LLM——用于微调预训练大型语言模型(LLM)的GPU内存优化与微调
前言
GPT-4、Bloom 和 LLaMA 等大型语言模型(LLM)通过扩展至数十亿参数,实现了卓越的性能。然而,这些模型因其庞大的内存需求,在部署进行推理或微调时面临挑战。这里将探讨关于内存的优化技术,旨在估计并优化在 LLM 推理以及在多样化硬件配置上进行微调过程中的内存消耗。
首先,需要认识到大型语言模型在运行时的内存消耗主要受以下几个因素影响:
- 模型规模:模型拥有的参数数量直接决定了其对内存的需求。参数数量越多,模型文件体积越大,加载和执行模型所需的内存也就越多。
- 输入数据量:处理的输入数据量增加,也会相应增加内存的使用。例如,处理更长的文本序列或更复杂的查询任务将需要更多的内存资源。
- 并行计算:虽然并行处理可以加快模型的执行速度,但同时也可能导致内存消耗的增加,因为每个处理核心可能都需要存储模型的一部分数据。
- 优化策略:采用模型剪枝、量化或知识蒸馏等技术可以有效减少模型的大小,从而降低其内存占用。
内存计算
加载大型语言模型(LLM)所需的内存量主要受模型参数的数量和参数存储所使用的数值精度的影响。在推理过程中,内存占用主要受以下两个因素影响:
- 模型参数:加载模型本身所需的内存量。
- 激活张量:在推理过程中,模型的每层都会产生临时的激活张量,这些张量同样需要占用内存。
推理期间的峰值内存使用量可以粗略地估算为加载模型参数所需的内存与激活张量所需的内存之和。
以下估算所需内存的量示例:
- 对于以32位浮点数(即单精度浮点数)存储的模型,每十亿(Billion)参数大约需要4X GB的VRAM。
- 对于以16位浮点数(如bfloat16或float16)存储的模型,每十亿参数大约需要2X GB的VRAM。
以拥有175B(即175十亿)参数的GPT-3模型为例,若采用bfloat16精度,则加载该模型将需要大约350GB的VRAM。截至目前,市面上最大的商用GPU,如NVIDIA的A100或H100,通常仅提供最高80GB的VRAM。因此,为了有效地部署这些庞大的模型,必须采用张量并行(tensor parallelism)和模型并行(model parallelism)等技术。
量化推理内存
这里使用 OctoCode 模型来量化推理的内存需求,该模型具有大约 15 亿个 bfloat16 格式的参数(约 31GB)。将使用transformers加载模型并生成文本:
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder",
torch_dtype=torch.bfloat16,
device_map="auto",
pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
prompt = "Question: Please write a Python function to convert bytes to gigabytes.nnAnswer:"
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
def bytes_to_gigabytes(bytes):
return bytes / 1024 / 1024 / 1024
bytes_to_gigabytes(torch.cuda.max_memory_allocated())
输出:
29.0260648727417
峰值GPU内存使用量大约为29GB,这一数值与我们估算的用于加载bfloat31格式模型参数所需的16GB内存大致相符。通过量化技术优化推理内存使用,尽管bfloat16是训练大型语言模型(LLM)时常用的数值精度,但研究人员已经发现,将模型权重量化为更低精度的数据类型,例如8位整数(int8)或4位整数,可以在最小化推理任务精度损失的同时显著减少内存使用量。这种方法特别适用于文本生成等场景,其中模型的输出主要由其生成的文本序列的质量来评估,而不是由模型的精确数值精度决定。
bfloat16、int8、int4是数据类型的缩写,它们用于在机器学习和深度学习中以不同的精度表示数值。
- bfloat16 (Brain Floating Point 16-bit):bfloat16是一种浮点数格式,提供了与32位单精度浮点数(fp32)相似的动态范围,但只使用了16位的存储空间。它在深度学习中被用于减少模型的内存占用,同时尽量保持较高的数值精度。
- int8 (8-bit Integer):int8是一种整数格式,能够表示-128到127的整数值。在深度学习模型的量化中,int8常用于减少模型大小和内存需求,加快推理速度,但相比于浮点数,它会有一定的精度损失。
- int4 (4-bit Integer):int4是一种低精度的整数格式,用于表示较小的整数值。在量化中使用int4可以进一步减少模型的内存占用,但这种精度的降低可能会导致较大的精度损失,适用于对精度要求不高的应用场景。
在深度学习中,从标准的32位单精度浮点数(fp32)到更低精度的格式(如bfloat16、int8或int4)的转换,可以在模型部署时显著减少内存占用和提高计算速度,但这种转换需要在模型精度和性能之间做出权衡。量化是实现模型优化以适应不同硬件平台的常用技术之一。
量化的优势在于它减少了模型文件的大小,从而降低了加载模型到内存中所需的空间。此外,量化还可以减少模型在推理时的计算需求,因为较低精度的运算通常比高精度的运算更快、更高效。
让我们看看 OctoCode 模型的 8 位和 4 位量化所节省的内存:
# 8-bit quantization
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True,
pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
bytes_to_gigabytes(torch.cuda.max_memory_allocated())</pre>
输出:
`15.219234466552734`
#4-bit quantization
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True,
low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
bytes_to_gigabytes(torch.cuda.max_memory_allocated())
输出:
9.543574333190918
通过采用8位量化,模型的内存需求可以从31GB降低到15GB,而进一步采用4位量化可以将内存需求减少至仅9.5GB。这样的内存优化使得在消费级GPU,如具有3090GB VRAM的RTX 15,运行拥有24B(即240亿)参数的OctoCode模型成为可能。
然而,需要注意的是,相比于4位或bfloat8(即8位浮点数)精度,更激进的量化策略(例如16位)有时可能会导致模型精度的下降。因此,用户应根据自己的应用场景仔细评估内存节省和准确性之间的权衡。
量化技术是一种强大的工具,它通过显著减少内存占用,使得大型语言模型(LLM)能够在资源受限的环境中部署,这包括云服务器实例、边缘设备,甚至是移动设备。量化不仅有助于降低模型的存储和传输需求,还可以减少模型推理时的计算负载,从而提高运行效率。
量化也会对模型的精度产生一定的影响,具体如下:
- 精度损失:量化过程中将浮点数转换为整数或更低精度的格式,这会导致数值表示的精度降低。模型权重和激活函数的量化可能会导致模型无法精确地表示其原始参数,从而影响模型的性能。
- 过拟合风险:量化可能会改变模型的学习动态,有时会导致过拟合的风险增加。这是因为量化后的模型可能更容易记住训练数据中的噪声,而不是学习泛化的模式。
- 梯度稀疏:在训练过程中使用量化可能会减少梯度的非零值数量,导致梯度稀疏。这可能会影响梯度下降算法的效率,从而影响模型的训练效果。
- 特定层的影响:量化对模型中不同层的影响可能不同。例如,深度学习网络的早期层通常对输入数据进行高度非线性变换,这些层可能对量化更敏感。
- 数据类型选择:选择不同的量化数据类型(如int8、int16、bfloat16等)对精度的影响也不同。一般来说,数据类型的位数越多,量化误差越小,但内存和计算成本也越高。
- 量化感知训练:为了减少量化对精度的负面影响,可以采用量化感知训练(Quantization Aware Training, QAT)。QAT在训练过程中模拟量化,使模型能够适应量化误差,从而在量化后保持较高的精度。
- 量化策略:不同的量化策略(如均匀量化、非均匀量化、逐层量化等)对模型精度的影响也不同。选择合适的量化策略对于在精度和效率之间取得平衡至关重要。
- 任务敏感性:不同的应用任务对模型精度的敏感度不同。例如,一些对精度要求极高的任务(如医疗图像分析)可能不适合使用量化,而其他任务(如语音识别)可能能够容忍一定程度的精度损失。
估计内存进行微调
量化确实是为了高效推理而广泛使用的技术,它通过减少模型参数的数值精度来降低模型的内存占用和加速推理过程。然而,在模型训练阶段,尤其是在微调大型语言模型(LLM)时,张量并行性和模型并行性等技术对于管理内存需求同样至关重要。
微调是指在特定任务的数据集上对预训练模型进行额外的训练,以使其更好地适应该任务。由于以下原因,微调期间的峰值内存消耗通常会比推理时高出3-4倍:
- 渐变:在训练过程中,需要存储模型参数的渐变信息,以便进行梯度下降等优化操作。
- 优化器状态:大多数现代优化器(如Adam)会存储关于模型参数的额外状态信息,如梯度的一阶和二阶矩。
- 激活存储:为了进行反向传播,需要存储前向传播过程中的中间激活值。
因此,对于具有X亿个参数的LLM,微调时的内存需求可以保守估计为大约4 * (2X) = 8X GB的VRAM,这里假设使用bfloat16精度。例如,微调一个7B(即70亿)参数的LLaMA模型,每个GPU大约需要7 * 8 = 56GB的显存以bfloat16精度进行微调。这个内存需求超出了当前大多数商用GPU的内存容量,因此需要使用分布式微调技术。
分布式微调涉及在多个GPU或机器上并行地训练模型,这样可以分散内存和计算负载,使得可以处理更大的模型或更复杂的任务。这通常需要额外的通信开销,但通过适当的优化和同步策略,可以有效地利用多个计算资源来训练或微调大型语言模型。
在微调大型模型时,除了内存需求外,还需要考虑计算资源、训练时间、模型性能和最终部署的效率之间的平衡。通过采用适当的量化、并行化技术和优化策略,可以在有限的资源下实现有效的模型微调和部署。
分布式微调技术
为了克服大型模型的 GPU 内存限制,目前有研究人员提出了以下几种分布式微调方法:
- 数据并行:经典的数据并行方法在多个 GPU 上复制整个模型,同时分割和分配训练数据批次。这会随着 GPU 数量的增加而线性减少训练时间,但不会减少每个 GPU 的峰值内存需求。
- ZeRO 第 3 阶段:一种高级形式的数据并行性,可跨 GPU 划分模型参数、梯度和优化器状态。与传统的数据并行相比,它通过在训练的不同阶段仅在每个 GPU 上保留所需的分区数据来减少内存。
- 张量并行:张量并行不是复制模型,而是将模型参数划分为行或列,并将它们分布在 GPU 上。每个 GPU 都在一组分区的参数、梯度和优化器状态上运行,从而节省大量内存。
- 流水线并行:该技术将模型层划分到不同的 GPU/worker 上,每个设备执行层的子集。激活在工作人员之间传递,减少了峰值内存,但增加了通信开销。
估计这些分布式方法的内存使用量并非易事,因为参数、梯度、激活和优化器状态的分布因技术而异。此外,不同的组件(例如变压器主体和语言建模头)可能会表现出不同的内存分配行为。
LLMem的GPU内存使用量
LLMem是一种在跨多个 GPU 对 LLM 应用分布式微调方法时准确估计 GPU 内存消耗的解决方案。
[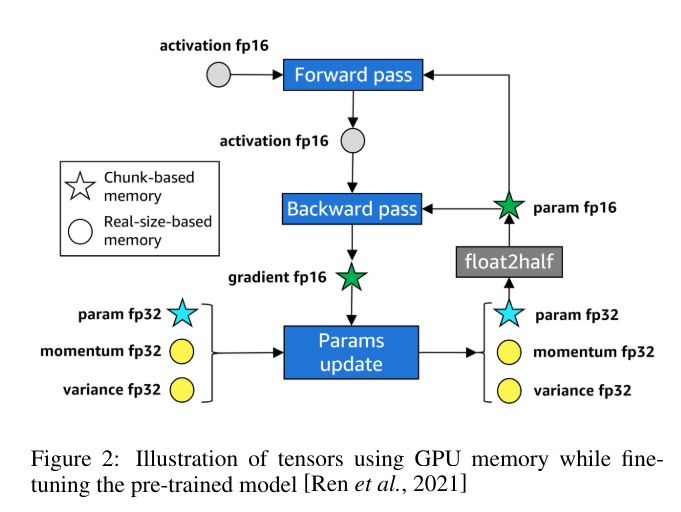
估计GPU内存使用情况以微调预训练的大型语言模型(LLM),LLMem考虑了多个因素,包括计算前重新组合参数(ZeRO的第三阶段)、反向传播中的输出收集(张量并行性),以及变换器主体和语言建模头部的不同内存分配策略。
实验结果显示,LLMem能够以高达1.6%的误差率估计在单个GPU上微调LLM时的峰值GPU内存使用量,这比最先进的DNNMem的平均误差率**42.6%要准确得多。当将分布式微调方法应用于在多个GPU上运行、参数超过10亿的LLM时,LLMem实现了平均误差率3.0%**的卓越性能。
通过提前准确估算内存需求,LLMem可以帮助用户选择最有效的分布式微调方法,避免内存不足的问题,同时尽可能减少训练时间。这种预先的估算对于确保微调过程的顺利进行和优化计算资源的使用至关重要。
当前研究现状
虽然量化、张量并行和模型并行等技术已经成熟,但研究人员仍在不断探索新方法,以进一步提高大型语言模型(LLM)训练和部署的效率。
- LoRA 和 QLoRA:这些技术涉及训练较小的残差适配器模块,用于更新预训练的LLM,使其适应新知识,而不是直接对大量参数进行微调。这种方法能够在保持模型大部分性能的同时,显著节省内存。
- FlashAttention:自注意力机制是Transformer模型中的内存和计算瓶颈。FlashAttention通过以线性复杂度逼近标准注意力机制,将输入序列长度的内存需求从二次方降低到线性,从而提高效率。
- 混合专家(Mixture of Experts):这种方法将每个输入数据样本有条件地路由到专门的专家模型,而不是让整个模型对其进行处理。这种动态稀疏性通过仅激活每个样本所需的专家子集来节省内存。
- 模型剪枝(Pruning):研究人员通过迭代删除如注意力头等相对不重要的组件,来探索模型压缩,以此在准确性和内存/速度之间做出权衡。
- 卸载(Offloading):将参数、优化器状态或激活卸载到CPU RAM或磁盘的技术,可以作为对大型模型有限GPU内存的补充,从而允许更大的模型或更长的序列处理。
这些尖端方法反映了一个活跃的研究生态系统,专注于实现在多样化硬件环境中高效训练和部署LLM的目标,推动了大型模型的民主化进程。通过这些技术,研究人员和工程师可以更灵活地在不同的应用场景中利用LLM,无论是在资源受限的个人设备上还是在大规模的云计算环境中。
结论
大型语言模型的内存要求对其在实际应用中的广泛采用提出了重大挑战。通过了解内存估计技术并利用量化、分布式训练策略和新兴创新,可以优化资源受限设备上的 LLM 部署。
LLMem 等工具为准确的内存估计铺平了道路,使用户能够选择最合适的微调配置。随着硬件的发展和研究的进步,我们可以预见更高效的训练和推理,从而推动自然语言处理和人工智能的进步。
在模型容量、准确性和资源利用率之间取得适当的平衡对于释放跨不同领域和用例的大型语言模型的全部潜力至关重要。通过采用内存优化技术,我们距离最先进的语言人工智能可访问、可扩展和可持续的未来又近了一步。
相关文章:
LLM——用于微调预训练大型语言模型(LLM)的GPU内存优化与微调
前言 GPT-4、Bloom 和 LLaMA 等大型语言模型(LLM)通过扩展至数十亿参数,实现了卓越的性能。然而,这些模型因其庞大的内存需求,在部署进行推理或微调时面临挑战。这里将探讨关于内存的优化技术,旨在估计并优…...

Telnet协议:远程控制的基石
目录 1. 概述 2. 工作机制 3. 网络虚拟终端 4. 选项协商 5. 操作方式 6. 用户接口命令 7. 验证的过程 1. 概述 Telnet(Telecommunication Network)是一种用于在互联网上远程登录到计算机系统的标准协议。它早期被广泛用于远程终端连接࿰…...
网络工程师必备:静态路由实验指南
大家好,这里是G-LAB IT实验室。今天带大家学习一下华为静态路由实验配置 01、实验拓扑 02、实验需求 1.R1环回口11,1,1.1模拟PC1 2.R2建立2个环回口模拟Server server-1: 22,1,1.1 server-2: 44.1.1.1 3.要求使用静态路由实现全网互通 PC1去往server-1从R3走…...

springboot利用切面保存操作日志(支持Spring表达式语言(简称SpEL))
springboot利用切面保存操作日志(支持Spring表达式语言(简称SpEL)) 文章目录 springboot利用切面保存操作日志(支持Spring表达式语言(简称SpEL))前言一、Spring EL是什么?…...

遂宁专业知识付费系统报价,免费网课平台怎么开通?需要哪些条件?
其实,不少的大咖老师都不愿意在大平台上开课,因为学员的留存并不是自己的,所以,很多人也考虑自己开通网课平台,那免费的平台怎么开通?这就是我们今天要跟老师们分享的内容了。 需要哪些条件? 大家如果想要开通免费的…...

【linuxC语言】fcntl和ioctl函数
文章目录 前言一、功能介绍二、具体使用2.1 fcntl函数2.2 ioctl函数三、拓展:填写arg总结前言 在Linux系统编程中,经常会涉及到对文件描述符、套接字以及设备的控制操作。fcntl和ioctl函数就是用来进行这些控制操作的两个重要的系统调用。它们提供了对文件、设备和套接字进行…...
)
java——继承(一)
一:匿名对象 只能使用一次,每一次使用都会创建一个新的对象,默认值和数组的默认值的规则相同。所以适用于调用一次对象的情况: public class ClassAnonymous {String name;public void show(){System.out.println(name"真厉…...

【Linux】进程间通信方式之管道
🤖个人主页:晚风相伴-CSDN博客 💖如果觉得内容对你有帮助的话,还请给博主一键三连(点赞💜、收藏🧡、关注💚)吧 🙏如果内容有误的话,还望指出&…...

【Linux】yum与vim
文章目录 软件包管理器:yumLinux安装和卸载软件包Linux中的编辑器:vimvim下的底行模式vim下的正常模式vim下的替换模式vim下的视图模式vim下的多线程 软件包管理器:yum yum其实就是一个软件,也可以叫商店 和你手机上的应用商店或app store一…...
苍穹外卖Day06笔记
疯玩了一个月,效率好低,今天开始捡起来苍穹外卖~ 1. 为什么不需要单独引入HttpClient的dependency? 因为我们在sky-common的pom.xml中已经引入了aliyun-sdk-oss的依赖,而这个依赖低层就引入了httpclinet的依赖,根据依…...

Maximo 使用 REST API 创建 Cron Task
接前面几篇文章,我没有了 automation script 以后,有时候需要让其定期自动执行,这时候就可以通过 Cron Task 来实现了。 通过Maximo REST API 来创建 Cron Task request: POST {{base_url}}/api/os/mxapicrontaskdef?apikey{{…...

【镜像仿真篇】磁盘镜像仿真常见错误
【镜像仿真篇】磁盘镜像仿真常见错误 记系统镜像仿真常见错误集—【蘇小沐】 1、实验环境 2023AFS39.E01(Windows11系统镜像)Arsenal Image Mounter,[v3.10.262]Vmware Workstation 17 Pro,[v17.5.1]Windows 11 专业工作站版…...

代码随想录算法训练营DAY45|C++动态规划Part7|70.爬楼梯(进阶版)、322. 零钱兑换、279.完全平方数
文章目录 70.爬楼梯(进阶版)⭐️322. 零钱兑换思路CPP代码总结 279.完全平方数思路CPP代码 70.爬楼梯(进阶版) 卡码网:57. 爬楼梯 文章讲解:70.爬楼梯(进阶版) 本题就是典型了完全背包排列问题,…...

Linux(openEuler、CentOS8)企业内网DHCP服务器搭建(固定Mac获取指定IP)
----本实验环境为openEuler系统<以server方式安装>(CentOS8基本一致,可参考本文)---- 目录 一、知识点二、实验(一)为服务器配置网卡和IP(二)为服务器安装DHCP服务软件(三&a…...

c#读取hex文件方法,相对来说比较清楚
Hex文件解读_c#读取hex文件-CSDN博客 https://wenku.csdn.net/answer/d67f30cf834c435ca37c3d1ef5e78a62?ops_request_misc%257B%2522request%255Fid%2522%253A%2522171498156816800227423661%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&…...
【ytb数据采集器】按关键词批量爬取视频数据,界面软件更适合文科生!
一、背景介绍 1.1 爬取目标 用Python独立开发的爬虫工具,作用是:通过搜索关键词采集油管的搜索结果,包含14个关键字段:关键词,页码,视频标题,视频id,视频链接,发布时间,视频时长,频道名称,频道id,频道链接,播放数,点赞数,评论数…...

三条命令快速配置Hugging Face
大家好啊,我是董董灿。 本文给出一个配置Hugging Face的方法,让你在国内可快速从Hugging Face上下在模型和各种文件。 1. 什么是 Hugging Face Hugging Face 本身是一家科技公司,专注于自然语言处理(NLP)和机器学习…...

Python网络编程 03 实验:FTP详解
文章目录 一、小实验FTP程序需求二、项目文件架构三、服务端1、conf/settings.py2、conf/accounts.cgf3、conf/STATUS_CODE.py4、启动文件 bin/ftp_server.py5、core/main.py6、core/server.py 四、客户端1、conf/STATUS_CODE.py2、bin/ftp_client.py 五、在终端操作示例 一、小…...
)
个人银行账户管理程序(2)
在(1)的基础上进行改进 1:增加一个静态成员函数total,记录账户总金额和静态成员函数getTotal 2对不需要改变的对象进行const修饰 3多文件实现 account。h文件 #ifndef _ACCOUNT_ #define _ACCOUNT_ class SavingAccount {pri…...

2024.04.19校招 实习 内推 面经
绿*泡*泡VX: neituijunsir 交流*裙 ,内推/实习/校招汇总表格 1、校招&转正实习 | 美团无人机业务部招聘(内推) 校招&转正实习 | 美团无人机业务部招聘(内推) 2、校招&实习 | 快手 这些岗位…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...