Apache Doris 基础 -- 数据表设计(分区分桶)
Versions: 2.1
本文档主要介绍了Doris的表创建和数据分区,以及表创建过程中可能遇到的问题和解决方案。
1、基本概念
在Doris中,数据以表的形式被逻辑地描述。
1.1 Row & Column
表由行和列组成:
- 行:表示用户数据的单行;
- 列:用于描述一行数据中的不同字段;
- 列可以分为两种类型:键和值。从业务角度来看,Key和Value可以分别对应于维度列和度量列。Doris中的键列是在表创建语句中指定的,它们是
unique key,aggregate key, 或duplicate key后面的列。其余列是值列。从聚合模型的角度来看,具有相同Key列的行将被聚合为单行。值列的聚合方法由用户在创建表期间指定。有关聚合模型的更多信息,请参阅Doris数据模型。
1.2 Partition & Tablet(分区和分桶)
Doris支持两层数据分区。第一层是Partitioning,支持Range和List分区。第二层是Bucket(也称为Tablet),它支持Hash和Random。如果在创建表期间没有建立分区,Doris将生成一个对用户透明的默认分区。使用默认分区时,只支持Bucket分区。
在Doris 存储引擎中,数据被水平分区为几个分片(tablets)。每个tablet包含几行数据。不同tablets中的数据之间没有重叠,它们在物理上是独立存储的。
**多个tablets 逻辑上属于不同的分区。一个tablet只属于一个分区,而一个分区包含多个tablet。**因为tablets 在物理上是独立存储的,所以分区也可以看作是物理上独立的。tablets 是用于数据移动和复制等操作的最小物理存储单元。
几个分区组成一个表。分区可以看作是最小的逻辑管理单元。
二级数据分区的好处:
- 对于具有时间或类似有序值的维度,这些维度列可以用作分区列。可以根据导入频率和分区数据量评估分区粒度( partition granularity)。
- 历史数据删除需求:如果需要删除历史数据(例如只保留最近几天的数据),可以使用复合分区通过删除历史分区来实现这一目标。或者,可以在指定的分区内发送DELETE语句来删除数据。
- 解决数据倾斜问题:每个分区可以独立指定桶的数量。例如,当按天进行分区,并且每天的数据量差异较大时,可以指定每个分区的桶数,以便将数据合理地分布在不同的分区上。建议选择辨识度高的列作为分桶列。
1.3 创建表的示例
Doris中的CREATE TABLE是一个同步命令。它在SQL执行完成后返回结果。成功的返回表明表创建成功。更多信息请参考CREATE TABLE,或输入HELP CREATE TABLE;命令。
本节介绍如何通过范围分区和散列桶在Doris中创建表。
-- Range Partition
CREATE TABLE IF NOT EXISTS example_range_tbl
(`user_id` LARGEINT NOT NULL COMMENT "User ID",`date` DATE NOT NULL COMMENT "Date when the data are imported",`timestamp` DATETIME NOT NULL COMMENT "Timestamp when the data are imported",`city` VARCHAR(20) COMMENT "User location city",`age` SMALLINT COMMENT "User age",`sex` TINYINT COMMENT "User gender",`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "User last visit time",`cost` BIGINT SUM DEFAULT "0" COMMENT "Total user consumption",`max_dwell_time` INT MAX DEFAULT "0" COMMENT "Maximum user dwell time",`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "Minimum user dwell time"
)
ENGINE=OLAP
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(PARTITION `p201701` VALUES [("2017-01-01"), ("2017-02-01")),PARTITION `p201702` VALUES [("2017-02-01"), ("2017-03-01")),PARTITION `p201703` VALUES [("2017-03-01"), ("2017-04-01"))
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
("replication_num" = "1"
);
这里以AGGREGATE KEY数据模型为例。在AGGREGATE KEY数据模型中,所有使用聚合类型(SUM、REPLACE、MAX或MIN)指定的列都是Value列。其余的是键列。
在CREATE TABLE语句末尾的PROPERTIES中,您可以通过参考有关CREATE TABLE的文档,找到有关可以在PROPERTIES中设置的相关参数的详细信息。
ENGINE的默认类型是OLAP。在Doris中,只有这个OLAP ENGINE类型由Doris自己负责数据管理和存储。其他ENGINE类型,如mysql、broker、es等,本质上只是映射到其他外部数据库或系统中的表,允许Doris读取这些数据。但是,Doris本身并不为非OLAP ENGINE类型创建、管理或存储任何表或数据。
IF NOT EXISTS表示如果该表之前没有被创建过,那么它将被创建。注意,这只检查表名是否存在,而不检查新表的模式是否与现有表的模式相同。因此,如果存在同名但模式不同的表,该命令也将成功返回,但这并不意味着创建了新表和新模式。
1.4 View partition
show create table命令用于查看表的分区信息。
> show create table example_range_tbl
+-------------------+---------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------------------+---------------------------------------------------------------------------------------------------------+
| example_range_tbl | CREATE TABLE `example_range_tbl` ( |
| | `user_id` largeint(40) NOT NULL COMMENT 'User ID', |
| | `date` date NOT NULL COMMENT 'Date when the data are imported', |
| | `timestamp` datetime NOT NULL COMMENT 'Timestamp when the data are imported', |
| | `city` varchar(20) NULL COMMENT 'User location city', |
| | `age` smallint(6) NULL COMMENT 'User age', |
| | `sex` tinyint(4) NULL COMMENT 'User gender', |
| | `last_visit_date` datetime REPLACE NULL DEFAULT "1970-01-01 00:00:00" COMMENT 'User last visit time', |
| | `cost` bigint(20) SUM NULL DEFAULT "0" COMMENT 'Total user consumption', |
| | `max_dwell_time` int(11) MAX NULL DEFAULT "0" COMMENT 'Maximum user dwell time', |
| | `min_dwell_time` int(11) MIN NULL DEFAULT "99999" COMMENT 'Minimum user dwell time' |
| | ) ENGINE=OLAP |
| | AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`) |
| | COMMENT 'OLAP' |
| | PARTITION BY RANGE(`date`) |
| | (PARTITION p201701 VALUES [('0000-01-01'), ('2017-02-01')), |
| | PARTITION p201702 VALUES [('2017-02-01'), ('2017-03-01')), |
| | PARTITION p201703 VALUES [('2017-03-01'), ('2017-04-01'))) |
| | DISTRIBUTED BY HASH(`user_id`) BUCKETS 16 |
| | PROPERTIES ( |
| | "replication_allocation" = "tag.location.default: 1", |
| | "is_being_synced" = "false", |
| | "storage_format" = "V2", |
| | "light_schema_change" = "true", |
| | "disable_auto_compaction" = "false", |
| | "enable_single_replica_compaction" = "false" |
| | ); |
+-------------------+---------------------------------------------------------------------------------------------------------+
可以使用show partitions from your_table命令查看表的分区信息。
> show partitions from example_range_tbl
+-------------+---------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------
+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+
| PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium
| CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable |
+-------------+---------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------
+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+
| 28731 | p201701 | 1 | 2024-01-25 10:50:51 | NORMAL | date | [types: [DATEV2]; keys: [0000-01-01]; ..types: [DATEV2]; keys: [2017-02-01]; ) | user_id | 16 | 1 | HDD
| 9999-12-31 23:59:59 | | | 0.000 | false | tag.location.default: 1 | true |
| 28732 | p201702 | 1 | 2024-01-25 10:50:51 | NORMAL | date | [types: [DATEV2]; keys: [2017-02-01]; ..types: [DATEV2]; keys: [2017-03-01]; ) | user_id | 16 | 1 | HDD
| 9999-12-31 23:59:59 | | | 0.000 | false | tag.location.default: 1 | true |
| 28733 | p201703 | 1 | 2024-01-25 10:50:51 | NORMAL | date | [types: [DATEV2]; keys: [2017-03-01]; ..types: [DATEV2]; keys: [2017-04-01]; ) | user_id | 16 | 1 | HDD
| 9999-12-31 23:59:59 | | | 0.000 | false | tag.location.default: 1 | true |
+-------------+---------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------
+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+
1.4 Alter partition
可以使用alter table add partition命令添加一个新分区。
ALTER TABLE example_range_tbl ADD PARTITION p201704 VALUES LESS THAN("2020-05-01") DISTRIBUTED BY HASH(`user_id`) BUCKETS 5;
有关更多分区修改操作,请参阅ALTER-TABLE-PARTITION的SQL手册。
2、手动分区
2.1 分区列
- 分区列可以指定为一个或多个列,分区列必须是KEY列。稍后将在多列分区的摘要部分介绍多列分区的用法。
- 当
allowPartitionColumnNullable设置为true时,Range分区支持使用NULL分区列。List Partition不支持NULL分区列。 - 无论分区列的类型如何,在写入分区值时都需要双引号。
- 理论上,分区的数量没有上限。
- 创建不分区的表时,系统会自动生成一个与表名同名的全范围分区。该分区对用户不可见,不能删除或修改。
- 在创建分区时,不允许有重叠的范围
2.2 Range partition
分区列通常是时间列,便于管理新旧数据。Range分区支持DATE、DATETIME、TINYINT、SMALLINT、INT、BIGINT、LARGEINT等列类型。
分区信息支持四种写法:
- FIXED RANGE:分区作为左闭,右开的间隔。
PARTITION BY RANGE(col1[, col2, ...])
( PARTITION partition_name1 VALUES [("k1-lower1", "k2-lower1", "k3-lower1",...), ("k1-upper1", "k2-upper1", "k3-upper1", ...)), PARTITION partition_name2 VALUES [("k1-lower1-2", "k2-lower1-2", ...), ("k1-upper1-2", MAXVALUE, ))
)
例如:
PARTITION BY RANGE(`date`)
(PARTITION `p201701` VALUES [("2017-01-01"), ("2017-02-01")),PARTITION `p201702` VALUES [("2017-02-01"), ("2017-03-01")),PARTITION `p201703` VALUES [("2017-03-01"), ("2017-04-01"))
)
- LESS THAN:只定义分区的上界。下界由前一个分区的上界决定。
PARTITION BY RANGE(col1[, col2, ...])
( PARTITION partition_name1 VALUES LESS THAN MAXVALUE | ("value1", "value2", ...), PARTITION partition_name2 VALUES LESS THAN MAXVALUE | ("value1", "value2", ...)
)
For example:
PARTITION BY RANGE(`date`)
(PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
)PARTITION BY RANGE(`date`)
(PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),PARTITION `p201703` VALUES LESS THAN ("2017-04-01")PARTITION `other` VALUES LESS THAN (MAXVALUE)
)
- BATCH RANGE:批量创建数字和时间类型的RANGE分区,将分区定义为左关闭间隔和右打开间隔,并设置步长。
PARTITION BY RANGE(int_col)
( FROM (start_num) TO (end_num) INTERVAL interval_value
)PARTITION BY RANGE(date_col)
( FROM ("start_date") TO ("end_date") INTERVAL num YEAR | num MONTH | num WEEK | num DAY | 1 HOUR
)
For example:
PARTITION BY RANGE(age)
(FROM (1) TO (100) INTERVAL 10
)PARTITION BY RANGE(`date`)
(FROM ("2000-11-14") TO ("2021-11-14") INTERVAL 2 YEAR
)
- MULTI RANGE:批量创建
RANGE分区,将分区定义为左关闭,右打开的间隔。例如:
2.3 List partition
分区列支持BOOLEAN、TINYINT、SMALLINT、INT、BIGINT、LARGEINT、DATE、DATETIME、CHAR、VARCHAR等数据类型。分区值是枚举值。只有当数据是目标分区的枚举值之一时,才能命中该分区。
分区支持通过VALUES IN (...)指定每个分区中包含的枚举值。
For example:
PARTITION BY LIST(city)
(PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),PARTITION `p_jp` VALUES IN ("Tokyo")
)
List分区也支持多列分区,例如:
PARTITION BY LIST(id, city)
(PARTITION p1_city VALUES IN (("1", "Beijing"), ("1", "Shanghai")),PARTITION p2_city VALUES IN (("2", "Beijing"), ("2", "Shanghai")),PARTITION p3_city VALUES IN (("3", "Beijing"), ("3", "Shanghai"))
)
3、动态分区
动态分区旨在管理分区的TTL (Time-to-Life),减轻用户的负担。
在某些使用场景中,用户会按天对表进行分区,每天定期执行例行任务。此时,用户需要手动管理分区。否则,由于用户没有创建分区,可能导致数据加载失败。这给用户带来了额外的维护成本。
使用动态分区,用户可以在建立表时定义分区创建和删除规则。FE启动一个后台线程,根据这些用户定义的规则来处理分区的创建或删除。用户还可以在运行时灵活地修改这些规则。
需要注意的是,动态分区只受范围分区的支持。目前,该功能支持动态添加和删除分区。
当被CCR(Cross Cluster Replication)同步时,此功能将被禁用。如果此表被CCR复制,即PROPERTIES中包含
is_being_synced = true,则在show create table中显示为enabled,但实际上不会生效。当is_being_synced设置为false时,这些特性将恢复工作,但是is_being_synced属性仅适用于CCR外设模块,不应该在CCR同步期间手动设置。
3.1 如何使用
动态分区规则可以在运行时创建或修改表时指定。
目前,只能为具有单个分区列的分区表设置动态分区规则。
创建表时指定:
CREATE TABLE tbl1
(...)
PROPERTIES
("dynamic_partition.prop1" = "value1","dynamic_partition.prop2" = "value2",...
)
在运行时修改:
ALTER TABLE tbl1 SET
("dynamic_partition.prop1" = "value1","dynamic_partition.prop2" = "value2",...
)
3.2 规则参数
动态分区规则的前缀是dynamic_partition。
-
dynamic_partition.enable
是否启用动态分区特性。可以指定为TRUE或FALSE。如果未填充,则默认为TRUE。如果为FALSE, Doris将忽略表的动态分区规则。 -
dynamic_partition.time_unit(必要参数)
动态分区调度单位。可以指定为HOUR、DAY、WEEK、MONTH和YEAR,表示分别按小时、日、周、月和年创建或删除分区。
当指定HOUR时,动态创建的分区名后缀格式为yyyyMMddHH,例如2020032501。当时间单位为HOUR时,分区列的数据类型不能为DATE。
当指定为DAY时,动态创建的分区名称后缀格式为yyyyMMdd,例如20200325。
当指定为WEEK时,动态创建的分区名后缀格式为yyyy_ww。也就是说,当前日期是当年的第几周。例如,为“2020-03-25”创建的分区后缀为“2020_13”,表示当前为2020年的第13周。
当指定为YEAR时,动态创建的分区名称后缀格式为yyyy,例如“2020”。 -
dynamic_partition.time_zone
动态分区的时区,如果没有填写,默认为当前机器系统的时区,如Asia/Shanghai,如果您想知道支持的TimeZone,可以在TimeZone中找到。 -
dynamic_partition.start
动态分区的起始偏移量,通常为负数。根据time_unit属性,基于当前日期(周/月),分区范围在此偏移量之前的分区将被删除。如果不填充,默认为-2147483648,即不删除历史分区。 -
dynamic_partition.end(必要参数)
动态分区的结束偏移量,通常为正数。根据time_unit属性的差异,按照当天(周/月)提前创建相应范围的分区。 -
dynamic_partition.prefix(必要参数)
动态创建的分区名称前缀 -
dynamic_partition.buckets
与动态创建的分区相对应的桶的数量。 -
dynamic_partition.replication_num
动态分区的副本数。如果不填写,则默认为表的副本数。 -
dynamic_partition.start_day_of_week
当time_unit为“WEEK”时,该参数用于指定一周的起始时间。取值范围为1 ~ 7。1是星期一,7是星期天。默认值是1,这意味着每周从星期一开始。 -
dynamic_partition.start_day_of_month
当time_unit为MONTH时,该参数用于指定每月的开始日期。取值范围是1 ~ 28。1表示每月的1号,28表示每月的28号。默认值是1,这意味着每个月从1号开始。目前不支持29、30和31,以避免阴历年或月造成的歧义。 -
dynamic_partition.create_history_partition
默认为false。当设置为true时,Doris将自动创建所有分区,如下面的创建规则所述。同时,FE的max_dynamic_partition_num参数将限制分区的总数,以避免一次创建太多分区。当期望创建的分区数量大于max_dynamic_partition_num时,操作将失败。
当不指定start属性时,该参数不起作用。 -
dynamic_partition.history_partition_num
当create_history_partition为true时,该参数用于指定历史分区的数量。默认值是-1,表示没有设置。
创建历史分区规则
当create_history_partition为true时,即启用历史分区创建,Doris根据dynamic_partition.start 和 dynamic_partition.history_partition_num确定要创建的历史分区的数量。
假设要创建的历史分区数量为expect_create_partition_num,根据不同的设置,数量如下:
create_history_partition=true- 没有设置
dynamic_partition.history_partition_num,即-1 - expect_create_partition_num =
end-start - 设置了
dynamic_partition.history_partition_num
expect_create_partition_num =end- max(start, -history_partition_num);
- 没有设置
create_history_partition=false
不创建历史分区,expect_create_partition_num=end- 0;
当expect_create_partition_num大于max_dynamic_partition_num(默认500)时,禁止创建过多的分区。
例子
假设今天是2021-05-20,按天划分,动态分区的属性设置为create_history_partition=true, end=3, start=-3, history_partition_num=1,然后系统将自动创建以下分区。
p20210519
p20210520
p20210521
p20210522
p20210523
history_partition_num =5并保持其余属性与1一样,那么系统将自动创建以下分区。
p20210517
p20210518
p20210519
p20210520
p20210521
p20210522
p20210523
history_partition_num =-1,也就是说,如果您不设置历史分区的数量,并保持其余属性与1相同,系统将自动创建以下分区。
p20210517
p20210518
p20210519
p20210520
p20210521
p20210522
p20210523
3.3 Example
1 表tbl1分区列k1,类型为DATE,创建动态分区规则。按天分区,只保留最近7天的分区,提前创建未来3天的分区。
CREATE TABLE tbl1
(k1 DATE,...
)
PARTITION BY RANGE(k1) ()
DISTRIBUTED BY HASH(k1)
PROPERTIES
("dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.start" = "-7","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "32"
);
假设当前日期为2020-05-29。根据上述规则,tbl1将生成以下分区:
p20200529: ["2020-05-29", "2020-05-30")
p20200530: ["2020-05-30", "2020-05-31")
p20200531: ["2020-05-31", "2020-06-01")
p20200601: ["2020-06-01", "2020-06-02")
第二天,2020-05-30,将创建一个新的分区p20200602: [" 2020-06-02 "," 2020-06-03 ")
在2020-06-06,因为dynamic_partition.start设置为7,则删除7天前的分区,即p20200529分区将被删除。
2 表tbl1分区列k1,类型为DATETIME,创建动态分区规则。按周分区,只保留前2周的分区,提前创建后2周的分区。
CREATE TABLE tbl1
(k1 DATETIME,...
)
PARTITION BY RANGE(k1) ()
DISTRIBUTED BY HASH(k1)
PROPERTIES
("dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "WEEK","dynamic_partition.start" = "-2","dynamic_partition.end" = "2","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "8"
);
假设当前日期为2020-05-29,即2020年的第22周。默认的星期从星期一开始。根据上述规则,tbl1将生成以下分区:
p2020_22: ["2020-05-25 00:00:00", "2020-06-01 00:00:00")
p2020_23: ["2020-06-01 00:00:00", "2020-06-08 00:00:00")
p2020_24: ["2020-06-08 00:00:00", "2020-06-15 00:00:00")
每个分区的开始日期是每周的星期一。同时,由于分区列k1的类型为DATETIME,分区值将填充小时、分钟和秒字段,且均为0。
2020-06-15,即第25周,删除2周前的分区,即p2020_22。
在上面的例子中,假设用户指定一周的开始日期为"dynamic_partition.start_day_of_week" = "3"也就是说,把星期三定为一周的开始。分区如下:
p2020_22: ["2020-05-27 00:00:00", "2020-06-03 00:00:00")
p2020_23: ["2020-06-03 00:00:00", "2020-06-10 00:00:00")
p2020_24: ["2020-06-10 00:00:00", "2020-06-17 00:00:00")
即分区的范围从本周的星期三到下周的星期二。
2019-12-31和2020-01-01在同一周,如果分区开始日期为2019-12-31,则分区名称为
p2019_53;如果分区开始日期为2020-01-01,则分区名称为p2020_01。
3 表tbl1分区列k1,类型为DATE,创建动态分区规则。按月分区,不删除历史分区,提前2个月创建分区。同时,将开始日期设置在每个月的3号。
CREATE TABLE tbl1
(k1 DATE,...
)
PARTITION BY RANGE(k1) ()
DISTRIBUTED BY HASH(k1)
PROPERTIES
("dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "MONTH","dynamic_partition.end" = "2","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "8","dynamic_partition.start_day_of_month" = "3"
);
假设当前日期为2020-05-29。根据上述规则,tbl1将生成以下分区:
p202005: ["2020-05-03", "2020-06-03")
p202006: ["2020-06-03", "2020-07-03")
p202007: ["2020-07-03", "2020-08-03")
因为dynamic_partition.start如果未设置,则不会删除历史分区。
假设今天是2020-05-20,每个月的起始日期设为28号,分区范围为:
p202004: ["2020-04-28", "2020-05-28")
p202005: ["2020-05-28", "2020-06-28")
p202006: ["2020-06-28", "2020-07-28")
3.4 修改动态分区属性
使用如下命令修改动态分区的属性
ALTER TABLE tbl1 SET
("dynamic_partition.prop1" = "value1",...
);
修改某些属性可能会导致冲突。假设分区粒度为DAY,并创建了以下分区:
p20200519: ["2020-05-19", "2020-05-20")
p20200520: ["2020-05-20", "2020-05-21")
p20200521: ["2020-05-21", "2020-05-22")
如果此时将分区粒度修改为MONTH,系统将尝试创建一个范围为["2020-05-01","2020-06-01")的分区,该范围与现有分区冲突。所以它不能被创造出来。可以正常创建范围为[“2020-06-01”,“2020-07-01”]的分区。因此,2020-05-22 ~ 2020-05-30之间的分区需要手工填充。
3.5 检查动态分区表调度状态
可以使用以下命令进一步查看动态分区表的调度情况:
mysql> SHOW DYNAMIC PARTITION TABLES;
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
| TableName | Enable | TimeUnit | Start | End | Prefix | Buckets | StartOf | LastUpdateTime | LastSchedulerTime | State | LastCreatePartitionMsg | LastDropPartitionMsg | ReservedHistoryPeriods |
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
| d3 | true | WEEK | -3 | 3 | p | 1 | MONDAY | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | [2021-12-01,2021-12-31] |
| d5 | true | DAY | -7 | 3 | p | 32 | N/A | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d4 | true | WEEK | -3 | 3 | p | 1 | WEDNESDAY | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d6 | true | MONTH | -2147483648 | 2 | p | 8 | 3rd | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d2 | true | DAY | -3 | 3 | p | 32 | N/A | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d7 | true | MONTH | -2147483648 | 5 | p | 8 | 24th | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
7 rows in set (0.02 sec)
- LastUpdateTime:最后一次修改动态分区属性的时间
- LastSchedulerTime:最后一次执行动态分区调度的时间
- State:动态分区调度最后一次执行的状态
- LastCreatePartitionMsg:最后一次动态添加分区调度的错误消息
- LastDropPartitionMsg:最后一次执行动态删除分区调度的错误消息
3.6 高级操作
FE配置项
dynamic_partition_enable
是否启用Doris的动态分区特性。默认值为false,即关闭。该参数只影响动态分区表的分区操作,不影响普通表的分区操作。修改fe.conf文件中的参数并重启FE生效。您还可以在运行时执行以下命令使其生效:
MySQL protocol:`ADMIN SET FRONTEND CONFIG ("dynamic_partition_enable" = "true")`HTTP protocol:`curl --location-trusted -u username:password -XGET http://fe_host:fe_http_port/api/_set_config?dynamic_partition_enable=true`
要全局关闭动态分区,请将此参数设置为false。
dynamic_partition_check_interval_seconds
动态分区线程的执行频率默认为3600次(1小时),即每1小时调度一次。修改fe.conf文件中的参数并重启FE生效。您还可以在运行时修改以下命令:
MySQL protocol:`ADMIN SET FRONTEND CONFIG ("dynamic_partition_check_interval_seconds" = "7200")`HTTP protocol:`curl --location-trusted -u username:password -XGET http://fe_host:fe_http_port/api/_set_config?dynamic_partition_check_interval_seconds=432000`
将动态分区表和手动分区表相互转换
对于一个表,动态分区和手动分区可以自由转换,但不能同时存在,只能存在一种状态。
手动分区转换为动态分区
如果表在创建时没有进行动态分区,那么可以在运行时通过使用ALTER TABLE修改动态分区属性将其转换为动态分区,使用HELP ALTER TABLE可以看到一个示例。
启用动态分区特性后,Doris将不再允许用户手动管理分区,而是根据动态分区属性自动管理分区。
如果
dynamic_partition.start设置后,分区范围在动态分区开始偏移量之前的历史分区将被删除。
将动态分区转换为手动分区
可以通过执行ALTER TABLE tbl_name SET ("dynamic_partition.enable" = "false")来禁用动态分区特性,并将其转换为手动分区表。
禁用动态分区特性后,Doris将不再自动管理分区,用户必须使用ALTER TABLE手动创建或删除分区。
4、自动分区
Doris版本2.1开始支持自动分区。
自动分区特性支持在数据导入过程中自动检测对应的分区是否存在。如果不存在,则自动创建分区并正常导入。
自动分区功能主要解决用户期望根据某一列对表进行分区,但该列的数据分布分散或不可预测,因此在构建或调整表结构时难以准确创建所需的分区,或者分区数量太大,手动创建分区过于繁琐的问题。
以时间类型分区列为例,在Dynamic partition功能中,我们支持自动创建新的分区,以适应特定时间段的实时数据。对于实时用户行为日志等场景,该特性基本满足需求。但是,在更复杂的场景中,例如处理非实时数据,分区列与当前系统时间无关,并且包含大量离散值。这个时候为了提高效率我们想要根据这个列对数据进行分区,但是实际涉及到的数据可能无法提前掌握分区,或者预期需要的分区数量太大。在这种情况下,动态分区或者手工创建的分区都不能满足我们的需求,自动分区功能很好的覆盖了这样的需求。
假设我们的表DDL如下:
CREATE TABLE `DAILY_TRADE_VALUE`
(`TRADE_DATE` datev2 NOT NULL COMMENT '交易日期',`TRADE_ID` varchar(40) NOT NULL COMMENT '交易编号',......
)
UNIQUE KEY(`TRADE_DATE`, `TRADE_ID`)
PARTITION BY RANGE(`TRADE_DATE`)
(PARTITION p_2000 VALUES [('2000-01-01'), ('2001-01-01')),PARTITION p_2001 VALUES [('2001-01-01'), ('2002-01-01')),PARTITION p_2002 VALUES [('2002-01-01'), ('2003-01-01')),PARTITION p_2003 VALUES [('2003-01-01'), ('2004-01-01')),PARTITION p_2004 VALUES [('2004-01-01'), ('2005-01-01')),PARTITION p_2005 VALUES [('2005-01-01'), ('2006-01-01')),PARTITION p_2006 VALUES [('2006-01-01'), ('2007-01-01')),PARTITION p_2007 VALUES [('2007-01-01'), ('2008-01-01')),PARTITION p_2008 VALUES [('2008-01-01'), ('2009-01-01')),PARTITION p_2009 VALUES [('2009-01-01'), ('2010-01-01')),PARTITION p_2010 VALUES [('2010-01-01'), ('2011-01-01')),PARTITION p_2011 VALUES [('2011-01-01'), ('2012-01-01')),PARTITION p_2012 VALUES [('2012-01-01'), ('2013-01-01')),PARTITION p_2013 VALUES [('2013-01-01'), ('2014-01-01')),PARTITION p_2014 VALUES [('2014-01-01'), ('2015-01-01')),PARTITION p_2015 VALUES [('2015-01-01'), ('2016-01-01')),PARTITION p_2016 VALUES [('2016-01-01'), ('2017-01-01')),PARTITION p_2017 VALUES [('2017-01-01'), ('2018-01-01')),PARTITION p_2018 VALUES [('2018-01-01'), ('2019-01-01')),PARTITION p_2019 VALUES [('2019-01-01'), ('2020-01-01')),PARTITION p_2020 VALUES [('2020-01-01'), ('2021-01-01')),PARTITION p_2021 VALUES [('2021-01-01'), ('2022-01-01'))
)
DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10
PROPERTIES ("replication_num" = "1"
);
该表存储了大量业务历史数据,这些数据是根据事务发生的日期进行分区的。正如您在构建表时所看到的,我们需要提前手动创建分区。如果分区列的数据范围发生了变化,例如,在上面的表中添加了2022,我们需要通过ALTER-TABLE-PARTITION创建一个分区来对表分区进行更改。如果需要更改这些分区,或者在更细的粒度级别上进行细分,那么修改它们是非常繁琐的。此时,我们可以使用AUTO PARTITION重写表DDL。
5、Manual bucketing
如果使用分区,使用DISTRIBUTED…语句描述在每个分区内划分数据的规则。
如果不使用分区,它描述了在整个表中划分数据的规则。
也可以为每个分区单独指定一个bucket方法。
bucket列可以是多个列。对于聚合和唯一模型,它们必须是键列,而对于重复键数据模型,它们可以是键列和值列。Bucket列可以与Partition列相同,也可以不同。
桶列的选择涉及到查询吞吐量和查询并发性之间的权衡:
-
如果选择多个桶列,数据分布将更加均匀。如果查询条件不包括所有桶列的相等条件,则查询将触发对所有桶的同时扫描,从而提高查询吞吐量并减少单个查询的延迟。这种方法适用于高吞吐量、低并发性的查询场景。
-
如果只选择一个或几个桶列,则点查询可以触发只扫描一个桶。在这种情况下,当多点查询并发时,它们更有可能触发对不同桶的扫描,从而减少查询之间的IO影响(特别是当不同桶分布在不同磁盘上时)。因此,这种方法适用于高并发点查询场景。
5.1 桶数量和数据量的建议
-
一个表的tablet总数等于(Partition num * Bucket num)。
-
在不考虑扩展的情况下,建议每个表的 tablets 数量略大于集群的磁盘总数。
-
理论上单tablet的数据量没有上限和下限,但建议在1G - 10G范围内。如果单片数据量过小,数据聚合效果不好,元数据管理压力大。如果数据量太大,将不利于副本的迁移和补充,并且会增加重试失败操作(如
Schema Change或Rollup)的成本(重试这些操作的粒度是tablet)。 -
当数据量原则与tablets数量原则存在冲突时,建议优先考虑数据量原则
-
在创建表时,统一指定每个分区的桶数量。但是,在动态添加分区
ADD PARTITION时,可以单独指定新分区的桶号。此功能可以方便地用于处理数据缩减或扩展。 -
一旦指定了分区的桶的数量,就不能更改。因此,在确定桶数量时,需要提前考虑集群扩容的场景。例如,如果只有3个主机,每个主机有1个磁盘,并且桶号设置为3或更少,那么即使以后添加更多的机器,也无法提高并发性。
下面是一些示例:假设有10个BE,每个BE有一个磁盘。如果一张表的总大小为500MB,则可以考虑使用4-8个 tablets。5GB: 8-16个tablets。50GB: 32个tablets。对于500GB:建议对表进行分区,每个分区大小在50GB左右,每个分区16-32个tablets。对于5TB:建议对表进行分区,每个分区大小约为50GB,每个分区16-32个tablets。
可以使用SHOW DATA命令查看表的数据量,结果除以副本的数量,得到表的实际数据量。
5.2 随机分布
- 如果OLAP表中没有update类型的字段,将表的数据桶模式设置为
RANDOM可以避免严重的数据倾斜。当数据导入到表的相应分区时,单个导入作业的每批都会随机选择一个tablet进行写入。 - 当表的桶模式设置为
RANDOM时,没有桶列,不可能根据桶列的值只查询几个桶。对表的查询将同时扫描所有命中分区的bucket。此设置适合对整个表数据进行聚合查询分析,但不适合高并发点查询。 - 如果OLAP表的数据分布为Random distribution,则在数据导入时可以设置单片导入模式(将
load_to_single_tablet设置为true)。这样,在导入大容量数据时,一个任务在向对应分区写入数据时,只会写入一个tablet。这样可以提高数据导入的并发性和吞吐量,减少数据导入和压缩带来的写放大,保证集群的稳定性
6、Auto bucket
用户经常遇到各种问题,由于不正确的桶设置。为了解决这个问题,我们提供了一种自动化的方法来设置桶的数量,这种方法目前只适用于OLAP表。
当被CCR同步时,此功能将被禁用。如果此表被CCR复制,即PROPERTIES中包含
is_being_synced = true,则在show create table中显示为enabled,但实际上不会生效。当is_being_synced设置为false时,这些特性将恢复工作,但是is_being_synced属性仅适用于CCR外设模块,不应该在CCR同步期间手动设置。
在过去,用户在创建表时必须手动设置桶的数量,但是自动桶特性是Apache Doris动态投影桶的数量的一种方式,因此桶的数量总是保持在一个合适的范围内,用户不必担心桶的数量的细节。
为了清晰起见,本节将桶分为两个时期,初始桶和后续桶;初始和后续只是本文中用来清晰描述该特性的术语,没有初始或后续Apache Doris bucket。
正如我们在上面创建桶的章节中所知道的,BUCKET_DESC非常简单,但是您需要指定桶的数量;对于自动桶投影特性,BUCKET_DESC的语法直接将桶的数量更改为Auto,并添加一个新的Properties配置。
-- old version of the creation syntax for specifying the number of buckets
DISTRIBUTED BY HASH(site) BUCKETS 20-- Newer versions use the creation syntax for automatic bucket imputation
DISTRIBUTED BY HASH(site) BUCKETS AUTO
properties("estimate_partition_size" = "100G")
新的配置参数estimate_partition_size表示单个分区的数据量。这个参数是可选的,如果没有给出,Doris将使用estimate_partition_size的默认值为10GB。
如上所述,分区桶是物理级别的Tablet,为了获得最佳性能,建议Tablet的大小在1GB - 10GB之间。那么,自动桶形投影如何确保Tablet的尺寸在这个范围内呢?
总而言之,有几个原则:
- 如果整体数据量较小,不宜设置过高的桶数
- 如果整体数据量较大,则桶的数量应与磁盘块的总数相关,以充分利用每台BE机和每个磁盘的容量
属性
estimate_partition_size不支持alter
6.1 初始分桶推算
- 根据数据大小获取桶的个数
N。最初,我们将estimate_partition_size的值除以5(考虑到在Doris中以文本格式存储数据时,数据压缩比为5:1)。得到的结果是
(, 100MB), then take N=1[100MB, 1GB), then take N=2(1GB, ), then one bucket per GB
- 根据BE节点数量和每个BE节点的硬盘容量计算桶数M。
Where each BE node counts as 1, and every 50G of disk capacity counts as 1.The calculation rule for M is: M = Number of BE nodes * (Size of one disk block / 50GB) * Number of disk blocks.For example: If there are 3 BEs, and each BE has 4 disks of 500GB, then M = 3 * (500GB / 50GB) * 4 = 120.- 计算逻辑以获得桶的最终数量。
Calculate an intermediate value x = min(M, N, 128).If x < N and x < the number of BE nodes, the final bucket is y.The number of BE nodes; otherwise, the final bucket is x.
- x = max(x, autobucket_min_buckets) 这里的
autobucket_min_buckets是在Config中配置的(其中默认为1)
上述过程的伪代码表示如下:
int N = Compute the N value;
int M = compute M value;int y = number of BE nodes;
int x = min(M, N, 128);if (x < N && x < y) {return y;
}
return x;
记住上面的算法,让我们引入一些示例来更好地理解这部分逻辑。
case1:
Amount of data 100 MB, 10 BE machines, 2TB * 3 disks
Amount of data N = 1
BE disks M = 10* (2TB/50GB) * 3 = 1230
x = min(M, N, 128) = 1
Final: 1case2:
Data volume 1GB, 3 BE machines, 500GB * 2 disks
Amount of data N = 2
BE disks M = 3* (500GB/50GB) * 2 = 60
x = min(M, N, 128) = 2
Final: 2case3:
Data volume 100GB, 3 BE machines, 500GB * 2 disks
Amount of data N = 20
BE disks M = 3* (500GB/50GB) * 2 = 60
x = min(M, N, 128) = 20
Final: 20case4:
Data volume 500GB, 3 BE machines, 1TB * 1 disk
Data volume N = 100
BE disks M = 3* (1TB /50GB) * 1 = 60
x = min(M, N, 128) = 63
Final: 63case5:
Data volume 500GB, 10 BE machines, 2TB * 3 disks
Amount of data N = 100
BE disks M = 10* (2TB / 50GB) * 3 = 1230
x = min(M, N, 128) = 100
Final: 100case 6:
Data volume 1TB, 10 BE machines, 2TB * 3 disks
Amount of data N = 205
BE disks M = 10* (2TB / 50GB) * 3 = 1230
x = min(M, N, 128) = 128
Final: 128case 7:
Data volume 500GB, 1 BE machine, 100TB * 1 disk
Amount of data N = 100
BE disk M = 1* (100TB / 50GB) * 1 = 2048
x = min(M, N, 128) = 100
Final: 100case 8:
Data volume 1TB, 200 BE machines, 4TB * 7 disks
Amount of data N = 205
BE disks M = 200* (4TB / 50GB) * 7 = 114800
x = min(M, N, 128) = 128
Final: 200
6.2 后续分桶推算
以上是初始桶的计算逻辑。由于已经存在一定数量的分区数据,因此可以根据可用的分区数据量评估后续的分区。后续的桶大小是基于最多前7个分区的EMA1值来评估的,该值用作estimate_partition_size。此时,有两种方法可以计算分区桶,假设按天进行分区,计数到第一天的分区大小为S7,计数到第二天的分区大小为S6,以此类推到S1。
- 如果7天内分区数据每天严格递增,则取此时的趋势值。有6个值,它们是
S7 - S6 = delta1,
S6 - S5 = delta2,
...
S2 - S1 = delta6
这将产生ema(delta)值。然后,今天的estimate_partition_size = S7 + ema(delta)
- 不是第一类,这次直接取前几天均线的平均值。今天的 estimate_partition_size = EMA(S1, …, S7)
根据上述算法,可以计算出初始桶数和后续桶数。与以前只能指定固定数量的桶不同,由于业务数据的变化,有可能上一个分区的桶数与下一个分区的桶数不同,这对用户来说是透明的,用户不需要关心每个分区的桶数的确切数量,这种自动外推将使桶数更加合理。
7、常见问题
- 在较长的表创建语句中可能出现不完整的语法错误提示。以下是手动故障排除可能出现的一些语法错误:
- 语法结构错误。请仔细阅读HELP CREATE TABLE并检查相关语法结构。
- 保留字。当用户定义的名称遇到保留字时,需要将它们用反引号(``)括起来。建议对所有自定义名称使用此符号。
- 中文字符或全宽字符。非utf8编码的中文字符或隐藏的全宽字符(空格,标点符号等)可能导致语法错误。建议使用能显示不可见字符的文本编辑器进行检查。
- Failed to create partition [xxx]. Timeout
Doris根据分区粒度顺序创建表。当创建分区失败时,可能会出现此错误。即使没有使用分区,当表创建出现问题时,仍然可能报告“Failed to create partition”,因为正如前面提到的,Doris为没有指定分区的表创建了一个不可修改的默认分区。 - 创建表命令长时间没有返回结果。
相关文章:
)
Apache Doris 基础 -- 数据表设计(分区分桶)
Versions: 2.1 本文档主要介绍了Doris的表创建和数据分区,以及表创建过程中可能遇到的问题和解决方案。 1、基本概念 在Doris中,数据以表的形式被逻辑地描述。 1.1 Row & Column 表由行和列组成: 行:表示用户数据的单行;列:用于描述一行数据中的…...

题目:求0—7所能组成的奇数个数。
题目:求0—7所能组成的奇数个数。 There is no nutrition in the blog content. After reading it, you will not only suffer from malnutrition, but also impotence. The blog content is all parallel goods. Those who are worried about being cheated should…...

网络协议学习笔记
HTTP协议 简单介绍 HTTP属于应用层 HTTP可以简单的理解成类似json一样的文本封装,但是这是超文本,所以可以封装的不止有文本,还有音视频、图片等 请求方法 HTTP报文格式 三大部分 起始行:描述请求或响应的基本信息头部字段…...

C语言文件操作:打开关闭,读写
程序文件 源程序文件(后缀为.c) 目标文件(Windows环境后缀为.obj) 可执行文件(Windows环境后缀为.exe) fputc FILE* pf fopen("test.txt","w");if (pf NULL){printf("%s\n"…...
启智CV机器人,ROS,ubuntu 20.04 【最后一步有问题】
资料: https://wiki.ros.org/kinetic/Installation/Ubuntu https://blog.csdn.net/qq_44339029/article/details/120579608 装VM。 装ubuntu20.04 desktop.iso系统。 装vm工具: sudo apt update sudo dpkg --configure -a sudo apt-get autoremove o…...

React-生成随机数和日期格式化
生成随机数 uuid文档:https://github.com/uuidjs/uuid npm install uuid import {v4 as uuidV4} from uuid 使用: uuidV4() 日期格式化 dayjs文档:安装 | Day.js中文网 npm install dayjs import dayjs from dayjs...

11Linux学习笔记
Linux 实操篇 目录 文章目录 Linux 实操篇1.rtm包(软件)1.1 基本命令1.2 基本格式1.3安装rtm包1.4卸载rtm包 2.apt包2.1 基本命令结构2.2 常用选项2.3常用命令 1.rtm包(软件) 1.1 基本命令 1.2 基本格式 1.3安装rtm包 1.4卸载r…...
004 仿muduo实现高性能服务器组件_Buffer模块与Socket模块的实现
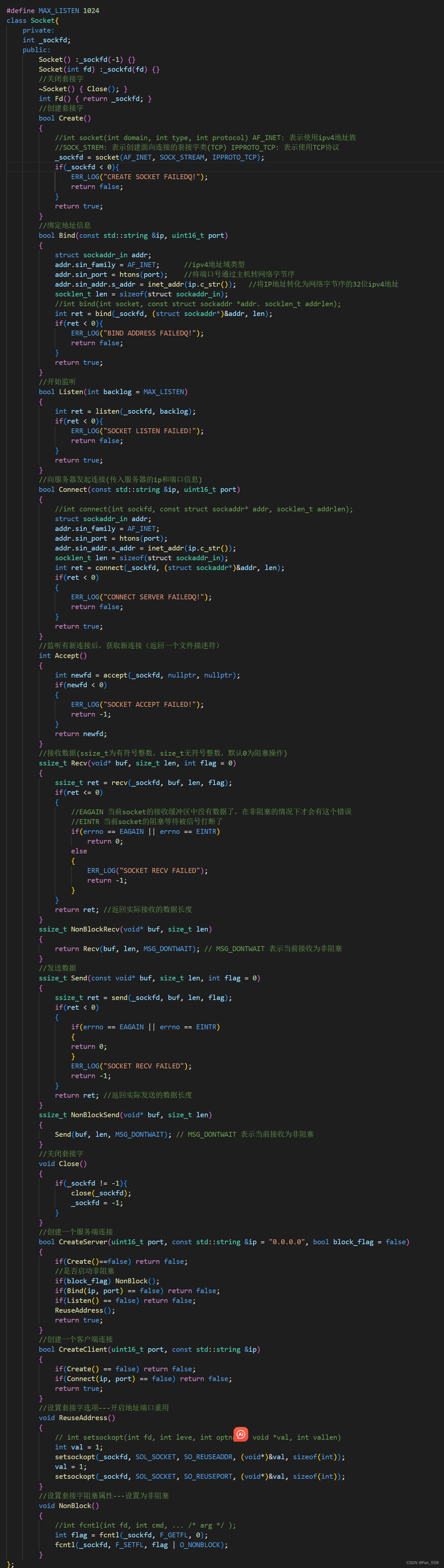
🌈个人主页:Fan_558 🔥 系列专栏:仿muduo 🌹关注我💪🏻带你学更多知识 文章目录 前言Buffer模块Socket模块 小结 前言 这章将会向你介绍仿muduo高性能服务器组件的buffer模块与socket模块的实…...
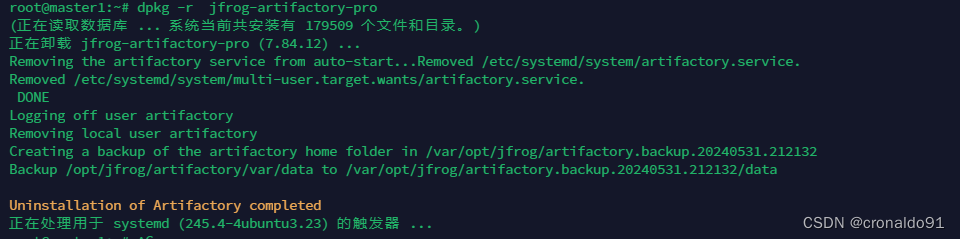
研发效能DevOps: Ubuntu 部署 JFrog 制品库
目录 一、实验 1.环境 2.Ubuntu 部署 JFrog 制品库 3.Ubuntu 部署 postgresql数据库 4.Ubuntu 部署 Xray 5. 使用JFrog 增删项目 二、问题 1.Ubuntu 如何通过apt方式部署 JFrog 制品库 2.Ubuntu 如何通过docker方式部署 JFrog 制品库 3.安装jdk报错 4.安装JFrog Ar…...

hadoop学习笔记
hadoop集群搭建 hadoop摘要 Hadoop 是一个开源的分布式存储和计算框架,旨在处理大规模数据集并提供高可靠性、高性能的数据处理能力。它主要包括以下几个核心组件: Hadoop 分布式文件系统(HDFS):HDFS 是 Hadoop 的分布…...

使用dockerfile快速构建一个带ssh的docker镜像
不多说先给代码 FROM ubuntu:22.04 # 基础镜像 可替换为其他镜像 USER root RUN echo root:root |chpasswd RUN apt-get update -y \&& apt-get install -y git wget curl RUN apt-get install -y openssh-server vim && apt clean \&& rm -rf /tmp/…...
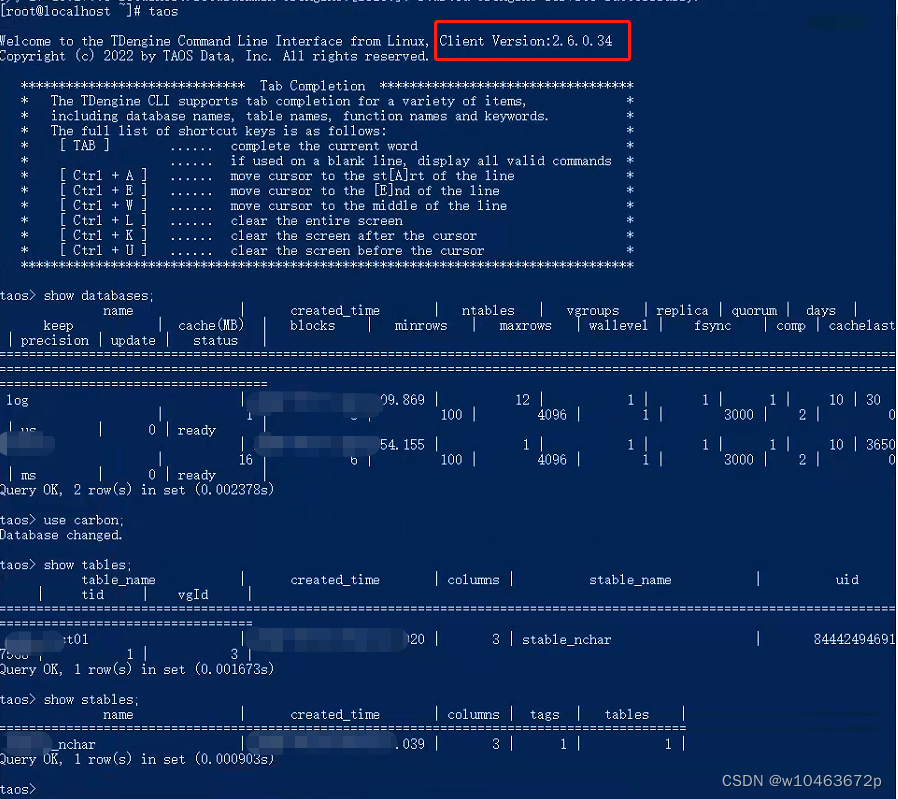
linux部署运维1——centos7.9离线安装部署涛思taos2.6时序数据库TDengine
在实际项目开发过程中,并非一直都使用关系型数据库,对于工业互联网类型的项目来说,时序型数据库也是很重要的一种,因此掌握时序数据库的安装配置也是必要的技能,不过对于有关系型数据库使用的开发工作者来说࿰…...

Linux shell编程学习笔记51: cat /proc/cpuinfo:查看CPU详细信息
0 前言 2024年的网络安全检查又开始了,对于使用基于Linux的国产电脑,我们可以编写一个脚本来收集系统的有关信息。对于中央处理器CPU比如,我们可以使用cat /proc/cpuinfo命令来收集中央处理器CPU的信息。 1. /proc/cpuinfo 保存了系统的cpu…...

Ps:调整画笔工具
调整画笔工具 Adjustment Brush Tool可以将选区、创建蒙版和应用调整的传统工作流程合并为一个步骤,简化了对图像进行非破坏性局部调整的操作。 快捷键:B 调整画笔工具是 Photoshop 2024 年 5 月版(25.9 版)新增的工具。 ◆ ◆ …...
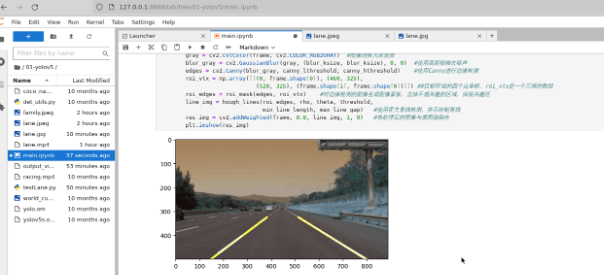
香橙派 AIpro上手体验并验证车道线识别算法
香橙派 AIpro上手体验并验证车道线识别算法 1.前言 最近入手了一块香橙派AIpro,体验了一下,感觉还不错,在这里分享给大家,大家可以做个参考。 2.开箱 整套产品包含一块主板、一个电源插头和一条双端Type-C的数据线,…...

为啥装了erlang,还报错erl: command not found?
转载说明:如果您喜欢这篇文章并打算转载它,请私信作者取得授权。感谢您喜爱本文,请文明转载,谢谢。 问题背景: 在一台不通外网的服务器上装rabbitmq,然后在启动的时候,遇到了报错 “/usr/lib/…...

容器技术基础理论与常用命令:必知必会,效率翻倍!
如何利用容器技术提升你的工作效率?掌握基础理论和常用命令是必不可少的,本文将为你全面介绍容器技术,并教你必知必会的技能,让你工作、学习效率翻倍,对于网络安全工作者也是必不可少的技能! 0. 引言 学习…...

ChatGPT Edu版本来啦:支持GPT-4o、自定义GPT、数据分析等
5月31日,OpenAI在官网宣布,推出ChatGPT Edu版本。 据悉,这是一个专门为大学校园提供的ChatGTP,支持GPT-4o、网络搜索、自定义GPT、数据分析、代码生成等功能,可以极大提升学生、老师的学习质量和教学效率。 目前&…...

Spark RDD案例
Apache Spark中的RDD(Resilient Distributed Dataset)是一个不可变、分布式对象集合,它允许用户在大型集群上执行并行操作。虽然RDD在Spark的早期版本中非常核心,但随着DataFrame和Dataset的引入,RDD的使用在某些场景下…...

【线性表 - 数组和矩阵】
数组是一种连续存储线性结构,元素类型相同,大小相等,数组是多维的,通过使用整型索引值来访问他们的元素,数组尺寸不能改变。 知识点数组与矩阵相关题目 # 知识点 数组的优点: 存取速度快 数组的缺点: 事先必须知道…...

接口实现第二步骤
接口实现流程模块化路由 -> API 接口规范文档定义模型类 -> 数据库表 (数据库设计文档)在 crud 文件夹里面创建文件,封装操作数据库的方法在路由处理函数里面调用 crud 封装好的方法,响应结果定义模型类规范基类,…...

解决 Antigravity 新谷歌账户无法登录的问题
最近在使用 Antigravity 时遇到一个奇葩问题,折腾了大半天终于解决,特意记录下来,希望能帮到有同样困扰的小伙伴 —— 老谷歌免费账户能正常登录 Antigravity,但新注册的谷歌 Pro 账户(和老账户一样都是美国地区&#…...

CLI为什么突然爆了?一文讲清 Skill、MCP、CLI 的真实关系
导读最近可以明显看到一个变化:钉钉、飞书、企业微信,开始陆续开放 CLI 能力 越来越多团队,不再只讨论提示词,而是在做一件更实际的事:让 AI 直接参与执行很多人开始有几个共通疑问:CLI 到底是什么Skill 和…...

PADS VX2.8 极坐标布局技巧:圆形灯板LED高效排列指南
1. 极坐标布局在圆形灯板设计中的核心价值 第一次接触圆形LED灯板设计时,我被密密麻麻的元件排列搞得头晕眼花。传统直角坐标系下,要精确控制每个LED灯珠的间距和角度,需要反复计算XY坐标,效率极低。直到发现PADS VX2.8的极坐标功…...

Ohm模块化扩展与面向对象语法继承:构建可维护解析器的终极指南
Ohm模块化扩展与面向对象语法继承:构建可维护解析器的终极指南 【免费下载链接】ohm A library and language for building parsers, interpreters, compilers, etc. 项目地址: https://gitcode.com/gh_mirrors/oh/ohm Ohm是一个强大的解析器构建库和语言&am…...
)
FALCON: Fast Autonomous Aerial ExplorationUsing Coverage Path Guidance(覆盖路径引导的快速自主空中探索)
创新点:提出一种基于连接性的增量式空间分解和连接图构造方法,捕获环境拓扑并促进有效的探测覆盖路径规划提出一种分层的探索规划方法,生成合理的覆盖路径作为全局指导,并优化局部边界访问顺序,保持覆盖路径的意图。提…...

AllCells细胞原料解析:Leukopak与PBMC在CGT中的应用【曼博生物供应人原代细胞】
AllCells细胞原料体系解析:Leukopak与PBMC在CGT中的应用 摘要: AllCells作为DLS体系中的重要品牌,提供GMP与RUO级人源细胞原料,包括Leukopak与PBMC等产品类型,广泛应用于细胞与基因治疗研发及生产流程。 关键词&#x…...

才聚:国内最早从事PMP培训的机构
在项目管理职业资格认证领域,PMP(项目管理专业人士)证书已成为衡量项目经理能力的重要标准。面对市场上众多的PMP培训机构,如何选择一个真正有历史沉淀、专业实力和考试服务能力的机构,成为考生最关心的问题。本文将从…...

AI 模型训练中的梯度裁剪技巧
AI模型训练中的梯度裁剪技巧 在深度学习的模型训练过程中,梯度爆炸是一个常见的问题,它会导致模型参数更新过大,进而使训练过程变得不稳定甚至无法收敛。为了解决这一问题,梯度裁剪(Gradient Clipping)技术…...

GHelper终极指南:免费解放华硕笔记本性能的完整解决方案
GHelper终极指南:免费解放华硕笔记本性能的完整解决方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, …...