Spring Data JPA 与 MyBatisPlus的比较
前言
JPA(Java Persistence API)和MyBatis Plus是两种不同的持久化框架,它们具有不同的特点和适用场景。
JPA是Java官方的持久化规范,它提供了一种基于对象的编程模型,可以通过注解或XML配置来实现对象与数据库的映射关系。JPA的优点是可以对数据库进行更高级的操作,如查询、更新、删除等,同时也支持事务管理和缓存机制,能够更好地支持复杂的业务逻辑。
MyBatis Plus (MPP) 是在MyBatis基础上进行封装的增强版本,它提供了更简单易用的API和更高效的性能。MyBatis Plus通过XML或注解的方式来配置数据库映射关系,并提供了丰富的查询、更新、删除操作的方法。相对于JPA,MyBatis Plus配置简单、易于上手,同时也灵活性较高,能够更好地满足项目的特定需求。
如果只是针对单表的增删改查,两者十分相似,本质上都算ORM框架,那么到底什么时候适合用JPA,什么时候用MyBatisPlus,下面做下这两者的详细对比。
POM依赖
JPA
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
MPP
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId>
</dependency>
Entity定义
JPA
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
import javax.persistence.GeneratedValue;@Entity
@Table(name = "dept")
public class Dept {@Id@Column(name = "id")@GeneratedValue(strategy = GenerationType.AUTO)private Long id;@Column(name = "code")private String code;@Column(name = "name")private String name;
}
MPP
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;@TableName(value = "dept")
public class Dept {@TableId(value = "id", type = IdType.AUTO)private Long id;@TableField(value = "code")private String code;@TableField(value = "name")private String name;
}
DAO定义
基础CRUD
JPA
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;@Repository
public interface DeptRepository extends JpaRepository<Dept, Long> {
}
MPP
import org.apache.ibatis.annotations.Mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;@Mapper
public interface DeptMapper extends BaseMapper<Dept> {
}
基类主要方法
| 方法 | JpaRepository | BaseMapper |
|---|---|---|
| 插入一条记录 | save(T entity) | insert(T entity) |
| 插入多条记录 | saveAll(Iterable entities) | insertBatchSomeColumn(List entityList) |
| 根据 ID 删除 | deleteById(ID id) | deleteById(Serializable id) |
| 根据实体(ID)删除 | delete(T entity) | deleteById(T entity) |
| 根据条件删除记录 | - | delete(Wrapper queryWrapper) |
| 删除(根据ID或实体 批量删除) | deleteAllById(Iterable<? extends ID> ids) | deleteBatchIds(Collection<?> idList) |
| 根据 ID 修改 | save(T entity) | updateById(T entity) |
| 根据条件更新记录 | - | update(Wrapper updateWrapper) |
| 根据 ID 查询 | findById(ID id) | selectById(Serializable id) |
| 查询(根据ID 批量查询) | findAllById(Iterable ids) | selectBatchIds(Collection<? extends Serializable> idList) |
| 根据条件查询一条记录 | - | selectOne(Wrapper queryWrapper) |
| 根据条件判断是否存在记录 | exists(Example example) | exists(Wrapper queryWrapper) |
| 根据条件查询总记录数 | count(Example example) | selectCount(Wrapper queryWrapper) |
| 根据条件查询全部记录 | findAll(Example example, Sort sort) | selectList(Wrapper queryWrapper) |
| 根据条件查询分页记录 | findAll(Example example, Pageable pageable) | selectPage(P page, Wrapper queryWrapper) |
Example、Specification VS Wrapper
JPA使用Example和Specification 类来实现范本数据的查询,而MPP使用QueryWrapper来设置查询条件
JPA Example
Dept dept = new Dept();
dept.setCode("100");
dept.setName("Dept1");// select * from dept where code = '100' and name = 'Dept1';
List<Dept> deptList = deptRepository.findAll(Example.of(dept));
默认是生成的条件都是 “=”,如果要设置其他比较符,需要使用ExampleMatcher
Dept dept = new Dept();
dept.setCode("100");
dept.setName("Dept1");// select * from dept where code like '100%' and name like '%Dept1%';
List<Dept> deptList = deptRepository.findAll(Example.of(dept, ExampleMatcher.matching().withMatcher("code", ExampleMatcher.GenericPropertyMatchers.startsWith()).withMatcher("name", ExampleMatcher.GenericPropertyMatchers.contains())));
Example仅能实现对字符串类型的匹配模式,如果要设置其他类型的字段,可以实现JpaSpecificationExecutor接口来完成:
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
import org.springframework.stereotype.Repository;@Repository
public interface DeptRepository extends JpaRepository<Dept, Long>, JpaSpecificationExecutor<Dept> {
}
增加以上接口后,会增加以下查询方法:
- findOne(Specification spec)
- findAll(Specification spec)
- findAll(Specification spec, Pageable pageable)
- count(Specification spec)
- exists(Specification spec)
使用示例:
Dept dept = new Dept();
dept.setCode("100");
dept.setName("Dept1");// select * from dept where code like '100%' and name like '%Dept1%';
Specification<Dept> spec = new Specification<Dept>() {@Overridepublic Predicate toPredicate(Root<Dept> root, CriteriaQuery<?> query, CriteriaBuilder cb) {List<Predicate> predicates = new ArrayList<>();// 模糊查询(前缀匹配)if (dept.getCode() != null && !dept.getCode().isEmpty()) {predicates.add(cb.like(root.get("code"), dept.getCode() + "%"));}// 模糊查询if (dept.getName() != null && !dept.getName().isEmpty()) {predicates.add(cb.like(root.get("code"), '%' + dept.getCode() + "%"));}return query.where(predicates.toArray(new Predicate[predicates.size()])).getRestriction();}
};
List<Dept> deptList = deptRepository.findAll(Example.of(dept));
除了equal、notEqual, 针对日期、数字类型,还有gt、ge、lt、le等常用比较符。
自定义接口
JPA
JPA支持接口规范方法名查询,一般查询方法以 find、findBy、read、readBy、get、getBy为前缀,JPA在进行方法解析的时候会把前缀取掉,然后对剩下部分进行解析。例如:
@Repository
public interface DeptRepository extends JpaRepository<Dept, Long> {// 调用此方法时,会自动生成 where code = ? 的条件Dept getByCode(String code);
}
常用的方法命名有:
| 关键字 | 方法命名 | sql where字句 |
|---|---|---|
| Distinct | findDistinctByLastnameAndFirstname | select distinct … where x.lastname = ?1 and x.firstname = ?2 |
| And | findByNameAndPwd | where name= ? and pwd =? |
| Or | findByNameOrSex | where name= ? or sex=? |
| Is,Equals | findById, findByIdIs, findByIdEquals | where id= ? |
| Between | findByIdBetween | where id between ? and ? |
| LessThan | findByIdLessThan | where id < ? |
| LessThanEquals | findByIdLessThanEquals | where id <= ? |
| GreaterThan | findByIdGreaterThan | where id > ? |
| GreaterThanEquals | findByIdGreaterThanEquals | where id > = ? |
| After | findByIdAfter | where id > ? |
| Before | findByIdBefore | where id < ? |
| IsNull | findByNameIsNull | where name is null |
| isNotNull,NotNull | findByNameNotNull | where name is not null |
| Like | findByNameLike | where name like ? |
| NotLike | findByNameNotLike | where name not like ? |
| StartingWith | findByNameStartingWith | where name like ‘?%’ |
| EndingWith | findByNameEndingWith | where name like ‘%?’ |
| Containing | findByNameContaining | where name like ‘%?%’ |
| OrderBy | findByIdOrderByXDesc | where id=? order by x desc |
| Not | findByNameNot | where name <> ? |
| In | findByIdIn(Collection<?> c) | where id in (?) |
| NotIn | findByIdNotIn(Collection<?> c) | where id not in (?) |
| True | findByEnabledTue | where enabled = true |
| False | findByEnabledFalse | where enabled = false |
| IgnoreCase | findByNameIgnoreCase | where UPPER(name)=UPPER(?) |
| First,Top | findFirstByOrderByLastnameAsc | order by lastname limit 1 |
| FirstN,TopN | findTop3ByOrderByLastnameAsc | order by lastname limit 3 |
MPP
MyBatisPlus没有JPA那样可以根据接口的方法名自动组装查询条件,但是可以利用Java8的接口默认实现来达到同样的目的,只不过需要编写少量的代码:
import org.apache.ibatis.annotations.Mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;@Mapper
public interface DeptMapper extends BaseMapper<Dept> {default Dept getByCode(String code) {return selectOne(Wrappers.<Dept>lambdaWrapper().eq(Dept::getCode, code));}
}
自定义SQL
JPA支持通过@Query注解和XML的形式实现自定义SQL,而MyBatis支持通过@Select、@Delete、@Update、@Script注解和XML的形式实现自定义SQL。
JPA
JPA的自定义SQL分为JPQL(Java Persistence Query Language Java 持久化查询语言)和原生SQL两种。
JPQL:
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;@Repository
public interface DeptRepository extends JpaRepository<Dept, Long> {@Query(value = "select d from Dept d where d.code = ?1")Dept getByCode(String code);@Modifying@Query(value = "delete from Dept d where d.code = :code")int deleteByCode(@Param("code") String code);
}
原生SQL
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;@Repository
public interface DeptRepository extends JpaRepository<Dept, Long> {@Query(value = "SELECT * FROM dept WHERE name = ?1", countQuery = "SELECT count(*) FROM dept WHERE name = ?1", nativeQuery = true)Page<Dept> findByName(@Param("name") String name, Pageable pageable);
}
XML形式:
/resource/META-INFO/orm.xml
<named-query name="Dept.getByCode"><query> select d from Dept d where d.code = ?1</query>
</named-query>
<named-native-query name="Dept.deleteByCode"><query> DELETE FROM dept WHERE code = ?1</query>
</named-native-query>
MyBatis
JPA的自定义SQL分为注解形式和XML形式
注解形式:
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.baomidou.mybatisplus.core.metadata.IPage;@Mapper
public interface DeptMapper extends BaseMapper<Dept> {@Select(value = "SELECT * FROM dept WHERE code = #{code}")Dept getByCode(@Param("code") String code);@Delete("DELETE FROM dept WHERE code = #{code}")int deleteByCode(@Param("code") String code);@Select(value = "SELECT * FROM dept WHERE name = #{name}")IPage<Dept> findByName(@Param("name") String name, IPage<Dept> page);
}
XML形式:
/resource/mapper/DeptMapper.xml
<select id = "getByCode", resultType = "Dept">SELECT * FROM dept WHERE code = #{code}
</select>
<delete id = "deleteByCode">DELETE FROM dept WHERE code = #{code}
</select>
<select id = "findByName">SELECT * FROM dept WHERE name = #{name}
</select>
相关文章:

Spring Data JPA 与 MyBatisPlus的比较
前言 JPA(Java Persistence API)和MyBatis Plus是两种不同的持久化框架,它们具有不同的特点和适用场景。 JPA是Java官方的持久化规范,它提供了一种基于对象的编程模型,可以通过注解或XML配置来实现对象与数据库的映射…...

【C++】STL-list的使用
目录 1、list的使用 1.1 list的构造 1.2 list的遍历 1.3 list capacity 1.4 list element access 1.5 容量相关 list是一个带头双向循环链表 1、list的使用 1.1 list的构造 1.2 list的遍历 list只有两种遍历方式,因为没有operator[] 因为list的双向链表&am…...
)
进度条(小程序)
缓冲区的概念 缓冲区是内存中的一个临时存储区域,用来存放输入或输出数据。在标准 I/O 库中,缓冲区的使用可以提高数据处理的效率。例如,当向终端输出文本时,字符通常存储在缓冲区中,直到缓冲区满或者遇到特定条件时才…...
PyCharm安装教程(超详细图文教程)
一、下载和安装 1.进入PyCharm官方下载,官网下载地址: https://www.jetbrains.com/pycharm/download/ 专业版安装插件放网盘了,网盘下载即可:itcxy.xyz/229.html2.安装 1.下载后找到PyCharm安装包,然后双击双击.ex…...

金蝶BI应收分析报表:关于应收,这样分析
这是一张出自奥威-金蝶BI方案的BI应收分析报表,是一张综合运用了筛选、内存计算等智能分析功能以及数据可视化图表打造而成的BI数据可视化分析报表,可以让企业运用决策层快速知道应收账款有多少?账龄如何?周转情况如何?…...
salmon使用体验
文章目录 salmon转录本定量brief模式一:fastq作为输入文件需要特别注意得地方 模式二: bam文件作为输入 salmon转录本定量 brief 第一点是,通常说的转录组分析其中有一项是转录本定量,这是一个很trick的说话,说成定量…...

Ubuntu 20.04 安装 Ansible
使用官方的 Ubuntu PPA 更新包列表: apt update安装软件属性常用命令 apt install software-properties-common添加 Ansible PPA 到系统: add-apt-repository --yes --update ppa:ansible/ansible再次更新包列表以包括新添加的 PPA: apt …...

TypeScript学习笔记:强类型JavaScript的优雅之旅
在前端开发领域,JavaScript以其灵活性和广泛的支持度成为无可争议的王者。然而,随着项目规模的增长,JavaScript的动态类型特性开始暴露出一些问题,比如代码的可维护性、类型错误难以提前发现等。为了解决这些问题,Micr…...
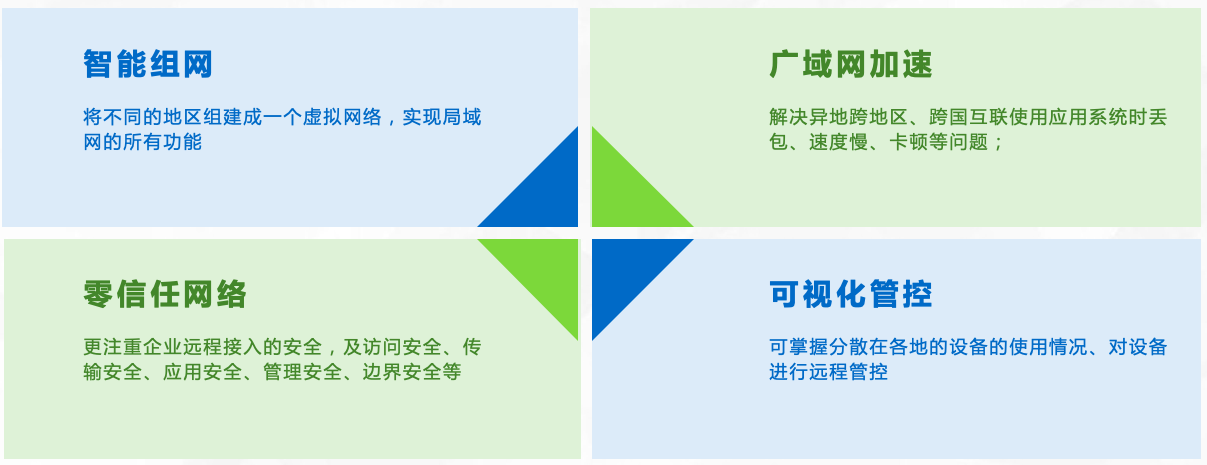
监控异地组网怎么组网?
监控异地组网是指在不同地域的网络环境下,实现对监控设备的远程访问和管理。在传统的网络环境下,由于网络限制和设备配置等问题,监控设备的远程访问往往受到一定的限制和困扰。为了解决这个问题,引入了天联组网技术,实…...
将本地托管模型与 Elastic AI Assistant 结合使用的好处
作者:来自 Elastic James Spiteri, Dhrumil Patel 当今公共部门组织利用生成式人工智能解决安全挑战的一种方式。 凭借其筛选大量数据以发现异常模式的能力,生成式人工智能现在在帮助团队保护其组织免受网络威胁方面发挥着关键作用。 它还可以帮助安全专…...

Linux的内核态和用户态
一、Linux操作系统运行在两种不同的运行模式下:内核态(Kernel Mode)和用户态(User Mode) 内核态(Kernel Mode): 内核态也称为特权模式或系统模式,是操作系统内核执行代码…...

springboot利用Redis的Geo数据类型,获取附近店铺的坐标位置和距离列表
文章目录 GEO介绍GEO命令行应用添加地理坐标位置获取指定单位半径的全部地理位置列表springboot 的实际应用 GEO介绍 在Redis 3.2版本中,新增了一种数据类型:GEO,它主要用于存储地理位置信息,并对存储的信息进行操作。 GEO实际上…...

Vitis HLS 学习笔记--理解串流Stream(2)
目录 1. 简介 2. 极简的对比 3. 硬件模块的多次触发 4. 进一步探讨 do-while 5. 总结 1. 简介 在这篇博文中《Vitis HLS 学习笔记--AXI_STREAM_TO_MASTER-CSDN博客》,我分享了关于 AXI Stream 接口的实际应用案例。然而,尽管文章中提供了代码示例&…...

Golang | Leetcode Golang题解之第80题删除有序数组中的重复项II
题目: 题解: func removeDuplicates(nums []int) int {n : len(nums)if n < 2 {return n}slow, fast : 2, 2for fast < n {if nums[slow-2] ! nums[fast] {nums[slow] nums[fast]slow}fast}return slow }...

uniapp自定义websocket类实现socket通信、心跳检测、连接检测、重连机制
uniapp自定义websocket类实现socket通信、心跳检测、检测连接、重连机制,仿vue-socket插件功能实现发送序列号进行连接检测,发送消息时42【key,value】格式,根据后端返回数据和需要接收到的数据做nsend与onSocketMessage的修改 //使用socket…...
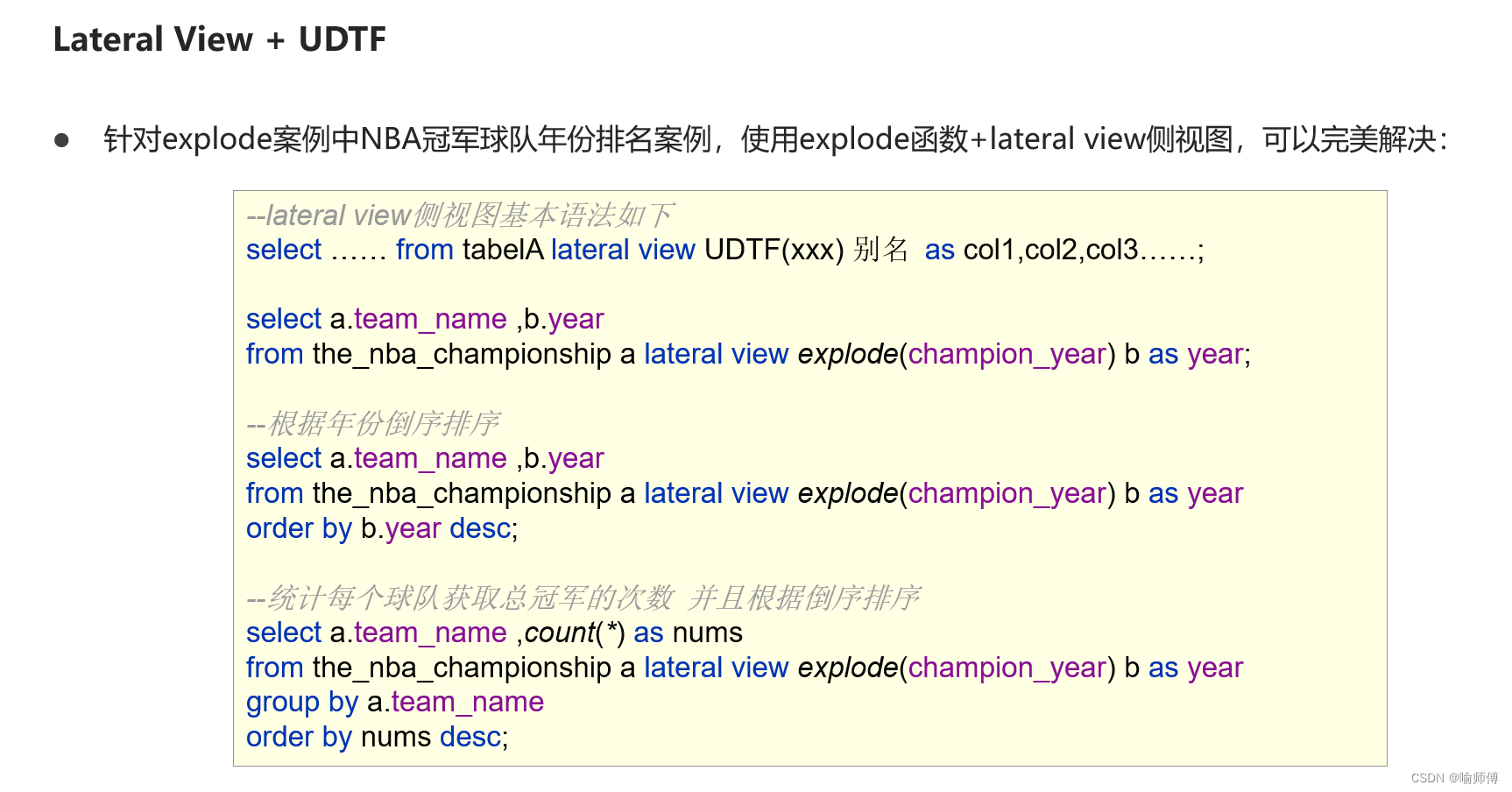
Hive UDTF之explode函数、Lateral View侧视图
Hive UDTF之explode函数 Hive 中的 explode() 函数是一种用于处理数组类型数据的 User-Defined Table-Generating Function (UDTF)。它将数组拆分成多行,每个数组元素对应生成的一行数据。这在处理嵌套数据结构时非常有用,例如处理 JSON 格式的数据。 …...

智慧公厕打造智慧城市新标杆
公共厕所作为城市基础设施的重要组成部分,直接关系到市民的生活品质和城市形象。传统的公厕管理方式存在着许多问题,如环境脏乱、清洁不及时等,给市民带来了诸多不便和不满。而智慧公厕作为一种全新的管理模式,通过物联网、大数据…...

字节发布文生图模型PuLID:高效身份ID特征定制,单张图像克隆AI虚拟分身
前言 字节研究团队近日提出了一种新型的文生图身份ID定制方法PuLID(Pure and Lightning ID Customization)。相较于传统的微调方法,PuLID无需复杂的参数优化就可以实现高效的身份ID定制,且能最大程度减少对原始模型行为的干扰。 PuLID是通过将轻量级的…...
SpringBoot启动流程分析之创建SpringApplication对象(一)
SpringBoot启动流程分析之创建SpringApplication对象(一) 目录: 文章目录 SpringBoot启动流程分析之创建SpringApplication对象(一)1、SpringApplication的构造方法1.1、推断应用程序类型1.2、设置Initializers1.3、设置Listener1.4、推断main方法所在类 流程分析…...

SSH简介 特点以及作用
引言 SSH(Secure Shell)是一种用于安全远程访问和数据传输的网络协议。它提供了一种安全的机制,使得用户可以在不安全的网络中安全地进行远程登录、命令执行和文件传输。SSH通过加密技术和认证机制来保护数据的安全性,防止数据在…...

STM32CubeMX+STM32CubeIDE:STM32G030F6P6TR的免费开发生态入门
STM32G030F6P6TR:超值型Cortex-M0 MCU如何以最小封装实现64MHz性能突破在嵌入式系统设计中,“性价比”往往意味着在某些关键指标上的妥协——更小的封装通常伴随更低的主频或更少的外设。然而,STM32G0系列的推出打破了这一行业惯例。STM32G03…...

GitHub星标6.6k+的WindTerm,除了快还有这些隐藏技巧:自动补全、锁屏密码重置、主题切换
GitHub星标6.6k的WindTerm高阶技巧:解锁专业级终端体验 当大多数用户还在用默认配置与终端工具"和平共处"时,真正的效率追求者早已开始挖掘那些藏在菜单深处的生产力加速器。作为GitHub上获得6.6k星标的现象级终端工具,WindTerm的…...

从硬开关到软开关:推挽谐振变换器原理与PSIM仿真实战
1. 从经典到谐振:为什么我们需要推挽变换器?在电源设计的工具箱里,推挽变换器(Push-Pull Converter)绝对算得上是一位“老将”。它的核心思想非常直观:利用一个带中心抽头的变压器,让两个开关管…...

开发AI Agent时如何通过Taotoken灵活调度不同模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发AI Agent时如何通过Taotoken灵活调度不同模型 在构建复杂的AI Agent系统时,一个常见的需求是根据不同的任务类型&a…...

三步解锁九大网盘高速下载:LinkSwift终极直链解析教程
三步解锁九大网盘高速下载:LinkSwift终极直链解析教程 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

瑞萨e² studio嵌入式IDE深度解析:从图形化配置到多核开发的实战指南
1. 项目概述:为什么我们需要关注e studio?如果你是一位嵌入式开发者,尤其是长期耕耘在瑞萨电子(Renesas)MCU生态中的朋友,那么对e studio这个名字一定不会陌生。它不是一个横空出世的全新IDE,而…...

开源AI智能体dreamGPT:让大语言模型学会自主思考与目标探索
1. 项目概述:当AI学会“做梦”,一个开源智能体的自我进化实验最近在开源社区里,一个名为dreamGPT的项目引起了我的注意。它来自 DivergentAI,名字本身就充满了想象力——“梦想GPT”。这可不是一个简单的聊天机器人或者代码生成工…...

从零构建私有容器镜像仓库:基于Registry 2与MinIO的实战部署指南
1. 项目概述:从零到一构建一个现代化的容器镜像仓库 在云原生和微服务架构成为主流的今天,容器镜像作为应用交付的标准单元,其存储、分发和管理的重要性不言而喻。Docker Hub 是大家最熟悉的公共仓库,但在企业级生产环境中&#…...
)
Trae IDE 实战:打造“创建完美智能体助手”(交互式+自动生成+模板删减,新手无脑上手)
Trae IDE 实战:打造“创建完美智能体助手”(交互式+自动生成+模板删减,新手无脑上手) 前言:在AI研发提效浪潮中,Trae IDE的自定义Agent已成为开发者的核心协作工具。本文聚焦「创建完美智能体助手」的打造,全程贴合Trae原生能力,主打“交互式引导、全自动文件生成、模…...

多项目并行开发时借助 Taotoken 统一管理各模型 API 密钥的实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多项目并行开发时借助 Taotoken 统一管理各模型 API 密钥的实践 当你同时推进多个 AI 应用项目时,可能会遇到一个典型的…...