深入分析Java的序列化与反序列化
序列化是一种对象持久化的手段。普遍应用在网络传输、RMI等场景中。本文通过分析ArrayList的序列化来介绍Java序列化的相关内容。主要涉及到以下几个问题:
怎么实现Java的序列化
为什么实现了java.io.Serializable接口才能被序列化
transient的作用是什么
怎么自定义序列化策略
自定义的序列化策略是如何被调用的
ArrayList对序列化的实现有什么好处
Java对象的序列化
Java平台允许我们在内存中创建可复用的Java对象,但一般情况下,只有当JVM处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比JVM的生命周期更长。但在现实应用中,就可能要求在JVM停止运行之后能够保存(持久化)指定的对象,并在将来重新读取被保存的对象。Java对象序列化就能够帮助我们实现该功能。
使用Java对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的”状态”,即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
除了在持久化对象时会用到对象序列化之外,当使用RMI(远程方法调用),或在网络中传递对象时,都会用到对象序列化。Java序列化API为处理对象序列化提供了一个标准机制,该API简单易用。
如何对Java对象进行序列化与反序列化
在Java中,只要一个类实现了java.io.Serializable接口,那么它就可以被序列化。这里先来一段代码:
code 1 创建一个User类,用于序列化及反序列化
package com.hollis;
import java.io.Serializable;
import java.util.Date;/*** Created by hollis on 16/2/2.*/
public class User implements Serializable{private String name;private int age;private Date birthday;private transient String gender;private static final long serialVersionUID = -6849794470754667710L;public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public Date getBirthday() {return birthday;}public void setBirthday(Date birthday) {this.birthday = birthday;}public String getGender() {return gender;}public void setGender(String gender) {this.gender = gender;}@Overridepublic String toString() {return "User{" +"name='" + name + ''' +", age=" + age +", gender=" + gender +", birthday=" + birthday +'}';}
}
复制代码code 2 对User进行序列化及反序列化的Demo
package com.hollis;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.IOUtils;
import java.io.*;
import java.util.Date;/*** Created by hollis on 16/2/2.*/
public class SerializableDemo {public static void main(String[] args) {//Initializes The ObjectUser user = new User();user.setName("hollis");user.setGender("male");user.setAge(23);user.setBirthday(new Date());System.out.println(user);//Write Obj to FileObjectOutputStream oos = null;try {oos = new ObjectOutputStream(new FileOutputStream("tempFile"));oos.writeObject(user);} catch (IOException e) {e.printStackTrace();} finally {IOUtils.closeQuietly(oos);}//Read Obj from FileFile file = new File("tempFile");ObjectInputStream ois = null;try {ois = new ObjectInputStream(new FileInputStream(file));User newUser = (User) ois.readObject();System.out.println(newUser);} catch (IOException e) {e.printStackTrace();} catch (ClassNotFoundException e) {e.printStackTrace();} finally {IOUtils.closeQuietly(ois);try {FileUtils.forceDelete(file);} catch (IOException e) {e.printStackTrace();}}}
}
//output
//User{name='hollis', age=23, gender=male, birthday=Tue Feb 02 17:37:38 CST 2016}
//User{name='hollis', age=23, gender=null, birthday=Tue Feb 02 17:37:38 CST 2016}
复制代码序列化及反序列化相关知识
1、在Java中,只要一个类实现了java.io.Serializable接口,那么它就可以被序列化。
2、通过ObjectOutputStream和ObjectInputStream对对象进行序列化及反序列化
3、虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID)
4、序列化并不保存静态变量。
5、要想将父类对象也序列化,就需要让父类也实现Serializable 接口。
6、Transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。
7、服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。
ArrayList的序列化
在介绍ArrayList序列化之前,先来考虑一个问题:
如何自定义的序列化和反序列化策略
带着这个问题,我们来看java.util.ArrayList的源码
code 3
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{private static final long serialVersionUID = 8683452581122892189L;transient Object[] elementData; // non-private to simplify nested class accessprivate int size;
}
复制代码笔者省略了其他成员变量,从上面的代码中可以知道ArrayList实现了java.io.Serializable接口,那么我们就可以对它进行序列化及反序列化。因为elementData是transient的,所以我们认为这个成员变量不会被序列化而保留下来。我们写一个Demo,验证一下我们的想法:
code 4
public static void main(String[] args) throws IOException, ClassNotFoundException {List<String> stringList = new ArrayList<String>();stringList.add("hello");stringList.add("world");stringList.add("hollis");stringList.add("chuang");System.out.println("init StringList" + stringList);ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("stringlist"));objectOutputStream.writeObject(stringList);IOUtils.close(objectOutputStream);File file = new File("stringlist");ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(file));List<String> newStringList = (List<String>)objectInputStream.readObject();IOUtils.close(objectInputStream);if(file.exists()){file.delete();}System.out.println("new StringList" + newStringList);}
//init StringList[hello, world, hollis, chuang]
//new StringList[hello, world, hollis, chuang]
复制代码了解ArrayList的人都知道,ArrayList底层是通过数组实现的。那么数组elementData其实就是用来保存列表中的元素的。通过该属性的声明方式我们知道,他是无法通过序列化持久化下来的。那么为什么code 4的结果却通过序列化和反序列化把List中的元素保留下来了呢?
writeObject和readObject方法
在ArrayList中定义了来个方法: writeObject和readObject。
这里先给出结论:
在序列化过程中,如果被序列化的类中定义了writeObject 和 readObject 方法,虚拟机会试图调用对象类里的 writeObject 和 readObject 方法,进行用户自定义的序列化和反序列化。
如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject 方法以及 ObjectInputStream 的 defaultReadObject 方法。
用户自定义的 writeObject 和 readObject 方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值。
来看一下这两个方法的具体实现:
code 5
private void readObject(java.io.ObjectInputStream s)throws java.io.IOException, ClassNotFoundException {elementData = EMPTY_ELEMENTDATA;// Read in size, and any hidden stuffs.defaultReadObject();// Read in capacitys.readInt(); // ignoredif (size > 0) {// be like clone(), allocate array based upon size not capacityensureCapacityInternal(size);Object[] a = elementData;// Read in all elements in the proper order.for (int i=0; i<size; i++) {a[i] = s.readObject();}}}
复制代码code 6
private void writeObject(java.io.ObjectOutputStream s)throws java.io.IOException{// Write out element count, and any hidden stuffint expectedModCount = modCount;s.defaultWriteObject();// Write out size as capacity for behavioural compatibility with clone()s.writeInt(size);// Write out all elements in the proper order.for (int i=0; i<size; i++) {s.writeObject(elementData[i]);}if (modCount != expectedModCount) {throw new ConcurrentModificationException();}}
复制代码那么为什么ArrayList要用这种方式来实现序列化呢?
why transient
ArrayList实际上是动态数组,每次在放满以后自动增长设定的长度值,如果数组自动增长长度设为100,而实际只放了一个元素,那就会序列化99个null元素。为了保证在序列化的时候不会将这么多null同时进行序列化,ArrayList把元素数组设置为transient。
why writeObject and readObject
前面说过,为了防止一个包含大量空对象的数组被序列化,为了优化存储,所以,ArrayList使用transient来声明elementData。 但是,作为一个集合,在序列化过程中还必须保证其中的元素可以被持久化下来,所以,通过重写writeObject 和 readObject方法的方式把其中的元素保留下来。
writeObject方法把elementData数组中的元素遍历的保存到输出流(ObjectOutputStream)中。
readObject方法从输入流(ObjectInputStream)中读出对象并保存赋值到elementData数组中。
至此,我们先试着来回答刚刚提出的问题:
如何自定义的序列化和反序列化策略
答:可以通过在被序列化的类中增加writeObject 和 readObject方法。那么问题又来了:
虽然ArrayList中写了writeObject 和 readObject 方法,但是这两个方法并没有显示的被调用啊。
那么如果一个类中包含writeObject 和 readObject 方法,那么这两个方法是怎么被调用的呢?
ObjectOutputStream
从code 4中,我们可以看出,对象的序列化过程通过ObjectOutputStream和ObjectInputputStream来实现的,那么带着刚刚的问题,我们来分析一下ArrayList中的writeObject 和 readObject 方法到底是如何被调用的呢?
为了节省篇幅,这里给出ObjectOutputStream的writeObject的调用栈:
writeObject ---> writeObject0 --->writeOrdinaryObject--->writeSerialData--->invokeWriteObject
这里看一下invokeWriteObject:
void invokeWriteObject(Object obj, ObjectOutputStream out)throws IOException, UnsupportedOperationException{if (writeObjectMethod != null) {try {writeObjectMethod.invoke(obj, new Object[]{ out });} catch (InvocationTargetException ex) {Throwable th = ex.getTargetException();if (th instanceof IOException) {throw (IOException) th;} else {throwMiscException(th);}} catch (IllegalAccessException ex) {// should not occur, as access checks have been suppressedthrow new InternalError(ex);}} else {throw new UnsupportedOperationException();}}
复制代码其中writeObjectMethod.invoke(obj, new Object[]{ out });是关键,通过反射的方式调用writeObjectMethod方法。官方是这么解释这个writeObjectMethod的:
class-defined writeObject method, or null if none
在我们的例子中,这个方法就是我们在ArrayList中定义的writeObject方法。通过反射的方式被调用了。
至此,我们先试着来回答刚刚提出的问题:
如果一个类中包含writeObject 和 readObject 方法,那么这两个方法是怎么被调用的?
答:在使用ObjectOutputStream的writeObject方法和ObjectInputStream的readObject方法时,会通过反射的方式调用。
至此,我们已经介绍完了ArrayList的序列化方式。那么,不知道有没有人提出这样的疑问:
Serializable明明就是一个空的接口,它是怎么保证只有实现了该接口的方法才能进行序列化与反序列化的呢?
Serializable接口的定义:
public interface Serializable {
}
复制代码读者可以尝试把code 1中的继承Serializable的代码去掉,再执行code 2,会抛出java.io.NotSerializableException。
其实这个问题也很好回答,我们再回到刚刚ObjectOutputStream的writeObject的调用栈:
writeObject ---> writeObject0 --->writeOrdinaryObject--->writeSerialData--->invokeWriteObject
writeObject0方法中有这么一段代码:
if (obj instanceof String) {writeString((String) obj, unshared);} else if (cl.isArray()) {writeArray(obj, desc, unshared);} else if (obj instanceof Enum) {writeEnum((Enum<?>) obj, desc, unshared);} else if (obj instanceof Serializable) {writeOrdinaryObject(obj, desc, unshared);} else {if (extendedDebugInfo) {throw new NotSerializableException(cl.getName() + "\n" + debugInfoStack.toString());} else {throw new NotSerializableException(cl.getName());}}
复制代码在进行序列化操作时,会判断要被序列化的类是否是Enum、Array和Serializable类型,如果不是则直接抛出NotSerializableException。
总结
1、如果一个类想被序列化,需要实现Serializable接口。否则将抛出NotSerializableException异常,这是因为,在序列化操作过程中会对类型进行检查,要求被序列化的类必须属于Enum、Array和Serializable类型其中的任何一种。
2、在变量声明前加上该关键字,可以阻止该变量被序列化到文件中。
3、在类中增加writeObject 和 readObject 方法可以实现自定义序列化策略
相关文章:

深入分析Java的序列化与反序列化
序列化是一种对象持久化的手段。普遍应用在网络传输、RMI等场景中。本文通过分析ArrayList的序列化来介绍Java序列化的相关内容。主要涉及到以下几个问题: 怎么实现Java的序列化 为什么实现了java.io.Serializable接口才能被序列化 transient的作用是什么 怎么自…...

、Tomcat源码分析-类加载器
接下来,我们再来看下 tomcat 是如何创建 common 类加载器的。关键代码如下所示,在创建类加载器时,会读取相关的路径配置,并把路径封装成 Repository 对象,然后交给 ClassLoaderFactory 创建类加载器。 Bootstrap.java…...
反转链表相关的练习(下)
目录 一、回文链表 二、 重排链表 三、旋转链表 一、回文链表 给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。 示例 1: 输入:head [1,2,2,1] 输…...

2.进程和线程
1.进程1.1 终止正常退出(自愿)出错退出(自愿)严重错误(非自愿)被其他进程杀死(非自愿)1.2 状态就绪态:可运行,但因为其他进程正在运行而暂时停止阻塞态:除非某种外部事件发生,否则进程不能运行1.3 实现一个进程在执行过程中可能被…...

C++回顾(十四)—— 函数模板
14.1 概述 所谓函数模板(function template),实际上是建立一个通用函数,其函数类型和形参类型不具体指定,用一个虚拟的类型来代表。这个通用函数就称为函数模板。凡是函数体相同的函数都可以用这个模板来代替,不必定义多个函数&a…...
如何做好项目各干系人的管理及应对?
如何更好地识别、分析和管理项目关系人?主要有以下几个方面: 1、项目干系人的分析 一般对项目干系人的分析有2种方法, 方法一:权利(影响),即对项目可以产生影响的人; 方法二…...
Elasticsearch使用系列-ES增删查改基本操作+ik分词
一、安装可视化工具KibanaES是一个NoSql数据库应用。和其他数据库一样,我们为了方便操作查看它,需要安装一个可视化工具 Kibana。官网:https://www.elastic.co/cn/downloads/kibana和前面安装ES一样,选中对应的环境下载࿰…...
07-PL/SQL基础(if语句,case语句,循环语句)
本章主要内容: 1.PL/SQL的基本构成:declare,begin,exception,end; 2.结构控制语句:IF语句,CASE语句 3.循环结构:loop循环,for loop循环,while loop循环 PL/SQL的基本构成 特点 PL/SQL语言是SQL语言的扩展ÿ…...

信捷 XDH Ethercat A_VELMOVE
本文描述信捷 EthercatA_VELMOVE指令,以设定的速度持续运行 上图中,在M100的上升沿,执行A_VELMOVE指令。A_VELMOVE HD100 D100 M101 K0HD100输入参数起始地址 ,HD118输入参数末尾地址HD100~HD103,双精度浮点数(64位&am…...
【专项训练】分治、回溯
分治、回溯其实就是递归,只是是递归的一个细分,是一种特殊的递归 碰到一个题目,你就找他的重复性 最近重复性:根据重复性怎么构造以及如何分解,包括:分治、回溯 最优重复性:动态规划 本质:找重复性、分解问题、组合子问题的结果 回溯:试错! 50. Pow(x, n) https:…...
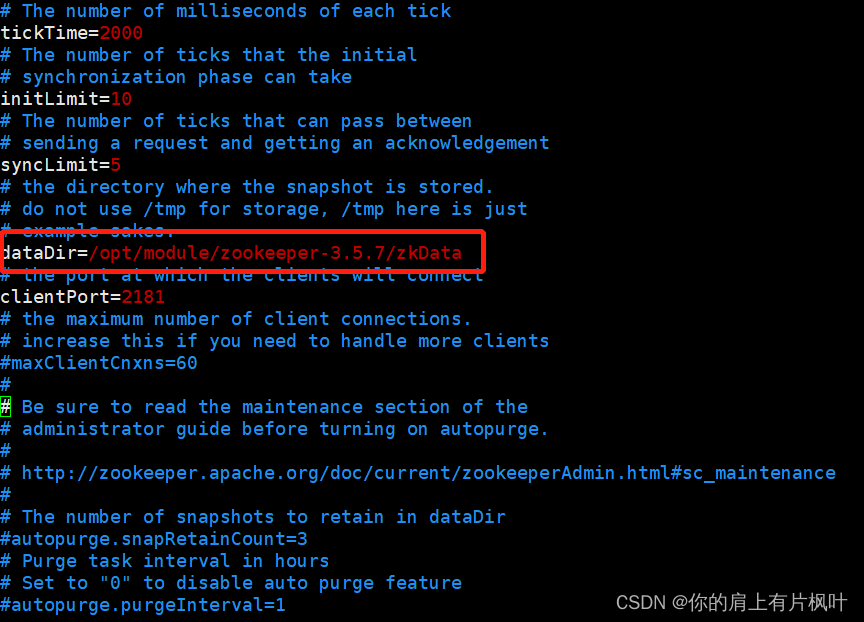
Linux上安装配置ZooKeeper
Linux上安装配置ZooKeeper 下载压缩文件 将压缩文件拷贝到指定目录下 执行命令 tar -zxvf [apache-zookeeper-3.5.7-bin.tar.gz] -C [/opt/module/]注:第一个括号里面是压缩文件名称,第二个括号里面是解压到指定的目录 进入到解压后的文件夹当中&am…...
idea leetcode插件无法登录
em 2022某天 leetcode-cn.com 改为了 leetcode.cn so , 如果是版本比较老idea leetcode插件, 就无法使用了. 因为用的旧域名 先说解决办法: 2.0 先把旧版本卸载了 2.1 ideaplugin官网找到本地idea版本下可安装的最高版本的leetcode.cn 假设是 leetcode-editor-6.9.zip 2.2 下…...

VR会议不断升级,为商务会谈打造云端洽谈服务!
VR会议不断升级,为商务会谈打造云端洽谈服务。在商务合作中,对客户需求的理解以及与客户讲解方案都需要建立在一个有效的沟通上,因此VR会议的用武之地就有了,以VR全景技术为核心,通过同屏互动和全景通信技术࿰…...
Ubuntu系统开机自动挂载NTFS硬盘【超实用】
由于跑深度学习实验(图像分割)f非常消耗内存,系统盘sda1内存小,配置了一个大容量得出NTFS机械盘,网上招了一些资料如何挂在,但是每次开机得手动挂载一遍才能使用硬盘,非常不方便,还容易造成数据丢失。 Step…...

淘宝十年资深架构师吐血总结淘宝的数据库架构设计和采用的技术手段。
淘宝十年资深架构师吐血总结淘宝的数据库架构设计和采用的技术手段。 文章目录淘宝十年资深架构师吐血总结淘宝的数据库架构设计和采用的技术手段。本文导读1.分库分表2.数据冗余3.异步复制4.读写分离总结本文导读 淘宝的数据库架构设计采用了分布式数据库技术,通过…...

训练自己的GPT2-Chinese模型
文章目录效果抢先看准备工作环境搭建创建虚拟环境训练&预测项目结构模型预测续写训练模型遇到的问题及解决办法显存不足生成的内容一样文末效果抢先看 准备工作 从GitHub上拉去项目到本地,准备已训练好的模型百度网盘:提取码【9dvu】。 gpt2对联训…...

springcloud3 fegin服务超时的配置和日志级别的配置2
一 fegin的概述 1.1 fegin的默认超时时间 默认fegin客户端只等待1秒钟,超过1秒钟,直接会返回错误。 1.2 架构图 1.2.1 说明 1.2.2 启动操作 1.先启动9001,9002 eureka 2.启动9003 服务提供者 3.启动9006消费者 1.3 情况验证 1.3.1 正常默认情…...

华为机试 HJ48 从单向链表中删除指定值的节点
题目链接 描述 输入一个单向链表和一个节点的值,从单向链表中删除等于该值的节点,删除后如果链表中无节点则返回空指针。 链表的值不能重复。 构造过程,例如输入一行数据为: 6 2 1 2 3 2 5 1 4 5 7 2 2 则第一个参数6表示输入总共6个节点&a…...

华为机试 HJ1 字符串最后一个单词的长度
华为机试 HJ1 字符串最后一个单词的长度 文章目录华为机试 HJ1 字符串最后一个单词的长度一、题目描述二、方法一 Java lastIndexOf() 方法三、方法二 Java split()方法使用Java的lastIndexOf()和split()解决求取方法字符串最后一个单词的长度的问题 一、题目描述 计算字符串最…...

从入门到精通MongoDB数据库系列之二:深入了解MongoDB基本概念文档、集合、数据库、数据类型、MongoDB shell
从入门到精通MongoDB数据库系列之二:深入了解MongoDB基本概念文档、集合、数据库、数据类型、MongoDB shell 一、MongoDB基本概念二、文档三、集合1.动态模式2.命名四、数据库五、MongoDB shell1.运行shell2.连接远程MongoDB数据库3.shell中的基本操作六、数据类型1.基本数据类…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

2025年渗透测试面试题总结-腾讯[实习]科恩实验室-安全工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]科恩实验室-安全工程师 一、网络与协议 1. TCP三次握手 2. SYN扫描原理 3. HTTPS证书机制 二…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...
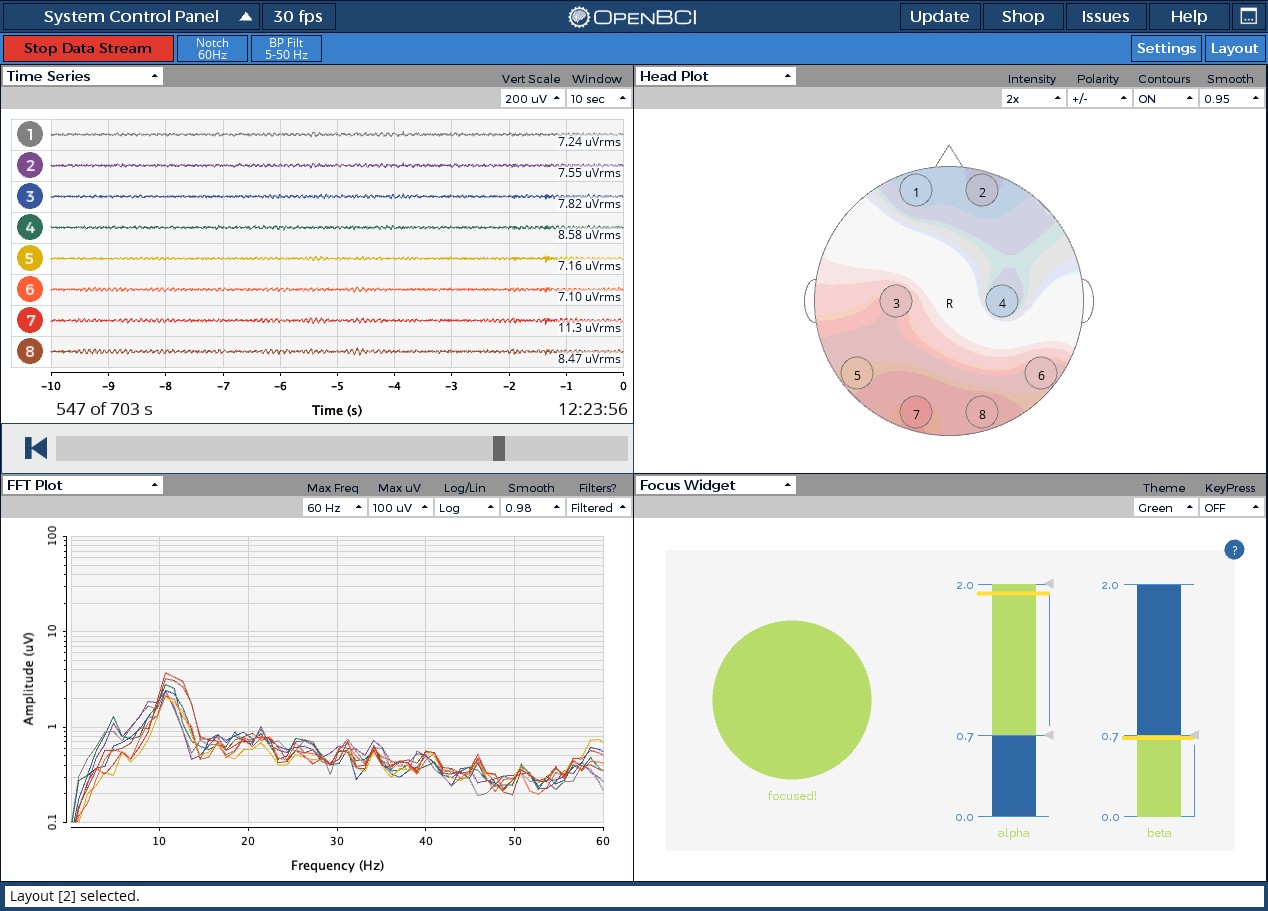
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...

Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement
Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement 1. LAB环境2. L2公告策略2.1 部署Death Star2.2 访问服务2.3 部署L2公告策略2.4 服务宣告 3. 可视化 ARP 流量3.1 部署新服务3.2 准备可视化3.3 再次请求 4. 自动IPAM4.1 IPAM Pool4.2 …...
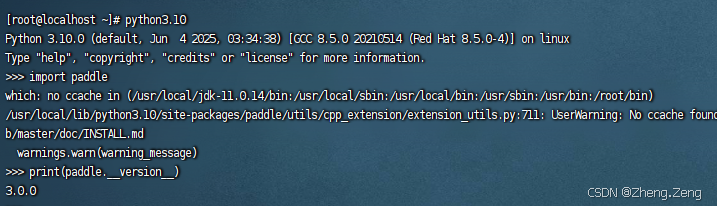
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...
CSS3相关知识点
CSS3相关知识点 CSS3私有前缀私有前缀私有前缀存在的意义常见浏览器的私有前缀 CSS3基本语法CSS3 新增长度单位CSS3 新增颜色设置方式CSS3 新增选择器CSS3 新增盒模型相关属性box-sizing 怪异盒模型resize调整盒子大小box-shadow 盒子阴影opacity 不透明度 CSS3 新增背景属性ba…...

Qt/C++学习系列之列表使用记录
Qt/C学习系列之列表使用记录 前言列表的初始化界面初始化设置名称获取简单设置 单元格存储总结 前言 列表的使用主要基于QTableWidget控件,同步使用QTableWidgetItem进行单元格的设置,最后可以使用QAxObject进行单元格的数据读出将数据进行存储。接下来…...

c++算法学习3——深度优先搜索
一、深度优先搜索的核心概念 DFS算法是一种通过递归或栈实现的"一条路走到底"的搜索策略,其核心思想是: 深度优先:从起点出发,选择一个方向探索到底,直到无路可走 回溯机制:遇到死路时返回最近…...