c++多线程2小时速成
简介
c++多线程基础需要掌握这三个标准库的使用:std::thread,std::mutex, andstd::async。
1. Hello, world
#include <iostream>
#include <thread>void hello() { std::cout << "Hello Concurrent World!\n";
}int main()
{std::thread t(hello);t.join();
}- g++编译时须加上
-pthread -std=c++11; - 管理线程的函数和类在
<thread>中声明,而保护共享数据的函数和类在其他头文件中声明; - 初始线程始于
main(),新线程始于hello(); join()使得初始线程必须等待新线程结束后,才能运行下面的语句或结束自己的线程;
2. std::thread
<thread> 和 <pthread> 都是用于多线程编程的库,但是它们针对不同的平台和编程环境。主要区别如下:
-
平台依赖性:
<thread>是 C++11 标准库的一部分,提供了跨平台的多线程支持,因此可以在任何支持 C++11 标准的编译器上使用。<pthread>是 POSIX 线程库,它是在类 Unix 操作系统上的标准库,因此在 Windows 平台上并不直接支持。
-
语言级别:
<thread>是 C++ 标准库的一部分,因此它提供了更加面向对象和现代化的接口,与 C++ 其他部分更加协同。<pthread>是 C 库的一部分,它提供了一组函数来操作线程,使用起来更加类似于传统的 C 风格。
-
使用方式:
<thread>提供了std::thread类,使用起来更加符合 C++ 的面向对象设计,比如通过函数对象、函数指针等方式来创建线程。<pthread>提供了一组函数,比如pthread_create()来创建线程,它需要传入函数指针和参数。
下面来看看标准库thread类:
// 标准库thread类
class thread
{ // class for observing and managing threads
public:class id;typedef void *native_handle_type;thread() _NOEXCEPT{ // construct with no thread_Thr_set_null(_Thr);}template<class _Fn,class... _Args,class = typename enable_if<!is_same<typename decay<_Fn>::type, thread>::value>::type>explicit thread(_Fn&& _Fx, _Args&&... _Ax){ // construct with _Fx(_Ax...)_Launch(&_Thr,_STD make_unique<tuple<decay_t<_Fn>, decay_t<_Args>...> >(_STD forward<_Fn>(_Fx), _STD forward<_Args>(_Ax)...));}~thread() _NOEXCEPT{ // clean upif (joinable())_XSTD terminate();}thread(thread&& _Other) _NOEXCEPT: _Thr(_Other._Thr){ // move from _Other_Thr_set_null(_Other._Thr);}thread& operator=(thread&& _Other) _NOEXCEPT{ // move from _Otherreturn (_Move_thread(_Other));}thread(const thread&) = delete;thread& operator=(const thread&) = delete;void swap(thread& _Other) _NOEXCEPT{ // swap with _Other_STD swap(_Thr, _Other._Thr);}bool joinable() const _NOEXCEPT{ // return true if this thread can be joinedreturn (!_Thr_is_null(_Thr));}void join(){ // join threadif (!joinable())_Throw_Cpp_error(_INVALID_ARGUMENT);// Avoid Clang -Wparentheses-equalityconst bool _Is_null = _Thr_is_null(_Thr);if (_Is_null)_Throw_Cpp_error(_INVALID_ARGUMENT);if (get_id() == _STD this_thread::get_id())_Throw_Cpp_error(_RESOURCE_DEADLOCK_WOULD_OCCUR);if (_Thrd_join(_Thr, 0) != _Thrd_success)_Throw_Cpp_error(_NO_SUCH_PROCESS);_Thr_set_null(_Thr);}void detach(){ // detach threadif (!joinable())_Throw_Cpp_error(_INVALID_ARGUMENT);_Thrd_detachX(_Thr);_Thr_set_null(_Thr);}id get_id() const _NOEXCEPT{ // return id for this threadreturn (_Thr_val(_Thr));}static unsigned int hardware_concurrency() _NOEXCEPT{ // return number of hardware thread contextsreturn (_Thrd_hardware_concurrency());}native_handle_type native_handle(){ // return Win32 HANDLE as void *return (_Thr._Hnd);}通过查看thread类的公有成员,我们得知:
- thread类包含三个构造函数:一个默认构造函数(什么都不做)、一个接受可调用对象及其参数的explicit构造函数(参数可能没有,这时相当于转换构造函数,所以需要定义为explicit)、和一个移动构造函数;
- 析构函数会在thread对象销毁时自动调用,如果销毁时thread对象还是joinable,那么程序会调用terminate()终止进程;
- thread类没有拷贝操作,只有移动操作,即thread对象是可移动不可拷贝的,这保证了在同一时间点,一个thread实例只能关联一个执行线程;
- swap函数用来交换两个thread对象管理的线程;
- joinable函数用来判断该thread对象是否是可加入的;
- join函数使得该thread对象管理的线程加入到原始线程,只能使用一次,并使joinable为false;
- detach函数使得该thread对象管理的线程与原始线程分离,独立运行,并使joinable为false;
get_id返回线程标识;hardware_concurrency返回能同时并发在一个程序中的线程数量,当系统信息无法获取时,函数也会返回0。注意其是static修饰的,应该这么使用–std::thread::hardware_concurrency()。
由于thread类只有一个有用的构造函数,所以只能使用可调用对象来构造thread对象。
可调用对象包括:
- 函数
- 函数指针
- lambda表达式
- bind创建的对象
- 重载了函数调用符的类
3. join和detach
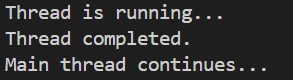
使用 join() 的示例:
#include <iostream>
#include <thread>void threadFunction() {std::cout << "Thread is running..." << std::endl;// Simulate some workstd::this_thread::sleep_for(std::chrono::seconds(3));std::cout << "Thread completed." << std::endl;
}int main() {std::thread t(threadFunction);// 等待线程完成t.join();std::cout << "Main thread continues..." << std::endl;return 0;
}
在这个例子中,join() 方法用于等待线程 t 完成。主线程会被阻塞,直到线程 t 执行完毕。
运行结果:
使用 detach() 的示例:
#include <iostream>
#include <thread>void threadFunction() {std::cout << "Thread is running..." << std::endl;// Simulate some workstd::this_thread::sleep_for(std::chrono::seconds(3));std::cout << "Thread completed." << std::endl;
}int main() {std::thread t(threadFunction);// 分离线程,使得线程可以在后台运行t.detach();std::cout << "Main thread continues..." << std::endl;// 由于线程被分离,这里不等待线程完成,直接返回return 0;
}
在这个例子中,detach() 方法用于将线程 t 分离,使得线程可以在后台运行而不受主线程的控制。因此,主线程不会被阻塞,直接继续执行。
![]() 然后main已经结束
然后main已经结束
4. 线程间共享数据
条件竞争(race condition):当一个线程A正在修改共享数据时,另一个线程B却在使用这个共享数据,这时B访问到的数据可能不是正确的数据,这种情况称为条件竞争。
数据竞争(data race):一种特殊的条件竞争,并发的去修改一个独立对象。
多线程的一个关键优点(key benefit)是可以简单的直接共享数据,但如果有多个线程拥有修改共享数据的权限,那么就会很容易出现数据竞争(data race)。
std::mutex
C++保护共享数据最基本的技巧是使用互斥量(mutex):访问共享数据前,使用互斥量将相关数据锁住,当访问结束后,再将数据解锁。当一个线程使用特定互斥量锁住共享数据时,其他线程要想访问锁住的数据,必须等到之前那个线程对数据进行解锁后,才能进行访问。
在C++中使用互斥量
- 创建互斥量:即构建一个
std::mutex实例; - 锁住互斥量:调用成员函数
lock(); - 释放互斥量:调用成员函数
unlock(); - 由于
lock()与unlock()必须配对,就像new和delete一样,所以为了方便和异常处理,C++标准库也专门提供了一个模板类std::lock_guard,其在构造时lock互斥量,析构时unlock互斥量。
5. 异步好帮手:std::async
你可以使用 std::async 来在后台执行一个函数,并且可以通过 std::future 对象来获取函数的返回值。
#include <iostream>
#include <future>int taskFunction() {return 42;
}int main() {// 使用 std::async 异步执行任务std::future<int> future = std::async(std::launch::async, taskFunction);// 获取任务的结果int result = future.get();std::cout << "Result: " << result << std::endl;return 0;
}
另一个例子:
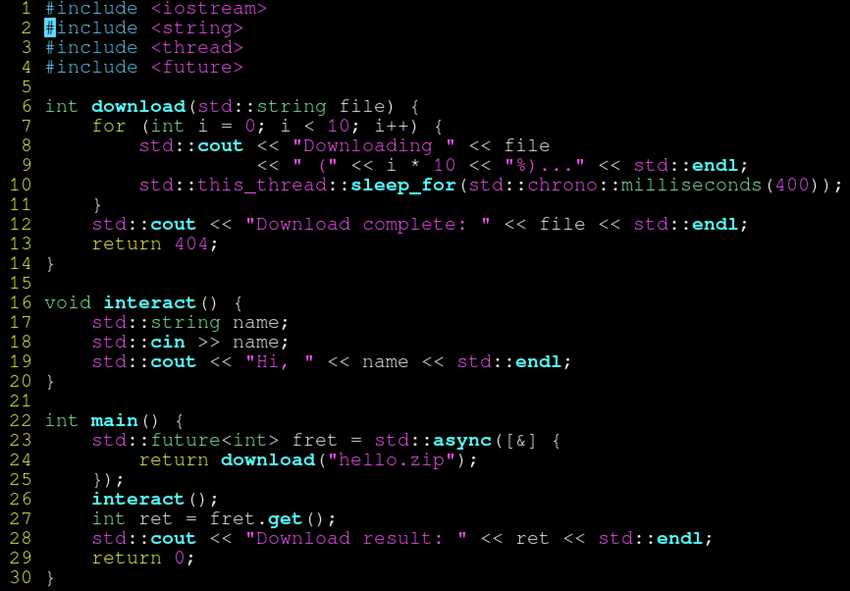
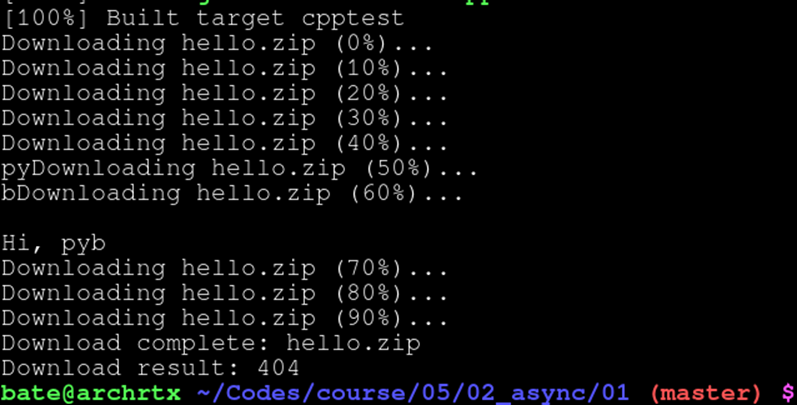
运行结果:
6. 应用例子:线程池(thread pool)
如果你是一个程序员,那么你大部分时间会待在办公室里,但是有时候你必须外出解决一些问题,如果外出的地方很远,就会需要一辆车,公司是不可能为你专门配一辆车的,但是大多数公司都配备了一些公用的车辆。你外出的时候预订一辆,回来的时候归还一辆;如果某一天公用车辆用完了,那么你只能等待同事归还之后才能使用。
线程池(thread pool)与上面的公用车辆类似:在大多数情况下,为每个任务都开一个线程是不切实际的(因为线程数太多以致过载后,任务切换会大大降低系统处理的速度),线程池可以使得一定数量的任务并发执行,没有执行的任务将被挂在一个队列里面,一旦某个任务执行完毕,就从队列里面取一个任务继续执行。
线程池通常由以下几个组件组成:
- 1.任务队列(Task Queue):用于存储待执行的任务。当任务提交到线程池时,它们被放置在任务队列中等待执行。
- 2.线程池管理器(Thread Pool Manager):负责创建、管理和调度线程池中的线程。它控制着线程的数量,可以动态地增加或减少线程的数量,以适应不同的工作负载。
- 3.工作线程(Worker Threads):线程池中的实际执行单元。它们不断地从任务队列中获取任务并执行。
- 4.任务接口(Task Interface):定义了要执行的任务的接口。通常,任务是以函数或可运行对象的形式表示。
使用线程池的好处
-
不采用线程池时:
创建线程 -> 由该线程执行任务 -> 任务执行完毕后销毁线程。即使需要使用到大量线程,每个线程都要按照这个流程来创建、执行与销毁。
虽然创建与销毁线程消耗的时间 远小于 线程执行的时间,但是对于需要频繁创建大量线程的任务,创建与销毁线程 所占用的时间与CPU资源也会有很大占比。
为了减少创建与销毁线程所带来的时间消耗与资源消耗,因此采用线程池的策略:
程序启动后,预先创建一定数量的线程放入空闲队列中,这些线程都是处于阻塞状态,基本不消耗CPU,只占用较小的内存空间。
接收到任务后,线程池选择一个空闲线程来执行此任务。
任务执行完毕后,不销毁线程,线程继续保持在池中等待下一次的任务。
线程池所解决的问题:
(1) 需要频繁创建与销毁大量线程的情况下,减少了创建与销毁线程带来的时间开销和CPU资源占用。(省时省力)
(2) 实时性要求较高的情况下,由于大量线程预先就创建好了,接到任务就能马上从线程池中调用线程来处理任务,略过了创建线程这一步骤,提高了实时性。(实时)
简单的ThreadPool 类实现
参考GitHub - progschj/ThreadPool: A simple C++11 Thread Pool implementation
ThreadPool.h:
#ifndef THREAD_POOL_H
#define THREAD_POOL_H#include <vector>
#include <queue>
#include <memory>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <future>
#include <functional>
#include <stdexcept>class ThreadPool {
public:ThreadPool(size_t);template<class F, class... Args>auto enqueue(F&& f, Args&&... args) -> std::future<typename std::result_of<F(Args...)>::type>;~ThreadPool();
private:// need to keep track of threads so we can join themstd::vector< std::thread > workers;// the task queuestd::queue< std::function<void()> > tasks;// synchronizationstd::mutex queue_mutex;std::condition_variable condition;bool stop;
};// the constructor just launches some amount of workers
inline ThreadPool::ThreadPool(size_t threads): stop(false)
{for(size_t i = 0;i<threads;++i)workers.emplace_back([this]{for(;;){std::function<void()> task;{std::unique_lock<std::mutex> lock(this->queue_mutex);this->condition.wait(lock,[this]{ return this->stop || !this->tasks.empty(); });if(this->stop && this->tasks.empty())return;task = std::move(this->tasks.front());this->tasks.pop();}task();}});
}// add new work item to the pool
template<class F, class... Args>
auto ThreadPool::enqueue(F&& f, Args&&... args) -> std::future<typename std::result_of<F(Args...)>::type>
{using return_type = typename std::result_of<F(Args...)>::type;auto task = std::make_shared< std::packaged_task<return_type()> >(std::bind(std::forward<F>(f), std::forward<Args>(args)...));std::future<return_type> res = task->get_future();{std::unique_lock<std::mutex> lock(queue_mutex);// don't allow enqueueing after stopping the poolif(stop)throw std::runtime_error("enqueue on stopped ThreadPool");tasks.emplace([task](){ (*task)(); });}condition.notify_one();return res;
}// the destructor joins all threads
inline ThreadPool::~ThreadPool()
{{std::unique_lock<std::mutex> lock(queue_mutex);stop = true;}condition.notify_all();for(std::thread &worker: workers)worker.join();
}#endifmain.cpp:
#include <iostream>
#include <vector>
#include <chrono>#include "ThreadPool.h"int main()
{ThreadPool pool(4);std::vector< std::future<int> > results;for(int i = 0; i < 8; ++i) {results.emplace_back(pool.enqueue([i] {std::cout << "hello " << i << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1));std::cout << "world " << i << std::endl;return i*i;}));}for(auto && result: results)std::cout << result.get() << ' ';std::cout << std::endl;return 0;
}Basic usage:
// create thread pool with 4 worker threads
ThreadPool pool(4);// enqueue and store future
auto result = pool.enqueue([](int answer) { return answer; }, 42);// get result from future
std::cout << result.get() << std::endl;
这个 ThreadPool 类是一个简单的线程池实现,用于管理多线程任务的执行。下面逐步解释每个部分的功能:
-
成员变量:
workers:一个std::vector,存储所有工作线程。这些线程在构造函数中创建,并在析构函数中被回收。tasks:一个std::queue,用于存储等待执行的任务。queue_mutex:一个互斥锁,用于保护任务队列,防止多个线程同时访问。condition:条件变量,用于线程之间的协调,特别是在任务的等待和通知上。stop:一个布尔值,用于告知线程何时停止执行,通常在析构函数中设置为true。
-
构造函数:
- 构造函数初始化
stop为false,并创建指定数量的工作线程。每个线程执行一个无限循环,等待直到有任务可执行或接收到停止信号。线程通过锁定互斥锁和等待条件变量来同步,只有在有任务可执行或需要停止时才继续运行。 [this]: 这是一个 lambda 表达式,捕获当前ThreadPool对象的this指针,使得线程能够访问类成员变量如queue_mutex、condition和tasks。for(;;): 这是一个无限循环,用于不断地处理任务。线程将一直在这个循环中运行,直到接收到停止信号。std::function<void()> task;: 定义一个std::function对象,用来存储从任务队列中取出的任务。std::unique_lock<std::mutex> lock(this->queue_mutex);: 使用互斥锁保护代码块,确保在访问共享资源(任务队列)时不会有其他线程同时访问。this->condition.wait(lock, [this]{ return this->stop || !this->tasks.empty(); });: 线程通过条件变量等待任务的到来或停止信号的到来。condition.wait自动释放锁并进入等待状态,直到其他线程调用notify_one()或notify_all()时被唤醒,并在唤醒后重新获取锁。if(this->stop && this->tasks.empty()) return;: 如果接收到停止信号,并且任务队列为空,则退出线程的执行函数,结束线程的运行。task = std::move(this->tasks.front()); this->tasks.pop();: 将队列前端的任务移动到局部变量task中,并从队列中移除该任务。task();: 执行从队列中取出的任务。
- 构造函数初始化
-
enqueue() 方法:
- 这个
enqueue方法提供了一种强大的机制来将任何可调用的任务安排到线程池中,并通过std::future提供了一种获取异步执行结果的方法。 template<class F, class... Args>: 这是一个模板声明,表示这个函数可以接受任何类型的函数F和任意数量和类型的参数Args...。auto ThreadPool::enqueue(F&& f, Args&&... args):enqueue函数接受一个可调用对象f和它的参数args...,这些参数都是通过完美转发(std::forward)传递的,以保持其值类别(lvalue 或 rvalue)。-> std::future<typename std::result_of<F(Args...)>::type>: 函数的返回类型是std::future,其中包含了函数f执行后的返回类型。std::result_of<F(Args...)>::type在 C++17 之前用于推断函数的返回类型。using return_type = typename std::result_of<F(Args...)>::type;: 这一行定义了return_type,即函数f的返回类型。std::make_shared< std::packaged_task<return_type()> >(...): 创建一个std::packaged_task对象,该对象封装了函数f及其参数,并用std::shared_ptr管理。std::packaged_task被设计用来执行并保存其返回值(或异常),这个返回值可以通过与之关联的std::future对象获得。std::bind(std::forward<F>(f), std::forward<Args>(args)...): 使用std::bind将函数f和它的参数绑定起来,通过std::forward完美转发参数,确保参数的正确传递(包括保持其lvalue或rvalue性质)。std::future<return_type> res = task->get_future();: 从std::packaged_task获取一个std::future对象,该对象将在任务完成时保存结果。std::unique_lock<std::mutex> lock(queue_mutex);: 在修改任务队列之前,先锁定互斥量以确保线程安全。if(stop) throw std::runtime_error("enqueue on stopped ThreadPool");: 如果线程池已经停止,则不允许再添加新任务,抛出异常。tasks.emplace([task](){ (*task)(); });: 将任务作为一个 lambda 表达式添加到任务队列。这个 lambda 包裹了std::packaged_task的调用。condition.notify_one();: 通知一个正在等待的线程(如果有的话),告诉它现在有新的任务可以执行。return res;: 返回与任务关联的std::future对象,允许调用者获取异步执行的结果。
- 这个
-
析构函数:
- 析构函数会首先设置
stop标志位为true,然后通过条件变量condition.notify_all()通知所有等待的工作线程。 - 最后,使用
join()方法等待所有工作线程执行完毕
- 析构函数会首先设置
应用场景:
-
Web服务器: Web服务器通常需要处理大量并发的客户端请求。每个请求可能包括计算任务,如处理HTTP请求、访问数据库或生成动态内容。线程池可以用来管理这些并发任务,提高响应速度和资源利用率。
-
数据处理: 在数据密集型应用程序中,如数据分析或图像处理,任务通常可以并行处理。使用线程池可以将数据分块处理,每个线程处理一块数据,从而加速整体处理速度。
-
异步I/O操作: 在需要执行大量异步I/O操作的应用中,例如文件处理或网络通信,线程池可以用来管理这些异步操作,提高处理效率。
-
GUI应用程序: 图形用户界面(GUI)应用程序需要快速响应用户交互,同时执行后台任务如加载数据或执行计算。线程池可以在后台处理这些任务,保持界面的响应性和流畅性。
示例代码
假设我们正在开发一个简单的图片处理应用,需要对一组图片进行大小调整。使用线程池可以并行处理每张图片,提高处理速度。
#include <iostream>
#include <vector>
#include <chrono>
#include "ThreadPool.h"// 假设的图片处理函数,这里只是简单模拟处理时间
void processImage(int imgSize) {std::this_thread::sleep_for(std::chrono::milliseconds(100)); // 模拟耗时操作std::cout << "Processed image of size " << imgSize << " in thread " << std::this_thread::get_id() << std::endl;
}int main() {ThreadPool pool(4); // 创建一个有4个工作线程的线程池std::vector<std::future<void>> results;std::vector<int> imageSizes = {1024, 2048, 512, 128, 256, 768}; // 各种大小的图片for (int size : imageSizes) {results.emplace_back(pool.enqueue(processImage, size));}// 等待所有图片处理完成for (auto &&result : results) {result.get(); // 获取任务结果(这里实际没有返回值)}std::cout << "All images processed." << std::endl;return 0;
}
在这个示例中,我们创建了一个线程池并并行处理了多张图片。每张图片的处理是通过调用 processImage 函数完成的,该函数接受一个代表图片大小的整数参数。我们通过线程池的 enqueue 方法提交了多个任务,并使用 std::future<void> 来跟踪这些任务的完成状态。处理完成后,主函数等待所有任务完成,然后输出完成信息。
参考:
https://chorior.github.io/2017/04/24/C++-thread-basis/#managing_threads
C++ Concurrency In Action,Anthony Williams
GitHub - progschj/ThreadPool: A simple C++11 Thread Pool implementationx
线程池代码解读:C++线程池实现解析_template<class f,class...args>-CSDN博客
相关文章:
c++多线程2小时速成
简介 c多线程基础需要掌握这三个标准库的使用:std::thread,std::mutex, andstd::async。 1. Hello, world #include <iostream> #include <thread>void hello() { std::cout << "Hello Concurrent World!\n"; }int main() {std::th…...

大模型日报2024-05-09
大模型日报 2024-05-09 大模型资讯 NVIDIA推出VILA视觉语言模型,开启边缘AI 2.0时代 摘要: NVIDIA最新推出的VILA家族视觉语言模型代表了边缘AI 2.0的到来。这些模型具备高级视觉推理能力,能够在低功耗的边缘设备上运行,为各种应用带来更智能…...

QGraphicsView实现简易地图11『指定层级-定位坐标』
前文链接:QGraphicsView实现简易地图10『自适应窗口大小』 提供一个地图初始化函数,指定地图显示的中心点和地图缩放层级 能够让地图显示某一层级的瓦片,并将中心点坐标显示在视图中心。 1、动态演示效果 7级地图-大连-老虎滩 定位到 8级地图…...
UE5 蓝图入门
基础节点创建: 常量: 按住 1 ,点击鼠标左键,创建常量 二维向量: 按住 2 ,点击鼠标左键,创建二维向量 三维向量: 按住 3 ,点击鼠标左键 乘法: 按住 m 键…...

英语单词学习
house of worship:宗教场所 dote: 喜爱 coffin:棺材 coffeine:咖啡因 expedient:权宜的 buster:破坏者 procrastinate: 拖延 gourmet:美食家 expound:阐述 narcissist:自我陶醉 assassinate:暗杀 salvage: 挽救 savage: 凶猛的 ulcer: 溃疡 obituary:讣告 arbitrary:武断的 abu…...

使用Python编写自动化测试代码规范整理
大家好,我们平时在写自动化测试脚本或者性能测试脚本时,需要注意代码规范,提高代码的可读性与维护性,之前给大家分享过pycharm的两个插件,大家可以参考:Pycharm代码规范与代码格式化插件安装 本文中主要从自…...

实验七 SJK数据库定义与操纵
实验题目 实验七 SJK数据库定义与操纵 实验时间 2023.5.17 实验地点 软件工程基础实验室 实验课时 2 实验目的 了解并掌握数据库定义与操纵的知识并能熟练应用 实验要求 熟练掌握和使用PL-SQL建立数据库基本表,使用PL/SQL developer操作数据库&a…...

Win10环境下yolov8快速配置与测试-详细
0.0 说明 参考黄家驹的Win10 环境下YOLO V8部署,遇到一些问题,并解决实现,记录如下: 斜线字体是原博客中的创作 0.1 参考链接 https://blog.csdn.net/m0_72734364/article/details/128865904 1 Windows10下yolov8 tensorrt模型加速部署 …...

C++面向对象学习笔记一
本文阅读下述文章,顺手记录学习《C面向对象程序设计》✍千处细节、万字总结(建议收藏)_c面向对象程序设计千处细节-CSDN博客 目录 前言 正文 浅拷贝和深拷贝 向函数传递对象 静态数据成员和静态成员函数 友元 友元函数 1、将非成员函数声明…...
C++容器之vector类
目录 1.vector的介绍及使用1.1vector的介绍1.2vector的使用1.2.1 vector的定义1.2.2 vector iterator 的使用1.2.3 vector 空间增长问题1.2.4 vector 增删查改1.2.5vector 迭代器失效问题1.2.6 vector 在OJ中的使用。 2.vector深度剖析及模拟实现2.1 std::vector的核心框架接口…...

什么是MVCC?
MVCC是一种数据库的并发控制策略,就是为了解决多个用户同时访问数据库修改同一数据所造成的问题,如何解决这个问题了? 就是通过创建同一个数据的不同的版本,通过创建时间的不同,最后进行数据合并,其就不用给数据库上锁了,其实数据库的锁,虽然说InnoDB已经非常牛逼了,可以使用行…...

数据结构队列学习
引入 众说周知,在队列的题目中,队头指针(front)和队尾指针(rear)有两种指示方法。 (1)队头指针 ①指向队头元素 ②指向队头元素元素的前一个位置 (2)队尾指针 ①指向队尾元素 ②指向队尾元素的后一个位置 指…...
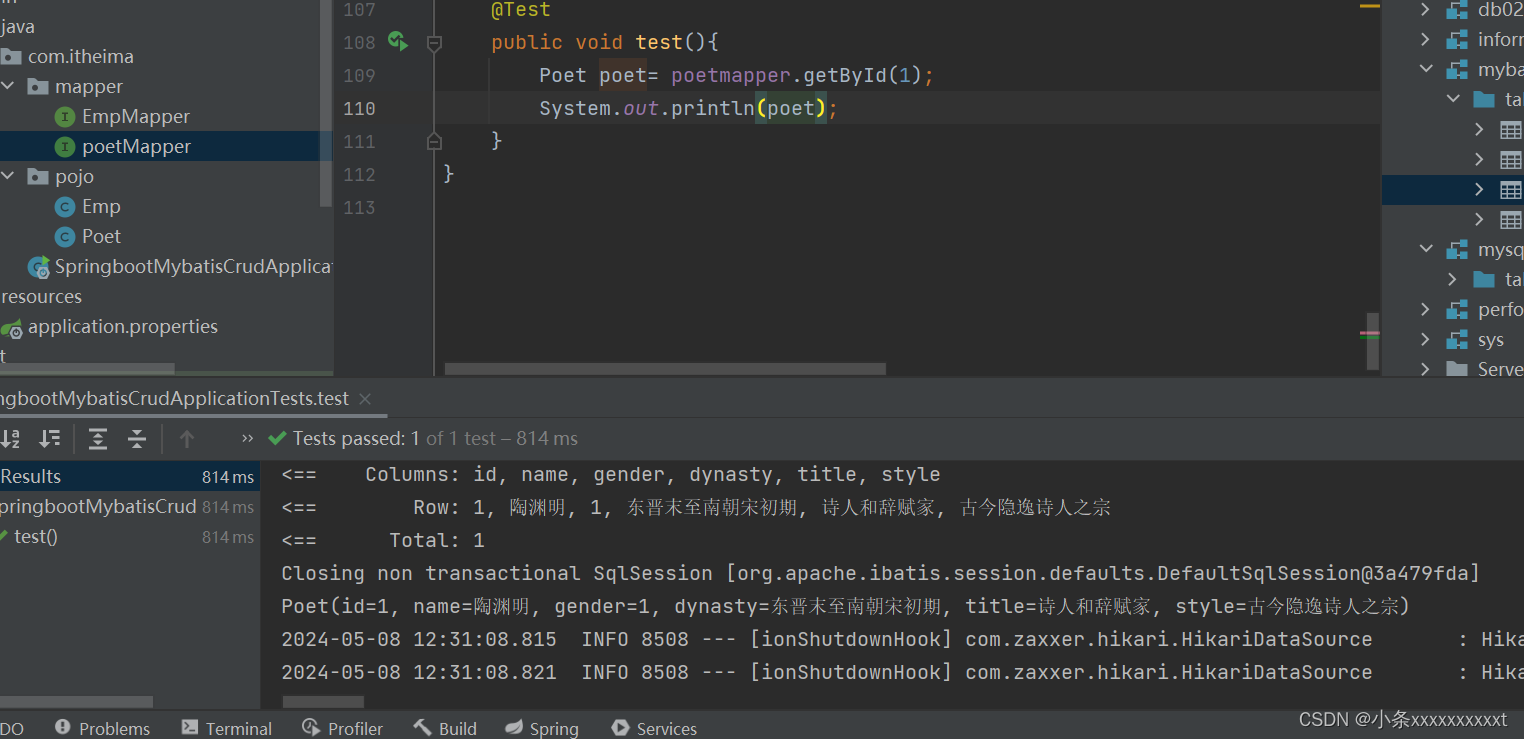
Javaweb第五次作业
poet数据库sql语言 create table poet(id int unsigned primary key auto_increment comment ID,name varchar(10) not null comment 姓名,gender tinyint unsigned not null comment 性别, 说明: 1 男, 2 女,dynasty varchar(10) not null comment朝代,title varchar(20) not…...

BetterMouse for Mac激活版:鼠标增强软件
BetterMouse for Mac是一款鼠标增强软件,旨在取代笨重的、侵入性的和耗费资源的鼠标驱动程序,如罗技选项。它功能丰富,重量轻,效率优化,而且完全隐私安全,试图满足你在MacOS上使用第三方鼠标的所有需求。 B…...

红米1s 刷入魔趣 (Mokee)ROM(Android 7.1)
目录 背景准备工具硬件(自己准备)软件(我会在文末提供链接) 刷机步骤1. 重启电脑2. 安装驱动3. 刷入TWRP4. 清空数据5. 刷入魔趣6. 开机 结尾下载链接 本文由Jzwalliser原创,发布在CSDN平台上,遵循CC 4.0 B…...

MySQL中的事务隔离级别
事务隔离级别 未提交读(Read uncommitted)是最低的隔离级别。通过名字我们就可以知道,在这种事务隔离级别下,一个事务可以读到另外一个事务未提交的数据。这种隔离级别下会存在幻读、不可重复读和脏读的问题。提交读(Read committed)也可以翻译成读已提交…...

多线程应用实战
文章目录 1、如何实现多线程交替打印字母和数字,打印效果:A1B2C3D4...AutomicBlockingQueueReentrantLockLockSupportSynchronizedWaitNotifyTransferQueueWay 2、实现多个线程顺序打印abc3、实现阻塞队列 1、如何实现多线程交替打印字母和数字ÿ…...

selenium解放双手--记某电力学校的刷课脚本
免责声明:本文仅做技术交流与学习... 重难点: 1-对目标网站的html框架具有很好的了解,定位元素,精准打击. 2-自动化过程中窗口操作的转换. 前置知识: python--selenium模块的操作使用 前端的html代码 验证码自动化操作 Chrome & Chromedriver : Chrome for Testing ava…...

JDK 17有可能代替 JDK 8 吗
不好说,去 Oracle 化是很多公司逐步推进的政策。 JVM 有 OpenJ9。很多公司可能会用 IBM 的版本。 JDK 这东西,能用就不会升级。 JDK 太基础了,决定了后面的很多 jar 的版本。 https://www.ossez.com/t/jdk-17-jdk-8/14102...

代码随想录算法训练营第36期DAY23
DAY23 530二叉搜索树的最小绝对差 /** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) : val(x), left(null…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...