python开发二
python开发二
requests请求模块
requests 是一个常用的 Python 第三方库,用于发送 HTTP 请求。它提供了简洁且易于使用的接口,使得与 Web 服务进行交互变得非常方便。
发送 GET 请求并获取响应
import requestsresponse = requests.get("https://api.example.com/data")
print(response.status_code) # 获取响应状态码
print(response.text) # 获取响应内容发送带参数的 GET 请求
import requestsresponse = requests.get("https://api.example.com/data")
print(response.status_code) # 获取响应状态码
print(response.text) # 获取响应内容发送 POST 请求并传递数据
import requestsdata = {"key": "value"}
response = requests.post("https://api.example.com/submit", data=data)
print(response.json()) # 解析响应内容为 JSON 格式发送带有请求头的请求
import requestsheaders = {"User-Agent": "Mozilla/5.0"}
response = requests.get("https://api.example.com/data", headers=headers)
print(response.text)可以自定义请求头,例如设置 User-Agent、Referer 等,以模拟不同的浏览器或来源。
处理响应内容
import requestsresponse = requests.get("https://api.example.com/data")
print(response.status_code) # 获取响应状态码
print(response.text) # 获取响应内容
print(response.json()) # 解析响应内容为 JSON 格式根据需要,可以获取响应的状态码、文本内容或将响应内容解析为 JSON 格式。
处理异常和错误
import requeststry:response = requests.get("https://api.example.com/data")response.raise_for_status() # 如果请求失败,抛出异常
except requests.HTTPError as e:print("HTTP Error:", e)
except requests.RequestException as e:print("Error:", e)使用 try-except 块来捕获可能发生的异常,如网络连接错误、超时等。
文件上传和下载
import requests# 文件上传
files = {"file": open("file.txt", "rb")}
response = requests.post("https://api.example.com/upload", files=files)# 文件下载
response = requests.get("https://example.com/image.jpg")
with open("image.jpg", "wb") as file:file.write(response.content)可以使用 files 参数将文件上传到服务器,并使用 response.content 获取返回的二进制数据,然后将其保存到本地文件中。
base64模块
-
- 编码:
b64encode(s): 对给定的字节串(bytes)进行 Base64 编码,返回编码后的字节串。
b64encode(s, altchars): 使用指定的替代字符进行 Base64 编码。
-
- 解码:
b64decode(s): 对给定的 Base64 编码的字节串进行解码,返回解码后的字节串。
b64decode(s, altchars): 使用指定的替代字符进行 Base64 解码。
示例:
import base64# 编码
text = "Hello, World!".encode("utf-8")
encoded_text = base64.b64encode(text)
print(encoded_text) # 输出:b'SGVsbG8sIFdvcmxkIQ=='# 解码
decoded_text = base64.b64decode(encoded_text)
print(decoded_text.decode("utf-8")) # 输出:Hello, World!编码和解码 URL 安全的 Base64:
URL 安全的 Base64 在编码结果中使用 - 和 _ 替代 + 和 /。可以使用 urlsafe_b64encode() 和 urlsafe_b64decode() 函数进行 URL 安全的编码和解码。
import base64text = "Hello, World!".encode("utf-8")# URL 安全的 Base64 编码
encoded_text = base64.urlsafe_b64encode(text)
print(encoded_text) # 输出:b'SGVsbG8sIFdvcmxkIQ=='# URL 安全的 Base64 解码
decoded_text = base64.urlsafe_b64decode(encoded_text)
print(decoded_text.decode("utf-8")) # 输出:Hello, World!多行输出和填充字符控制
可以使用 b64encode() 函数的 break_lines 参数来控制是否启用多行输出,并使用 b64encode() 和 b64decode() 函数的 pad 参数来控制是否启用填充字符。
import base64text = "Hello, World!".encode("utf-8")# 启用多行输出和填充字符
encoded_text = base64.b64encode(text, break_lines=True).decode("utf-8")
print(encoded_text)decoded_text = base64.b64decode(encoded_text, pad=True).decode("utf-8")
print(decoded_text)对文件进行编码和解码
import base64# 编码文件
with open("example.jpg", "rb") as file:encoded_image = base64.b64encode(file.read())print(encoded_image)# 解码文件
with open("decoded_image.jpg", "wb") as file:file.write(base64.b64decode(encoded_image))etree模块
-
- 解析 XML 数据:
parse(file): 解析给定文件名或文件对象中的 XML 数据,并返回根元素对象。
fromstring(xmlstring): 解析给定的 XML 字符串,并返回根元素对象。
-
- 遍历 XML 树:
iter(): 遍历 XML 树的所有元素。
find(tag): 在当前元素的子元素中查找并返回第一个具有给定标签名的子元素。
findall(tag): 在当前元素的子元素中查找并返回所有具有给定标签名的子元素。
-
- 获取和修改元素内容:
text: 获取或设置元素的文本内容。
attrib: 获取或设置元素的属性字典。
示例:
import xml.etree.ElementTree as etree# 解析 XML 数据
tree = etree.parse("data.xml")
root = tree.getroot()# 遍历 XML 树
for child in root:print(child.tag, child.attrib)# 获取和修改元素内容
element = root.find("element")
print(element.text) # 输出元素的文本内容element.text = "New Text" # 修改元素的文本内容
element.set("attribute", "value") # 设置元素的属性# 生成 XML 字符串
xml_string = etree.tostring(root, encoding="utf-8")
print(xml_string)创建新的 XML 元素
- Element(tag, attrib={}): 创建具有给定标签名和属性的新元素。
- SubElement(parent, tag, attrib={}): 在父元素下创建具有给定标签名和属性的新子元素。
import xml.etree.ElementTree as etree# 创建根元素
root = etree.Element("root")# 创建子元素
child = etree.SubElement(root, "child")
child.text = "Hello"# 添加属性
child.set("attribute", "value")# 输出 XML 字符串
xml_string = etree.tostring(root, encoding="utf-8")
print(xml_string)删除元素
- remove(element): 从父元素中删除指定的子元素
import xml.etree.ElementTree as etreetree = etree.parse("data.xml")
root = tree.getroot()# 删除指定的子元素
element_to_remove = root.find("element")
root.remove(element_to_remove)# 输出修改后的 XML 字符串
xml_string = etree.tostring(root, encoding="utf-8")
print(xml_string)寻找命名空间
- register_namespace(prefix, uri): 注册一个命名空间前缀和 URI 的映射关系。
- QName(uri, localname): 创建具有给定命名空间 URI 和本地名称的 QName 对象。
import xml.etree.ElementTree as etree# 注册命名空间前缀和 URI 映射关系
etree.register_namespace("prefix", "http://example.com/ns")# 创建带有命名空间的元素
element = etree.Element("{http://example.com/ns}tag")# 使用 QName 创建带有命名空间的属性
qname = etree.QName("http://example.com/ns", "attribute")
element.set(qname, "value")解析和生成字符串
- tostring(element, encoding=‘unicode’): 将给定的元素转换为字符串。
- fromstringlist(sequence): 从字符串列表解析多个 XML 文档。
import xml.etree.ElementTree as etree# 解析多个 XML 文档
xml_list = ['<root><child>1</child></root>', '<root><child>2</child></root>']
for xml_string in xml_list:root = etree.fromstring(xml_string)# 处理每个 XML 文档# 生成 XML 字符串
root = etree.Element("root")
xml_string = etree.tostring(root, encoding="utf-8")
print(xml_string)xpath解析方式
XPath 是一种用于在 XML 文档中定位元素的语言。etree 模块提供了支持 XPath 的功能,使得可以使用 XPath 表达式来解析和选取 XML 数据。
以下是使用 XPath 解析 XML 数据的示例:
import xml.etree.ElementTree as etree# 解析 XML 数据
tree = etree.parse("data.xml")
root = tree.getroot()# 使用 XPath 选取元素
elements = root.findall(".//element") # 选取所有名为 "element" 的元素
for element in elements:print(element.text)element = root.find(".//element[@attribute='value']") # 选取具有属性值为 "value" 的 "element" 元素
if element is not None:print(element.text)利用xpath获取网址的域名,标题和IP地址
import requests
from lxml import etree# 发送请求并获取网页内容
url = "https://example.com" # 替换为您要获取信息的网址
response = requests.get(url)
html = response.text# 使用 lxml 解析 HTML
tree = etree.HTML(html)# 使用 XPath 提取域名
domain = tree.xpath("//a/@href")
if domain:domain = domain[0].strip("/")# 使用 XPath 提取标题
title = tree.xpath("//title/text()")[0]# 使用 XPath 提取 IP 地址
ip_address = tree.xpath("//span[@class='ip-address']/text()")[0]# 打印结果
print("Domain:", domain)
print("Title:", title)
print("IP Address:", ip_address)具体情况需要根据实际情况修改 XPath 表达式,以适应目标网页的结构和元素选择方式。
ftplib库
ftplib 模块提供了一系列方法和功能,用于通过 FTP 协议进行文件传输和管理。以下是 ftplib 的主要功能:
连接和认证:
- FTP(host[, user[, passwd]]): 创建一个 FTP 对象并连接到指定的 FTP 服务器。
- login(user=‘’, passwd=‘’, acct=‘’): 使用给定的用户名、密码和账户信息进行认证。
文件上传和下载:
- storbinary(cmd, file[, blocksize[, callback[, rest]]]): 将本地文件的数据流上传到远程服务器。
- retrbinary(cmd, callback[, maxblocksize[, rest]]): 从远程服务器下载文件的数据流到本地。
- storlines(cmd, file[, callback]): 将本地文件逐行上传到远程服务器。
- retrlines(cmd, callback): 从远程服务器逐行下载文件到本地。
目录和文件管理:
- cwd(path): 更改当前工作目录到指定的路径。
- pwd(): 获取当前工作目录的路径。
- nlst([path]): 列出指定路径下的文件和目录名称(不包含详细信息)。
- dir([path[,…]]): 列出指定路径下的文件和目录详细信息。
- delete(pathname): 删除远程服务器上的指定文件。
- rename(fromname, toname): 重命名远程服务器上的文件或目录。
- mkd(pathname): 在远程服务器上创建新目录。
- rmd(dirname): 删除远程服务器上的指定目录。
其他功能:
- quit(): 关闭 FTP 连接。
- getwelcome(): 获取服务器的欢迎消息。
- sendcmd(cmd): 发送原始 FTP 命令到服务器。
- voidcmd(cmd): 执行无返回值的 FTP 命令。
- voidresp(): 等待服务器的响应,如果响应不是成功的响应码,则引发异常。
示例:
from ftplib import FTP# 连接和认证
ftp = FTP("example.com")
ftp.login(user="username", passwd="password")# 文件上传和下载
with open("local_file.txt", "rb") as file:ftp.storbinary("STOR remote_file.txt", file)with open("local_file.txt", "wb") as file:ftp.retrbinary("RETR remote_file.txt", file.write)# 目录和文件管理
ftp.cwd("/path/to/directory")
current_dir = ftp.pwd()
file_list = ftp.nlst("/path/to/directory")
dir_list = ftp.dir("/path/to/directory")
ftp.delete("/path/to/file.txt")
ftp.rename("/path/from/file.txt", "/path/to/file.txt")
ftp.mkd("/path/to/new_directory")
ftp.rmd("/path/to/directory")# 其他功能
ftp.quit()
welcome_message = ftp.getwelcome()
response = ftp.sendcmd("CMD")
ftp.voidcmd("CMD")
ftp.voidresp()相关文章:

python开发二
python开发二 requests请求模块 requests 是一个常用的 Python 第三方库,用于发送 HTTP 请求。它提供了简洁且易于使用的接口,使得与 Web 服务进行交互变得非常方便。 发送 GET 请求并获取响应 import requestsresponse requests.get("https:/…...
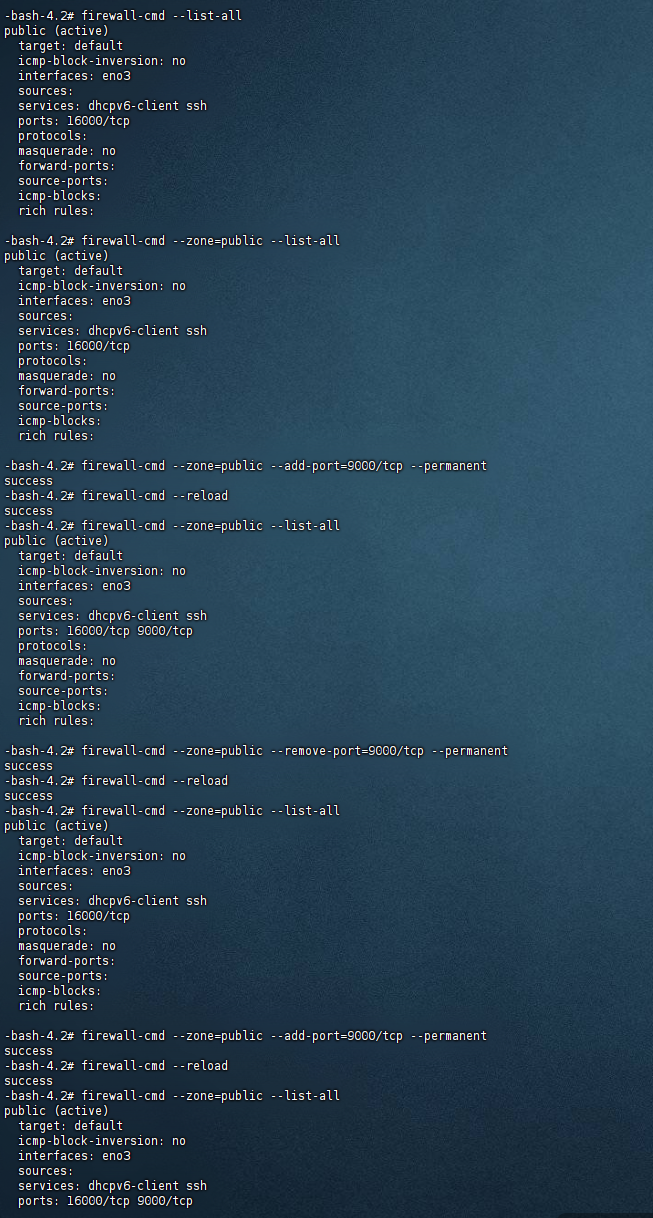
部署JVS服务出现上传文件不可用,问题原因排查。
事情的起因是这样的,部门经理让我部署一下JVS资源共享框架,项目的地址是在这里 项目资源地址 各位小伙伴们做好了,我要开始发车了,全新的“裂开之旅” 简单展示一下如何部署JVS文档 直达链接 撕裂要开始了 本来服务启动的好好…...

机器视觉检测为什么是工业生产的刚需?
机器视觉检测在工业生产中被视为刚需,主要是因为它具备以下几个关键优势: 提高精度与效率:机器视觉系统可以进行高速、高精度的检测。这对于保证产品质量、减少废品非常关键。例如,在生产线上,机器视觉可以迅速识别产品…...
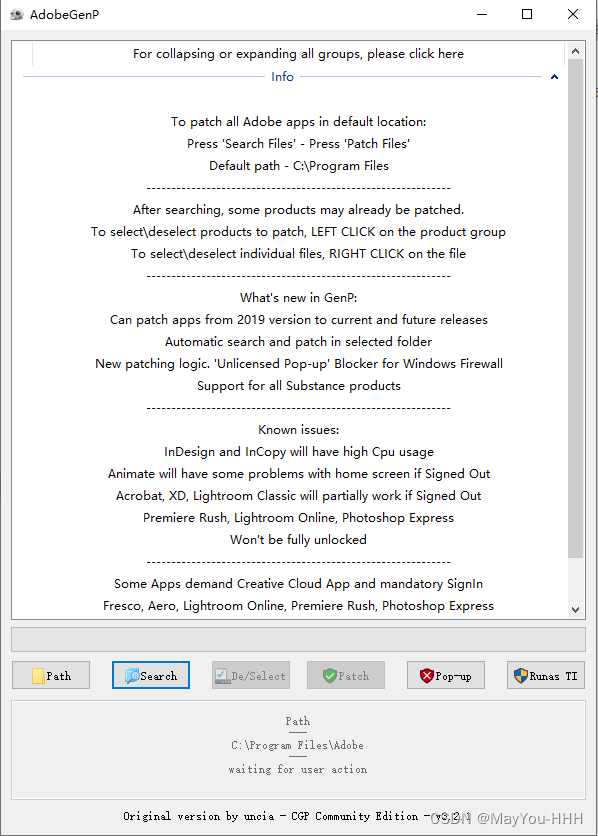
Adobe系列软件安装
双击解压 先运行Creative_Cloud_Set_Up.exe。 完毕后,运行AdobeGenP.exe 先Path,选路径,如 C:\Program Files\Adobe 后Search 最后Patch。 关闭软件,修图!...
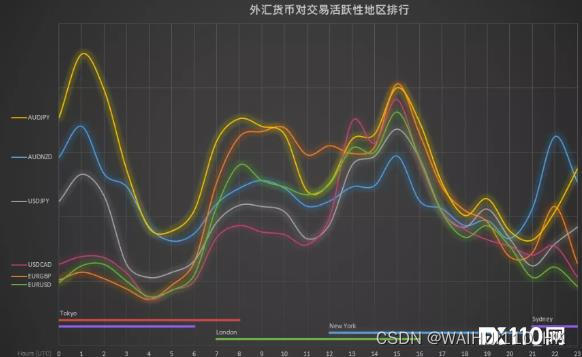
【FX110】2024外汇市场中交易量最大的货币对是哪个?
作为最大、最流动的金融市场之一,外汇市场每天的交易量高达几万亿美元,涉及到数百种货币。不同货币对的交易活跃程度并不一样,交易者需要根据货币对各自的特点去进行交易。 全年外汇市场中涉及美元的外汇交易超过50%! 实际上&…...
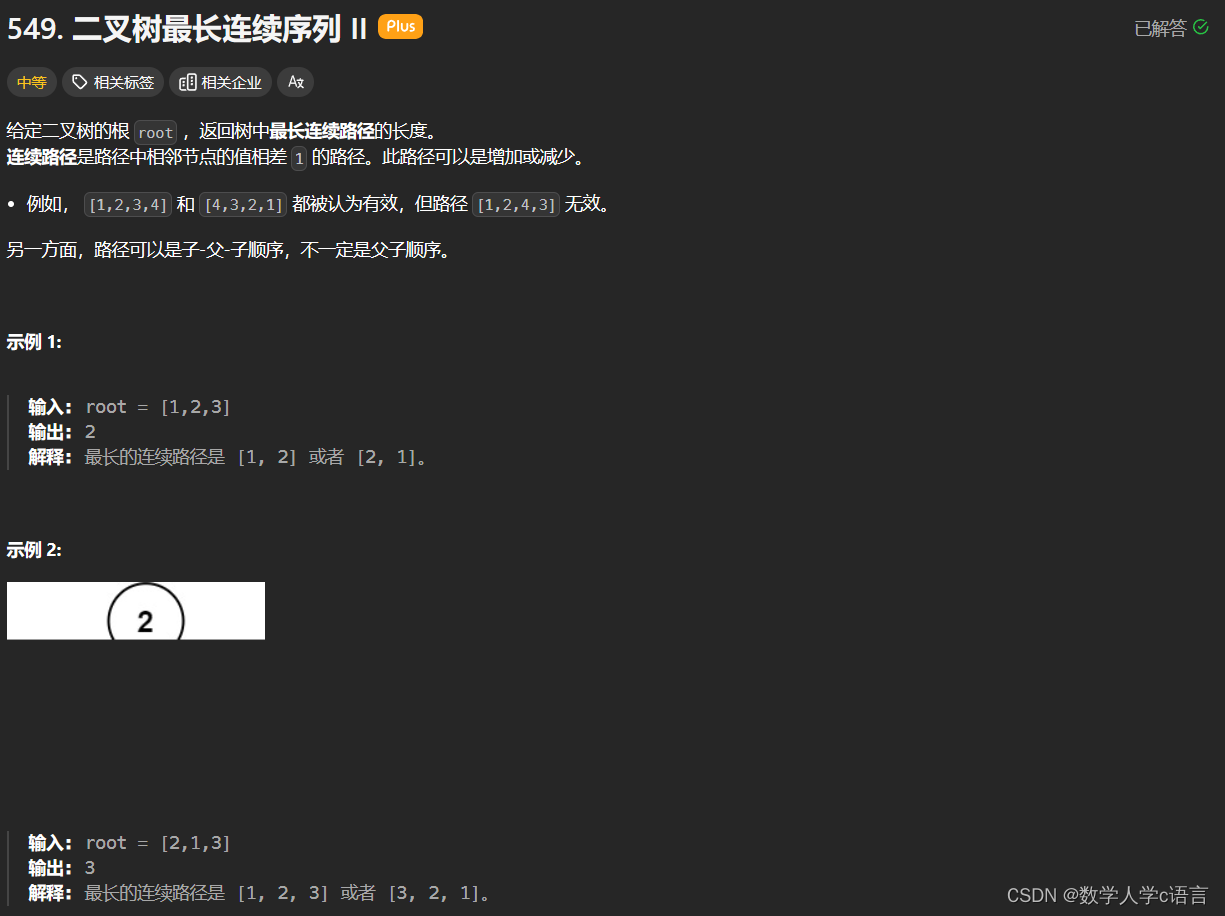
leetcode尊享面试100题(549二叉树最长连续序列||,python)
题目不长,就是分析时间太久了。 思路使用dfs深度遍历,先想好这个函数返回什么,题目给出路径可以是子-父-子的路径,那么1-2-3可以,3-2-1也可以,那么考虑dfs返回两个值,对于当前节点node来说&…...

C#面试题: 寻找中间值
给定一个数组,在区间内从左到右查找中间值,每次查找最小值与最大值区间内的中间值,且这个区间元素数量不小于3。 例如 1.给定数组float[] data { 1, 2.3f, 4, 5.75f, 8.125f, 10.5f, 13, 15, 20 } 输出:10.5、5.75、4、2.3、8…...
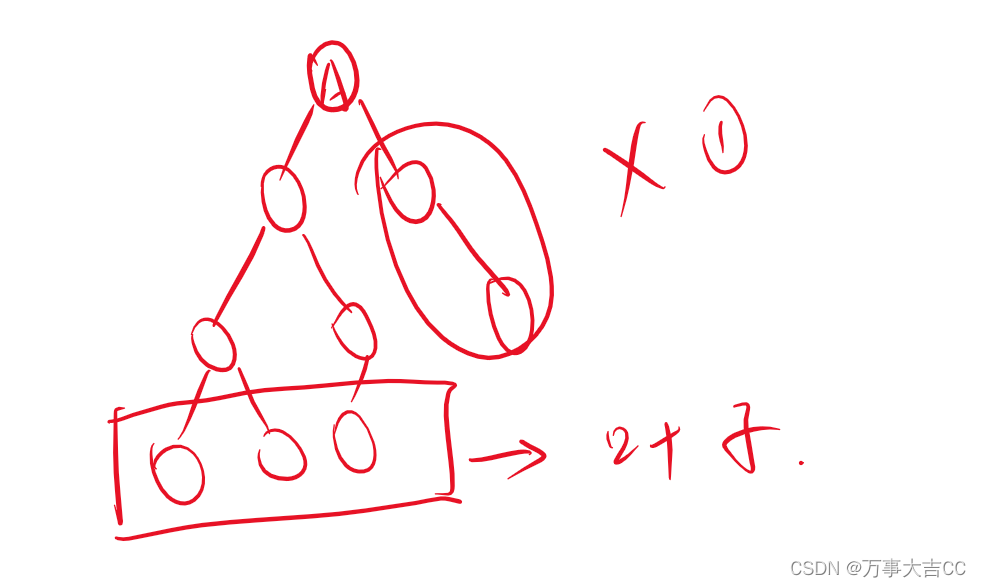
987: 输出用先序遍历创建的二叉树是否为完全二叉树的判定结果
解法: 一棵二叉树是完全二叉树的条件是: 对于任意一个结点,如果它有右子树而没有左子树,则这棵树不是完全二叉树。 如果一个结点有左子树但是没有右子树,则这个结点之后的所有结点都必须是叶子结点。 如果满足以上条…...

13:HAL---SPI
目录 一:SPL通信 1:简历 2:硬件电路 3:移动数据图 4:SPI时序基本单元 A : 开/ 终条件 B:SPI时序基本单元 A:模式0 B:模式1 C:模式2 D:模式3 C:SPl时序 A:发送指令 B: 指定地址写 C:指定地址读 5:NSS(CS) 6:时钟 二: W25Q64 1:简历 2…...

微服务---gateway网关
目录 gateway作用 gateway使用 添加依赖 配置yml文件 自定义过滤器 nacos上的gateway的配置文件 我们现在知道了通过nacos注册服务,通过feign实现服务间接口的调用,那对于不同权限的用户访问同一个接口,我们怎么知道他是否具有访问的权…...
HTML4(二)
文章目录 1 开发者文档2 基本标签2.1 排版标签2.2 语义化标签2.3 行内元素与块级元素2.4 文本标签2.5 常用标签补充 3 图片标签4 超链接标签4.1 跳转页面4.2 跳转文件4.3 跳转锚点4.4 唤起指定应用 5 列表5.1 有序列表5.2 无序列表5.3 自定义列表 6 表格6.1 基本结构6.2 表格标…...
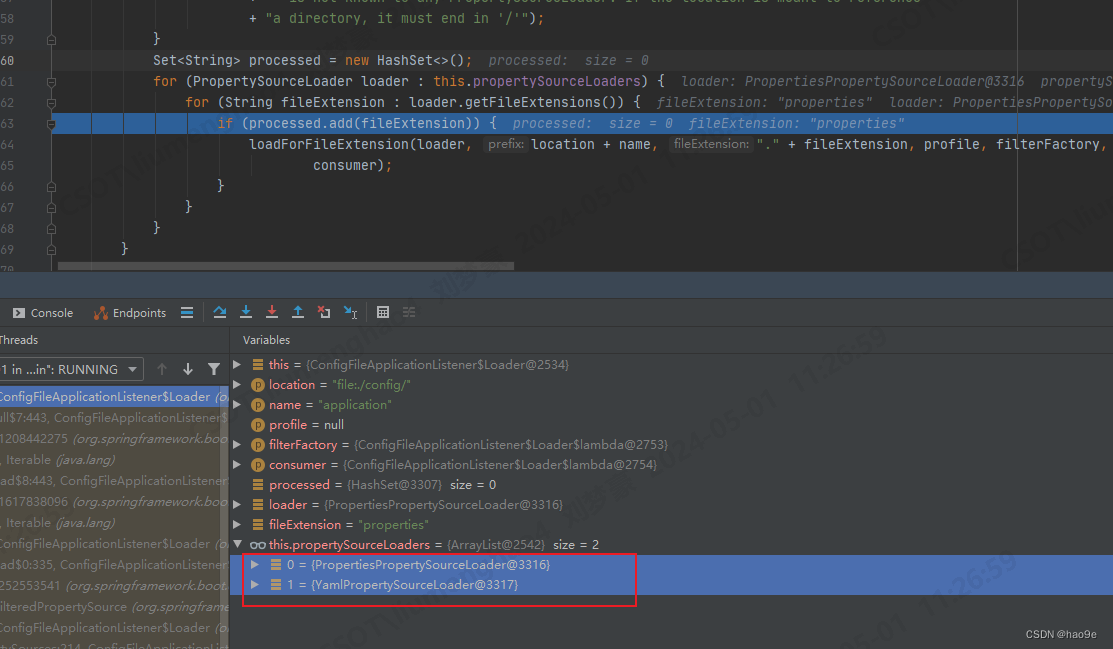
SpringBoot 扩展篇:ConfigFileApplicationListener源码解析
SpringBoot 扩展篇:ConfigFileApplicationListener源码解析 1.概述2. ConfigFileApplicationListener定义3. ConfigFileApplicationListener回调链路3.1 SpringApplication#run3.2 SpringApplication#prepareEnvironment3.3 配置environment 4. 环境准备事件 Config…...

蓝桥杯省三爆改省二,省一到底做错了什么?
到底怎么个事 这届蓝桥杯选的软件测试赛道,都说选择大于努力,软件测试一不卷二不难。省赛结束,自己就感觉稳啦,全部都稳啦。没想到一出结果,省三,g了。说落差,是真的有一点,就感觉和自己预期的…...
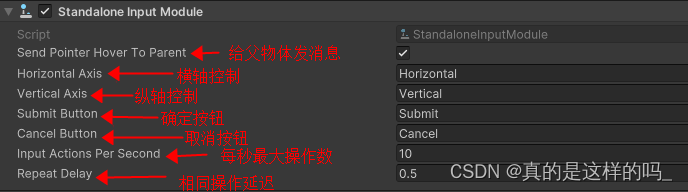
Unity EventSystem入门
概述 相信在学习Unity中,一定有被UI事件困扰的时候把,当添加UICanvas的时候,Unity会为我们自动添加EventSystem,这个是为什么呢,Unity的UI事件是如何处理的呢,在使用各个UI组件的时候,一定有不…...

第4章 Vim编辑器与Shell命令脚本
第4章 Vim编辑器与Shell命令脚本 1. Vim文本编辑器2. 编写Shell脚本2.2 接收用户的参数2.3 判断用户的参数 3. 流程控制语句3.1 if条件测试语句3.2 for条件循环语句3.3 while条件循环语句3.4 case条件测试语句 4. 计划任务服务程序复习题 1. Vim文本编辑器 Vim编辑器中设置了三…...
javaWeb快速部署到tomcat阿里云服务器
目录 准备 关闭防火墙 配置阿里云安全组 点击控制台 点击导航栏按钮 点击云服务器ECS 点击安全组 点击管理规则 点击手动添加 设置完成 配置web服务 使用yum安装heepd服务 启动httpd服务 查看信息 部署java通过Maven打包好的war包项目 Maven打包项目 上传项目 …...
[MQTT]Mosquitto的內網連接(intranet)和使用者/密碼權限設置
[MQTT | Raspberry Pi]Publish and Subscribe with RSSI Data of Esp32 on Intranet 延續[MQTT]Mosquitto的簡介、安裝與連接測試文章,接著將繼續測試在內網的兩台機器是否也可以完成發佈和訂閱作業。 同一網段的兩台電腦測試: 假設兩台電腦的配置如下: A電腦為發…...
某盾BLACKBOX逆向关键点
需要准备的东西: 1、原JS码 2、AST解混淆码 3、token(来源于JSON) 一、原JS码很好获取,每次页面刷新,混淆的代码都会变,这是正常,以下为部分代码 while (Qooo0) {switch (Qooo0) {case 110 14 - 55: {function O0…...
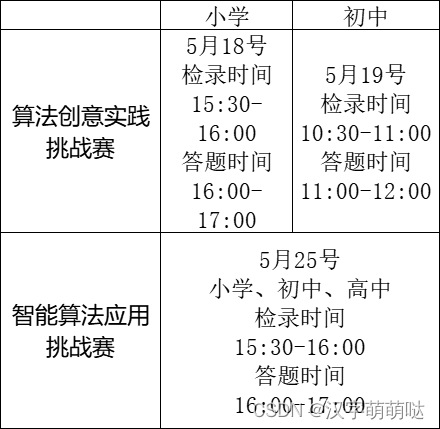
【2024全国青少年信息素养大赛初赛时间以及模拟题】
2024全国青少年信息素养大赛时间已经出来了 目录 全国青少年信息素养大赛智能算法挑战赛初中模拟卷 全国青少年信息素养大赛智能算法挑战赛初中模拟卷 1、比赛时间和考试内容: 算法创意实践挑战赛初中组于5月19日举行,检录时间为10:30-11:00…...
2024年软件测试最全jmeter做接口压力测试_jmeter接口性能测试_jmeter压测接口(3),【大牛疯狂教学
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化! 由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、…...

C++ 用户态协议栈:基于 DPDK 的 C++ 网络库开发与内核绕过技术分析
各位技术同仁,下午好!今天,我们将深入探讨一个在高性能网络领域至关重要的话题:C 用户态协议栈的开发,特别是如何基于 DPDK 构建一个高性能网络库,以及其背后的内核绕过技术。在现代数据中心和网络基础设施…...

[RAG在LangChain中的实现-07]利用重排序选择相关性最高的检索内容构建上下文
重排序(Re-ranking)是一种关键的RAG优化技术。它通过在“初始检索”与“最终生成”之间,通过对初步检索出的文档进行二次评估,筛选出与用户查询语义最相关的结果,从而提高生成内容的准确性。在典型的检索流程中&#x…...

如何通过LeaguePrank实现游戏界面个性化:打造独特的英雄联盟视觉体验
如何通过LeaguePrank实现游戏界面个性化:打造独特的英雄联盟视觉体验 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank LeaguePrank是一款专注于英雄联盟客户端界面自定义的开源工具,它通过安全的官方LCU…...

Docker测试学习思路
Docker 核心概念学习与实战指南本文系统梳理 Docker 学习的核心思路与方法,用通俗类比帮助理解 Docker 的本质,涵盖镜像构建、容器运行、网络通信、数据持久化、资源限制五大核心能力,适合初学者建立清晰的 Docker 知识框架。一、Docker 到底…...
惊艳效果:书法题跋+钤印位置+行气关系可视化还原)
深求·墨鉴(DeepSeek-OCR-2)惊艳效果:书法题跋+钤印位置+行气关系可视化还原
深求墨鉴(DeepSeek-OCR-2)惊艳效果:书法题跋钤印位置行气关系可视化还原 1. 引言:当OCR遇见水墨美学 你有没有遇到过这样的场景?面对一幅珍贵的书法作品或古籍文献,想要将其中的文字内容数字化࿰…...

Phi-3-mini-4k-instruct-gguf一文详解:GGUF格式优势与Phi-3系列轻量设计哲学
Phi-3-mini-4k-instruct-gguf一文详解:GGUF格式优势与Phi-3系列轻量设计哲学 1. 认识Phi-3-mini-4k-instruct-gguf Phi-3-mini-4k-instruct-gguf是微软Phi-3系列中的轻量级文本生成模型,采用GGUF格式封装。这个模型特别适合处理问答、文本改写、摘要整…...

Kimi-VL-A3B-Thinking开源大模型部署教程:MoonViT视觉编码器实测解析
Kimi-VL-A3B-Thinking开源大模型部署教程:MoonViT视觉编码器实测解析 1. 模型简介与核心能力 Kimi-VL-A3B-Thinking是一款创新的开源混合专家(MoE)视觉语言模型(VLM),在多模态推理领域展现出卓越性能。这…...

OpenClaw+Qwen2.5-VL-7B省钱方案:自建多模态接口替代GPT-4V
OpenClawQwen2.5-VL-7B省钱方案:自建多模态接口替代GPT-4V 1. 为什么选择本地多模态方案 去年我在开发一个智能内容管理工具时,频繁调用GPT-4V处理截图和文档解析,每月账单轻松突破2000元。最痛心的是,80%的简单图片识别任务其实…...

Flash Memory技术解析与应用实践
1. Flash Memory技术全景解析作为一名嵌入式系统开发工程师,我使用Flash Memory已有十余年经验。从早期的NOR Flash烧录到现在的TLC NAND优化,这项技术始终是存储领域的核心支柱。让我们抛开教科书式的定义,从实际工程角度重新认识这项既熟悉…...

2026年4月OpenClaw如何安装?腾讯云2分钟零基础教程及百炼APIKey配置方法
2026年4月OpenClaw如何安装?腾讯云2分钟零基础教程及百炼APIKey配置方法。OpenClaw(原Clawdbot)作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉钉,让AI在企业群…...