神经网络与深度学习——第14章 深度强化学习
本文讨论的内容参考自《神经网络与深度学习》https://nndl.github.io/ 第14章 深度强化学习
深度强化学习
强化学习(Reinforcement Learning,RL),也叫增强学习,是指一类从与环境交互中不断学习的问题以及解决这类问题的方法,强化学习可以描述为一个智能体从与环境交互中不断学习以完成特定目标(比如取得最大奖励值)。和深度学习类似,强化学习中的关键问题也是贡献度分配问题(即一个系统中不同的组件(component)对最终输出结果的贡献或影响),每一个动作并不能直接得到监督信息,需要通过整个模型的最终监督信息(奖励)得到,并且有一定的延时性。
强化学习和监督学习的不同在于,强化学习问题不需要给出“正确”策略作为监督信息,只需要给出策略的(延迟)回报,并通过调整策略来取得最大化的期望回报。
强化学习问题
典型例子
强化学习广泛应用于很多领域,比如电子游戏、棋类游戏、迷宫类游戏、控制系统、推荐等。
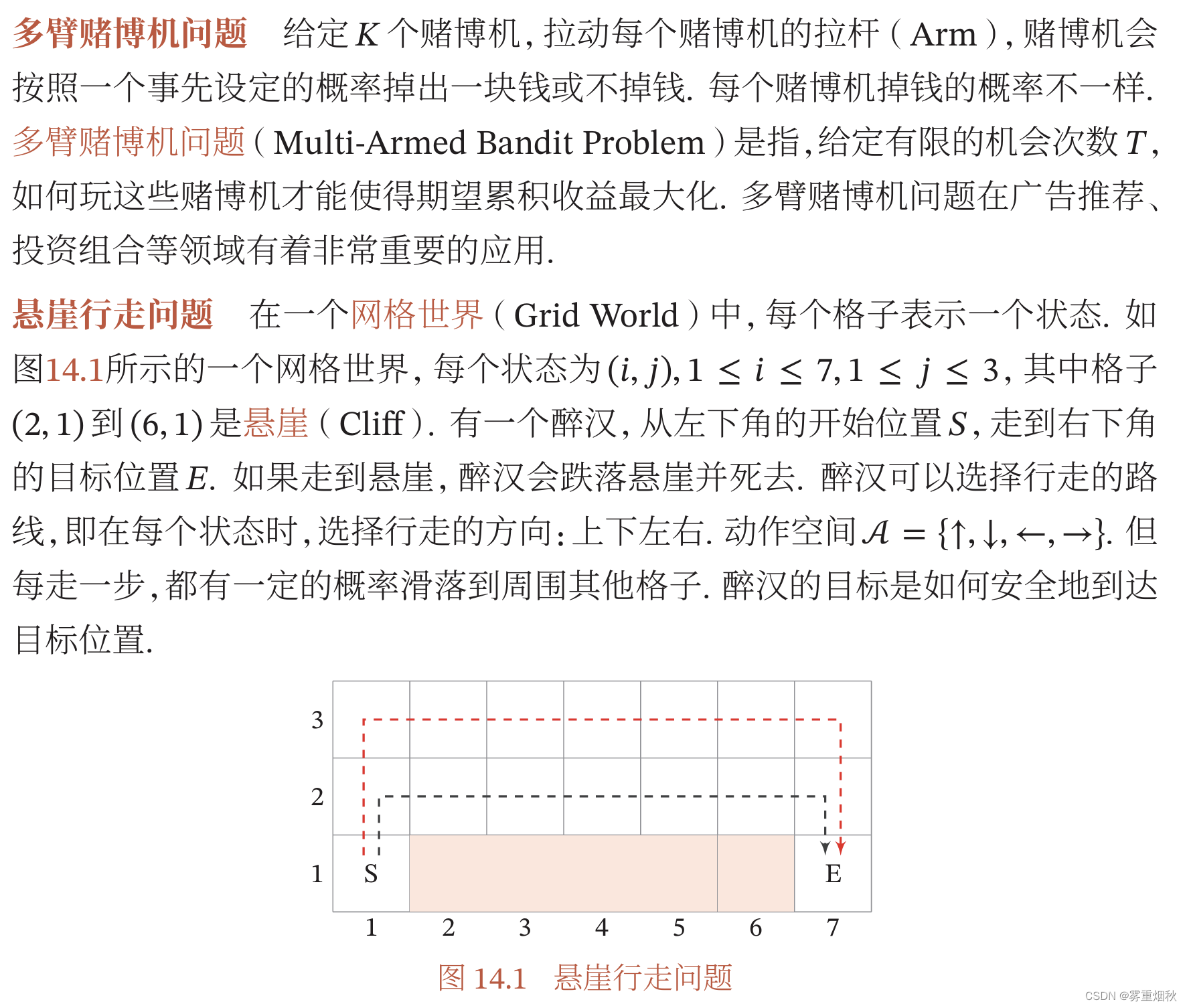
强化学习定义
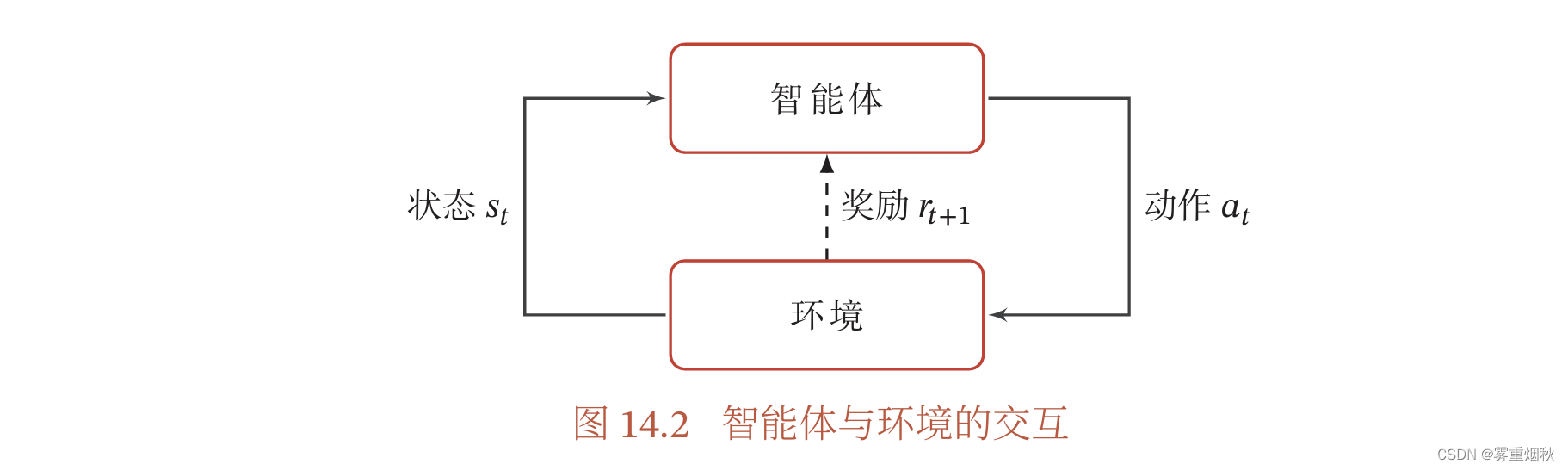
在强化学习中,有两个可以进行交互的对象:智能体和环境。
(1)智能体(Agent)可以感知外界环境的状态(State)和反馈的奖励(Reward),并进行学习和决策。智能体的决策功能是指根据外界环境的状态来做出不同的动作,而学习功能是指根据外界环境的奖励来调整策略。
(2)环境是智能体外部的所有事物,并受智能体动作的影响而改变其状态,并反馈给智能体相应的奖励。
强化学习的基本要素包括:
(1)状态 s s s是对环境的描述,可以是离散的或连续的,其状态空间为 S S S。
(2)动作 a a a是对智能体行为的描述,可以是离散的或连续的,其动作空间为 A A A。
(3)策略 π ( a ∣ s ) \pi (a|s) π(a∣s)是智能体根据环境状态 s s s来决定下一步动作 a a a的函数。
(4)状态转移概率 p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a)是在智能体根据当前状态 s s s作出一个动作 a a a之后,环境在下一个时刻转变为状态 s ′ s' s′的概率。
(5)即时奖励 r ( s , a , s ′ ) r(s,a,s') r(s,a,s′)是一个标量函数,即智能体根据当前状态 s s s做出动作 a a a之后,环境会反馈给智能体一个奖励,这个奖励也经常和下一个时刻的状态 s ′ s' s′有关。
策略 智能体的策略(Policy)就是智能体如何根据环境状态 s s s来决定下一步的动作 a a a,通常可以分为确定性策略(Deterministic Policy)和随机性策略(Stochastic Policy)两种。
确定性策略是从状态空间到动作空间的映射函数 π : S − > A \pi : S -> A π:S−>A。随机性策略表示在给定环境状态时,智能体选择某个动作的概率分布
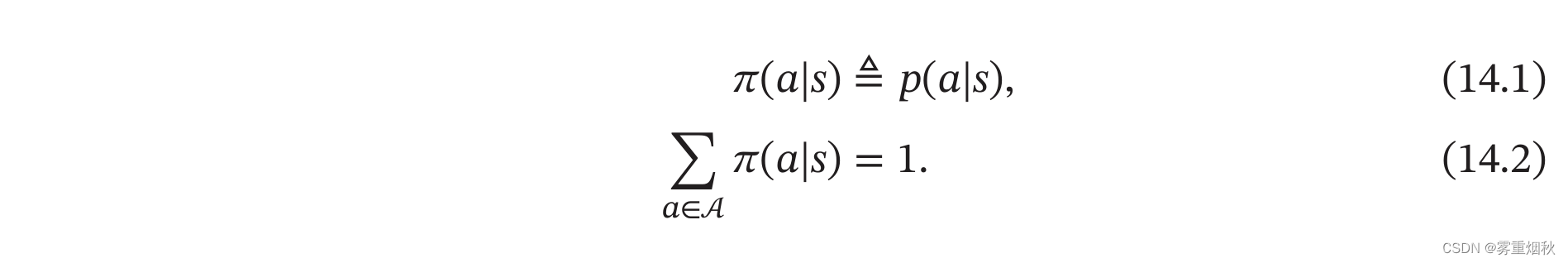
通常情况下,强化学习一般使用随机性策略。随机性策略可以有很多优点:1)在学习时可以通过引入一定随机性更好的探索环境;2)随机性策略的动作具有多样性,这一点在多个智能体博弈时也非常重要。采用确定性策略的智能体总是对同样的环境做出相同的动作,会导致它的策略很容易被对手预测。
马尔可夫决策过程
为简单起见,我们将智能体与环境的交互看作离散的时间序列。智能体从感知到初始环境 s 0 s_0 s0开始,然后决定做一个相应的动作 a 0 a_0 a0,环境相应地发生改变到新的状态 s 1 s_1 s1,并反馈给智能体一个即时奖励 r 1 r_1 r1,然后智能体又根据状态 s 1 s_1 s1做一个动作 a 1 a_1 a1,环境相应改变为 s 2 s_2 s2,并反馈奖励 r 2 r_2 r2。这样的交互可以一直进行下去。
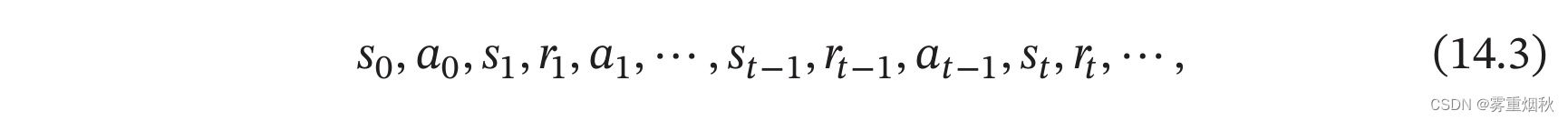
其中 r t = r ( s t − 1 , a t − 1 , s t ) r_t = r(s_{t-1},a_{t-1},s_t) rt=r(st−1,at−1,st)是第 t t t时刻的即时奖励。图14.2给出了智能体与环境的交互。
智能体与环境的交互过程可以看作一个马尔可夫决策过程。马尔可夫过程(Markov Process)是一组具有马尔可夫性质的随机变量序列 s 0 , s 1 , . . . , s t ∈ S s_0,s_1,...,s_t \in S s0,s1,...,st∈S,其中下一个时刻的状态 s t + 1 s_{t+1} st+1只取决于当前状态 s t s_t st,
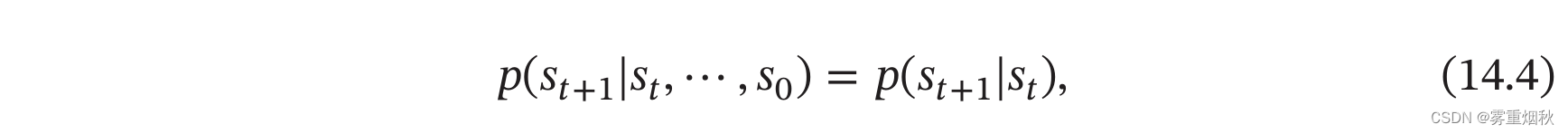
其中 p ( s t + 1 ∣ t ) p(s_{t+1}|t) p(st+1∣t)称为状态转移概率, ∑ s t + 1 ∈ S p ( s t + 1 ∣ s t ) = 1 \sum_{s_{t+1} \in S} p(s_{t+1}|s_t)=1 ∑st+1∈Sp(st+1∣st)=1。
马尔可夫决策过程在马尔可夫过程中加入一个额外的变量:动作 a a a,下一个时刻的状态 s t + 1 s_{t+1} st+1不但和当前时刻的状态 s t s_t st相关,而且和动作 a t a_t at相关,
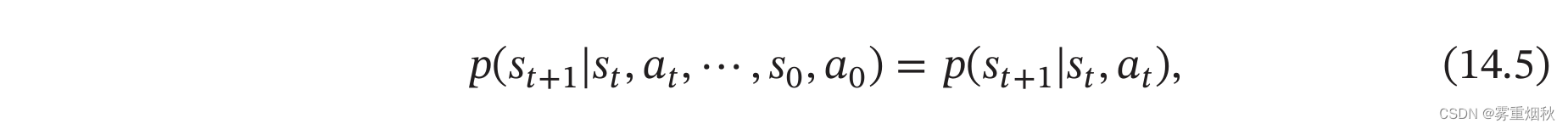
其中 p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t,a_t) p(st+1∣st,at)为状态转移概率。
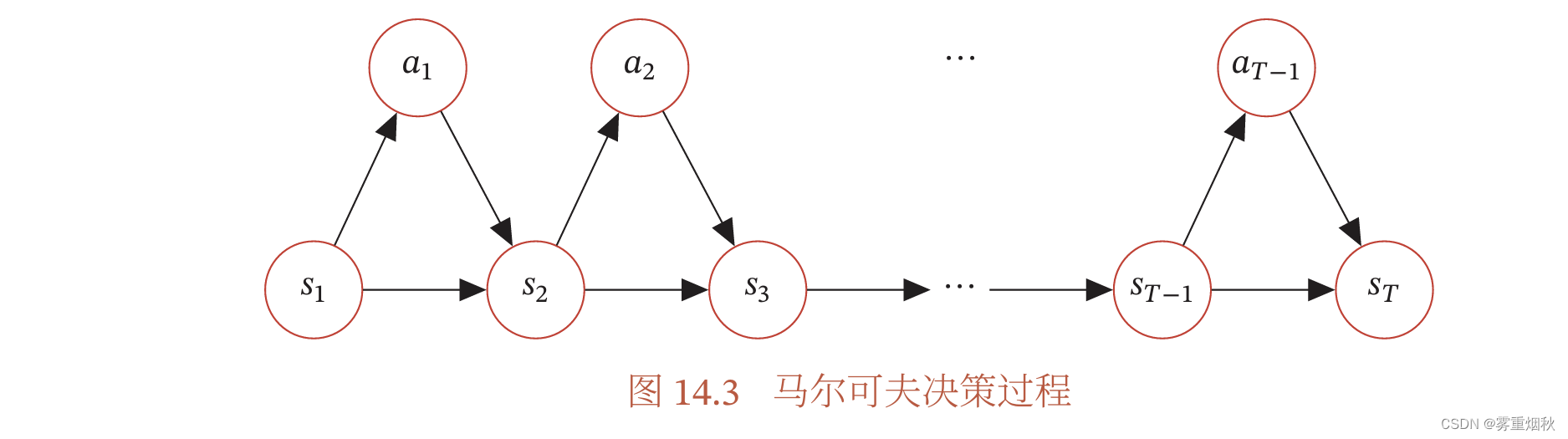
图14,3给出了马尔可夫决策过程的图模型表示。
给定策略 π ( a ∣ s ) \pi(a|s) π(a∣s),马尔可夫决策过程的一个轨迹(Trajectory) τ = s 0 , a 0 , s 1 , r 1 , a 1 , . . . , s T − 1 , a T − 1 , s T , r T \tau = s_0,a_0,s_1,r_1,a_1,...,s_{T-1},a_{T-1},s_T,r_T τ=s0,a0,s1,r1,a1,...,sT−1,aT−1,sT,rT的概率为
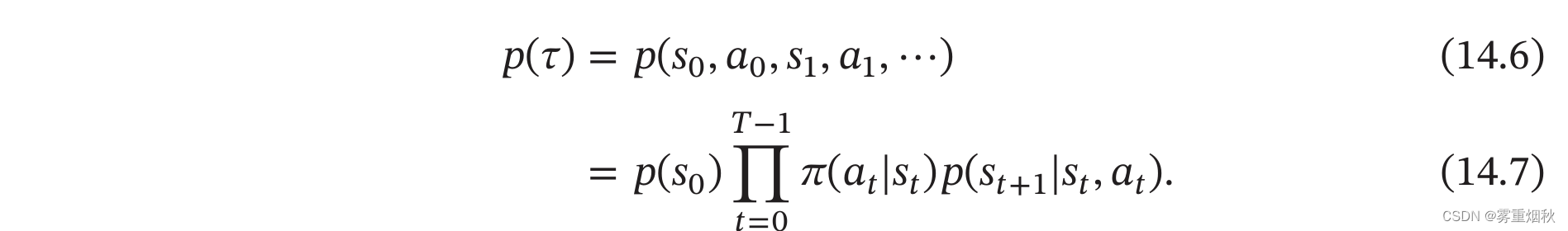
证明过程如下:
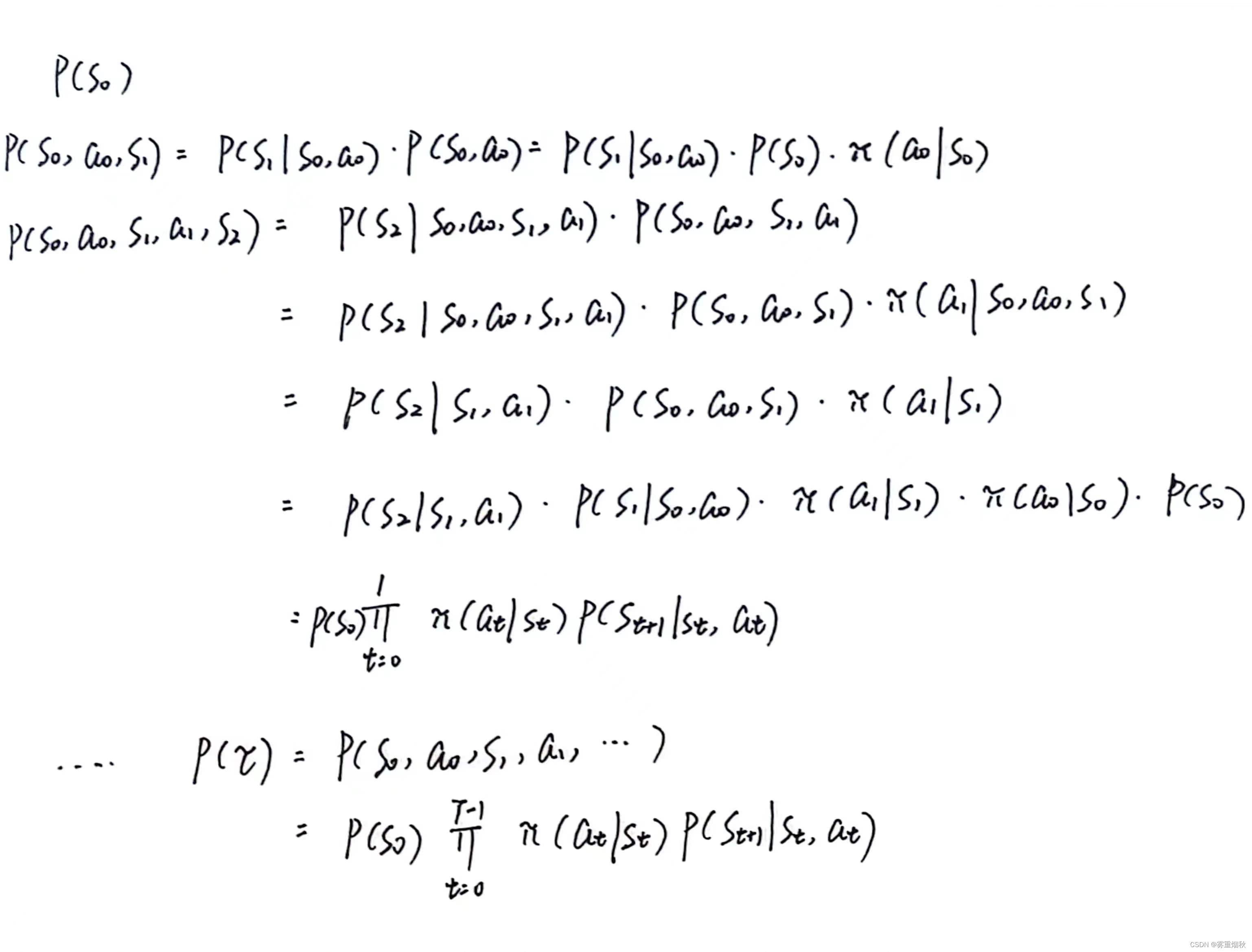
强化学习的目标函数
总回报
给定策略 π ( a ∣ s ) \pi(a|s) π(a∣s),智能体和环境一次交互过程的轨迹 τ \tau τ所收到的累积奖励为总回报(Return)。
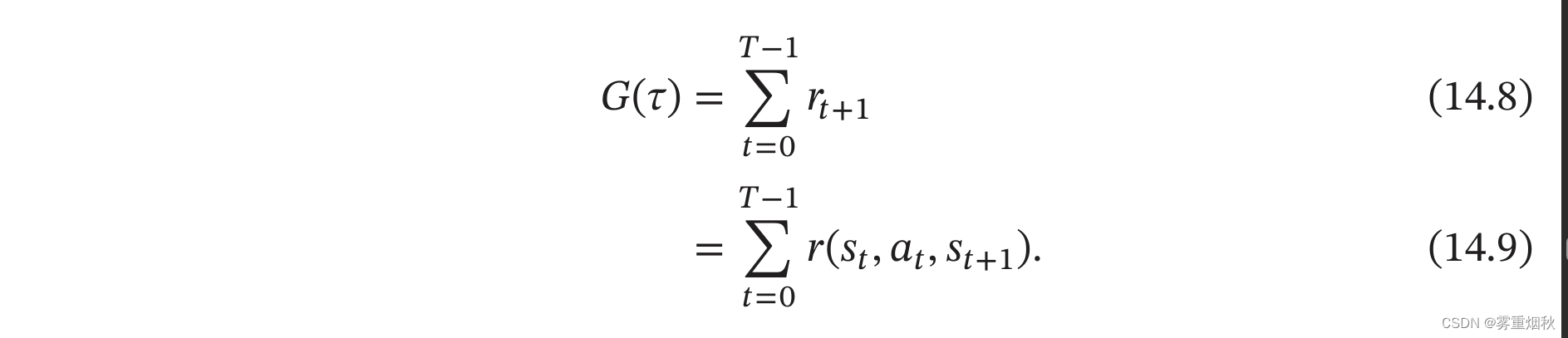
假设环境中有一个或多个特殊的终止状态(Terminal State),当到达终止状态时,一个智能体和环境的交互过程就结束了。这一轮交互的过程称为一个回合(Episode)或试验(Trial)。一般的强化学习任务(比如下棋、游戏)都属于这种回合式任务(Episodic Task)。
如果环境中没有终止状态(比如终身学习的机器人),即 T = ∞ T=\infty T=∞,称为持续式任务(Continuing Task),其总回报也可能是无穷大。为了解决这个问题,我们可以引入一个折扣率来降低远期回报的权重。折扣回报(Discounted Return)定义为
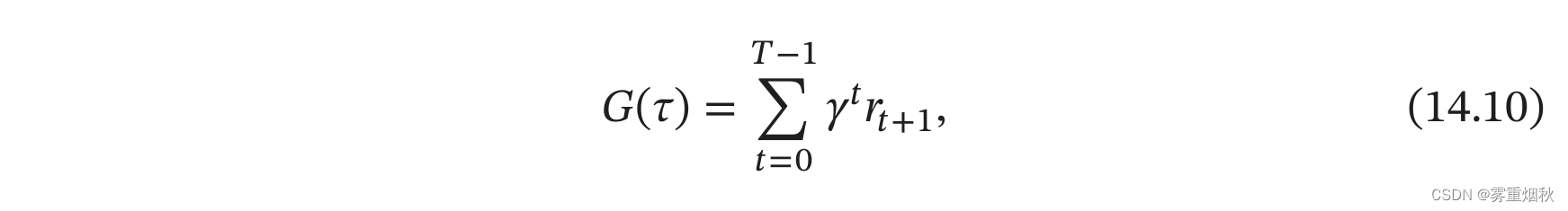
其中 γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1]是折扣率。当 γ \gamma γ接近于0时,智能体更在意短期汇报;而当 γ \gamma γ接近于1时,长期回报变得更重要。
目标函数
因为策略和状态转移都有一定的随机性,所以每次试验得到的轨迹是一个随机序列,其收获的总回报也不一样。强化学习的目标是学习到一个策略 π σ ( a ∣ s ) \pi_{\sigma}(a|s) πσ(a∣s)来最大化期望回报(Expected Return),即希望智能体执行一系列的动作来获得尽可能多的平均回报。
强化学习的目标函数为
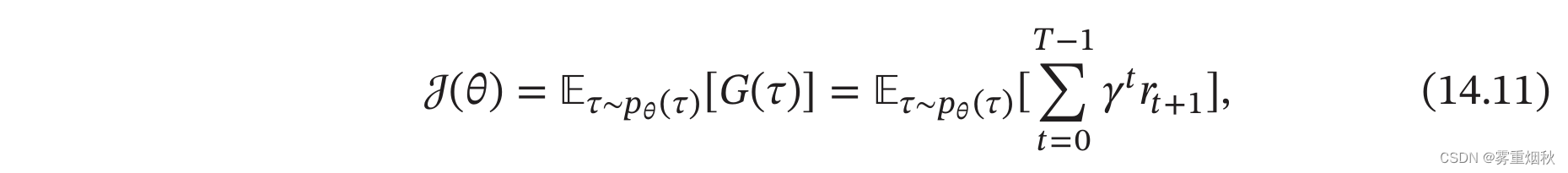
其中 σ \sigma σ为策略函数的参数。
值函数
为了评估策略\pi的期望回报,我们定义两个值函数:状态值函数和状态-动作值函数。
状态值函数
策略 π \pi π的期望回报可以分解为
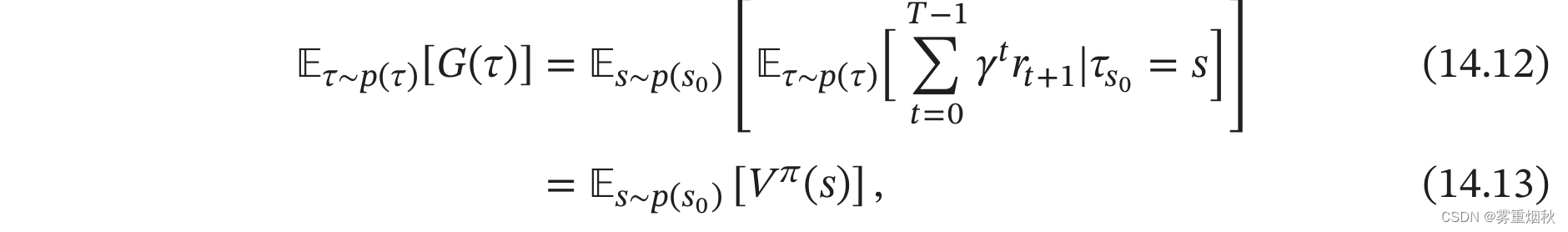
其中 V π ( s ) V^{\pi}(s) Vπ(s)称为状态值函数(State Value Function),表示从状态 s s s开始,执行策略 π \pi π得到的期望总回报

其中 τ s 0 \tau_{s_0} τs0表示轨迹 τ \tau τ的起始状态。
为了方便起见,我们用 τ 0 : T \tau_{0:T} τ0:T来表示轨迹 s 0 , a 0 , s 1 , . . . , s T s_0,a_0,s_1,...,s_T s0,a0,s1,...,sT,用 τ 1 : T \tau_{1:T} τ1:T来表示轨迹 s 1 , a 1 , . . . , s T s_1,a_1,...,s_T s1,a1,...,sT,因此有 τ 0 : T = s 0 , a 0 , τ 1 : T \tau_{0:T} = s_0,a_0,\tau_{1:T} τ0:T=s0,a0,τ1:T。
根据马尔可夫性质, V π ( s ) V^{\pi}(s) Vπ(s)可展开得到
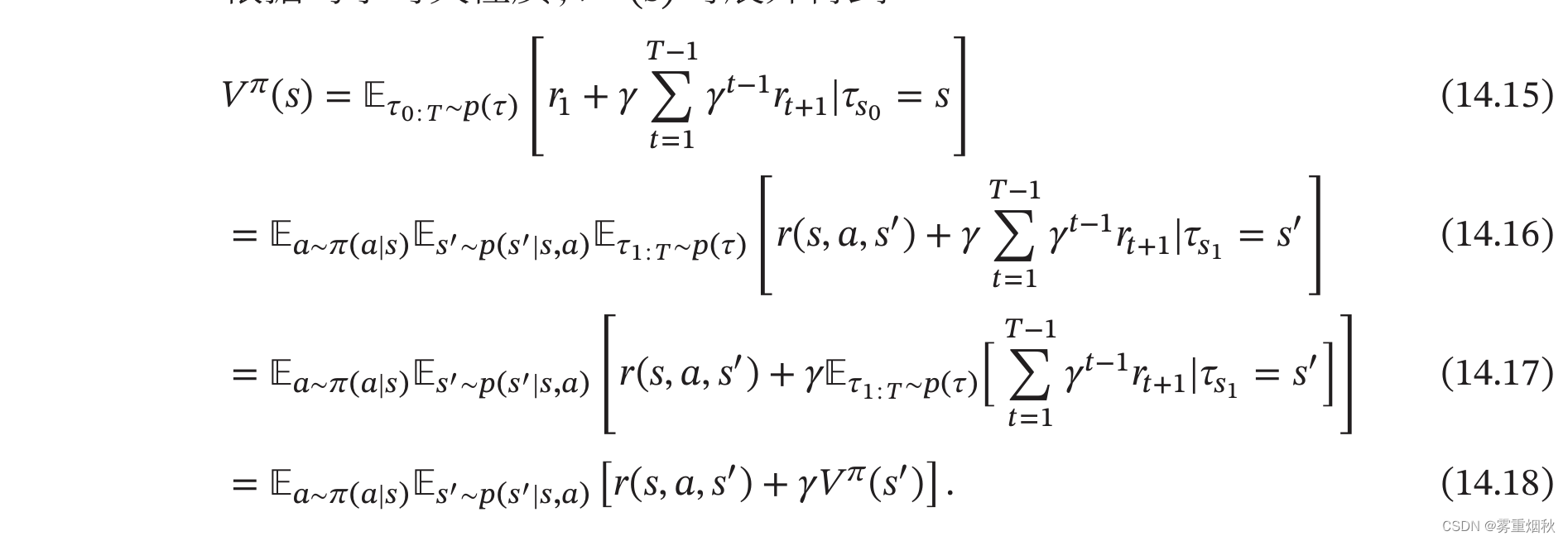
公式(14.18)也称为贝尔曼方程,表示当前状态的值函数可以通过下个状态的值函数来计算。
如果给定策略 π ( a ∣ s ) \pi(a|s) π(a∣s),状态转移概率 p ( s ′ ∣ s . a ) p(s'|s.a) p(s′∣s.a)和奖励 r ( s , a , s ′ ) r(s,a,s') r(s,a,s′),我们就可以通过迭代的方式来计算 V π ( s ) V^{\pi}(s) Vπ(s)。由于存在折扣率,迭代一定步数后,每个状态的值函数就会固定不变。
状态-动作值函数
公式(14.18)中的第二个期望是指初始状态为s并进行动作a,然后执行策略\pi得到的期望总汇报,称为状态-动作值函数:
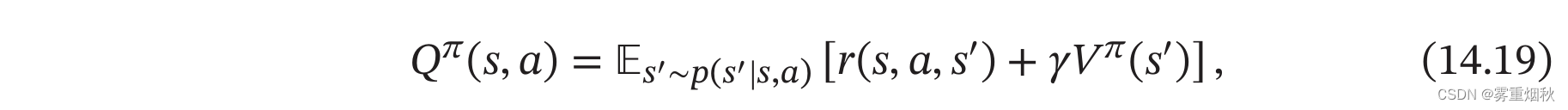
状态-动作值函数也经常称为Q函数(Q-Function)。
状态值函数 V π ( s ) V^{\pi}(s) Vπ(s)是 Q Q Q函数 Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a)关于动作 a a a的期望,即:
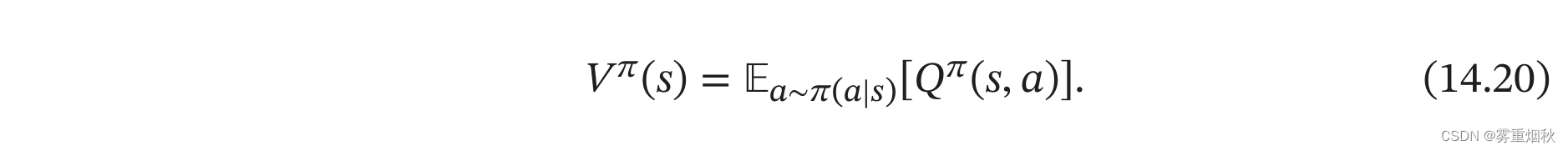
结合公式(14.19)和公式(14.20),Q函数可以写为:
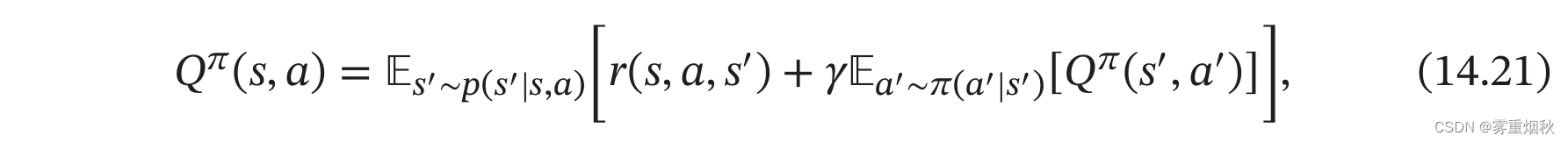
这是关于Q函数的贝尔曼方程。
值函数的作用
值函数可以看作对策略 π \pi π的评估,因此我们就可以根据值函数来优化策略。假设在状态 s s s,有一个动作 a ∗ a^{*} a∗使得 Q π ( s , a ∗ ) > V π ( s ) Q^{\pi}(s,a^*)>V^{\pi}(s) Qπ(s,a∗)>Vπ(s),说明执行动作 a ∗ a^* a∗的回报比当前策略 π ( a ∣ s ) \pi(a|s) π(a∣s)要高,我们就可以调整参数使得策略中动作 a ∗ a^* a∗的概率 p ( a ∗ ∣ s ) p(a^*|s) p(a∗∣s)增加。
深度强化学习
在强化学习中,一般需要建模策略 π ( a ∣ s ) \pi(a|s) π(a∣s)和值函数 V π ( s ) V^{\pi}(s) Vπ(s)和 Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a)。早期的强化学习算法主要关注状态和动作都是离散且有限的问题,可以使用表格来记录这些概率。但在很多实际问题中,有些任务的状态和动作的数量非常多。比如围棋的棋局有KaTeX parse error: Undefined control sequence: \Approx at position 10: 10^{361} \̲A̲p̲p̲r̲o̲x̲ ̲10^{170}种状态,动作数量为361。还有些任务的状态和动作是连续的。比如在自动驾驶中,智能体感知到的环境状态是各种传感器数据,一般都是连续的。动作是操作方向盘的方向(-90度~90度)和速度控制(0-300公里/小时),也是连续的。
为了有效地解决这些问题,我们可以设计一个更强的策略函数(比如深度神经网络),使得智能体可以应对复杂的环境,学习更优的策略,并具有更好的泛化能力。
深度强化学习是将强化学习和深度学习结合在一起,用强化学习来定义问题和优化目标,用深度学习来解决策略和值函数的建模问题,然后使用误差反向传播算法来优化目标函数。深度强化学习在一定程度上具备解决复杂问题的通用智能,并在很多任务上都取得了很大的成功。
基于值函数的学习方法
值函数是对策略 π \pi π的评估,如果策略 π \pi π有限(即状态数和动作数都有限),可以对所有的策略进行评估并选出最优策略 π ∗ \pi^{*} π∗。
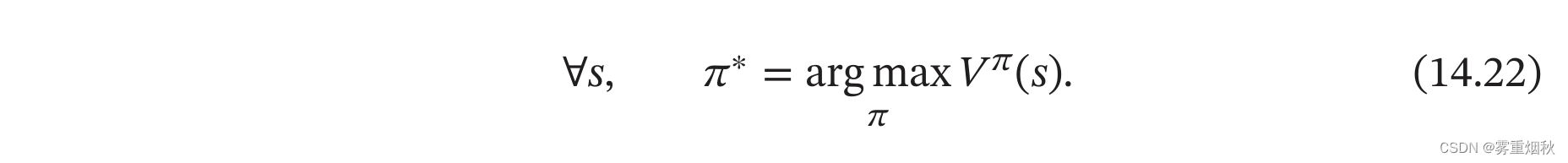
但这种方式在实践中很难实现。假设状态空间 S S S和动作空间 A A A都是离散且有限的,策略空间为 ∣ A ∣ ∣ S ∣ |A|^{|S|} ∣A∣∣S∣,往往也非常大。
一种可行的方式是通过迭代的方法不断优化策略,直到选出最优策略。对于一个策略 π ( a ∣ s ) \pi(a|s) π(a∣s),其 Q Q Q函数为 Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a),我们可以设置一个新的策略 π ′ ( a ∣ s ) \pi '(a|s) π′(a∣s),
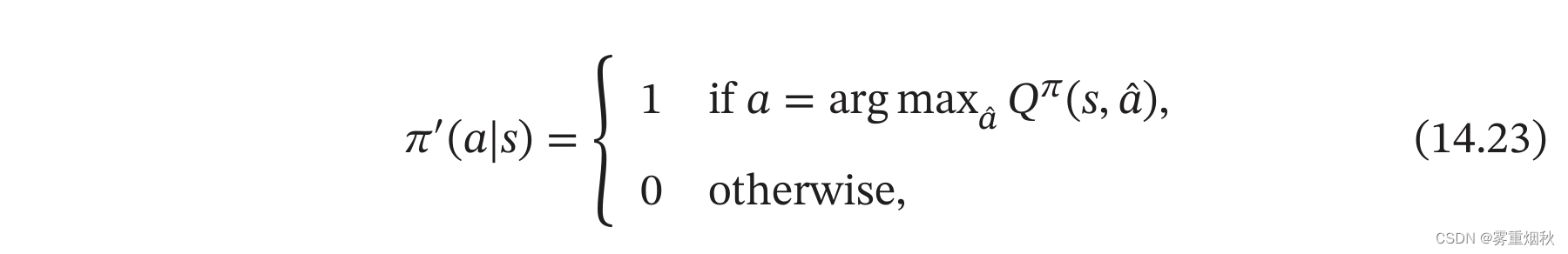
即 π ′ ( a ∣ s ) \pi '(a|s) π′(a∣s)为一个确定性的策略,也可以直接写为

如果执行 π ′ \pi ' π′,会有
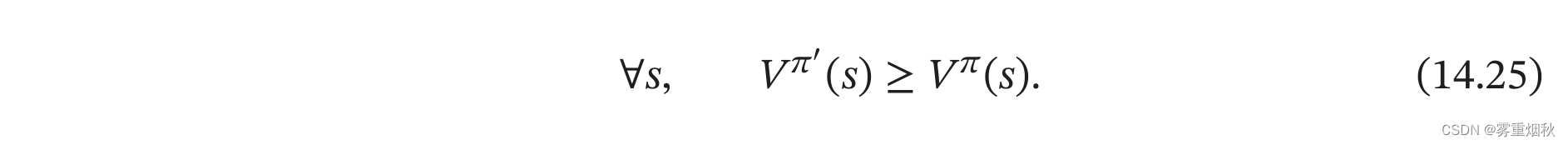
根据公式(14.25),我们可以通过下面方式来学习最优策略:先随机初始化一个策略,计算该策略的值函数,并根据值函数来设置新的策略,然后一直反复迭代直到收敛。(即将策略更新为每个状态下都选取最优行动的策略)
基于值函数的策略学习方法中最关键的是如何计算策略 π \pi π的值函数,一般有动态规划或蒙特卡罗两种计算方式。
动态规划算法
从贝尔曼方程可知,如果知道马尔可夫决策过程的状态转移概率 p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a)和奖励 r ( s , a , s ′ ) r(s,a,s') r(s,a,s′),我们直接可以通过贝尔曼方程来迭代计算其值函数。这种模型已知的强化学习算法也称为基于模型的强化学习算法,这里的模型就是指马尔可夫决策过程。
在模型已知时,可以通过动态规划的算法来计算。常用的方法主要有策略迭代算法和值迭代算法。
策略迭代算法
策略迭代算法中,每次迭代可以分为两步:
(1)策略评估:计算当前策略下每个状态的值函数,即算法 14.1 14.1 14.1中的3-6步。策略评估可以通过贝尔曼方程(14.18)进行迭代计算 V π ( s ) V^{\pi}(s) Vπ(s)。
(2)策略改进:根据值函数来更新策略,即算法14.1中的7-8步。
策略迭代算法如算法14.1所示。

值迭代算法
策略迭代算法中的策略评估和策略改进是交替轮流进行,其中策略评估也是通过一个内部迭代来进行计算,其计算量比较大.事实上,我们不需要每次计算出每次策略对应的精确的值函数,也就是说内部迭代不需要执行到完全收敛。
值迭代算法将策略评估和策略改进两个过程合并,来直接计算出最优策略,最优策略 π ∗ \pi^{*} π∗对应的值函数称为最优值函数,其中包括最有状态值函数 V ∗ ( s ) V^{*}(s) V∗(s)和最优状态-动作值函数 Q ∗ ( s , a ) Q^{*}(s,a) Q∗(s,a),它们之间的关系为
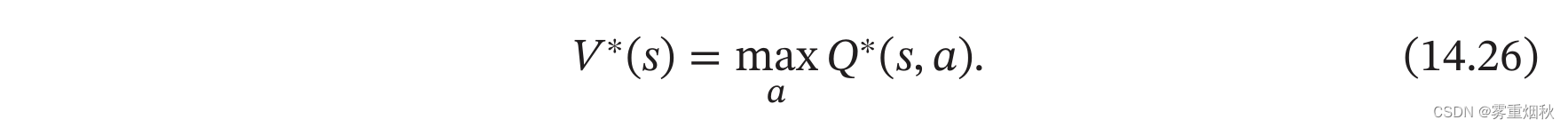
根据贝尔曼方程,我们可以通过迭代的方式来计算最优状态值函数 V ∗ ( s ) V^{*}(s) V∗(s)和最优状态-动作值函数 Q ∗ ( s , a ) Q^{*}(s,a) Q∗(s,a):
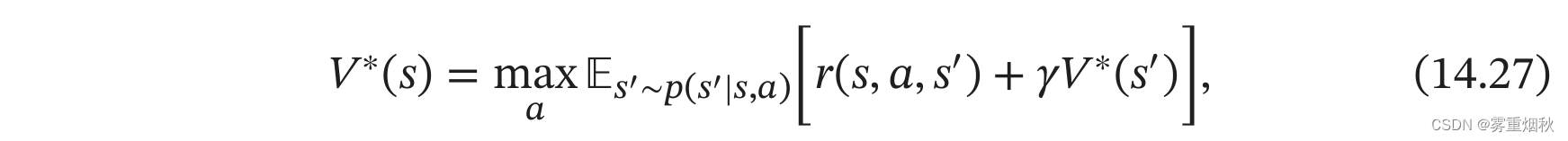
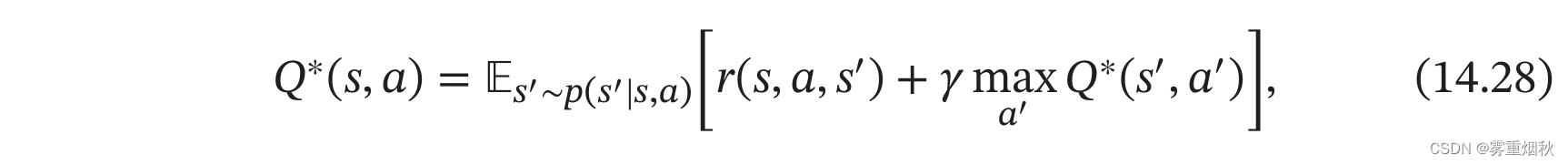
这两个公式称为贝尔曼最优方程。
值迭代算法通过直接优化贝尔曼最优方程(14.27),迭代计算最优值函数,值迭代算法如算法14.2所示。


基于模型的强化学习算法实际上是一种动态规划方法。在实际应用中有以下两点限制:
(1)要求模型已知,即要给出马尔可夫决策过程的状态转移概率 p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a)和奖励函数 r ( s , a , s ′ ) r(s,a,s') r(s,a,s′)。但实际应用中这个要求很难满足。如果我们事先不知道模型,那么可以先让智能体与环境交互来估计模型,即估计状态转移概率和奖励函数。一个简单的估计模型的方法为R-max,通过随机游走的方法来探索环境。每个随机一个策略并执行,然后收集状态转移和奖励的样本。在收集一定的样本后,就可以通过统计或监督学习来重构出马尔可夫决策过程。但是,这种基于采样的重构过程的复杂度也非常高,只能应用于状态数非常少的场合。
(2)效率问题,即当状态数量较多时,算法效率比较低。但在实际应用中,很多问题的状态数量和动作数量非常多。比如,围棋有361个位置,每个位置有黑子、白子或无子三种状态。动作数量为361。不管是值迭代还是策略迭代,以当前计算机的计算能力,根本无法计算。一种有效的方法是通过一个函数(比如神经网络)来近似计算值函数,以减少复杂度,并提高泛化能力。
蒙特卡罗方法
在很多应用场景中,马尔可夫决策过程的状态转移概率和奖励函数都是未知的。在这种情况下,我们一般需要智能体和环境进行交互,并收集一些样本,然后再根据这些样本来求解马尔可夫决策过程最优策略。这种模型未知,基于采样的学习算法也称为模型无关的强化学习算法。
Q Q Q函数 Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a)是初始状态为 s s s,并执行动作 a a a后所能得到的期望总回报:
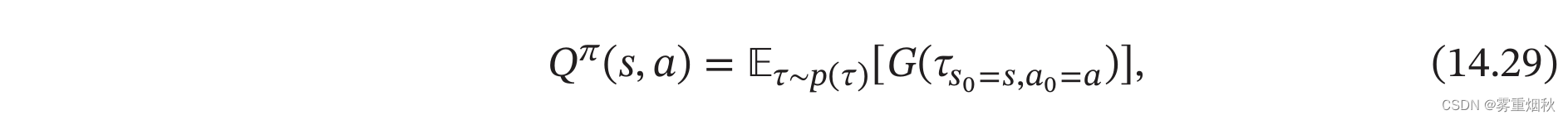
其中 τ s 0 = s , a 0 = a \tau_{s_0=s,a_0=a} τs0=s,a0=a表示轨迹 τ \tau τ的起始状态和动作为 s , a s,a s,a。
如果模型未知, Q Q Q函数可以通过采样来进行计算,这就是蒙特卡罗方法。对于一个策略 π \pi π,智能体从状态 s s s,执行动作 a a a开始,然后通过随机游走的方法来探索环境,并计算其得到的总回报。假设我们进行 N N N次试验,得到 N N N个轨迹 τ ( 1 ) , τ ( 2 ) , . . . , τ ( N ) \tau^{(1)},\tau^{(2)},...,\tau^{(N)} τ(1),τ(2),...,τ(N),其总回报分别为 G ( τ ( 1 ) ) , G ( τ ( 2 ) ) , . . . , G ( τ ( N ) ) G(\tau^{(1)}),G(\tau^{(2)}),...,G(\tau^{(N)}) G(τ(1)),G(τ(2)),...,G(τ(N))。 Q Q Q函数可以近似为
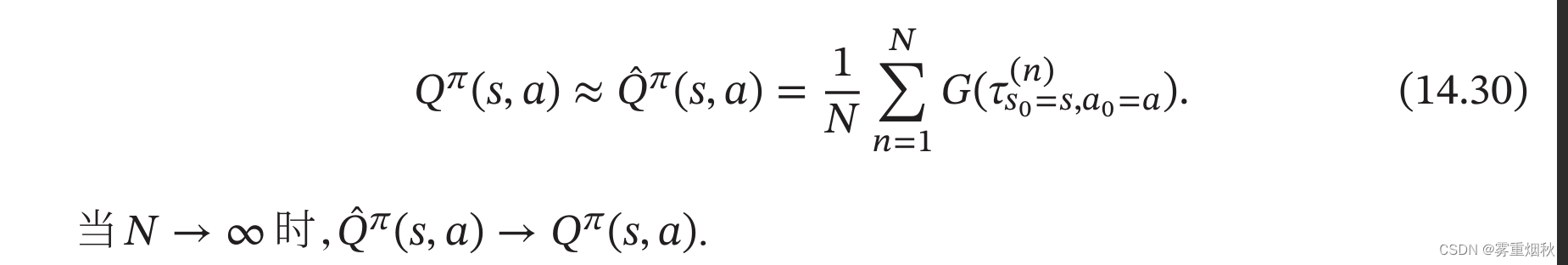
在近似估计出 Q Q Q函数 Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a)之后,就可以进行策略改进。然后在新的策略下重新通过采样来估计 Q Q Q函数,并不断重复,直至收敛。
利用和探索 但在蒙特卡罗方法中,如果采用确定性策略 π \pi π,每次试验得到的轨迹是一样的,只能计算出 Q π ( s , π ( s ) ) Q^{\pi}(s,\pi(s)) Qπ(s,π(s)),而无法计算其他动作 a ′ a' a′的 Q Q Q函数,因此也无法进一步改进策略。这样情况仅仅是对当前策略的利用(exploitation),而缺失了对环境的探索(exploration),即实验的轨迹应该尽可能覆盖所有的状态和动作,以找到更好的策略。
为了平衡利用和探索,我们可以采用 ϵ − \epsilon- ϵ−贪心法( ϵ − \epsilon- ϵ−greedy Method),对于一个目标策略 π \pi π,其对应的 ϵ − \epsilon- ϵ−贪心法策略为

这样, ϵ − \epsilon- ϵ−贪心法将一个仅利用的策略转为带探索的策略。每次选择动作 π ( s ) \pi(s) π(s)的概率为 1 − ϵ + ϵ ∣ A ∣ 1-\epsilon+\frac{\epsilon}{|A|} 1−ϵ+∣A∣ϵ,其他动作的概率为 ϵ ∣ A ∣ \frac{\epsilon}{|A|} ∣A∣ϵ。
同策略 在蒙特卡罗方法中,如果采样策略是 π ϵ ( s ) \pi^{\epsilon}(s) πϵ(s),不断改进策略也是 π ϵ ( s ) \pi^{\epsilon}(s) πϵ(s)而不是目标策略 π ( s ) \pi(s) π(s)这种采样与改进策略相同的强化学习方法叫作同策略(On-Policy)方法。
异策略 如果采样策略是 π ϵ ( s ) \pi^{\epsilon}(s) πϵ(s),而优化目标是策略 π \pi π,可以通过重要性采样,引入重要性权重来实现对目标策略 π \pi π的优化。这种采样与改进分别使用不同策略的强化学习方法叫做异策略(Off-Policy)方法。
时序差分学习方法
蒙特卡罗方法一般需要拿到完整的轨迹,才能对策略进行评估并更新模型,因此效率也比较低。时序差分学习(Temporal-Difference Learning)方法是蒙特卡罗方法的一种改进,通过引入动态规划算法来提高学习效率。时序差分学习方法是模拟一段轨迹,每行动一步(或者几步),就利用贝尔曼方程来评估行动前的状态的价值。



因此,更新 Q ^ π ( s , a ) \hat{Q}^{\pi}(s,a) Q^π(s,a)只需要知道当前状态 s s s和动作 a a a,奖励 r ( s , a , s ′ ) r(s,a,s') r(s,a,s′),下一步的状态 s ′ s' s′和动作 a ′ a' a′。这种策略学习方法称为SARSA算法。
SARSA算法的学习过程如算法14.3所示,其采样和优化的策略都是 π ϵ \pi^{\epsilon} πϵ,因此是一种同策略算法。为了提高计算效率,我们不需要对环境中所有的 s , a s,a s,a组合进行穷举,并计算值函数,只需要将当前的探索 ( s , a , r , s ′ , a ′ ) (s,a,r,s',a') (s,a,r,s′,a′)中 s ′ , a ′ s',a' s′,a′作为下一次估计的起始状态和动作。

时序差分学习是强化学习的主要想学习方法,其关键步骤就是在每次迭代中优化 Q Q Q函数来减少现实 r + γ Q ( s ′ , a ′ ) r+\gamma Q(s',a') r+γQ(s′,a′)和预期 Q ( s , a ) Q(s,a) Q(s,a)的差距。这和动物学习的机制十分相像。在大脑神经元中,多巴胺的释放机制和时序差分学习十分吻合。在一个实验中,通过监测猴子大脑释放的多巴胺浓度,发现如果猴子获得比预期更多的果汁,或者在没有预想到的时间喝到果汁,多巴胺释放大增。如果没有喝到本来预期的果汁,多巴胺的释放就会大减。多巴胺的释放,来自对于实际奖励和预期奖励的差异,而不是奖励本身。
时序差分学习方法和蒙特卡罗方法主要不同为:蒙特卡罗方法需要一条完整的路径才能知道其总回报,也不依赖马尔可夫性质;而时序差分学习方法只需要一步,其总回报需要通过马尔可夫性质来进行近似学习。
Q学习
Q学习是一种异策略的时许差分学习方法,在 Q Q Q学习中, Q Q Q函数的估计方法为
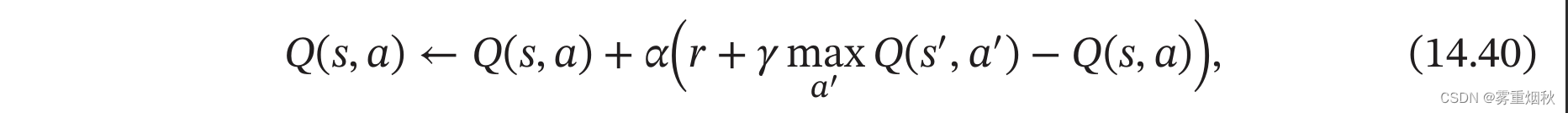
相当于让 Q ( s , a ) Q(s,a) Q(s,a)直接去估计最优状态值函数 Q ∗ ( s , a ) Q^{*}(s,a) Q∗(s,a)。
与SARSA算法不同, Q Q Q学习算法不通过 π ϵ \pi^{\epsilon} πϵ来选下一步的动作 a ′ a' a′,而是直接选最优的 Q Q Q函数,因此更新后的 Q Q Q函数是关于策略 π \pi π的,而不是策略 π ϵ \pi^{\epsilon} πϵ的。
算法14.4给出了 Q Q Q学习的学习过程

深度Q网络
为了在连续的状态和动作空间中计算值函数Q^{\pi}(s,a),我们可以用一个函数 Q ϕ ( s , a ) Q_{\phi}(\bm s,\bm a) Qϕ(s,a)来表示近似计算,称为值函数近似。
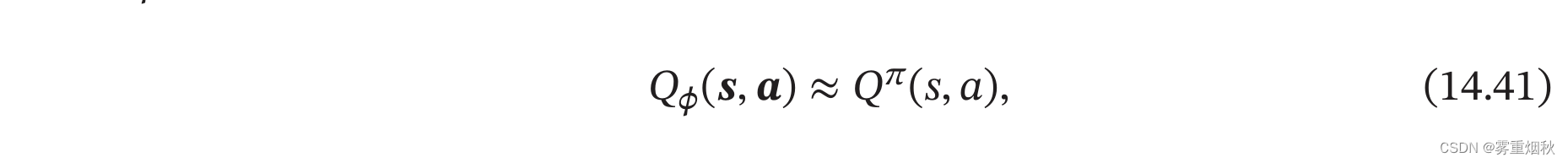
其中 s , a \bm s,\bm a s,a分别是状态 s s s和动作 a a a的向量表示;函数 Q ϕ ( s , a ) Q_{\phi}(\bm s,\bm a) Qϕ(s,a)通常是一个参数为 ϕ \phi ϕ的函数,比如神经网络,输出一个实数,称为Q网络。
如果动作为有限离散的 M M M个动作 a 1 , . . . , a M a_1,...,a_M a1,...,aM,我们可以让Q网络输出一个 M M M维向量,其中第 m m m维表示 Q ϕ ( s , a m ) Q_{\phi}(\bm s,\bm a_m) Qϕ(s,am),对应值函数 Q π ( s , a m ) Q^{\pi}(s,a_m) Qπ(s,am)的近似值。
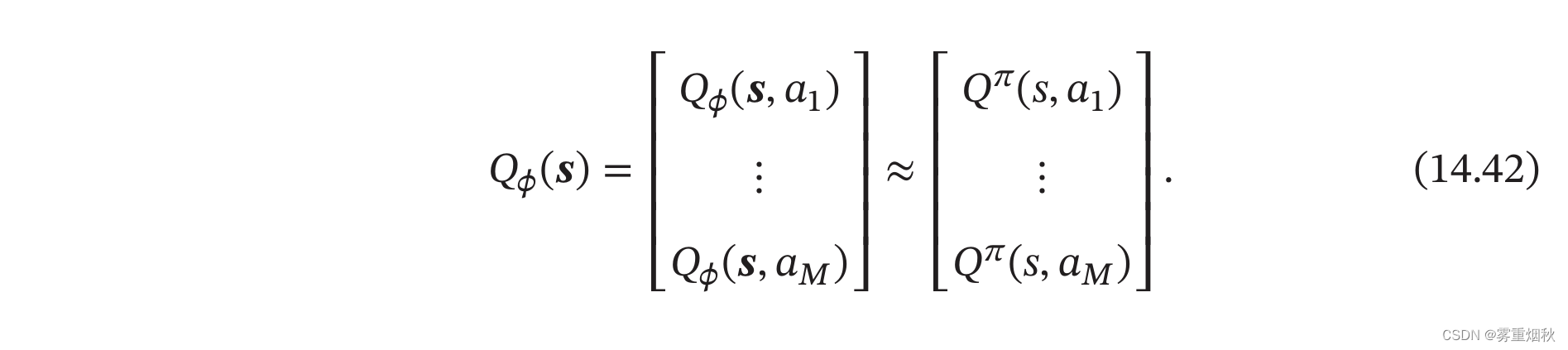
我们需要学习一个参数 ϕ \phi ϕ来使得函数 Q ϕ ( s , a m ) Q_{\phi}(\bm s,\bm a_m) Qϕ(s,am)可以逼近值函数 Q π ( s , a m ) Q^{\pi}(s,a_m) Qπ(s,am)。如果采用蒙特卡罗方法,就直接让 Q ϕ ( s , a m ) Q_{\phi}(\bm s,\bm a_m) Qϕ(s,am)去逼近平均的总回报 Q ^ π ( s , a m ) \hat{Q}^{\pi}(s,a_m) Q^π(s,am);如果采用时序差分学习方法,就让 Q ϕ ( s , a m ) Q_{\phi}(\bm s,\bm a_m) Qϕ(s,am)去逼近 E s ′ , a ′ [ r + γ Q ϕ ( s ′ , a ′ ) ] \mathbb{E}_{\boldsymbol{s}^{\prime}, \boldsymbol{a}^{\prime}}\left[r+\gamma Q_\phi\left(\boldsymbol{s}^{\prime}, \boldsymbol{a}^{\prime}\right)\right] Es′,a′[r+γQϕ(s′,a′)]。
以Q学习为例,采用随机梯度下降,目标函数为
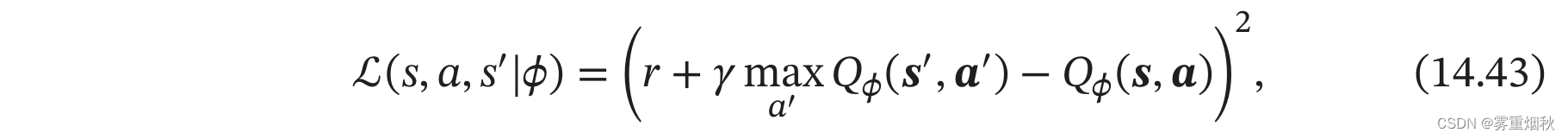
然而,这个目标函数存在两个问题:一是目标不稳定,参数学习的目标依赖于参数本身;二是样本之间有很强的相关性。为了解决这两个问题,[Mnih et all., 2015]提出了一种深度Q网络(Deep Q-Networks,DQN)。深度Q网络采取两个措施:一是目标网络冻结(Freezing Target Networks),即在一个时间段内固定目标中的参数,来稳定学习目标;二是经验回放(Experience Replay),即构建一个经验池(Replay Buffer)来去除数据相关性。经验池是由智能体最近的经历组成的数据集。
训练时,随机从经验池中抽取样本来代替当前的样本用来进行训练。这样,就打破了和相邻训练样本之间的相似性,避免模型陷入局部最优。经验回放在一定程度上类似于监督学习。先收集样本,然后再这些样本上进行训练,深度Q网络的学习过程如算法14.5所示。

整体上,在基于值函数的学习方法中,策略一般为确定性策略。策略优化通常都依赖于值函数,比如贪心策略 π ( s ) = a r g m a x a Q ( s , a ) \pi(s)=argmax_aQ(s,a) π(s)=argmaxaQ(s,a)。最优策略一般需要遍历当前状态 s s s下的所有动作,并找出最优的 Q ( s , a ) Q(s,a) Q(s,a)。当动作空间离散但是很大时,遍历求最大需要很高的时间复杂度;当动作空间是连续的并且 Q ( s , a ) Q(s,a) Q(s,a)非凸时,也很难求解出最佳的策略。
基于策略函数的学习方法
强化学习的目标是学习到一个策略 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s)来最大化期望回报。一种直接的方法是在策略空间直接搜索来得到最佳策略,称为策略搜索,策略搜索本质是一个优化问题,可以分为基于梯度的优化和无梯度优化。策略搜索和基于值函数的方法相比,策略搜索可以不需要值函数,直接优化策略。参数化的策略能够处理连续状态和动作,可以直接学出随机性策略。
策略梯度(Policy Gradient)是一种基于梯度的强化学习方法。假设 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s)是一个关于 θ \theta θ的连续可微函数,我们可以用梯度上升的方法来优化参数 θ \theta θ使得目标函数 J ( θ ) J(\theta) J(θ)最大。



REINFORCE算法
公式(14.54)中,期望可以通过采样方法来近似。根据当前策略 π θ \pi_{\theta} πθ,通过随机游走的方式来采集多个轨迹 τ ( 1 ) , τ ( 2 ) , . . . , τ ( N ) \tau^{(1)},\tau^{(2)},...,\tau^{(N)} τ(1),τ(2),...,τ(N),其中每一条轨迹 τ ( n ) = s 0 ( n ) , a 0 ( n ) , s 1 ( n ) , a 1 ( n ) , . . . \tau^{(n)}={s_0}^{(n)},{a_0}^{(n)},{s_1}^{(n)},{a_1}^{(n)},... τ(n)=s0(n),a0(n),s1(n),a1(n),...。这样。策略梯度 ∂ J ( θ ) ∂ θ \frac{\partial J(\theta)}{\partial \theta} ∂θ∂J(θ)可以写为
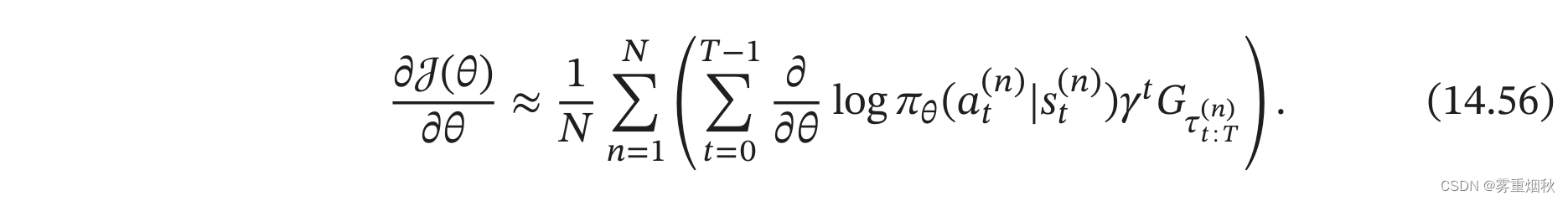
结合随机梯度上升算法,我们可以每次采集一条轨迹,计算每个时刻的梯度并更新参数,这称为REINFORCE算法,如算法14.6所示。

带基准线的REINFORCE算法
REINFORCE算法的一个主要缺点是不同路径之间的方差很大,导致训练不稳定,这是在高维空间中使用蒙特卡罗方法的通病。一种减少方差的通用方法是引入一个控制变量。假设要估计函数 f f f的期望,为了减少 f f f的方差,我们引入一个已知期望的函数 g g g,令




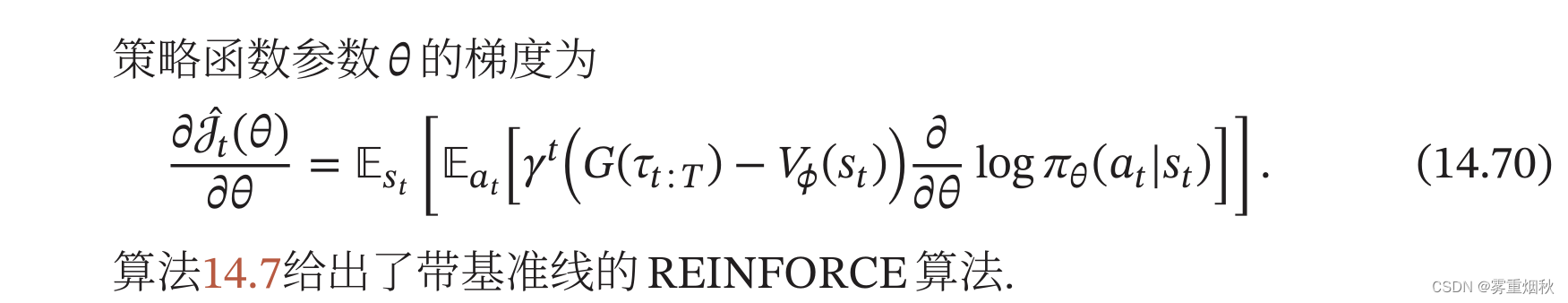

演员-评论员算法
在REINFORCE算法中,每次需要根据一个策略采集一条完整的轨迹,并计算这条轨迹上的回报。这种采样方式方差比较大,学习效率也比较低。我们可以借鉴时序差分学习的思想,是用动态规划方法来提高采样的效率,即从状态 s s s开始的总回报可以通过当前动作的即时奖励 r ( s , a , s ′ ) r(s,a,s') r(s,a,s′)和下一个状态 s ′ s' s′的值函数来近似估计。
演员-评论员算法(Actor-Critic Algorithm)是一种结合策略梯度和时序差分学习的强化学习方法。其中演员是指策略函数 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s),即学习一个策略来得到尽量高的回报,评论员是指值函数 V ϕ ( s ) V_{\phi}(s) Vϕ(s),对当前策略的值函数进行估计,即评估演员的好坏。借助于值函数,演员-评论员算法可以进行单步更新参数,不需要等到回合结束才进行更新。


在每步更新中,演员根据当前的环境状态 s s s和策略 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s)去执行动作 a a a,环境状态变为 s ′ s' s′,并得到即时奖励 r r r。评论员根据环境给出的真实奖励和之前标准下的打分 ( r + γ V ϕ ( s ′ ) ) (r+\gamma V_{\phi}(s')) (r+γVϕ(s′)),来调整自己的打分标准,使得自己的评分更接近环境的真实回报。演员则根据评论员的打分,调整自己的策略 π θ \pi_{\theta} πθ,争取下次做得更好。开始训练时,演员随机表演,评论员随机打分。通过不断地学习,评论员的评分越来越准,演员的动作越来越好。
算法14.8给出了演员-评论员算法的训练过程

虽然带基准线的REINFORCE算法也同时学习策略函数和值函数,但是它并不是一种演员-评论员算法,因为其中值函数只是用作基线函数以减少方差,并不用来估计回报(即评论员的角色)。
总结和深入阅读
强化学习是一种十分吸引人的机器学习方法,通过智能体不断与环境进行交互,并根据经验调整其策略来最大化其长远的所有奖励的累积值。相比其他机器学习方法,强化学习更接近生物学习的本质,可以应对多种复杂的场景,从而更接近通用人工智能系统的目标。
强化学习和监督学习的区别在于:1)强化学习的样本通过不断与环境进行交互产生,即试错学习,而监督学习的样本由人工收集并标注;2)强化学习的反馈信息只有奖励,而且是延迟的,而监督学习需要明确的指导信息(每一个状态对应的动作)。
现代强化学习可以追溯到两个来源:一个是心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为;另一个是控制论领域的最优控制问题,即在满足一定约束条件下,寻求最优控制策略,使得性能指标取极大值或极小值。
强化学习的算法非常多,大体上可以分为基于值函数的方法(包括动态规划、时序差分学习等)、基于策略函数的方法(包括策略梯度等)以及融合两者的方法,不同算法之间的关系如图14.4所示:
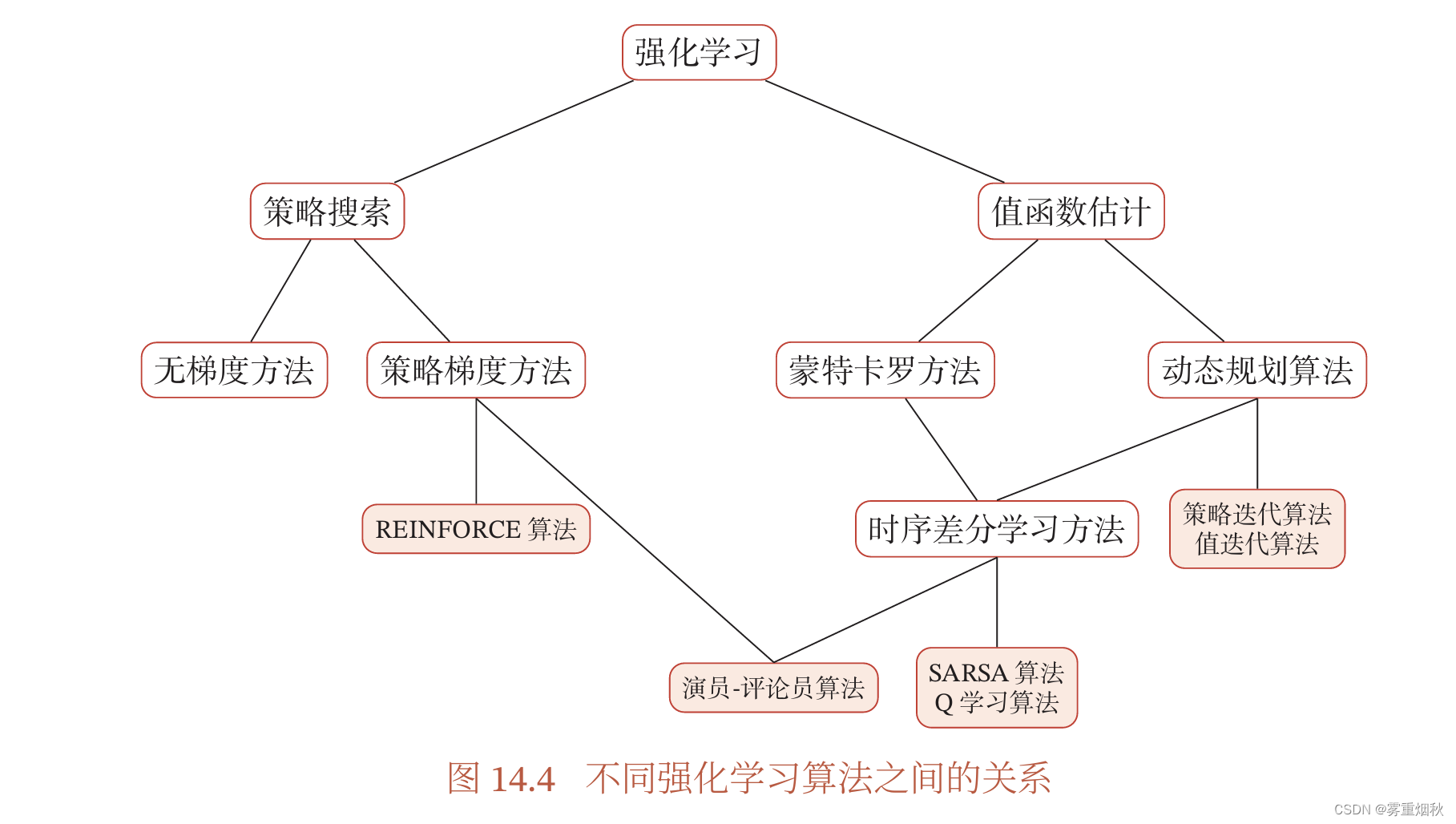
一般而言,基于值函数的方法在策略更新时可能会导致值函数的改变比较大,对收敛性有一定影响,而基于策略函数的方法在策略更新时更加平稳。但后者因为策略函数的解空间比较大,难以进行充分的采样,导致方差较大,并容易收敛到局部最优解。演员-评论员算法通过融合两种方法,取长补短,有着更好的收敛性。
这些不同的强化学习算法的优化步骤都可以分为3步:1)执行策略,生成样本;2)估计回报;3)更新策略。表14.1给出了4种典型的强化学习算法优化步骤的比较。





相关文章:
神经网络与深度学习——第14章 深度强化学习
本文讨论的内容参考自《神经网络与深度学习》https://nndl.github.io/ 第14章 深度强化学习 深度强化学习 强化学习(Reinforcement Learning,RL),也叫增强学习,是指一类从与环境交互中不断学习的问题以及解决这类问题…...

centOS 编译C/C++
安装C和C编译器 yum -y install gcc*查看CenterOS系统信息 cat /etc/system-releaseCentOS Linux release 8.2.2004 (Core)查看gcc版本 gcc --versiongcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-4) Copyright (C) 2018 Free Software Foundation, Inc. This is free software…...

java——网络原理初识
T04BF 👋专栏: 算法|JAVA|MySQL|C语言 🫵 小比特 大梦想 目录 1.网络通信概念初识1.1 IP地址1.2端口号1.3协议1.3.1协议分层协议分层带来的好处主要有两个方面 1.3.2 TCP/IP五层 (或四层模型)1.3.3 协议的层和层之间是怎么配合工作的 1.网络通信概念初识…...

js怎么判断是否为手机号?js格式校验方法
数据格式正确与否是表单填写不可避免的一个流程,现整理一些较为常用的信息格式校验方法。 判断是否为手机号码 // 判断是否为手机号码 function isPhoneNumber(phone) {return /^[1]\d{10}$/.test(phone) }判断是否为移动手机号 function isChinaMobilePhone(phon…...

深入理解Java中的方法重载:让代码更灵活的秘籍
关注微信公众号 “程序员小胖” 每日技术干货,第一时间送达! 引言 在Java编程的世界里,重载(Overloading)是一项基础而强大的特性,它让我们的代码更加灵活、可读性强。对于追求高效、优雅编码的开发者而言,掌握方法重…...

鸿蒙ArkTS声明式开发:跨平台支持列表【显隐控制】 通用属性
显隐控制 控制组件是否可见。 说明: 开发前请熟悉鸿蒙开发指导文档: gitee.com/li-shizhen-skin/harmony-os/blob/master/README.md点击或者复制转到。 从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本…...

每日一题——Java编程练习题
题目: 键盘录入两个数字number1和number2表示一个范围,求这个范围之内的数字和。 我写的代码: public class Test {public static void main(String[] args) {Scanner sc new Scanner(System.in);System.out.print("输入第一个数:&q…...

java编辑器中如何调试程序?
目录 如何调试java程序? 待续、更新中 如何调试java程序? 1 看错误信息 2 相应位置输入输出信息: System.out.println("测试信息1 "); 以此查看哪条语句未进行输入 待续、更新中 1 顿号、: 先使用ctrl. ,再使用一遍切回 2 下标: 21 2~1~ 3 上标: 2…...

第四范式Q1业务进展:驰而不息 用科技锻造不朽价值
5月28日,第四范式发布今年前三个月的核心业务进展,公司坚持科技创新,业务稳步拓展,用人工智能为千行万业贡献价值。 今年前三个月,公司总收入人民币8.3亿元,同比增长28.5%,毛利润人民币3.4亿元&…...

SpringBoot整合Kafka的快速使用教程
目录 一、引入Kafka的依赖 二、配置Kafka 三、创建主题 1、自动创建(不推荐) 2、手动动创建 四、生产者代码 五、消费者代码 六、常用的KafKa的命令 Kafka是一个高性能、分布式的消息发布-订阅系统,被广泛应用于大数据处理、实时日志分析等场景。Spring B…...
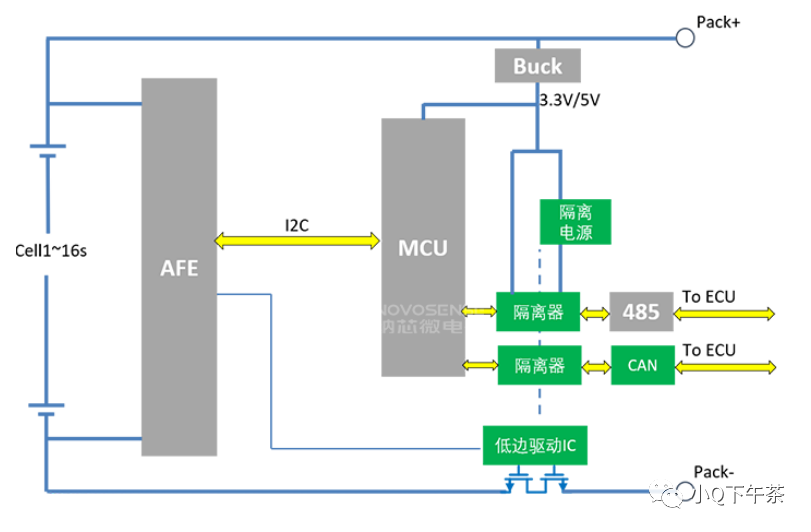
低边驱动与高边驱动
一.高边驱动和低边驱动 低边驱动(LSD): 在电路的接地端加了一个可控开关,低边驱动就是通过闭合地线来控制这个开关的开关。容易实现(电路也比较简单,一般由MOS管加几个电阻、电容)、适用电路简化和成本控制的情况。 高边驱动&am…...
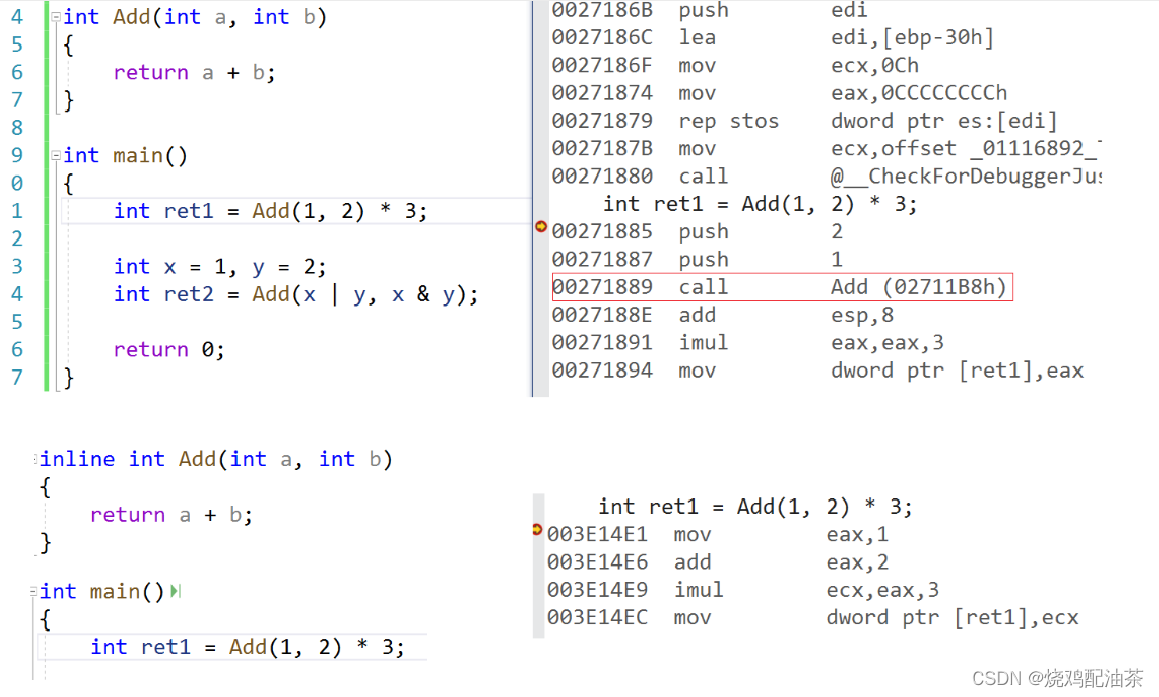
【C++】入门(二):引用、内联、auto
书接上回:【C】入门(一):命名空间、缺省参数、函数重载 文章目录 六、引用引用的概念引用的使用场景1. 引用做参数作用1:输出型参数作用2:对象比较大,减少拷贝,提高效率 2. 引用作为…...
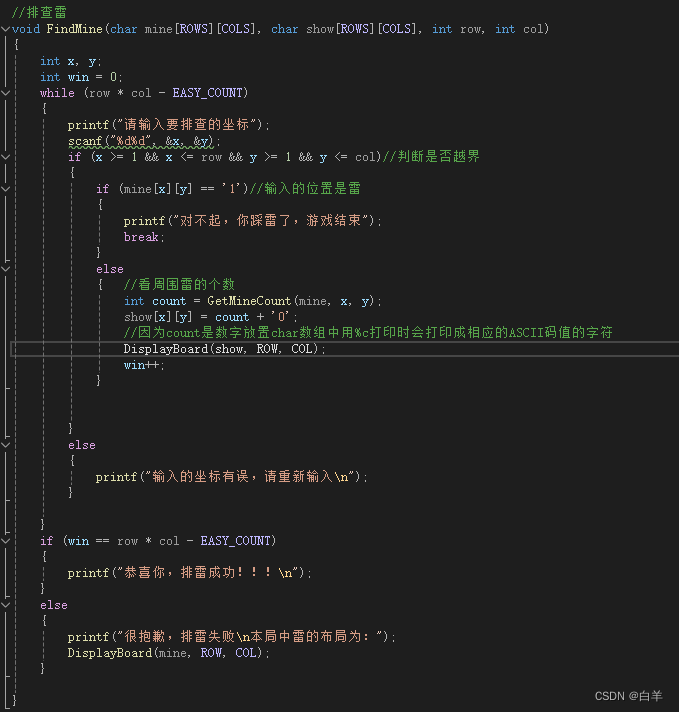
编程学习 (C规划) 6 {24_4_18} 七 ( 简单扫雷游戏)
首先我们要清楚扫雷大概是如何实现的: 1.布置雷 2.扫雷(排查雷) (1)如果这个位置是雷就炸了,游戏结束 (2)如果不是雷,就告诉周围有几个雷 3.把所有不是雷的位置都找…...
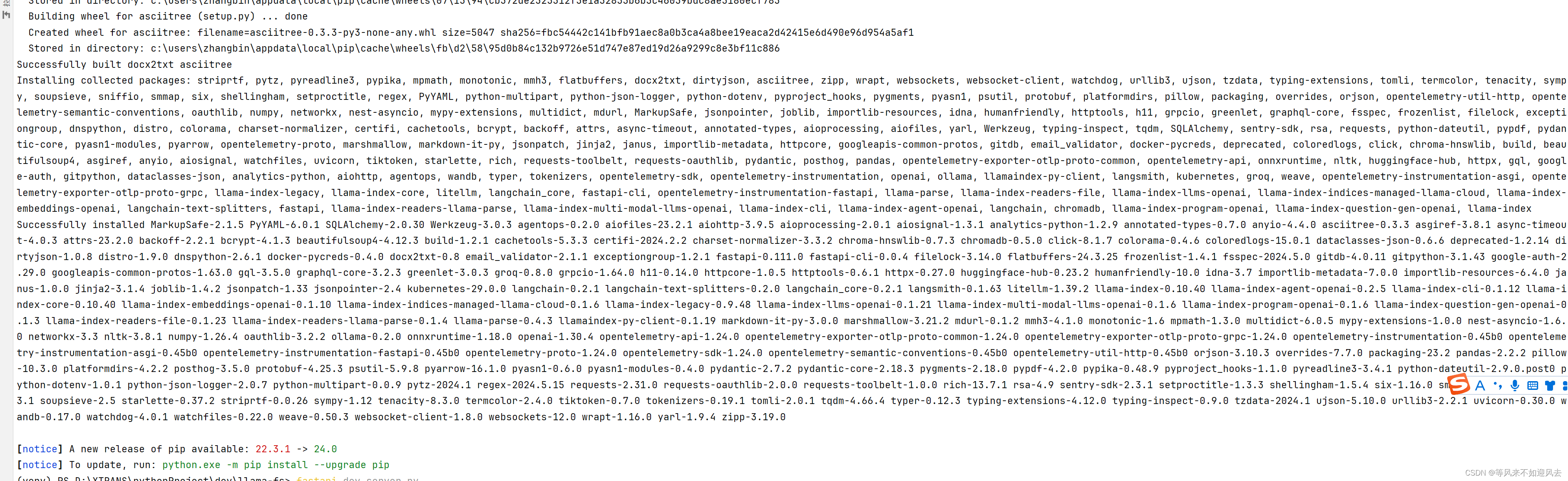
【AI】llama-fs的 安装与运行
pip install -r .\requirements.txt Windows PowerShell Copyright (C) Microsoft Corporation. All rights reserved.Install the latest PowerShell for new features and improvements! https://aka.ms/PSWindows(venv) PS D:\XTRANS\pythonProject>...
内存监控)
Android NDK系列(五)内存监控
在日常的开发中,内存泄漏是一种比较比较棘手的问题,这是由于其具有隐蔽性,即使发生了泄漏,很难检测到并且不好定位到哪里导致的泄漏。如果程序在运行的过程中不断出现内存泄漏,那么越来越多的内存得不到释放࿰…...

软件设计师,下午题 ——试题六
模型图 简单工厂模式 工厂方法模式抽象工厂模式生成器模式原型模式适配器模式桥接模式组合模式装饰(器)模式亨元模式命令模式观察者模式状态模式策略模式访问者模式中介者模式 简单工厂模式 工厂方法模式 抽象工厂模式 生成器模式 原型模式 适配器模式 桥…...

《Kubernetes部署篇:基于麒麟V10+ARM64架构部署harbor v2.4.0镜像仓库》
总结:整理不易,如果对你有帮助,可否点赞关注一下? 更多详细内容请参考:企业级K8s集群运维实战 一、环境信息 K8S版本 操作系统 CPU架构 服务版本 1.26.15 Kylin Linux Advanced Server V10 ARM64 harbor v2.4.0 二、部…...
远程工作/线上兼职网站整理(数字游民友好)
文章目录 国外线上兼职网站fiverrupwork 国内线上兼职网站甜薪工场猪八戒网云队友 国外线上兼职网站 fiverr https://www.fiverr.com/start_selling?sourcetop_nav upwork https://www.upwork.com/ 国内线上兼职网站 甜薪工场 https://www.txgc.com/ 猪八戒网 云队友 …...
elasticsearch7.15实现用户输入自动补全
Elasticsearch Completion Suggester(补全建议) Elasticsearch7.15安装 官方文档 补全建议器提供了根据输入自动补全/搜索的功能。这是一个导航功能,引导用户在输入时找到相关结果,提高搜索精度。 理想情况下,自动补…...

掌握正则表达式的力量:全方位解析PCRE的基础与进阶技能
Perl 兼容正则表达式(PCRE)是 Perl scripting language 中所使用的正则表达式语法标准。这些正则表达式在 Linux 命令行工具(如 grep -P)及其他编程语言和工具中也有广泛应用。以下是一些基础和进阶特性,帮你掌握和使用…...

TPAMI 2026 | 跨十大数据集验证,PoundNet重新审视AI图像检测范式
随着 AI 生成图像技术快速演进,伪造内容在网络传播风险持续上升,高鲁棒性检测技术因此成为学界与产业界关注的关键问题。然而,现有不少方法过于追求单一数据集上的短期收益,往往仅围绕“真/假”二分类目标对大规模预训练模型进行专…...

LabVIEW 2018+ 也能玩转OpenCV了?手把手教你用秣厉科技工具包实现摄像头人脸识别
LabVIEW与OpenCV的跨界融合:零代码实现工业级视觉检测方案 当图形化编程遇上计算机视觉,会碰撞出怎样的火花?对于习惯了LabVIEW数据流编程的工程师来说,OpenCV那些复杂的矩阵运算和算法实现往往令人望而生畏。而现在,…...

5分钟掌握:billd-desk跨平台远程控制高效解决方案
5分钟掌握:billd-desk跨平台远程控制高效解决方案 【免费下载链接】billd-desk 基于Vue3 WebRTC Nodejs Flutter搭建的远程桌面控制 项目地址: https://gitcode.com/gh_mirrors/bi/billd-desk 还在为远程办公的卡顿和限制而烦恼吗?当你急需远程…...

PyTorch 3.0静训性能断崖预警:当AllReduce延迟>8.3ms或图编译耗时>117s时,你的训练任务已在 silently fail——附实时诊断CLI工具
第一章:PyTorch 3.0静态图分布式训练的静默失效危机全景PyTorch 3.0 引入的 TorchScript 静态图编译机制与 torch.distributed 的深度耦合,在多节点多卡场景下暴露出一类高危静默失效现象:训练进程持续运行、梯度同步无报错、loss 曲线看似收…...

TTI-Chicago等机构突破性研究:AI学会了一笔一划创作矢量草图
这项由芝加哥丰田技术研究院(TTI-Chicago)、芝加哥大学和麻省理工学院联合开展的研究发表于2026年,论文编号为arXiv:2603.19500v1。有兴趣深入了解技术细节的读者可以通过该编号查询完整论文。当我们看到一位画家创作时,他们通常不…...

Qwen3-14B芯片设计辅助:Verilog注释生成、RTL代码解释、DFT建议
Qwen3-14B芯片设计辅助:Verilog注释生成、RTL代码解释、DFT建议 1. 镜像概述与硬件适配 Qwen3-14B私有部署镜像是专为芯片设计工程师打造的AI辅助工具,基于通义千问大语言模型优化定制。该镜像完美适配RTX 4090D 24GB显存配置,预装了完整的…...

Blender 3MF插件终极指南:从零开始掌握3D打印文件格式
Blender 3MF插件终极指南:从零开始掌握3D打印文件格式 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 3MF(3D Manufacturing Format)格…...

厦门选117E还是120E?手把手教你为你的城市选择正确的高斯克吕格投影坐标系
厦门GIS项目实战:如何精准选择高斯克吕格投影坐标系 第一次在ArcGIS里看到上百个坐标系选项时,我的鼠标指针在列表上方徘徊了整整十五分钟——就像站在自动售货机前不知道按哪个按钮的新手。特别是当项目 deadline 临近,而厦门市规划局的Shap…...

3个突破性技术,让抖音无水印视频下载效率提升200%
3个突破性技术,让抖音无水印视频下载效率提升200% 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

视频硬字幕提取终极指南:用本地AI工具10倍提升你的字幕制作效率
视频硬字幕提取终极指南:用本地AI工具10倍提升你的字幕制作效率 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测…...