基于Python的LSTM网络实现单特征预测回归任务(TensorFlow)
单特征:数据集中只包含2列,时间列+价格列,仅利用价格来预测价格
目录
一、数据集
二、任务目标
三、代码实现
1、从本地路径中读取数据文件
2、数据归一化
3、创建配置类,将LSTM的各个超参数声明为变量,便于后续使用
4、创建时间序列数据
5、划分数据集
6、定义LSTM网络
(1)创建顺序模型实例
(2)添加LSTM层
(3)添加全连接层
7、编译LSTM模型
8、训练模型
9、模型预测
10、数据反归一化
11、绘制图像
12、完整版代码
一、数据集
自建数据集--【load.xlsx】。包含2列:
- date列(时间列,记录2022年6月2日起始至2023年12月31日为止,日度数据)
- price列(价格列,记录日度数据对应的某品牌衣服的价格,浮点数)

二、任务目标
实现基于时间序列的单特征价格预测
三、代码实现
1、从本地路径中读取数据文件
- read_excel函数读取Excel文件(read_csv用来读取csv文件),读取为DataFrame对象
- index_col='date'将'date'列设置为DataFrame的索引
- .values属性获取price列的值,pandas会将对应数据转换为NumPy数组
# 字符串前的r表示一个"原始字符串",raw string
# 文件路径中包含多个反斜杠。如果我们不使用原始字符串(即不使用r前缀),那么Python会尝试解析\U、\N等作为转义序列,这会导致错误
data = pd.read_excel(r'E:\load.xlsx', index_col='date')
# print(data)
prices = data['price'].values
# print(prices)打印data:

打印prices:

2、数据归一化
- 归一化:将原始数据的大小转化为[0,1]之间,采用最大-最小值归一化
- 数值过大,造成神经网络计算缓慢
- 在多特征任务中,存在多个特征属性,但神经网络会认为数值越小的,影响越小。所以可能关键属性A的值很小,不重要属性B的值却很大,造成神经网络的混淆
- scikit-learn的转换器通常期望输入是二维的,其中每一行代表一个样本,每一列代表一个特征
- prices.reshape(-1, 1) 用于确保 prices 是一个二维数组,即使它只有一个特征列
- -1的意思是让 NumPy 自动计算该轴上的元素数量,以保持原始数据的元素总数不变
- fit方法计算了数据中每个特征的最小值和最大值,这些值将被用于缩放
- transform方法使用这些统计信息来实际缩放数据,将其转换到 [0, 1] 范围内
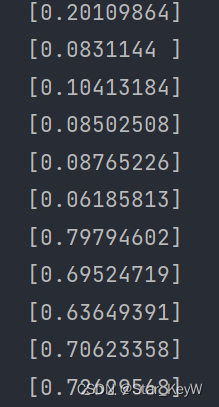
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_prices = scaler.fit_transform(prices.reshape(-1, 1)) # 二维数组
# print(scaled_prices)打印归一化后的价格数据:
3、创建配置类,将LSTM的各个超参数声明为变量,便于后续使用
- timestep:时间步长,滑动窗口大小
- feature_size:每个步长对应的特征数量,这里只使用1维,即每天的价格数据
- batch_size:批次大小,即一次性送入多少个数据(一时间步长为单位)进行训练
- output_size:单输出任务,输出层为1,预测未来1天的价格
- hidden_size:隐藏层大小,即神经元个数
- num_layers:神经网络的层数
- learning_rate:学习率
- epochs:迭代轮数,即总共要让神经网络训练多少轮,全部数据训练一遍成为一轮
- best_loss:记录损失
- activation = 'relu':定义激活函数使用relu
class Config():timestep = 7 # 时间步长,滑动窗口大小feature_size = 1 # 每个步长对应的特征数量,这里只使用1维,每天的价格数据batch_size = 1 # 批次大小output_size = 1 # 单输出任务,输出层为1,预测未来1天的价格hidden_size = 128 # 隐藏层大小num_layers = 1 # lstm的层数learning_rate = 0.0001 # 学习率epochs = 500 # 迭代轮数model_name = 'lstm' # 模型名best_loss = 0 # 记录损失activation = 'relu' # 定义激活函数
config = Config()4、创建时间序列数据
- 通过滑动窗口移动获取数据,时间步内数据作为特征数据,时间步外1个数据作为标签数据
- 通过序列的切片实现特征和标签的划分
- 通过np.array将数据转化为NumPy数组

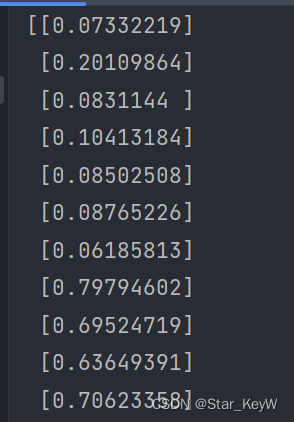
# 创建时间序列数据
X, y = [], []
for i in range(len(scaled_prices) - config.timestep):# 从当前索引i开始,取sequence_length个连续的价格数据点,并将其作为特征添加到列表 X 中。X.append(scaled_prices[i: i + config.timestep])# 将紧接着这sequence_length个时间点的下一个价格数据点作为目标添加到列表y中。y.append(scaled_prices[i + config.timestep])
X = np.array(X)
print(X)
y = np.array(y)
print(y)打印特征数据:
- 三维数组,X 是由多个二维数组(即多个时间步长的数据)组成的,加之本身是一个列表
- 每次迭代都会从 scaled_prices 中取出一个长度为 config.timestep 的连续子序列,并将其添加到 X 列表中
- 由于 scaled_prices 本身是一个二维数组,所以每次取出的子序列也是一个二维数组,形状大致为 [config.timestep, features]
- 当多个这样的二维数组被添加到 X 列表中时,X 就变成了一个列表的列表,其中每个内部列表都是一个二维数组
- 它的形状将是 [n_samples - config.timestep, config.timestep, features],这是一个三维数组

打印标签数据:
- 二维数组,y 是由单个数据点(即单个时间步长的数据)组成的,所以它保持为二维数组
- 从 scaled_prices 中取出一个单独的数据点(即一个二维数组中的一行),并将其添加到 y 列表中
- y 列表中的每个元素都是一个一维数组(或可以看作是一个具有多个特征的向量)
- 它的形状将是 [n_samples - config.timestep, features],这仍然是一个二维数组
5、划分数据集
- 按照9:1的比例划分训练集和测试集
- train_test_split:是sklearn.model_selection模块中的一个函数,用于将数据集随机划分为训练集和测试集
- shuffle=False:表示在划分数据之前不进行随机打乱,意味着数据会按照其原始顺序进行划分
- 因为时间序列数据具有时序性,用过去时间数据预测新时间数据,要保证时间有序
- 测试数据为时间序列的末尾数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, shuffle=False)6、定义LSTM网络
(1)创建顺序模型实例
model = Sequential()(2)添加LSTM层
- LSTM:这是 Keras 中提供的 LSTM 层的类。通过调用这个类,创建一个 LSTM 层
- activation=config.activation:这设置了 LSTM 层中使用的激活函数
- units=config.hidden_size:这设置了 LSTM 层中的隐藏单元数量
- input_shape=(config.timestep, config.feature_size):这定义了输入数据的形状,是一个元组
- 告诉模型,输入数据应该是一个形状为[batch_size, config.timestep, config.feature_size]的三维
- 其中batch_size是批次中样本的数量,它在模型训练时会自动确定(根据你传递给模型的批次数据大小)
model.add(LSTM(activation=config.activation, units=config.hidden_size, input_shape=(config.timestep, config.feature_size)))- LSTM层的输出是一个三维张量,其形状通常为(seq_len, batch_size, num_directions * hidden_size)
- seq_len表示序列长度,即时间序列展开的步数
- batch_size表示数据批次的大小,即一次性输入到LSTM层的数据样本数量
- num_directions * hidden_size表示隐藏层的输出特征维度
- 对于单向LSTM,num_directions为1
- 对于双向LSTM,num_directions为2。hidden_size则是隐藏层节点数,即LSTM单元中隐藏状态的维度
- 含义:LSTM层的输出包含了每个时间步的隐藏状态
(3)添加全连接层
- Dense:是 Keras 中用于创建全连接层的类,也就是每个输入节点与输出节点之间都连接有一个权重
- config.output_size:指定了该全连接层的输出单元数量
model.add(Dense(config.output_size))- 由于此例中,全连接层的大小为1,因此LSTM层输出的三维张量在经过全连接层后将被压缩成一个二维张量
- (batch_size, 1)这样的形状
7、编译LSTM模型
- model.compile():这个方法是Keras模型的一个函数,用于配置模型训练前的参数
- optimizer='adam':这里指定了使用Adam优化器来训练模型
- loss='mean_squared_error':这里指定了损失函数为均方误差(Mean Squared Error, MSE)
model.compile(optimizer='adam', loss='mean_squared_error')8、训练模型
- model.fit():是 Keras 模型的一个函数,用于训练模型。它将根据提供的训练数据 X_train 和对应的标签 y_train,通过多次迭代(epochs)来训练模型。
- x=X_train:指定了训练数据的输入
- y=y_train:指定了训练数据的标签(或目标值)
- epochs=config.epochs:指定了训练过程中数据集的完整遍历次数。
- batch_size=config.batch_size:指定了每次更新模型时使用的样本数
- verbose=2:控制训练过程中的日志输出。verbose=2 表示每个 epoch 输出一行日志,显示训练过程中的损失值和评估指标(如果在编译时指定了评估指标)
- history 对象是一个记录训练过程中信息的字典,包含了训练过程中的损失值和评估指标(如果有的话)
history = model.fit(x=X_train, y=y_train, epochs=config.epochs, batch_size=config.batch_size, verbose=2)9、模型预测
- model.predict():是 Keras 模型的一个函数,它根据提供的输入数据,给出模型对于这些数据的预测结果
predictions = model.predict(X_test)10、数据反归一化
- 当模型训练完成后并进行预测时,预测出的值会是缩放后的值(即按照训练数据缩放的比例)
- 为了得到原始的比例或范围,需要使用缩放器的 inverse_transform 方法来将这些缩放后的值转换回原始的比例或范围
y_test_true_unnormalized = scaler.inverse_transform(y_test)
y_test_preds_unnormalized = scaler.inverse_transform(predictions)- 确保模型的预测结果和真实的测试集标签都在同一个比例或范围内,从而可以准确地评估模型的性能,并以更直观、更易于理解的方式呈现预测结果
11、绘制图像
# 设置图形的大小为10x5单位
plt.figure(figsize=(10, 5))# 绘制真实的测试集标签,使用圆圈('o')作为标记,并命名为'True Values'
plt.plot(y_test_true_unnormalized, label='True Values', marker='o')# 绘制模型的预测值,使用叉号('x')作为标记,并命名为'Predictions'
plt.plot(y_test_preds_unnormalized, label='Predictions', marker='x')# 设置图形的标题
plt.title('Comparison of True Values and Predictions')# 设置x轴的标签
plt.xlabel('Time Steps')# 设置y轴的标签
plt.ylabel('Prices')# 显示图例
plt.legend()# 显示图形
plt.show()12、完整版代码
import pandas as pd
import numpy as np
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from matplotlib import pyplot as plt
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropoutclass Config():timestep = 7hidden_size = 128batch_size = 1output_size = 1epochs = 500feature_size = 1activation = 'relu'
config = Config()# dataframe对象
qy_data = pd.read_excel(r'E:\load.xlsx', index_col='date')
# print(qy_data)
# numpy数组 一维
prices = qy_data['price'].values
# print(prices)scaler = MinMaxScaler()
# 归一化后变成二维数组
scaled_prices = scaler.fit_transform(prices.reshape(-1, 1))
# print(scaled_prices)# Create time series data
X, y = [], []
for i in range(len(scaled_prices) - config.timestep):X.append(scaled_prices[i: i + config.timestep])y.append(scaled_prices[i + config.timestep])
X = np.array(X)
# print(X)
y = np.array(y)
# print(y)# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, shuffle=False)# Define the LSTM mode
model = Sequential()
model.add(LSTM(activation=config.activation, units=config.hidden_size, input_shape=(config.timestep, config.feature_size)))
model.add(Dense(config.output_size))# Compile the model
# adam默认学习率是0.01
model.compile(optimizer='adam', loss='mean_squared_error')model.save('LSTM.h5')# Train the model
history = model.fit(x=X_train, y=y_train, epochs=config.epochs, batch_size=config.batch_size, verbose=2)# Predictions
predictions = model.predict(X_test)# Inverse transform predictions and true values
y_test_true_unnormalized = scaler.inverse_transform(y_test)
y_test_preds_unnormalized = scaler.inverse_transform(predictions)# Plot true values and predictions
plt.figure(figsize=(10, 5))
plt.plot(y_test_true_unnormalized, label='True Values', marker='o')
plt.plot(y_test_preds_unnormalized, label='Predictions', marker='x')
plt.title('Comparison of True Values and Predictions')
plt.xlabel('Time Steps')
plt.ylabel('Prices')
plt.legend()
plt.show()
相关文章:
基于Python的LSTM网络实现单特征预测回归任务(TensorFlow)
单特征:数据集中只包含2列,时间列价格列,仅利用价格来预测价格 目录 一、数据集 二、任务目标 三、代码实现 1、从本地路径中读取数据文件 2、数据归一化 3、创建配置类,将LSTM的各个超参数声明为变量,便于后续…...
Spring - 8 ( 10000 字 Spring 入门级教程 )
一: MyBatis 1.1 引入 MyBatis 我们学习 MySQL 数据库时,已经学习了 JDBC 来操作数据库, 但是 JDBC 操作太复杂了. 我们先来回顾⼀下 JDBC 的操作流程: 创建数据库连接池 DataSource通过 DataSource 获取数据库连接 Connection编写要执行带 ? 占位符…...

鸿蒙内核源码分析(忍者ninja篇) | 都忍者了能不快吗
ninja | 忍者 ninja是一个叫 Evan Martin的谷歌工程师开源的一个自定义的构建系统,最早是用于 chrome的构建,Martin给它取名 ninja(忍者)的原因是因为它strikes quickly(快速出击).这是忍者的特点,可惜Martin不了解中国文化,不然叫小李飞刀更合适些.究竟有多块呢? 用Martin自…...
Linux——守护进程化(独立于用户会话的进程)
目录 前言 一、进程组ID与会话ID 二、setsid() 创建新会话 三、daemon 守护进程 前言 在之前,我们学习过socket编程中的udp通信与tcp通信,但是当时我们服务器启动的时候,都是以前台进程的方式启动的,这样很不优雅,…...
安卓开发--按键跳转页面,按键按下变色
前面已经介绍了一个空白按键工程的建立以及响应方式,可以参考这里:安卓开发–新建工程,新建虚拟手机,按键事件响应。 安卓开发是页面跳转是基础!!!所以本篇博客介绍利用按键实现页面跳转&#…...

Ps基础学习笔记
Ps基础学习笔记 Adobe Photoshop(简称Ps)是一款非常流行的图像处理软件,被广泛应用于图像编辑、修饰和设计等领域。作为一名初学者,了解Ps的基础知识是非常重要的,本文将介绍Ps的基本操作和常用工具,帮助你…...
)
spring开发问题总结(持续更新)
开始 最近在做项目的时候,总遇到一些大小不一,奇形怪状的问题。 现在终于有时间来总结一下遇到的问题,以备复习之用。 以下提到的问题经过简化,不代表任何项目代码或问题。 问题1:未完成任务状态搜索结果有误&#x…...

Android 状态栏WiFi图标的显示逻辑
1. 状态栏信号图标 1.1 WIFI信号显示 WIFI信号在状态栏的显示如下图所示 当WiFi状态为关闭时,状态栏不会有任何显示。当WiFi状态打开时,会如上图所示,左侧表示有可用WiFi,右侧表示当前WiFi打开但未连接。 当WiFi状态连接时&#x…...

更改 DeepXDE 的后端
DeepXDE 库为科学计算和工程优化等领域提供了深度学习方法,是一个非常有用的工具。其中一个重要的功能是它允许用户自定义后端。在本文中,我们将指导如何更改 DeepXDE 的后端,并且验证更改是否成功。 更改 DeepXDE 的后端 DeepXDE 支持多种…...
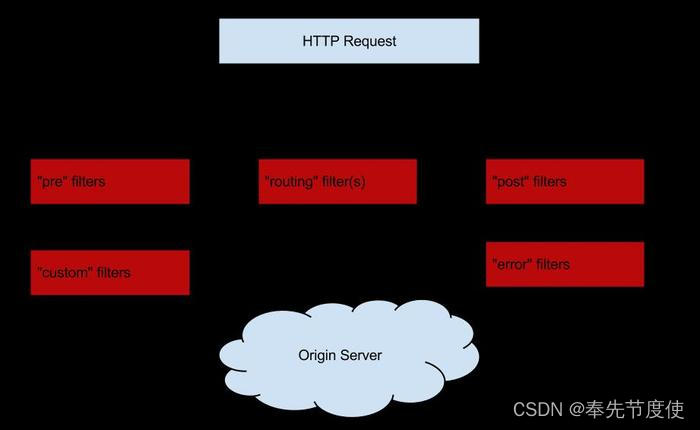
SpringBoot之Zuul服务
概述 Spring Cloud Netflix zuul组件是微服务架构中的网关组件,Zuul作为统一网关,是所有访问该平台的请求入口,核心功能是路由和过滤。 目前公司业务就是基于Zuul搭建的网关服务,且提供的服务包括转发请求(路由)、黑名单IP访问拦截、URL资源访问时的权限拦截、统一访问日志记…...

Go-变量
可以理解为一个昵称 以后这个昵称就代指这些信息 var sg string "czy" 声明赋值 package mainimport "fmt"func main() {var sg string "陈政洋"fmt.Println(sg)var age int 73fmt.Println(age)var flag bool truefmt.Println(flag) } …...
【CTF-Crypto】RSA-选择明密文攻击 一文通
RSA:选择明密文攻击 关于选择明/密文攻击,其实这一般是打一套组合拳的,在网上找到了利用的思路,感觉下面这个题目是真正将这个问题实现了,所以还是非常棒的一道题,下面先了解一下该知识点:(来自…...
 和 torch.repeat())
Pytorch基础:torch.expand() 和 torch.repeat()
在torch中,如果要改变某一个tensor的维度,可以利用view、expand、repeat、transpose和permute等方法,这里对这些方法的一些容易混淆的地方做个总结。 expand和repeat函数是pytorch中常用于进行张量数据复制和维度扩展的函数,但其…...

如何正确安装Scrapy 2.6.1并解决常见的Python环境问题
在配置Python环境和安装包时,常常会遇到版本冲突和路径问题,特别是当系统中存在多个Python版本时。本文将指导你如何在CentOS系统中正确使用pip3安装Scrapy 2.6.1,并解决一些常见的环境问题。 步骤1: 确认和升级 pip3 确认 pip3 的版本&…...
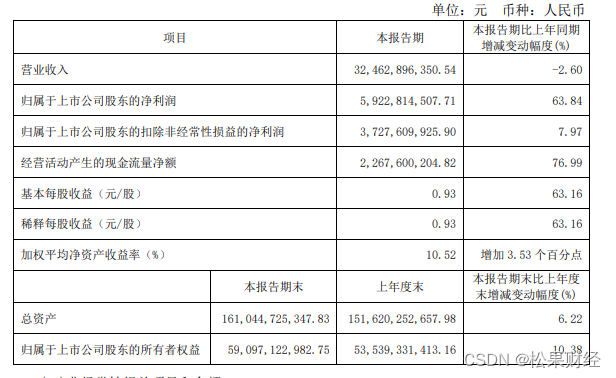
阵痛中的乳业产业,何时才能成为下一个啤酒产业?
说起饮品,近年来中国啤酒业中各大品牌齐齐聚焦高端化的趋势绝对值得一提。然而,与之相反,国内乳业却是仍未进入高端化阶段,甚至陷入了周期底部中。 图源:中国圣牧财报 增收降利 牧企承受巨大的供需缺口压力 从产业链…...

关于模型参数融合的思考
模型参数融合通常指的是在训练过程中或训练完成后将不同模型的参数以某种方式结合起来,以期望得到更好的性能。这种融合可以在不同的层面上进行,例如在神经网络的不同层之间,或者是在完全不同的模型之间。模型参数融合的目的是结合不同模型的…...

Windows MySQL本地服务器设置并导入数据库和数据
文章目录 小结问题及解决导出数据库Windows MySQL本地服务器设置导入数据库和数据 参考 小结 最近需要在本地Windows环境中设置MySQL服务器,并导入数据库和数据,记录过程。 问题及解决 导出数据库 首先需要导出数据库: C:\mysql-8.0.37-…...
豪投巨资,澳大利亚在追逐海市蜃楼吗?
澳大利亚政府正在积极投资于量子计算领域。继2021年向量子技术投资逾1亿澳元后,2023年5月,该国发布了首个国家量子战略,详细阐述了如何把握量子技术的未来及保持全球领先地位。 澳大利亚的国家量子战略概述 原文链接: https://ww…...
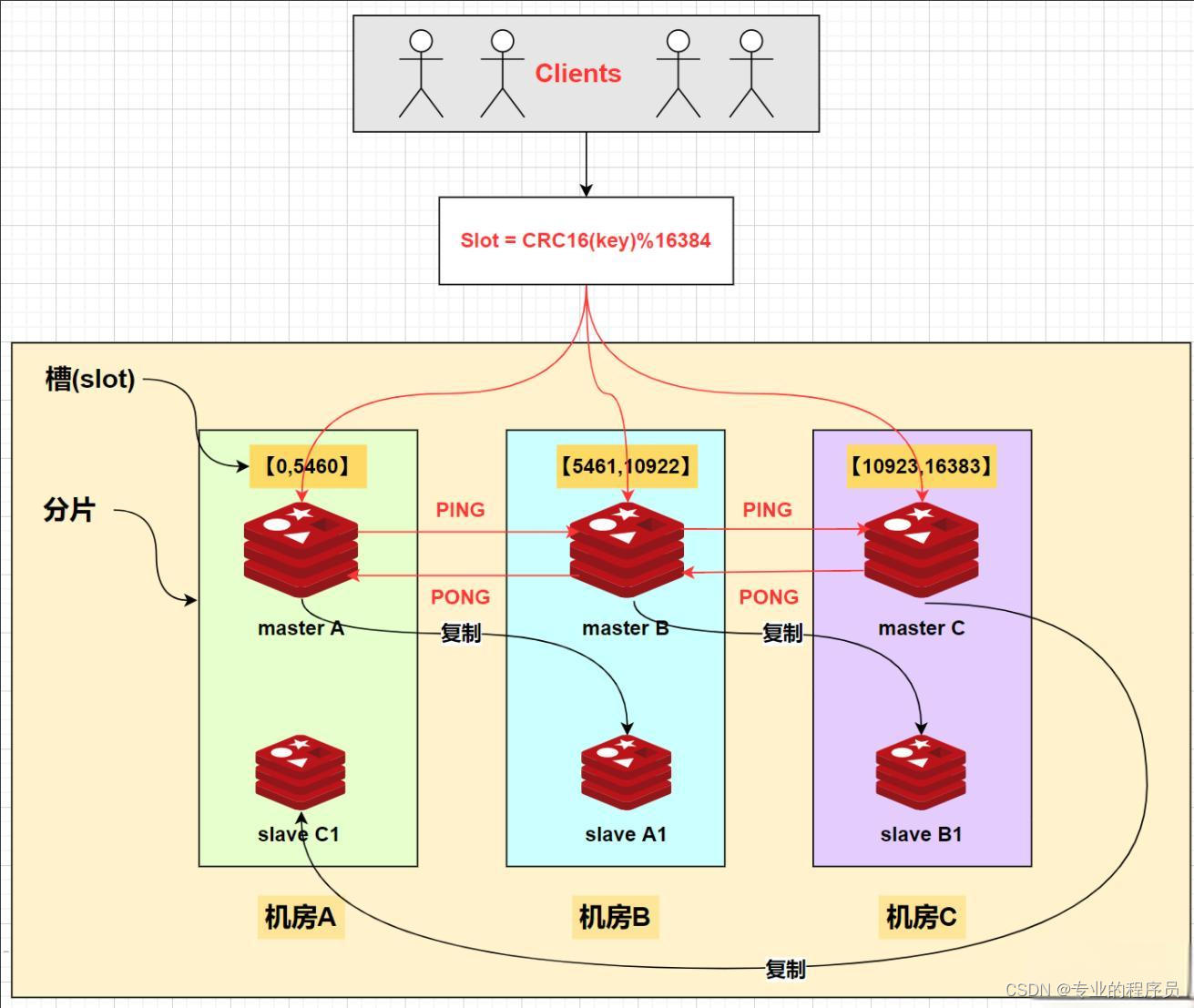
面试集中营—Redis架构篇
一、Redis到底是多线程还是单线程 1、redis6.0版本之前的单线程,是指网络请求I/O与数据的读写是由一个线程完成的; 2、redis6.0版本升级成了多线程,指的是在网络请求I/O阶段应用的多线程技术;而键值对的读写还是由单线程完成的。所…...

05_kafka-整合springboot
文章目录 kafka 整合 springboot pom.xml <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.1.5.RELEASE</version> </parent> <dependencies>&…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...

LabVIEW双光子成像系统技术
双光子成像技术的核心特性 双光子成像通过双低能量光子协同激发机制,展现出显著的技术优势: 深层组织穿透能力:适用于活体组织深度成像 高分辨率观测性能:满足微观结构的精细研究需求 低光毒性特点:减少对样本的损伤…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...