【OceanBase 系列】—— OceanBase v4.3 特性解读:查询性能提升之利器列存储引擎
原文链接:OceanBase 社区
对于分析类查询,列存可以极大地提升查询性能,也是 OceanBase 做好 HTAP 和 OLAP 的一项不可缺少的特性。本文介绍 OceanBase 列存的实现特色。
OceanBase从诞生起就一直坚持LSM-Tree架构,不断打磨功能支持了各类典型的 TP 类型业务,持续优化性能满足各种极限负载压力,积累了大量工程实践经验,打造出一套纯自主研发且有充分特色的业界领先LSM-tree 存储引擎。常见的 OLAP 场景往往是批量写入,不会有大量随机更新,尽量保证列存组织数据是静态的,这种场景天然适合 LSM-Tree 架构。
在4.3版本,基于原有技术积累,OceanBase 存储引擎继续扩展,实现对列存的支持,实现存储一体化,一套代码一个架构一个OBServer,列存数据和行存数据完美共存,这样真正实现了对TP类和AP类查询的性能的兼顾。
整体架构
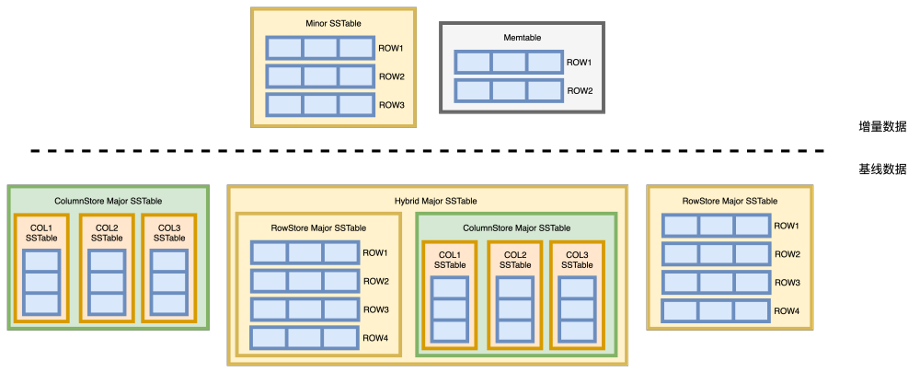
OceanBase作为原生分布式数据库,用户数据默认会多副本存储,为了利用多副本的优势,为用户提供数据强校验以及迁移数据重用等进一步的增强体验,自研的LSM-Tree存储引擎也做了较多的针对性设计,首先每个用户数据整体可以分成两个大部分基线数据和增量数据。
- 基线数据。不同于其它主流LSM-Tree数据库,OceanBase利用分布式多副本的基础,提出'每日合并'的概念,租户会定期或者根据用户操作选择一个全局版本号,租户数据的所有副本均以这个版本完成一轮Major Compaction,最后生成这个版本的基线数据,所有副本同一个版本的基线数据物理完全一致。
- 增量数据。相对基线数据而言,用户数据在最新版本的基线数据之后所有写入数据均属于增量数据,具体来说,增量数据可以是用户刚写入Memtable的内存数据,也可以是已经转储为SSTable的磁盘数据。 对于用户数据的所有副本来说,增量数据各个副本独立维护,不保证一致,并且不同于基线数据基于指定版本生成,增量数据包含所有多版本数据。
基于列存应用场景随机更新量可控的背景,OceanBase结合自身基线数据和增量数据的特质,提出了一套对上层透明的列存实现方式:
- 基线数据存储为列存模式,增量数据保持行存,用户所有 DML 操作不受影响,上下游同步无缝接入,列存表数据仍然可以像行存表一样进行所有事务操作。
- 列存模式下每列数据存储为一个独立SSTable,所有列的SSTable组合成为一个虚拟SSTable作为用户的列存基线数据,如下图所示。
- 根据用户建表指定设置,基线数据可以有行存,列存,行存列存冗余三种模式。
我们不仅在存储引擎中实现了列存模式,为了让用户能够更容易从其它 OLAP 数据库迁移过来,以及帮助之前有 OLAP 需求的 OceanBase 老客户升级到列存,从优化器到执行器以及存储其它相关模块,都针对列存进行了适配以及优化,让用户迁移到列存后基本对业务无感,能够像使用行存一样享受到列存带来的性能优势。 也让OceanBase真正实现了TP/AP一体化,实现一套引擎一套代码支持不同类型业务的目标,打造完善的HTAP引擎。
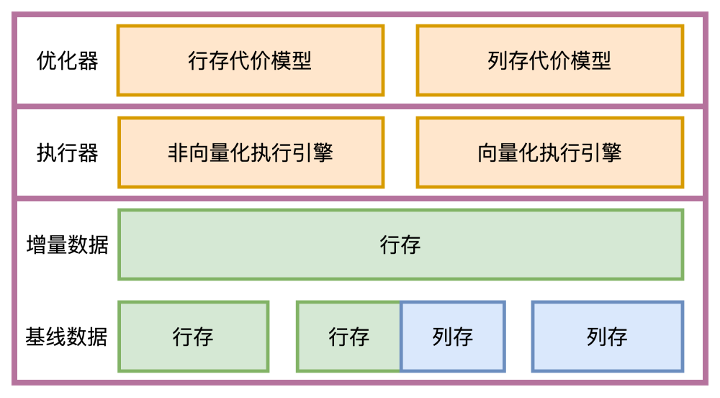
- SQL一体化
- 为列存设计实现了新的代价模型,并增加列存相关统计信息,优化器根据数据表存储模式根据代价自动选择计划。
- 实现新的向量化引擎,完成关键算子的新引擎重构,不同类型计划根据代价自适应选择向量化以及批大小。
- 存储一体化
- 用户数据根据表模式指定,可以根据业务负载类型灵活设置为列存行存或者行列冗余模式,用户查询/备份恢复等操作完全透明。
- 列存表完整支持所有在线及离线DDL操作,完整支持所有数据类型及二级索引创建,保证用户使用方法和行存别无二致。
- 事务一体化
- 增量数据全部为行存,事务内修改、日志内容以及多版本控制等和行存完全共享逻辑。
核心特性
特性1:自适应Compaction
引入新的列存存储模式之后,数据合并行为和原有行存数据有较大变化,由于增量数据全部是行存,需要和基线数据合并后拆分到每个列的独立SSTable中,合并时间和资源占用相对行存会有较大增长.
为了加速列存表合并速度,Compaction流程进行大幅增强,对于列存表,除了能够像行存表一样进行水平拆分并行合并加速之外,还增加了垂直拆分加速,列存表会降多个列的合并动作放在一个合并任务内进行,并且一个任务内的列数能够根据系统资源自主选择升降,保证整体在合并速度以及内存开销达到更好的平衡。
特性2:列式编码算法
OceanBase一直以来存储数据会经过两级压缩,第一级是OceanBase自研的行列混合编码压缩,第二级是通用压缩,其中行列混合编码由于是数据库内置算法,因此可以支持不解压直接查询,同时可以利用编码信息进行查询过滤加速,尤其对AP类查询会有极大的加速。
但是原有行列混合编码算法仍然偏向行组织,因此针对列存表实现了全新的列式编码算法,相比原有编码算法,新算法支持查询的全面向量化执行,支持兼容不同指令集的SIMD优化,同时针对数值类型大幅提高压缩比,实现对原有算法在性能和压缩比上的全面提升。
特性3:Skip Index
常见列存数据库一般均会对每列数据按照一定的粒度进行预聚合计算,聚合的结果随数据一起持久化,当用户查询请求访问列数据时,数据库能够通过预聚合数据过滤数据,大幅减少数据访问开销,减少不必要的IO消耗。
在列存引擎中,我们同样增加了skip index的支持,针对每列数据会按照微块粒度进行最大值、最小值、和以及null总量等多个维度的聚合计算,并逐层向上聚合累加获得宏块、SSTable等更大粒度的聚合值,用户查询能够根据扫描范围不断下钻选取合适粒度聚合值进行过滤以及聚合输出。
特性4:查询下压
OceanBase 在3.2版本开始初步支持简单的查询下压,从4.x版本开始存储全面支持了向量化以及更多的下压支持,在列存引擎中,下压功能进一步得到增强和扩展,具体包括:
- 所有查询filter下压,同时根据filter类型,能够进一步利用skip index以及编码信息加速。
- 常用聚合函数的下压,非group by场景下,目前count/max/min/sum/avg等聚合函数已能下压到存储引擎.
- group by下压,在NDV较少的列上,支持group by下压存储计算,利用微块内字典信息进行大幅加速。
使用列存
默认创建列存表
对于 OLAP 业务,我们推荐默认创建列存表。如何让租户创建出来的表默认就是列存表?通过下面的配置项即可实现:
alter system set default_table_store_format = "column";随后我们创建的表格没有指定 column group 时,默认就是列存表。
OceanBase(root@test)>create table t1 (c1 int primary key, c2 int ,c3 int);
Query OK,0 rows affected (0.301 sec)OceanBase(root@test)>show create table t1;CREATE TABLE `t1` (`c1` int(11) NOT NULL,`c2` int(11) DEFAULT NULL,`c3` int(11) DEFAULT NULL,PRIMARY KEY (`c1`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
WITH COLUMN GROUP(each column)1 row in set (0.101 sec)指定创建列存表
列存引入新的语法with column group,当用户建表时最后指定 with column group(each column) 即代表创建列存表。
OceanBase(root@test)>create table tt_column_store (c1 int primary key, c2 int ,c3 int) with column group (each column);
Query OK,0 rows affected (0.308 sec)OceanBase(root@test)>show create table tt_column_store;CREATE TABLE `tt_column_store` (`c1` int(11) NOT NULL,`c2` int(11) DEFAULT NULL,`c3` int(11) DEFAULT NULL,PRIMARY KEY (`c1`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 WITH COLUMN GROUP(each column)1 row in set (0.108 sec)指定创建列存行存冗余表
对于部分场景,用户可以忍受一定程度的数据冗余,希望带来AP/TP业务场景的兼顾,此时可以增加行存数据的冗余,通过with column group语法增加指定all columns即可。
create table tt_column_row (c1 int primary key, c2 int , c3 int) with column group (all columns, each column);
Query OK, 0 rows affected (0.252 sec)OceanBase(root@test)>show create table tt_column_row;
CREATE TABLE `tt_column_row` (`c1` int(11) NOT NULL, `c2` int(11) DEFAULT NULL, `c3` int(11) DEFAULT NULL, PRIMARY KEY (`c1`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 WITH COLUMN GROUP(all columns, each column)1 row in set (0.075 sec)列存扫描
如何查看是否列存扫描计划?
计划展示上新增COLUMN TABLE FULL SCAN,描述列存表的范围扫描
OceanBase(root@test)>explain select * from tt_column_store;
+--------------------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------------------+
| ================================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------------------- |
| |0 |COLUMN TABLE FULL SCAN|tt_column_store|1 |7 | |
| ================================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([tt_column_store.c1], [tt_column_store.c2], [tt_column_store.c3]), filter(nil), rowset=16 |
| access([tt_column_store.c1], [tt_column_store.c2], [tt_column_store.c3]), partitions(p0) |
| is_index_back=false, is_glOceanBaseal_index=false, |
| range_key([tt_column_store.c1]), range(MIN ; MAX)always true |
+--------------------------------------------------------------------------------------------------------+计划展示上新增COLUMN TABLE GET,描述列存表上的指定主键的get操作
OceanBase(root@test)>explain select * from tt_column_store where c1 = 1;
+--------------------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------------------+
| =========================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------------- |
| |0 |COLUMN TABLE GET|tt_column_store|1 |14 | |
| =========================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([tt_column_store.c1], [tt_column_store.c2], [tt_column_store.c3]), filter(nil), rowset=16 |
| access([tt_column_store.c1], [tt_column_store.c2], [tt_column_store.c3]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([tt_column_store.c1]), range[1 ; 1], |
| range_cond([tt_column_store.c1 = 1]) |
+--------------------------------------------------------------------------------------------------------+
12 rows in set (0.051 sec)如何通过hint指定列存行存冗余表走列存扫描?
对于列存行存冗余表,优化器会根据代价选择走行存或者列存扫描,如简单场景做全表扫描,会默认使用行存生成计划
OceanBase(root@test)>explain select * from tt_column_row;
+--------------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------------+
| ======================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| -------------------------------------------------------- |
| |0 |TABLE FULL SCAN|tt_column_row|1 |3 | |
| ======================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), filter(nil), rowset=16 |
| access([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([tt_column_row.c1]), range(MIN ; MAX)always true |
+--------------------------------------------------------------------------------------------------+此时如果用户还是希望手动调优,走列存扫描,可以通过hint USE_COLUMN_TABLE来强制tt_column_row 表走列存扫描
OceanBase(root@test)>explain select /*+ USE_COLUMN_TABLE(tt_column_row) */ * from tt_column_row;
+--------------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------------+
| =============================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| --------------------------------------------------------------- |
| |0 |COLUMN TABLE FULL SCAN|tt_column_row|1 |7 | |
| =============================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), filter(nil), rowset=16 |
| access([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([tt_column_row.c1]), range(MIN ; MAX)always true |
+--------------------------------------------------------------------------------------------------+类似的,通过hint NO_USE_COLUMN_TABLE可以强制表不走列存扫描
OceanBase(root@test)>explain select /*+ NO_USE_COLUMN_TABLE(tt_column_row) */ c2 from tt_column_row;
+------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------+
| ======================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| -------------------------------------------------------- |
| |0 |TABLE FULL SCAN|tt_column_row|1 |3 | |
| ======================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([tt_column_row.c2]), filter(nil), rowset=16 |
| access([tt_column_row.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([tt_column_row.c1]), range(MIN ; MAX)always true |
+------------------------------------------------------------------+
11 rows in set (0.053 sec)相关文章:
【OceanBase 系列】—— OceanBase v4.3 特性解读:查询性能提升之利器列存储引擎
原文链接:OceanBase 社区 对于分析类查询,列存可以极大地提升查询性能,也是 OceanBase 做好 HTAP 和 OLAP 的一项不可缺少的特性。本文介绍 OceanBase 列存的实现特色。 OceanBase从诞生起就一直坚持LSM-Tree架构,不断打磨功能支…...

【Java开发的我出书啦,各位同仁快过来围观】!!!
文章目录 🔊博主介绍🥤本文内容出书的目的出书的过程书籍的内容 📥博主的话 🔊博主介绍 文章目录 🔊博主介绍🥤本文内容出书的目的出书的过程书籍的内容 📥博主的话 🌾阅读前&#x…...
AI预测福彩3D第10套算法实战化赚米验证第1弹2024年5月5日第1次测试
从今天开始,准备启用第10套算法,来验证下本算法的可行性。因为本算法通过近三十期的内测(内测版没有公开预测结果),发现本算法的预测结果优于其他所有算法的效果。彩票预测只有实战才能检验是否有效,只有真…...

leetcode 2944.购买水果需要的最小金币
思路:dp 这道题一开始想的时候并不会,但是看到了有些水果可以买也可以不买,所以就想到了选择与不选择的思路。 对于每一个水果,我们都有买和不买的选择,但是我们的第一个水果是一定要买的。然后再往后推导。 用dp[]…...
:从“探索平衡策略”看“生活工作的平衡之道”)
算法人生(14):从“探索平衡策略”看“生活工作的平衡之道”
在强化学习中,有一种策略叫“探索平衡策略Exploration-Exploitation Trade-off)”,这种策略的核心是在探索未知领域(以获取更多信息)和利用已知信息(来最大化即时回报)之间寻求平衡,…...
如何使用Tushare+ Backtrader进行股票量化策略回测
数量技术宅团队在CSDN学院推出了量化投资系列课程 欢迎有兴趣系统学习量化投资的同学,点击下方链接报名: 量化投资速成营(入门课程) Python股票量化投资 Python期货量化投资 Python数字货币量化投资 C语言CTP期货交易系统开…...

Guid转换为字符串
在理想情况下,任何计算机和计算机集群都不会生成两个相同的GUID。GUID 的总数达到了2128(3.41038)个,所以随机生成两个相同GUID的可能性非常小,但并不为0。GUID一词有时也专指微软对UUID标准的实现。 (1). GUID&#…...

OpenAI的搜索引擎要来了!
最近的报道和业界泄露信息显示,OpenAI正秘密研发一款新的搜索引擎,可能叫SearchGPT或Sonic,目标是挑战Google的搜索霸权。预计这款搜索引擎可能在5月9日即将到来的活动中正式亮相。 SearchGPT的蛛丝马迹 尽管OpenAI对SearchGPT尚未表态&…...

PaddlePaddle与OpenMMLab
产品全景_飞桨产品-飞桨PaddlePaddle OpenMMLab算法应用平台...

HBuilderX uniapp+vue3+vite axios封装
uniapp 封装axios 注:axios必须低于0.26.0,重中之重 重点:封装axios的适配器adapter 1.安装axios npm install axios0.26.0创建api文件夹 2.新建adapter.js文件 import settle from "axios/lib/core/settle" import buildURL…...
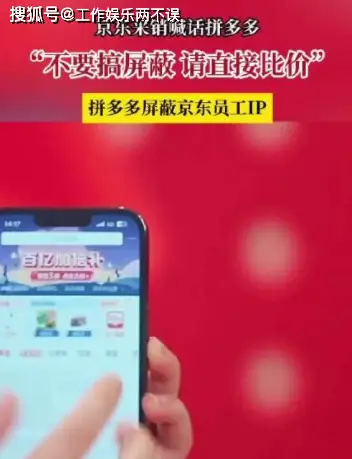
【网络安全产品】---应用防火墙(WAF)
what Web应用防火墙(Web Application Firewall) WAF可对网站或者App的业务流量进行恶意特征识别及防护,在对流量清洗和过滤后,将正常、安全的流量返回给服务器,避免网站服务器被恶意入侵导致性能异常等问题,从而保障…...
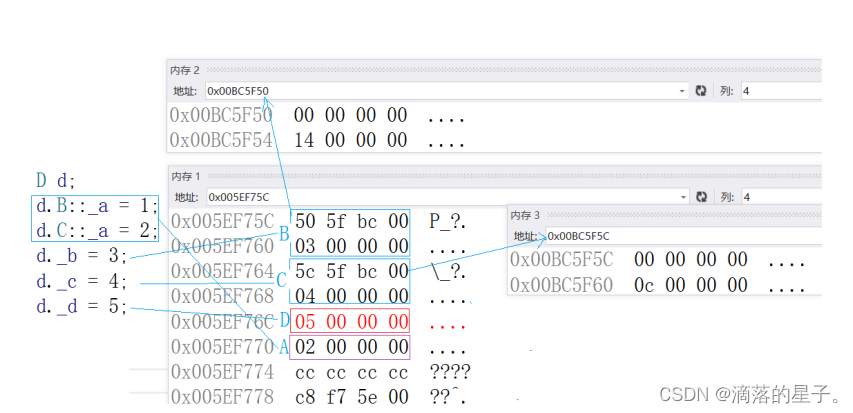
C++学习第十二天(继承)
1、继承的概念以及定义 继承的概念 继承机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性的基础上进行拓展,增加功能,这样产生新的类,称派生类。继承呈现了面向对象程序设计的层次结构&#x…...

WPF DataGrid绑定后端 在AutoGeneratingColumn事件中改变列名
public void OnAutoGeneratingColumn(DataGridAutoGeneratingColumnEventArgs e){var propertyDescriptor (PropertyDescriptor)e.PropertyDescriptor;if (propertyDescriptor.IsBrowsable){e.Column.Header propertyDescriptor.DisplayName;}else{e.Cancel true;}}实体类中…...

2024 CorelDraw最新图形设计软件 激活安装教程来了
2024年3月,备受瞩目的矢量制图及设计软件——CorelDRAW Graphics Suite 2024 正式面向全球发布。这一重大更新不仅是 CorelDRAW 在 36 年创意服务历史中的又一重要里程碑,同时也展现了其在设计软件领域不断创新和卓越性能的领导地位。 链接: https://pan…...

双网口扩展IO支持8DO输出
M320E以太网远程I/O数据采集模块是一款工业级、隔离设计、高可靠性、高稳定性和高精度数据采集模块,嵌入式32位高性能微处理器MCU,集成2路工业10/100M自适应以太网模块里面。提供多种I/O,支持标准Modbus TCP,可集成到SCADA、OPC服…...
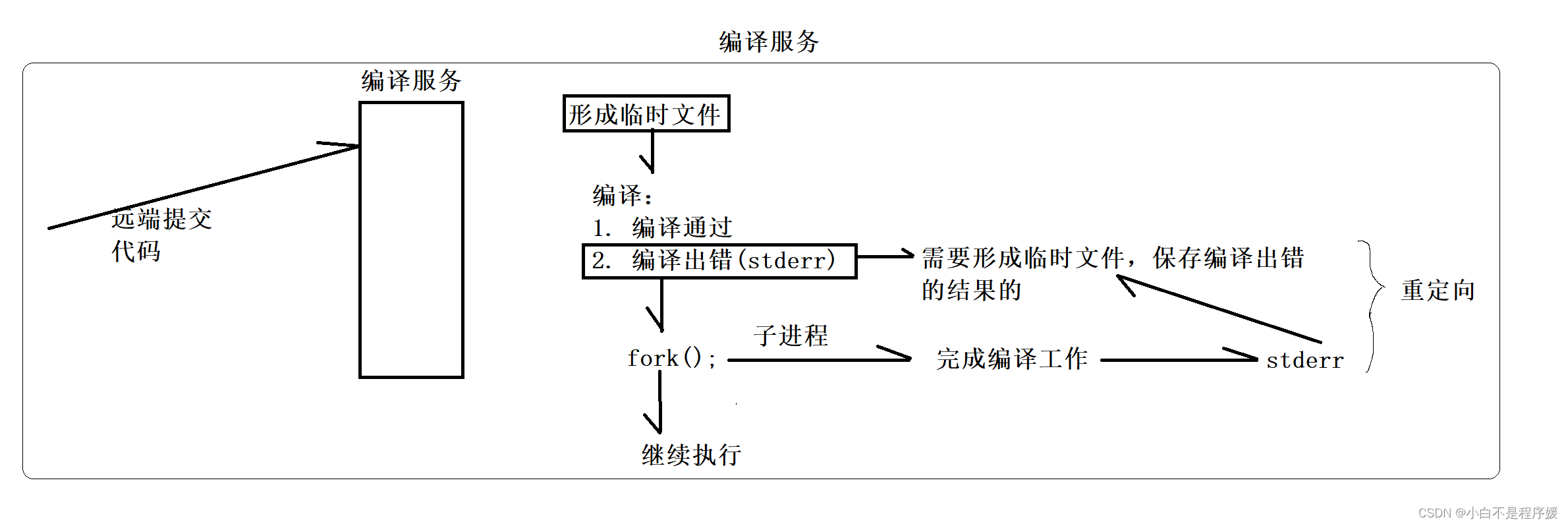
【负载均衡在线OJ项目日记】编译与日志功能开发
目录 日志功能开发 常见的日志等级 日志功能代码 编译功能开发 创建子进程和程序替换 重定向 编译功能代码 日志功能开发 日志在软件开发和运维中起着至关重要的作用,目前我们不谈运维只谈软件开发;日志最大的作用就是用于故障排查和调试&#x…...
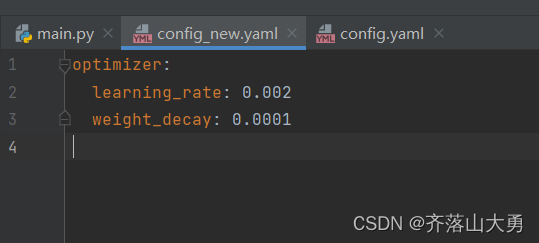
yaml配置文件的在深度学习中的简单应用
1 .创作灵感 小伙伴们再阅读深度学习模型的代码的时候,经常会遇到yaml格式的配置文件。用这个配置文件是因为我们在训练模型的时候会涉及很多的参数,如果这些参数东一个,西一个,我们调起来的时候就会很不方便,所以用y…...

spring boot 核心配置文件是什么?
Spring Boot 的核心配置文件主要是 application.properties 或 application.yml(也称为 YAML 格式)。这两个文件通常位于项目的 src/main/resources 目录下,用于配置 Spring Boot 应用程序的各种属性和设置。 application.properties…...

Python的奇妙之旅——回顾其历史
我们这个神奇的宇宙里,有一个名叫Python的小家伙,它不仅聪明,而且充满活力。它一路走来,从一个小小的编程语言成长为如今全球最受欢迎的编程语言之一。今天,我们就来回顾一下Python的历史,看看它如何从一个…...

Flink面试整理-Flink的性能优化策略
Apache Flink 的性能优化是一个多方面的任务,涉及硬件资源、算法选择、配置调整等多个层面。以下是一些常见的 Flink 性能优化策略: 1. 资源分配和管理 合理配置 TaskManager 和 JobManager:根据作业的需求和可用资源,合理分配内存和 CPU 给 TaskManager 和 JobManager。适…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

排序算法总结(C++)
目录 一、稳定性二、排序算法选择、冒泡、插入排序归并排序随机快速排序堆排序基数排序计数排序 三、总结 一、稳定性 排序算法的稳定性是指:同样大小的样本 **(同样大小的数据)**在排序之后不会改变原始的相对次序。 稳定性对基础类型对象…...