源码分析Spring解决循环依赖的过程
循环依赖是之前很爱问的一个面试题,最近不咋问了,但是梳理Spring解决循环依赖的源码,会让我们对Spring创建bean的流程有一个清晰的认识,有必要搞一搞。开始搞之前,先参考了这个老哥写的文章,对Spring处理循环依赖有了一个基本的认识之后,然后开始进行源码debug,感谢这位老哥的分享:https://developer.aliyun.com/article/766880
我们搞一个简单的例子,先看看什么是循环依赖,我们只讲最简单的这种,set方法循环依赖,除此之外还有构造器循环依赖,我们讲最简单的这种,其实道理是一样的。
搞一个demo
@Data
@Component
public class TestA {@Autowiredprivate TestB testB;public void getA(){System.out.println("我是getA方法");}
}
@Data
@Component
public class TestB {@Autowiredprivate TestA testA;
}
A依赖B,B依赖A。这样就形成了一个简单的循环依赖。众所周知,Spring解决循环依赖的经典方法是三级缓存,当然还有其他的方法也可以处理,比如懒加载。今天我们只聊三级缓存,其他方式,感兴趣的话,可以自己查一些资料。
如果之前看过Spring的代码,我们就知道,Spring在创建bean之前都会先获取bean,如果获取不到,才会创建bean。所以我们从获取bean开始看起。
获取bean的入口在AbstractBeanFactory的doGetBean方法中。第一行代码,我们先看到从缓存获取bean的流程
// Eagerly check singleton cache for manually registered singletons.
Object sharedInstance = getSingleton(beanName);
这个方法里,我们想看的三级缓存就全了
protected Object getSingleton(String beanName, boolean allowEarlyReference) {//先从一级缓存取Object singletonObject = this.singletonObjects.get(beanName);if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {synchronized (this.singletonObjects) {//一级缓存没有,从二级缓存取singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null && allowEarlyReference) {//二级缓存没有,从三级缓存取ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);if (singletonFactory != null) {singletonObject = singletonFactory.getObject();//三级缓存取出来之后放入二级缓存this.earlySingletonObjects.put(beanName, singletonObject);//从三级缓存移除this.singletonFactories.remove(beanName);}}}}return singletonObject;}
刚开始,这三个缓存里,肯定都没有,父容器中也不会有。所以此时,需要创建A。
创建A的流程也在doGetBean方法里,我们向下看,有这样一段逻辑
// Create bean instance.
if (mbd.isSingleton()) {sharedInstance = getSingleton(beanName, () -> {try {return createBean(beanName, mbd, args);}catch (BeansException ex) {}});
}
createBean就是创建一个bean,但是这个createBean的过程是getSingleton方法的一个参数,是一个工厂方法,也就是说先执行getSingleton方法,某一个时机下,再触发工厂方法,我们看一下getSingleton的逻辑,我去掉了无关代码。先从一级缓存中获取,如果没有获取到,会触发createBean工厂方法的执行
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {synchronized (this.singletonObjects) {//从一级缓存中获取Object singletonObject = this.singletonObjects.get(beanName);if (singletonObject == null) {//一级缓存不存在,执行工厂方法创建beansingletonObject = singletonFactory.getObject();newSingleton = true;//bean创建成功,放入一级缓存if (newSingleton) {addSingleton(beanName, singletonObject);}}return singletonObject;}}//将创建完成的对象放入一级缓存中,也就是单例池中protected void addSingleton(String beanName, Object singletonObject) {synchronized (this.singletonObjects) {this.singletonObjects.put(beanName, singletonObject);this.singletonFactories.remove(beanName);this.earlySingletonObjects.remove(beanName);this.registeredSingletons.add(beanName);}}
从上面的逻辑,我们可以得到一个结论,一级缓存的bean已经是创建完成的bean,可以对外提供服务。
接下来,我们继续看工厂方法createBean的流程,创建bean的流程在AbstractAutowireCapableBeanFactory的doCreateBean方法中,我去掉了无关逻辑。
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)throws BeanCreationException {//初始化bean,相当于new对象操作if (instanceWrapper == null) {instanceWrapper = createBeanInstance(beanName, mbd, args);}boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&isSingletonCurrentlyInCreation(beanName));//Spring解决循环依赖的核心逻辑if (earlySingletonExposure) {if (logger.isTraceEnabled()) {logger.trace("Eagerly caching bean '" + beanName +"' to allow for resolving potential circular references");}//放入三级缓存addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));}// Initialize the bean instance.Object exposedObject = bean;//对当前bean进行依赖注入populateBean(beanName, mbd, instanceWrapper);//初始化bean,执行bean的一些初始化方法,比如各种aware、实现各种接口啥的。这个流程也有一个经典的面试题,bean的生命周期exposedObject = initializeBean(beanName, exposedObject, mbd);return exposedObject;}
上面就是创建A的具体逻辑,我们画个图梳理一下
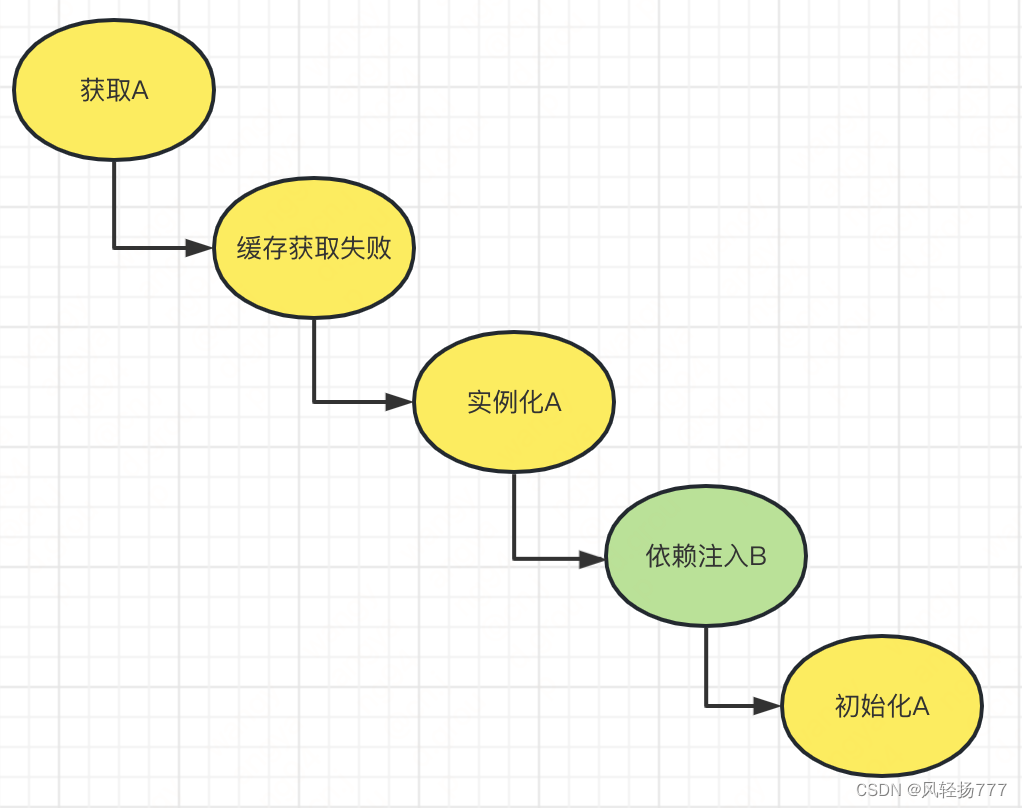
创建A的流程中可以看到,在实例化A之后,就执行了放入三级缓存的动作。只要你没有禁止循环依赖,刚实例化的bean就会放入三级缓存。
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {Assert.notNull(singletonFactory, "Singleton factory must not be null");synchronized (this.singletonObjects) {if (!this.singletonObjects.containsKey(beanName)) {this.singletonFactories.put(beanName, singletonFactory);this.earlySingletonObjects.remove(beanName);this.registeredSingletons.add(beanName);}}}
添加进三级缓存的是一个lambda表达式,() -> getEarlyBeanReference(beanName, mbd, bean),我们经常叫做工厂,那这个工厂方法又是什么时候触发呢?先按下不表,我们继续往下看,A进入三级缓存后,逻辑紧接着就要对A进行依赖注入,A需要依赖注入B,此时要去容器中获取B,获取B的流程和获取A的流程是一样的,获取入口也是AbstractBeanFactory的doGetBean方法,和获取A一样,也执行一遍三级缓存的获取操作,就是getSingleton方法。当然也是没有,所以需要创建B。
创建B的过程和创建A的过程一样。
实例化—>依赖注入—>初始化
我们把B的创建流程也画一下
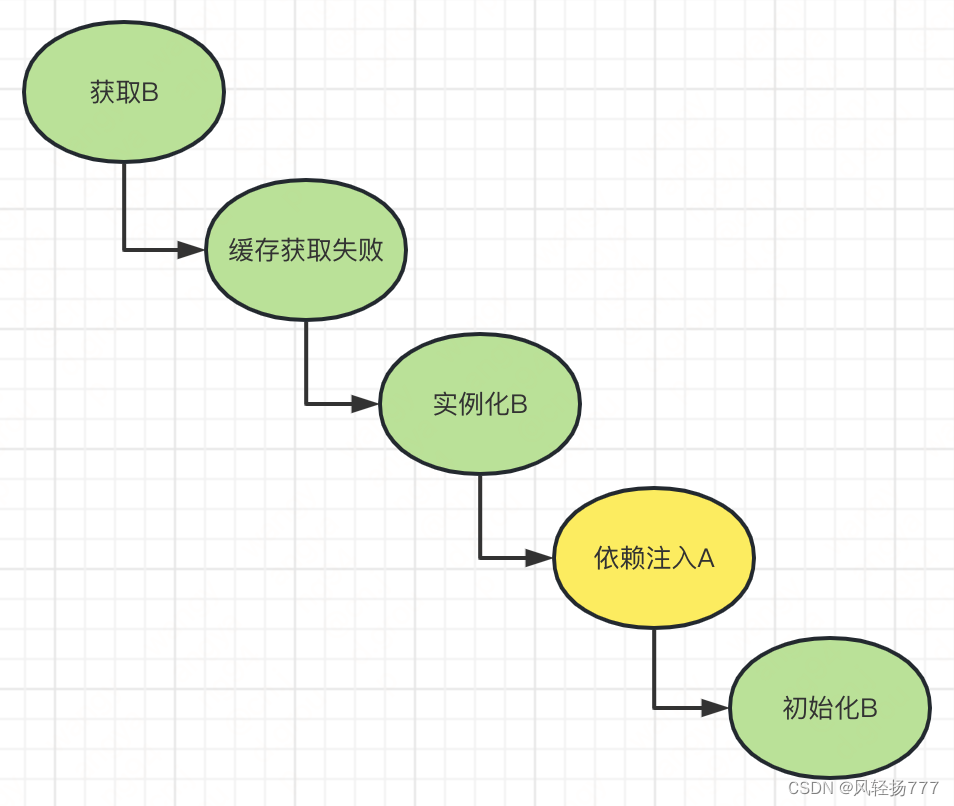
B的依赖注入,需要注入A,我们需要先获取A,此时就又会走到AbstractBeanFactory的doGetBean的逻辑中。又会执行getSingleton逻辑。
protected Object getSingleton(String beanName, boolean allowEarlyReference) {//先从一级缓存取Object singletonObject = this.singletonObjects.get(beanName);if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {synchronized (this.singletonObjects) {//一级缓存没有,从二级缓存取singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null && allowEarlyReference) {//二级缓存没有,从三级缓存取ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);if (singletonFactory != null) {singletonObject = singletonFactory.getObject();//三级缓存取出来之后放入二级缓存this.earlySingletonObjects.put(beanName, singletonObject);//从三级缓存移除this.singletonFactories.remove(beanName);}}}}return singletonObject;}
一级缓存还是没有,二级缓存也没有,但是三级,此时就有了,因为我们创建A的过程中,已经把A先放入了三级缓存。此时从三级缓存中获取出来的工厂方法 “() -> getEarlyBeanReference(beanName, mbd, bean)” 就会触发,拿到A,然后将A放入二级缓存。我们看下这个工厂方法的逻辑里都干了啥
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {Object exposedObject = bean;if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {for (BeanPostProcessor bp : getBeanPostProcessors()) {if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);}}}return exposedObject;}
以上代码等价于
Object exposedObject = bean;
exposedObject = beanPostProcessor.getEarlyBeanReference(exposedObject, beanName);
return exposedObject;
processor虽然是一个集合,但是真正起作用的processor只有一个,就是AnnotationAwareAspectJAutoProxyCreator,它是通过@EnableAspectJAutoProxy注解导入到bean容器中的,从名字也能看到它是处理AOP的。我们看看这个processor的处理逻辑
@Overridepublic Object getEarlyBeanReference(Object bean, String beanName) {Object cacheKey = getCacheKey(bean.getClass(), beanName);this.earlyProxyReferences.put(cacheKey, bean);//获取AOP代理对象return wrapIfNecessary(bean, beanName, cacheKey);}
实际上就是AOP代理的增强过程
但是,我们的业务代码,不一定都会用到AOP吧。那如果不用AOP的话,容器中就不会有AnnotationAwareAspectJAutoProxyCreator对象,那getEarlyBeanReference方法就可以简化为:
Object exposedObject = bean;
return exposedObject;
相当于工厂方法啥也没干。所以这就是为啥Spring放入三级缓存的是一个工厂方法,而不是立即获取代理对象放入三级缓存,因为在创建A的过程中,并不一定存在循环依赖,如果没有循环依赖,Spring处理AOP增强的逻辑统一在bean创建流程的末尾,就是initializeBean方法中
//对当前bean进行依赖注入populateBean(beanName, mbd, instanceWrapper);//初始化bean,执行bean的一些初始化方法,比如各种aware、实现各种接口啥的。这个流程也有一个经典的面试题,bean的生命周期exposedObject = initializeBean(beanName, exposedObject, mbd);
就是因为Spring也不确认依赖注入过程中是否会有循环依赖,它没办法,只能先暴露一个工厂方法,等到循环依赖真正产生的时候,再执行工厂方法,相当于把AOP增强过程延迟了。
至此,我们小结一下,我们完善一下创建A的流程
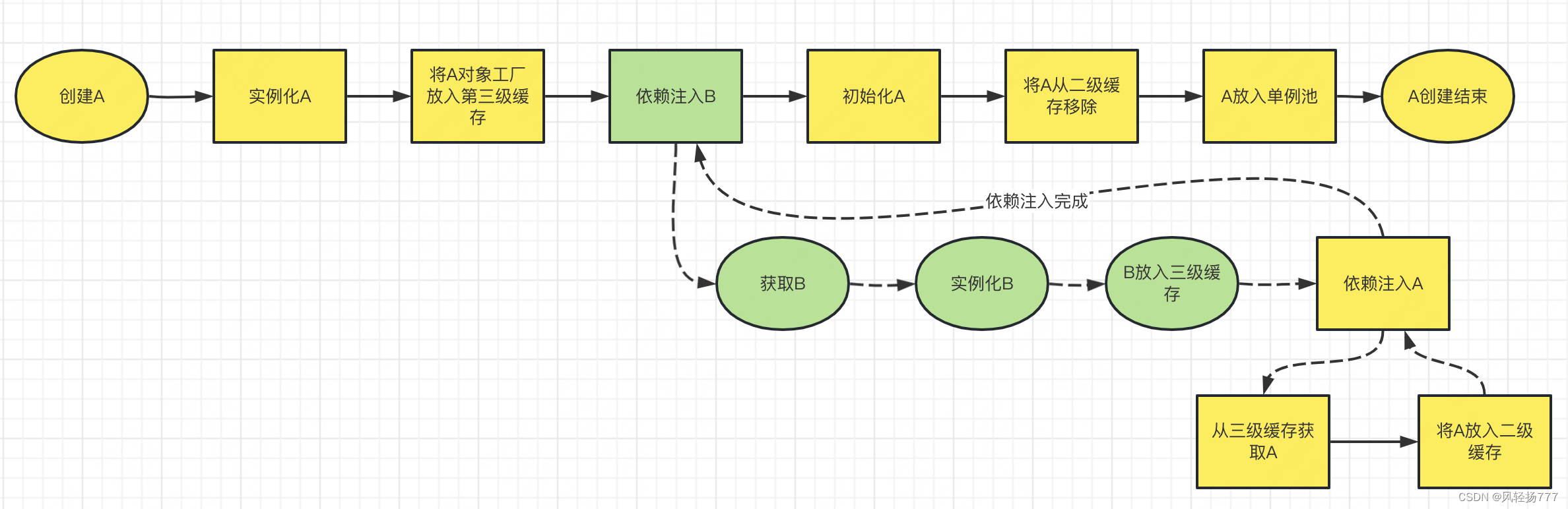
此时,我们就拿到了A,虽然不完美,但是已经可以让B的创建流程继续往下走,B创建完成后,将B放入单例池。然后,继续创建A。A完成,放入单例池,结束。Spring的循环依赖就是这样解决的。
下面,我们说2个经典的面试题
1、为什么需要三级缓存,二级缓存可以吗?
不但不可以,而且可能会破坏Spring的整体设计。我们说2种情况。
A是一个AOP对象,对A进行依赖注入前,Spring也不知道会不会存在循环依赖,只能先把A进行AOP增强,放入二级缓存,这样做明显是不合理的,如果后面不存在循环依赖,我们提前搞了一个代理对象,就做了无用功,并且也破坏了Spring的整体设计,因为Spring会在bean创建的末尾统一进行AOP增强,提前搞没有任何意义。有的同学会说,工厂方法确实有必要存在,那二级缓存有必要吗?我只保留一级和三级,不要二级可以吗?那就是下面这道面试题了。
2、只有一级和三级,没有二级可以吗?
猛地一看,二级缓存确实啥也没干,就是存取对象,真实的情况是这样吗?肯定不是的。抛开代码不说,就凭Spring的使用范围如此之广,不可能出现一段无用代码。那二级缓存的作用是什么呢?我举一个例子,你马上就明白了。下面这种场景,二级缓存必须得有。
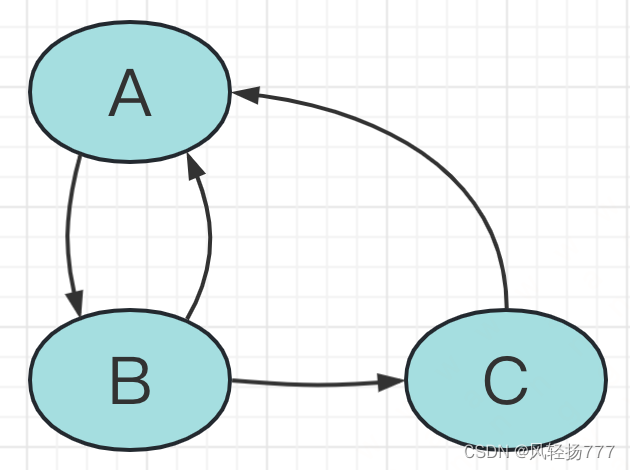
A依赖B,B依赖A(三级缓存中获取A,将A加入二级缓存),B依赖C,C依赖A(二级缓存中获取A),如果没有二级缓存,那我们需要执行两次A的三级缓存工厂方法,如果依赖关系更复杂,可能需要执行多次工厂方法,显然是不合理的,所以Spring的二级缓存很重要。
我们画一下以上循环依赖的处理过程
我标注了序号,你可以按照序号来看一下整个过程,然后自己debug一遍代码,对二级缓存存在的必要会有一个更清洗的认识
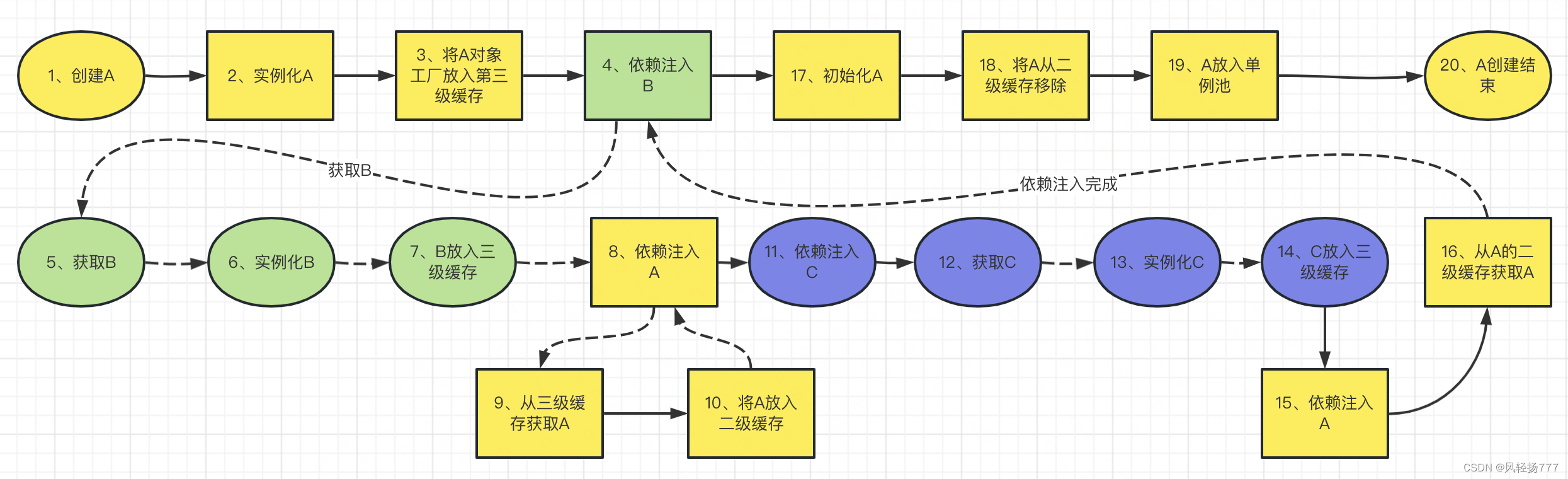
我们总结一下Spring三级缓存的作用。
第一级缓存:存放完整的bean对象,这里面的bean已经可以对外提供服务
第二级缓存:已经进行了实例化,但是未完成依赖注入和初始化的对象
第三级缓存:存放工厂方法。提前暴露的一个对象,Spring解决循环依赖的核心所在
相关文章:
源码分析Spring解决循环依赖的过程
循环依赖是之前很爱问的一个面试题,最近不咋问了,但是梳理Spring解决循环依赖的源码,会让我们对Spring创建bean的流程有一个清晰的认识,有必要搞一搞。开始搞之前,先参考了这个老哥写的文章,对Spring处理循…...
LabVIEW中加载.NET 2.0,3.0和3.5程序集
LabVIEW中加载.NET 2.0,3.0和3.5程序集已使用.NETFramework 2.0,3.0或3.5创建了.NET程序集,但是当尝试在构造函数节点中加载这些程序集时,却收到LabVIEW消息显示: 所选文件不是.NET程序集,所属类型库或自动化可执行文件。所以想确认是否可以在…...

Fluent Python 笔记 第 2 章 序列构成的数组
2.1 内置类型序列概览 容器序列(能存放不同类型的数据):(作者分的类) list、tuple 和 collections.deque扁平序列(只能容纳一种类型): str、byes、bytearray、memoryview 和 array.array可变:…...

句子扩充法
人,物,时,地,事 什么人和什么物在什么时间什么地点发生了什么事。 思维导图:以人为中心,人具有客观能动性。 例如:秋燕南飞。 扩展为: 盘旋在洞庭湖上方的大雁渐渐消失了。“它们都…...

Java并发编程概述
在学习并发编程之前,我们需要稍微回顾以下线程相关知识:线程基本概念程序:静态的代码,存储在硬盘中进程:运行中的程序,被加载在内存中,是操作系统分配内存的基本单位线程:是cpu执行的…...
Java常见数据结构的排序与遍历(包括数组,List,Map)
数组遍历与排序 数组定义 //定义 int a[] new int[5]int[] a new int[5];//带初始值定义 int b[] {1,2,3,4,5};赋值 //定义时赋值 int b[] {1,2,3,4,5};//引用赋值 a[6] 1 a[9] 9 //未赋值为空取值 //通过下表取值,从0开始 b[1] 1 b[2] 2遍历 Test p…...
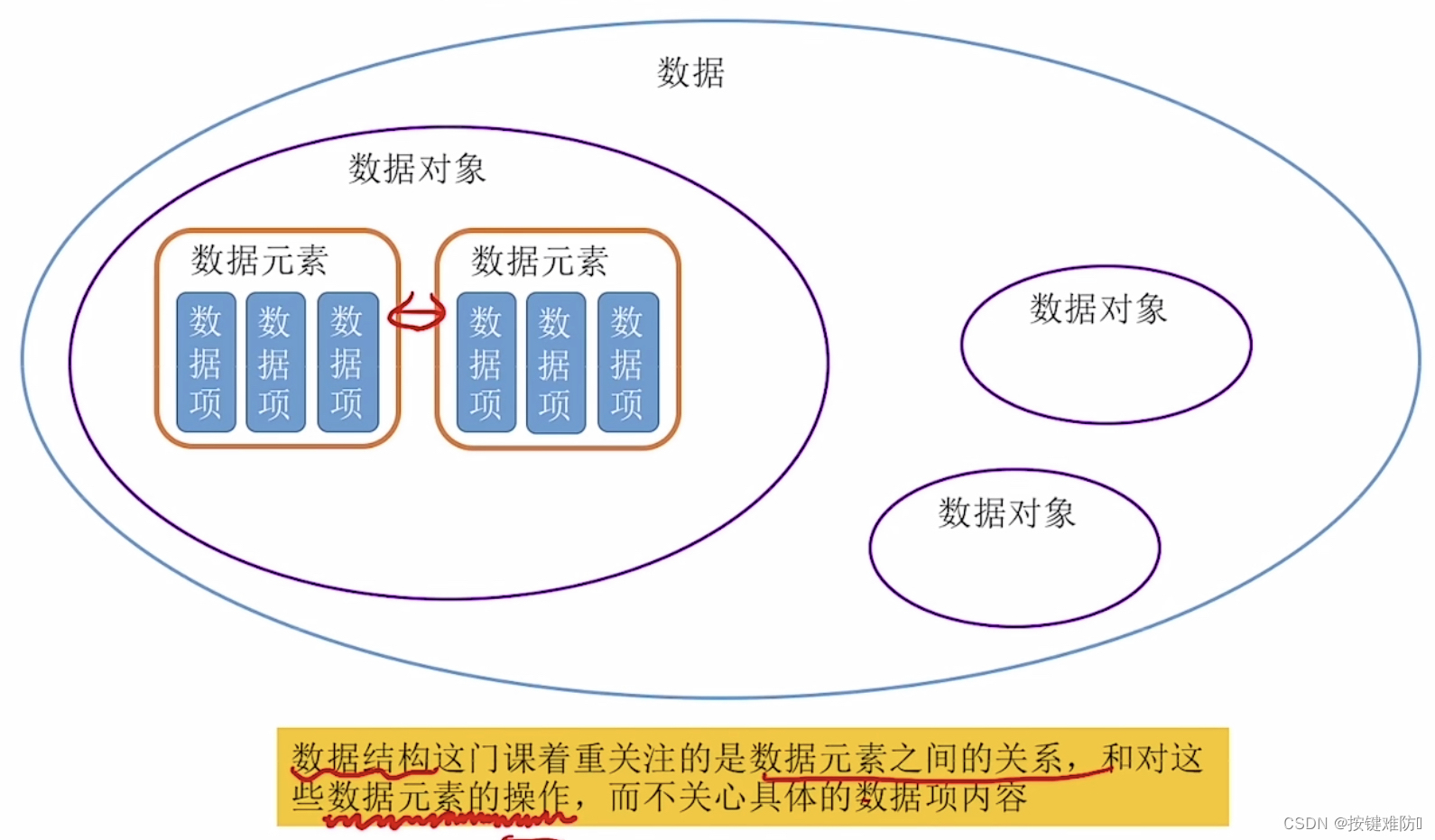
数据结构|绪论
🔥Go for it!🔥 📝个人主页:按键难防 📫 如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀 📖系列专栏:数据结构与算法 ὒ…...
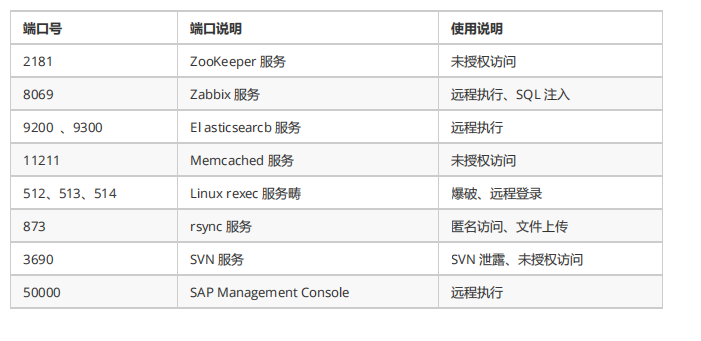
内网渗透(十二)之内网信息收集-内网端口扫描和发现
系列文章第一章节之基础知识篇 内网渗透(一)之基础知识-内网渗透介绍和概述 内网渗透(二)之基础知识-工作组介绍 内网渗透(三)之基础知识-域环境的介绍和优点 内网渗透(四)之基础知识-搭建域环境 内网渗透(五)之基础知识-Active Directory活动目录介绍和使用 内网渗透(六)之基…...
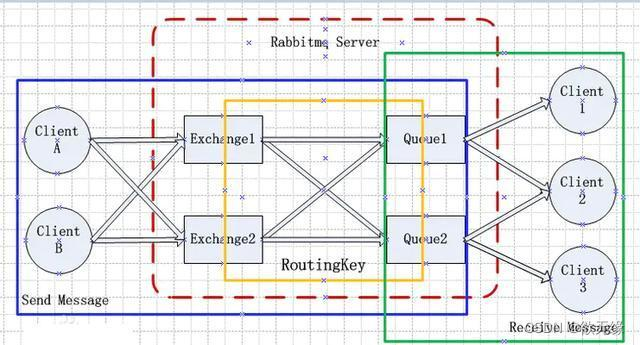
RabbitMq相关面试题
文章目录消息队列有没有接触过? 简单介绍一下?消息中间件模式分类 ?使用MQ有什么好处?MQ如何选型 ?你们项目中用到过 MQ 吗?谈谈你对 MQ 的理解?MQ消费者消费消息的顺序一致性问题?R…...
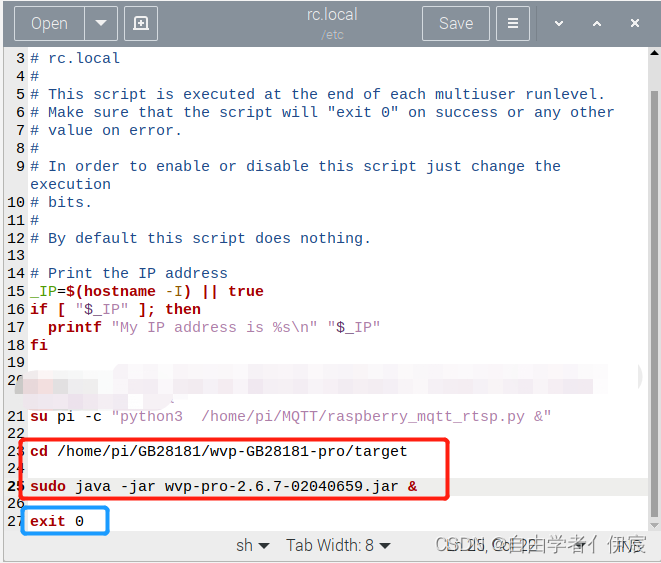
树莓派开机自启动Python脚本或者应用程序
树莓派开机自启动Python脚本或者应用程序前言一、对于Python脚本的自启动方法1、打开etc/rc.local文件2、编辑输入需要启动的指令3、重启树莓派验证二、对于需要读写配置文件的应用程序的自启前言 在树莓派上写了一些Python脚本,还有一个java 的jar包想要在树莓派上…...

全国青少年编程等级考试scratch四级真题2022年9月(含题库答题软件账号)
青少年编程等级考试scratch真题答题考试系统请点击电子学会-全国青少年编程等级考试真题Scratch一级(2019年3月)在线答题_程序猿下山的博客-CSDN博客_小航答题助手1、运行下列程序,说法正确的是?( )A.列表…...
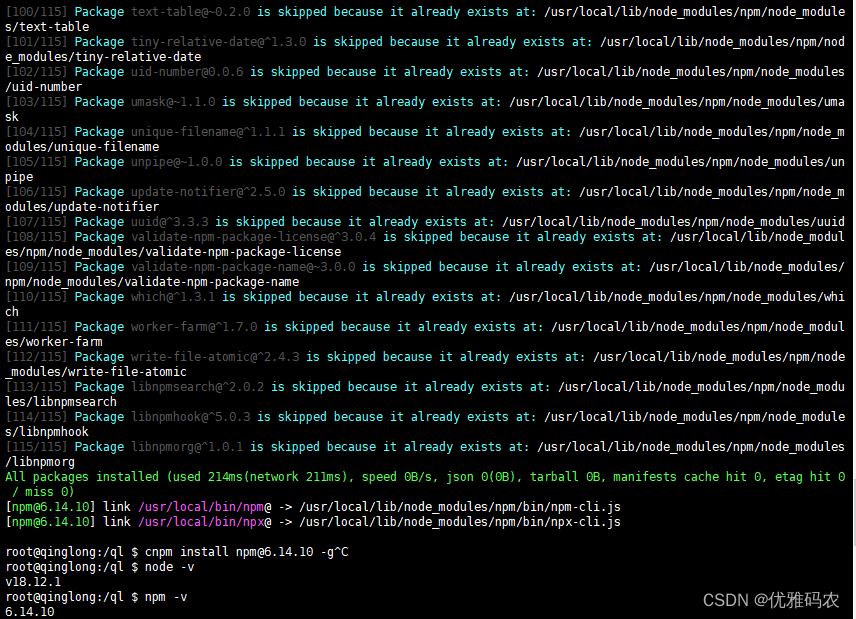
NodeJS与npm版本不一致时降级npm的方法
首先查看 Node.js 与 npm 版本对应关系:Node.js与npm版本查看。 安装 cnpm: npm install -g cnpm 查看一下 npm 和 cnpm 的镜像: npm config get registry cnpm config get registry 2 如果不是 https://registry.npm.taobao.org/ 的话就修…...
)
《C++ Primer Plus》第16章:string类和标准模板库(8)
关联容器 关联容器(associative container)是对容器概念的另一个改进。关联容器将值与键关联在一起,并使用键来查找值。例如,值可以表示雇员信息(如姓名、地址、办公室号码、家庭电话和工作电话、健康计划等ÿ…...

Linux安装达梦8数据库
Linux安装达梦8数据库 服务器系统:centos7 数据库版本:达梦8 先获取安装包:https://eco.dameng.com/download/?_blank 选择相应版本下载,下载完解压之后会得到一个iso文件,把他上传到服务器上,建议上传到/opt目录下…...
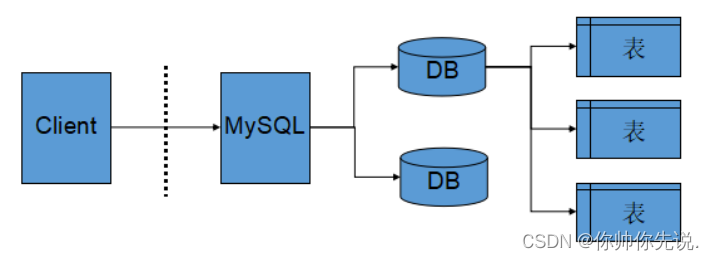
[数据库]初识数据库
●🧑个人主页:你帅你先说. ●📃欢迎点赞👍关注💡收藏💖 ●📖既选择了远方,便只顾风雨兼程。 ●🤟欢迎大家有问题随时私信我! ●🧐版权:本文由[你帅…...
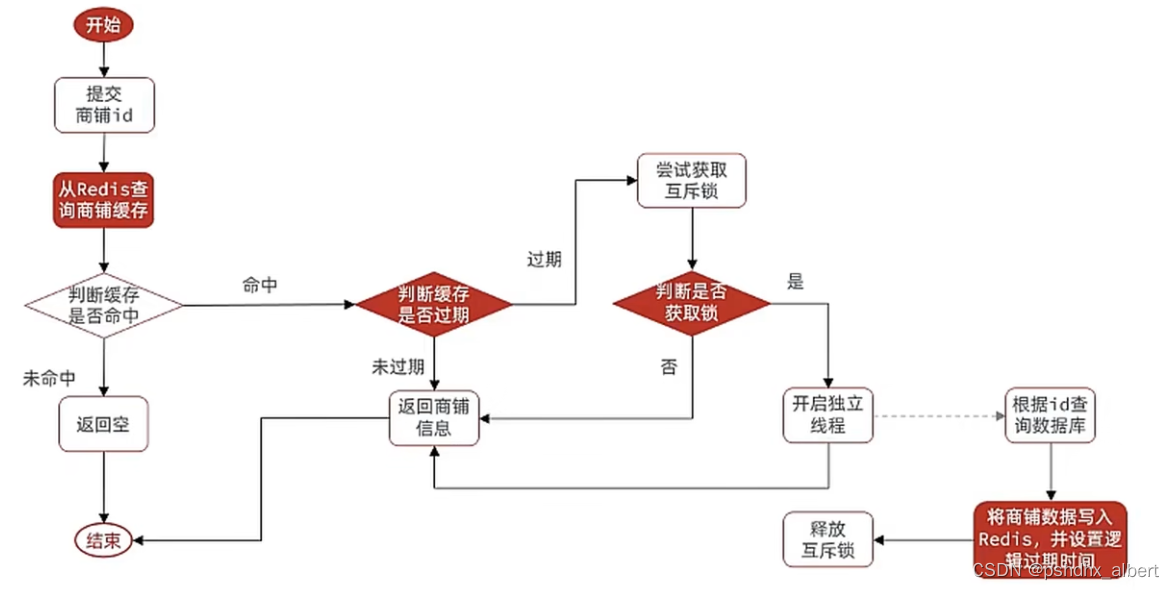
Redis的缓存雪崩、击穿、穿透和解决方案
2.5 缓存穿透问题的解决思路 缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。 常见的解决方案有两种: 缓存空对象 优点:实现简单,维护…...

52000000
选择题(共52题,合计52.0分) 1. 敏捷团队在项目执行过程中会用到一种叫做“看板”的可视化工具,它可显示WIP, 帮助识别瓶颈和过度承诺, 从而使团队能够优化工作流。请从下列选项中选择WIP的最佳解释?() A 等待初步加工的材料的库存 B 目前正…...
内网资源探测
✅作者简介:CSDN内容合伙人、信息安全专业在校大学生🏆 🔥系列专栏 :内网安全 📃新人博主 :欢迎点赞收藏关注,会回访! 💬舞台再大,你不上台,永远是…...
)
Java后端内部面试题(前一部分)
面试题 基础篇 1、Java语言有哪些特点 1、简单易学、有丰富的类库 2、面向对象(Java最重要的特性,让程序耦合度更低,内聚性更高) 2、面向对象和面向过程的区别 面向过程:是分析解决问题的步骤,然后用函数把…...

关于如何抄引擎源码
前两天,后台有网友发私信给我,问我如何抄引擎源码。我一愣,感觉像吃饭喝水一样自然。 抄源码的好处就不说了,抄之前不懂的内容,抄完后就懂了,至少懂一部分了。当然也可以只读不抄,不过ÿ…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...

Caliper 配置文件解析:fisco-bcos.json
config.yaml 文件 config.yaml 是 Caliper 的主配置文件,通常包含以下内容: test:name: fisco-bcos-test # 测试名称description: Performance test of FISCO-BCOS # 测试描述workers:type: local # 工作进程类型number: 5 # 工作进程数量monitor:type: - docker- pro…...
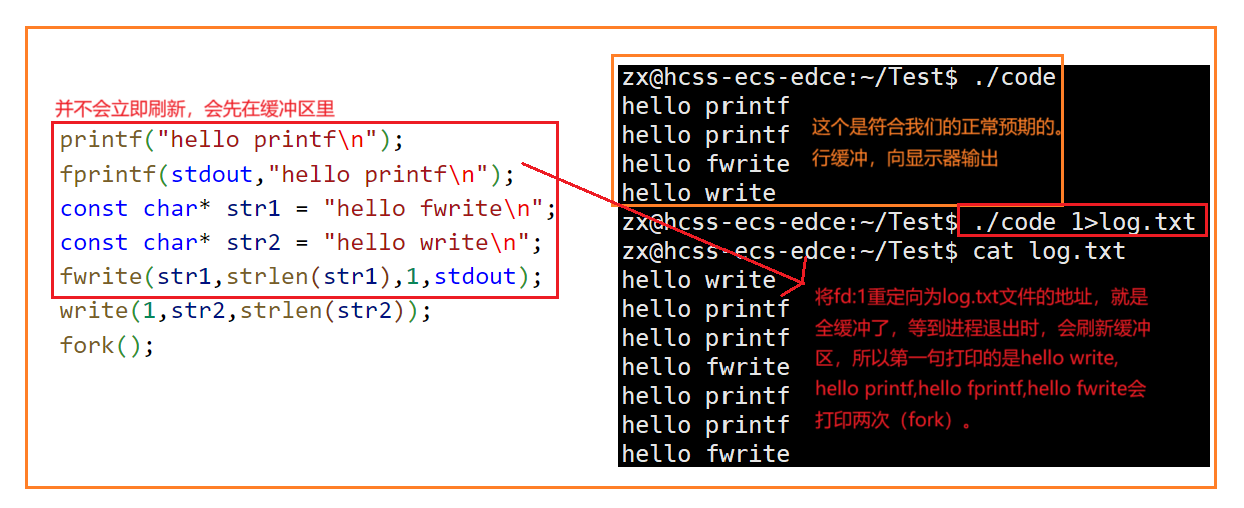
Linux中《基础IO》详细介绍
目录 理解"文件"狭义理解广义理解文件操作的归类认知系统角度文件类别 回顾C文件接口打开文件写文件读文件稍作修改,实现简单cat命令 输出信息到显示器,你有哪些方法stdin & stdout & stderr打开文件的方式 系统⽂件I/O⼀种传递标志位…...