神经网络的工程基础(二)——随机梯度下降法|文末送书
相关说明
这篇文章的大部分内容参考自我的新书《解构大语言模型:从线性回归到通用人工智能》,欢迎有兴趣的读者多多支持。
本文涉及到的代码链接如下:regression2chatgpt/ch06_optimizer/stochastic_gradient_descent.ipynb
本文将讨论利用PyTorch实现随机梯度下降法的细节。
关于大语言模型的内容,推荐参考这个专栏。
内容大纲
- 相关说明
- 一、随机梯度下降法:更优化的算法
- 二、算法细节
- 三、代码实现
- 四、粉丝福利
一、随机梯度下降法:更优化的算法
梯度下降法虽然在理论上很美好,但在实际应用中常常会碰到瓶颈。为了说明这个问题,令 L i L_i Li表示模型在 i i i点的损失,即 L i = ( y i − a x i − b ) 2 L_i = (y_i - ax_i - b)^2 Li=(yi−axi−b)2,对所有数据点的损失求和后,可以得到整体损失函数: L = 1 ⁄ n ∑ i L i L = 1⁄n ∑_iL_i L=1⁄n∑iLi 。即模型的损失函数实际上是各个数据点损失的平均值,这一观点适用于大多数模型 1。
计算整体损失函数 L L L的梯度可得, ∇ L = 1 ⁄ n ∑ i L i ∇L = 1⁄n \sum_i L_i ∇L=1⁄n∑iLi。也就是说,损失函数的梯度等于所有数据点处梯度的平均值。但是在实际应用中,通常会使用大型数据集计算所有数据点的梯度和,这需要相当长的时间。为了加速这个计算过程,可以考虑使用随机梯度下降法(Stochastic Gradient Descent,SGD)。
二、算法细节
随机梯度下降法的核心思想是:每次迭代时只随机选择小批量的数据点来计算梯度,然后用这个小批量数据点的梯度平均值来代替整体损失函数的梯度2。
为了使算法的细节更加准确,引入一个超参数,称为批量大小(Batch Size),记作m。每次随机选取m个数据,记为 I 1 , I 2 , ⋯ , I m I_1,I_2,⋯,I_m I1,I2,⋯,Im。使用这些数据点的梯度平均值来近似代替整体损失函数的梯度: ∇ L = 1 ⁄ n ∑ i ∇ L i ≈ 1 ⁄ m ∑ j = 1 m ∇ L I j ∇L = 1⁄n ∑_i∇L_i ≈ 1⁄m ∑_{j = 1}^m∇L_{I_j } ∇L=1⁄n∑i∇Li≈1⁄m∑j=1m∇LIj 。由此得到新的参数迭代公式:
a k + 1 = a k − η / m ∑ j = 1 m ∂ L I j / ∂ a b k + 1 = b k − η / m ∑ j = 1 m ∂ L I j / ∂ b (1) a_{k + 1} = a_k - η/m ∑_{j = 1}^m∂L_{I_j }/∂a \\ b_{k + 1} = b_k -η/m ∑_{j = 1}^m∂L_{I_j }/∂b \tag{1} ak+1=ak−η/mj=1∑m∂LIj/∂abk+1=bk−η/mj=1∑m∂LIj/∂b(1)
在随机梯度下降法中,所有数据点都使用了一遍,称为模型训练了一轮。由此在实际应用中常使用另一个超参数——训练轮次(Epoch),表示所有数据将被用几遍,用于控制随机梯度下降法的循环次数。换句话说,就是公式(1)被迭代运算多少次。
在一些机器学习书籍和学术文献中,还对随机梯度下降法(当m=1时)和小批量梯度下降法(当m>1时)进行了进一步的区分。然而,这两种方法之间的区别并不大,其核心思想都是基于随机采样来近似计算梯度,从而高效地更新参数、优化模型。在实际应用中,会根据问题的性质和数据规模选择合适的批次大小,以获得最佳的训练效果。因此,本书将统一使用随机梯度下降法来代表这一类方法,以保持概念清晰和简洁。
与梯度下降法相比,随机梯度下降法更高效,这是因为小批量梯度计算比整体梯度计算快得多。尽管在随机梯度下降法中,采用小批量数据估计梯度可能会引入一些噪声,但实践证明这些噪声对整个优化过程有好处,有助于模型克服局部最优的“陷阱”,逐步逼近全局最优参数。
三、代码实现
随机梯度下降法的实现与梯度下降法类似,不同之处在于,每次计算梯度时需要“随机”选取一部分数据,具体的实现步骤可以参考程序清单1(完整代码)。
- 在程序清单1的第2行,引入一个名为batch_size的超参数,用于控制每个批次中的数据量大小。选择合适的batch_size对算法的运行效率和稳定性至关重要。如果参数设置过大,可能会导致算法运行效率下降;而过小的参数可能使算法变得过于随机,影响收敛的稳定性。选择合适的参数需要结合具体的模型和应用场景,结合相关领域的经验进行决策。
- 在程序清单1的第11—13行,展示了一种随机选取批次数据的实现方式。这也是随机梯度下降法与普通梯度下降法的主要区别之一。实现随机性的方式有很多种,比如引入随机数等。这里仅呈现一种经典方法:将数据按顺序划分成批次。
1 | # 定义每批次用到的数据量2 | batch_size = 203 | # 定义模型4 | model = Linear()5 | # 确定最优化算法6 | learning_rate = 0.17 | optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)8 | 9 | for t in range(20):
10 | # 选取当前批次的数据,用于训练模型
11 | ix = (t * batch_size) % len(x)
12 | xx = x[ix: ix + batch_size]
13 | yy = y[ix: ix + batch_size]
14 | yy_pred = model(xx)
15 | # 计算当前批次数据的损失
16 | loss = (yy - yy_pred).pow(2).mean()
17 | # 将上一次的梯度清零
18 | optimizer.zero_grad()
19 | # 计算损失函数的梯度
20 | loss.backward()
21 | # 迭代更新模型参数的估计值
22 | optimizer.step()
23 | # 注意!loss记录的是模型在当前批次数据上的损失,该数值的波动较大
24 | print(f'Step {t + 1}, Loss: {loss: .2f}; Result: {model.string()}')
在随机梯度下降法的执行过程中,通常使用模型的整体损失作为指标来监测算法的运行情况。但要注意的是,程序清单1中第16行定义的loss表示模型在小批量数据上的损失,这个值仅依赖于少量数据,迭代过程中会表现出极大的不稳定性,因此并不适合作为评估算法运行情况的主要标志。
如果希望更准确地监测算法的运行情况,需要在更大的数据集上估计模型的整体损失,例如在全部训练数据上计算损失,如图1所示。这种评估方式更稳定,能够更全面地反映模型的训练进展。

四、粉丝福利
参与方式:关注博主、点赞、收藏、评论区评论“解构大语言模型”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
本次送书数量不少于3本,【阅读量越多,送得越多】
活动结束后,会私信中奖粉丝,请各位注意查看私信哦~
活动截止时间:2024-05-24 24:00:00
对于解决回归问题的模型,这个结论显然成立。对于解决分类问题的模型(比如逻辑回归模型),只需对模型的似然函数做简单的数学变换(先求对数,再求相反数),就可以得到同样的结论。 ↩︎
这在数学上是完全合理的。从统计的角度来看,用所有数据点求平均值,并不比随机抽样的方法高明很多。与线性回归参数估计值类似,两个结果都是随机变量:它们都以真实梯度为期望,只是前者的置信区间更小。 ↩︎
相关文章:
神经网络的工程基础(二)——随机梯度下降法|文末送书
相关说明 这篇文章的大部分内容参考自我的新书《解构大语言模型:从线性回归到通用人工智能》,欢迎有兴趣的读者多多支持。 本文涉及到的代码链接如下:regression2chatgpt/ch06_optimizer/stochastic_gradient_descent.ipynb 本文将讨论利用…...

常见的几种编码方式
常见的编码方式及其特点: 编码方式的设计是为了适应不同的字符集和应用需求,因此它们在表示字符时使用的位数和字节数各不相同 常见编码方式及其位数和字节数 ASCII(American Standard Code for Information Interchange)&#x…...
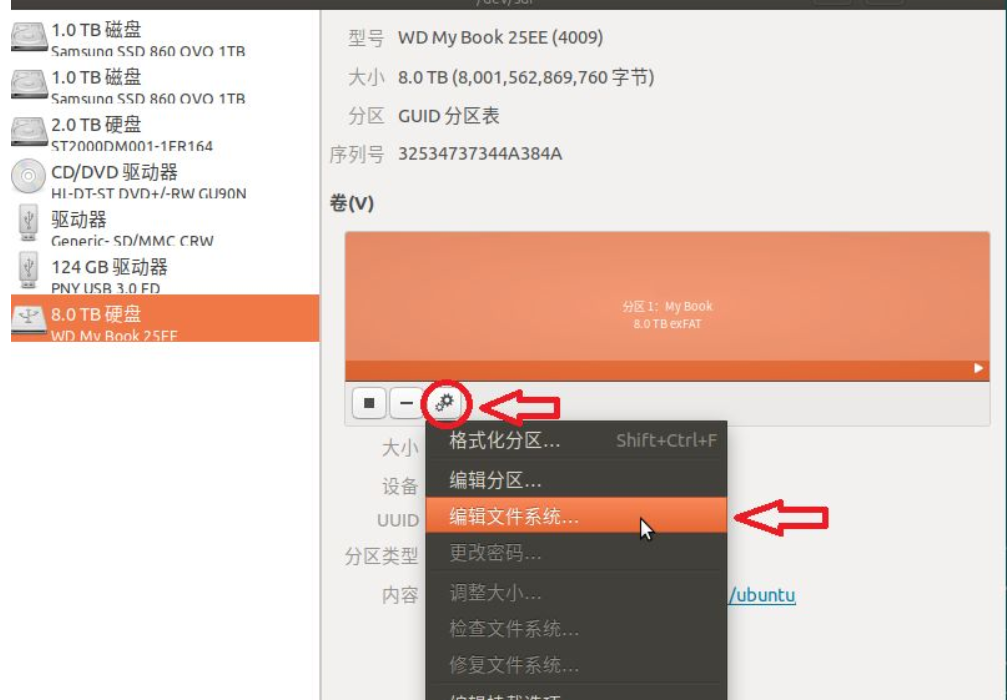
ubuntu移动硬盘重命名
因为在ubuntu上移动硬盘的名字是中文的,所以想要改成英文的。 我的方法: 将移动硬盘插到windows上,直接右键重命名。再插到ubuntu上名字就改变了。 别人的方法: ubuntu下如何修改U盘名字-腾讯云开发者社区-腾讯云 在自带的软件…...

VUE框架前置知识总结
一、前言 在学习vue框架中,总是有些知识不是很熟悉,又不想系统的学习JS,因为学习成本太大了,所以用到什么知识就学习什么知识。此文档就用于记录零散的知识点。主要是还是针对与ES6规范的JS知识点。 以下实验环境都是在windows环…...

张宇1000题80%不会?别急,这个方法肯定有用!
这太正常了,1000题的难度本来就高,不要慌 我考研的时候跟的也是张宇老师,但是1000题我根本就没做几道题就给换成880题660题了,而且只是强化阶段用880题,基础阶段我用的都是汤家凤的1800题。 不要担心做的不是张宇老师…...

【python】爬虫记录每小时金价
数据来源: https://www.cngold.org/img_date/ 因为这个网站是数据随时变动的,用requests、BeautifulSoup的方式解析html的话,数据的位置显示的是“--”,并不能取到数据。 所以采用webdriver访问网站,然后从界面上获取…...
一行命令将已克隆的本地Git仓库推送到内网服务器
一、需求背景 我们公司用gitea搭建了一个git服务器,其中支持win7的最高版本是v1.20.6。 我们公司的电脑在任何时候都不能连接外网,但是希望将一些开源的仓库移植到内网的服务器来。一是有相关代码使用的需求,二是可以建设一个内网能够查阅的…...

Linux文本处理三剑客(详解)
一、文本三剑客是什么? 1. 对于接触过Linux操作系统的人来说,应该都听过说Linux中的文本三剑客吧,即awk、grep、sed,也是必须要掌握的Linux命令之一,三者都是用来处理文本的,但侧重点各不相同,a…...
AI在线UI代码生成,不需要敲一行代码,聊聊天,上传图片,就能生成前端页面的开发神器
ioDraw的在线UI代码生成器是一款开发神器,它可以让您在无需编写一行代码的情况下创建前端页面。 主要优势: 1、极简操作:只需聊天或上传图片,即可生成响应式的Tailwind CSS代码。 2、节省时间:自动生成代码可以节省大…...

go-zero整合单机版ClickHouse并实现增删改查
go-zero整合单机版ClickHouse并实现增删改查 本教程基于go-zero微服务入门教程,项目工程结构同上一个教程。 本教程主要实现go-zero框架整合单机版ClickHouse,并暴露接口实现对ClickHouse数据的增删改查。 go-zero微服务入门教程:https://b…...
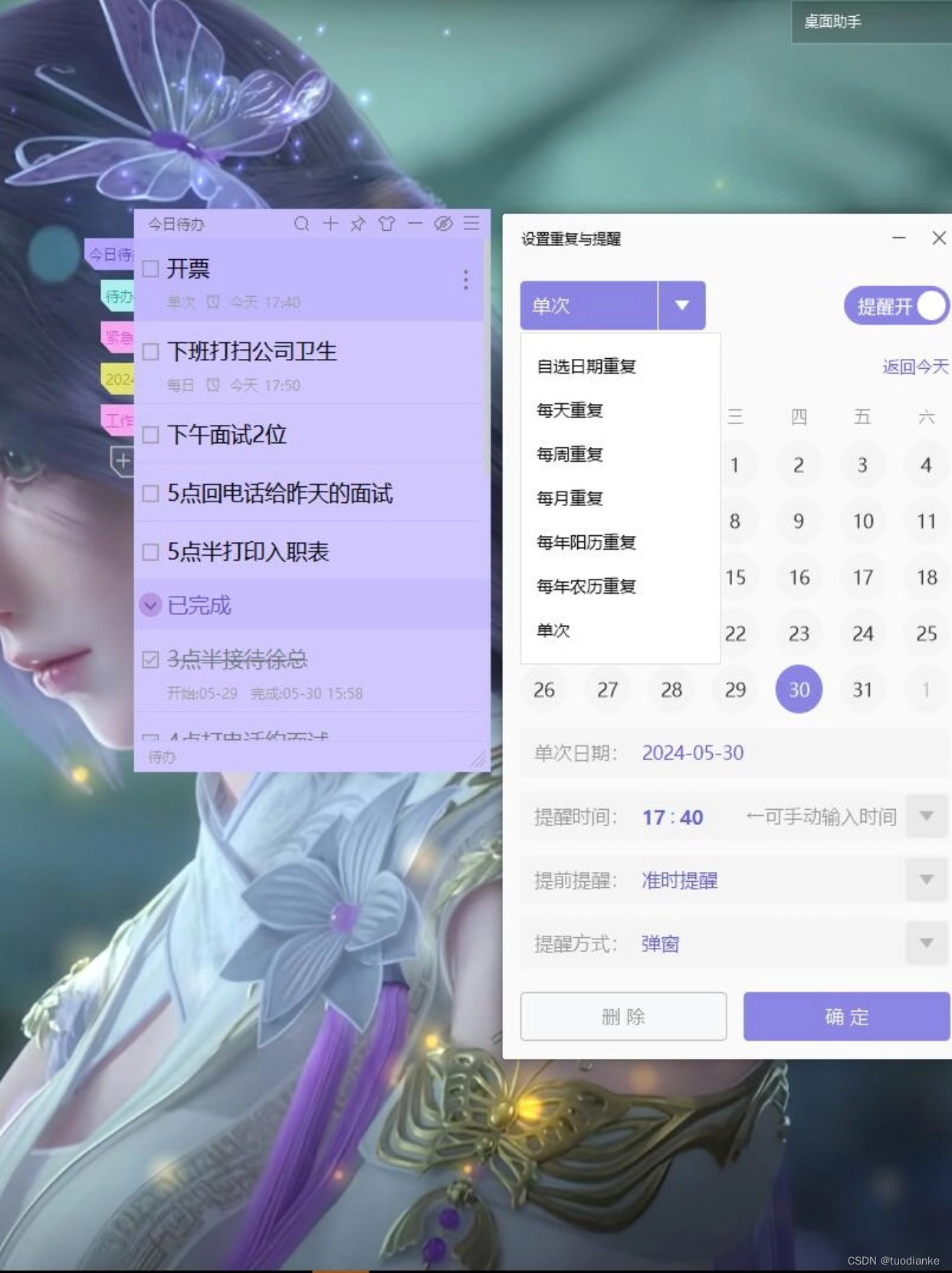
行政工作如何提高效率?桌面备忘录便签软件哪个好
在行政管理工作中,效率的提高无疑是每个行政人员都追求的目标。而随着科技的发展,各种便捷的工具也应运而生,其中桌面备忘录便签软件便是其中的佼佼者。那么,这类软件又如何帮助我们提高工作效率呢? 首先,…...

利用向日葵和微信/腾讯会议实现LabVIEW远程开发
利用向日葵远程控制软件结合微信或腾讯会议的视频通话功能,可以实现LabVIEW的远程开发和调试。通过向日葵进行远程桌面访问,配合视频通话工具进行实时沟通与问题解决,不仅提高了开发效率,还减少了地域限制带来的不便。介绍这种远程…...
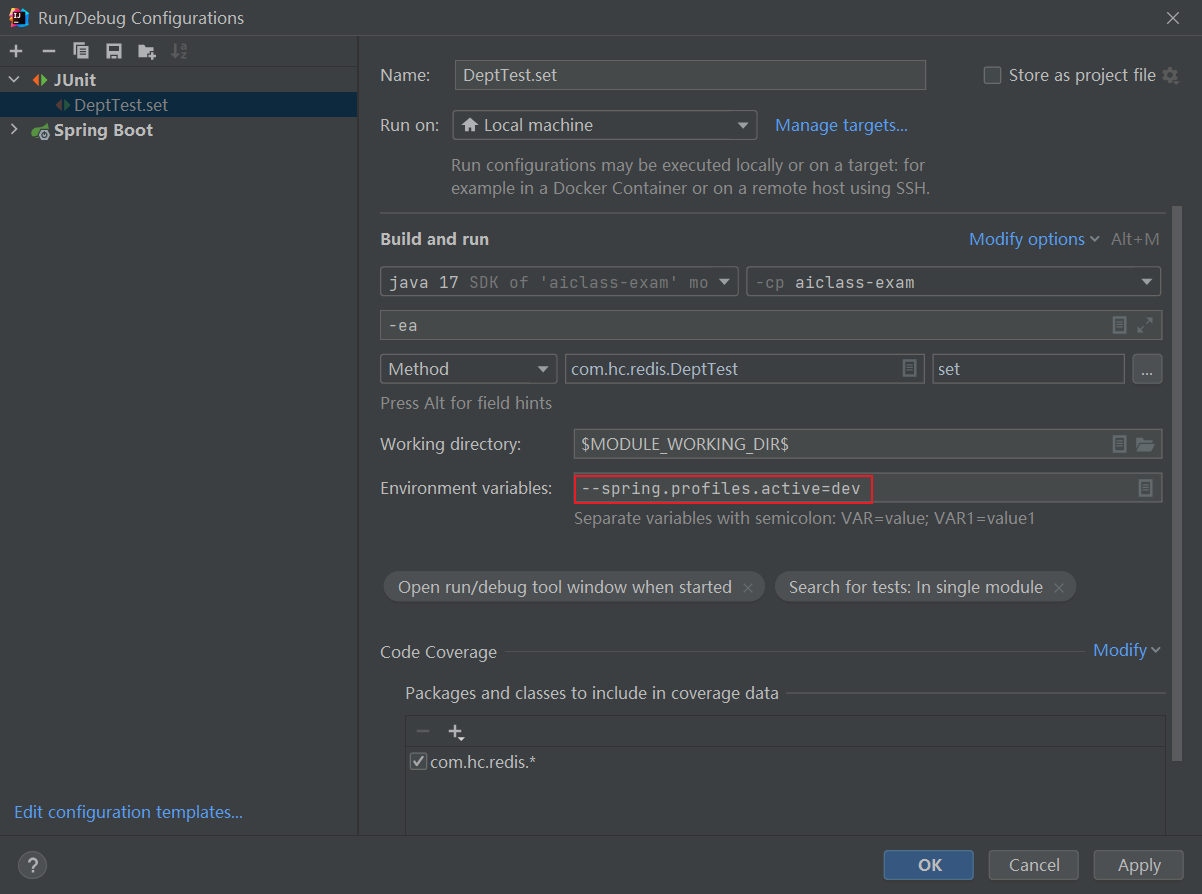
SpringBoot 单元测试 指定 环境
如上图所示,在配置窗口中添加--spring.profiles.activedev,就可以了。...

Flutter 中的 SliverOpacity 小部件:全面指南
Flutter 中的 SliverOpacity 小部件:全面指南 Flutter 是一个功能强大的 UI 框架,由 Google 开发,允许开发者使用 Dart 语言来构建高性能、美观的跨平台应用。在 Flutter 的滚动组件体系中,SliverOpacity 是一个用来为其子 Slive…...

源码分析の前言
源码分析路线图: 初级部分:ArrayList->LinkedList->Vector->HashMap(红黑树数据结构,如何翻转,变色,手写红黑树)->ConcurrentHashMap 中级部分:Spring->Spring MVC->Spring Boot->M…...
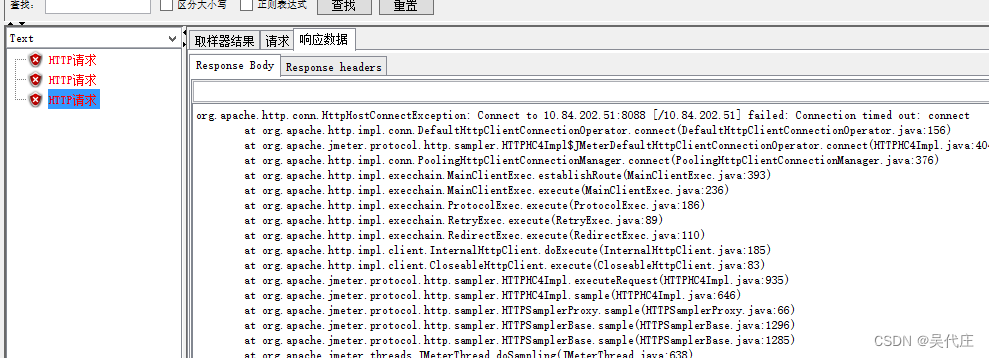
接口性能测试复盘:解决JMeter超时问题的实践
在优化接口并重新投入市场后,我们面临着一项关键任务:确保其在高压环境下稳定运行。于是,我们启动了一轮针对该接口的性能压力测试,利用JMeter工具模拟高负载场景。然而,在测试进行约一分钟之后,频繁出现了…...

[数据集][目标检测]猕猴桃检测数据集VOC+YOLO格式1838张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1838 标注数量(xml文件个数):1838 标注数量(txt文件个数):1838 标注…...
摸鱼大数据——Hive函数7-9
7、日期时间函数 Hive函数链接:LanguageManual UDF - Apache Hive - Apache Software Foundation SimpleDateFormat (Java Platform SE 8 ) current_timestamp: 获取时间原点到现在的秒/毫秒,底层自动转换方便查看的日期格式 常用 to_date: 字符串格式时间…...

python连接数据库
python连接MYSQL、postgres、oracle等的基本操作 python连接mysql MySQLdb MySQLdb又叫MySQL-python ,是 Python 连接 MySQL 的一个驱动,很多框架都也是基于此库进行开发,只支持 Python2.x,而且安装的时候有很多前置条件&#…...

能不能接受这些坑?买电车前一定要看
图片来源:汽车之家 文 | Auto芯球 作者 | 雷慢 刚有个朋友告诉我,买了电车后感觉被骗了, 很多“坑”都是他买车后才知道的。 不提前研究,不做功课,放着我这个老司机不请教, 这个大冤种他不当谁当&…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...