pg数据库学习知识要点分析-1
知识要点1 对象标识OID
在PostgreSQL内部,所有的数据库对象都通过相应的对象标识符(object identifier,oid)进行管理,这些标识符是无符号的4字节整型。数据库对象与相应oid 之间的关系存储在对应的系统目录中,依具体的对象类型而异。例如数据库和堆表对象的 oid 分别存储在pg_database和pg_class中,因此,当你希望找出oid时,可以执行以下查询:

sampledb=# SELECT datname, oid FROM pg_database WHERE datname = 'sampledb'; sampledb=# SELECT relname, oid FROM pg_class WHERE relname = 'sampletbl';
OID不变,但是relfilenode在进行ddl操作后会发生变化。
知识要点2 软件物理结构
1 PGBASE,PGDATA,CONF文件。
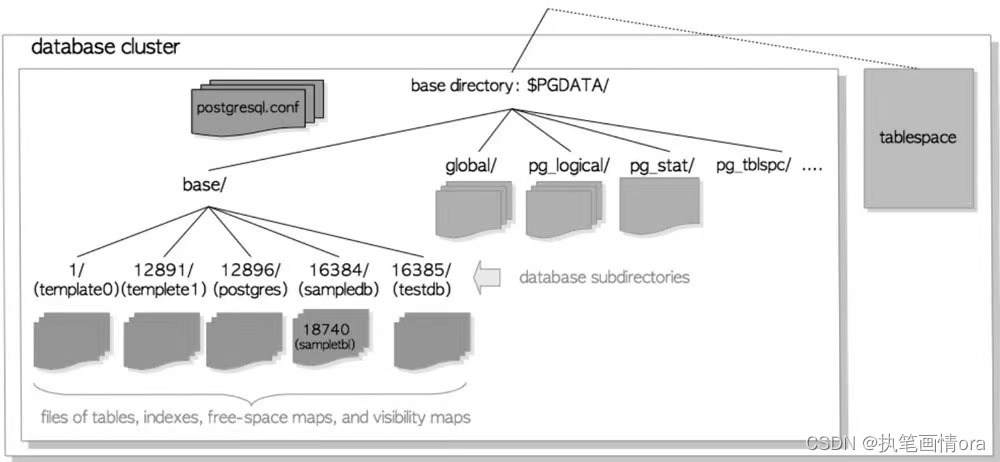
4个配置文件
pg_hba.conf 控制PG数据库客户端认证
pg_ident.conf控制用户名映射。
postgresql.conf配置参数
postgresql.auto.conf存储使用alter system调整的参数
表空间文件结构布局
select pg_relation_filepath(sampletbl);
postgres=# select pg_relation_filepath('pg_class');
base/13593/1259
PG中表空间是基础PGDATA目录之外的附加数据区域。8.0版本引入该功能。
本身的初始化数据目录要对外面的表空间有一个管理,那么pg_tblspc就实现了功能。
create tablespace tbs1 location '/home/postgres/datafile/tbs1';
[postgres@localhost pg_tblspc]$ pwd
/home/postgres/PGDATA/pg_tblspc
[postgres@localhost pg_tblspc]$ ls -la
lrwxrwxrwx 1 postgres postgres 28 May 4 15:34 16388 -> /home/postgres/datafile/tbs1
[postgres@localhost pg_tblspc]$
create table test02 (id int) tablespace tbs1;
insert into test02 select 3;
postgres=# select oid,spcname from pg_tablespace;
oid | spcname
-------+------------
1663 | pg_default
1664 | pg_global
16388 | tbs1
(3 rows)
postgres=# select oid,reltablespace,relfilenode,relowner from pg_class where relname='test02';
oid | reltablespace | relfilenode | relowner
-------+---------------+-------------+----------
16392 | 16388 | 16392 | 10
(1 row)
[postgres@localhost 13593]$ pwd
/home/postgres/datafile/tbs1/PG_12_201909212/13593 --这个目录是个啥??
[postgres@localhost 13593]$ ls
16392
postgres=#
表文件路径查询:
select pg_relation_filepath('test02');
[postgres@localhost 13593]$ psql
psql (12.18)
Type "help" for help.postgres=# select pg_relation_filepath('test02');
pg_relation_filepath
---------------------------------------------
pg_tblspc/16388/PG_12_201909212/13593/16392
(1 row)postgres=#

执行 CREATE TABLESPACE语句会在指定的目录下创建表空间。在该目录下还会创建版本特定的子目录(例如PG_9.4_201409291)。版本特定的命名方式为:
PG_主版本号_目录版本号
例如在/pg/data/ 目录中创建表空间 new_TBLSPC 对应的OID为 16384,则会在表空间下创建一个名为 pg_version_banben的字目录。
cd /pg/data/pg_11.2_20220121/16384
如果在表空间中创建新表,则新表对应的OID值 创建在/pg/data/pg_11.2_20220121/16384中,而且对应的数据段大小可以在初始化时制定大小,超过大小后分裂为OID.1,OID.2文件(热点快数据优化?)。还有表及其他对象对应的管理文件(空闲空间映射,可见性映射等fsm和vm文件)
$PGDATA/pg_tblspc/16384 -------------> /pg/data/
堆表文件的内部布局
数据文件包括(堆表,索引,空间空间映射,可见性空间映射文件 )内部被划分为固定大小的页
或者叫做区块 8KB。从0开始编号叫做区块号。
为了识别表中的元组,数据库内部会使用元组标识符(tuple identifier TID)
- TID:由一组值组成分别为元组所属页面的区块号和指向元组的行指针偏移号,TID典型应用为索引。
- 大小超过2kb的堆元组会使用toast 超大属性存储技术。
PG进程和内存架构
C/S架构,客户端/服务器风格
pgserver实际上是一些列协同工作的进程集合。
[postgres@localhost ~]$ ps -ef|grep postgres |grep -v grep|grep 1*
postgres 30957 1 0 May03 ? 00:00:00 /home/postgres/postgresql/bin/postgres -D /home/postgres/PGDATA
postgres 30958 30957 0 May03 ? 00:00:00 postgres: logger
postgres 30960 30957 0 May03 ? 00:00:00 postgres: checkpointer
postgres 30961 30957 0 May03 ? 00:00:00 postgres: background writer
postgres 30962 30957 0 May03 ? 00:00:00 postgres: walwriter
postgres 30963 30957 0 May03 ? 00:00:00 postgres: autovacuum launcher
postgres 30964 30957 0 May03 ? 00:00:00 postgres: stats collector
postgres 30965 30957 0 May03 ? 00:00:00 postgres: logical replication launcher
[postgres@localhost ~]$
本地内存区域和共享内存区域。
[postgres@localhost ~]$ ipcs -ma|grep postgres
0x0052e2c1 1376262 postgres 600 56 6
[postgres@localhost ~]$
本地内存区域:由每个后端进程分配供自己使用 类似pga。
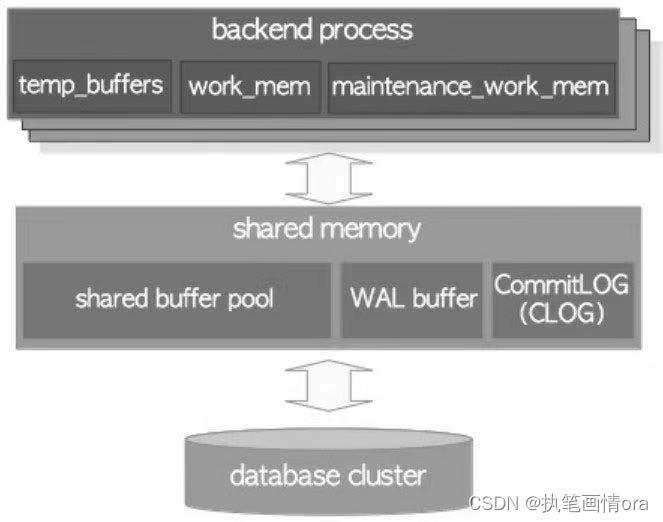
如何去查看进程占用的内存???
linux用top


1 PG时CS架构,采用多进程架构。
2 PG服务进程是所有进程的父进程。postgres server process.
3 后端进程,backed process负责处理客户端发出的查询语句。
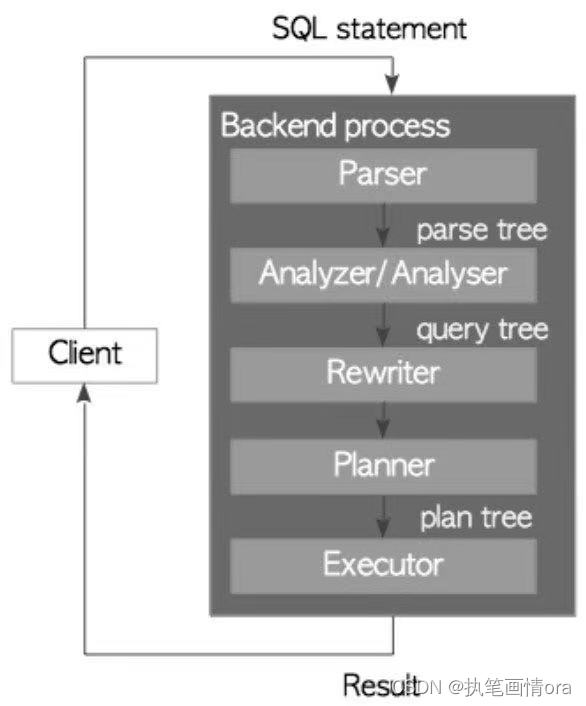
- 重写器:重写器会根据存储在pg_rules中的规则对查询进行转换。
- pg不支持提示hint。
4 各种后台进程background process 负责执行各种数据库管理任务(例如清理过程和存档过程)
5 各种复制进程(replication associate process负责复制流。)
6 pg_ctl start会启动postgres server process父进程,它会在内存中分配共享内存区域,启动各种后台进程。如果有必要还要启动replication并等待客户端的连接请求。有客户端连接它就会启动一个后端进程,然后由后端进程处理该客户端的所有查询请求。(oracle 1-1的专享连接模式)
7 PG没有原生的资源池,可以采用池化中间件pgbouncer pgpool-II
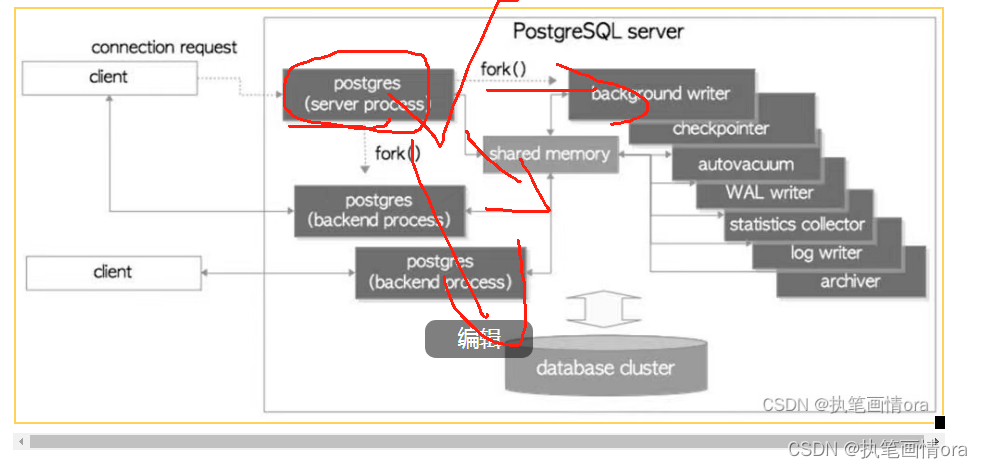
PG后台进程解释
登录pg服务器,使用ps -ef|grep postgres可以发现有很对pg进程以下简要解释下各个后台进程的含义。
background writer 本进程负责吧共享池中的脏页刷新到磁盘中。
checkpointer负责检查点。
autoavcuum launcher自动清理死元组清理工作
WAL writer 预写日志管理。
statistic collector收集统计信息,例如pg_STAT_ACTIVITY,PG_STAT_DATABASE等。
logging collector日志采集统计
archiver wal日志归档。
backed process,例如10.228.11.1:577423 progres格式。
单表查询的代价估计
所有被执行的操作都有着相应的代价函数
cost_seq_scan()顺序扫描
cost_index()索引扫描
对于cost,pg定义为3种,1 启动代价,运行代价,总代价。
启动代价:在读取到第一条元组前花费的代价。索引扫描:读取目标表索引页获取第一个元组的代价。
运行代价:获取全部元组的代价。
总代价:前面2个的和。explain,命令只显示启动代价和总代价。
postgres=# explain select * from test02;
QUERY PLAN
------------------------------------------------------
Seq Scan on test02 (cost=0.00..1.01 rows=1 width=4)
(1 row)
启动代价为0.00,总代价为1.01
顺序扫描代价评估
postgres=# create table tbl(id int primary key,data int);
CREATE TABLE
postgres=# create index tbl_data_idx on tbl(data);
CREATE INDEX
postgres=# insert into tbl select generate_series(1,10000),generate_series(1,10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# \d tbl
Table "public.tbl"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | not null |
data | integer | | |
Indexes:
"tbl_pkey" PRIMARY KEY, btree (id)
"tbl_data_idx" btree (data)
postgres=#
postgres=# select relpages,reltuples from pg_class where relname='tbl';
relpages | reltuples
----------+-----------
45 | 10000
(1 row)
postgres=#
run_cost=(cpu_tuple_cos+cpu_operator_cost)*N(tuples)+seq_page_cost*N(pages)
而3个cost值在配置文件postgresql.conf中都是可以设置的,存在默认值的。
0.01/0.0025/1.0
(0.01+0.0025)*1000+1.0*45=170
postgres=# explain select * from tbl where id<8000;
QUERY PLAN
--------------------------------------------------------
Seq Scan on tbl (cost=0.00..170.00 rows=7999 width=8)
Filter: (id < 8000)-----表级别过滤谓词,并不影响扫描的page数。
(2 rows)
postgres=#
索引扫描代价评估
postgres=# select relpages,reltuples from pg_class where relname='tbl_data_idx';
relpages | reltuples
----------+-----------
30 | 10000
(1 row)
事务标识(并发控制-一致性和隔离性)
ACID
原子性一个事务要不全成功要不全失败。
一致性:
隔离性:
持久性:wal日志
每种技术都有不同的变体,在MVCC中每个写操作都会创建一个新版本的数据项,并保留其就版本(undo,page保持标记等),当其他事务读取数据对象时,系统会选择一个版本让它读取,确保事务间相互隔离。(读不阻塞写,写不阻塞读MVCC)
PG的MVCC是怎么样的那?
快照隔离。(snapshot isolation SI)
像oracle mysql都是用undo来实现SI。而PG采用的是新数据被插入到相关的表页中,读取对象时,postgresql根据可见性规则(mysql+read view+undo?),为每个事务选择合适的对象版本作为响应。
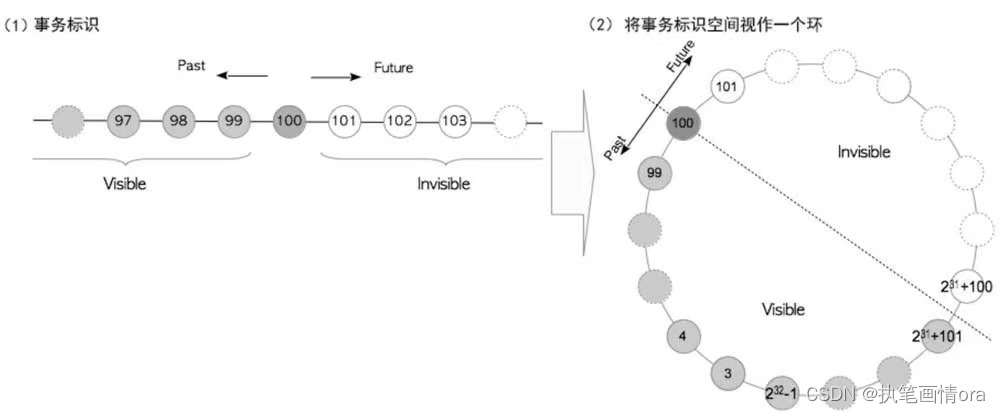
每个事务开始时,事务管理器会为其分配一个事务标识 tid,最大值42亿,32位无符号整型。
select txid_current();--查看当前事务的txid。012表示预留的txid。
txid可以互相比较大小,例如txid=100 则小于100的属于过去,大于100的属于未来。
因为txid在逻辑上是无限的,而实际系统中的txid空间不足(4B整型的取值空间大小约42亿),因此PostgreSQL将txid空间视为一个环。对于某个特定的txid,其前约21亿个txid属于过去,其后约21亿个txid属于未来
提交日志PG_XACT
postgresql在提交日志中CLOG,中保存事务的状态,提交日志分配在内存中,并用于事务处理的全过程,
事务状态
postgresql定义了4种事务状态,in_process,commited,aborted和sub commited。
提交日志如何工作
提交日志是一个数组,在共享内存中一些列8K页面组成。数组的序列号代表的事务的标识tid,其内容则是事务的状态,

T1:txid 200提交;txid 200的状态从IN_PROGRESS变为COMMITTED。
T2:txid 201中止;txid 201的状态从IN_PROGRESS变为ABORTED。
txid 不断前进,当 CLOG空间耗尽无法存储新的事务状态时,就会追加分配一个新的页面。
当需要获取事务的状态时,PostgreSQL将调用相应内部函数读取CLOG,并返回所请求事务的状态。
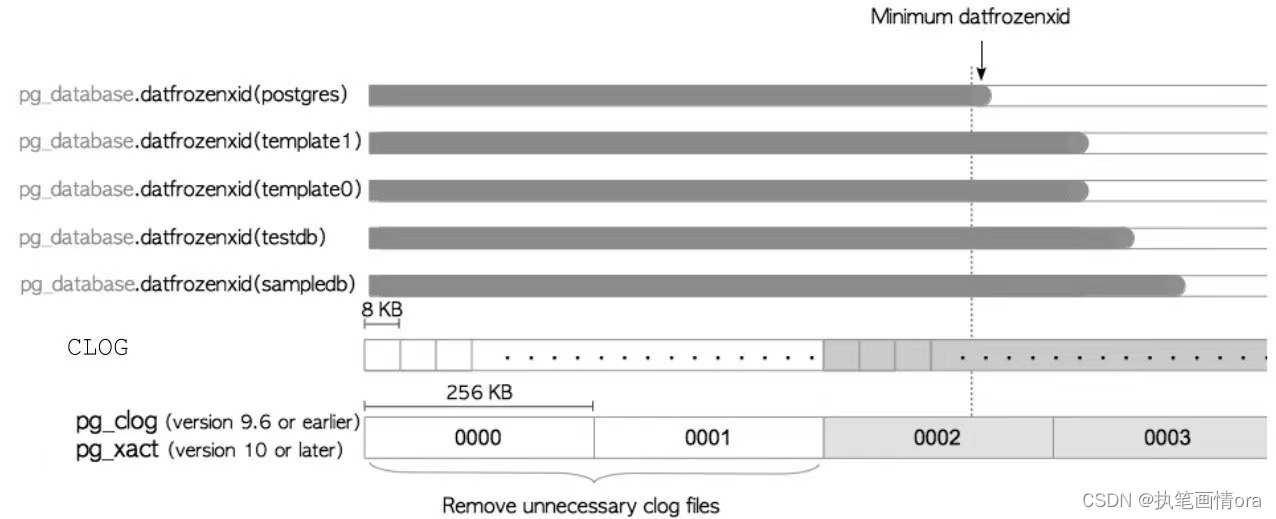
5.4.3 提交日志的维护
当PostgreSQL关机或执行存档过程时,CLOG数据会写入pg_clog子目录下的文件中(注意,在10.0版本中,pg_clog被重命名为pg_xact)。这些文件被命名为0000,0001等。文件的最大尺寸为256 KB。例如当CLOG使用8个页面时,从第1页到第8页的总大小为64 KB,这些数据会写入文件0000(64 KB)中,而当CLOG使用37个页面时(296 KB),数据则会写入0000和0001两个文件中,其大小分别为256 KB和40 KB。
当PostgreSQL启动时会加载存储在pg_clog(pg_xact)中的文件,用其数据初始化CLOG。
CLOG的大小会不断增长,因为只要CLOG一填满就会追加新的页面。但并非所有数据都是必要的。
clog是如何删除的那???
CLOG存储着事务的状态。当更新pg_database.datfrozenxid时, PostgreSQL会尝试删除不必要的CLOG文件。注意,相应的CLOG页面也会被删除。
图 6.7 给出了一个例子。如果 CLOG 文件 0002 中包含最小的 pg_database.datfro zenxid,则可以删除旧文件(0000 和0001),因为存储在这些文件中的所有事务在整个数据库集簇中已经被视为冻结了。
元组
读取
两种典型的读取方式:顺序扫描,索引扫描。
通过扫描每一页中的行指针,依次读取所有页面的数据。
B树扫描 :索引文件包含 索引元组,索引元组由一对健值组成,健值和TID。

pg还支持TID扫描 ,位图扫描 ,仅索引扫描。TID扫描时一种通过索引元祖直接获取数据的扫描。
或者例如使用select语句指定。
select * from test02 where ctid='(0,1)'---第0个页面的第一个元组信息。
postgres=# select * from test02 where ctid='(0,1)';
id
----
3
(1 row)postgres=# explain select * from test02 where ctid='(0,1)';
QUERY PLAN
------------------------------------------------------
Seq Scan on test02 (cost=0.00..1.01 rows=1 width=4)
Filter: (ctid = '(0,1)'::tid)
(2 rows)postgres=# explain select * from test02 where ctid='(0,2)';
QUERY PLAN
------------------------------------------------------
Seq Scan on test02 (cost=0.00..1.01 rows=1 width=4)
Filter: (ctid = '(0,2)'::tid)
(2 rows)postgres=# select * from test02 where ctid='(0,2)';
id
----
(0 rows)postgres=#
元祖包含的隐藏列
txid xmin xmax ctid 数据。(前面只显示核心的4个字段。)
postgres=# select txid_current(),xmin,xmax,ctid from pg_class limit 10;
488 | 36 | 0 | (0,46)
488 | 273 | 0 | (0,47)
488 | 1 | 0 | (1,19)
488 | 1 | 0 | (1,20)
488 | 1 | 0 | (1,21)
488 | 1 | 0 | (1,22)
488 | 1 | 0 | (1,23)
488 | 1 | 0 | (1,24)
488 | 1 | 0 | (1,25)
488 | 1 | 0 | (1,26)
postgres=#
postgres=#
元组的增删改FSM:用于插入和更新元组的自由空间映射。
通常不需要的元组,在POSTgres中被称为死元组。
增:
在插入中,新元组直接插入目标表的page中,如图所示:

Tuple_1:
· t_xmin设置为99,因为此元组由txid=99的事务所插入。
· t_xmax设置为0,因为此元组尚未被删除或更新。
· t_cid设置为0,因为此元组是由txid=99的事务所执行的第一条命令插入的。
· t_ctid设置为(0,1),指向自身,因为这是该元组的最新版本。
pageinspect
PostgreSQL自带了一个第三方贡献的扩展模块pageinspect,可用于检查数据库页面的具体内容。
testdb=# CREATE EXTENSION pageinspect; CREATE EXTENSION
testdb=# CREATE TABLE tbl (data text);
CREATE TABLE
testdb=# INSERT INTO tbl VALUES(A);
INSERT 0 1
testdb=# SELECT lp as tuple, t_xmin, t_xmax, t_field3 as t_cid, t_ctid FROM heap_page_items(get_raw_page(tbl, 0));
tuple | t_xmin | t_xmax | t_cid | t_ctid -------+--------+--------+-------+--------
1 | 99 | 0 | 0 | (0,1) (1 row)
12.18环境
postgres=# CREATE EXTENSION pageinspect;
ERROR: could not open extension control file "/home/postgres/postgresql/share/extension/pageinspect.control": No such file or directory
postgres-#
实验
postgres=# create table test(id int);
CREATE TABLE
postgres=# insert into test select 1;
INSERT 0 1
postgres=# select txid_current(),xmin,xmax,ctid from test limit 10;
txid_current | xmin | xmax | ctid
--------------+------+------+-------
491 | 490 | 0 | (0,1)
postgres=# insert into test select 2;
INSERT 0 1
postgres=# select txid_current(),xmin,xmax,ctid from test limit 10;
txid_current | xmin | xmax | ctid
--------------+------+------+-------
493 | 490 | 0 | (0,1) ----490事务插入
493 | 492 | 0 | (0,2) ----492事务插入
postgres=# update test set id=10;
UPDATE 2
postgres=# select txid_current(),xmin,xmax,ctid from test limit 10;
txid_current | xmin | xmax | ctid
--------------+------+------+-------
495 | 494 | 0 | (0,3)
495 | 494 | 0 | (0,4) --全部被494事务更新update。
删
在删除操作中,目标元组只是在逻辑上被标记为删除。目标元组的t_xmax字段将被设置成delete命令事务的txid。

假设tuple_1被事务111删除,在这种情况下Tuple_1的首部字段被t_xmax设置成111,如果事务txid=111已经提交,就不一定要tuple_1元组,通常不需要的元组此时已经成为死元组。
死元组最终将从页面中被移除,清除死元组的过程称为:VACUUM。
改
在更新操作中,PG在逻辑上实际执行的是删除最新的元组,并插入一条新的元组。

假设由txid=99的事务插入的行,被txid=100的事务更新两次。
当执行第一条UPDATE命令时,Tuple_1的t_xmax被设为txid 100,在逻辑上被删除,然后Tuple_2被插入,接下来重写Tuple_1的t_ctid以指向Tuple_2。Tuple_1和Tuple_2的头部字段设置如下。
Tuple_1:
· t_xmax被设置为100。
· t_ctid从(0,1)被改写为(0,2)。
Tuple_2:
· t_xmin被设置为100。
· t_xmax被设置为0。
· t_cid被设置为0。
· t_ctid被设置为(0,2)。
当执行第二条UPDATE命令时,和第一条UPDATE命令类似,Tuple_2被逻辑删除,Tuple_3被插入。Tuple_2和Tuple_3的首部字段设置如下。
Tuple_2:
· t_xmax被设置为100。
· t_ctid从(0,2)被改写为(0,3)。
Tuple_3:
· t_xmin被设置为100。
· t_xmax被设置为0。
· t_cid被设置为1。
· t_ctid被设置为(0,3)。
与删除操作类似,如果txid=100的事务已经提交,那么Tuple_1和Tuple_2就成了死元组,而如果txid=100的事务中止,Tuple_2和Tuple_3就成了死元组。
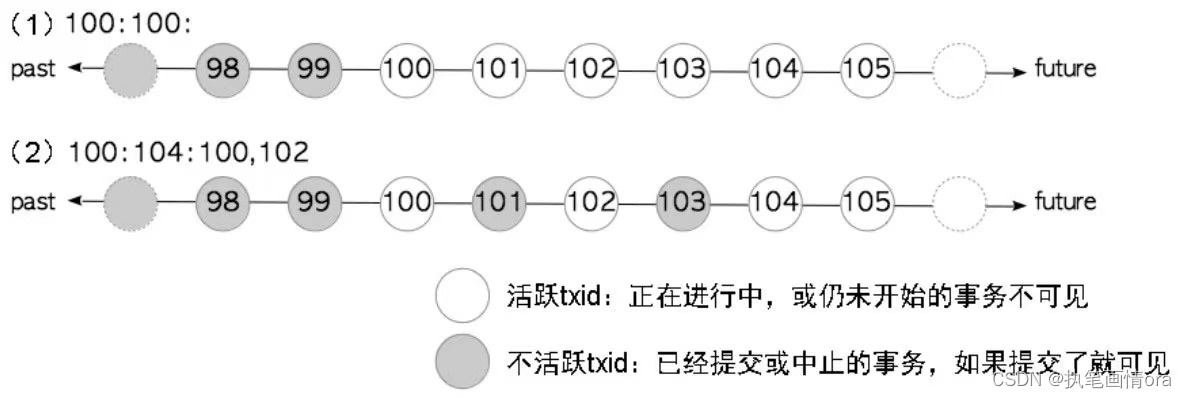
事务快照
select txid_current_snapshot();
xmin:xmax:xip_list。
postgres=# select txid_current_snapshot();
489:489:postgres=#
事务快照是一个数据集,存储某个特定事务在某个特定时间所看到的事务状态信息。哪些事务处于活跃状态(事务正在进行或者还没开始)。事务快照在PostgreSQL内部的文本表示格式为100:100,
100:100 意味着txid<100的事务处于非活跃状态,txid>=100的事务处于活跃状态。
清理过程VACUUM
为了移除死元组,清理过程有另种模式分别为并发清理与完整清理,清理过程会删除表文件每个页面的死元组而其他事务可以在运行时继续读取该表。
完整清理:不仅移除死元组,还会对活的元组进行碎片整理,此时表不可访问。
在8.0以前需要手动清理,直到出现autovacuum守护进程实现自动化。
由于清理过程需要全表扫描,因此代价过于高昂。 可见性映射提高了(VM)移除死元组的效率,并在后期的版本中VM增强。
postgresql FDW
需要进行配置扩展。
相关文章:
pg数据库学习知识要点分析-1
知识要点1 对象标识OID 在PostgreSQL内部,所有的数据库对象都通过相应的对象标识符(object identifier,oid)进行管理,这些标识符是无符号的4字节整型。数据库对象与相应oid 之间的关系存储在对应的系统目录中…...
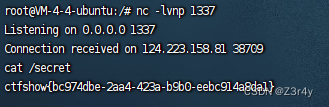
【Web】CTFSHOW 七夕杯 题解
目录 web签到 easy_calc easy_cmd web签到 CTF中字符长度限制下的命令执行 rce(7字符5字符4字符)汇总_ctf中字符长度限制下的命令执行 5个字符-CSDN博客7长度限制直接梭了 也可以打临时文件RCE import requestsurl "http://4ae13f1e-8e42-4afa-a6a6-1076acd08211.c…...

react native 设置屏幕锁定
原生配置 android 在android/app/src/main/AndroidManifest.xml在这个文件里的入口activity里添加 android:screenOrientation"portrait" <activityandroid:name".MainActivity"android:label"string/app_name" …...

探索 IPv6 协议:互联网的新一代寻址
目录 一.概述 IPv4 的问题和 IPv6 的新特性 IPv6 协议体系 二.IPv6 寻址架构:巨大的地址空间与灵活的寻址模式 IPv6 寻址概述 地址表示方法 地址前缀与地址类型标识 单播地址 任播地址 多播地址 特殊的 IPv6 地址 IPv6 主机与路由器寻址 地址分配 三.I…...

Ubuntu意外断电vmdk损坏--打不开磁盘“***.vmdk”或它所依赖的某个快照磁盘。
背景:电脑资源管理器崩溃卡死,强行断电重启,结果虚拟机打不开了,提示打不开磁盘“***.vmdk”或它所依赖的某个快照磁盘。 删除lck文件:失败vmware-vdiskmanager修复 :提示无法修复最终用 VMFS Recovery挂载…...

202466读书笔记|《一天一首古诗词》——借问梅花何处落,风吹一夜满关山
202466读书笔记|《一天一首古诗词》——借问梅花何处落,风吹一夜满关山 上册下册 《一天一首古诗词》作者李锡琴,蛮早前加入书架的已购买书籍,这次刚好有点时间,利用起来读完。 赏析没有细看,只读了诗词部分࿰…...

如何调用本地ollama的http请求接口
http://127.0.0.1:11434/api/generate 使用http post请求,参数 { "model": "qwen", "prompt": "为什么天空是蓝色?", "stream": false } 返回结果如下: {"model": "qwen",…...

【C】190 颠倒二进制位
颠倒给定的 32 位无符号整数的二进制位。 提示: 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因…...

蓝桥杯备战5.图书管理员
[NOIP2017]图书管理员 (nowcoder.com) #include<bits/stdc.h> #define endl \n #define int long long using namespace std; const int N 2e510,M1e310; int a[N]; int n,q; int check(int l,int x) {int tmppow(10,l);for(int i1;i<n;i){if(a[i]%tmpx){cout<&…...

微型显示器可以实时监测大脑活动
美国团队开发基于LED的设备,以可视化大脑活动,在脑外科手术中指导神经外科医生 来自加州大学圣地亚哥分校和马萨诸塞州总医院的工程师和医生开发了一种薄膜显示设备,该设备结合了电极网格和特殊的GaN LED,可以在手术过程中实时跟…...

移动端适配方案
移动端适配 方案 1:rem html font-size 方案 2:vw rem html font-size rem 是相对于 html 元素的 font-size 来设置的单位,通过在不同屏幕尺寸下动态修改 html 元素的 font-size 可达到适配效果 在开发中,我们只需要考虑两个…...

【Ajax零基础教程】-----第一课 Ajax简介
一、什么是ajax ajax即 Asynchronous javascript And XML (异步 javaScript 和 XML) 是一种创建交互式,快速动态应用的网页开发技术,无需重新加载整个网页的情况下,能够更新页面局部数据的技术。 二、为什么使用Ajax 通过在后台与服务器进行少…...
Swagger的使用)
大型医疗挂号微服务“马上好医”医疗项目(5)Swagger的使用
Swagger的简单介绍 Swagger 是一个 RESTful 接口文档的规范和工具集,它的目标是统一 RESTful 接口文档的格式和规范。在开发过程中,接口文档是非常重要的一环,它不仅方便开发者查看和理解接口的功能和参数,还能帮助前后端开发协同…...

C语言从头学04——介绍占位符和输出格式
占位符、输出格式都是与 printf() 相关的,当然其它函数也有用到占位符的。这里先介绍它们在 printf() 的使用。 一、先介绍占位符,所谓“占位符”通俗讲就是先占个位置,后边再找具体值(参数)代入进行显示的一种方法。先用一个例子说明…...
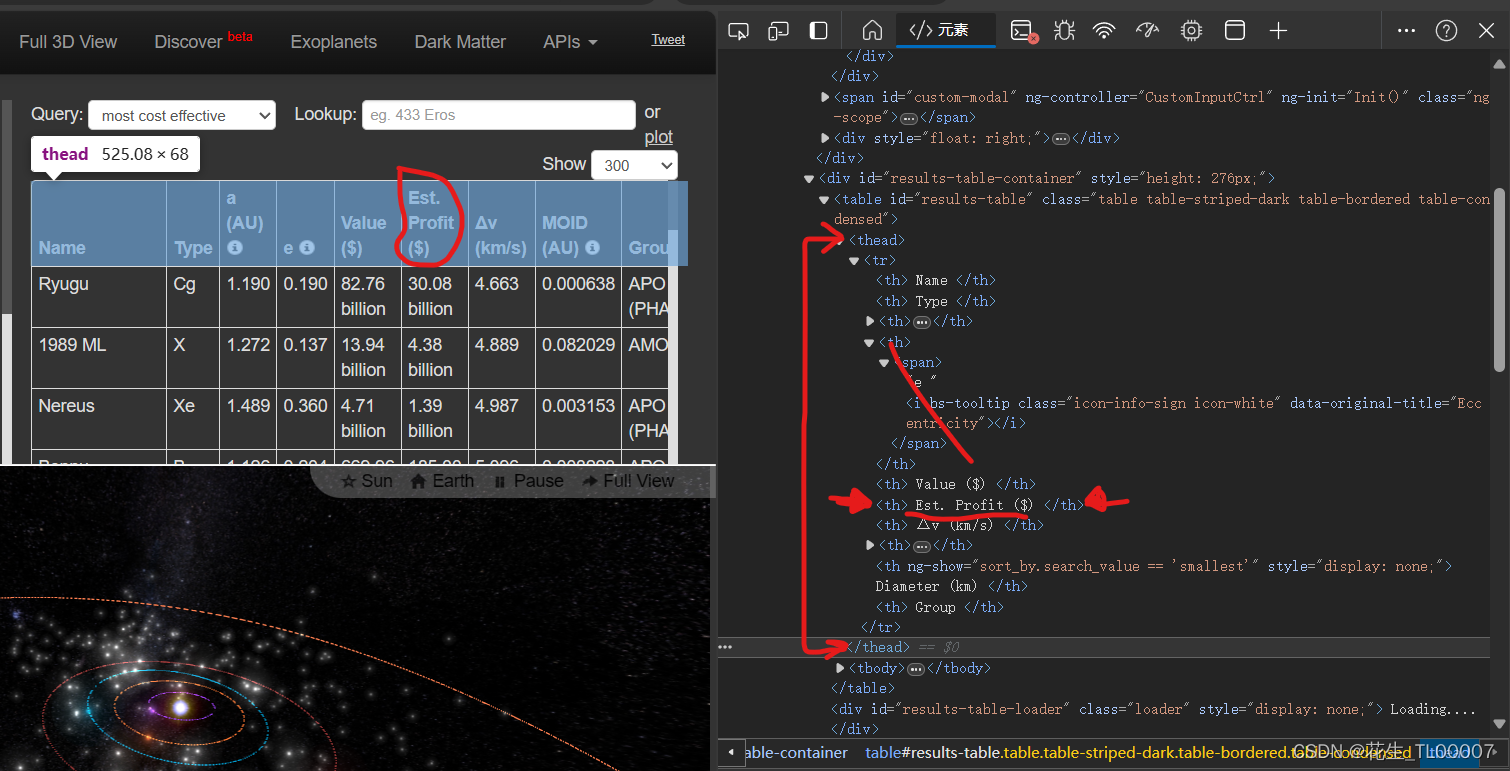
写爬虫代码抓取Asterank中小行星数据
2024年5月4日 问题来源 解决方案 回顾2023年7月14日自己写的爬虫代码 import requests import re import pandas as pd texts[] def getData(page):#每页评论的网址urlhttps://item.jd.com/51963318622.html#comment#添加headers,伪装成浏览器headers{User-Agent:…...
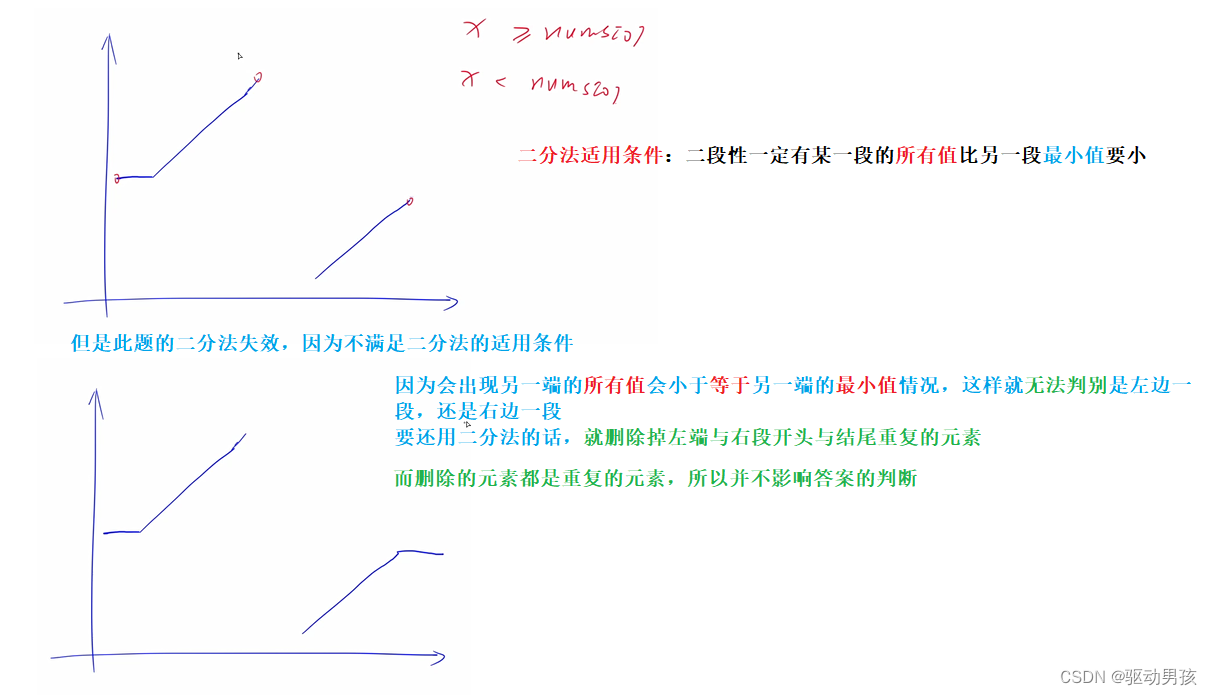
leetCode81. 搜索旋转排序数组 II
leetCode81. 搜索旋转排序数组 II 题目思路 可以二分后的具体思路见我的上篇博客 搜索旋转排序数组 代码 class Solution { public:bool search(vector<int>& nums, int target) {if(nums.empty()) return false;int R nums.size() - 1;while(R > 0 &&…...

在Ubuntu上怎么查看安装了哪些包?
2024年5月3日,周五晚上 在Ubuntu上,你可以使用以下命令来查看系统中已安装的包: 使用dpkg命令:dpkg --list这个命令将列出系统中所有已安装的软件包,包括名称、版本号和描述等信息。你可以使用 grep 命令来过滤结果&a…...
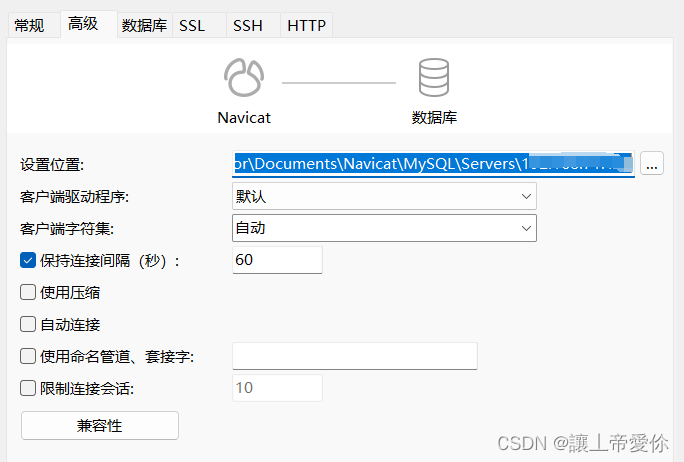
Navicat连接远程数据库时,隔一段时间不操作出现的卡顿问题
使用 Navicat 连接服务器上的数据库时,如果隔一段时间没有使用,再次点击就会出现卡顿的问题。 如:隔一段时间再查询完数据会出现: 2013 - Lost connection to MySQL server at waiting for initial communication packet, syste…...

修改页签标题 + 页签图表
修改图标 在App.vue下的created()里或者路由守卫中输入 var link document.querySelector("link[rel*icon]") || document.createElement("link"); link.type "image/x-icon"; link.rel "shortcut icon"; link.href require(l…...
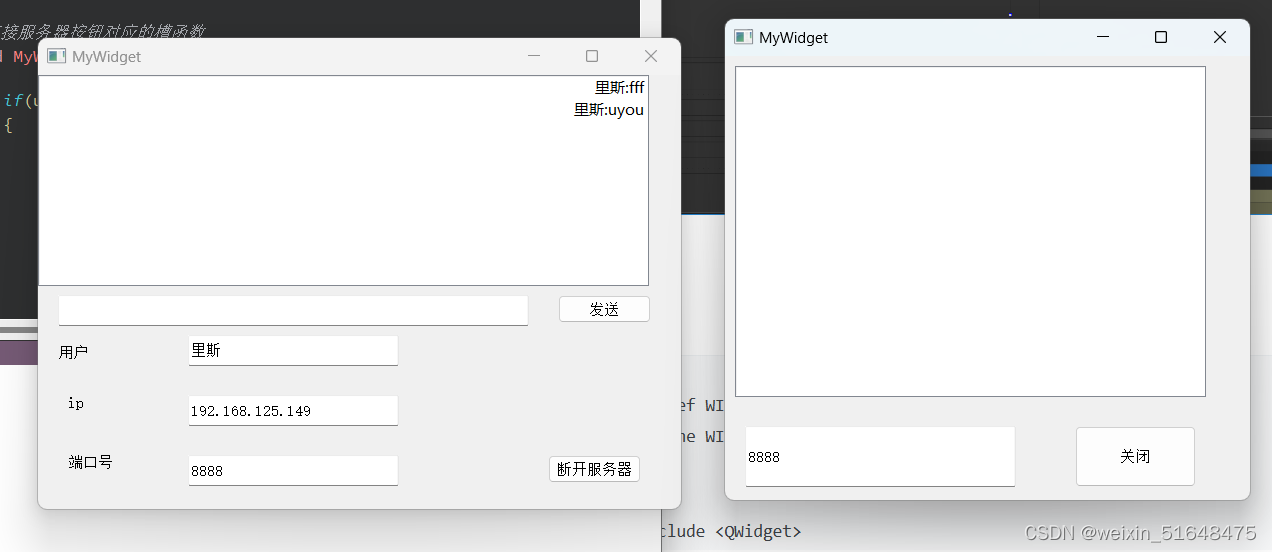
QT---day5,通信
1、思维导图 2、TCp 服务器 #ifndef MYWIDGET_H #define MYWIDGET_H #include <QWidget> #include <QTcpServer> #include <QList> #include <QTcpSocket> #include <QMessageBox> #include <QDebug> #include <QTcpServer> QT_B…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...