hadoop学习---基于Hive的教育平台数据仓库分析案例(三)
衔接第一部分,第一部分请点击:基于Hive的教育平台数据仓库分析案例(一)
衔接第二部分,第二部分请点击:基于Hive的教育平台数据仓库分析案例(二)

学生出勤模块(全量分析):
需求指标:
需求一: 统计指定时间段内,不同班级的出勤人数。打卡时间在上课前40分钟(否则认为无效)~上课时间点之内,且未早退,则为正常上课打卡。
需求二: 统计指定时间段内,不同班级的学生出勤率。可以下钻到具体学生的出勤数据。出勤率=出勤人数/当日在读学员人数。
需求三: 统计指定时间段内,不同班级的迟到人数。上课10分钟后视为迟到。可以下钻到具体学生的迟到数据。跨天数据直接累加。
需求四: 统计指定时间段内,不同班级的学生迟到率。上课10分钟后视为迟到。可以下钻到具体学生的迟到数据。迟到率=迟到人数/当日在读学员人数。
需求五: 统计指定时间段内,不同班级的请假人数。跨天数据直接累加。
需求六:统计指定时间段内,不同班级的学生请假率。请假率=请假人数/当日在读学员人数。
需求七: 统计指定时间段内,不同班级的旷课人数。跨天数据直接累加。旷课人数=当日在读学员人数-出勤人数-请假人数。
需求八:统计指定时间段内,不同班级的学生旷课率。旷课率=旷课人数/当日在读学员人数。
总体分析:
第一类: 指标: 计算 出勤人数, 出勤率, 迟到人数, 迟到率
涉及维度:
时间维度: 年 月 天 上午 下午 晚自习
班级维度:
学生维度:涉及表:
course_table_upload_detail: 日志课程明细表 (课表) (维度表)
tbh_student_signin_record: 学生打卡记录表 (事实表)
tbh_class_time_table: 班级作息时间表 (维度表)
关联条件:
学生打卡表.class_id = 课程表.class_id
班级作息时间表.id = 学生打卡表.time_table_id涉及到字段:
时间维度: 课程表.class_date
班级维度: 课程表.class_id
学生维度: 学生打卡表.student_id
指标字段: 学生打卡表.signin_time(打卡时间)
计算方案:
先判断是否出勤
情况1: 出勤了, 再次判断是否是正常出勤和迟到出勤
情况2: 未出勤, 认为没有来
指标判断指标:
作息时间表:
morning_begin_time
morning_end_time
afternoon_begin_time
afternoon_end_time
evening_begin_time
evening_end_time过滤操作
1) ifnull(ctud.content,'') != '' 相当于 ctud.content != null and ctud.content != ''
转换为hive的操作
nvl(ctud.content,'') != ''
2) 将content中为开班典礼数据过滤掉
ctud.content != '开班典礼'
3) 确保打卡表中学生数据都是开启公屏
学生打卡表.share_state=1
判断学生出勤状态: 0(正常出勤) 1(迟到出勤) 2(缺勤
首先根据打卡时间, 如果打卡的时间在 上课的前40分钟内 ~ 上课截止时间内
情况1: 出勤了, 接着判断 是否是正常出勤还是迟到出勤,
如果打卡时间在 上课的前40分钟内容 ~ 上课的开始时间后10分内, 认为正常出勤了 返回 0
否则认为迟到出勤 返回 1
情况2: 没有出去, 认为没有来 返回 2
第二类: 指标: 计算 请假人数, 请假率涉及维度:
时间维度: 年 月 天 上午 下午 晚自习
班级维度:涉及表:
student_leave_apply: 学生请假表 (事实表)
tbh_class_time_table: 班级作息时间表 (维度表)
course_table_upload_detail: 课程表 (维度表)表关联条件:
学生请假表.class_id = 班级作息时间表.class_id
学生请假表.class_id = 课程表.class_id涉及字段:
时间维度: 课程表.class_date
班级维度: 课程表.class_id
指标字段: 请假表.student_id
需要进行去重统计操作过滤条件:
课程表:
content 不能为空 为null 以及不能为 开班典礼
获取有效的作息时间:
课程表.class_date between 作息表.use_begin_date and 作息表.use_end_date
学生请假表:保证请假数据有效的
audit_state =1 -- 审核通过
cancel_state = 0 -- 没有取消
valid_state = 1 -- 有效的
判断是否请假条件:
请假的开始时间(请假表.begin_time) <= 上课的开始时间 (morning_begin_time |afternon_begin_time | evening_begin_time)
请假的结束时间(请假表.end_time) >= 上课的开始时间(morning_begin_time |afternon_begin_time | evening_begin_time)
第三类: 计算旷课人数, 旷课率涉及维度:
时间维度: 年 月 天 上午 下午 晚自习
班级维度:
计算标准:
旷课人数 = 当日在读人数 - 出勤人数(正常出勤+迟到出勤) -请假人数
数据准备:
将原始数据加载到本地MySQL数据库中
创建数据库
create database teach default character set utf8mb4 collate utf8mb4_unicode_ci;执行sql文件: 点击下载:学生出勤模块sql文件

表1: 当日在读人数表
表2: 课程日期表
表3: 学生请假表
表4: 班级作息时间表
表5: 学生打卡记录表表6:课程日历表(无用)
建模分析:
ODS层:源数据层
作用: 对接数据源, 一般和数据源的表保持相同粒度
一般存放事实表以及少量的维度表建表方案:
构建两张表 : 学生打卡记录表 和 学生请假表在构建的时候, 需要额外添加一个分区字段: start_time(抽取数据的时间)
DIM层:维度层
作用: 用于存储维度表的数据, 一般和数据源对表保持相同粒度
建表方案:
构建三个表: 课程日期表, 班级作息时间表, 当日在读人数表
在构建的时候, 需要额外添加一个分区字段: start_time(抽取数据的时间)
DWD层:明细层
作用: 1) 清洗转换操作 2) 少量的维度退化操作 (不需要)
清洗转换操作:
可做
1) 日期转换为 年 月 日
2) 过滤无效的请假数据
3) 过滤没有开启公屏的数据如果没有这些操作, 这些操作可放置在别的层,所以此时DWD层 是不需要存在的
DWM层:中间层
作用: 维度退化 以及 提前聚合操作
处理逻辑: 先 分 在 合的操作,先从原始数据库中拆分出多个表,再根据需要聚合
建表方案:
第一个表: 学生出勤状态表
作用: 用于统计每天每个班级, 每个学生的出勤状态(0(正常出勤) 1(迟到出勤) 2(没来))
表字段 :
yearinfo, monthinfo,dayinfo, 班级id, 学生id, 上午出勤, 下午出勤, 晚自习出勤
第二个表: 班级出勤人数表
作用: 用于统计每天每个班级的出勤人数(出勤人数, 迟到出勤人数)
表字段:
yearinfo, monthinfo,dayinfo, 班级id,上午出勤人数, 上午迟到人数, 下午出勤人数, 下午迟到人数, 晚上出勤人数, 晚上迟到人数
第三个表: 班级请假人数表
作用: 用于统计每天每个班级的请假人数
表字段:
yearinfo, monthinfo,dayinfo, 班级id, 上午请假人数, 下午请假人数, 晚上请假人数
第四个表: 班级旷课人数表
作用: 用于统计每天每个班级的旷课人数
表字段:
yearinfo, monthinfo,dayinfo, 班级id, 上午旷课人数, 下午旷课人数, 晚上旷课人数
第五个表: 班级指标汇总表 (提前聚合表)
作用: 用于将前几个表相关的指标数据汇总起来, 同时计算出 相关比率操作 (统计每天的上午 下午 晚自习)
表字段:
yearinfo, monthinfo,dayinfo, 班级id, 班级当日在读人数,
上午出勤人数, 上午出勤率, 下午出勤人数 下午出勤率, 晚上出勤人数, 晚上出勤率
上午迟到人数, 上午迟到率, 下午迟到人数, 下午迟到率, 晚上迟到人数, 晚上迟到率
上午请假人数, 上午请假率, 下午请假人数, 下午请假率, 晚上请假人数, 晚上请假率
上午旷课人数, 上午旷课率, 下午旷课人数, 下午旷课率, 晚上旷课人数, 晚上旷课率
DWS层:业务层
作用: 细化维度统计操作
建表方案:
yearinfo, monthinfo,dayinfo, 班级id, 班级当日在读人数, time_str,time_type
上午出勤人数, 上午出勤率, 下午出勤人数 下午出勤率, 晚上出勤人数, 晚上出勤率
上午迟到人数, 上午迟到率, 下午迟到人数, 下午迟到率, 晚上迟到人数, 晚上迟到率
上午请假人数, 上午请假率, 下午请假人数, 下午请假率, 晚上请假人数, 晚上请假率
上午旷课人数, 上午旷课率, 下午旷课人数, 下午旷课率, 晚上旷课人数, 晚上旷课率
DA层:
根据需要从DWS层直接抽取对应数据
建模操作(建表):
ODS层:(仅存储数据表数据)
学生打卡信息表:
CREATE TABLE IF NOT EXISTS itcast_ods.student_signin_ods (id int,normal_class_flag int comment '是否正课 1 正课 2 自习 3 休息',time_table_id int comment '作息时间id normal_class_flag=2 关联tbh_school_time_table 或者 normal_class_flag=1 关联 tbh_class_time_table',class_id int comment '班级id',student_id int comment '学员id',signin_time String comment '签到时间',signin_date String comment '签到日期',inner_flag int comment '内外网标志 0 外网 1 内网',signin_type int comment '签到类型 1 心跳打卡 2 老师补卡 3 直播打卡',share_state int comment '共享屏幕状态 0 否 1是 在上午或下午段有共屏记录,则该段所有记录该字段为1,内网默认为1 外网默认为0 (暂不用)',inner_ip String comment '内网ip地址',create_time String comment '创建时间')
comment '学生打卡记录表'
PARTITIONED BY (dt STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orcfile
TBLPROPERTIES ('orc.compress'='SNAPPY','orc.bloom.filter.columns'='time_table_id,class_id,signin_date,share_state');学生请假信息表:
CREATE TABLE IF NOT EXISTS itcast_ods.student_leave_apply_ods (id int,class_id int comment '班级id',student_id int comment '学员id',audit_state int comment '审核状态 0 待审核 1 通过 2 不通过',audit_person int comment '审核人',audit_time String comment '审核时间',audit_remark String comment '审核备注',leave_type int comment '请假类型 1 请假 2 销假 (查询是否请假不用过滤此类型,通过有效状态来判断)',leave_reason int comment '请假原因 1 事假 2 病假',begin_time String comment '请假开始时间',begin_time_type int comment '1:上午 2:下午 3:晚自习',end_time String comment '请假结束时间',end_time_type int comment '1:上午 2:下午 3:晚自习',days float comment '请假/已休天数',cancel_state int comment '撤销状态 0 未撤销 1 已撤销',cancel_time String comment '撤销时间',old_leave_id int comment '原请假id,只有leave_type =2 销假的时候才有',leave_remark String comment '请假/销假说明',valid_state int comment '是否有效(0:无效 1:有效)',create_time String comment '创建时间')
comment '学生请假申请表'
PARTITIONED BY (dt STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orcfile
TBLPROPERTIES ('orc.compress'='SNAPPY','orc.bloom.filter.columns'='class_id,audit_state,cancel_state,valid_state');
DIM层:(存储维度表数据)
3张维度表
-- 日期课程表
CREATE TABLE IF NOT EXISTS itcast_dimen.course_table_upload_detail_dimen
(id int comment 'id',base_id int comment '课程主表id',class_id int comment '班级id',class_date STRING comment '上课日期',content STRING comment '课程内容',teacher_id int comment '老师id',teacher_name STRING comment '老师名字',job_number STRING comment '工号',classroom_id int comment '教室id',classroom_name STRING comment '教室名称',is_outline int comment '是否大纲 0 否 1 是',class_mode int comment '上课模式 0 传统全天 1 AB上午 2 AB下午 3 线上直播',is_stage_exam int comment '是否阶段考试(0:否 1:是)',is_pay int comment '代课费(0:无 1:有)',tutor_teacher_id int comment '晚自习辅导老师id',tutor_teacher_name STRING comment '辅导老师姓名',tutor_job_number STRING comment '晚自习辅导老师工号',is_subsidy int comment '晚自习补贴(0:无 1:有)',answer_teacher_id int comment '答疑老师id',answer_teacher_name STRING comment '答疑老师姓名',answer_job_number STRING comment '答疑老师工号',remark STRING comment '备注',create_time STRING comment '创建时间')
comment '班级课表明细表'
PARTITIONED BY (dt STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orcfile
TBLPROPERTIES ('orc.compress'='SNAPPY','orc.bloom.filter.columns'='class_id,class_date');-- 班级作息时间表
CREATE TABLE IF NOT EXISTS itcast_dimen.class_time_dimen (id int,class_id int comment '班级id',morning_template_id int comment '上午出勤模板id',morning_begin_time STRING comment '上午开始时间',morning_end_time STRING comment '上午结束时间',afternoon_template_id int comment '下午出勤模板id',afternoon_begin_time STRING comment '下午开始时间',afternoon_end_time STRING comment '下午结束时间',evening_template_id int comment '晚上出勤模板id',evening_begin_time STRING comment '晚上开始时间',evening_end_time STRING comment '晚上结束时间',use_begin_date STRING comment '使用开始日期',use_end_date STRING comment '使用结束日期',create_time STRING comment '创建时间',create_person int comment '创建人',remark STRING comment '备注')
comment '班级作息时间表'
PARTITIONED BY (dt STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orcfile
TBLPROPERTIES ('orc.compress'='SNAPPY','orc.bloom.filter.columns'='id,class_id');-- 当日在读人数表:
CREATE TABLE IF NOT EXISTS itcast_dimen.class_studying_student_count_dimen (id int,school_id int comment '校区id',subject_id int comment '学科id',class_id int comment '班级id',studying_student_count int comment '在读班级人数',studying_date STRING comment '在读日期')
comment '在读班级的每天在读学员人数'
PARTITIONED BY (dt STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orcfile
TBLPROPERTIES ('orc.compress'='SNAPPY','orc.bloom.filter.columns'='studying_student_count,studying_date');DWD层:
降维操作留到DWM层,此层不需要清洗转换。
DWM层:
-- 学生出勤状态信息表
CREATE TABLE IF NOT EXISTS itcast_dwm.student_attendance_dwm (dateinfo String comment '日期',class_id int comment '班级id',student_id int comment '学员id',morning_att String comment '上午出勤情况:0.正常出勤、1.迟到、2.其他(请假+旷课)',afternoon_att String comment '下午出勤情况:0.正常出勤、1.迟到、2.其他(请假+旷课)',evening_att String comment '晚自习出勤情况:0.正常出勤、1.迟到、2.其他(请假+旷课)')
comment '学生出勤(正常出勤和迟到)数据'
PARTITIONED BY (yearinfo STRING, monthinfo STRING, dayinfo STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orcfile
TBLPROPERTIES ('orc.compress'='SNAPPY');-- 班级出勤人数表:
CREATE TABLE IF NOT EXISTS itcast_dwm.class_attendance_dwm (dateinfo String comment '日期',class_id int comment '班级id',morning_att_count String comment '上午出勤人数',afternoon_att_count String comment '下午出勤人数',evening_att_count String comment '晚自习出勤人数',morning_late_count String comment '上午迟到人数',afternoon_late_count String comment '下午迟到人数',evening_late_count String comment '晚自习迟到人数')
comment '学生出勤(正常出勤和迟到)数据'
PARTITIONED BY (yearinfo STRING, monthinfo STRING, dayinfo STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orcfile
TBLPROPERTIES ('orc.compress'='SNAPPY');-- 班级请假人数表
CREATE TABLE IF NOT EXISTS itcast_dwm.class_leave_dwm (dateinfo String comment '日期',class_id int comment '班级id',morning_leave_count String comment '上午请假人数',afternoon_leave_count String comment '下午请假人数',evening_leave_count String comment '晚自习请假人数')
comment '班级请假数据统计'
PARTITIONED BY (yearinfo STRING, monthinfo STRING, dayinfo STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orcfile
TBLPROPERTIES ('orc.compress'='SNAPPY');-- 班级旷课人数表
CREATE TABLE IF NOT EXISTS itcast_dwm.class_truant_dwm (dateinfo String comment '日期',class_id int comment '班级id',morning_truant_count String comment '上午旷课人数',afternoon_truant_count String comment '下午旷课人数',evening_truant_count String comment '晚自习旷课人数')
comment '班级请假数据统计'
PARTITIONED BY (yearinfo STRING, monthinfo STRING, dayinfo STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orcfile
TBLPROPERTIES ('orc.compress'='SNAPPY');-- 汇总表CREATE TABLE IF NOT EXISTS itcast_dwm.class_all_dwm (dateinfo String comment '日期',class_id int comment '班级id',studying_student_count int comment '在读班级人数',morning_att_count String comment '上午出勤人数',morning_att_ratio String comment '上午出勤率',afternoon_att_count String comment '下午出勤人数',afternoon_att_ratio String comment '下午出勤率',evening_att_count String comment '晚自习出勤人数',evening_att_ratio String comment '晚自习出勤率',morning_late_count String comment '上午迟到人数',morning_late_ratio String comment '上午迟到率',afternoon_late_count String comment '下午迟到人数',afternoon_late_ratio String comment '下午迟到率',evening_late_count String comment '晚自习迟到人数',evening_late_ratio String comment '晚自习迟到率',morning_leave_count String comment '上午请假人数',morning_leave_ratio String comment '上午请假率',afternoon_leave_count String comment '下午请假人数',afternoon_leave_ratio String comment '下午请假率',evening_leave_count String comment '晚自习请假人数',evening_leave_ratio String comment '晚自习请假率',morning_truant_count String comment '上午旷课人数',morning_truant_ratio String comment '上午旷课率',afternoon_truant_count String comment '下午旷课人数',afternoon_truant_ratio String comment '下午旷课率',evening_truant_count String comment '晚自习旷课人数',evening_truant_ratio String comment '晚自习旷课率')
comment '班级请假数据统计'
PARTITIONED BY (yearinfo STRING, monthinfo STRING, dayinfo STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orcfile
TBLPROPERTIES ('orc.compress'='SNAPPY');
DWS层:
CREATE TABLE IF NOT EXISTS itcast_dws.class_attendance_dws (dateinfo String comment '日期',class_id int comment '班级id',studying_student_count int comment '在读班级人数',morning_att_count String comment '上午出勤人数',morning_att_ratio String comment '上午出勤率',afternoon_att_count String comment '下午出勤人数',afternoon_att_ratio String comment '下午出勤率',evening_att_count String comment '晚自习出勤人数',evening_att_ratio String comment '晚自习出勤率',morning_late_count String comment '上午迟到人数',morning_late_ratio String comment '上午迟到率',afternoon_late_count String comment '下午迟到人数',afternoon_late_ratio String comment '下午迟到率',evening_late_count String comment '晚自习迟到人数',evening_late_ratio String comment '晚自习迟到率',morning_leave_count String comment '上午请假人数',morning_leave_ratio String comment '上午请假率',afternoon_leave_count String comment '下午请假人数',afternoon_leave_ratio String comment '下午请假率',evening_leave_count String comment '晚自习请假人数',evening_leave_ratio String comment '晚自习请假率',morning_truant_count String comment '上午旷课人数',morning_truant_ratio String comment '上午旷课率',afternoon_truant_count String comment '下午旷课人数',afternoon_truant_ratio String comment '下午旷课率',evening_truant_count String comment '晚自习旷课人数',evening_truant_ratio String comment '晚自习旷课率',time_type STRING COMMENT '聚合时间类型:1、按小时聚合;2、按天聚合;3、按周聚合;4、按月聚合;5、按年聚合。')
comment '班级请假数据统计'
PARTITIONED BY (yearinfo STRING, monthinfo STRING, dayinfo STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orcfile
TBLPROPERTIES ('orc.compress'='SNAPPY');数据采集:
数据: 目前存储在MySQL中
目的地: 放置hive中
技术: 采用 apache sqoop 来解决
DIM层:
# 当日在读人数表
sqoop import \
--connect jdbc:mysql://192.168.52.150:3306/teach \
--username root \
--password 123456 \
--query 'select *,"2021-10-07" as dt from class_studying_student_count where 1=1 and $CONDITIONS' \
--hcatalog-database itcast_dimen \
--hcatalog-table class_studying_student_count_dimen \
-m 1# 日期课程表
sqoop import \
--connect jdbc:mysql://192.168.52.150:3306/teach \
--username root \
--password 123456 \
--query 'select *,"2021-10-07" as dt from course_table_upload_detail where 1=1 and $CONDITIONS' \
--hcatalog-database itcast_dimen \
--hcatalog-table course_table_upload_detail_dimen \
-m 1# 作息时间表
sqoop import \
--connect jdbc:mysql://192.168.52.150:3306/teach \
--username root \
--password 123456 \
--query 'select *,"2021-10-07" as dt from tbh_class_time_table where 1=1 and $CONDITIONS' \
--hcatalog-database itcast_dimen \
--hcatalog-table class_time_dimen \
-m 1ODS层:
# 学生打卡记录表sqoop import \
--connect jdbc:mysql://192.168.52.150:3306/teach \
--username root \
--password 123456 \
--query 'select *,"2021-10-07" as dt from tbh_student_signin_record where 1=1 and $CONDITIONS' \
--hcatalog-database itcast_ods \
--hcatalog-table student_signin_ods \
-m 1# 学生请假信息表sqoop import \
--connect jdbc:mysql://192.168.52.150:3306/teach \
--username root \
--password 123456 \
--query 'select *,"2021-10-07" as dt from student_leave_apply where 1=1 and $CONDITIONS' \
--hcatalog-database itcast_ods \
--hcatalog-table student_leave_apply_ods \
-m 1数据清洗转换:
目的: 主要是用于从ODS以及DIM层 将数据灌入到DWM层操作
生成DWD层数据:
------------DWD层不需要,降维操作留到DWM层
生成DWM层数据:
由于DWM层的字段是来源于事实表和所有维度表中的字段, 此时如果生成DWM层数据, 必须要先将所有的表关联在一起,七表关联数据庞大,要开启各种优化。
学生出勤状态信息表
先把表与表之间的关联条件,过滤条件,字段依次实现
基本逻辑:
select
ctudd.class_date,
ctudd.class_id,
student_id,
'' as morning_att, --未实现
'' as afternoon_att, --未实现
'' as evening_att, --未实现
substr(ctudd.class_date,1,4) as yearinfo,
substr(ctudd.class_date,6,2) as monthinfo,
substr(ctudd.class_date,9,2) as dayinfo
from (select * from itcast_dimen.course_table_upload_detail_dimen where nvl(content,'')!='' and content !='开班典礼') ctudd
left join (select * from itcast_ods.student_signin_ods where share_state = 1) sso on sso.class_id = ctudd.class_id
left join itcast_dimen.class_time_dimen ctd on ctd.id = sso.time_table_id
group by ctudd.class_date , ctudd.class_id,sso.student_id;
如何判断学生出勤状态呢? ----先判断是否出勤,再判断是否迟到。
基于学生的打卡时间 以上午为例
如果学生的打卡时间 在 上午上课开始时间前40分钟内 ~~ 上午上课截止时间内
认为 学生出勤了
此时接着判断, 如何学生的打卡时间在 上午上课开始时间前40分钟内容 ~~ 上午上课开始时间后10分钟内
认为 学生是正常出勤 返回 0
否则 认为学生是迟到出勤 返回 1
否则认为学生没有出勤, 直接返回 2
伪代码:不能运行,逻辑推敲

如何实现日期的 相加 和 相减 (对分钟处理) ?
在hive中, 并没有发现可以对分钟加减的函数, 只有对天的加减函数, 但是不符合要求, 如何解决呢?
可以尝试将日期数据转换为时间戳, 然后对时间戳进行加减处理 即可解决问题,时间戳以秒为单位转换
select unix_timestamp('2021-10-08 15:40:30','yyyy-MM-dd HH:mm:ss') - 40*60;
发现: 作息时间表的 上课时间内容, 只有 时 分 秒 没有 年 月 日,可以将上课日期时间加入。

Hive的各种优化开启
最后代码实现:数据量太大,只抽取三天:
set hive.auto.convert.join=false;--分区
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=10000;
set hive.exec.max.dynamic.partitions=100000;
set hive.exec.max.created.files=150000;
--hive压缩
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
--写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
--分桶
--set hive.enforce.bucketing=true;
--set hive.enforce.sorting=true;
--set hive.optimize.bucketmapjoin = true;
--set hive.auto.convert.sortmerge.join=true;
--set hive.auto.convert.sortmerge.join.noconditionaltask=true;
--并行执行
set hive.exec.parallel=true;
set hive.exec.parallel.thread.number=8;
--小文件合并
-- set mapred.max.split.size=2147483648;
-- set mapred.min.split.size.per.node=1000000000;
-- set mapred.min.split.size.per.rack=1000000000;
--矢量化查询
set hive.vectorized.execution.enabled=true;
--关联优化器
set hive.optimize.correlation=true;
--读取零拷贝
set hive.exec.orc.zerocopy=true;
--join数据倾斜
set hive.optimize.skewjoin=true;
-- set hive.skewjoin.key=100000;
set hive.optimize.skewjoin.compiletime=true;
set hive.optimize.union.remove=true;
-- group倾斜
set hive.groupby.skewindata=true;insert into table itcast_dwm.student_attendance_dwm partition(yearinfo,monthinfo,dayinfo)
select ctudd.class_date,ctudd.class_id,student_id,if(sum(if( unix_timestamp(sso.signin_time,'yyyy-MM-dd HH:mm:ss')between unix_timestamp(concat(ctudd.class_date,' ',ctd.morning_begin_time),'yyyy-MM-dd HH:mm:ss') - 40*60 and unix_timestamp(concat(ctudd.class_date,' ',ctd.morning_end_time),'yyyy-MM-dd HH:mm:ss'),1,0)) > 0, -- 如果大于0 认为当天的打卡记录中, 一定是有出勤的打卡记录, 如果小于等于0 认为没有出勤if(sum(if(unix_timestamp(sso.signin_time,'yyyy-MM-dd HH:mm:ss') between unix_timestamp(concat(ctudd.class_date,' ',ctd.morning_begin_time),'yyyy-MM-dd HH:mm:ss') - 40*60 and unix_timestamp(concat(ctudd.class_date,' ',ctd.morning_begin_time),'yyyy-MM-dd HH:mm:ss') + 10*60, 1 , 0)) >0, -- 如果大于0, 认为当天打卡记录中, 一定是有正常出勤的记录, 否则认为迟到出勤0,1),2)as morning_att, if(sum(if( unix_timestamp(sso.signin_time,'yyyy-MM-dd HH:mm:ss')between unix_timestamp(concat(ctudd.class_date,' ',ctd.afternoon_begin_time),'yyyy-MM-dd HH:mm:ss') - 40*60 and unix_timestamp(concat(ctudd.class_date,' ',ctd.afternoon_end_time),'yyyy-MM-dd HH:mm:ss'),1,0)) > 0, -- 如果大于0 认为当天的打卡记录中, 一定是有出勤的打卡记录, 如果小于等于0 认为没有出勤if(sum(if(unix_timestamp(sso.signin_time,'yyyy-MM-dd HH:mm:ss') between unix_timestamp(concat(ctudd.class_date,' ',ctd.afternoon_begin_time),'yyyy-MM-dd HH:mm:ss') - 40*60 and unix_timestamp(concat(ctudd.class_date,' ',ctd.afternoon_begin_time),'yyyy-MM-dd HH:mm:ss') + 10*60, 1 , 0)) >0, -- 如果大于0, 认为当天打卡记录中, 一定是有正常出勤的记录, 否则认为迟到出勤0,1),2) as afternoon_att, if(sum(if( unix_timestamp(sso.signin_time,'yyyy-MM-dd HH:mm:ss')between unix_timestamp(concat(ctudd.class_date,' ',ctd.evening_begin_time),'yyyy-MM-dd HH:mm:ss') - 40*60 and unix_timestamp(concat(ctudd.class_date,' ',ctd.evening_end_time),'yyyy-MM-dd HH:mm:ss'),1,0)) > 0, -- 如果大于0 认为当天的打卡记录中, 一定是有出勤的打卡记录, 如果小于等于0 认为没有出勤if(sum(if(unix_timestamp(sso.signin_time,'yyyy-MM-dd HH:mm:ss') between unix_timestamp(concat(ctudd.class_date,' ',ctd.evening_begin_time),'yyyy-MM-dd HH:mm:ss') - 40*60 and unix_timestamp(concat(ctudd.class_date,' ',ctd.evening_begin_time),'yyyy-MM-dd HH:mm:ss') + 10*60, 1 , 0)) >0, -- 如果大于0, 认为当天打卡记录中, 一定是有正常出勤的记录, 否则认为迟到出勤0,1),2) as evening_att, --未实现substr(ctudd.class_date,1,4) as yearinfo,substr(ctudd.class_date,6,2) as monthinfo,substr(ctudd.class_date,9,2) as dayinfo
from (select * from itcast_dimen.course_table_upload_detail_dimen where nvl(content,'')!='' and content !='开班典礼') ctuddleft join (select * from itcast_ods.student_signin_ods where share_state = 1) sso on sso.class_id = ctudd.class_idleft join itcast_dimen.class_time_dimen ctd on ctd.id = sso.time_table_id
where ctudd.class_date in ('2019-09-03','2019-09-04','2019-09-05')
group by ctudd.class_date , ctudd.class_id,sso.student_id;班级出勤人数表
insert into table itcast_dwm.class_attendance_dwm partition(yearinfo,monthinfo,dayinfo)
select dateinfo,class_id,count(case when morning_att in ('0','1') then student_idelse null end) as morning_att_count,count(case when afternoon_att in ('0','1') then student_idelse null end) as afternoon_att_count,count(case when evening_att in ('0','1') then student_idelse null end) as evening_att_count,sum(case when morning_att ='1' then 1else 0 end) as morning_late_count,sum(case when afternoon_att ='1' then 1else 0 end) as afternoon_late_count,sum(case when evening_att ='1' then 1else 0 end) as evening_late_count,yearinfo,monthinfo,dayinfo
from itcast_dwm.student_attendance_dwm
group by dateinfo,yearinfo,monthinfo,dayinfo,class_id;班级请假人数表
计算上午的每天各个班级请假人数:
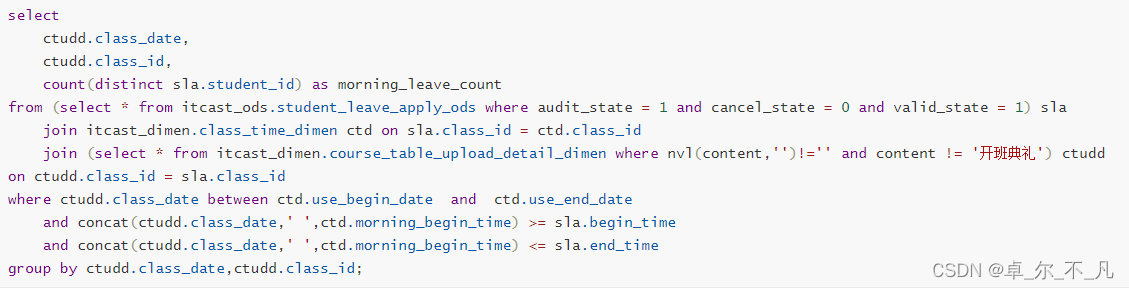
计算中午的每天各个班级请假人数:
计算晚上的每天各个班级请假人数:
最后的总表应该合并上面三个表的数据,汇总每个班的早中晚的请假总人数:全外连接

先 分 后 拆 :从A、B、C表中聚合成temp表,再group by字段组成新表。
set hive.auto.convert.join=false;--分区
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=10000;
set hive.exec.max.dynamic.partitions=100000;
set hive.exec.max.created.files=150000;
--hive压缩
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
--写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
--分桶
--set hive.enforce.bucketing=true;
--set hive.enforce.sorting=true;
--set hive.optimize.bucketmapjoin = true;
--set hive.auto.convert.sortmerge.join=true;
--set hive.auto.convert.sortmerge.join.noconditionaltask=true;
--并行执行
set hive.exec.parallel=true;
set hive.exec.parallel.thread.number=8;
--小文件合并
-- set mapred.max.split.size=2147483648;
-- set mapred.min.split.size.per.node=1000000000;
-- set mapred.min.split.size.per.rack=1000000000;
--矢量化查询
set hive.vectorized.execution.enabled=true;
--关联优化器
set hive.optimize.correlation=true;
--读取零拷贝
set hive.exec.orc.zerocopy=true;
--join数据倾斜
set hive.optimize.skewjoin=false;
-- set hive.skewjoin.key=100000;
set hive.optimize.skewjoin.compiletime=false;
set hive.optimize.union.remove=false;
-- group倾斜
set hive.groupby.skewindata=false;with A as (selectctudd.class_date,ctudd.class_id,count(distinct sla.student_id) as morning_leave_count
from (select * from itcast_ods.student_leave_apply_ods where audit_state = 1 and cancel_state = 0 and valid_state = 1) slajoin itcast_dimen.class_time_dimen ctd on sla.class_id = ctd.class_idjoin (select * from itcast_dimen.course_table_upload_detail_dimen where nvl(content,'')!='' and content != '开班典礼') ctudd on ctudd.class_id = sla.class_id
where ctudd.class_date between ctd.use_begin_date and ctd.use_end_date and concat(ctudd.class_date,' ',ctd.morning_begin_time) >= sla.begin_timeand concat(ctudd.class_date,' ',ctd.morning_begin_time) <= sla.end_time
group by ctudd.class_date,ctudd.class_id),B AS (selectctudd.class_date,ctudd.class_id,count(distinct sla.student_id) as afternoon_leave_count
from (select * from itcast_ods.student_leave_apply_ods where audit_state = 1 and cancel_state = 0 and valid_state = 1) slajoin itcast_dimen.class_time_dimen ctd on sla.class_id = ctd.class_idjoin (select * from itcast_dimen.course_table_upload_detail_dimen where nvl(content,'')!='' and content != '开班典礼') ctudd on ctudd.class_id = sla.class_id
where ctudd.class_date between ctd.use_begin_date and ctd.use_end_date and concat(ctudd.class_date,' ',ctd.afternoon_begin_time) >= sla.begin_timeand concat(ctudd.class_date,' ',ctd.afternoon_begin_time) <= sla.end_time
group by ctudd.class_date,ctudd.class_id),C AS (selectctudd.class_date,ctudd.class_id,count(distinct sla.student_id) as evening_leave_count
from (select * from itcast_ods.student_leave_apply_ods where audit_state = 1 and cancel_state = 0 and valid_state = 1) slajoin itcast_dimen.class_time_dimen ctd on sla.class_id = ctd.class_idjoin (select * from itcast_dimen.course_table_upload_detail_dimen where nvl(content,'')!='' and content != '开班典礼') ctudd on ctudd.class_id = sla.class_id
where ctudd.class_date between ctd.use_begin_date and ctd.use_end_date and concat(ctudd.class_date,' ',ctd.evening_begin_time) >= sla.begin_timeand concat(ctudd.class_date,' ',ctd.evening_begin_time) <= sla.end_time
group by ctudd.class_date,ctudd.class_id),
temp as (select coalesce(A.class_date,B.class_date,C.class_date) AS class_date,coalesce(A.class_id,B.class_id,C.class_id) AS class_id,nvl(A.morning_leave_count,0) as morning_leave_count,nvl(B.afternoon_leave_count,0) as afternoon_leave_count,nvl(C.evening_leave_count,0) as evening_leave_count
from A full join B on A.class_date = B.class_date and A.class_id = B.class_idfull join C on A.class_date = C.class_date and A.class_id = C.class_id)
insert into table itcast_dwm.class_leave_dwm partition(yearinfo,monthinfo,dayinfo)
select class_date,class_id,sum(morning_leave_count) as morning_leave_count,sum(afternoon_leave_count) as afternoon_leave_count,sum(evening_leave_count) as evening_leave_count,substr(class_date,1,4) as yearinfo,substr(class_date,6,2) as monthinfo,substr(class_date,9,2) as dayinfo
from temp group by class_date,class_id;旷课人数表
计算规则:
旷课人数 = 当日在读人数 - 出勤人数 - 请假人数
insert into table itcast_dwm.class_truant_dwm partition(yearinfo,monthinfo,dayinfo)
select ctudd.class_date as dateinfo,ctudd.class_id,cssc.studying_student_count - nvl(cad.morning_att_count,0) - nvl(cld.morning_leave_count,0) as morning_truant_count,cssc.studying_student_count - nvl(cad.afternoon_att_count,0) - nvl(cld.afternoon_leave_count,0) as afternoon_truant_count,cssc.studying_student_count - nvl(cad.evening_att_count,0) - nvl(cld.evening_leave_count,0) as evening_truant_count,substr(ctudd.class_date,1,4) as yearinfo,substr(ctudd.class_date,6,2) as monthinfo,substr(ctudd.class_date,9,2) as dayinfo
from (select * from itcast_dimen.course_table_upload_detail_dimen where nvl(content,'')!='' and content != '开班典礼') ctudd left join itcast_dimen.class_studying_student_count_dimen cssc on ctudd.class_date = cssc.studying_date and ctudd.class_id = cssc.class_idleft join itcast_dwm.class_attendance_dwm cad on ctudd.class_id = cad.class_id and ctudd.class_date = cad.dateinfoleft join itcast_dwm.class_leave_dwm cld on ctudd.class_id = cld.class_id and ctudd.class_date = cld.dateinfo
where ctudd.class_date in('2019-09-03','2019-09-04','2019-09-05')汇总表:
insert into table itcast_dwm.class_all_dwm partition(yearinfo,monthinfo,dayinfo)
selectctudd.class_date as dateinfo,ctudd.class_id,cssc.studying_student_count,cad.morning_att_count,concat(round(nvl(cad.morning_att_count,0) / cssc.studying_student_count * 100,2),'%') as morning_att_ratio,cad.afternoon_att_count,concat(round(nvl(cad.afternoon_att_count,0) / cssc.studying_student_count * 100,2),'%') as afternoon_att_ratio,cad.evening_att_count,concat(round(nvl(cad.evening_att_count,0) / cssc.studying_student_count * 100,2),'%') as evening_att_ratio,cad.morning_late_count,concat(round(nvl(cad.morning_late_count,0) / cssc.studying_student_count * 100,2),'%') as morning_late_ratio,cad.afternoon_late_count,concat(round(nvl(cad.afternoon_late_count,0) / cssc.studying_student_count * 100,2),'%') as afternoon_late_ratio,cad.evening_late_count,concat(round(nvl(cad.evening_late_count,0) / cssc.studying_student_count * 100,2),'%') as evening_late_ratio,cld.morning_leave_count,concat(round(nvl(cld.morning_leave_count,0) / cssc.studying_student_count * 100,2),'%') as morning_leave_ratio,cld.afternoon_leave_count,concat(round(nvl(cld.afternoon_leave_count,0) / cssc.studying_student_count * 100,2),'%') as afternoon_leave_ratio,cld.evening_leave_count,concat(round(nvl(cld.evening_leave_count,0) / cssc.studying_student_count * 100,2),'%') as evening_leave_ratio,ctd.morning_truant_count,concat(round(nvl(ctd.morning_truant_count,0) / cssc.studying_student_count * 100,2),'%') as morning_truant_ratio,ctd.afternoon_truant_count,concat(round(nvl(ctd.afternoon_truant_count,0) / cssc.studying_student_count * 100,2),'%') as afternoon_truant_ratio,ctd.evening_truant_count,concat(round(nvl(ctd.evening_truant_count,0) / cssc.studying_student_count * 100,2),'%') as evening_truant_ratio,substr(ctudd.class_date,1,4) as yearinfo,substr(ctudd.class_date,6,2) as monthinfo,substr(ctudd.class_date,9,2) as dayinfofrom (select * from itcast_dimen.course_table_upload_detail_dimen where nvl(content,'')!='' and content != '开班典礼') ctuddleft join itcast_dimen.class_studying_student_count_dimen cssc on cssc.class_id = ctudd.class_id and cssc.studying_date = ctudd.class_dateleft join itcast_dwm.class_attendance_dwm cad on ctudd.class_id = cad.class_id and ctudd.class_date = cad.dateinfoleft join itcast_dwm.class_leave_dwm cld on ctudd.class_id = cld.class_id and ctudd.class_date = cld.dateinfoleft join itcast_dwm.class_truant_dwm ctd on ctudd.class_id = ctd.class_id and ctudd.class_date = ctd.dateinfo
where ctudd.class_date in ('2019-09-03','2019-09-04','2019-09-05');数据分析:DWS
DWS: 细化维度统计操作
需求一: 统计每年 每月 每天 上午, 下午, 晚自习 各个班级的 相关的指标 (指的DWM层的汇总表数据),建议直接抽取存储即可
需求二: 统计每年 每月 上午, 下午, 晚自习 各个班级的 相关的指标
需求三: 统计每年 上午, 下午, 晚自习 各个班级的 相关的指标
需求二: 统计每年 每月 上午, 下午, 晚自习 各个班级的 相关的指标:
insert into table itcast_dws.class_attendance_dws partition(yearinfo,monthinfo,dayinfo)
select concat(yearinfo,'-',monthinfo) as dateinfo,class_id,sum(studying_student_count) as studying_student_count,sum(morning_att_count) as morning_att_count,concat(round(sum(morning_att_count) / sum(studying_student_count) *100,2),'%') as morning_att_ratio,sum(afternoon_att_count) as afternoon_att_count,concat(round(sum(afternoon_att_count) / sum(studying_student_count) *100,2),'%') as afternoon_att_ratio,sum(evening_att_count) as evening_att_count,concat(round(sum(evening_att_count) / sum(studying_student_count) *100,2),'%') as evening_att_ratio,sum(morning_late_count) as morning_late_count,concat(round(sum(morning_late_count) / sum(studying_student_count) *100,2),'%') as morning_late_ratio,sum(afternoon_late_count) as afternoon_late_count,concat(round(sum(afternoon_late_count) / sum(studying_student_count) *100,2),'%') as afternoon_late_ratio,sum(evening_late_count) as evening_late_count,concat(round(sum(evening_late_count) / sum(studying_student_count) *100,2),'%') as evening_late_ratio,sum(morning_leave_count) as morning_leave_count,concat(round(sum(morning_leave_count) / sum(studying_student_count) *100,2),'%') as morning_leave_ratio,sum(afternoon_leave_count) as afternoon_leave_count,concat(round(sum(afternoon_leave_count) / sum(studying_student_count) *100,2),'%') as afternoon_leave_ratio,sum(evening_leave_count) as evening_leave_count,concat(round(sum(evening_leave_count) / sum(studying_student_count) *100,2),'%') as evening_leave_ratio,sum(morning_truant_count) as morning_truant_count,concat(round(sum(morning_truant_count) / sum(studying_student_count) *100,2),'%') as morning_truant_ratio,sum(afternoon_truant_count) as afternoon_truant_count,concat(round(sum(afternoon_truant_count) / sum(studying_student_count) *100,2),'%') as afternoon_truant_ratio,sum(evening_truant_count) as evening_truant_count,concat(round(sum(evening_truant_count) / sum(studying_student_count) *100,2),'%') as evening_truant_ratio,'4' as time_type,yearinfo,monthinfo,'-1' as dayinfofrom itcast_dwm.class_all_dwm
group by yearinfo,monthinfo,class_id;数据导出:
类比第一第二模块……
数据可视化
商业BI系统
商业BI系统的概念:
商业智能系统,通常简称为商业智能系统,是商业智能软件的简称,是为提高企业经营绩效而采用的一系列方法、技术和软件的总和。通常被理解为将企业中的现有数据转换为知识并帮助企业做出明智的业务决策的工具。(数据仓库+数据挖掘+可视化)
商业BI系统的数据来源:
BI系统中的数据来自企业的其他业务系统。例如,一个面向业务的企业,其业务智能系统数据包括业务系统订单、库存、交易账户、客户和供应商信息,以及企业所属行业和竞争对手的数据,以及其他外部环境数据。这些数据可能来自于CRM、SCM和发票等业务系统。
商业BI系统的功能:
首先,需要收集所有的数据。这个过程称为“数据仓库”。数据仓库提供了一个数据存储环境,从多个数据源获取的数据根据特定的主题进行ETL(提取、转换、转储)数据、清理数据和存储。
其次,需要数据分析来辅助企业建模的能力。OLAP是一种基于数据仓库环境的数据分析工具。OLAP解决了基于OLTP分析的多维度分析效率低的缺点。在实际应用中,数据挖掘也常用来挖掘过去和预测未来。它是一个使用知识发现工具来挖掘以前未知的和潜在有用的知识的过程。它是一种主动的自动发现方法。
商业智能的一个重要特性是数据可视化。数据可视化是指通过适当的图表类型以一种视觉上吸引人的方式显示信息,使每个人都能更快更好地理解数据。另外,BI还有终端信息查询和报表生成功能。
到这里,所有的流程就被称为“BI系统”。
离线静态可视化图表:
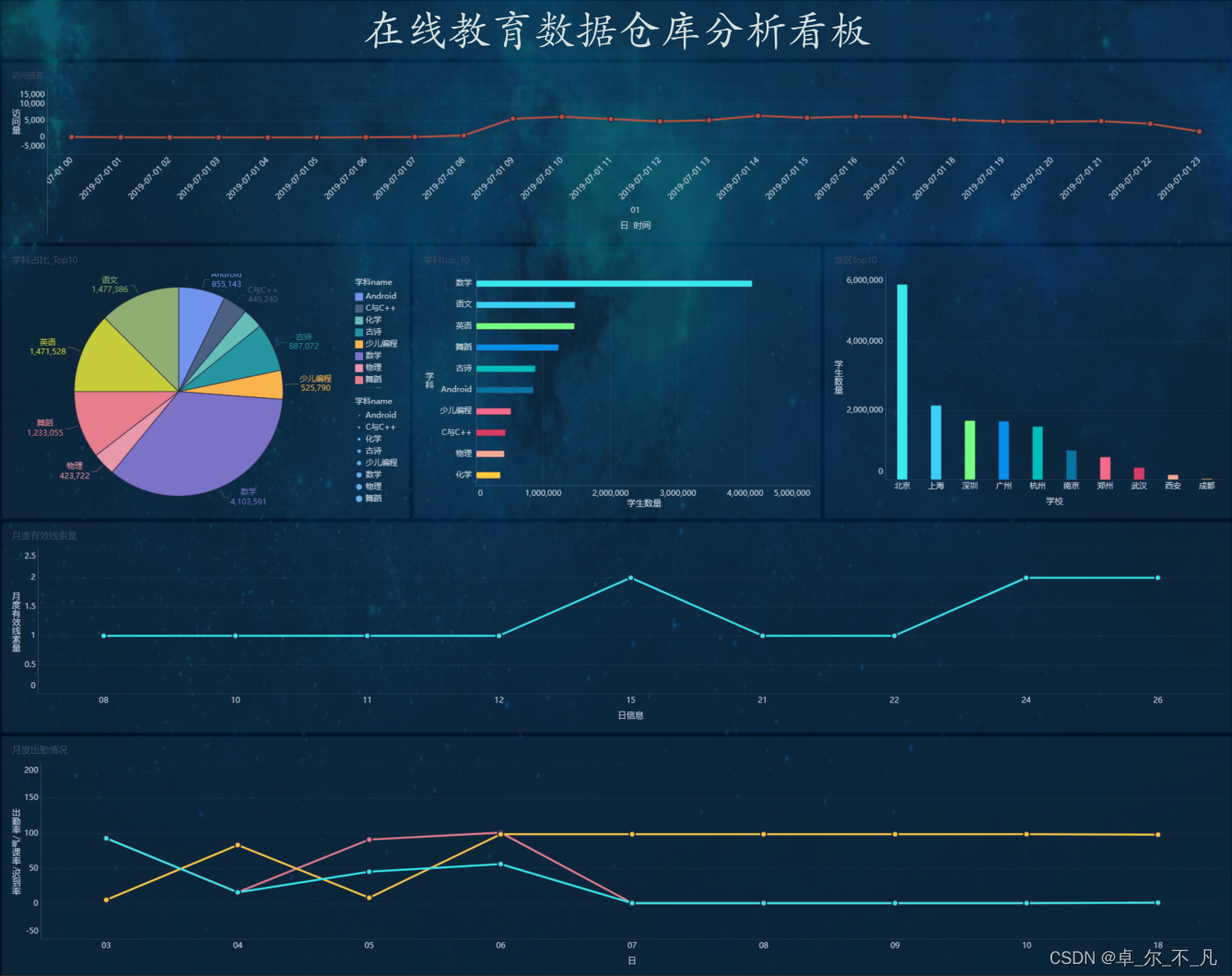
相关文章:
hadoop学习---基于Hive的教育平台数据仓库分析案例(三)
衔接第一部分,第一部分请点击:基于Hive的教育平台数据仓库分析案例(一) 衔接第二部分,第二部分请点击:基于Hive的教育平台数据仓库分析案例(二) 学生出勤模块(全量分析):…...

RAFT:引领 Llama 在 RAG 中发展
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
上海亚商投顾:沪指缩量调整 合成生物概念股持续爆发
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 沪指昨日缩量震荡调整,深成指、创业板指均跌超1%。细胞免疫治疗概念股大涨,冠昊生物、…...

Maven+Junit5 + Allure +Jenkins 搭建 UI 自动化测试实战
文章目录 效果展示Junit 5Junit 5 介绍Junit 5 与 Junit 4 对比PageFactory 模式编写自动化代码公共方法提取测试用例参数化Jenkins 搭建及配置参数化执行生成 Allure 报告Maven 常用命令介绍POM 文件效果展示 本 chat 介绍 UI 自动化测试框架的搭建: 运用 page factory 模式…...
docker学习笔记(三)搭建NFS服务实验
目录 什么是NFS 简单架构编辑 一.搭建nfs服务器 二.新建共享目录和网页文件 三.设置共享目录 四:创建使用nfs共享目录的卷 五:创建容器使用nfs-web-1卷 六:测试访问 七:是否同步测试 什么是NFS NFS 服务器:ne…...

super关键字
super关键字 在Java中,super是一个关键字,它用于引用当前对象的父类。在继承的关系中,子类可以通过super关键字来调用父类的构造方法、成员方法和成员变量。 super关键字的主要用途 调用父类的构造方法: 在子类的构造方法中&…...
)
【经典算法】LeetCode 200. 岛屿数量(Java/C/Python3/Go实现含注释说明,中等)
目录 题目描述思路及实现方式一:深度优先搜索(DFS)思路代码实现Java版本C语言版本Python3版本Golang版本 复杂度分析 方式二: 使用广度优先搜索(BFS)思路代码实现Java实现C实现Python3实现Go实现 总结相似题…...
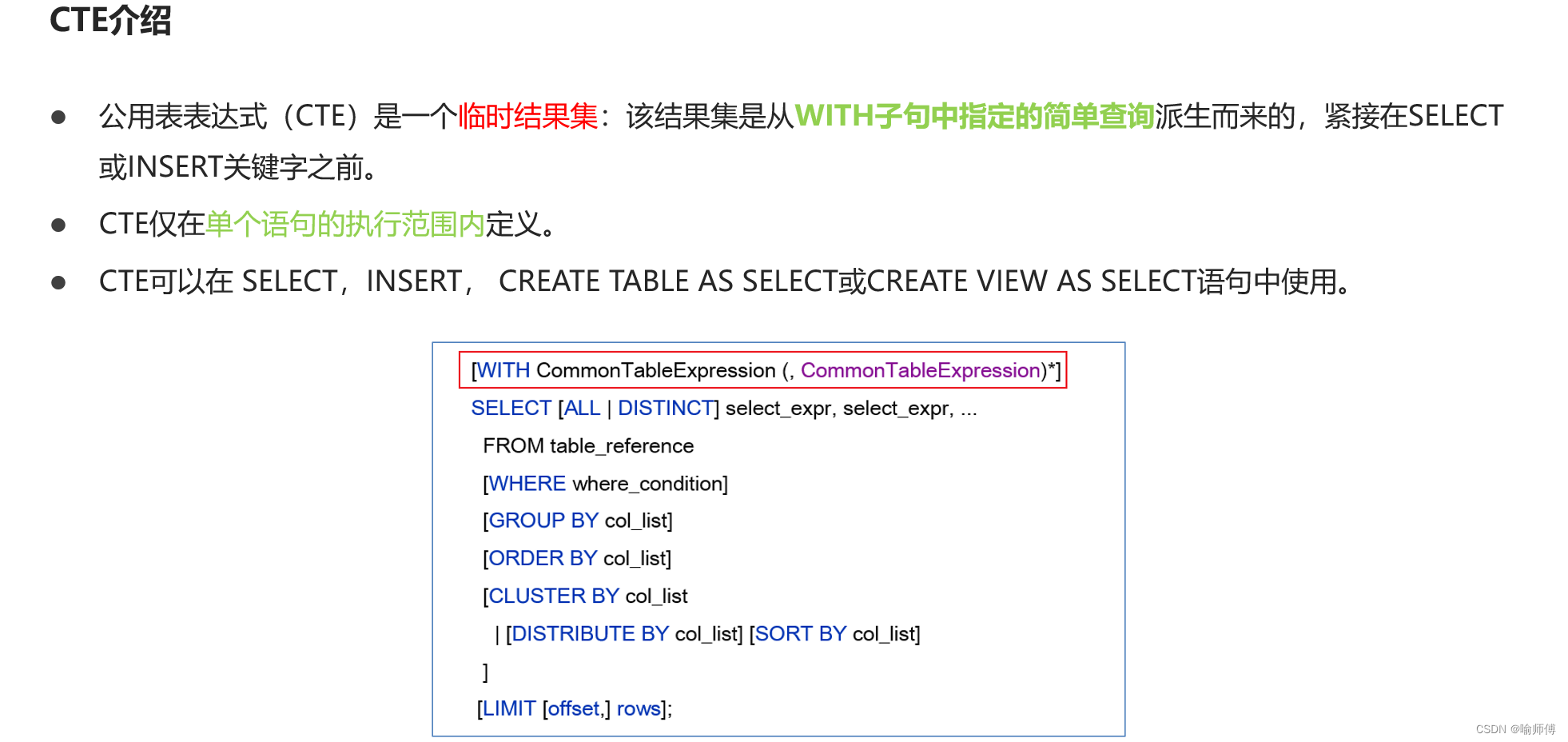
Hive SQL-DQL-Select查询语句用法详解
HQL Select用法详解 1.基础语法 (1)select_exp (2)ALL、DISTINCT (3)WHERE (4)分区查询、分区裁剪 (5)GROUP BY (6)HAVING ࿰…...
沙盘Sandboxie v5.56.4
菜鸟高手裸奔工具沙盘Sandboxie是一款国外著名的系统安全工具,它可以让选定程序在安全的隔离环境下运行, 只要在此环境中运行的软件,浏览器或注册表信息等都可以完整的进行清空,不留一点痕迹。同时可以防御些 带有木马或者病毒的…...
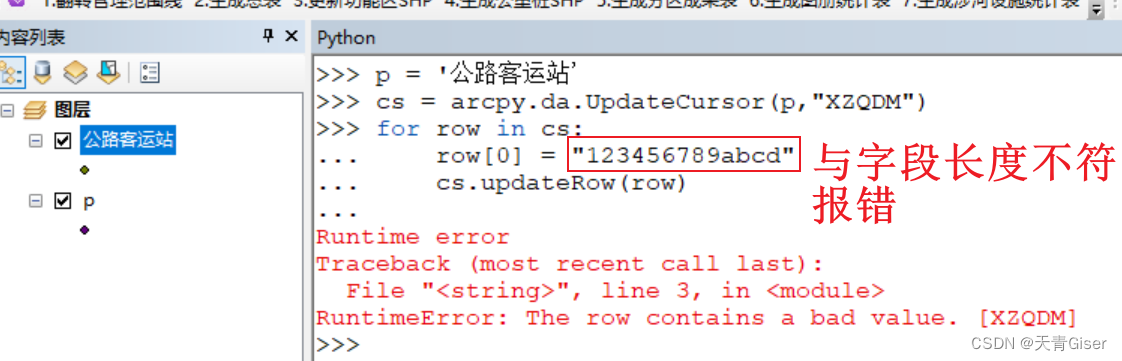
Arcpy开发记录
一.GDB数据库相关 1.单独的shape更新时,不会有限制,数据会自动截取 2.在GDB下,使用UpdateCursor更新字段时,填入的数据长度必须与字段长度要求一致,否则报错: 二.Cursor相关 嵌套使用cursor时,…...

Android使用itextpdf操作PDF文档
1、导入jar包: itext-asian.jaritextpdf-5.5.8.jar Paragraph 和 Phrase 的区别: 在 iTextPDF 库中,Paragraph 和 Phrase 是用于创建和组织文本内容的两个不同的类。 Paragraph(段落): Paragraph 是一个…...
llama_index微调BGE模型
微调模型是为了让模型在特殊领域表现良好,帮助其学习到专业术语等。 本文采用llama_index框架微调BGE模型,跑通整个流程,并学习模型微调的方法。 已开源:https://github.com/stay-leave/enhance_llm 一、环境准备 Linux环境,GPU L20 48G,Python3.8.10。 pip该库即可。…...
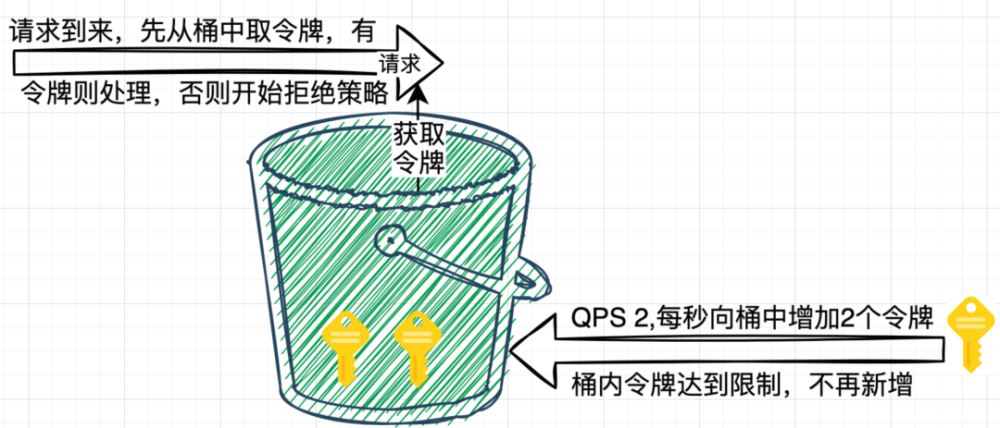
什么是限流?常见的限流算法
目录 1. 什么是限流 2. 常见限流算法 3. 固定窗口算法 4. 滑动窗口算法 5. 漏桶算法 6. 令牌桶算法 7. 限流算法选择 1. 什么是限流 限流(Rate Limiting)是一种应用程序或系统资源管理的策略,用于控制对某个服务、接口或功能的访问速…...

ZL-0895小动物活动记录仪可同时检测8只动物的活动量
简单介绍: 小动物活动记录仪是一种多用途、宽范围的小动物活动记录仪器,可用于小鼠、大鼠、豚鼠和兔的实验,小动物活动记录仪具有不需对动物使用特别盛具的特点,可在不改变动物原生活环境的情况下,进行实时监测&…...

注册测绘师的前世今生
本文梳理了 注册测绘师 的前世今生,具体情况如下表: 历史线时间事件诞生2007年1月原人事部、国家测绘局联合印发《注册测绘师制度暂行规定》,注册测绘师制度建立。同时同步发布《注册测绘师资格考试实施办法》、《注册测绘师资格考核认定办法…...

Python中的异常处理:深入探索try-except-finally结构
Python中的异常处理:深入探索try-except-finally结构 一、引言 在Python编程中,异常处理是一个非常重要的部分。当程序遇到错误时,比如尝试除以零、文件读取失败等,Python会抛出一个异常。如果我们不捕获这些异常,程…...
【R语言】边缘概率密度图
边缘概率密度图是一种在多变量数据分析中常用的图形工具,用于显示每个单独变量的概率密度估计。它通常用于散点图的边缘,以便更好地理解单个变量的分布情况,同时保留了散点图的相关性信息。 在边缘概率密度图中,每个变量的概率密度…...

中国结(科普)
中国结是一种手工编织工艺品,它身上所显示的情致与智慧正是汉族古老文明中的一个侧面。 [1]它原本是由旧石器时代的缝衣打结,后推展至汉朝的仪礼记事,再演变成今日的装饰手艺。周朝人随身的佩戴玉常以中国结为装饰,而战国时代的铜…...

使用Android Studio 搭建AOSP FrameWork 源码阅读开发环境
文章目录 概述安装Android Studio编译源码使用Android Studio打开源码制作ipr文件直接编译成功后自动打开Android Studio 修改SystemUI验证开发环境 概述 我们都知道Android的系统源码量非常之大,大致有frameworka层源码,硬件层(HAL)源码,内…...
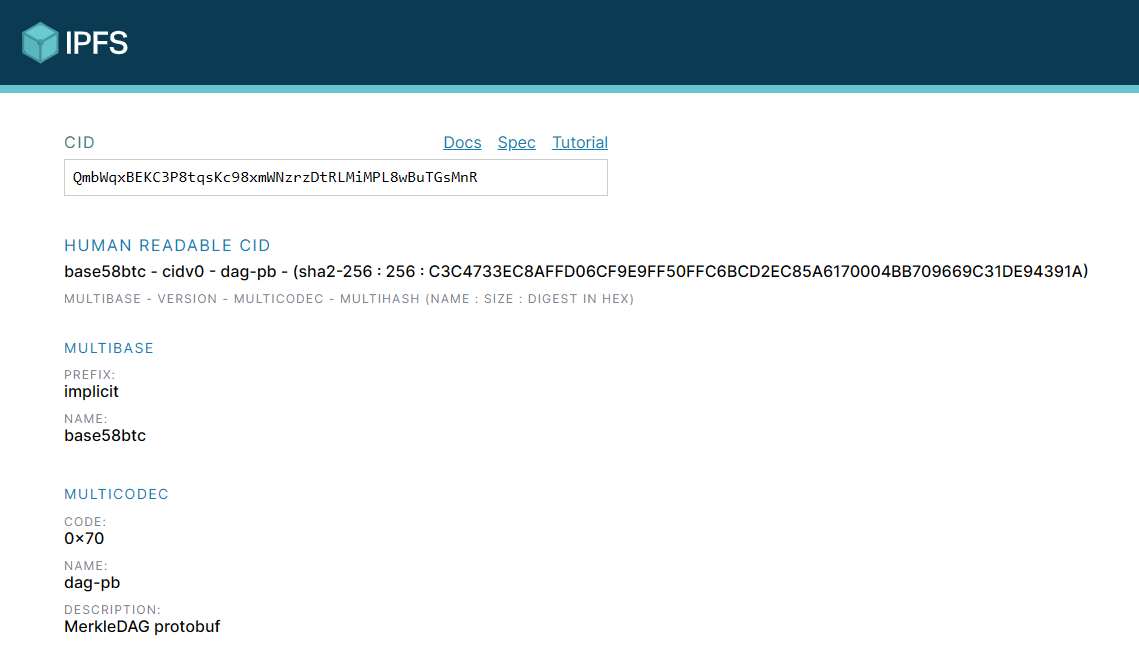
区块链 | IPFS:CID
🦊原文:Anatomy of a CID 🦊写在前面:本文属于搬运博客,自己留存学习。 1 CID 在分布式网络中与其他节点交换数据时,我们依赖于内容寻址(而不是中心化网络的位置寻址)来安全地定位…...
离线参数自学习的完整流程与避坑指南)
别再纠结在线辨识了!聊聊永磁同步电机(PMSM)离线参数自学习的完整流程与避坑指南
永磁同步电机离线参数辨识实战:从理论到工程落地的全流程解析 在电机控制领域,参数辨识一直是个让人又爱又恨的话题。尤其是当项目从实验室走向量产时,那些在仿真中运行良好的算法,往往会因为实际电机参数的偏差而表现失常。我曾亲…...

Qwen3-0.6B-FP8惊艳效果:Qwen3-0.6B-FP8在中文法律条文理解任务中表现优异
Qwen3-0.6B-FP8惊艳效果:在中文法律条文理解任务中表现优异 最近,我在测试一个非常有意思的模型——Qwen3-0.6B-FP8。你可能听说过各种大模型,但这个模型有点特别,它是个“小个子”,却想在“大任务”上证明自己。我把…...

告别复杂配置:SDXL 1.0电影级绘图工坊开箱即用体验
告别复杂配置:SDXL 1.0电影级绘图工坊开箱即用体验 1. 为什么选择SDXL 1.0电影级绘图工坊 在AI绘图领域,Stable Diffusion XL(SDXL)1.0代表了当前最先进的文本到图像生成技术。然而,对于大多数非技术背景的创作者来说…...

League Akari:英雄联盟玩家的终极效率工具集,免费提升游戏体验
League Akari:英雄联盟玩家的终极效率工具集,免费提升游戏体验 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit …...

AutoDock Vina特殊金属元素对接技术指南:从问题诊断到方案落地
AutoDock Vina特殊金属元素对接技术指南:从问题诊断到方案落地 【免费下载链接】AutoDock-Vina AutoDock Vina 项目地址: https://gitcode.com/gh_mirrors/au/AutoDock-Vina 问题溯源:金属元素对接的技术瓶颈 在分子对接实践中,科研人…...
)
文艺复兴,什么是XSS,常见形式(二)
前言 本文将继续介绍XSS的常见形状,依赖于portswigger提供的免费Lab环境,将重点介绍关于使用脚本来进行表单XSS验证以及针对标签的模糊测试。 Lab: Stored DOM XSS 这是一个存储型的DOM类的XSS,具体的是当你将内容提交到评论区,…...
,实现传统文化里的 “时间轮回”)
【数据结构实战】循环队列FIFO 特性生成六十甲子(天干地支纪年法),实现传统文化里的 “时间轮回”
前言天干地支纪年法是中国传统文化的重要组成部分,十天干与十二地支依次相配,组成六十甲子。本文将使用循环队列这一数据结构完成六十甲子的生成,严格遵循题目要求:定义两个循环队列,分别存储十天干、十二地支队列空则…...

2026年小学英语学习小程序排行榜
对于小学生而言,英语学习早已打破“只背单词、只刷习题”的单一模式,听、说、读、写全方位同步训练,才是提升英语能力的关键。2026年,市面上涌现出多款优质小学英语学习小程序,覆盖单词记忆、听力训练、阅读提升、语法…...
)
电动汽车工程师视角:碳化硅模块在电驱系统中的应用实战(含热管理设计)
碳化硅功率模块在电动汽车电驱系统中的工程实践 当一辆搭载碳化硅逆变器的电动汽车从静止加速到100km/h时,功率模块内部的温度变化可能超过100℃。这种极端工况正是第三代半导体材料大显身手的舞台。作为参与过多个量产项目的电驱系统工程师,我想分享一些…...
开发中,EEG实时预处理流程设计与避坑指南)
从实验室到产品:脑机接口(BCI)开发中,EEG实时预处理流程设计与避坑指南
从实验室到产品:脑机接口(BCI)开发中EEG实时预处理流程设计与避坑指南 在咖啡馆见到那位渐冻症患者用脑电波操控机械臂喝咖啡时,我意识到脑机接口技术正从实验室走向真实世界。但鲜有人提及的是,这套酷炫系统背后藏着怎样的信号处理炼狱——当…...