2023黑马头条.微服务项目.跟学笔记(五)
2023黑马头条.微服务项目.跟学笔记 五
-
- 延迟任务精准发布文章
-
- 1.文章定时发布
- 2.延迟任务概述
-
- 2.1 什么是延迟任务
- 2.2 技术对比
-
- 2.2.1 DelayQueue
- 2.2.2 RabbitMQ实现延迟任务
- 2.2.3 redis实现
- 3.redis实现延迟任务
- 4.延迟任务服务实现
-
- 4.1 搭建heima-leadnews-schedule模块
- 4.2 数据库准备
-
- 4.2.1 数据库准备-数据库自身解决并发两种策略
- 4.2.2 数据库准备-mybatis-plus集成乐观锁的使用
- 4.3 安装redis
- 4.4 项目集成redis
- 4.5 添加任务
- 4.6 取消任务
- 4.7 消费任务
- 4.8 未来数据定时刷新
-
- 4.8.1 redis key值匹配
- 4.8.2 redis管道
- 4.8.3 未来数据定时刷新-功能完成
- 4.9 分布式锁解决集群下的方法抢占执行
-
- 4.9.1 问题描述
- 4.9.2 分布式锁
- 4.9.3 redis分布式锁
- 4.9.4 在工具类CacheService中添加方法
- 4.10 数据库同步到redis
- 5.延迟队列解决精准时间发布文章
-
-
- 5.1 延迟队列服务提供对外接口
- 5.2 发布文章集成添加延迟队列接口
- 5.3 消费任务进行审核文章
-
延迟任务精准发布文章
1.文章定时发布

2.延迟任务概述
2.1 什么是延迟任务
- 定时任务:有固定周期的,有明确的触发时间。
- 延迟队列:没有固定的开始时间,它常常是由一个事件触发的,而在这个事件触发之后的一段时间内触发另一个事件,任务可以立即执行,也可以延迟。

应用场景:
场景一:订单下单之后30分钟后,如果用户没有付钱,则系统自动取消订单;如果期间下单成功,任务取消。

场景二:接口对接出现网络问题,1分钟后重试,如果失败,2分钟重试,直到出现阈值终止。
文章定时任务
2.2 技术对比
2.2.1 DelayQueue
JDK自带DelayQueue 是一个支持延时获取元素的阻塞队列, 内部采用优先队列 PriorityQueue 存储元素,同时元素必须实现 Delayed 接口;在创建元素时可以指定多久才可以从队列中获取当前元素,只有在延迟期满时才能从队列中提取元素

DelayQueue属于排序队列,它的特殊之处在于队列的元素必须实现Delayed接口,该接口需要实现compareTo和getDelay方法
getDelay方法:获取元素在队列中的剩余时间,只有当剩余时间为0时元素才可以出队列。
compareTo方法:用于排序,确定元素出队列的顺序。
实现:
1:在测试包jdk下创建延迟任务元素对象DelayedTask,实现compareTo和getDelay方法,
2:在main方法中创建DelayQueue并向延迟队列中添加三个延迟任务,
3:循环的从延迟队列中拉取任务
public class DelayedTask implements Delayed{// 任务的执行时间private int executeTime = 0;public DelayedTask(int delay){Calendar calendar = Calendar.getInstance();calendar.add(Calendar.SECOND,delay);this.executeTime = (int)(calendar.getTimeInMillis() /1000 );}/*** 元素在队列中的剩余时间* @param unit* @return*/@Overridepublic long getDelay(TimeUnit unit) {Calendar calendar = Calendar.getInstance();return executeTime - (calendar.getTimeInMillis()/1000);}/*** 元素排序* @param o* @return*/@Overridepublic int compareTo(Delayed o) {long val = this.getDelay(TimeUnit.NANOSECONDS) - o.getDelay(TimeUnit.NANOSECONDS);return val == 0 ? 0 : ( val < 0 ? -1: 1 );}public static void main(String[] args) {DelayQueue<DelayedTask> queue = new DelayQueue<DelayedTask>();queue.add(new DelayedTask(5));queue.add(new DelayedTask(10));queue.add(new DelayedTask(15));System.out.println(System.currentTimeMillis()/1000+" start consume ");while(queue.size() != 0){DelayedTask delayedTask = queue.poll();if(delayedTask !=null ){System.out.println(System.currentTimeMillis()/1000+" cosume task");}//每隔一秒消费一次try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}} }
}
DelayQueue实现完成之后思考一个问题:
使用线程池或者原生DelayQueue程序挂掉之后,任务都是放在内存,需要考虑未处理消息的丢失带来的影响,如何保证数据不丢失,需要持久化(磁盘)
2.2.2 RabbitMQ实现延迟任务
-
TTL:Time To Live (消息存活时间)
-
死信队列:Dead Letter Exchange(死信交换机),当消息成为Dead message后,可以重新发送另一个交换机(死信交换机)
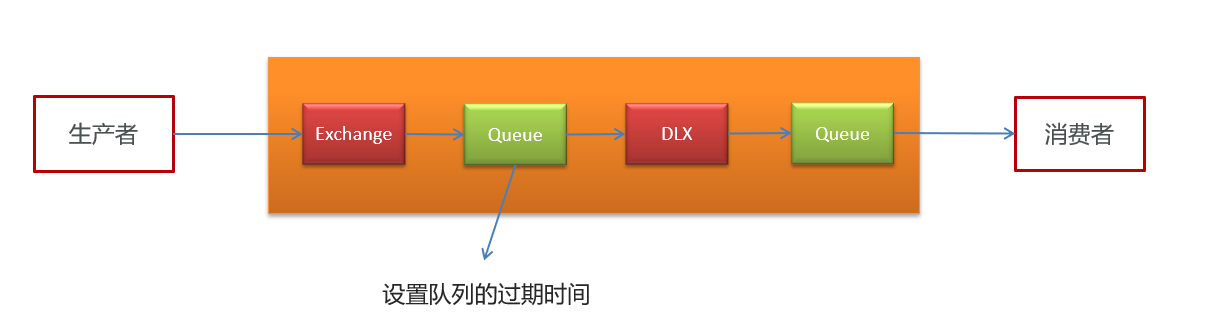
2.2.3 redis实现
zset数据类型的去重有序(分数排序)特点进行延迟。例如:时间戳作为score进行排序

例如:
生产者添加到4个任务到延迟队列中,时间亳秒值分别为97、98、 99、 100。 当前时间的亳秒值为90。
消费者端进行监听,如果当前时间的毫秒值匹配到了延迟队列中的秒值就立即消费。
总结:
3.redis实现延迟任务
实现思路
问题思路
1.为什么任务需要存储在数据库中?
延迟任务是一个通用的服务,任何需要延迟得任务都可以调用该服务,需要考虑数据持久化的问题,存储数据库中是一种数据安全的考虑。
2.为什么redis中使用两种数据类型,list和zset?
原因一: list存储立即执行的任务,zset存储未来的数据。
原因二:任务量过大以后,zset的性能会下降。
时间复杂渡:执行时间(次数)随着数据规模增长的变化趋势
- 操作redis中的list命令LPUSH: 时间复杂度: 0(1)
- 操作redis中的zset命令zadd: 时间复杂度: O(M*log(n))

3.在添加zset数据的时候,为什么需要预加载?
任务模块是一个通用的模块,项目中任何需要延迟队列的地方,都可以调用这个接口,要考虑到数据量的问题,如果数据量特别大,为了防止阻塞,只需要把未来几分钟要执行的数据存入缓存即可,是一种优化形式。
4.延迟任务服务实现
4.1 搭建heima-leadnews-schedule模块
leadnews-schedule是一个通用的服务,单独创建模块来管理任何类型的延迟任务
①:导入资料文件夹下的heima-leadnews-schedule模块到heima-leadnews-service下,如下图所示:
在pom.xml中添加子模块
<module>heima-leadnews-schedule</module>
- 1

②:添加bootstrap.yml
server:port: 51701
spring:application:name: leadnews-schedulecloud:nacos:discovery:server-addr: 192.168.200.130:8848config:server-addr: 192.168.200.130:8848file-extension: yml
③:在nacos中添加对应配置,并添加数据库及mybatis-plus的配置
spring:datasource:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/leadnews_schedule?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTCusername: rootpassword: root
# 设置Mapper接口所对应的XML文件位置,如果你在Mapper接口中有自定义方法,需要进行该配置
mybatis-plus:mapper-locations: classpath*:mapper/*.xml# 设置别名包扫描路径,通过该属性可以给包中的类注册别名type-aliases-package: com.heima.model.schedule.pojos
4.2 数据库准备
导入资料中leadnews_schedule数据库
taskinfo 任务表
注意事项
MySQL中,BLOB是一个二 进制大型对象,是一个可以存储大量数据的容器。
LongBlob 最大存储4G
实体类
package com.heima.model.schedule.pojos;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;import java.io.Serializable;
import java.util.Date;/*** <p>* * </p>** @author itheima*/
@Data
@TableName("taskinfo")
public class Taskinfo implements Serializable {private static final long serialVersionUID = 1L;/*** 任务id*/@TableId(type = IdType.ID_WORKER)private Long taskId;/*** 执行时间*/@TableField("execute_time")private Date executeTime;/*** 参数*/@TableField("parameters")private byte[] parameters;/*** 优先级*/@TableField("priority")private Integer priority;/*** 任务类型*/@TableField("task_type")private Integer taskType;}
taskinfo_logs 任务日志表
实体类
package com.heima.model.schedule.pojos;import com.baomidou.mybatisplus.annotation.*;
import lombok.Data;import java.io.Serializable;
import java.util.Date;/*** <p>* * </p>** @author itheima*/
@Data
@TableName("taskinfo_logs")
public class TaskinfoLogs implements Serializable {private static final long serialVersionUID = 1L;/*** 任务id*/@TableId(type = IdType.ID_WORKER)private Long taskId;/*** 执行时间*/@TableField("execute_time")private Date executeTime;/*** 参数*/@TableField("parameters")private byte[] parameters;/*** 优先级*/@TableField("priority")private Integer priority;/*** 任务类型*/@TableField("task_type")private Integer taskType;/*** 版本号,用乐观锁*/@Versionprivate Integer version;/*** 状态 0=int 1=EXECUTED 2=CANCELLED*/@TableField("status")private Integer status;}
4.2.1 数据库准备-数据库自身解决并发两种策略

4.2.2 数据库准备-mybatis-plus集成乐观锁的使用

乐观锁支持:
/*** mybatis-plus乐观锁支持* @return*/
@Bean
public MybatisPlusInterceptor optimisticLockerInterceptor(){MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());return interceptor;
}
4.3 安装redis
①拉取镜像
docker pull redis
- 1
② 创建容器
docker run -d --name redis --restart=always -p 6379:6379 redis --requirepass "leadnews"
- 1
③链接测试
打开资料中的Redis Desktop Manager,输入host、port、password链接测试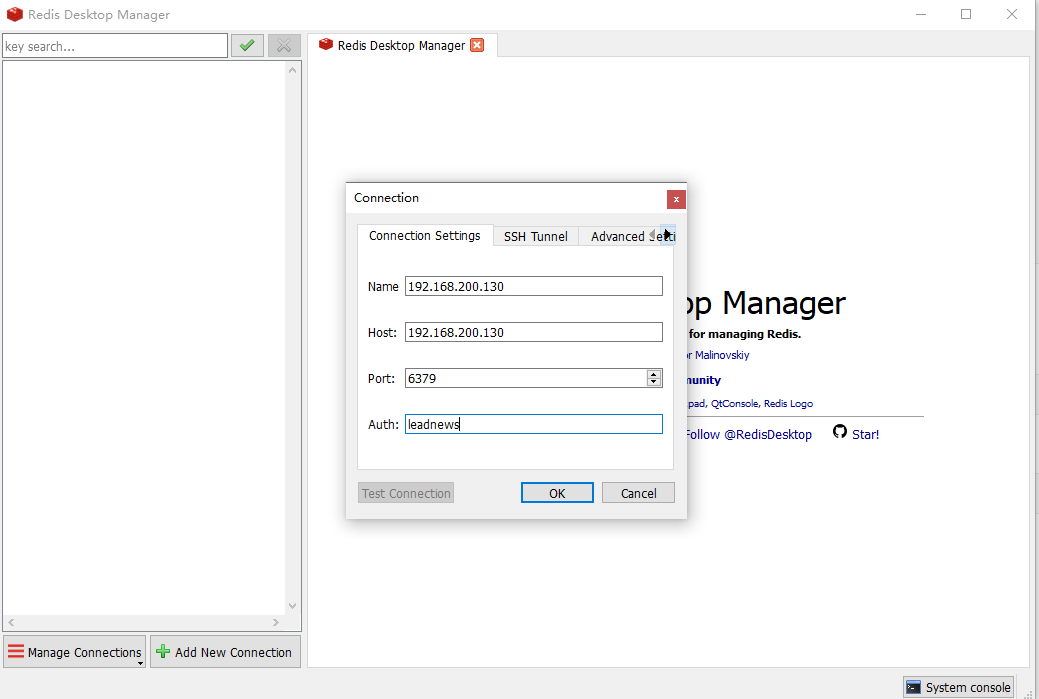
能链接成功,即可
4.4 项目集成redis
① 在heima-leadnews-common项目导入redis相关依赖,已经完成
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- redis依赖commons-pool 这个依赖一定要添加 -->
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId>
</dependency>
② 在heima-leadnews-schedule中集成redis,添加以下nacos配置,链接上redis
spring:redis:host: 192.168.200.130password: leadnewsport: 6379
③ 拷贝资料文件夹下的类:CacheService到heima-leadnews-common模块下,并添加自动配置
com.heima.common.redis.CacheService
- 1
④:测试
package com.heima.schedule.test;import com.heima.common.redis.CacheService;
import com.heima.schedule.ScheduleApplication;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import java.util.Set;@SpringBootTest(classes = ScheduleApplication.class)
@RunWith(SpringRunner.class)
public class RedisTest {@Autowiredprivate CacheService cacheService;@Testpublic void testList(){//在list的左边添加元素
// cacheService.lLeftPush("list_001","hello,redis");//在list的右边获取元素,并删除String list_001 = cacheService.lRightPop("list_001");System.out.println(list_001);}@Testpublic void testZset(){//添加数据到zset中 分值/*cacheService.zAdd("zset_key_001","hello zset 001",1000);cacheService.zAdd("zset_key_001","hello zset 002",8888);cacheService.zAdd("zset_key_001","hello zset 003",7777);cacheService.zAdd("zset_key_001","hello zset 004",999999);*///按照分值获取数据Set<String> zset_key_001 = cacheService.zRangeByScore("zset_key_001", 0, 8888);System.out.println(zset_key_001);}
}
我们先测试一下list的存取情况:
我们打印到后台看下
rpop之后,数据就没了
再测试一下zset,存取成功
查询一下0~8888的数据
4.5 添加任务
①:拷贝mybatis-plus生成的文件,mapper
②:创建task类,用于接收添加任务的参数
package com.heima.model.schedule.dtos;import lombok.Data;import java.io.Serializable;@Data
public class Task implements Serializable {/*** 任务id*/private Long taskId;/*** 类型*/private Integer taskType;/*** 优先级*/private Integer priority;/*** 执行id*/private long executeTime;/*** task参数*/private byte[] parameters;}
![]()
③:创建TaskService
package com.heima.schedule.service;import com.heima.model.schedule.dtos.Task;/*** 对外访问接口*/
public interface TaskService {/*** 添加任务* @param task 任务对象* @return 任务id*/public long addTask(Task task) ;}
![]()
实现:
package com.heima.schedule.service.impl;import com.alibaba.fastjson.JSON;
import com.heima.common.constants.ScheduleConstants;
import com.heima.common.redis.CacheService;
import com.heima.model.schedule.dtos.Task;
import com.heima.model.schedule.pojos.Taskinfo;
import com.heima.model.schedule.pojos.TaskinfoLogs;
import com.heima.schedule.mapper.TaskinfoLogsMapper;
import com.heima.schedule.mapper.TaskinfoMapper;
import com.heima.schedule.service.TaskService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;import java.util.Calendar;
import java.util.Date;@Service
@Transactional
@Slf4j
public class TaskServiceImpl implements TaskService {/*** 添加延迟任务** @param task* @return*/@Overridepublic long addTask(Task task) {//1.添加任务到数据库中boolean success = addTaskToDb(task);if (success) {//2.添加任务到redisaddTaskToCache(task);}return task.getTaskId();}@Autowiredprivate CacheService cacheService;/*** 把任务添加到redis中** @param task*/private void addTaskToCache(Task task) {String key = task.getTaskType() + "_" + task.getPriority();//获取5分钟之后的时间 毫秒值Calendar calendar = Calendar.getInstance();calendar.add(Calendar.MINUTE, 5);long nextScheduleTime = calendar.getTimeInMillis();//2.1 如果任务的执行时间小于等于当前时间,存入listif (task.getExecuteTime() <= System.currentTimeMillis()) {cacheService.lLeftPush(ScheduleConstants.TOPIC + key, JSON.toJSONString(task));} else if (task.getExecuteTime() <= nextScheduleTime) {//2.2 如果任务的执行时间大于当前时间 && 小于等于预设时间(未来5分钟) 存入zset中cacheService.zAdd(ScheduleConstants.FUTURE + key, JSON.toJSONString(task), task.getExecuteTime());}}@Autowiredprivate TaskinfoMapper taskinfoMapper;@Autowiredprivate TaskinfoLogsMapper taskinfoLogsMapper;/*** 添加任务到数据库中** @param task* @return*/private boolean addTaskToDb(Task task) {boolean flag = false;try {//保存任务表Taskinfo taskinfo = new Taskinfo();BeanUtils.copyProperties(task, taskinfo);taskinfo.setExecuteTime(new Date(task.getExecuteTime()));taskinfoMapper.insert(taskinfo);//设置taskIDtask.setTaskId(taskinfo.getTaskId());//保存任务日志数据TaskinfoLogs taskinfoLogs = new TaskinfoLogs();BeanUtils.copyProperties(taskinfo, taskinfoLogs);taskinfoLogs.setVersion(1);taskinfoLogs.setStatus(ScheduleConstants.SCHEDULED);taskinfoLogsMapper.insert(taskinfoLogs);flag = true;} catch (Exception e) {e.printStackTrace();}return flag;}
}
![]()
ScheduleConstants常量类
package com.heima.common.constants;public class ScheduleConstants {//task状态public static final int SCHEDULED=0; //初始化状态public static final int EXECUTED=1; //已执行状态public static final int CANCELLED=2; //已取消状态public static String FUTURE="future_"; //未来数据key前缀public static String TOPIC="topic_"; //当前数据key前缀
}
④:测试
对TaskService,使用快捷键Alt + Enter选择Create Test,勾选addTask
TaskServiceImplTest.java内容如下:
package com.heima.schedule.service.impl;import com.heima.model.schedule.dtos.Task;
import com.heima.schedule.ScheduleApplication;
import com.heima.schedule.service.TaskService;
import org.junit.jupiter.api.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import java.util.Date;import static org.junit.jupiter.api.Assertions.*;@SpringBootTest(classes = ScheduleApplication.class)
@RunWith(SpringRunner.class)
class TaskServiceImplTest {@Autowiredprivate TaskService taskService;@Testvoid addTask() {Task task = new Task();task.setTaskType(100);task.setPriority(50);task.setParameters("task test".getBytes());task.setExecuteTime(new Date().getTime());long taskId = taskService.addTask(task);System.out.println(taskId);}
}
![]()
执行测试类之后,有可能报com.heima.schedule.mapper找不到的错误,这里我们可以通过Maven重新编译一下heima-leadnews-schedule
我们看到数据库:

后台打印:
再看一下redis
那我们更改一下代码
后台如下:
数据库如下:

发现redis增加了未来的一条zset结构
我们把时间进一步增加,超过5分钟,发现数据库有存,redis缓冲就没有添加了。
后台如下:
数据库:增加了数据

redis缓存:没有数据
4.6 取消任务

在TaskService中添加方法
/*** 取消任务* @param taskId 任务id* @return 取消结果*/
public boolean cancelTask(long taskId);实现
/*** 取消任务* @param taskId* @return*/
@Override
public boolean cancelTask(long taskId) {boolean flag = false;//删除任务,更新日志Task task = updateDb(taskId,ScheduleConstants.EXECUTED);//删除redis的数据if(task != null){removeTaskFromCache(task);flag = true;}return false;
}/*** 删除redis中的任务数据* @param task*/
private void removeTaskFromCache(Task task) {String key = task.getTaskType()+"_"+task.getPriority();if(task.getExecuteTime()<=System.currentTimeMillis()){cacheService.lRemove(ScheduleConstants.TOPIC+key,0,JSON.toJSONString(task));}else {cacheService.zRemove(ScheduleConstants.FUTURE+key, JSON.toJSONString(task));}
}/*** 删除任务,更新任务日志状态* @param taskId* @param status* @return*/
private Task updateDb(long taskId, int status) {Task task = null;try {//删除任务taskinfoMapper.deleteById(taskId);TaskinfoLogs taskinfoLogs = taskinfoLogsMapper.selectById(taskId);taskinfoLogs.setStatus(status);taskinfoLogsMapper.updateById(taskinfoLogs);task = new Task();BeanUtils.copyProperties(taskinfoLogs,task);task.setExecuteTime(taskinfoLogs.getExecuteTime().getTime());}catch (Exception e){log.error("task cancel exception taskid={}",taskId);}return task;}
![]()
测试,修改TaskServiceImplTest.java
@Testpublic void removeTask() {taskService.cancelTask(1677946555950288898L);}
运行前先看下数据库的数据
redis数据如下:
执行后:leadnews_schedule.taskinfo数据如下
leadnews_schedule.taskinfo_logs 数据如下:
4.7 消费任务

消费任务:
在TaskService中添加方法
/*** 按照类型和优先级来拉取任务* @param type* @param priority* @return*/
public Task poll(int type,int priority);
实现
/*** 按照类型和优先级拉取任务* @return*/
@Override
public Task poll(int type,int priority) {Task task = null;try {String key = type+"_"+priority;String task_json = cacheService.lRightPop(ScheduleConstants.TOPIC + key);if(StringUtils.isNotBlank(task_json)){task = JSON.parseObject(task_json, Task.class);//更新数据库信息updateDb(task.getTaskId(),ScheduleConstants.EXECUTED);}}catch (Exception e){e.printStackTrace();log.error("poll task exception");}return task;
}
![]()
测试TaskServiceImplTest.java,添加方法如下:
@Testpublic void popTask() {Task task = taskService.popTask(100, 50);System.out.println("消息如下:" + task);}
测试前数据库如下:
测试前redis如下:
消息如下:
再看下数据库:

再看下redis:
4.8 未来数据定时刷新


思考:
方案1:
方案2:
4.8.1 redis key值匹配
方案1:keys 模糊匹配
keys的模糊匹配功能很方便也很强大,但是在生产环境需要慎用!开发中使用keys的模糊匹配却发现redis的CPU使用率极高,所以公司的redis生产环境将keys命令禁用了!redis是单线程,会被堵塞
方案2:scan
SCAN 命令是一个基于游标的迭代器,SCAN命令每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为SCAN命令的游标参数, 以此来延续之前的迭代过程。
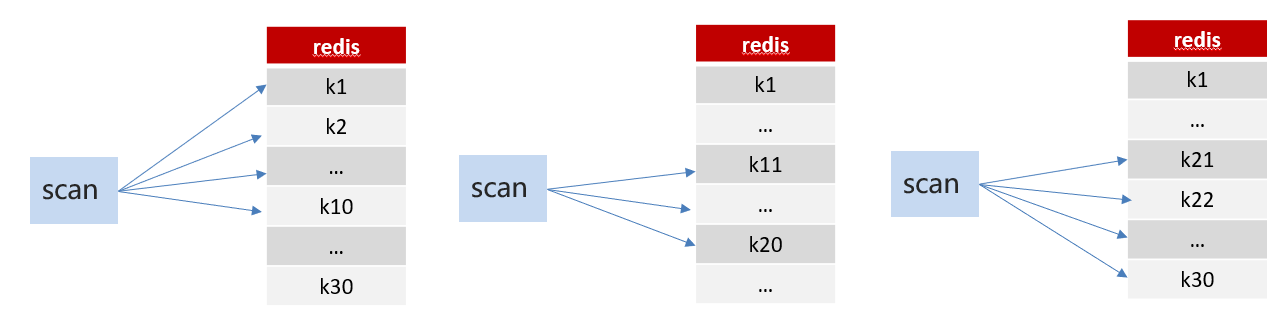
代码案例:RedisTest.java中添加方法testKeys,具体内容如下:
@Testpublic void testKeys() {Set<String> keys = cacheService.keys(ScheduleConstants.FUTURE + "*");System.out.println("方式一:");System.out.println(keys);Set<String> scan = cacheService.scan(ScheduleConstants.FUTURE + "*");System.out.println("方式二:");System.out.println(scan);}
运行结果如下:
4.8.2 redis管道

普通redis客户端和服务器交互模式
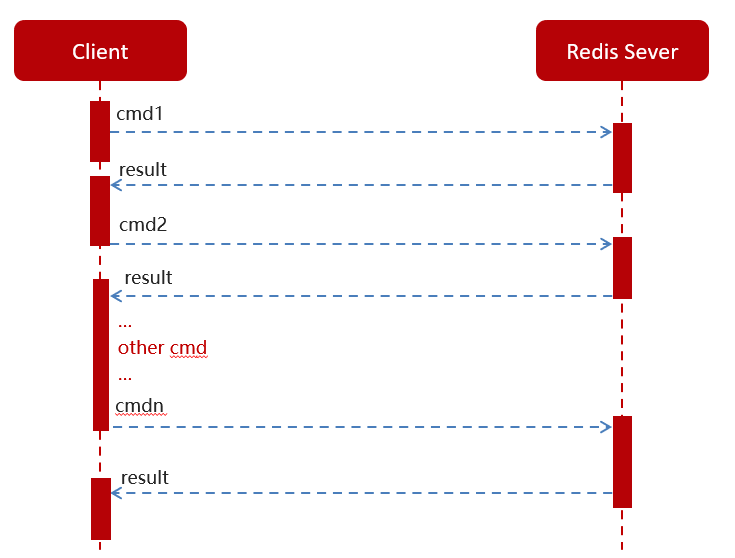
Pipeline请求模型
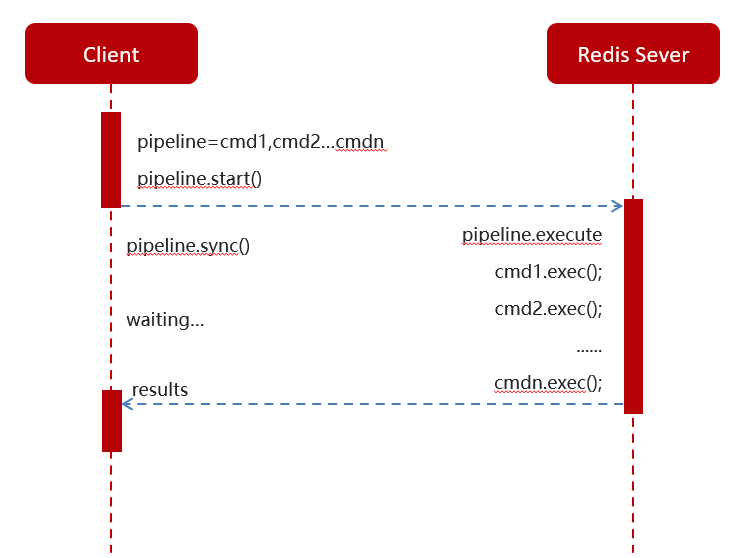
官方测试结果数据对比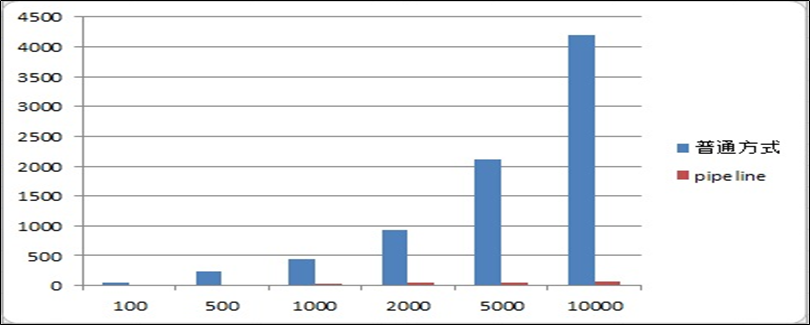
测试案例对比:
//耗时6151
@Test
public void testPiple1(){long start =System.currentTimeMillis();for (int i = 0; i <10000 ; i++) {Task task = new Task();task.setTaskType(1001);task.setPriority(1);task.setExecuteTime(new Date().getTime());cacheService.lLeftPush("1001_1", JSON.toJSONString(task));}System.out.println("耗时"+(System.currentTimeMillis()- start));
}@Test
public void testPiple2(){long start = System.currentTimeMillis();//使用管道技术List<Object> objectList = cacheService.getstringRedisTemplate().executePipelined(new RedisCallback<Object>() {@Nullable@Overridepublic Object doInRedis(RedisConnection redisConnection) throws DataAccessException {for (int i = 0; i <10000 ; i++) {Task task = new Task();task.setTaskType(1001);task.setPriority(1);task.setExecuteTime(new Date().getTime());redisConnection.lPush("1001_1".getBytes(), JSON.toJSONString(task).getBytes());}return null;}});System.out.println("使用管道技术执行10000次自增操作共耗时:"+(System.currentTimeMillis()-start)+"毫秒");
}
![]()
测试后发现,分别用时: 7521毫秒和1621毫秒
还是通过管道更加快捷。
4.8.3 未来数据定时刷新-功能完成

在TaskService中添加方法
@Scheduled(cron = "0 */1 * * * ?")
public void refresh() {System.out.println(System.currentTimeMillis() / 1000 + "执行了定时任务");// 获取所有未来数据集合的key值Set<String> futureKeys = cacheService.scan(ScheduleConstants.FUTURE + "*");// future_*for (String futureKey : futureKeys) { // future_250_250String topicKey = ScheduleConstants.TOPIC + futureKey.split(ScheduleConstants.FUTURE)[1];//获取该组key下当前需要消费的任务数据Set<String> tasks = cacheService.zRangeByScore(futureKey, 0, System.currentTimeMillis());if (!tasks.isEmpty()) {//将这些任务数据添加到消费者队列中cacheService.refreshWithPipeline(futureKey, topicKey, tasks);System.out.println("成功的将" + futureKey + "下的当前需要执行的任务数据刷新到" + topicKey + "下");}}
}
![]()
然后新建一个测试方法TaskServiceImplTest.java
/*** @param* @return long* @description // 添加延迟任务(循环)* @param: task* @date 2023/7/9 15:03* @author wty**/public void addTaskNew() {for (int i = 0; i < 5; i++) {Task task = new Task();task.setTaskType(100 + i);task.setPriority(50);task.setParameters("task test".getBytes());task.setExecuteTime(new Date().getTime() + 500 * i);long taskId = taskService.addTask(task);}}
![]()
先测试一下测试类,运行完后redis增加了5条数据
在引导类中添加开启任务调度注解:@EnableScheduling
添加后启动ScheduleApplication.java
启动后,刷新成功
再看redis,前缀由future变为了topic
4.9 分布式锁解决集群下的方法抢占执行
4.9.1 问题描述
启动两台heima-leadnews-schedule服务,每台服务都会去执行refresh定时任务方法
我们再开一个服务演示一下,多个不同实例运行同一个服务的情况。
更改为
-Dserver.port=51702
- 1
这个时候,把两个端口都启动
4.9.2 分布式锁
分布式锁:控制分布式系统有序的去对共享资源进行操作,通过互斥来保证数据的一致性。
解决方案:
4.9.3 redis分布式锁
sexnx (SET if Not eXists) 命令在指定的 key 不存在时,为 key 设置指定的值。
这种加锁的思路是,如果 key 不存在则为 key 设置 value,如果 key 已存在则 SETNX 命令不做任何操作
- 客户端A请求服务器设置key的值,如果设置成功就表示加锁成功
- 客户端B也去请求服务器设置key的值,如果返回失败,那么就代表加锁失败
- 客户端A执行代码完成,删除锁
- 客户端B在等待一段时间后再去请求设置key的值,设置成功
- 客户端B执行代码完成,删除锁
4.9.4 在工具类CacheService中添加方法
在heima-leadnews-common中添加方法
/*** 加锁** @param name* @param expire* @return*/
public String tryLock(String name, long expire) {name = name + "_lock";String token = UUID.randomUUID().toString();RedisConnectionFactory factory = stringRedisTemplate.getConnectionFactory();RedisConnection conn = factory.getConnection();try {//参考redis命令://set key value [EX seconds] [PX milliseconds] [NX|XX]Boolean result = conn.set(name.getBytes(),token.getBytes(),Expiration.from(expire, TimeUnit.MILLISECONDS),RedisStringCommands.SetOption.SET_IF_ABSENT //NX);if (result != null && result)return token;} finally {RedisConnectionUtils.releaseConnection(conn, factory,false);}return null;
}
![]()
修改未来数据定时刷新的方法,如下:
/*** 未来数据定时刷新*/
@Scheduled(cron = "0 */1 * * * ?")
public void refresh(){String token = cacheService.tryLock("FUTURE_TASK_SYNC", 1000 * 30);if(StringUtils.isNotBlank(token)){log.info("未来数据定时刷新---定时任务");//获取所有未来数据的集合keySet<String> futureKeys = cacheService.scan(ScheduleConstants.FUTURE + "*");for (String futureKey : futureKeys) {//future_100_50//获取当前数据的key topicString topicKey = ScheduleConstants.TOPIC+futureKey.split(ScheduleConstants.FUTURE)[1];//按照key和分值查询符合条件的数据Set<String> tasks = cacheService.zRangeByScore(futureKey, 0, System.currentTimeMillis());//同步数据if(!tasks.isEmpty()){cacheService.refreshWithPipeline(futureKey,topicKey,tasks);log.info("成功的将"+futureKey+"刷新到了"+topicKey);}}}
}
![]()
修改完之后,直接重启项目
发现51702时20点25分执行的
发现51701时20点26分执行的
因为有分布式锁的存在,即便是有多个端口,也只会执行其中的一个。
4.10 数据库同步到redis
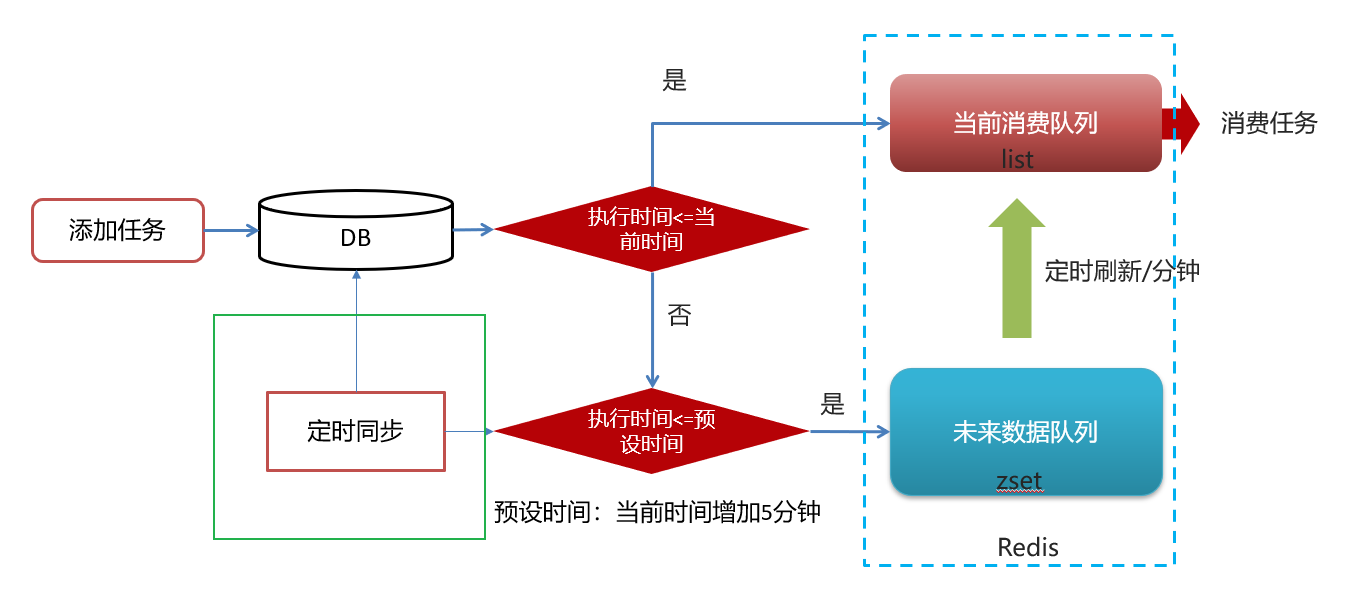
步骤如下:
@Scheduled(cron = "0 */5 * * * ?")
@PostConstruct
public void reloadData() {clearCache();log.info("数据库数据同步到缓存");Calendar calendar = Calendar.getInstance();calendar.add(Calendar.MINUTE, 5);//查看小于未来5分钟的所有任务List<Taskinfo> allTasks = taskinfoMapper.selectList(Wrappers.<Taskinfo>lambdaQuery().lt(Taskinfo::getExecuteTime,calendar.getTime()));if(allTasks != null && allTasks.size() > 0){for (Taskinfo taskinfo : allTasks) {Task task = new Task();BeanUtils.copyProperties(taskinfo,task);task.setExecuteTime(taskinfo.getExecuteTime().getTime());addTaskToCache(task);}}
}private void clearCache(){// 删除缓存中未来数据集合和当前消费者队列的所有keySet<String> futurekeys = cacheService.scan(ScheduleConstants.FUTURE + "*");// future_Set<String> topickeys = cacheService.scan(ScheduleConstants.TOPIC + "*");// topic_cacheService.delete(futurekeys);cacheService.delete(topickeys);
}
![]()
具体测试的话,先执行TaskServiceImplTest.java中的addTaskNew方法,运行几个任务数据
Java后台如下:
redis中数据如下
数据库中数据如下:
我们删除一些redis的数据
然后我们重启schedule微服务
再看一下redis如下:
5.延迟队列解决精准时间发布文章

5.1 延迟队列服务提供对外接口
提供远程的feign接口,在heima-leadnews-feign-api编写类如下:
package com.heima.apis.schedule;import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.schedule.dtos.Task;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;@FeignClient("leadnews-schedule")
public interface IScheduleClient {/*** 添加任务* @param task 任务对象* @return 任务id*/@PostMapping("/api/v1/task/add")public ResponseResult addTask(@RequestBody Task task);/*** 取消任务* @param taskId 任务id* @return 取消结果*/@GetMapping("/api/v1/task/cancel/{taskId}")public ResponseResult cancelTask(@PathVariable("taskId") long taskId);/*** 按照类型和优先级来拉取任务* @param type* @param priority* @return*/@GetMapping("/api/v1/task/poll/{type}/{priority}")public ResponseResult poll(@PathVariable("type") int type,@PathVariable("priority") int priority);
}
![]()
注意这里的@FeignClient要与服务一致
在heima-leadnews-schedule微服务下提供对应的实现
package com.heima.schedule.feign;import com.heima.apis.schedule.IScheduleClient;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.schedule.dtos.Task;
import com.heima.schedule.service.TaskService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;@RestController
public class ScheduleClient implements IScheduleClient {@Autowiredprivate TaskService taskService;/*** 添加任务* @param task 任务对象* @return 任务id*/@PostMapping("/api/v1/task/add")@Overridepublic ResponseResult addTask(@RequestBody Task task) {return ResponseResult.okResult(taskService.addTask(task));}/*** 取消任务* @param taskId 任务id* @return 取消结果*/@GetMapping("/api/v1/task/cancel/{taskId}")@Overridepublic ResponseResult cancelTask(@PathVariable("taskId") long taskId) {return ResponseResult.okResult(taskService.cancelTask(taskId));}/*** 按照类型和优先级来拉取任务* @param type* @param priority* @return*/@GetMapping("/api/v1/task/poll/{type}/{priority}")@Overridepublic ResponseResult poll(@PathVariable("type") int type, @PathVariable("priority") int priority) {return ResponseResult.okResult(taskService.poll(type,priority));}
}
![]()
5.2 发布文章集成添加延迟队列接口

在创建WmNewsTaskService
package com.heima.wemedia.service;import com.heima.model.wemedia.pojos.WmNews;public interface WmNewsTaskService {/*** 添加任务到延迟队列中* @param id 文章的id* @param publishTime 发布的时间 可以做为任务的执行时间*/public void addNewsToTask(Integer id, Date publishTime);}
![]()
实现:
package com.heima.wemedia.service.impl;import com.heima.apis.schedule.IScheduleClient;
import com.heima.model.common.enums.TaskTypeEnum;
import com.heima.model.schedule.dtos.Task;
import com.heima.model.wemedia.pojos.WmNews;
import com.heima.utils.common.ProtostuffUtil;
import com.heima.wemedia.service.WmNewsTaskService;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;@Service
@Slf4j
public class WmNewsTaskServiceImpl implements WmNewsTaskService {@Autowiredprivate IScheduleClient scheduleClient;/*** 添加任务到延迟队列中* @param id 文章的id* @param publishTime 发布的时间 可以做为任务的执行时间*/@Override@Asyncpublic void addNewsToTask(Integer id, Date publishTime) {log.info("添加任务到延迟服务中----begin");Task task = new Task();task.setExecuteTime(publishTime.getTime());task.setTaskType(TaskTypeEnum.NEWS_SCAN_TIME.getTaskType());task.setPriority(TaskTypeEnum.NEWS_SCAN_TIME.getPriority());WmNews wmNews = new WmNews();wmNews.setId(id);task.setParameters(ProtostuffUtil.serialize(wmNews));scheduleClient.addTask(task);log.info("添加任务到延迟服务中----end");}}
![]()
枚举类:
package com.heima.model.common.enums;import lombok.AllArgsConstructor;
import lombok.Getter;@Getter
@AllArgsConstructor
public enum TaskTypeEnum {NEWS_SCAN_TIME(1001, 1,"文章定时审核"),REMOTEERROR(1002, 2,"第三方接口调用失败,重试");private final int taskType; //对应具体业务private final int priority; //业务不同级别private final String desc; //描述信息
}
序列化工具对比
- JdkSerialize:java内置的序列化能将实现了Serilazable接口的对象进行序列化和反序列化, ObjectOutputStream的writeObject()方法可序列化对象生成字节数组
- Protostuff:google开源的protostuff采用更为紧凑的二进制数组,表现更加优异,然后使用protostuff的编译工具生成pojo类
拷贝资料中的两个类到heima-leadnews-utils下
Protostuff需要引导依赖:
<dependency><groupId>io.protostuff</groupId><artifactId>protostuff-core</artifactId><version>1.6.0</version>
</dependency><dependency><groupId>io.protostuff</groupId><artifactId>protostuff-runtime</artifactId><version>1.6.0</version>
</dependency>
运行一下测试类
可以发现protostuff花费的时间是很少的
修改发布文章代码:
把之前的异步调用修改为调用延迟任务
@Autowired
private WmNewsTaskService wmNewsTaskService;/*** 发布修改文章或保存为草稿* @param dto* @return*/
@Override
public ResponseResult submitNews(WmNewsDto dto) {//0.条件判断if(dto == null || dto.getContent() == null){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}//1.保存或修改文章WmNews wmNews = new WmNews();//属性拷贝 属性名词和类型相同才能拷贝BeanUtils.copyProperties(dto,wmNews);//封面图片 list---> stringif(dto.getImages() != null && dto.getImages().size() > 0){//[1dddfsd.jpg,sdlfjldk.jpg]--> 1dddfsd.jpg,sdlfjldk.jpgString imageStr = StringUtils.join(dto.getImages(), ",");wmNews.setImages(imageStr);}//如果当前封面类型为自动 -1if(dto.getType().equals(WemediaConstants.WM_NEWS_TYPE_AUTO)){wmNews.setType(null);}saveOrUpdateWmNews(wmNews);//2.判断是否为草稿 如果为草稿结束当前方法if(dto.getStatus().equals(WmNews.Status.NORMAL.getCode())){return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);}//3.不是草稿,保存文章内容图片与素材的关系//获取到文章内容中的图片信息List<String> materials = ectractUrlInfo(dto.getContent());saveRelativeInfoForContent(materials,wmNews.getId());//4.不是草稿,保存文章封面图片与素材的关系,如果当前布局是自动,需要匹配封面图片saveRelativeInfoForCover(dto,wmNews,materials);//审核文章// wmNewsAutoScanService.autoScanWmNews(wmNews.getId());wmNewsTaskService.addNewsToTask(wmNews.getId(),wmNews.getPublishTime());return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);}
![]()
启动三个微服务
启动nginx
登录http://localhost:8802/#/login
发布文章
把数据库中的表leadnews_schedule.taskinfo和leadnews_schedule.taskinfo_logs全部截断
redis的数据也全部清空
全部操作完后再点击提交审核
我们发现,任务是待审核的状态,因为还没有消费
数据库如下:

redis如下:
再次发布一个未来5分钟内的文章
发布后:
发布后数据库如下:


redis如下:
5.3 消费任务进行审核文章

WmNewsTaskService中添加方法
/*** 消费延迟队列数据*/
public void scanNewsByTask();
实现
@Autowired
private WmNewsAutoScanServiceImpl wmNewsAutoScanService;/*** 消费延迟队列数据*/
@Scheduled(fixedRate = 1000)
@Override
@SneakyThrows
public void scanNewsByTask() {log.info("文章审核---消费任务执行---begin---");ResponseResult responseResult = scheduleClient.poll(TaskTypeEnum.NEWS_SCAN_TIME.getTaskType(), TaskTypeEnum.NEWS_SCAN_TIME.getPriority());if(responseResult.getCode().equals(200) && responseResult.getData() != null){String json_str = JSON.toJSONString(responseResult.getData());Task task = JSON.parseObject(json_str, Task.class);byte[] parameters = task.getParameters();WmNews wmNews = ProtostuffUtil.deserialize(parameters, WmNews.class);System.out.println(wmNews.getId()+"-----------");wmNewsAutoScanService.autoScanWmNews(wmNews.getId());}log.info("文章审核---消费任务执行---end---");
}
![]()
在WemediaApplication自媒体的引导类中添加开启任务调度注解@EnableScheduling
启动4个微服务
登录
http://localhost:8802/
发布文章
发布成功后,审批成功
我们再发布一个5分钟内的延时任务
发表后,并没有马上审核
1分钟后,再次刷新,发现审核了
相关文章:
2023黑马头条.微服务项目.跟学笔记(五)
2023黑马头条.微服务项目.跟学笔记 五 延迟任务精准发布文章 1.文章定时发布2.延迟任务概述 2.1 什么是延迟任务2.2 技术对比 2.2.1 DelayQueue2.2.2 RabbitMQ实现延迟任务2.2.3 redis实现3.redis实现延迟任务4.延迟任务服务实现 4.1 搭建heima-leadnews-schedule模块4.2 数据库…...

C语言 | Leetcode C语言题解之第75题颜色分类
题目: 题解: void swap(int *a, int *b) {int t *a;*a *b, *b t; }void sortColors(int *nums, int numsSize) {int p0 0, p2 numsSize - 1;for (int i 0; i < p2; i) {while (i < p2 && nums[i] 2) {swap(&nums[i], &num…...

淘宝扭蛋机小程序开发:掌上惊喜,转出你的幸运宝藏
一、全新玩法,尽在掌中 淘宝扭蛋机小程序,将传统的扭蛋乐趣与数字时代完美结合,为您带来全新的购物体验。在这个小小的平台上,您可以用手指轻松操控,探索无尽的宝藏世界,转出专属于您的幸运好物。 二、海…...

Oracle索引组织表与大对象平滑迁移至OceanBase的实施方案
作者简介:严军(花名吉远),十年以上专注于数据库存储领域,精通Oracle、Mysql、OceanBase,对大数据、分布式、高并发、高性能、高可用有丰富的经验。主导过蚂蚁集团核心系统数据库升级,数据库LDC单元化多活项目ÿ…...
【服务治理中间件】consul介绍和基本原理
目录 一、CAP定理 二、服务注册中心产品比较 三、Consul概述 3.1 什么是Consul 3.2 Consul架构 3.3 Consul的使用场景 3.4 Consul健康检查 四、部署consul集群 4.1 服务器部署规划 4.2 下载解压 4.3 启动consul 五、服务注册到consul 一、CAP定理 CAP定理ÿ…...

无人机运营合格证:民用无人机驾驶航空器运营合格证书
无人机运营合格证是指经国家相关部门审核通过并颁发给相应无人驾驶航空器运营机构的一种资质证明。获得该证书的机构具备相关的技术和管理能力,能够安全、合规地运营无人驾驶航空器。 无人机运营合格证的申请流程一般包括报名、培训学习、考试准备、考试报名、考试…...

【编码利器 —— BaiduComate】
目录 1. 智能编码助手介绍 2. 场景需求 3. 功能体验 3.1指令功能 3.2插件用法 3.3知识用法 3.4自定义配置 4. 试用感受 5. AI编程应用 6.总结 智能编码助手是当下人工智能技术在编程领域的一项重要应用。Baidu Comate智能编码助手作为一款具有强大功能和智能特性的工…...
)
python 关键字(in)
9、in 在Python中,in关键字是一个强大的工具,用于检查一个元素是否存在于某个序列(如列表、元组、字符串等)或集合(如集合、字典的键)中。 基础小白知识:in的基本用法 1.1 在序列中检查元素 …...

【Node.js从基础到高级运用】二十八、Node.js 内存管理浅析
Node.js 作为一个基于 Chrome V8 引擎的 JavaScript 运行环境,其性能和效率在很大程度上取决于内存管理的优劣。 1. Node.js 内存结构 在深入了解内存管理之前,我们需要先了解 Node.js 的内存结构。Node.js 的内存可以大致分为以下几个部分:…...

AES加密解密
加密 java.util.Base64; javax.crypto.Cipher; javax.crypto.spec.SecretKeySpec; // 入参:data(String)、seed(String) Cipher cipher Cipher.getInstance("AES/ECB/PKCS5Padding"); SecretKeySpec secre…...

通过红黑树封装 map 和 set 容器(1):红黑树的迭代器
一、红黑树的迭代器 红黑树的遍历默认为中序遍历 —— key 从小到大,因此 begin() 应该获取到红黑树的最左节点 —— 最小,end() 获取到红黑树最右节点的下一个位置, operator() 也应保证红黑树的遍历为中序的状态。 首先对红黑树节点进行改造…...

mysqlbinlog恢复delete的数据
实验目的 delete数据后,用mysqlbinlog进行数据恢复 实验过程 原表 mysql> select * from mytest; ----------------- | id | name | score | ----------------- | 1 | xw01 | 90 | | 2 | xw02 | 92 | | 3 | xw03 | 93 | | 4 | xw04 | 94 | |…...

传递给组件
React 组件使用 props 相互通信。每个父组件都可以通过为其子组件提供道具来将一些信息传递给子组件。Props 可能会让您想起 HTML 属性,但您可以通过它们传递任何 JavaScript 值,包括对象、数组和函数。 Props 是传递给 JSX 标签的信息。例如࿰…...

鸿蒙通用组件弹窗简介
鸿蒙通用组件弹窗简介 弹窗----Toast引入ohos.promptAction模块通过点击按钮,模拟弹窗 警告对话框----AlertDialog列表弹窗----ActionSheet选择器弹窗自定义弹窗使用CustomDialog声明一个自定义弹窗在需要使用的地方声明自定义弹窗,完整代码 弹窗----Toa…...

[译文] 恶意代码分析:1.您记事本中的内容是什么?受感染的文本编辑器notepad++
这是作者新开的一个专栏,主要翻译国外知名安全厂商的技术报告和安全技术,了解它们的前沿技术,学习它们威胁溯源和恶意代码分析的方法,希望对您有所帮助。当然,由于作者英语有限,会借助LLM进行校验和润色&am…...
Spring Boot3.x集成Disruptor4.0
Disruptor介绍 Disruptor是一个高性能内存队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级)。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。2011年&…...

GoEdge自建CDN工具
GoEdge是一款管理分布式CDN边缘节点的开源工具软件,可以让用户轻松地、低成本地创建CDN/WAF等应用。同时提供免费版本和商业版本,本文基本免费版本安装测试。 GoEdgep安装涉及三部分: 边缘节点 - 接收和响应用户请求的终端节点 管理员系统 - …...

牛客储物点的距离
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 题目描述 一个数轴,每一个储物点会有一些东西,同时它们之间存在距离。 每次给个区间[l,r],查询把这个区间内所有储物点的东西运到另外一个储物点的代价是多少࿱…...

【C++历练之路】红黑树——map与set的封装实现
W...Y的个人主页💕 gitee代码仓库分享😊 前言:上篇博客中,我们为了使二叉搜索树不会出现”一边倒“的情况,使用了AVL树对搜索树进行了处理,从而解决了数据在有序或者接近有序时出现的情况。但是AVL树还会…...
RDB快照是怎么实现的?
RDB快照是怎么实现的? 前言快照怎么用?执行快照时,数据能被修改吗?RDB 和 AOF 合体 前言 虽说 Redis 是内存数据库,但是它为数据的持久化提供了两个技术。 分别是「 AOF 日志和 RDB 快照」。 这两种技术都会用各用一…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

安宝特方案丨XRSOP人员作业标准化管理平台:AR智慧点检验收套件
在选煤厂、化工厂、钢铁厂等过程生产型企业,其生产设备的运行效率和非计划停机对工业制造效益有较大影响。 随着企业自动化和智能化建设的推进,需提前预防假检、错检、漏检,推动智慧生产运维系统数据的流动和现场赋能应用。同时,…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...