【读点论文】SAM-LIGHTENING: A LIGHTWEIGHT SEGMENT ANYTHING MODEL,改进自注意力机制,然后知识蒸馏提点
SAM-LIGHTENING: A LIGHTWEIGHT SEGMENT ANYTHING MODEL WITH DILATED FLASH ATTENTION TO ACHIEVE 30× ACCELERATION
ABSTRACT
- 分割任意模型(SAM)由于其零样本泛化能力,在分割任务中引起了广泛的关注。然而,SAM在现实世界实践中的更广泛应用受到其低推理速度和高计算内存需求的限制,这主要源于注意力机制。现有的工作集中在优化编码器上,但还没有充分解决注意力机制本身的低效问题,即使将其提炼为一个较小的模型,这也为进一步改进留下了空间。作为回应,我们介绍了SAM Lightening,这是SAM的一种变体,其特点是重新设计的注意力机制,称为扩展闪光注意力。它不仅有助于提高并行性,提高处理效率,还保留了与现有FlashAttention的兼容性。相应地,我们提出了一种渐进式蒸馏,以实现从香草SAM的有效知识转移,而无需从头开始进行昂贵的训练。在COCO和LVIS上的实验表明,SAM Lighting在运行时间效率和分割精度方面都显著优于最先进的方法。具体来说,对于1024×1024像素的图像,它可以实现每张图像7毫秒(ms)的推理速度,这比普通SAM快30.1倍,比最先进的快2.1倍。此外,它只需要244MB的内存,是普通SAM的3.5%。代码和权重可在 Anonymized Repository - Anonymous GitHub (4open.science)。
- 论文地址:[2403.09195] SAM-Lightening: A Lightweight Segment Anything Model with Dilated Flash Attention to Achieve 30 times Acceleration (arxiv.org)
INTRODUCTION
- 传统上,图像分割受到深度学习模型在为特定任务设计的数据集上进行专门训练的必要性的限制。手工制作的数据集的这种专业化往往限制了它们的生成能力。针对这一限制,Segment Anything Model(SAM)代表了一种典型的转变,其零样本学习能力使其能够分割新的和看不见的图像。然而,SAM在增强现实(AR)、图像编辑、智能手机部署和医学成像等不同领域的应用受到其图像编码器计算负担挑战的阻碍,该编码器包含大量6.32亿个参数。这种大小大约是U-Net等传统分割网络的20倍,导致计算需求很高。
- 为了应对这一挑战,已开始作出各种努力。例如,FastSAM采用了一种策略,用更精简的卷积神经网络(CNN)取代SAM的转换器编码器,旨在创建更轻的模型。然而,这往往会导致准确性下降,尤其是在复杂的分割任务中。另一个值得注意的方法是MobileSAM,它使用蒸馏技术将知识从SAM的编码器转移到更紧凑的ViT微小编码器。类似地,EfficientSAM等举措旨在完善MobileSAM的训练流程,以提高准确性。相反,SAMFast专注于通过量化和修剪等技术优化原始SAM的速度,但这些修改对性能增强的影响有限。
- 我们的研究确定了先前关于SAM的工作中的关键局限性,主要是在注意力机制中低效的计算和内存使用方面。为了解决这些问题,我们将FlashAttention和扩展注意力机制集成到我们的SAM框架中,对现有方法进行正交改进。这些增强不仅减少了内存消耗,还改进了并行处理,使其与以前的进步相辅相成。然而,将这些机制直接应用于SAM将需要对模型进行完全的重新训练,从而产生大量的计算成本。为了规避这一挑战,我们提出了一种动态分层蒸馏(DLD)。DLD通过逐步分配特征权重,为图像编码器实现了一种渐进式提取方案,有效地促进了知识从SAM转移到我们的轻量级模型。我们证明了我们的模型(SAM Lightening)不仅具有足够的表达能力来表示原始SAM,而且在计算上也是高效的,在7ms内完成推理。简而言之,我们的主要贡献有四个方面:
- 我们引入了一种新的SAM结构,SAM Lighting,以显著降低计算复杂度。
- 我们设计了一种新的扩展 flash attention 机制来取代香草式的自我注意,以提高SAM Lighting的效率和推理速度。
- 为了有效地将知识从香草SAM转移到SAM Lighting,我们建议在不影响性能的情况下进行动态分层蒸馏。
- SAM Lightening实现了每张图像7ms的最先进性能,比普通SAM快30.1倍。
RELATED WORK
-
Segment Anything Model: SAM包括三个主要部分:图像编码器、提示编码器和掩码解码器。值得注意的是,图像编码器是SAM中参数密集度最高的部分,占其处理时间的98.3%,这突出了优化的必要性。FastSAM采用CNN编码器,特别是YOLOv8 seg来代替ViT编码器,以提高处理速度。然而,已经观察到它会影响分割精度,特别是在复杂场景和捕捉精细边缘细节时。MobileSAM提取编码器以减少模型大小和计算要求。然而,MobileSAM编码器结构和参数分布的不平衡限制了其实际部署和性能优化的潜力。SAMFast代表了另一种优化策略,专注于使用量化和稀疏化等方法提高SAM的处理速度。虽然这一方案确实提供了一些加速,但其总体影响仍然温和。另一方面,EfficientSAM改进了MobileSAM的训练方法,特别是针对MobileSAM方法的准确性方面。
-
FlashAttention: FlashAttention机制介绍了一种在神经网络中计算注意力的有效而准确的方法。它主要通过战略性平铺和重新计算技术,显著减少了高带宽内存的读取和写入。在此基础上,FlashAttention-2通过增强的矩阵乘法运算进一步细化了该过程。这些改进已被证明在特定的计算环境中可将性能提高两倍。
-
知识蒸馏:知识蒸馏是一种将知识从复杂模型转移到更简单模型的技术。它们旨在保留较大模型的性能属性,同时显著减少其计算足迹和模型大小。MobileSAM通过从原始SAM的ViT-H图像编码器中提取输出,并使用它们直接提取到预先训练的ViT微型编码器中,从而采用解耦的知识提取。事实证明,这种策略对已经拥有预训练参数的较小模型特别有益。
METHODS
Dilated Flash Attention
-
为了解决SAM图像编码器的高计算需求,我们设计了一种新的带有FlashAttention的注意力操作,以加快推理速度。
-
分割和稀疏化:为了减轻注意力操作中处理(Q,K,V)的计算负担,我们将每个输入划分为等长部分(w),然后在每个片段内沿序列维度应用稀疏化。这种稀疏化包括以固定的间隔(r)选择行,从而减少注意力机制需要处理的数据量。如下图所示,稀疏化过程可以公式化为:
-
X ˉ i = [ X i w , X i w + r , X i w + 2 r , . . . , X ( i + 1 ) w − 1 ] \bar X_i = [X_{iw}, X_{iw+r}, X_{iw+2r}, . . . , X_{(i+1)w−1}] Xˉi=[Xiw,Xiw+r,Xiw+2r,...,X(i+1)w−1]
-
这里, X ˉ i \bar Xi Xˉi 表示采样的稀疏矩阵。X表示变量Q、K或V中的任何一个。
-

-
SAM Lightening的总体框架以及动态分层蒸馏,可以有效地从香草SAM转移知识,而无需从头开始训练。
-
-
FlashAttention并行处理:每个输入数据的稀疏段是密集矩阵,可以独立参与注意力计算,因此可以并行处理。这种并行性对于有效管理大规模图像数据集、显著加快处理时间和提高实时图像分割模型的效率至关重要。合并FlashAttention通过在过程中并行化密集矩阵计算,进一步提高了效率。
-
Output Recomposition:在所提出的扩展Flash Attention框架中,我们并行处理稀疏片段,实现了应用于的乘积的softmax函数 Q ˉ i \bar Q_i Qˉi 与 K ˉ i \bar K_i Kˉi 的转置,随后与 V ˉ i \bar V_i Vˉi 相乘如下:
- O ˉ i = s o f t m a x ( Q ˉ i ⋅ K ˉ i T ) ⋅ V ˉ i . \bar O_i = softmax(\bar Qi ·\bar K^T_i ) · \bar V_i . Oˉi=softmax(Qˉi⋅KˉiT)⋅Vˉi.
-
将这些输出重新组合为有凝聚力的最终输出O涉及一个精心设计的过程:
-
最初,我们建立了一个零矩阵 O i n i t O_{init} Oinit,它反映了原始输入的维度,用于累积各个分段的输出。
-
对于每个计算段输出 O ˉ \bar O Oˉ 确定了一个特定的偏移 γ i γ_i γi。这个偏移量决定了 O ˉ i \bar O_i Oˉi 的精确起始位置在 O i n i t O_{init} Oinit 矩阵内。
-
每个 O ˉ i \bar O_i Oˉi 使用基于其 γ i γ_i γi 的映射操作将映射到 O i n i t O_{init} Oinit:
-
O = ∑ i M A P ( O i n i t , O ˉ i , γ i ) O = \sum_i MAP(O_{init}, \bar O_i , γ_i) O=i∑MAP(Oinit,Oˉi,γi)
-
“MAP”操作放置每个 O ˉ I \bar O_I OˉI 根据 γ i γ_i γi 确定的位置,将元素转换为 O i n i t O_{init} Oinit。这保证了每个分段的输出在最终输出矩阵 O 内基于其原始输入位置的精确对准。
-
-
计算效率:利用所提出的扩展Flash Attention机制,效率在数量上提高了因子 N w r 2 \frac N {wr^2} wr2N,其中N表示输入的总大小,w表示每个片段的长度,r 表示稀疏化的间隔。这种数学关系表明,对于任何给定的输入大小,扩展的 Flash Attention 需要少得多的计算。因此,这提高了模型有效处理大规模图像分割任务的能力,标志着性能和实用性都有了显著提高。
Dynamic Layer-Wise Distillation (DLD)
-
从头开始训练SAM Lightening是昂贵的,而层适应是具有挑战性的,因为以ViT-H作为特征编码器的SAM和SAM Lighteniing之间的独特结构。为了实现从普通SAM到所提出的框架的有效知识转移,我们提出了一种新的动态分层蒸馏(DLD),它动态修改特征权重以增强模型之间的分层蒸馏。
-
动态逐层权重:如果前面的层没有很好地提取出来,那么后面的层的性能可能会受到从前面的层提取的低质量特征的影响。通过为这些初始层的损失分配更大的权重,动态加权确保它们在训练过程中得到更多的关注。这有助于在初始阶段更好地调整学生模式和教师模式。给定由 L 层组成的深度神经网络,每一层 i 都与时间权重 α i ( t ) α_i(t) αi(t) 相关联。该机制在不同的训练阶段 t 调整神经网络中每一层i的重要性。初始层保留最大强调 ( α 1 ( t ) = 1 ) (α_1(t)=1) (α1(t)=1),随后的层遵循动态加权方案,该方案可以用分段函数进行数学表示:
-
α i ( t ) = 0 f o r t < T i = t − T i Δ t f o r T i ≤ t ≤ T i + Δ t = 1 f o r t ≥ T i + Δ t \alpha_i(t)=0~~for ~t<T_i\\ =\frac{t-T_i}{\Delta t}~~ for~T_i\leq t \leq T_i+\Delta t\\ =1~~for~t\geq T_i+\Delta t αi(t)=0 for t<Ti=Δtt−Ti for Ti≤t≤Ti+Δt=1 for t≥Ti+Δt
-
其中 T i T_i Ti 表示第 i 层开始更新其权重的 epoch,并且前一层已达到饱和,即 T i = T i − 1 + ∆ t T_i=T_{i−1}+∆t Ti=Ti−1+∆t。参数 ∆ t ∆t ∆t 表示权重从 0 过渡到 1 的epoch数。对于预定义的历元增量 ∆ t ∆t ∆t,在前一层达到其峰值权重后,每一层依次激活其学习潜力。这种机制有助于从教师模型中级联吸收知识。
-
-
Decoupled Feature Distillation: 提取过程将知识从SAM的编码器(教师模型)转移到我们提出的编码器(学生模型),如上图所示。我们选择了最接近输出的N层进行特征提取。由于这些更深层次与模型的输出直接相关,因此提取它们可以更有效地传递预测结果的关键信息。这些层被指定为“Focus Layers”。
-
在训练的初始阶段,更接近输入的层被给予优先权。这里,目的是将学生模型的SAM Lightning主要特征表示(表示为 f S A M − L i ( x ) f^i_{SAM-L}(x) fSAM−Li(x))与教师模型的SAM Lighting主要特征表示 f S A M i ( x ) f^i_{SAM}(x) fSAMi(x)对齐,用于最接近输入的 i 层。随着训练的进行,逐层加权会动态变化。与后续层相关联的损耗被逐渐放大。在这个过程中,损失函数进化为吸收来自后续层的表示:
-
L P = ∑ i ∈ F o c u s α i ( t ) ∑ j = 1 N ∣ ∣ f S A M ( i ) ( x j ) − f S A M − L ( i ) ( x j ) ∣ ∣ 2 2 L_P = \sum_{i∈Focus} α_i(t) \sum^N_{j=1} ||f^{(i)}_{SAM}(x_j ) − f^{(i)}_{SAM-L}(x_j ) ||^ 2_2 LP=i∈Focus∑αi(t)j=1∑N∣∣fSAM(i)(xj)−fSAM−L(i)(xj)∣∣22
-
其中 L 是层的完全计数,系数 α(i)是由训练 epoch 和层 i 确定的分段函数。综合蒸馏损失公式为:
-
L i n t e g r a t e d = L p + λ L o u t p u t L_{integrated}=L_p+\lambda L_{output} Lintegrated=Lp+λLoutput
-
其中 L P L_P LP 封装了所有选定特征层损失的加权和, L o u t p u t L_{output} Loutput 是图像编码器输出层的损失,λ 是在整个提取过程中平衡解码器输出重要性的比例因子。
-
-
对齐解码器:此外,通过去耦蒸馏获得的轻量级图像编码器与冻结解码器存在对齐问题,尤其是对于基于点的提示分割任务。因此,我们通过在SA-1B数据集上采样点提示和框提示来微调解码器,以与图像编码器对齐。损失函数定义如下:
-
L f i n e − t i n e = 20 ∗ I O U + D i c e + F o c a l L o s s L_{fine-tine}=20*IOU+Dice+FocalLoss Lfine−tine=20∗IOU+Dice+FocalLoss
-
这里,IOU表示交集和并集损失,而 dice 损失和 focal 损失分别用于解决类不平衡和具有挑战性的分割区域。
-
EXPERIMENT
Experimental Setups
- 我们的模型利用SA-1B数据集的1%进行蒸馏和微调。它的特点是一个嵌入尺寸为384的编码器、六个注意力头和六层结构。对于FlashAttention组件,我们使用bfloat16。蒸馏和微调过程各进行10个时期,学习率为10−3,批量为32。梯度累积设置为步长为4。该模型在两个NVIDIA RTX 4090 GPU上进行训练。为了提高训练速度,保存SAM图像编码器的输出。
Results
-
运行时间和内存效率评估:我们在下表中比较了我们提出的SAM Lighting与香草SAM(即SAM-ViT-H)、FastSAM、MobileSAM、EfficientSAM、SAMFast的性能。关于分割性能,香草SAM被认为是上界。重要的是,下表显示,SAM Lightening在推理延迟和峰值内存使用方面优于所有同类产品,与普通SAM相比实现了30.1倍的加速,峰值内存减少了96.5%,与最先进的相比实现了2.1倍的加速。
-

-
Nvidia RTX 4090 GPU的性能比较,其中“Enc.”表示编码器,“Dec.”表示解码器,“Mem.”表示内存使用情况,“Tot.”表示总时间,“SU”表示加速比。
-
-
下表中的吞吐量比较进一步加强了SAM Lighteniing的卓越性能,在各种批量中实现了最高吞吐量。总之,这种高吞吐量及其低延迟和内存使用,将SAM Lighting定位为图像分割任务的高效模型。
-

-
并行吞吐量比较。推断时间以毫秒(ms)为单位。
-
-
框/点提示模式下的比较:我们首先评估了在边界框和基于点的提示下的性能。对于边界框提示,我们遵循普通SAM中的设置,利用COCO和LVIS中的 GT 注释来合成定义每个图像中感兴趣区域的边界框。对于点提示,我们从图像中随机采样 GT 遮罩内的点,挑战所有模型来准确分割与每个点相关的对象或区域。在数量上,我们使用并集上的平均交集(mIoU)作为度量。
-

-
在提示模式下,SAM Lightening和香草SAM之间的代表性图像分割结果。
-
-
如下表所示,与普通SAM相比,SAMFast和MobileSAM的性能都有所下降,尤其是在点提示的情况下。作为一个基于卷积神经网络的模型,FastSAM显示出更明显的下降,这在处理包含大量小对象的LVIS数据集中尤为明显。这一观察结果反映了基于CNN的编码器在处理更复杂的分割场景时的局限性。相比之下,SAM Lightening在分割性能方面与原始SAM匹配,以获得最佳上下文。这甚至适用于基于点的提示场景,其中SAM Lightening实现了类似于普通SAM的mIoU。
-

-
基于mIOU的COCO和LVIS分割性能比较。标签“box”、“1P”和“3P”分别对应于使用边界框、一个点和三个点作为提示。
-
-
Anything Mode 下的比较:虽然分割任何模式是一种创新的方法,但它不是一种常用的分割方法,因此不能有效地代表典型的分割任务。因此,我们的分析主要集中在通过基于点和基于框的方法直观地比较分割结果,这在实际应用中更为普遍。然而,为了完整性和证明模型的多功能性,我们在比较中还包括了分段任意模式的输出。
-
从下图所示的代表性样本来看,SAM Lightening和MobileSAM都表现出与普通SAM几乎无法区分的分割结果。这种相似性在边缘清晰度和细节保持方面是显著的,这是高质量分割的标志。SAM Lightening展示了其稳健性和准确性,与普通SAM的性能紧密一致。
-

-
Representative samples under anything mode.
-
Ablation study
- 值得注意的是,许多以前的工作对SAM使用的输入大小小于1024。为了进行公平的比较,我们还在这些场景中进行了实验,发现在输入大小等于或小于512×512的情况下保持FlashAttention可以获得最佳性能。这表明FlashAttention的适用性取决于模型的输入大小和特定的硬件配置。使用FlashAttention的决定应基于特定的应用程序上下文和性能要求。尽管FlashAttention加速了模型提取中的训练,但它对推理性能的影响是由各种硬件指标决定的。在我们的推理平台上,特别是对于输入大小为1024的SAM,多头注意力算子表现出更注重计算的特性。如下图所示,与不使用FlashAttention相比,使用FlashAttention会导致推理速度略低。因此,我们选择在蒸馏过程中使用FlashNote来优化性能,同时在评估阶段删除它。
-

-
FlashAttention的推理时间对输入大小的影响,其中我们选择两个嵌入维度,即768和384进行比较。
-
CONCLUSION
- 我们提出 SAM-Lightening ,以解决普通SAM中计算需求高和推理速度慢的主要限制,使其更适合部署在资源受限的设备上。我们的方法涉及SAM中图像编码器的重新设计,通过动态分层蒸馏将自注意算子蒸馏为扩展的FlashAttention。这些优化有助于显著降低计算复杂度和内存使用量,而不会影响分割性能。具体而言,SAM Lightening可以在每张图像7毫秒内完成推理,实现比SAM-ViT-H高30.1倍的速度。由于SAM Lighteniing与修剪和量化互补,未来的一个方向可以研究与它们的集成。
学习资料
-
luca-medeiros/lightning-sam: Fine-tune Segment-Anything Model with Lightning Fabric. (github.com)
-
Learn how to fine-tune the Segment Anything Model (SAM) | Encord
-
NVIDIA-AI-IOT/nanosam: A distilled Segment Anything (SAM) model capable of running real-time with NVIDIA TensorRT (github.com)
-
chongzhou96/EdgeSAM: Official PyTorch implementation of “EdgeSAM: Prompt-In-the-Loop Distillation for On-Device Deployment of SAM” (github.com)
-
NVIDIA-AI-IOT/clip-distillation: Zero-label image classification via OpenCLIP knowledge distillation (github.com)
-
How to Use the Segment Anything Model (SAM) (roboflow.com)
-
MobileSAM (Mobile Segment Anything Model) - Ultralytics YOLOv8 Docs
-
PyTorch官方教程中文版 (pytorch123.com)
-
zergtant/pytorch-handbook: pytorch handbook是一本开源的书籍,目标是帮助那些希望和使用PyTorch进行深度学习开发和研究的朋友快速入门,其中包含的Pytorch教程全部通过测试保证可以成功运行 (github.com)
-
AISystem/02Hardware at main · chenzomi12/AISystem (github.com)
相关文章:
【读点论文】SAM-LIGHTENING: A LIGHTWEIGHT SEGMENT ANYTHING MODEL,改进自注意力机制,然后知识蒸馏提点
SAM-LIGHTENING: A LIGHTWEIGHT SEGMENT ANYTHING MODEL WITH DILATED FLASH ATTENTION TO ACHIEVE 30 ACCELERATION ABSTRACT 分割任意模型(SAM)由于其零样本泛化能力,在分割任务中引起了广泛的关注。然而,SAM在现实世界实践中…...

PostgreSQL函数和运算符
PostgreSQL为内置的数据类型提供了大量的函数和运算符,用户也可以定义自己的函数和运算符,使用psql命令\df和\do可以列出所有可用的函数和运算符 1. 逻辑运算符 常用的逻辑运算符有AND、OR、NOT,逻辑系统有三个值true、fase和nullÿ…...

使用网络工具监控网络性能
网络工具和实用程序有助于有效地检测网络问题,诊断其原因和位置,以及缓解和解决问题,这有助于确保网络环境的稳定性,使用户免受设备连接问题带来的麻烦。 网络工具已经成为每个网络管理员用于有效诊断和处理网络问题的解决方案中…...

Gradle基础笔记
配置镜像 修改 gradle>wrapper>gradle-wrapper.properties distributionUrlhttps://mirrors.aliyun.com/macports/distfiles/gradle/gradle-8.6-all.zip 配置父项目 使用 subprojects 编码问题处理 [compileJava, compileTestJava, javadoc].options.encoding ‘UTF-…...
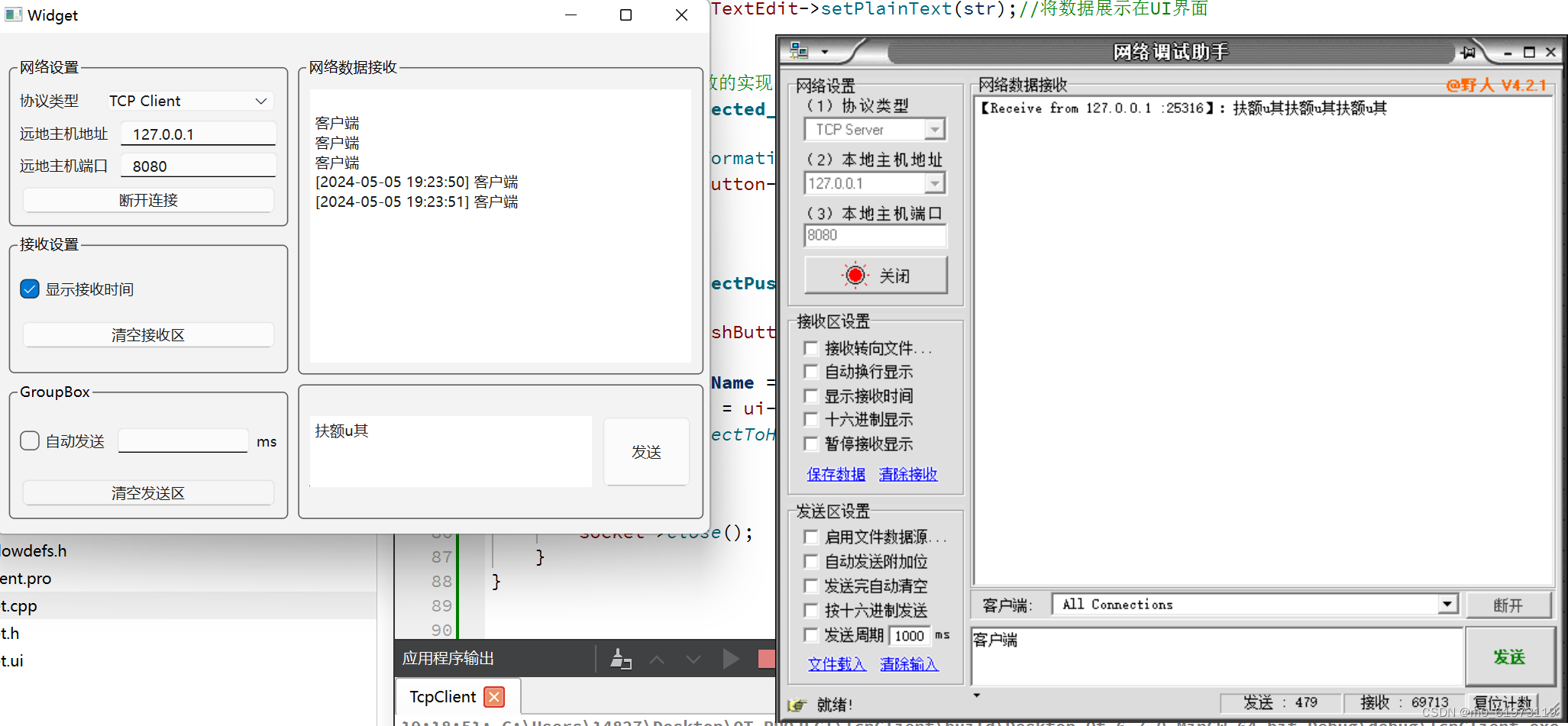
QT+网络调试助手+TCP客户端
一、网络调试助手UI界面 编程主要思路: 首先将水平的控件 水平布局 ,然后相对垂直的控件 垂直布局 ,哪怕是底下的groupBox也需要和里面的内容 水平布局,然后最后框选全部 栅格布局。如果需要界面自适应窗口大小,…...
数据库调优-SQL语句优化
2. SQL语句优化 sql 复制代码 # 请问这两条SQL语句有什么区别呢?你来猜一猜那条SQL语句执行查询效果更好! select id from sys_goods where goods_name华为 HUAWEI 麦芒7 魅海蓝 6G64G 全网通; select id from sys_goods where goods_id14967325985…...

h函数 render函数 JSX基本用法
1.1认识h函数(hyperscript工具 基于JavaScript编写模板的工具) Vue推荐在绝大多数情况下使用模板来创建你的HTML,然后一些特殊的场景,需要JavaSript的完全编程能力,可以使用渲染函数,它比模板更接近编译器&…...
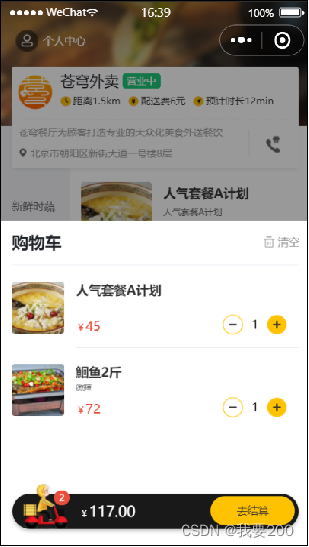
购物车操作
添加购物车: 需求分析和接口设计: 接口设计: 请求方式:POST 请求路径:/user/shoppingCart/add请求参数:套餐id、菜品id、口味返回结果:code、data、msg 数据库设计: 这上面出现了…...
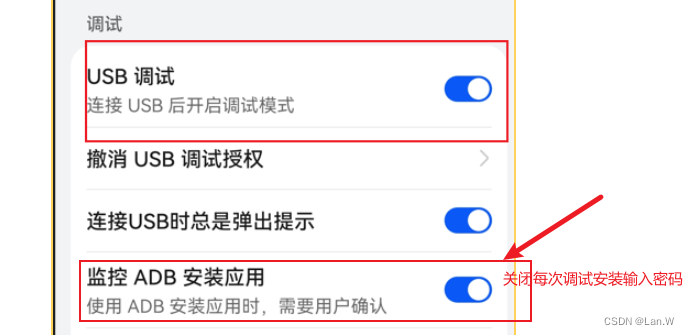
华为手机 鸿蒙系统-android studio识别调试设备,开启adb调试权限
1.进入设置-关于手机-版本号,连续点击7次 认证:有锁屏密码需要输入密码, 开启开发者配置功能ok 进入开发者配置界面 打开调试功能 重新在androd studio查看可运行running devices显示了, 不行的话,重启一下android …...
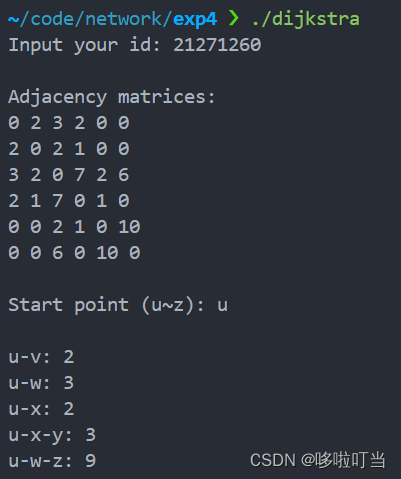
计算机网络——Dijkstra路由算法
实验目的 实现基于 Dijkstra 算法的路由软件 实验内容 网络拓扑如图所示 实验过程 先编写开辟应该图的空间,然后给点映射数字,构建图。程序获取用户输入的学号,构建图中边的权值。接下来程序从用户输入获取最短路径的搜索起点࿰…...

AI智能化逐渐趋于成熟后,预测今后最吃香的开发职业
AI智能化正在成熟的路途中,这中间会有波折,但终有一天会来的,我相信等到了这一天,我们的开发效率和代码质量,将会大大不同,而我们的团队与个人,也会面临着很棒的体验。 那么在AI智能化真正趋于成…...

Acwing2024蓝桥杯BFS
AcWing 1355. 母亲的牛奶 bfs: #include<iostream> #include<queue> using namespace std; const int N21; int A,B,C; bool flag[N][N][N]; struct node{int a,b,c; }; queue<node>q; void check(int a,int b,int c){if(!flag[a][b][c]){q.push({a,b,c})…...
vue打包报错:CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory
前言: vue项目,打包报错:CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory 报错现象: 报错原因: 这个错误是由Node.js在尝试分配内存时因为系统的可用内存不足而发生的。"JavaScript heap…...
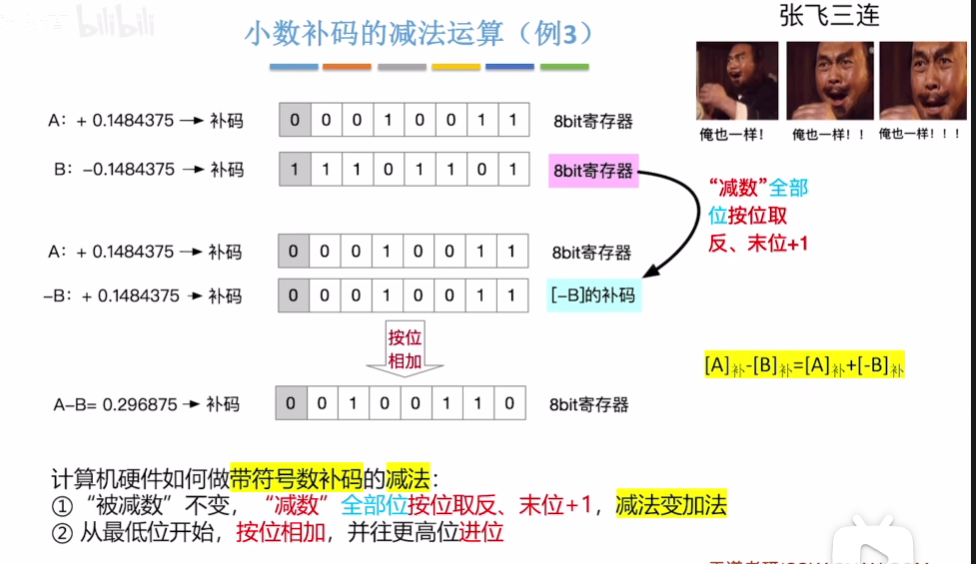
计算机组成原理网课笔记
无符号整数的表示与运算 带符号整数的表示与运算 原反补码的特性对比 移码 定点小数...

Python学习第四部分 函数式编程
文章目录 高阶函数lambda 表达式和匿名函数偏函数闭包map函数reduce函数filter 函数sorted函数 函数式编程主要学习:高阶函数、闭包closure、匿名函数、偏函数,map函数、reduce函数、filter函数、sorted函数 函数式编程是个很古老的概念,最古…...
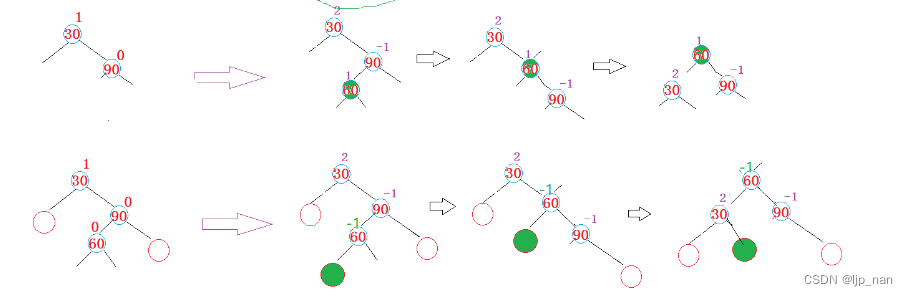
数据结构-二叉树-AVL树(平衡二叉树)
红黑树是平衡二叉树的一个变种。 一、 产生平衡二叉树的原因。 二叉搜索树的问题在于极端场景下退化为类似链表的结构,所以搜索的时间复杂度就变成了O(N)。为了保证二叉树不退化为链表,我们必须保证二叉树的的平衡性。 二叉平衡搜索树就是解决上面的问…...
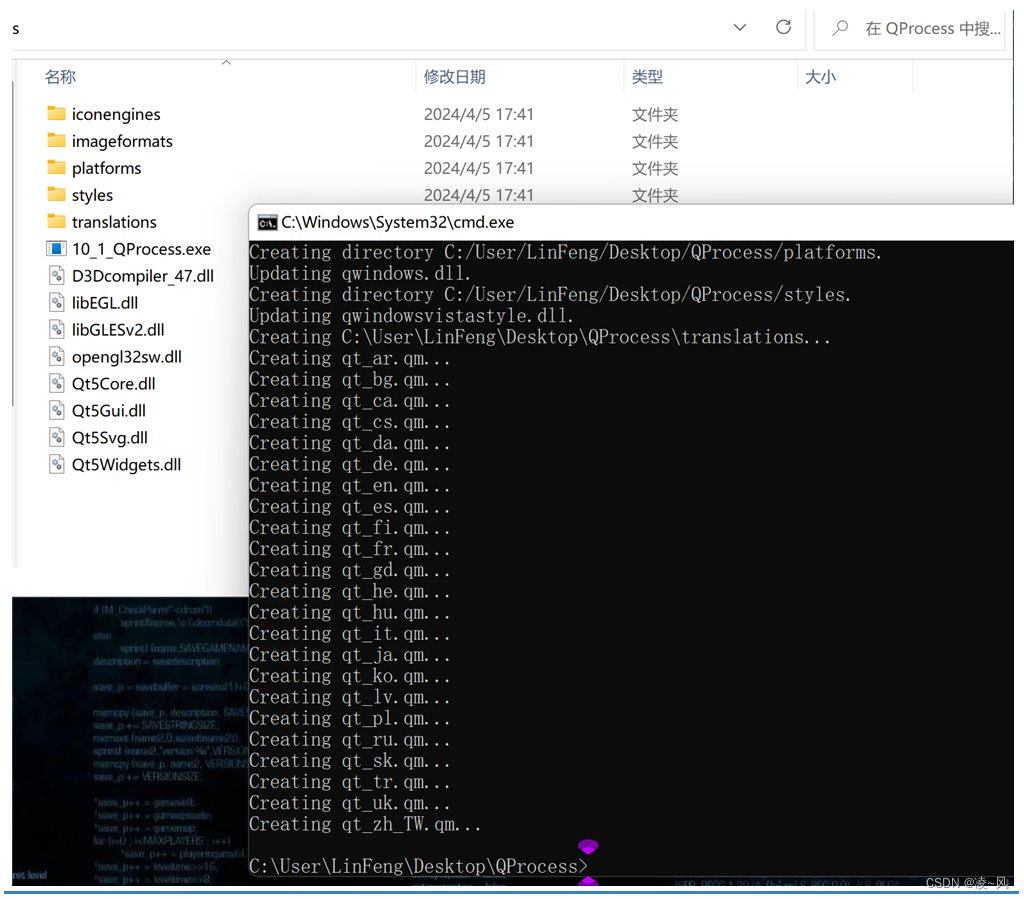
【Qt问题】windeployqt如何提取Qt依赖库
往期回顾 【Qt问题】Qt Creator 如何链接第三方库-CSDN博客 【Qt问题】Qt 如何带参数启动外部进程-CSDN博客 【Qt问题】VS2019 Qt win32项目如何添加x64编译方式-CSDN博客 【Qt问题】windeployqt如何提取Qt依赖库 考虑这个问题主要是:当我们的程序运行好之后&#…...

VS2019下使用MFC完成科技项目管理系统
背景: (一)实验目的 通过该实验,使学生掌握windows程序设计的基本方法。了解科技项目组织管理的主要内容和管理方面的基本常识,熟练应用数据库知识,通过处理过程对计算机软件系统工作原理的进一步理解&…...

【Android】Kotlin学习之数据容器(数组for循环遍历)
数组遍历 1. for ( item in arr){…} 2. for ( i in arr.indeces ) {…} (遍历下标) 3. for ((index, item) in arr.withInfex()) {…} (遍历下标和元素) 4. arr.forEach {} ( 遍历元素 ) 5. arr.forEachIndexed{index, item -> …}...

JavaWeb_请求响应_简单参数实体参数
一、SpringBoot方式接收携带简单参数的请求 简单参数:参数名与形参变量名相同,定义形参即可接收参数。并且在接收过程中,会进行自动的类型转换。 启动应用程序后,在postman中进行测试: 请求成功,响应回了O…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...
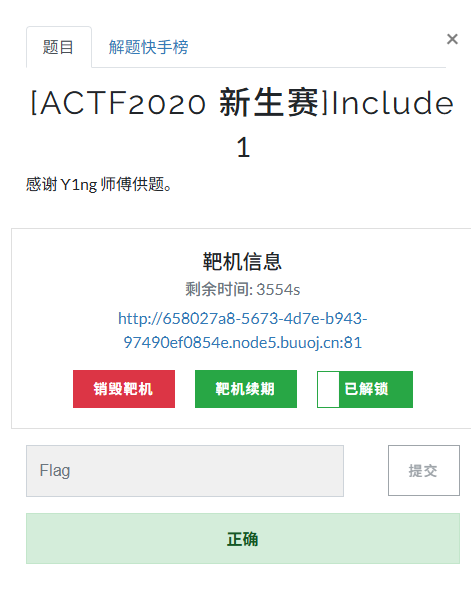
[ACTF2020 新生赛]Include 1(php://filter伪协议)
题目 做法 启动靶机,点进去 点进去 查看URL,有 ?fileflag.php说明存在文件包含,原理是php://filter 协议 当它与包含函数结合时,php://filter流会被当作php文件执行。 用php://filter加编码,能让PHP把文件内容…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

Vue3 PC端 UI组件库我更推荐Naive UI
一、Vue3生态现状与UI库选择的重要性 随着Vue3的稳定发布和Composition API的广泛采用,前端开发者面临着UI组件库的重新选择。一个好的UI库不仅能提升开发效率,还能确保项目的长期可维护性。本文将对比三大主流Vue3 UI库(Naive UI、Element …...

简单介绍C++中 string与wstring
在C中,string和wstring是两种用于处理不同字符编码的字符串类型,分别基于char和wchar_t字符类型。以下是它们的详细说明和对比: 1. 基础定义 string 类型:std::string 字符类型:char(通常为8位)…...

RLHF vs RLVR:对齐学习中的两种强化方式详解
在语言模型对齐(alignment)中,强化学习(RL)是一种重要的策略。而其中两种典型形式——RLHF(Reinforcement Learning with Human Feedback) 与 RLVR(Reinforcement Learning with Ver…...

英国云服务器上安装宝塔面板(BT Panel)
在英国云服务器上安装宝塔面板(BT Panel) 是完全可行的,尤其适合需要远程管理Linux服务器、快速部署网站、数据库、FTP、SSL证书等服务的用户。宝塔面板以其可视化操作界面和强大的功能广受国内用户欢迎,虽然官方主要面向中国大陆…...
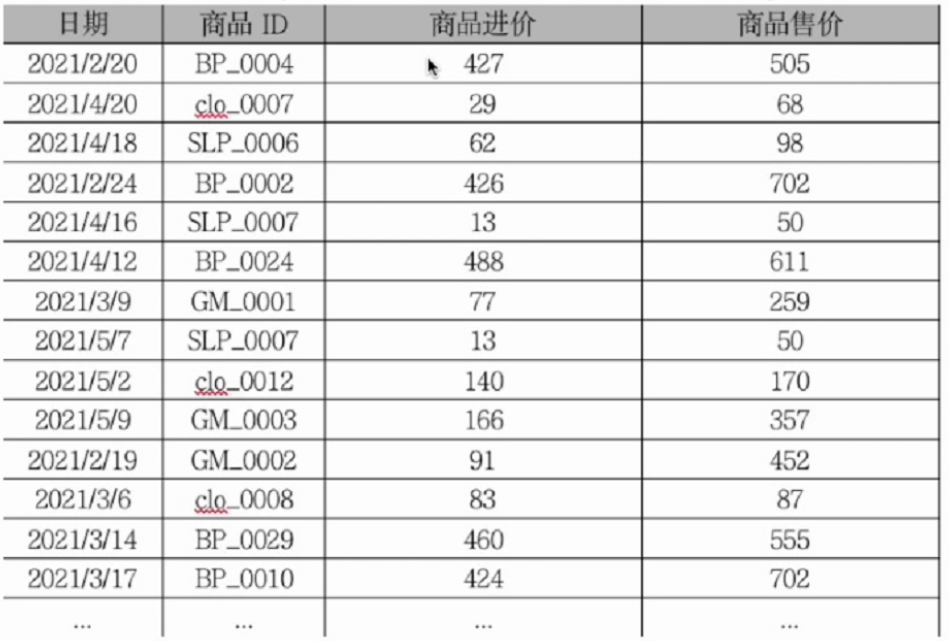
智警杯备赛--excel模块
数据透视与图表制作 创建步骤 创建 1.在Excel的插入或者数据标签页下找到数据透视表的按钮 2.将数据放进“请选择单元格区域“中,点击确定 这是最终结果,但是由于环境启不了,这里用的是自己的excel,真实的环境中的excel根据实训…...