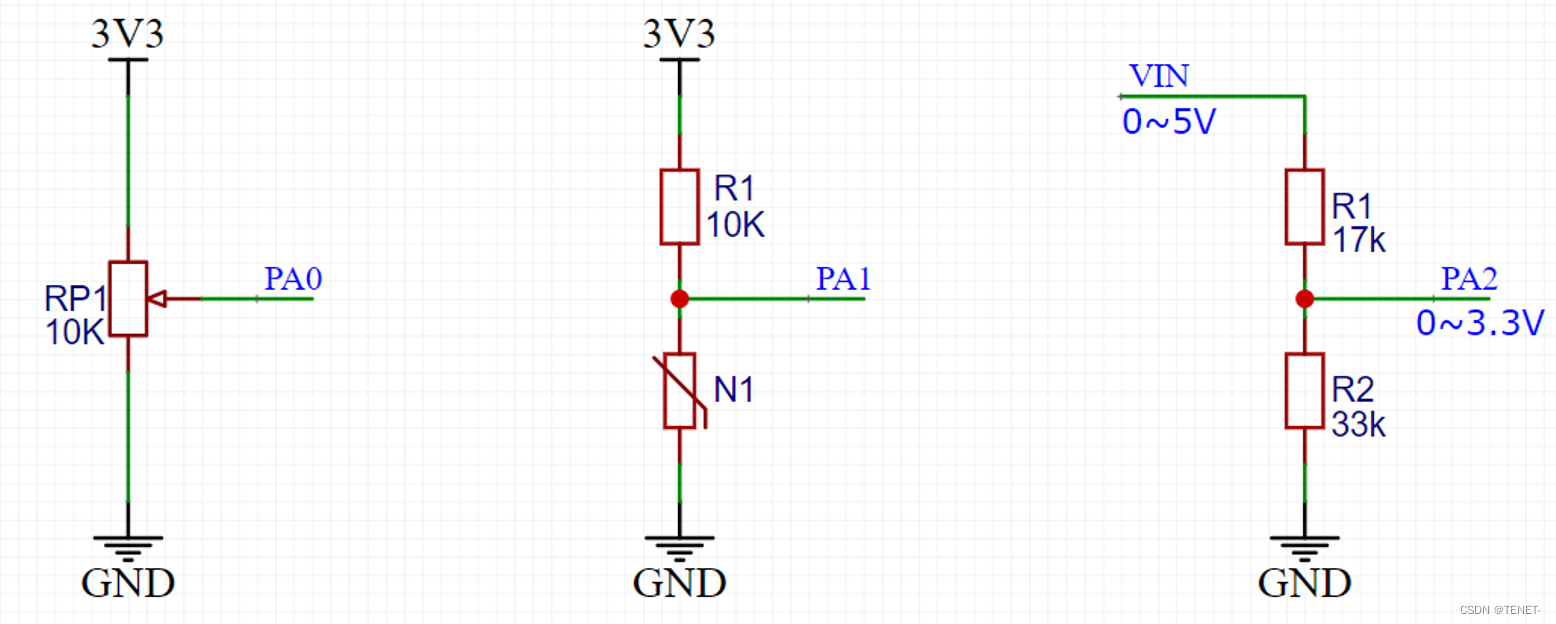
STM32单片机ADC功能详解
文章目录 1. ADC概述 2. ADC结构图 3. 引脚定义 4. 转换模式 5. 数据对齐 6. 转换时间 7. 硬件电路 8. STM32使用ADC单/多通道检测数据 1. ADC概述 功能:ADC是一个将模拟信号(如电压)转换为数字信号的设备。在微控制器中,…...

47.Redis学习笔记
小林coding -> 图解redis的学习笔记 文章目录 Rediswindwos安装docker安装redis启动redis使用RDM访问虚拟机中的redispython连接redis缓存穿透、击穿、雪崩基本数据类型高级数据类型高并发指标布隆过滤器分布式锁Redis 的有序集合底层为什么要用跳表,而不用平衡…...

数控六面钻适用场景-不止家具制造
在快节奏的现代生活中,家具作为我们生活的重要组成部分,其美观度和实用性日益受到人们的关注。而在这背后,一个不可或缺的“工匠”正默默地发挥着它的作用——那就是数控六面钻。 数控六面钻,顾名思义,是一种高度自动…...

【力扣】86. 分隔链表
86. 分隔链表 题目描述 给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。 你应当 保留 两个分区中每个节点的初始相对位置。 示例 1: 输入:head […...

海云安受邀参加诸子云 4.27南京「金融互联网」私董会
4月27日,“安在新媒体网安用户行业活动”第四期私董会在南京顺利举办。活动以“金融&互联网”为主题,邀请十余位业内资深的甲方用户以及典型厂商代表。摒弃传统的议题分享,采取“随时问答,自由讨论”的形式,提问题…...

docker操作使用注意事项
文章目录 一、运行docker二、拉取的镜像存放位置1、查询所有拉取的镜像2、查询所有安装的镜像3、查询docker应用的所有信息 一、运行docker 该命令执行后是在窗口下运行的,关闭或退出后docker应用会停止运行 -p:设置绑定端口映射,10022对应…...

Leetcode—163. 缺失的区间【简单】Plus
2024每日刷题(126) Leetcode—163. 缺失的区间 实现代码 class Solution { public:vector<vector<int>> findMissingRanges(vector<int>& nums, int lower, int upper) {int n nums.size();vector<vector<int>> an…...
Ansible自动化运维工具 - playbook 剧本编写
一. inventory 主机清单 Inventory 支持对主机进行分组,每个组内可以定义多个主机,每个主机都可以定义在任何一个或多个主机组内。 1.1 inventory 中的变量含义 Inventory 变量名 含义ansible_hostansible连接节点时的IP地址ansible_port连接对方…...
Web前端一套全部清晰 ⑥ day4 CSS.2 复合选择器、CSS特性、背景属性、标签的显示模式
别人的议论,那是别人的,你的人生,才是你的 —— 24.5.7 一、复合选择器 定义:由两个或多个基础选择器,通过不同的方式组合而成 作用:更准确、更高效的选择目标元素(标签) 1.后代选择…...
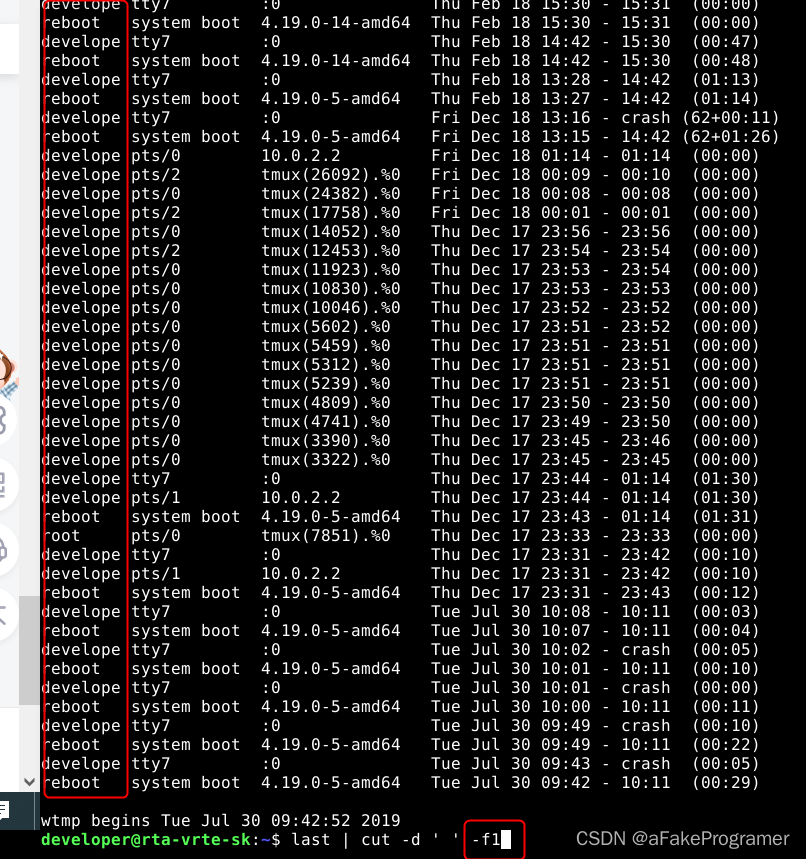
Linux 认识与学习Bash——3
在Linux bash中,数据流重定向是指将命令的输出从默认的标准输出(通常是终端)重定向到其他位置,如文件或另一个命令的输入。这是通过使用特定的符号来实现的。例如,>用于将输出重定向到文件,而<用于将…...

匠心精神与创新力量:构筑网络安全的新防线
一、匠心精神在网络安全中的重要性 匠心精神代表着对工作的专注和对质量的极致追求。在网络安全领域,这意味着对每一个安全漏洞的深入挖掘,对每一项安全技术的精心打磨。亿林网络李璐昆的提名,正是对其在网络安全领域匠心精神的认可。 二、…...

接口信息解析
目录 一、通讯流程 二、如何获取接口信息--抓包 1、抓包步骤: 2、抓包工具 接口文档:又称为API文档,是由后端开发编写,用来描述接口信息的文档 一、通讯流程 功能(比如:登录)请求(请求路径、请求方式、…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...