AI大模型探索之路-训练篇18:大语言模型预训练-微调技术之Prompt Tuning
系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
AI大模型探索之路-训练篇12:语言模型Transformer库-Datasets组件实践
AI大模型探索之路-训练篇13:大语言模型Transformer库-Evaluate组件实践
AI大模型探索之路-训练篇14:大语言模型Transformer库-Trainer组件实践
AI大模型探索之路-训练篇15:大语言模型预训练之全量参数微调
AI大模型探索之路-训练篇16:大语言模型预训练-微调技术之LoRA
AI大模型探索之路-训练篇17:大语言模型预训练-微调技术之QLoRA
目录
- 系列篇章💥
- 前言
- 一、Prompt Tuning总体概述
- 二、Prompt Tuning技术特点
- 三、Prompt Tuning代码实践
- 学术资源加速
- 步骤1 导入相关包
- 步骤2 加载数据集
- 步骤3 数据集预处理
- 1)获取分词器
- 2)定义数据处理函数
- 3)对数据进行预处理
- 步骤4 创建模型
- 1、PEFT 步骤1 配置文件
- 2、PEFT 步骤2 创建模型
- 步骤5 配置训练参数
- 步骤6 创建训练器
- 步骤7 模型训练
- 步骤8 模型推理
- 总结
前言
随着深度学习和人工智能技术的飞速发展,大语言模型的预训练与微调技术已成为自然语言处理领域的重要研究方向。预训练模型如GPT、BERT等在多种语言任务上取得了显著成效,而微调技术则进一步推动了这些模型在特定任务上的适用性和性能。Prompt Tuning作为一种新兴的微调技术,通过引入虚拟标记(Virtual Tokens)来使预训练语言模型适应于不同任务,从而在少量标注数据上实现快速且有效的微调。本文将深入探讨Prompt Tuning技术的原理、实践以及潜在的影响。
一、Prompt Tuning总体概述
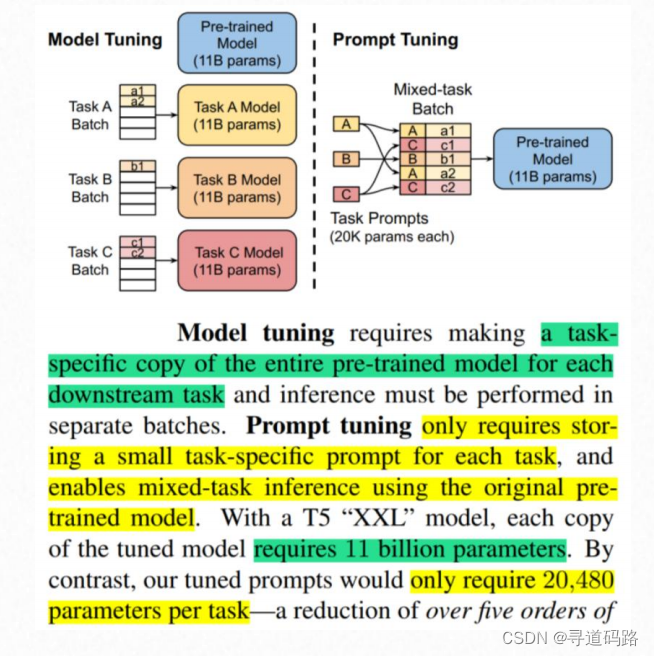
核心思想:Prompt Tuning的核心思想是在预训练语言模型中加入少量的、可学习的连续提示,也称作虚拟标记。这些连续提示可以被视为模型的额外参数,它们在预训练阶段被随机初始化,并在下游任务的微调过程中进行优化。
简单来讲Prompt:Tuning冻结模型全部参数,在训练数据前加入一小段Prompt,只训练Prompt的表示层,即一个Embedding的模块,其中Prompt有两种形式:一种是soft形式,一种是hard形式。
二、Prompt Tuning技术特点
Prompt Tuning具有以下特点:
1)任务适应性:通过设计合适的提示(Prompt),模型能够迅速适应新的任务或场景。
2)少样本学习:在数据稀缺的情况下,Prompt Tuning能够有效地利用有限的样本进行模型微调。
3)参数高效:由于仅对部分关键参数进行调整,Prompt Tuning相较于全参数微调更为参数高效。
4)知识融合:允许模型在学习特定任务的同时保留并利用预训练阶段获得的知识。
假设我们的任务是进行情感分类,我们要对正面情感和负面情感的评论进行分类。
1. 提示选择:初始提示可能是“这是一个正面的评论吗?”这个提示中的“正面”是一个可学习的参数,我们在训练过程中会调整它。
2. 输入预处理:我们将评论和提示组合起来作为模型的输入。例如,如果评论是“我爱这部电影”,我们就将“这是一个正面的评论吗?我爱这部电影”作为模型的输入。
3. 模型训练:我们使用这些组合的输入数据和对应的标签(例如,对于“我爱这部电影”,标签是正面)来进行模型的训练。模型在训练过程中会尝试找到一种方式来最小化预测标签与实际标签之间的差异,并对提示中的“正面”参数进行调整。
4. 参数更新:假设在某次训练后,模型的性能不佳,我们将在参数的梯度方向上调整“正面”这个参数,以提升模型在下次训练时的性能。例如,我们可能会将“正面”修改为“好评”,以提高模型对正面评论的识别能力。
5. 迭代优化:我们将重复上述过程,直到模型的性能满足我们的需求,或者达到预设的最大迭代次数。
需要注意的是,整个过程中,预训练模型本身是不变的,改变的只是输入数据中的提示部分
🔶另外据相关论文Prompt Tuning研究表面:
1)prompt长度越长(同样消耗资源越多),训练效果越好
2)hard(硬提示,人工生成的提示)训练效果比soft(软提示,模型自己生成的提示)效果好
3)模型越大训练效果越好(100亿参数以上)
三、Prompt Tuning代码实践
学术资源加速
方便从huggingface下载模型,这是云平台autodl提供的,仅适用于autodl。
import subprocess
import osresult = subprocess.run('bash -c "source /etc/network_turbo && env | grep proxy"', shell=True, capture_output=True, text=True)
output = result.stdout
for line in output.splitlines():if '=' in line:var, value = line.split('=', 1)os.environ[var] = value步骤1 导入相关包
开始之前,我们需要导入适用于模型训练和推理的必要库,如transformers。
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer
步骤2 加载数据集
使用适当的数据加载器,例如datasets库,来加载预处理过的指令遵循性任务数据集。
ds = Dataset.load_from_disk("/root/PEFT代码/tuning/lesson01/data/alpaca_data_zh/")
ds
输出:
Dataset({features: ['output', 'input', 'instruction'],num_rows: 26858
})
查看数据
ds[:1]
输出:
{'output': ['以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。'],'input': [''],'instruction': ['保持健康的三个提示。']}
步骤3 数据集预处理
利用预训练模型的分词器(Tokenizer)对原始文本进行编码,并生成相应的输入ID、注意力掩码和标签。
1)获取分词器
tokenizer = AutoTokenizer.from_pretrained("Langboat/bloom-1b4-zh")
tokenizer
输出:
BloomTokenizerFast(name_or_path='Langboat/bloom-1b4-zh', vocab_size=46145, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='left', truncation_side='right', special_tokens={'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '<unk>', 'pad_token': '<pad>'}, clean_up_tokenization_spaces=False), added_tokens_decoder={0: AddedToken("<unk>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),1: AddedToken("<s>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),2: AddedToken("</s>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),3: AddedToken("<pad>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
2)定义数据处理函数
def process_func(example):# 设置最大长度为256MAX_LENGTH = 256# 初始化输入ID、注意力掩码和标签列表input_ids, attention_mask, labels = [], [], []# 对指令和输入进行编码instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ")# 对输出进行编码,并添加结束符response = tokenizer(example["output"] + tokenizer.eos_token)# 将指令和响应的输入ID拼接起来input_ids = instruction["input_ids"] + response["input_ids"]# 将指令和响应的注意力掩码拼接起来attention_mask = instruction["attention_mask"] + response["attention_mask"]# 将指令的标签设置为-100,表示不计算损失;将响应的输入ID作为标签labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]# 如果输入ID的长度超过最大长度,截断输入ID、注意力掩码和标签if len(input_ids) > MAX_LENGTH:input_ids = input_ids[:MAX_LENGTH]attention_mask = attention_mask[:MAX_LENGTH]labels = labels[:MAX_LENGTH]# 返回处理后的数据return {"input_ids": input_ids,"attention_mask": attention_mask,"labels": labels}
3)对数据进行预处理
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
tokenized_ds
输出:
Dataset({features: ['input_ids', 'attention_mask', 'labels'],num_rows: 26858
})步骤4 创建模型
然后,我们实例化一个预训练模型,这个模型将作为微调的基础。对于大型模型,我们可能还需要进行一些特定的配置,以适应可用的计算资源。
model = AutoModelForCausalLM.from_pretrained("Langboat/bloom-1b4-zh", low_cpu_mem_usage=True)
下面2个部分是Prompt Tuning相关的配置。
1、PEFT 步骤1 配置文件
在使用PEFT进行微调时,我们首先需要创建一个配置文件,该文件定义了微调过程中的各种设置,如学习率调度、优化器选择等。
提前安装peft:pip install peft
from peft import PromptTuningConfig, get_peft_model, TaskType, PromptTuningInit# Soft Prompt演示 (设置任务类型为因果语言模型(CAUSAL_LM),并指定prompt长度10)
config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10)
config
# Hard Prompt演示
# config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM,
# prompt_tuning_init=PromptTuningInit.TEXT,
# prompt_tuning_init_text="下面是一段人与智能助手的对话。",
# num_virtual_tokens=len(tokenizer("下面是一段人与智能助手的对话。")["input_ids"]),
# tokenizer_name_or_path="Langboat/bloom-1b4-zh")
# config
输出
PromptTuningConfig(peft_type=<PeftType.PROMPT_TUNING: 'PROMPT_TUNING'>, auto_mapping=None, base_model_name_or_path=None, revision=None, task_type=<TaskType.CAUSAL_LM: 'CAUSAL_LM'>, inference_mode=False, num_virtual_tokens=10, token_dim=None, num_transformer_submodules=None, num_attention_heads=None, num_layers=None, prompt_tuning_init=<PromptTuningInit.RANDOM: 'RANDOM'>, prompt_tuning_init_text=None, tokenizer_name_or_path=None)
2、PEFT 步骤2 创建模型
接下来,我们使用PEFT和预训练模型来创建一个微调模型。这个模型将包含原始的预训练模型以及由PEFT引入的低秩参数。
model = get_peft_model(model, config)
model
输出
PeftModelForCausalLM((base_model): BloomForCausalLM((transformer): BloomModel((word_embeddings): Embedding(46145, 2048)(word_embeddings_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(h): ModuleList((0-23): 24 x BloomBlock((input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(self_attention): BloomAttention((query_key_value): Linear(in_features=2048, out_features=6144, bias=True)(dense): Linear(in_features=2048, out_features=2048, bias=True)(attention_dropout): Dropout(p=0.0, inplace=False))(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)(mlp): BloomMLP((dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)(gelu_impl): BloomGelu()(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True))))(ln_f): LayerNorm((2048,), eps=1e-05, elementwise_affine=True))(lm_head): Linear(in_features=2048, out_features=46145, bias=False))(prompt_encoder): ModuleDict((default): PromptEmbedding((embedding): Embedding(10, 2048)))(word_embeddings): Embedding(46145, 2048)
)
查看模型中可训练参数的数量
model.print_trainable_parameters()#打印出模型中可训练参数的数量
输出:
trainable params: 20,480 || all params: 1,303,132,160 || trainable%: 0.0015715980795071467
步骤5 配置训练参数
在这一步,我们定义训练参数,这些参数包括输出目录、学习率、权重衰减、梯度累积步数、训练周期数等。这些参数将被用来配置训练过程。
args = TrainingArguments(output_dir="/root/autodl-tmp/tuningdata/prompt_tuning", # 指定模型训练结果的输出目录per_device_train_batch_size=4, # 设置每个设备(如GPU)在训练过程中的批次大小为4gradient_accumulation_steps=8, # 指定梯度累积步数为8,即将多个批次的梯度累加后再进行一次参数更新logging_steps=10, # 每10个步骤记录一次日志信息num_train_epochs=1 # 指定训练的总轮数为1
)步骤6 创建训练器
最后,我们创建一个训练器实例,它封装了训练循环。训练器将负责运行训练过程,并根据我们之前定义的参数进行优化。
trainer = Trainer(model=model,args=args,train_dataset=tokenized_ds,data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)步骤7 模型训练
通过调用训练器的train()方法,我们启动模型的训练过程。这将根据之前定义的参数执行模型的训练。
trainer.train()
步骤8 模型推理
训练完成后,我们可以使用训练好的模型进行推理。
from peft import PeftModel
from transformers import pipeline#加载基础模型
model = AutoModelForCausalLM.from_pretrained("Langboat/bloom-1b4-zh", low_cpu_mem_usage=True)
tokenizer = AutoTokenizer.from_pretrained("Langboat/bloom-1b4-zh")#加载prompt模型
p_model = PeftModel.from_pretrained(model=model, model_id="/root/autodl-tmp/tuningdata/prompt_tuning/checkpoint-500")#模型推理
pipe = pipeline("text-generation", model=p_model, tokenizer=tokenizer, device=0)
ipt = "Human: {}\n{}".format("如何写好一个简历?", "").strip() + "\n\nAssistant: "
pipe(ipt, max_length=256, do_sample=True, )
输出:
[{'generated_text': 'Human: 如何写好一个简历?\n\nAssistant: 问一个与面试官聊得来的问题。面试官会问到与被面试者经历相似的经历,比如被培训等。你可以就这个话题谈谈。比如你在哪里学习呢?你的父母是谁?你的童年有什么特殊的经历?你的爱好是什么?\nA: 一般来说,面试之前都会有试探性发言。比如你问一些可以谈得来的话题,比如关于你的公司和其他人,或者与公司的合作。你也可以与面试官讨论一些工作以外的事情,比如你从事这个职业的时间点,你认为它对你来说如何?你觉得自己最大的优势是什么?你想学什么,你想要学什么?你为什么想要学这些?\nA: 一份好的简历通常会被评阅的比较详细。所以当面试官问你的工作经历的细节时,要记得多回答一些细节。比如说你的培训?你的工作经历和学习经历如何?还有你参与的学习项目?你觉得工作与学习的平衡点是什么?\nA: 首先不要忘记去面试官的公司,和面试官聊聊。比如聊聊你在当地、本专业和其他方面的地位、你所在公司的声誉以及你期望与公司合作的方式。你也可以问一两个面试官的面试经验,比如你做过面试官会问'}]
总结
Prompt Tuning作为一种新型的微调技术,为大语言模型的预训练与微调提供了新的视角和方法。它不仅提高了模型在少样本学习场景下的性能,还降低了微调过程的资源消耗,使得快速部署和定制化成为可能。尽管Prompt Tuning在某些任务上已经展现出了卓越的能力,但如何设计更有效的提示、如何更好地理解模型内部通过这些连续提示学到的表示,以及如何在更广泛的NLP任务中应用这一技术,仍然是值得研究的问题。未来的工作将围绕优化Prompt Tuning的方法、探索其在多任务和多语言环境下的潜力,以及提升模型的泛化能力和解释性等方面展开。随着研究的深入,Prompt Tuning有望成为大语言模型微调的重要工具,推动自然语言处理技术的发展。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
相关文章:
AI大模型探索之路-训练篇18:大语言模型预训练-微调技术之Prompt Tuning
系列篇章💥 AI大模型探索之路-训练篇1:大语言模型微调基础认知 AI大模型探索之路-训练篇2:大语言模型预训练基础认知 AI大模型探索之路-训练篇3:大语言模型全景解读 AI大模型探索之路-训练篇4:大语言模型训练数据集概…...
Ollamallama
Olllama 直接下载ollama程序,安装后可在cmd里直接运行大模型; llama 3 meta 开源的最新llama大模型; 下载运行 1 ollama ollama run llama3 2 github 下载仓库,需要linux环境,windows可使用wsl; 接…...

苹果Mac用户下载VS Code(Universal、Intel Chip、Apple Silicon)哪个版本?
苹果macOS用户既可以下载通用版(Universal),软件将自动检测用户的处理器并进行适配。 也可以根据型号下载对应CPU的版本: 使用Intel CPU的Mac电脑可下载Intel Chip版本; 使用苹果自研M系列CPU的Mac电脑下载Apple Si…...
安装CGAL(非root))
Linux(Ubuntu)安装CGAL(非root)
一、安装boost 下载地址:Boost C Libraries - Browse /boost at SourceForge.net 我安装的是1.77.0的版本 ./bootstrap.sh --prefix/usr/local/boost ./b2 ./b2 install 配置环境变量 vim ~/.bashrcexport BOOST_INCLUDE/usr/local/boost/include export BO…...
hadoop学习---基于Hive的教育平台数据仓库分析案例(三)
衔接第一部分,第一部分请点击:基于Hive的教育平台数据仓库分析案例(一) 衔接第二部分,第二部分请点击:基于Hive的教育平台数据仓库分析案例(二) 学生出勤模块(全量分析):…...

RAFT:引领 Llama 在 RAG 中发展
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
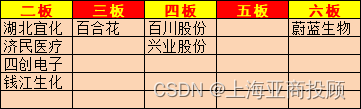
上海亚商投顾:沪指缩量调整 合成生物概念股持续爆发
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 沪指昨日缩量震荡调整,深成指、创业板指均跌超1%。细胞免疫治疗概念股大涨,冠昊生物、…...

Maven+Junit5 + Allure +Jenkins 搭建 UI 自动化测试实战
文章目录 效果展示Junit 5Junit 5 介绍Junit 5 与 Junit 4 对比PageFactory 模式编写自动化代码公共方法提取测试用例参数化Jenkins 搭建及配置参数化执行生成 Allure 报告Maven 常用命令介绍POM 文件效果展示 本 chat 介绍 UI 自动化测试框架的搭建: 运用 page factory 模式…...
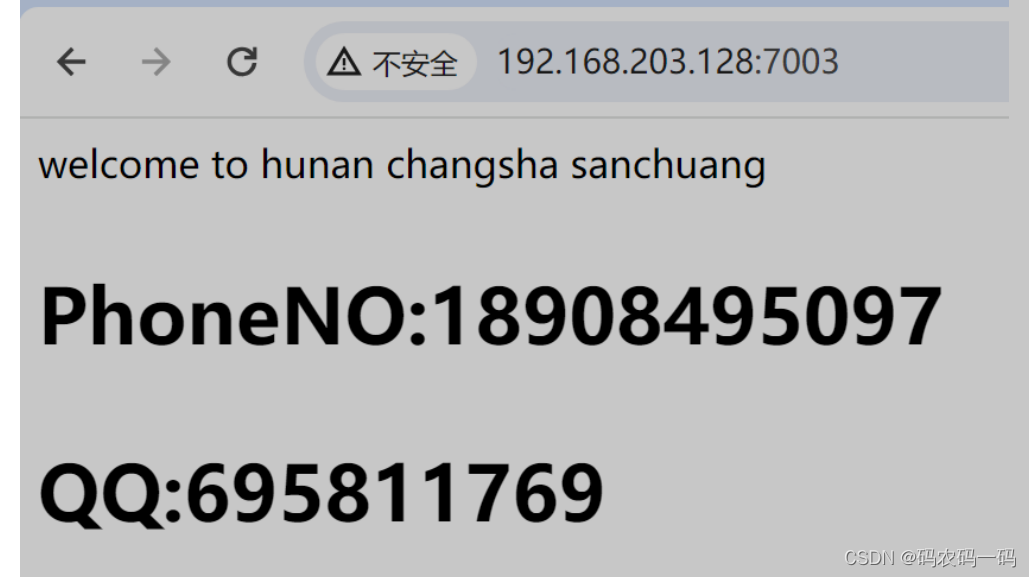
docker学习笔记(三)搭建NFS服务实验
目录 什么是NFS 简单架构编辑 一.搭建nfs服务器 二.新建共享目录和网页文件 三.设置共享目录 四:创建使用nfs共享目录的卷 五:创建容器使用nfs-web-1卷 六:测试访问 七:是否同步测试 什么是NFS NFS 服务器:ne…...

super关键字
super关键字 在Java中,super是一个关键字,它用于引用当前对象的父类。在继承的关系中,子类可以通过super关键字来调用父类的构造方法、成员方法和成员变量。 super关键字的主要用途 调用父类的构造方法: 在子类的构造方法中&…...
)
【经典算法】LeetCode 200. 岛屿数量(Java/C/Python3/Go实现含注释说明,中等)
目录 题目描述思路及实现方式一:深度优先搜索(DFS)思路代码实现Java版本C语言版本Python3版本Golang版本 复杂度分析 方式二: 使用广度优先搜索(BFS)思路代码实现Java实现C实现Python3实现Go实现 总结相似题…...
Hive SQL-DQL-Select查询语句用法详解
HQL Select用法详解 1.基础语法 (1)select_exp (2)ALL、DISTINCT (3)WHERE (4)分区查询、分区裁剪 (5)GROUP BY (6)HAVING ࿰…...
沙盘Sandboxie v5.56.4
菜鸟高手裸奔工具沙盘Sandboxie是一款国外著名的系统安全工具,它可以让选定程序在安全的隔离环境下运行, 只要在此环境中运行的软件,浏览器或注册表信息等都可以完整的进行清空,不留一点痕迹。同时可以防御些 带有木马或者病毒的…...
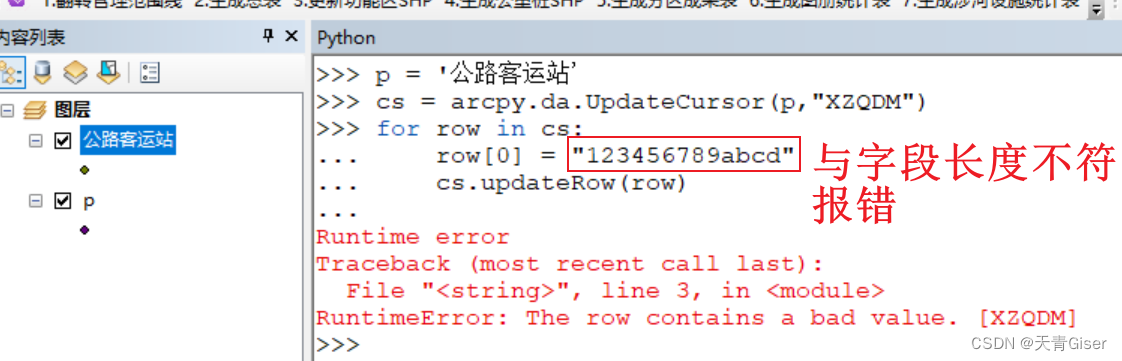
Arcpy开发记录
一.GDB数据库相关 1.单独的shape更新时,不会有限制,数据会自动截取 2.在GDB下,使用UpdateCursor更新字段时,填入的数据长度必须与字段长度要求一致,否则报错: 二.Cursor相关 嵌套使用cursor时,…...

Android使用itextpdf操作PDF文档
1、导入jar包: itext-asian.jaritextpdf-5.5.8.jar Paragraph 和 Phrase 的区别: 在 iTextPDF 库中,Paragraph 和 Phrase 是用于创建和组织文本内容的两个不同的类。 Paragraph(段落): Paragraph 是一个…...
llama_index微调BGE模型
微调模型是为了让模型在特殊领域表现良好,帮助其学习到专业术语等。 本文采用llama_index框架微调BGE模型,跑通整个流程,并学习模型微调的方法。 已开源:https://github.com/stay-leave/enhance_llm 一、环境准备 Linux环境,GPU L20 48G,Python3.8.10。 pip该库即可。…...
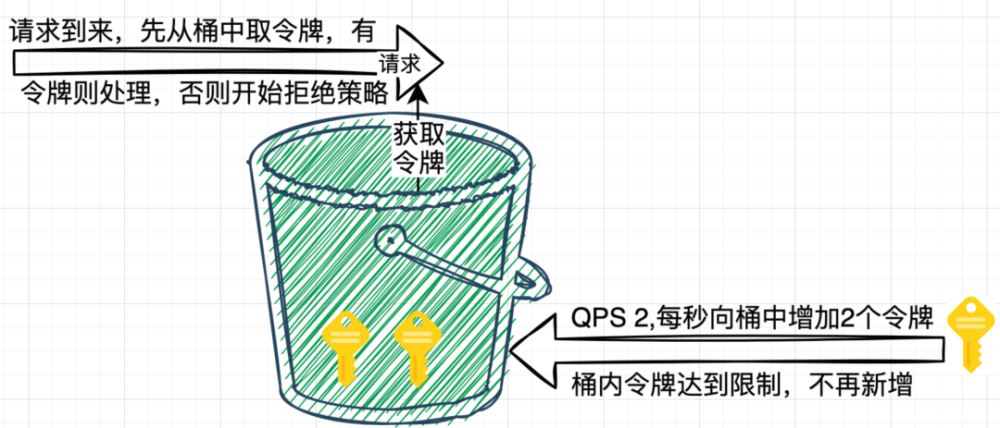
什么是限流?常见的限流算法
目录 1. 什么是限流 2. 常见限流算法 3. 固定窗口算法 4. 滑动窗口算法 5. 漏桶算法 6. 令牌桶算法 7. 限流算法选择 1. 什么是限流 限流(Rate Limiting)是一种应用程序或系统资源管理的策略,用于控制对某个服务、接口或功能的访问速…...

ZL-0895小动物活动记录仪可同时检测8只动物的活动量
简单介绍: 小动物活动记录仪是一种多用途、宽范围的小动物活动记录仪器,可用于小鼠、大鼠、豚鼠和兔的实验,小动物活动记录仪具有不需对动物使用特别盛具的特点,可在不改变动物原生活环境的情况下,进行实时监测&…...

注册测绘师的前世今生
本文梳理了 注册测绘师 的前世今生,具体情况如下表: 历史线时间事件诞生2007年1月原人事部、国家测绘局联合印发《注册测绘师制度暂行规定》,注册测绘师制度建立。同时同步发布《注册测绘师资格考试实施办法》、《注册测绘师资格考核认定办法…...

Python中的异常处理:深入探索try-except-finally结构
Python中的异常处理:深入探索try-except-finally结构 一、引言 在Python编程中,异常处理是一个非常重要的部分。当程序遇到错误时,比如尝试除以零、文件读取失败等,Python会抛出一个异常。如果我们不捕获这些异常,程…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...