【Python】特征编码
特征编码
- 1. 独热编码(离散变量编码) sklearn.preprocessing.OneHotEncoder
- 1.1 原理 & 过程
- 1.2 封装函数
- 2. 连续变量分箱(连续变量编码) sklearn.preprocessing.KBinsDiscretizer
- 2.1 原理
- 2.2 等宽分箱 KBinsDiscretizer(strategy='uniform')
- 2.3 等频分箱 KBinsDiscretizer(strategy='quantile')
- 2.4 聚类分箱 KBinsDiscretizer(strategy='kmeans')
1. 独热编码(离散变量编码) sklearn.preprocessing.OneHotEncoder
- 【sklearn】数据预处理 独热编码
1.1 原理 & 过程
- 原理
'''
二分类离散变量,转换后知到一列取值已知则另一列取值也确定
OneHotEncoder(drop='if_binary') 跳过二分类,只对多分类离散变量进行转化
ID Gender ID Gender_F Gender_M
1 F 1 1 0
2 M >>> 2 0 1
3 M 3 0 1
4 F 4 1 0
ID Gender Income ID Gender Income_High Income_medium Income_Low
1 F High 1 0 1 0 0
2 M Medium >>> 2 1 0 1 0
3 M High 3 1 1 0 0
4 F Low 4 0 0 0 1
'''
- 数据
X = pd.DataFrame({'Gender': ['F', 'M', 'M', 'F'],'Income': ['High', 'Medium', 'High', 'Low']})
X
| Gender | Income | |
|---|---|---|
| 0 | F | High |
| 1 | M | Medium |
| 2 | M | High |
| 3 | F | Low |
- 代码
from sklearn.preprocessing import OneHotEncoderenc = OneHotEncoder(drop='if_binary')
enc.fit_transform(X).toarray()
'''array([[0., 1., 0., 0.],[1., 0., 0., 1.],[1., 1., 0., 0.],[0., 0., 1., 0.]])
'''
# 转换规则
'''
二分类 F >>> 0,M >>> 1
多分类 第一列High,第二列Low,第三列Medium
'''
enc.categories_
'''[array(['F', 'M'], dtype=object),array(['High', 'Low', 'Medium'], dtype=object)]
'''
# 编码后命名列 原列名_字段取值
# 原始列名
cate_cols = X.columns.tolist()
cate_cols
'''['Gender', 'Income']
'''
# 新编码字段名称存储
cate_cols_new = []
# 提取独热编码后所有特征的名称
for idx, colname in enumerate(cate_cols):# 二分类离散变量if len(enc.categories_[idx]) == 2:cate_cols_new.append(colname)# 多分类离散变量else:for f in enc.categories_[idx]:feature_name = colname + '_' + fcate_cols_new.append(feature_name)
cate_cols_new
'''['Gender', 'Income_High', 'Income_Low', 'Income_Medium']
'''
# 组合成新DataFrame
pd.DataFrame(enc.fit_transform(X).toarray(),columns=cate_cols_new)
| Gender | Income_High | Income_Low | Income_Medium | |
|---|---|---|---|---|
| 0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 1 | 1.0 | 0.0 | 0.0 | 1.0 |
| 2 | 1.0 | 1.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 1.0 | 0.0 |
1.2 封装函数
def cate_colName(Transformer, category_cols, drop='if_binary'):"""离散字段独热编码后字段名创建函数:param Transformer: 独热编码转化器:param category_cols: 原始列名:param drop: 独热编码转化器的drop参数"""# 新编码字段名称存储cate_cols_new = []col_value = Transformer.categories_# 提取独热编码后所有特征的名称for idx, colname in enumerate(cate_cols):# 二分类离散变量if (len(col_value[idx]) == 2) & (drop == 'if_binary'):cate_cols_new.append(colname)# 多分类离散变量else:for f in col_value[idx]:feature_name = colname + '_' + fcate_cols_new.append(feature_name)return (cate_cols_new)
cate_colName(enc, cate_cols)
'''['Gender', 'Income_High', 'Income_Low', 'Income_Medium']
'''
2. 连续变量分箱(连续变量编码) sklearn.preprocessing.KBinsDiscretizer
2.1 原理
'''
字段 连续型 >>> 离散型
减少异常值影响,消除特征量纲影响
对于线性模型来说引入非线性因素,提升模型表现
对于树模型来说损失连续变量信息,影响模型效果[0,30)->0 [30,60)->1 [60,inf)->2
ID Income ID Income_Level
1 0 1 0
2 10 2 0
3 180 >>> 3 2
4 30 4 1
5 55 5 1
'''
'''
等宽分箱 uniforme 一定程度受异常值影响
等频分箱 quantile 完全忽略异常值影响
聚类分箱 kmeans 兼顾变量原始数值分布,优先考虑
'''
2.2 等宽分箱 KBinsDiscretizer(strategy=‘uniform’)
# 等宽分箱
# 根据连续变量的取值范围,划分宽度相等的区间
income = np.array([0, 10, 180, 30, 55, 35, 25, 75, 80, 10]).reshape(-1, 1)
income
'''array([[ 0],[ 10],[180],[ 30],[ 55],[ 35],[ 25],[ 75],[ 80],[ 10]])
'''
from sklearn.preprocessing import KBinsDiscretizer
'''
KBinsDiscretizer转化器 (discrete离散的)n_bins 分箱个数strategy 分箱方式'uniforme' 等宽分箱'quantile' 等频分箱'kmeans' 聚类分箱encode 分箱后的离散字段进一步编码方式'ordinal' 二分类-自然数编码'onehot' 多分类-独热编码
'''dis = KBinsDiscretizer(n_bins=3, strategy='uniform', encode='ordinal')
dis.fit_transform(income)
'''array([[0.],[0.],[2.],[0.],[0.],[0.],[0.],[1.],[1.],[0.]])
'''
# 查看分箱边界
dis.bin_edges_
'''array([array([ 0., 60., 120., 180.])], dtype=object)
'''
2.3 等频分箱 KBinsDiscretizer(strategy=‘quantile’)
'''
根据分箱数和连续变量数,划分样本数量相等的区间
若样本数无法整除箱数,最后一个箱子包含余数样本(10/3 -> 3/3/4).
'''
np.sort(income.flatten(), axis=0) # 分两个箱的话会以32.5划分
'''array([ 0, 10, 10, 25, 30, 35, 55, 75, 80, 180])
'''
dis = KBinsDiscretizer(n_bins=3, strategy='quantile', encode='ordinal')
dis.fit_transform(income)
'''array([[0.],[0.],[2.],[1.],[1.],[1.],[0.],[2.],[2.],[0.]])
'''
# 查看分箱边界
dis.bin_edges_
'''array([array([ 0., 25., 55., 180.])], dtype=object)
'''
2.4 聚类分箱 KBinsDiscretizer(strategy=‘kmeans’)
# 对连续变量进行聚类(多KMeans聚类),按样本所属类别作为标记代替原始值
from sklearn import clusterkmeans = cluster.KMeans(n_clusters=3)
kmeans.fit(income)
kmeans.labels_
'''array([0, 0, 1, 0, 2, 0, 0, 2, 2, 0], dtype=int32)
'''
dis = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='kmeans')
dis.fit_transform(income) # 分类结果和上面相同但更合理,小数字更能体现收入水平低
'''array([[0.],[0.],[2.],[0.],[1.],[0.],[0.],[1.],[1.],[0.]])
'''
dis.bin_edges_
'''array([array([ 0. , 44.16666667, 125. , 180. ])],dtype=object)
'''
相关文章:

【Python】特征编码
特征编码1. 独热编码(离散变量编码) sklearn.preprocessing.OneHotEncoder1.1 原理 & 过程1.2 封装函数2. 连续变量分箱(连续变量编码) sklearn.preprocessing.KBinsDiscretizer2.1 原理2.2 等宽分箱 KBinsDiscretizer(strategyuniform)2.3 等频分箱 KBinsDiscretizer(stra…...
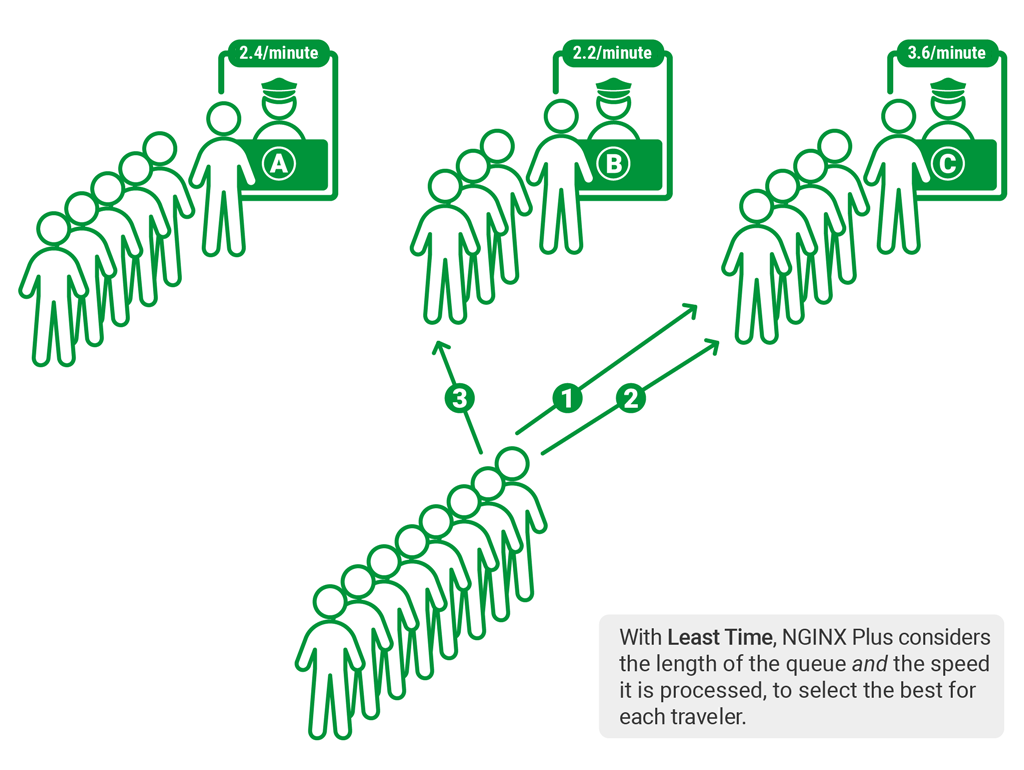
前端开发者必备的Nginx知识
nginx在应用程序中的作用 解决跨域请求过滤配置gzip负载均衡静态资源服务器…nginx是一个高性能的HTTP和反向代理服务器,也是一个通用的TCP/UDP代理服务器,最初由俄罗斯人Igor Sysoev编写。 nginx现在几乎是众多大型网站的必用技术,大多数情…...
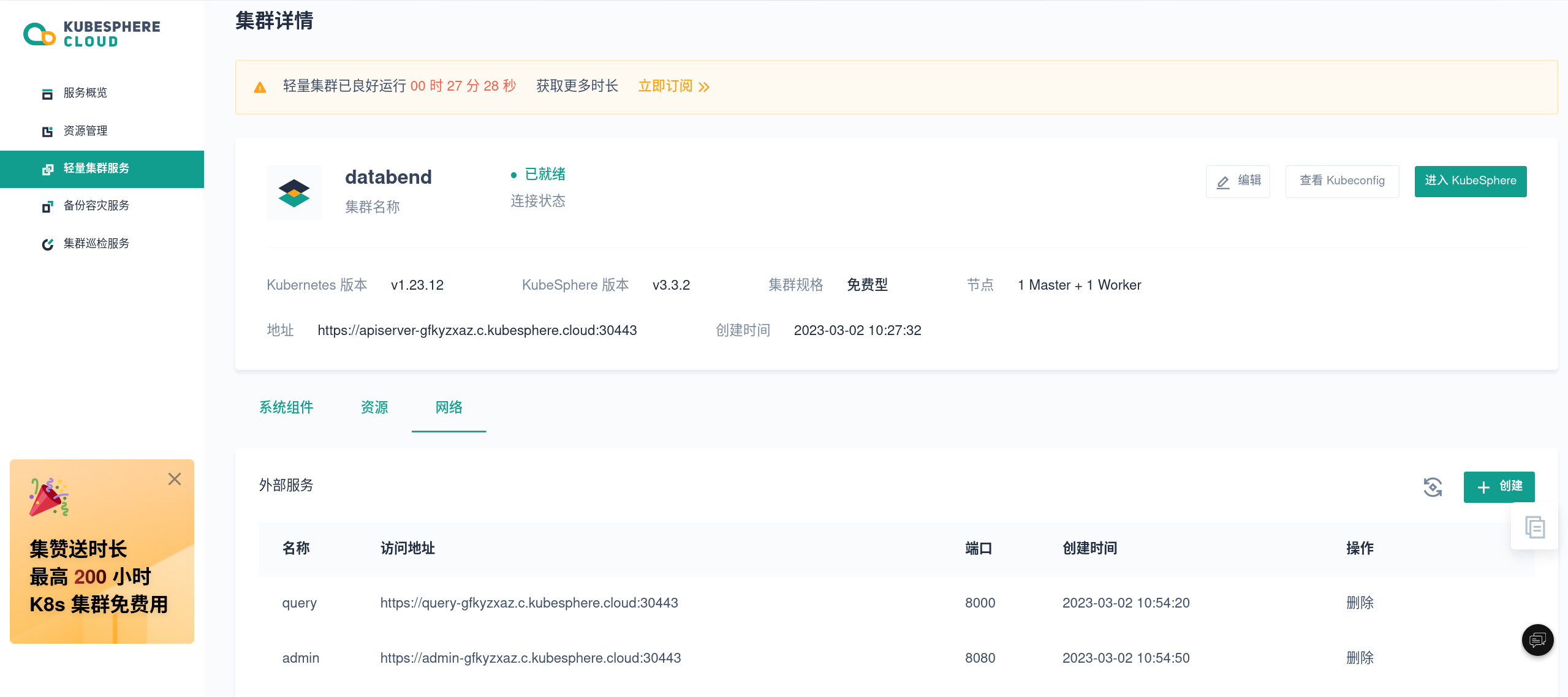
在 KubeSphere 中开启新一代云原生数仓 Databend
作者:尚卓燃(https://github.com/PsiACE),Databend 研发工程师,Apache OpenDAL (Incubating) PPMC。 前言 Databend 是一款完全面向云对象存储的新一代云原生数据仓库,专为弹性和高效设计,为您…...
【独家】)
华为OD机试 - 最优资源分配(C 语言解题)【独家】
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 使用说明本期题目:最优资源…...

求数组的中心索引
给你一个整数数组 nums ,请计算数组的 中心下标 。 数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。 如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点…...
Ubuntu 搭建NextCloud私有云盘【内网穿透远程访问】
文章目录1.前言2.本地软件安装2.1 nextcloud安装2.2 cpolar安装3.本地网页发布3.1 Cpolar云端设置3.2 Cpolar本地设置4.公网访问测试5. 结语1.前言 对于爱好折腾的电脑爱好者来说,Linux是绕不开的、必须认识的系统(大部分服务器都是采用Linux操作系统&a…...
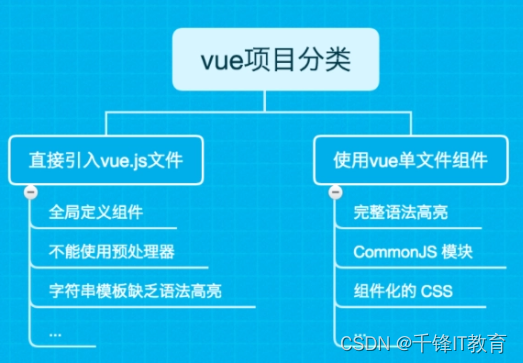
如何使用vue创建一个完整的前端项目
搭建Vue项目的完整流程可以分为以下几个步骤:安装Node.js和npm:Vue.js是基于Node.js开发的,因此在开始搭建Vue项目之前,需要先安装Node.js和npm(Node.js的包管理器)。可以从官网下载Node.js安装包并安装。安…...
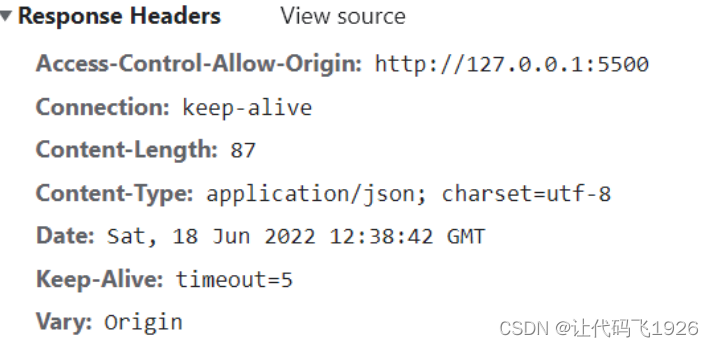
http组成及状态及参数传递
http组成及状态及参数传递 早期的网页都是通过后端渲染来完成的:服务器端渲染(SSR,server side render): 客户端发出请求 -> 服务端接收请求并返回相应HTML文档 -> 页面刷新,客户端加载新的HTML文档&…...

USART_GetITStatus与 USART_GetFlagStatus的区别
文章目录共同点不同点USART_GetITStatus函数详解USART_GetFlagStatus函数共同点 都能访问串口的SR寄存器 不同点 USART_GetFlagStatus(USART_TypeDef USARTx, uint16_t USART_FLAG):* 该函数只判断标志位(访问串口的SR寄存器)。在没有使能…...
Java 系列之 Springboot
系列文章目录 文章目录系列文章目录前言一、Springboot 简介?1.1 什么是启动器?1.2 Springboot 优点1.3 Springboot 核心二、搭建方式2.1 搭建方式一2.2 搭建方式二2.3 搭建方式三三、启动原理3.1 初始化SrpingApplication对象3.2 执行run()方法1. 加载监…...

乐山持点科技:抖客推广准入及准出管理规则
抖音小店平台新增《抖客推广准入及准出管理规则》,本次抖音规则具体如下:第一章 概述1.1 目的及依据为维护精选联盟平台经营秩序,保障精选联盟抖客、商家、消费者等各方的合法权益;根据《巨量百应平台服务协议》、《“精选联盟”服务协议(推广…...

Steam流
Steam流 Stream 流是什么,为什么要用它? Stream是 Java8 新引入的一个包( java.util.stream),它让我们能用声明式的方式处理数据(集合、数组等)。Stream流式处理相较于传统方法简洁高效&#…...
Nuxt实战教程基础-Day01
Nuxt实战教程基础-Day01Nuxt是什么?Nuxt.js框架是如何运作的?Nuxt特性流程图服务端渲染(通过 SSR)单页应用程序 (SPA)静态化 (预渲染)Nuxt优缺点优点缺点安装运行项目总结前言:本教程基于Nuxt2,作为教程的第一天,我们先…...
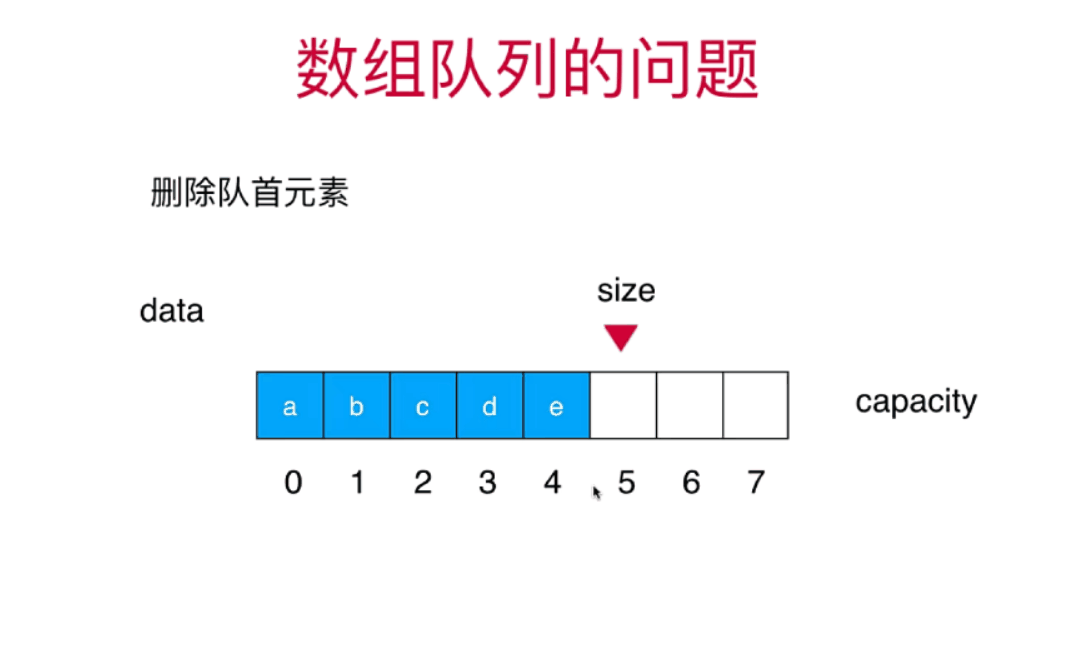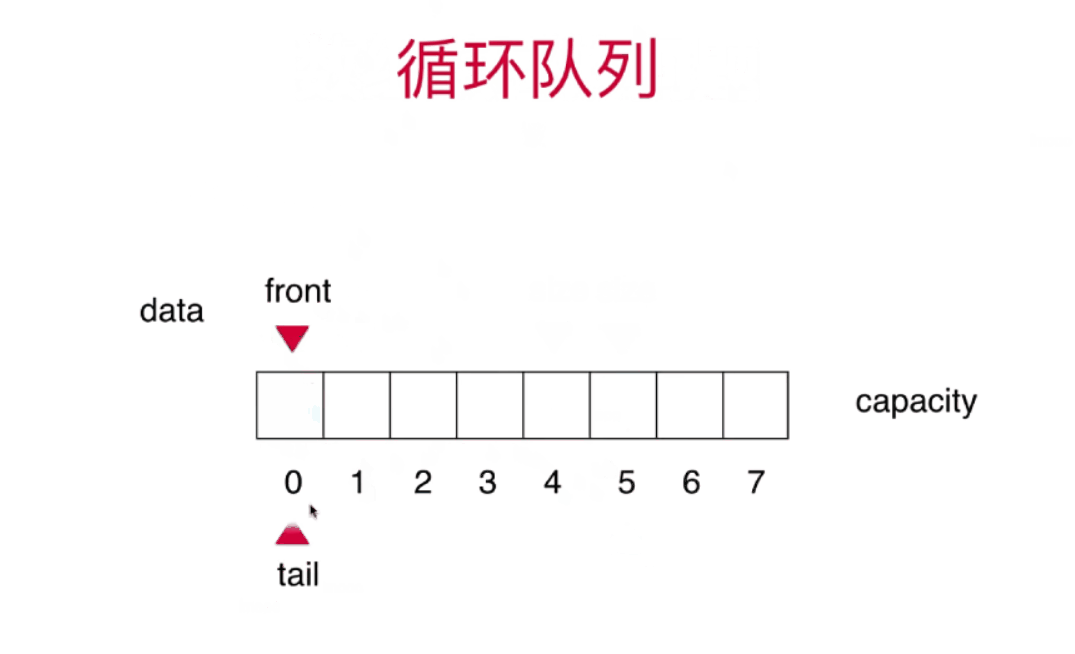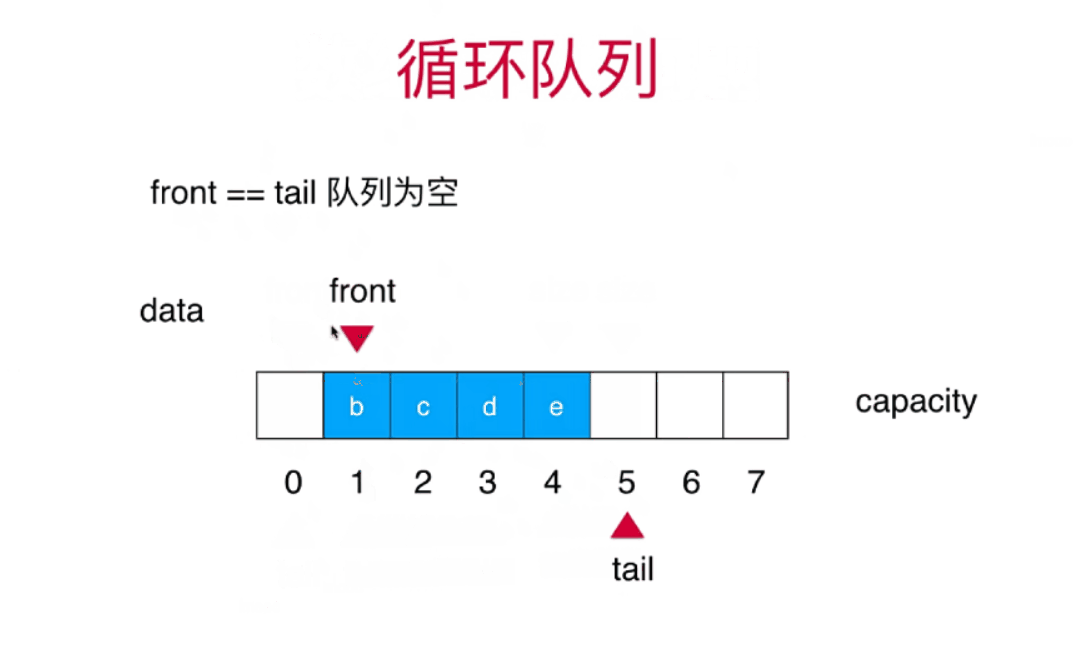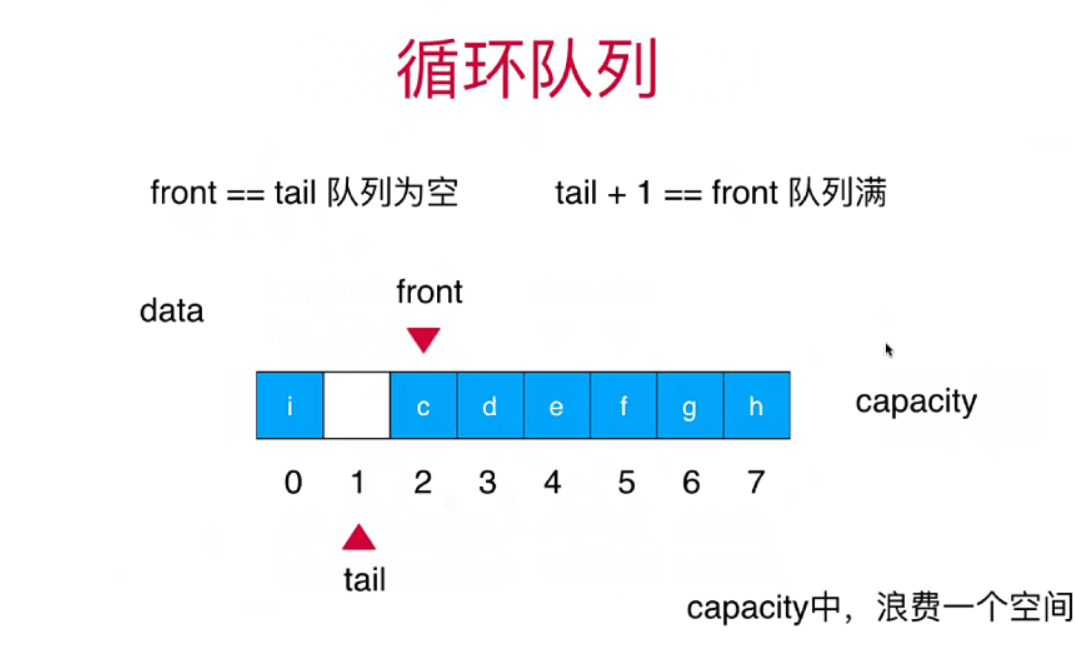
栈和队列详细讲解+算法动画
栈和队列 栈stack 栈也是一种线性结构相比数组,栈对应的操作数数组的子集只能从一端添加元素,也只能从一端取出元素这一端称为栈顶 栈是一种后进先出的数据结构Last in Firt out(LIFO)在计算机的世界里,栈拥有者不可思议的作用 栈的应用 …...
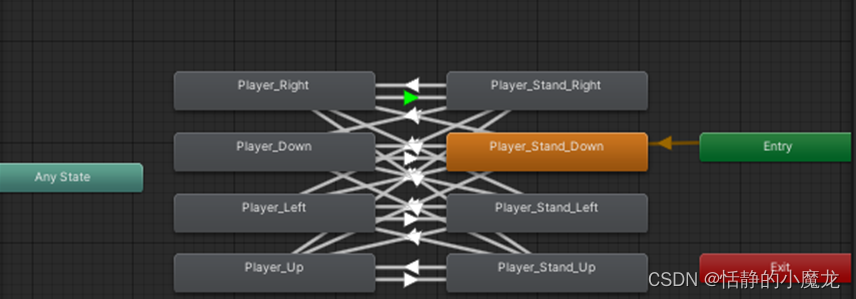
【Unity3D小技巧】Unity3D中判断Animation以及Animator动画播放结束,以及动画播放结束之后执行函数
推荐阅读 CSDN主页GitHub开源地址Unity3D插件分享简书地址我的个人博客 大家好,我是佛系工程师☆恬静的小魔龙☆,不定时更新Unity开发技巧,觉得有用记得一键三连哦。 一、前言 在日常开发中,可能会遇到要判断Animation或者Anima…...

【1】熟悉刷题平台操作
TestBench使用 与quartus中testbench的写法有些许。或者说这是平台特有的特性!! 1 平台使用谨记 (1)必须删除:若设计为组合逻辑,需将自动生成的clk删除 若不删除,会提示运行超时错误。 &#…...
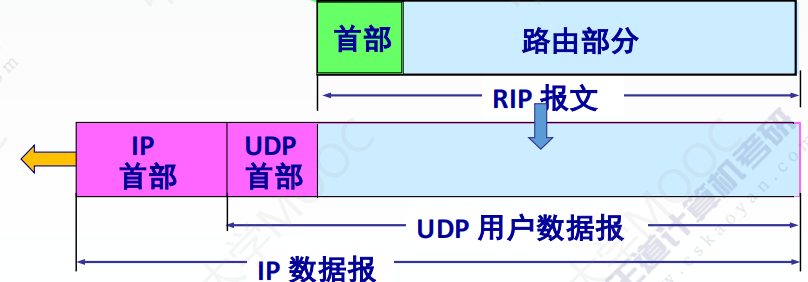
计算机网络:RIP协议以及距离向量算法
RIP协议 RIP是一种分布式的基于适量向量的路由选择协议,最大优点是简单。要求网络中的每一个路由器都要维护从它自己到其他每一个目的网络的唯一最佳(最短)距离记录,最多包含15个路由器,距离为16就表示网络不可达&…...
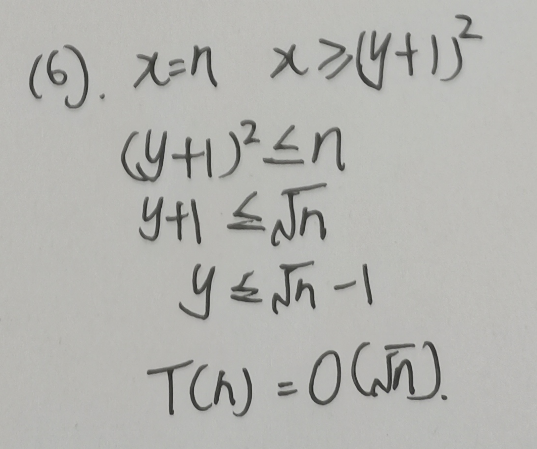
[数据结构与算法(严蔚敏 C语言第二版)]第1章 绪论(课后习题+答案解析)
1. 简述下列概念:数据、数据元素、数据项、数据对象、数据结构、逻辑结构、存储结构、抽象数据类型。 数据 数据是客观事物的符号表示,是所有能输人到计算机中并被计算机程序处理的符号的总称。数据是信息的载体,能够被计算机识别、存储和加工 数据元素…...

JS_countup.js 的简单使用,数字滚动效果
countup.js countup.js 是一个轻量级,无依赖的JavaScript类,通过简单的设置就可以达到数字滚动的效果 官网:https://inorganik.github.io/countUp.js/ 源码 var CountUpfunction(target,startVal,endVal,decimals,duration,options){var …...

【C++知识点】STL 容器总结
✍个人博客:https://blog.csdn.net/Newin2020?spm1011.2415.3001.5343 📚专栏地址:C/C知识点 📣专栏定位:整理一下 C 相关的知识点,供大家学习参考~ ❤️如果有收获的话,欢迎点赞👍…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

MySQL 部分重点知识篇
一、数据库对象 1. 主键 定义 :主键是用于唯一标识表中每一行记录的字段或字段组合。它具有唯一性和非空性特点。 作用 :确保数据的完整性,便于数据的查询和管理。 示例 :在学生信息表中,学号可以作为主键ÿ…...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...
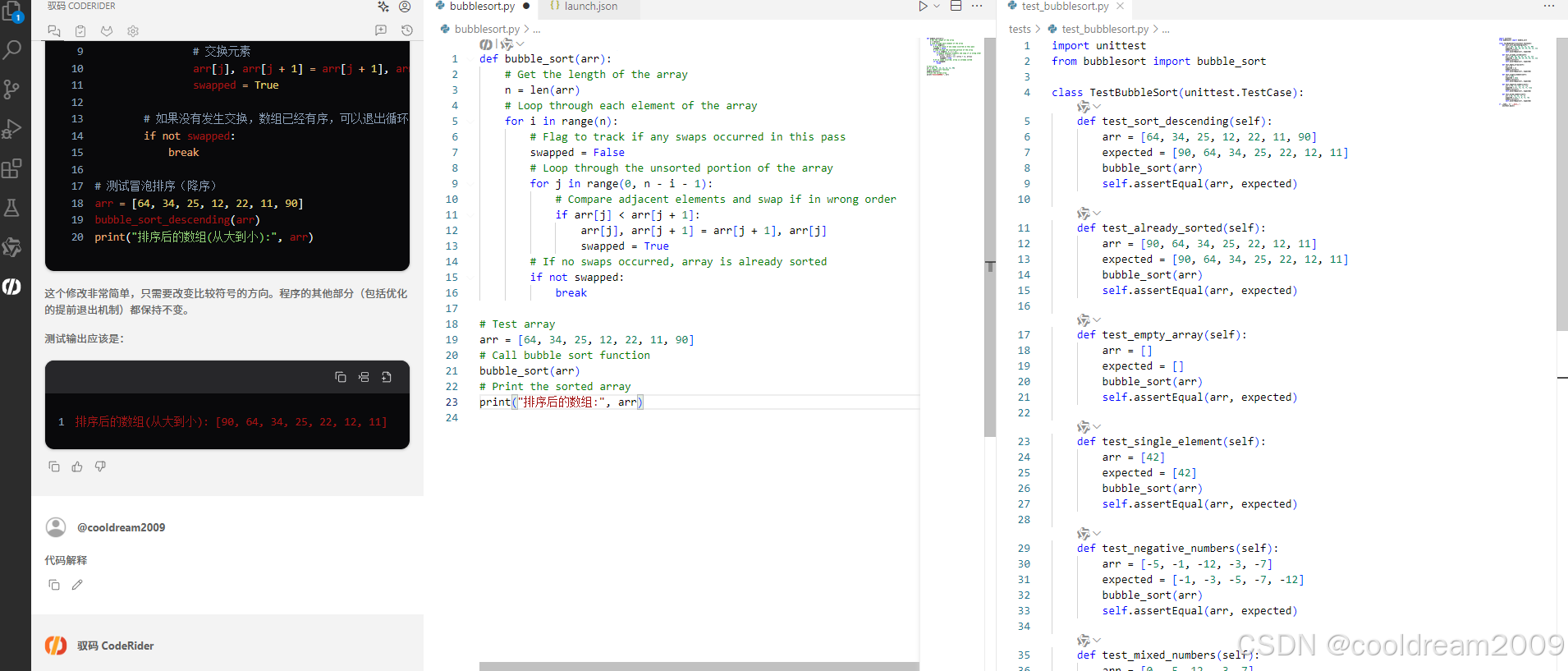
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...

[USACO23FEB] Bakery S
题目描述 Bessie 开了一家面包店! 在她的面包店里,Bessie 有一个烤箱,可以在 t C t_C tC 的时间内生产一块饼干或在 t M t_M tM 单位时间内生产一块松糕。 ( 1 ≤ t C , t M ≤ 10 9 ) (1 \le t_C,t_M \le 10^9) (1≤tC,tM≤109)。由于空间…...