Fluent Python 笔记 第 2 章 序列构成的数组
2.1 内置类型序列概览
容器序列(能存放不同类型的数据):(作者分的类)
list、tuple 和 collections.deque
扁平序列(只能容纳一种类型):
str、byes、bytearray、memoryview 和 array.array
可变:
list、bytearray、array.array、collections.deque 和 memoryview
不可变:
tuple、str 和 bytes
2.2 列表推导和生成器表达式
很多 Python 程序员都把列表推导(list comprehension)简称为 listcomps,生成器表达式(generator expression)则称为 genexps。
Python 会忽略代码里 []、{} 和 () 中的换行
2.2.1 列表推导和可读性
l2 = [fc(itm) for itm in l1]
2.2.2 列表推导同 filter 和 map 的比较
beyond_ascii = [ord(s) for s in symbols if ord(s) > 127]
beyond_ascii = list(filter(lambda c: c > 127, map(ord, symbols)))
2.2.3 笛卡儿积
tshirts = [(color, size) for color in colors for size in sizes]
2.2.4 生成器表达式
生成器表达式的语法跟列表推导差不多,只不过把方括号换成圆括号而已。
tuple(ord(symbol) for symbol in symbols)
生成器表达式之后, 内存里不会留下一个组合的列表,因为生成器表达式会在每次 for 循环运行时才生成一个组合。
2.3 元组不仅仅是不可变的列表
2.3.1 元组和记录
2.3.2 元组拆包
lax_coordinates = (33.9425, -118.408056)
latitude, longitude = lax_coordinates # 元组拆包
b, a = a, b
用 * 来处理剩下的元素
>>> a, b, *rest = range(5)
>>> a, b, rest
(0, 1, [2, 3, 4])
>>> a, b, *rest = range(3)
>>> a, b, rest
(0, 1, [2])
>>> a, b, *rest = range(2)
>>> a, b, rest
(0, 1, [])>>> a, *body, c, d = range(5)
>>> a, body, c, d
(0, [1, 2], 3, 4)
>>> *head, b, c, d = range(5)
>>> head, b, c, d
([0, 1], 2, 3, 4)
2.3.3 嵌套元组拆包
name, cc, pop, (latitude, longitude) = ('Tokyo','JP',36.933,(35.689722,139.691667))
2.3.4 具名元组
collections.namedtuple 是一个工厂函数。用 namedtuple 构建的类的实例所消耗的内存跟元组是一样的,因为字段名都 被存在对应的类里面。这个实例跟普通的对象实例比起来也要小一些,因为 Python 不会用 __dict__ 来存放这些实例的属性。
创建一个具名元组需要两个参数,一个是类名,另一个是类的各个字段的名字。后者可 以是由数个字符串组成的可迭代对象,或者是由空格分隔开的字段名组成的字符串
from collections import namedtupleCity = namedtuple('City', 'name country population coordinates')
tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 139.691667))
元组有一些自己专有的属性。展示了几个最有用的:_fields 类属性、类方法 _make(iterable) 和实例方法 _asdict()。
>>> City._fields
('name', 'country', 'population', 'coordinates')
>>> LatLong = namedtuple('LatLong', 'lat long')
>>> delhi_data = ('Delhi NCR', 'IN', 21.935, LatLong(28.613889, 77.208889)) >>> delhi = City._make(delhi_data)
>>> delhi._asdict()
OrderedDict([('name', 'Delhi NCR'), ('country', 'IN'), ('population', 21.935), ('coordinates', LatLong(lat=28.613889, long=77.208889))])
2.3.5 作为不可变列表的元组
除了跟增减元素相关的方法之外,元组支持列表的其他所有方法。还有一个例 外,元组没有 __reversed__ 方法,但是这个方法只是个优化而已,reversed(my_tuple) 这 个用法在没有 __reversed__ 的情况下也是合法的。
2.4 切片
2.4.1 为什么切片和区间会忽略最后一个元素
在切片和区间操作里不包含区间范围的最后一个元素是 Python 的风格,这个习惯符合
Python、C 和其他语言里以 0 作为起始下标的传统。
2.4.2 对对象进行切片
>>> s = 'bicycle'
>>> s[::3]
'bye'
>>> s[::-1]
'elcycib'
>>> s[::-2]
'eccb'
可以给切片起名字增强可读性!:
SKU = slice(0, 6)
print(item[SKU]
2.4.3 多维切片和省略
省略(ellipsis)。ellipsis 是类名,全小写,而它的内置实例写作 Ellipsis。这其实跟 bool 是小写,但是它的两个实例写作 True 和 False 异曲同工。
2.4.4 给切片赋值
对原序列就地修改!如果赋值的对象是一个切片,那么赋值语句的右侧必须是个可迭代对象。即便只有单独 一个值,也要把它转换成可迭代的序列。
2.5 对序列使用 + 和 *
>>> l = [1, 2, 3]
>>> l * 5
[1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]
>>> 5 * 'abcd'
'abcdabcdabcdabcdabcd'
+ 和 * 都遵循这个规律,不修改原有的操作对象,而是构建一个全新的序列。
如果在a * n这个语句中,序列a里的元素是对其他可变对象的引用的话, 你就需要格外注意了,因为这个式子的结果可能会出乎意料。比如,你想用 my_list = [[]] * 3来初始化一个由列表组成的列表,但是你得到的列表里 包含的 3 个元素其实是 3 个引用,而且这 3 个引用指向的都是同一个列表。 这可能不是你想要的效果。
正确方式:
board = [['_'] * 3 for i in range(3)]
2.6 序列的增量赋值
+= 背后的特殊方法是 __iadd__(用于“就地加法”)。但是如果一个类没有实现这个方法的
话,Python 会退一步调用 __add__。
如果 a 实现了 iadd 方法,就会调用这个方法。同时对可变序列(例如 list、 bytearray 和 array.array)来说,a 会就地改动,就像调用了 a.extend(b) 一样。但是如 果 a 没有实现 iadd 的话,a += b 这个表达式的效果就变得跟 a = a + b 一样了:首先 计算 a + b,得到一个新的对象,然后赋值给 a。也就是说,在这个表达式中,变量名会不 会被关联到新的对象,完全取决于这个类型有没有实现 iadd 这个方法。而不可变序列根 本就不支持这个操作,对这个方法的实现也就无从谈起。
>>> l = [1, 2, 3]
>>> id(l) 4311953800
>>> l *= 2
>>> l
[1, 2, 3, 1, 2, 3]
>>> id(l)
4311953800
>>> t = (1, 2, 3)
>>> id(t)
4312681568
>>> t *= 2
>>> id(t)
4301348296
一个关于+=的谜题
>>> t = (1, 2, [30, 40])
>>> t[2] += [50, 60]
到底会发生下面 4 种情况中的哪一种?
- a. t 变成 (1, 2, [30, 40, 50, 60])。
- b. 因为 tuple 不支持对它的元素赋值,所以会抛出 TypeError 异常。
- c. 以上两个都不是。
- d. a 和 b 都是对的。
答案是 d
>>> t = (1, 2, [30, 40])
>>> t[2] += [50, 60]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> t
(1, 2, [30, 40, 50, 60])
- 将 s[a] 的值存入 TOS(Top Of Stack,栈的顶端)。
- 计算 TOS += b。这一步能够完成,是因为 TOS 指向的是一个可变对象。
- s[a] = TOS 赋值。这一步失败,是因为 s 是不可变的元组。
2.7 list.sort方法和内置函数sorted
list.sort 方法会就地排序列表,返回 None。sorted,它会新建一个列表作为返回值。
两个可选的关键字参数。
reverse:
如果被设定为 True,被排序的序列里的元素会以降序输出(也就是说把最大值当作最 小值来排序)。这个参数的默认值是 False。
key:
一个只有一个参数的函数,这个函数会被用在序列里的每一个元素上,所产生的结果 将是排序算法依赖的对比关键字。
可选参数 key 还可以在内置函数 min() 和 max() 中起作用。另外,还有些标准库里的函数也接受这个参数,像 itertools.groupby() 和 heapq.nlargest() 等。
2.8 用bisect来管理已排序的序列
import bisect
2.8.1 用bisect来搜索
bisect 函数其实是 bisect_right 函数的别名,后者还有个姊妹函数叫 bisect_left。 它们的区别在于,bisect_left 返回的插入位置是原序列中跟被插入元素相等的元素的位置, 也就是新元素会被放置于它相等的元素的前面,而 bisect_right 返回的则是跟它相等的元素之后的位置。
两个可选参数 lo 和 hi 来缩小搜寻的范围。lo 的默认值是 0,hi 的默认值是序列的长度,即 len() 作用于该序列的返回值。
2.8.2 用bisect.insort插入新元素
bisect.insort(my_list, new_item)
insort 跟 bisect 一样,有 lo 和 hi 两个可选参数用来控制查找的范围。也有个变体叫 insort_left。
2.9 当列表不是首选时
2.9.1 数组
速度非常快
from array import arrayfloats = array('d', (random() for i in range(10**7)))
fp = open('floats.bin', 'wb')
floats.tofile(fp)
fp.close()floats2 = array('d')
fp = open('floats.bin', 'rb')
floats2.fromfile(fp, 10**7)
fp.close()
从 Python 3.4 开始,数组(array)类型不再支持诸如 list.sort() 这种就地排序方法。要给数组排序的话,得用 sorted 函数新建一个数组: a = array.array(a.typecode, sorted(a)) 想要在不打乱次序的情况下为数组添加新的元素,bisect.insort 还是能派上用场。
2.9.2 内存视图
低级视角
numbers = array.array('h', [-2, -1, 0, 1, 2]) >>> memv = memoryview(numbers)
len(memv)
# 5
>>> memv[0]
# -2
memv_oct = memv.cast('B')
memv_oct.tolist()
# [254, 255, 255, 255, 0, 0, 1, 0, 2, 0] >>> memv_oct[5] = 4
numbers
# array('h', [-2, -1, 1024, 1, 2])
2.9.3 NumPy 和 SciPy
2.9.4 双向队列和其他形式的队列
collections.deque 类(双向队列)是一个线程安全、可以快速从两端添加或者删除元素的数据类型。
dq = deque(range(10), maxlen=10)
maxlen 无法修改。
extendleft(iter) 方法会把迭代器里的元素逐个添加到双向队列的左边,因此迭代器里的元素会逆序出现在队列里。
>>> from collections import deque
>>> dq = deque(range(10), maxlen=10)
>>> dq
deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
>>> dq.rotate(3)
>>> dq
deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)
>>> dq.rotate(-4)
>>> dq
deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0], maxlen=10)
>>> dq.appendleft(-1)
>>> dq
deque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10) >>> dq.extend([11, 22, 33])
>>> dq
deque([3, 4, 5, 6, 7, 8, 9, 11, 22, 33], maxlen=10) >>> dq.extendleft([10, 20, 30, 40])
>>> dq
deque([40, 30, 20, 10, 3, 4, 5, 6, 7, 8], maxlen=10)
append 和 popleft 都是原子操作,也就说是 deque 可以在多线程程序中安全地当作先进先 出的队列使用,而使用者不需要担心资源锁的问题。
queue
提供了同步(线程安全)类 Queue、LifoQueue 和 PriorityQueue,不同的线程可以利用 这些数据类型来交换信息。这三个类的构造方法都有一个可选参数 maxsize,它接收正 整数作为输入值,用来限定队列的大小。但是在满员的时候,这些类不会扔掉旧的元素 来腾出位置。相反,如果队列满了,它就会被锁住,直到另外的线程移除了某个元素而 腾出了位置。这一特性让这些类很适合用来控制活跃线程的数量。
multiprocessing
这个包实现了自己的 Queue,它跟 queue.Queue 类似,是设计给进程间通信用的。同时还有一个专门的 multiprocessing.JoinableQueue 类型,可以让任务管理变得更方便。
asyncio
Python 3.4 新 提 供 的 包, 里 面 有 Queue、LifoQueue、PriorityQueue 和 JoinableQueue, 这些类受到 queue 和 multiprocessing 模块的影响,但是为异步编程里的任务管理提供 了专门的便利。
heapq
跟上面三个模块不同的是,heapq 没有队列类,而是提供了 heappush 和 heappop 方法,让用户可以把可变序列当作堆队列或者优先队列来使用。
相关文章:

Fluent Python 笔记 第 2 章 序列构成的数组
2.1 内置类型序列概览 容器序列(能存放不同类型的数据):(作者分的类) list、tuple 和 collections.deque扁平序列(只能容纳一种类型): str、byes、bytearray、memoryview 和 array.array可变:…...

句子扩充法
人,物,时,地,事 什么人和什么物在什么时间什么地点发生了什么事。 思维导图:以人为中心,人具有客观能动性。 例如:秋燕南飞。 扩展为: 盘旋在洞庭湖上方的大雁渐渐消失了。“它们都…...

Java并发编程概述
在学习并发编程之前,我们需要稍微回顾以下线程相关知识:线程基本概念程序:静态的代码,存储在硬盘中进程:运行中的程序,被加载在内存中,是操作系统分配内存的基本单位线程:是cpu执行的…...
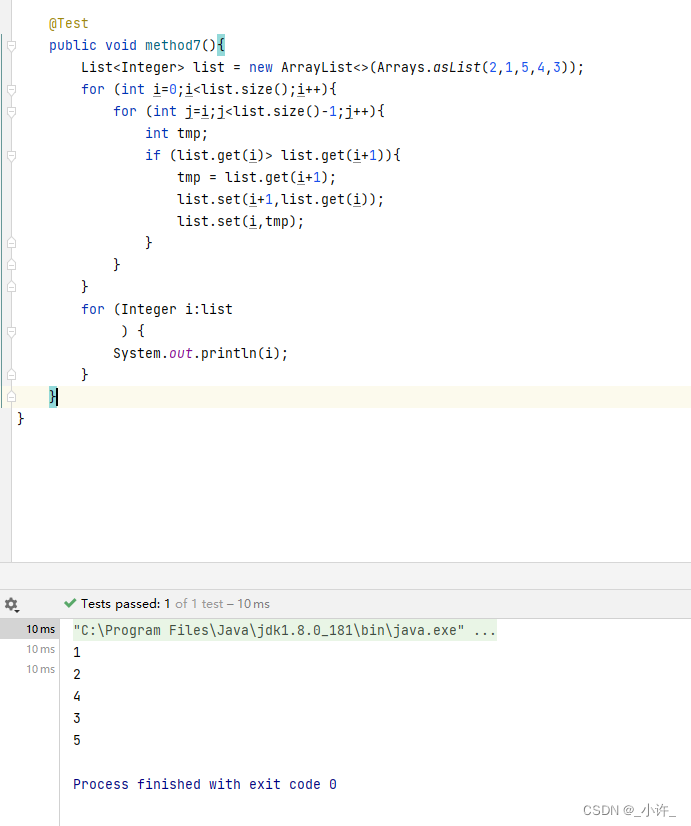
Java常见数据结构的排序与遍历(包括数组,List,Map)
数组遍历与排序 数组定义 //定义 int a[] new int[5]int[] a new int[5];//带初始值定义 int b[] {1,2,3,4,5};赋值 //定义时赋值 int b[] {1,2,3,4,5};//引用赋值 a[6] 1 a[9] 9 //未赋值为空取值 //通过下表取值,从0开始 b[1] 1 b[2] 2遍历 Test p…...
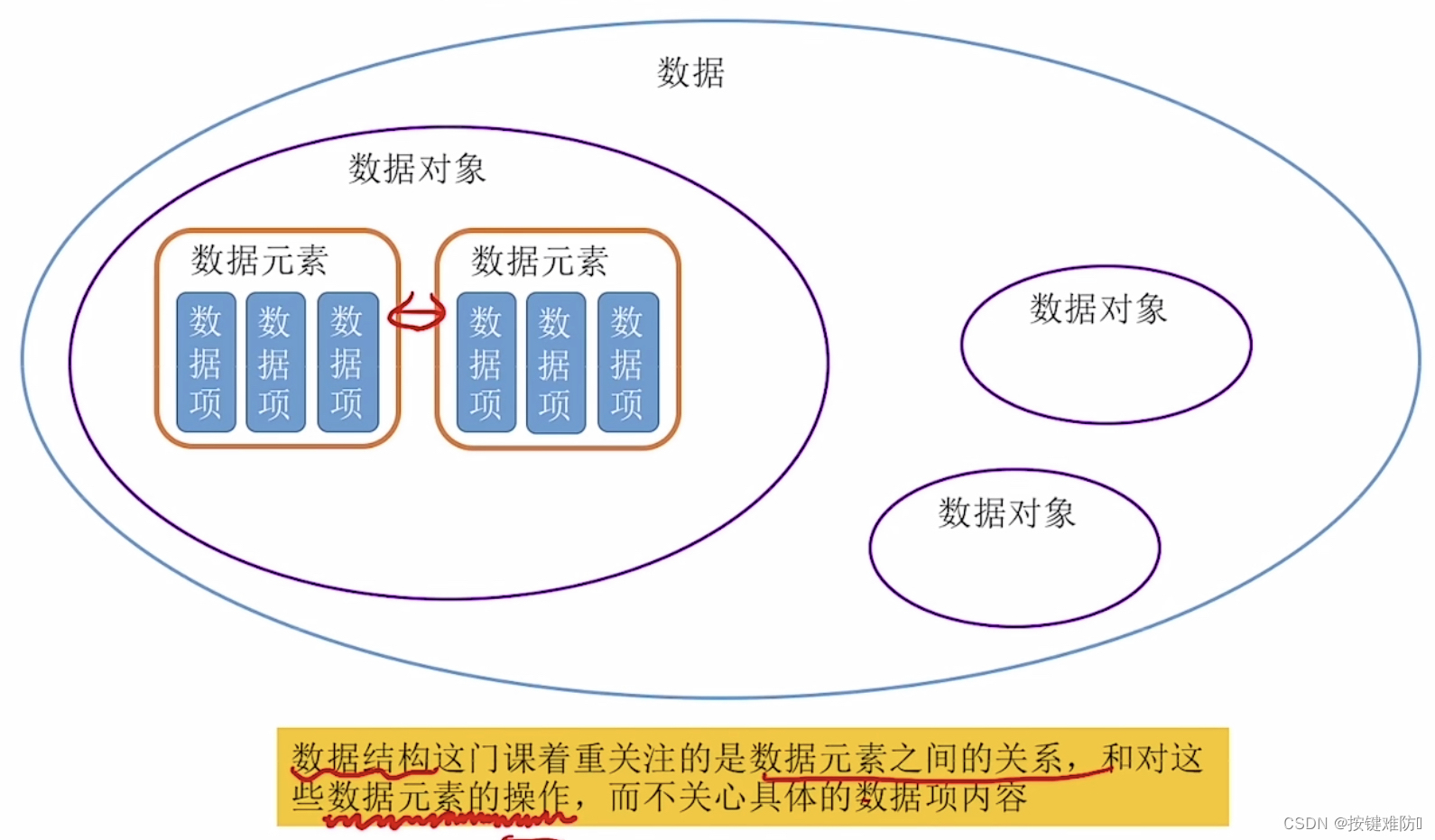
数据结构|绪论
🔥Go for it!🔥 📝个人主页:按键难防 📫 如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀 📖系列专栏:数据结构与算法 ὒ…...
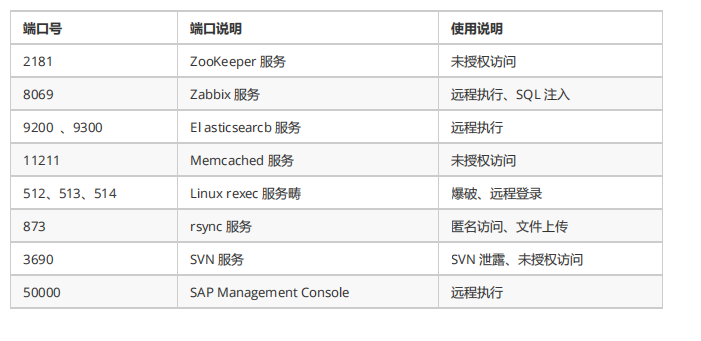
内网渗透(十二)之内网信息收集-内网端口扫描和发现
系列文章第一章节之基础知识篇 内网渗透(一)之基础知识-内网渗透介绍和概述 内网渗透(二)之基础知识-工作组介绍 内网渗透(三)之基础知识-域环境的介绍和优点 内网渗透(四)之基础知识-搭建域环境 内网渗透(五)之基础知识-Active Directory活动目录介绍和使用 内网渗透(六)之基…...
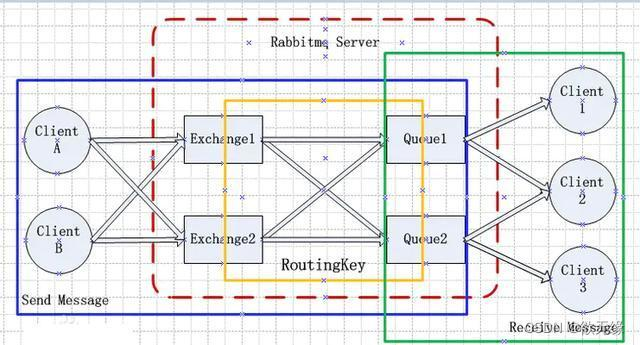
RabbitMq相关面试题
文章目录消息队列有没有接触过? 简单介绍一下?消息中间件模式分类 ?使用MQ有什么好处?MQ如何选型 ?你们项目中用到过 MQ 吗?谈谈你对 MQ 的理解?MQ消费者消费消息的顺序一致性问题?R…...
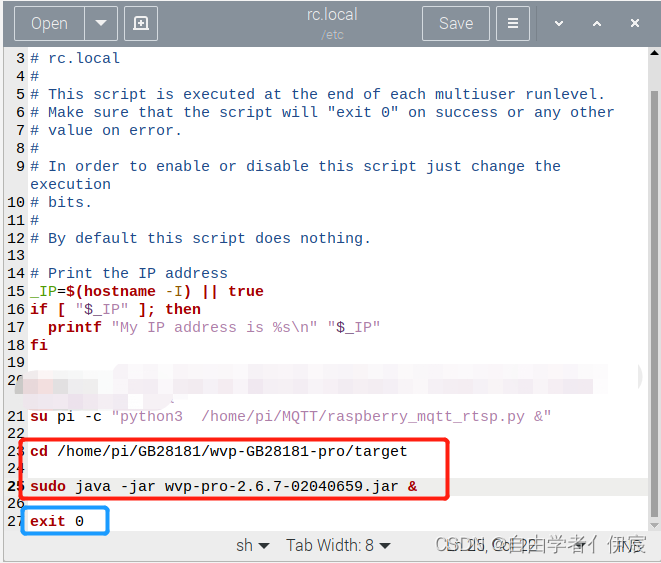
树莓派开机自启动Python脚本或者应用程序
树莓派开机自启动Python脚本或者应用程序前言一、对于Python脚本的自启动方法1、打开etc/rc.local文件2、编辑输入需要启动的指令3、重启树莓派验证二、对于需要读写配置文件的应用程序的自启前言 在树莓派上写了一些Python脚本,还有一个java 的jar包想要在树莓派上…...

全国青少年编程等级考试scratch四级真题2022年9月(含题库答题软件账号)
青少年编程等级考试scratch真题答题考试系统请点击电子学会-全国青少年编程等级考试真题Scratch一级(2019年3月)在线答题_程序猿下山的博客-CSDN博客_小航答题助手1、运行下列程序,说法正确的是?( )A.列表…...
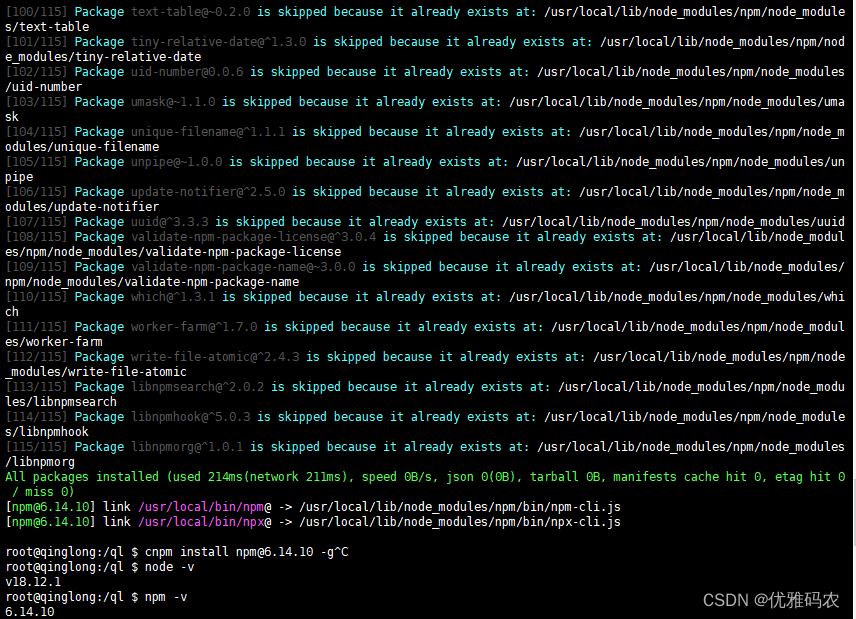
NodeJS与npm版本不一致时降级npm的方法
首先查看 Node.js 与 npm 版本对应关系:Node.js与npm版本查看。 安装 cnpm: npm install -g cnpm 查看一下 npm 和 cnpm 的镜像: npm config get registry cnpm config get registry 2 如果不是 https://registry.npm.taobao.org/ 的话就修…...
)
《C++ Primer Plus》第16章:string类和标准模板库(8)
关联容器 关联容器(associative container)是对容器概念的另一个改进。关联容器将值与键关联在一起,并使用键来查找值。例如,值可以表示雇员信息(如姓名、地址、办公室号码、家庭电话和工作电话、健康计划等ÿ…...

Linux安装达梦8数据库
Linux安装达梦8数据库 服务器系统:centos7 数据库版本:达梦8 先获取安装包:https://eco.dameng.com/download/?_blank 选择相应版本下载,下载完解压之后会得到一个iso文件,把他上传到服务器上,建议上传到/opt目录下…...
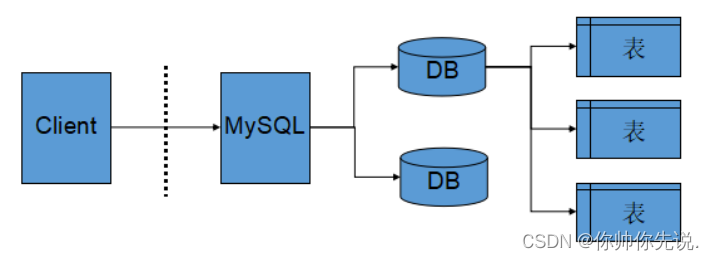
[数据库]初识数据库
●🧑个人主页:你帅你先说. ●📃欢迎点赞👍关注💡收藏💖 ●📖既选择了远方,便只顾风雨兼程。 ●🤟欢迎大家有问题随时私信我! ●🧐版权:本文由[你帅…...
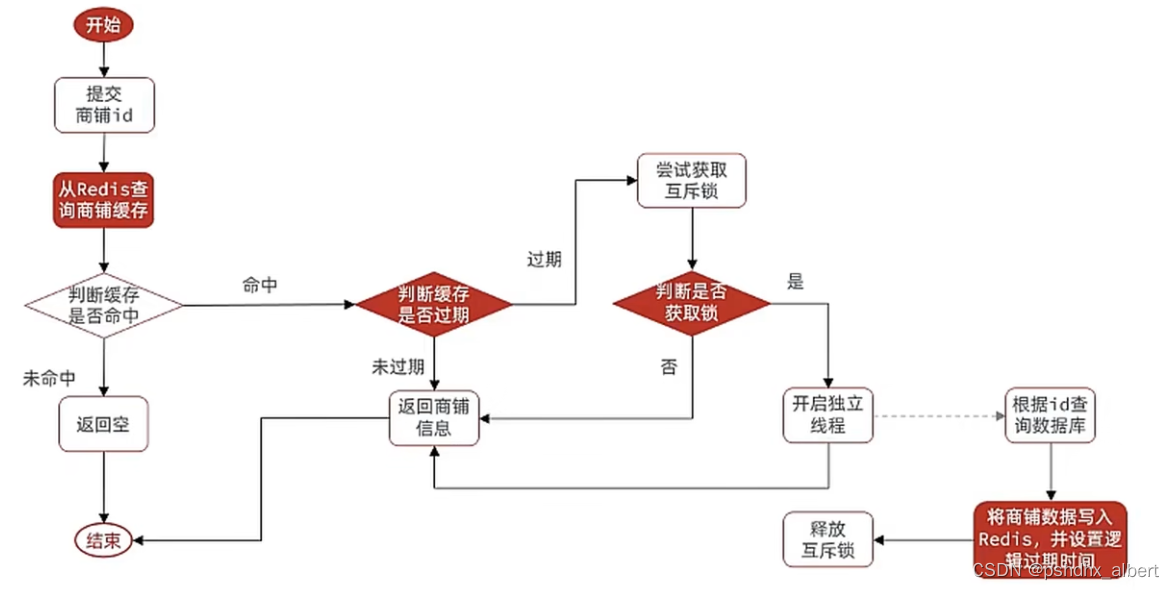
Redis的缓存雪崩、击穿、穿透和解决方案
2.5 缓存穿透问题的解决思路 缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。 常见的解决方案有两种: 缓存空对象 优点:实现简单,维护…...

52000000
选择题(共52题,合计52.0分) 1. 敏捷团队在项目执行过程中会用到一种叫做“看板”的可视化工具,它可显示WIP, 帮助识别瓶颈和过度承诺, 从而使团队能够优化工作流。请从下列选项中选择WIP的最佳解释?() A 等待初步加工的材料的库存 B 目前正…...
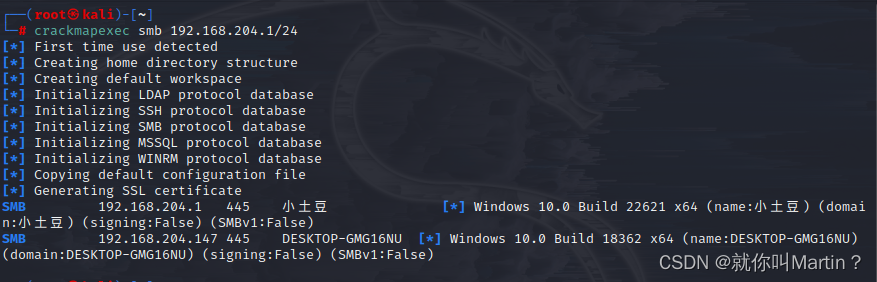
内网资源探测
✅作者简介:CSDN内容合伙人、信息安全专业在校大学生🏆 🔥系列专栏 :内网安全 📃新人博主 :欢迎点赞收藏关注,会回访! 💬舞台再大,你不上台,永远是…...
)
Java后端内部面试题(前一部分)
面试题 基础篇 1、Java语言有哪些特点 1、简单易学、有丰富的类库 2、面向对象(Java最重要的特性,让程序耦合度更低,内聚性更高) 2、面向对象和面向过程的区别 面向过程:是分析解决问题的步骤,然后用函数把…...

关于如何抄引擎源码
前两天,后台有网友发私信给我,问我如何抄引擎源码。我一愣,感觉像吃饭喝水一样自然。 抄源码的好处就不说了,抄之前不懂的内容,抄完后就懂了,至少懂一部分了。当然也可以只读不抄,不过ÿ…...
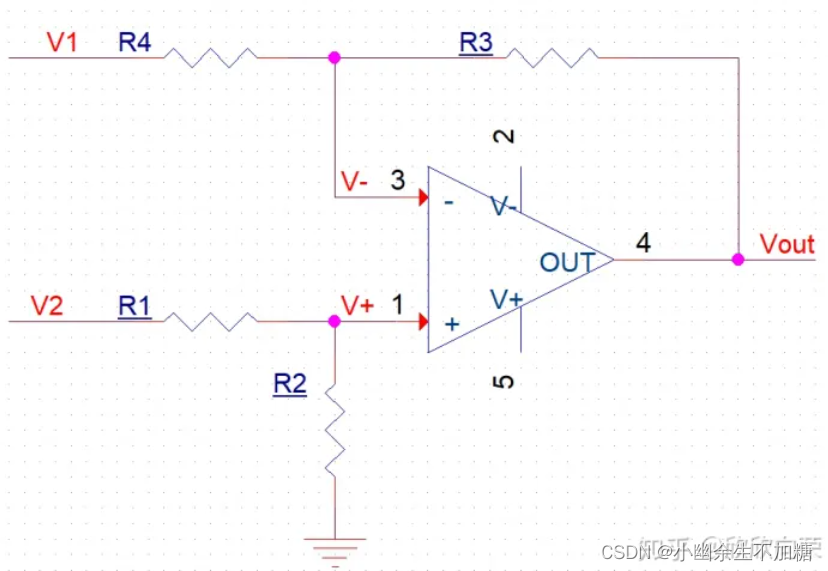
差分模拟信号转单端输出电路设计
需求分析: 1.差分输入0~16V -Vpp电压量; 2.输入频率0~1.2KHz; 3.单端对应输出0~3V的模拟量; 4.输出频率对应0~1.2KHz; 5.供电范围3~5V。 针对以上需求,设计如下图所示电路。 1.电路功能: …...

Java中的clone方法
注解定义: 注解是一种注释机制,它可以注释包、类、方法、变量、参数,在编译器生成类文件时,标注可以被嵌入到字节码中。注解的分类:内置注解Override :重写方法,引用时没有该方法时会编译错误public class …...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

Caliper 配置文件解析:fisco-bcos.json
config.yaml 文件 config.yaml 是 Caliper 的主配置文件,通常包含以下内容: test:name: fisco-bcos-test # 测试名称description: Performance test of FISCO-BCOS # 测试描述workers:type: local # 工作进程类型number: 5 # 工作进程数量monitor:type: - docker- pro…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...