【数据结构】六种排序实现方法及区分比较
文章目录
- 前言
- 插入排序
- 希尔排序
- 选择排序
- 堆排序
- 快速排序
- 冒泡排序
- 总结
前言
众所周知,存在许多种排序方法,作为新手,最新接触到的就是冒泡排序,这种排序方法具有较好的教学意义,但是实用意义不高,原因就在于它的时间复杂度太高了,为 O(n^2) 即便后来我们使用 flag 去优化它,也不过也不过少了一点,如果序列完全倒序,就没什么用。
所以为了使代码运行效率更高,人们就设计了许多种排序方法,这里笔者将比较常用的六种进行介绍,并对其的一些使用情景及效率进行一下比较。
默认实现时都为升序
- 插入排序
- 希尔排序
- 选择排序
- 堆排序
- 冒泡排序
- 快速排序
为了等下便于比较我们可以建立多个存有相同大小的数组,利用 c l o c k ( ) clock() clock() 来记录排序十万或一百万数据所需的时间,这样就可以直观地比较了,代码如下
void TestOP()
{srand((unsigned)time(0));const int N = 100000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);int* a3 = (int*)malloc(sizeof(int) * N);int* a4 = (int*)malloc(sizeof(int) * N);int* a5 = (int*)malloc(sizeof(int) * N);int* a6 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; i++){a1[i] = rand();a2[i] = a1[i];a3[i] = a1[i];a4[i] = a1[i];a5[i] = a1[i];a6[i] = a1[i];}int begin1 = clock();InsertSort(a1, N);int end1 = clock();int begin2 = clock();//ShellSort(a2, N);int end2 = clock();int begin3 = clock();//SelectSort(a3, N);int end3 = clock();int begin4 = clock();//HeapSort(a4, N);int end4 = clock();int begin5 = clock();//QuickSort(a5, N);int end5 = clock();int begin6 = clock();//BubbleSort(a6, N);int end6 = clock();printf("InsertSort:%d\n", end1 - begin1);printf("ShellSort:%d\n", end2 - begin2);printf("SelectSort:%d\n", end3 - begin3);printf("HeapSort:%d\n", end4 - begin4);printf("QuickSort:%d\n", end5 - begin5);printf("BubbleSort:%d\n", end6 - begin6);free(a1);free(a2);free(a3);free(a4);free(a5);free(a6);
}
插入排序
插入排序的平均时间复杂度为 O ( n 2 ) O(n^2) O(n2),最坏情况下的时间复杂度也为 O ( n 2 ) O(n^2) O(n2)。
关于希尔排序的时间复杂度,是很难计算的。要准确计算希尔排序的时间复杂度,需要考虑具体的增量序列和数据分布情况。不同的增量序列可能会导致不同的时间复杂度。
需要注意的是,这些时间复杂度估计是基于理论分析和实验结果得出的,但实际情况可能会有所不同。在实际应用中,希尔排序的性能还会受到硬件、数据特点等因素的影响。
插入排序的思想就是把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列。

在插入排序的过程中,每次插入一个元素时,都需要在已经有序的序列中找到合适的位置插入该元素。这个过程需要进行比较和移动操作,因此插入排序的时间复杂度主要取决于比较和移动操作的次数。
具体思路:
- 从左往右插入排序
- 建立临时变量 e n d end end标志当前的有序末尾
- 不断将 e n d + 1 end+1 end+1的值插入到有序序列中
//插入排序,升序
// 时间复杂度:O(N^2) 什么情况最坏:逆序
// 最好:顺序有序,O(N)
void InsertSort(int* a, int n)
{for (int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];while (end >= 0){if (tmp < a[end]){a[end + 1] = a[end];end--;}elsebreak;}a[end + 1] = tmp;}
}
我们尝试排序一下十万个数据,用时3点多秒,还算可以
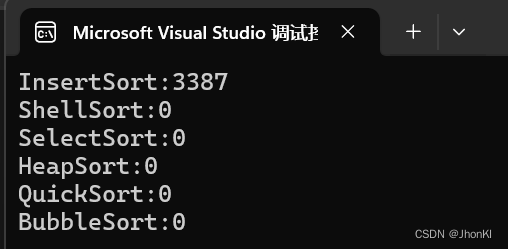
但是当我们把数据改成一百万个时,笔者等了两分多种都没出结果,可见这个插入排序的漏洞还是很大的
希尔排序
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至 1 时,整个文件恰被分成一组,算法便终止。
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。

希尔排序的具体步骤如下:
- 选择一个增量序列 t1,t2,…,tk,其中 ti > tj, tk = 1;
- 按增量序列个数 k,对序列进行 k 趟排序;
- 每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
希尔排序的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn),空间复杂度为 O ( 1 ) O(1) O(1)。希尔排序是一种不稳定的排序算法。
//希尔排序
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;for (size_t i = 0; i < n - gap; i++){int end = i;int tmp = a[end + gap];while (end >= 0){if (a[end] > tmp){a[end + gap] = a[end];end -= gap;}else{break;}a[end + gap] = tmp;}}}
}
如果比较难理解可以看下图,假设我们当前是 g a p = 3 gap = 3 gap=3,就相当于每三个元素提取出来一个放进一个数组里,这样的数组有3个
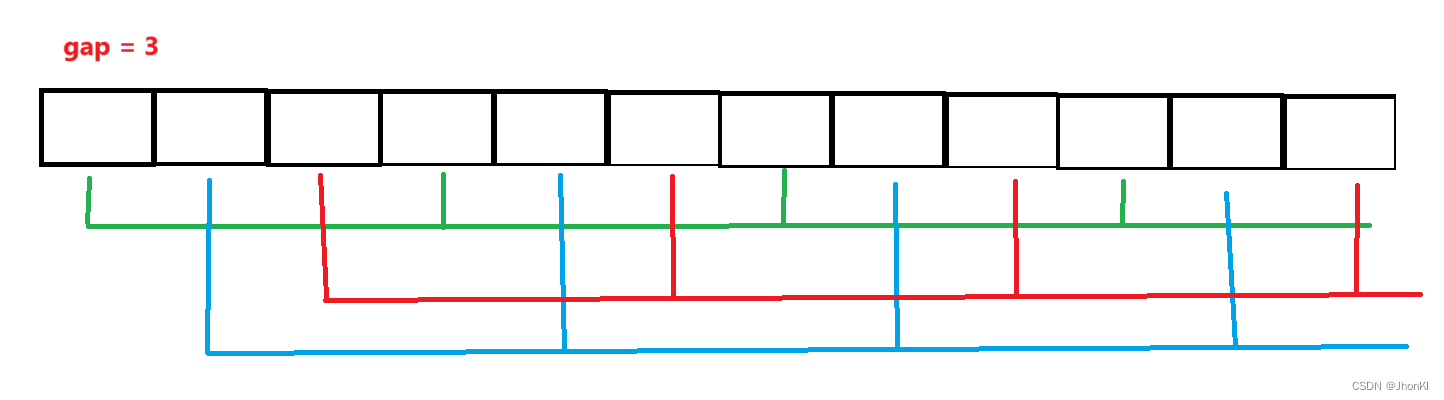
之后在对这三个元素分别进行插入排序,这样的好处是分担了大量元素一次排序的性能,并且在多次这样预排序后会整个数组都趋近于有序,这样一来,越后面的排序基本就不需要交换了,性能也就更高。
可以直观感受一下对十万个数据两者的差距
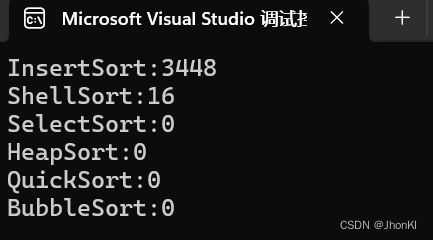
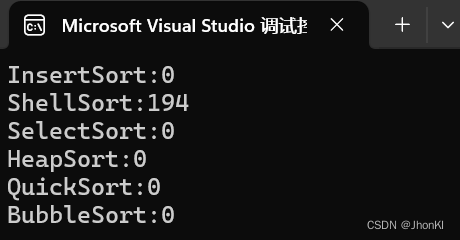
即便改成了排序一百万个数据,也只消耗了0.2秒。
选择排序
选择排序(Selection Sort)是一种简单直观的排序算法。它首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
选择排序的基本思想是:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。

选择排序的具体步骤如下:
- 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置;
- 然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾;
- 以此类推,直到所有元素均排序完毕。
选择排序的时间复杂度为 O ( n 2 ) O(n^2) O(n2),空间复杂度为 O ( 1 ) O(1) O(1)。选择排序是一种不稳定的排序算法。
//选择排序
void SelectSort(int* a, int n)
{int begin = 0;int end = n - 1;while (begin < end){int mini = begin;int maxi = begin;for (size_t i = begin + 1; i < end; i++){if (a[i] < a[mini])mini = i;if (a[i] > a[maxi])maxi = i;}Swap(&a[mini], &a[begin]);if (begin == maxi)maxi = mini;Swap(&a[maxi], &a[end]);begin++;end--;}
}
但是这种算法的时间复杂度还是太高,要比较和交换的次数太多了,相比于冒泡排序,这种甚至连教学意义都没有,仅仅需要了解一下其中的思想就行了,一般代码中都不会用这种排序。
堆排序
堆排序(Heap Sort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
堆排序的基本思想是:将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余 n-1 个元素重新构造成一个堆,这样会得到 n 个元素的次小值。如此反复执行,便能得到一个有序序列了。

堆排序的具体步骤如下:
- 构建初始堆:将待排序序列构造成一个大顶堆;
- 交换堆顶元素和末尾元素:将堆顶元素与末尾元素进行交换;
- 调整堆结构:对交换后的堆进行调整,使其重新成为一个大顶堆;
- 重复步骤 2 和 3,直到整个序列有序。
堆排序的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn),空间复杂度为 O ( 1 ) O(1) O(1)。堆排序是一种不稳定的排序算法。
建堆的过程可以通过从最后一个非叶子节点开始,逐步向上调整堆的结构来实现。这个过程的时间复杂度为 O ( n ) O(n) O(n),其中 n n n是待排序元素的数量。
排序的过程是通过不断地将堆顶元素与末尾元素交换,并调整堆结构来实现的。每次交换和调整堆结构的时间复杂度为 O ( l o g n ) O(logn) O(logn),因为堆的高度为 l o g n logn logn。
因此,堆排序的总时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)。
代码实现如下
//堆排序
void AdjustDown(int* a, int parent, int n)
{//建大堆int child = parent * 2 + 1;while (child < n){if (child + 1 < n && a[child + 1] > a[child])child++;if (a[parent] < a[child]){Swap(&a[parent], &a[child]);parent = child;child = parent * 2 + 1;}else{break;}}
}void HeapSort(int* a, int n)
{//建大堆 O(n^2)for (int i = (n - 1 - 1) / 2 ; i > 0; i--){AdjustDown(a, i, n);}int end = n - 1;//O(logn)while (end > 0){Swap(&a[end], &a[0]);AdjustDown(a, 0, end);end--;}
}
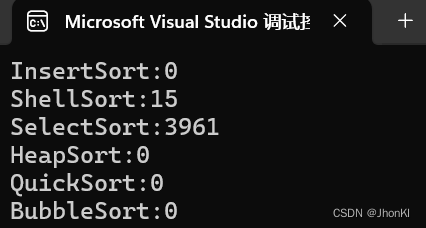
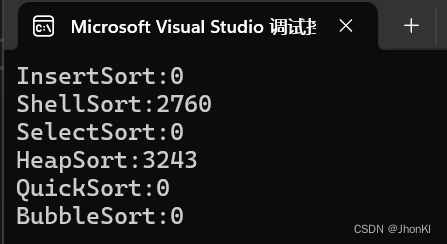
在十万个数据下,它进行的也是比较快的

更改为1000万个数据后,堆排序的性能还是可以的,仅次于希尔排序
快速排序
快速排序(Quick Sort)是一种常用的排序算法。它的平均时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn),空间复杂度为 O ( l o g n ) O(logn) O(logn)。快速排序的基本思想是通过选择一个基准元素,将数组分为两部分,使得左边的元素都小于等于基准元素,右边的元素都大于等于基准元素。然后,对左右两部分分别进行快速排序,直到整个数组有序。
快速排序的时间复杂度主要取决于划分的过程。
在快速排序中,每次选择一个基准元素,将数组分为两部分,使得左边的元素都小于等于基准元素,右边的元素都大于等于基准元素。这个过程的时间复杂度为 O ( n ) O(n) O(n),其中 n n n是数组的长度。
然后,对左右两部分分别进行快速排序,这个过程的时间复杂度也为 O ( n ) O(n) O(n)。
因此,快速排序的总时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)。
需要注意的是,这是快速排序的平均时间复杂度。在最坏情况下,快速排序的时间复杂度可能会达到 O ( n 2 ) O(n^2) O(n2),例如当数组已经有序时。但是,在大多数情况下,快速排序的时间复杂度都非常接近 O ( n l o g n ) O(nlogn) O(nlogn)。

快速排序的具体步骤如下:
- 选择一个基准元素,可以选择数组的第一个元素、最后一个元素或中间元素等。
- 将数组分为两部分,使得左边的元素都小于等于基准元素,右边的元素都大于等于基准元素。可以通过交换元素的位置来实现。
- 对左右两部分分别进行快速排序,直到整个数组有序。
快速排序的优点是平均时间复杂度较低,空间复杂度也较低,而且实现简单。但是,快速排序在最坏情况下的时间复杂度为 O ( n 2 ) O(n^2) O(n2),当数组已经有序或接近有序时,快速排序的性能会下降。为了避免这种情况,可以选择随机选择基准元素或使用其他改进的快速排序算法。
void QuickSort(int* a, int left, int right)
{if (left >= right){return NULL;}int ret = left;int begin = left;int end = right;while (begin < end){while (end > begin && a[end] >= a[ret])end--;while (end > begin && a[begin] <= a[ret])begin++;Swap(&a[end], &a[begin]);}Swap(&a[begin], &a[ret]);QuickSort(a, left, begin - 1);QuickSort(a, begin + 1, right);
}
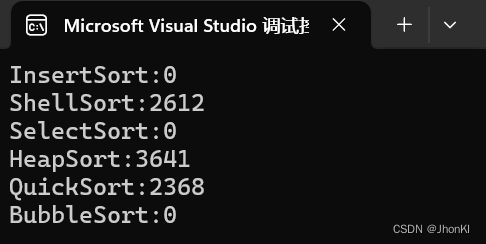
这里利用递归的方法不断对左右两边进行排序,直至有序
但是我们可以发现上述过程还是可以优化的
- 当数组元素小于10个时,用插入排序(注意插入排序的起始位置)
- 每次都是那最左边的元素作为基准元素,在整个数组趋于有序时定然左少右多,找左右中元素中间的那个值作为基准元素更有效
//快速排序
int midi(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[mid] > a[left]){if (a[mid] < a[right])return mid;else{if (a[left] > a[right])return left;elsereturn right;}}else{if (a[mid] > a[right])return mid;else{if (a[left] < a[right])return left;elsereturn right;}}
}
void QuickSort(int* a, int left, int right)
{if (left >= right){return NULL;}if ((right - left + 1) < 10){InsertSort(a+left, right - left + 1);//加上left,从第left个元素开始}else{int mid = midi(a, left, right);Swap(&a[mid], &a[left]);int ret = left;int begin = left;int end = right;while (begin < end){while (end > begin && a[end] >= a[ret])end--;while (end > begin && a[begin] <= a[ret])begin++;Swap(&a[end], &a[begin]);}Swap(&a[begin], &a[ret]);QuickSort(a, left, begin - 1);QuickSort(a, begin + 1, right);}
}
冒泡排序
冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地走访要排序的数列,一次比较两个数据元素,如果顺序不对则进行交换,并一直重复这样的走访操作,直到没有要交换的数据元素为止。
冒泡排序的基本思想是:通过相邻元素之间的比较和交换,将最大的元素逐步“冒泡”到数列的末尾。具体来说,冒泡排序的每一轮都会比较相邻的两个元素,如果它们的顺序错误,就将它们交换位置。这样,每一轮都会将一个最大的元素“冒泡”到数列的末尾。经过若干轮比较和交换后,整个数列就会变得有序。

冒泡排序的时间复杂度为 O ( n 2 ) O(n^2) O(n2),空间复杂度为 O ( 1 ) O(1) O(1)。它是一种稳定的排序算法,即相同元素的相对顺序在排序前后不会改变。
冒泡排序的优点是实现简单,容易理解。缺点是效率较低,对于大规模数据的排序不太适用。在实际应用中,冒泡排序通常用于对小规模数据进行排序,或者作为其他排序算法的辅助步骤。
void BubbleSort(int* a, int n)
{for (size_t i = 0; i < n - 1; i++){int flag = 0;for (size_t j = 0; j < n - 1 - i; j++){if (a[j] > a[j + 1])Swap(&a[j], &a[j + 1]);flag = 1;}if (flag == 0)break;}
}
排序一万个数据就可以看到冒泡与别的排序方法的差距
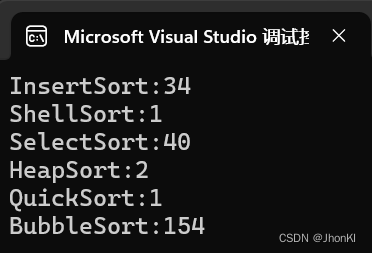
笔者尝试排序十万个,可是冒泡排序等了2分钟都没出结果就不管它了,别的排序算法比较如下
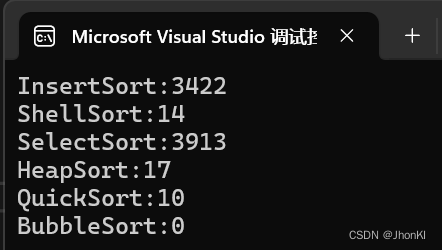
总结
以下是对插入排序、希尔排序、选择排序、堆排序、快速排序和冒泡排序的比较分析总结:
-
插入排序:
- 基本思想:将未排序元素逐个插入已排序序列的合适位置。
- 时间复杂度:平均情况和最坏情况均为 O ( n 2 ) O(n^2) O(n2)。
- 空间复杂度: O ( 1 ) O(1) O(1)。
- 稳定性:稳定。
- 优点:简单直观,适用于小规模数据。
- 缺点:效率较低。
-
希尔排序:
- 基本思想:通过将数组分成较小的子数组,并对每个子数组进行插入排序来改进插入排序。
- 时间复杂度:取决于增量序列的选择,平均情况和最坏情况的时间复杂度较为复杂。
- 空间复杂度: O ( 1 ) O(1) O(1)。
- 稳定性:不稳定。
- 优点:在某些情况下比插入排序更快。
- 缺点:增量序列的选择对性能影响较大。
-
选择排序:
- 基本思想:在未排序序列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
- 时间复杂度:平均情况和最坏情况均为 O ( n 2 ) O(n^2) O(n2)。
- 空间复杂度: O ( 1 ) O(1) O(1)。
- 稳定性:不稳定。
- 优点:简单直观,交换次数较少。
- 缺点:效率较低。
-
堆排序:
- 基本思想:利用堆这种数据结构来进行排序。堆是一种完全二叉树,其每个节点的值都大于等于(或小于等于)其左右子节点的值。
- 时间复杂度:平均情况和最坏情况均为 O ( n l o g n ) O(nlogn) O(nlogn)。
- 空间复杂度: O ( 1 ) O(1) O(1)。
- 稳定性:不稳定。
- 优点:效率较高。
- 缺点:实现相对复杂。
-
快速排序:
- 基本思想:通过选择一个基准元素,将数组分为两部分,使得左边的元素都小于等于基准元素,右边的元素都大于等于基准元素。然后,对左右两部分分别进行快速排序,直到整个数组有序。
- 时间复杂度:平均情况为 O ( n l o g n ) O(nlogn) O(nlogn),最坏情况为 O ( n 2 ) O(n^2) O(n2)。
- 空间复杂度:平均情况为 O ( l o g n ) O(logn) O(logn),最坏情况为 O ( n ) O(n) O(n)。
- 稳定性:不稳定。
- 优点:效率高,平均情况下性能较好。
- 缺点:最坏情况下时间复杂度较高。
-
冒泡排序:
- 基本思想:通过反复比较相邻的元素并交换它们的位置,将最大的元素逐步“冒泡”到数组的末尾。
- 时间复杂度:平均情况和最坏情况均为 O ( n 2 ) O(n^2) O(n2)。
- 空间复杂度: O ( 1 ) O(1) O(1)。
- 稳定性:稳定。
- 优点:简单易懂,容易实现。
- 缺点:效率较低。
综上所述,不同的排序算法在时间复杂度、空间复杂度、稳定性和实现难度等方面存在差异。在实际应用中,应根据具体情况选择合适的排序算法。对于小规模数据,插入排序和冒泡排序可能是简单有效的选择;对于大规模数据,快速排序和堆排序通常具有较好的性能。希尔排序和选择排序在某些情况下也可能表现良好
相关文章:
【数据结构】六种排序实现方法及区分比较
文章目录 前言插入排序希尔排序选择排序堆排序快速排序冒泡排序总结 前言 众所周知,存在许多种排序方法,作为新手,最新接触到的就是冒泡排序,这种排序方法具有较好的教学意义,但是实用意义不高,原因就在于…...

QT之QTableWidget详细介绍
本文来自于学习QT时遇到QTableWidget类时进行总结的知识点,涵盖了QTableWidget主要函数。本人文笔有限,欢迎大家评论区讨论。 一、QTableWidget介绍 QTableWidget 类是 Qt 框架中的一个用于展示和编辑二维表格数据的控件。它是对 QTableView 和 QStand…...
mac电脑安卓设备文件传输助手:MacDroid pro 中文激活版
MacDroid Pro是一款专为Mac电脑和Android设备设计的软件,旨在简化两者之间的文件传输和数据管理,双向文件传输:支持从Mac电脑向Android设备传输文件,也可以将Android设备上的文件轻松传输到Mac电脑上。完整的文件访问和管理&#…...
车流量监控系统
1.项目介绍 本文档是对于“车流量检测平台”的应用技术进行汇总,适用于此系统所有开发,测试以及使用人员,其中包括设计背景,应用场景,系统架构,技术分析,系统调度,环境依赖…...

LAMP集群分布式实验报告
前景: 1.技术成熟度和稳定性: LAMP架构(Linux、Apache、MySQL、PHP)自1998年提出以来,经过长时间的发展和完善,已经成为非常成熟和稳定的Web开发平台。其中,Linux操作系统因其高度的灵活性和稳…...

vue3中函数必须有返回值么?
在 Vue 3 中,特别是涉及到Composition API的使用时,setup() 函数确实必须有返回值。setup() 函数是组件的入口点,它的返回值会被用来决定哪些数据和方法是可被模板访问的。返回的对象中的属性和方法可以直接在模板中使用。如果setup()没有返回…...

经常用到的函数
创建文件夹和删除文件夹的函数 def make_dirs(*dirs):for new_dir in dirs:if not os.path.exists(new_dir):try:os.makedirs(new_dir)except RuntimeError:return Falsereturn Truedef remove_files(file_path_list):""" 删除列表中指定路径文件Args:file_pat…...
vue3学习(六)
前言 接上一篇学习笔记,今天主要是抽空学习了vue的状态管理,这里学习的是vuex,版本4.1。学习还没有学习完,里面有大坑,难怪现在官网出的状态管理用Pinia。 一、vuex状态管理知识点 上面的方式没有写全,还有…...

[数据集][目标检测]猫狗检测数据集VOC+YOLO格式8291张2类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):8291 标注数量(xml文件个数):8291 标注数量(txt文件个数):8291 标注…...

简单模拟实现shell(Linux)
目录 前言 展示效果 实现代码 前言 该代码模拟了shell的实现,也就是解析类似于“ls -a -l"的命令,当我们启动我们自己写的shell的可执行程序时,我们输入"ls"的命令,也可以展示出在shell中输入&…...

SQL深度解析:从基础到高级应用
SQL(Structured Query Language)是用于管理关系型数据库的语言,广泛应用于数据管理、分析和查询。本文将详细介绍SQL的基础知识、高级特性以及一些常见的代码示例,帮助您全面掌握SQL的应用。 一、SQL基础语法 数据库操作 创建数据…...
乡村振兴与脱贫攻坚相结合:巩固拓展脱贫攻坚成果,推动乡村全面振兴,建设更加美好的乡村生活
目录 一、引言 二、巩固拓展脱贫攻坚成果 1、精准施策,确保稳定脱贫 2、强化政策支持,巩固脱贫成果 3、激发内生动力,促进持续发展 三、推动乡村全面振兴 1、加快产业发展,增强乡村经济实力 2、推进乡村治理体系和治理能力…...
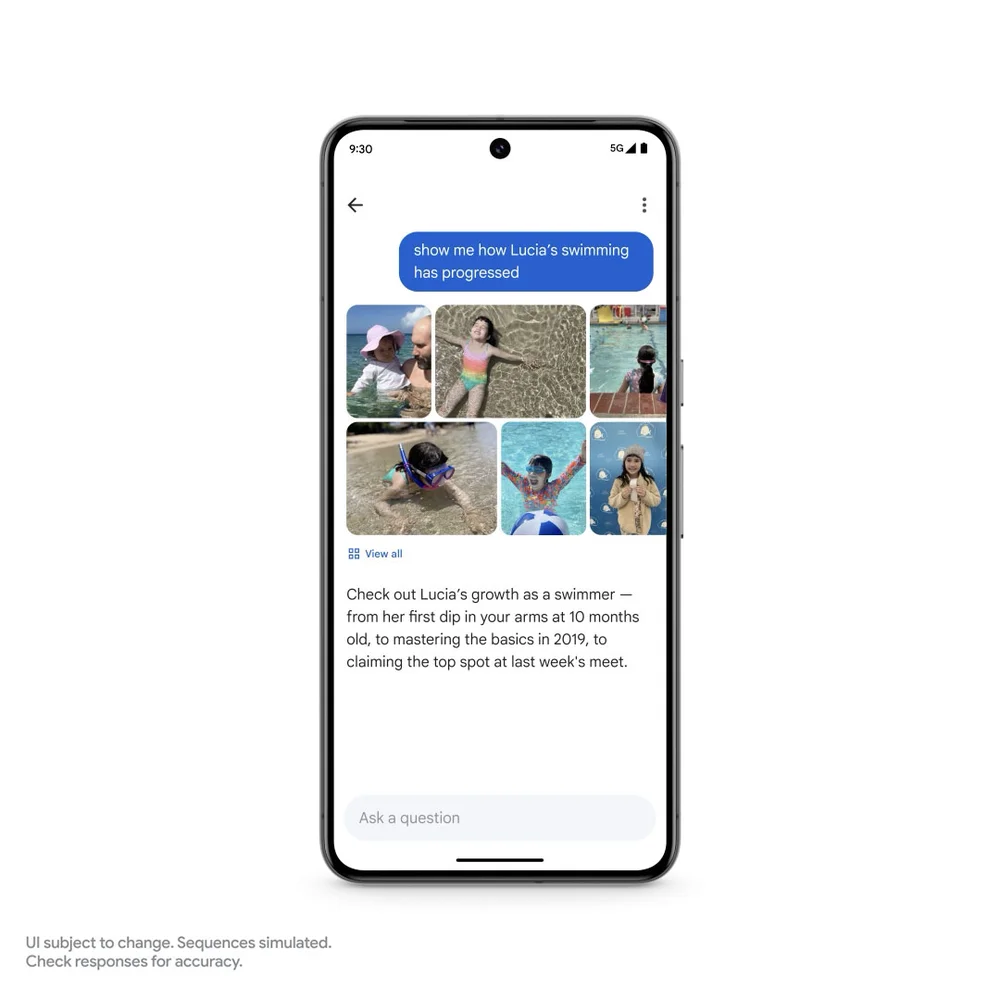
[AI Google] Google I/O 2024: 为新一代设计的 I/O
编辑注:以下是 Sundar Pichai 在 I/O 2024 上讲话的编辑版,并包含了更多在舞台上宣布的内容。查看我们收藏中的所有公告。 Google 完全进入了我们的 Gemini 时代。 在开始之前,我想反思一下我们所处的这一刻。我们已经在 AI 上投资了十多年…...
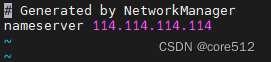
CentOS配置DNS
1.打开/etc/resolv.conf文件 sudo vi /etc/resolv.conf2.添加配置 nameserver 114.114.114.1143.保存并关闭文件。 4.为了确保配置生效,重启网络服务或重启系统。例如: 重启网络: sudo systemctl restart network重启系统: …...
ArcGIS空间数据处理、空间分析与制图;PLUS模型和InVEST模型的原理,参量提取与模型运行及结果分析;土地利用时空变化以及对生态系统服务的影响分析
工业革命以来,社会生产力迅速提高,人类活动频繁,此外人口与日俱增对土地的需求与改造更加强烈,人-地关系日益紧张。此外,土地资源的不合理开发利用更是造成了水土流失、植被退化、水资源短缺、区域气候变化、生物多样性…...

Linux基于V4L2的视频捕捉
简介 linux环境使用V4l2实现摄像头捕捉,界面流畅播放并可以保存图片到本地。 代码 void VideoCapture::run() {qDebug() << "VideoCapture start";// 打开设备int fd open("/dev/video0", O_RDWR);if(fd < 0){qDebug("video设…...

ECS搭建2.8版本的redis
要在ECS(Elastic Compute Service)上手动搭建Redis 2.8版本,你可以按照以下步骤操作: 步骤1:更新系统和安装依赖 首先,登录到你的ECS实例,确保系统是最新的并安装必要的依赖包: s…...

[机器学习]GPT LoRA 大模型微调,生成猫耳娘
往期热门专栏回顾 专栏描述Java项目实战介绍Java组件安装、使用;手写框架等Aws服务器实战Aws Linux服务器上操作nginx、git、JDK、VueJava微服务实战Java 微服务实战,Spring Cloud Netflix套件、Spring Cloud Alibaba套件、Seata、gateway、shadingjdbc…...

代码随想录算法训练营Day24|216.组合总和III、17.电话号码的字母组合
组合总和III 216. 组合总和 III - 力扣(LeetCode) 思路和昨日的组合题类似,但注意对回溯算法中,收获时的条件需要写对,path的长度要为k的同时,path中元素总和要为n。 class Solution { public:vector<…...

【Python系列】Python 中方法定义与方法调用详解
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...

Python常用模块:time、os、shutil与flask初探
一、Flask初探 & PyCharm终端配置 目的: 快速搭建小型Web服务器以提供数据。 工具: 第三方Web框架 Flask (需 pip install flask 安装)。 安装 Flask: 建议: 使用 PyCharm 内置的 Terminal (模拟命令行) 进行安装,避免频繁切换。 PyCharm Terminal 配置建议: 打开 Py…...