跟踪一个Pytorch Module在训练过程中的内存分配情况
跟踪一个Pytorch Module在训练过程中的内存分配情况
- 代码
- 输出
目的:跟踪一个Pytorch Module在训练过程中的内存分配情况
方法:
1.通过pre_hook module的来区分module的边界
2.通过__torch_dispatch__拦截所有的aten算子,计算在该算子中新创建tensor的总内存占用量
3.通过tensor.data_ptr()为tensor去重,表示一块独立的内存
代码
import numpy as np
import torch
from torch.nn import Module, Linear
import torch.nn as nn
from torch.optim import Adam,SGD
from torch.utils._python_dispatch import TorchDispatchMode
from dataclasses import dataclass
from typing import Any
import time@dataclass
class _ProfilerState:cls: Anyobject: Any = Nonecurrent_module=None
tesor_cache=set()def get_current_mem():global current_moduleprint(f'[INFO]{current_module["name"]}:{np.sum(current_module["size"])}')current_module=Noneclass InputDescriptor:def __init__(self) -> None:self.total_input_size=0def _save_var(self,v):class_name=v.__class__.__name__if class_name in ["Tensor","Parameter"]:global tesor_cachetensorid=v.data_ptr()if v.device.type!="cuda":return if tensorid not in tesor_cache:tesor_cache.add(tensorid)sz=v.numel()*v.element_size()print(v.shape,v.dtype)self.total_input_size += szif class_name=="Parameter" and v.grad is not None: tensorid=v.grad.data_ptr()if tensorid not in tesor_cache:tesor_cache.add(tensorid)sz=v.grad.numel()*v.grad.element_size()print("grad",v.grad.shape,v.grad.dtype)self.total_input_size += szelif class_name in ["list","tuple"]:for t in v:self._save_var(t)else:passdef save_vars(self,ret,*args,**kwargs):for arg in args:self._save_var(arg) for k,v in kwargs.items():self._save_var(v)self._save_var(ret)global current_module if current_module is None:current_module={"name":"Other","size":[]}current_module["size"].append(self.total_input_size)# 对象和类名缓存
object_cache = {}
class_name_count = {}def get_unique_name(class_name, obj_id):# 生成唯一的对象名称if class_name not in class_name_count:class_name_count[class_name] = 0uid = f"{class_name}_{obj_id}"if uid not in object_cache:class_name_count[class_name] += 1object_cache[uid] = {"idx": class_name_count[class_name]}return f'{class_name}-{object_cache[uid]["idx"]}'def initialize_module_attributes(module):# 初始化模块属性if not hasattr(module, 'uuid'):module.uuid = get_unique_name(module.__class__.__name__, id(module))if not hasattr(module, 'backward_mem'):module.backward_mem = []if not hasattr(module, 'forward_mem'):module.forward_mem = []def pre_backward_hook(module, grad_input):# 反向传播前的钩子函数initialize_module_attributes(module)global current_moduleif current_module is not None and np.sum(current_module["size"])>0:print(f'[INFO]{current_module["name"]}:{np.sum(current_module["size"])}')module.backward_mem.clear()current_module={"name":f"backward-{module.uuid}","size":module.backward_mem}def post_backward_hook(module, grad_input, grad_output):# 反向传播后的钩子函数initialize_module_attributes(module)def pre_forward_hook(module, input):# 前向传播前的钩子函数initialize_module_attributes(module)global current_moduleif current_module is not None and np.sum(current_module["size"])>0:print(f'[INFO]{current_module["name"]}:{np.sum(current_module["size"])}')module.forward_mem.clear()current_module={"name":f"forward-{module.uuid}","size":module.forward_mem}def post_forward_hook(module, input, output):# 前向传播后的钩子函数initialize_module_attributes(module)def register_forward_hooks(module):# 注册反向传播钩子module.register_forward_pre_hook(pre_forward_hook)module.register_forward_hook(post_forward_hook)def register_backward_hooks(module):# 注册反向传播钩子module.register_full_backward_pre_hook(pre_backward_hook)module.register_full_backward_hook(post_backward_hook)class HookModel(object):def __init__(self, model):output_dict = {}self.get_submodule_recrusicve(model, "", output_dict)for name, module in output_dict.items():if name.endswith("Sequential"):continueregister_forward_hooks(module)register_backward_hooks(module)def get_submodule_recrusicve(self,module, prefix, output_dict):prefix = prefix + "/" + type(module).__name__output_dict[prefix] = modulefor name, submodule in module.named_children():self.get_submodule_recrusicve(submodule, f"{prefix}[{name}]", output_dict)class TorchDumpDispatchMode(TorchDispatchMode):def __init__(self,parent):super().__init__()self.parent=parentdef __torch_dispatch__(self, func, types, args=(), kwargs=None):if kwargs is None:kwargs = {} ret= func(*args, **kwargs)desc=InputDescriptor()desc.save_vars(ret,*args,**kwargs)if desc.total_input_size>0:print(f"{func.__name__}:{desc.total_input_size}")return retclass TorchDebugDumper:_CURRENT_Dumper = Nonedef __init__(self):self.p= _ProfilerState(TorchDumpDispatchMode)def __enter__(self):assert TorchDebugDumper._CURRENT_Dumper is NoneTorchDebugDumper._CURRENT_Dumper = selfif self.p.object is None:o = self.p.cls(self)o.__enter__()self.p.object = oelse:self.p.object.step()return selfdef __exit__(self, exc_type, exc_val, exc_tb):TorchDebugDumper._CURRENT_Dumper = Noneif self.p.object is not None:self.p.object.__exit__(exc_type, exc_val, exc_tb)del self.p.objectclass FeedForward(Module):def __init__(self,hidden_size,ffn_size):super().__init__()self.fc = nn.Sequential(Linear(in_features=hidden_size, out_features=ffn_size,bias=False),nn.ReLU(),Linear(in_features=ffn_size, out_features=ffn_size*2,bias=False),nn.Dropout(0.5),Linear(in_features=ffn_size*2, out_features=hidden_size,bias=False),)self.norm = nn.LayerNorm(normalized_shape=hidden_size, elementwise_affine=False)def forward(self, x):return x + self.fc(self.norm(x))def main():model=FeedForward(100,128)model=model.float().cuda()model.train()obj=HookModel(model)global current_modulewith TorchDebugDumper():opt=Adam(model.parameters(),lr=0.001)input=torch.randn(1,100).float().cuda()output=model(input)get_current_mem()loss=-torch.log(output.sum())opt.zero_grad()loss.backward()get_current_mem()current_module=Noneopt.step() get_current_mem()num_model_params = sum(p.numel() for p in model.parameters())print(f"[INFO]Number of model parameters: {num_model_params}")
main()
输出
torch.Size([1, 100]) torch.float32
_to_copy.default:400
[INFO]Other:400
torch.Size([1, 100]) torch.float32
torch.Size([1, 1]) torch.float32
torch.Size([1, 1]) torch.float32
native_layer_norm.default:408
[INFO]forward-LayerNorm-1:408
torch.Size([128, 100]) torch.float32
t.default:51200
[INFO]forward-Linear-1:51200
torch.Size([256, 128]) torch.float32
t.default:131072
torch.Size([1, 256]) torch.float32
mm.default:1024
[INFO]forward-Linear-2:132096
torch.Size([1, 256]) torch.float32
native_dropout.default:1024
[INFO]forward-Dropout-1:1024
torch.Size([100, 256]) torch.float32
t.default:102400
torch.Size([1, 100]) torch.float32
add.Tensor:400
[INFO]forward-Linear-3:102800
torch.Size([]) torch.float32
log.default:4
torch.Size([]) torch.float32
neg.default:4
torch.Size([]) torch.float32
neg.default:4
torch.Size([]) torch.float32
div.Tensor:4
[INFO]Other:16
torch.Size([100, 256]) torch.float32
mm.default:102400
torch.Size([1, 256]) torch.float32
mm.default:1024
[INFO]backward-Linear-3:103424
torch.Size([128, 100]) torch.float32
mm.default:51200
[INFO]backward-Linear-1:51200
torch.Size([128, 100]) torch.float32
zeros_like.default:51200
torch.Size([128, 100]) torch.float32
zeros_like.default:51200
torch.Size([256, 128]) torch.float32
zeros_like.default:131072
torch.Size([256, 128]) torch.float32
zeros_like.default:131072
torch.Size([100, 256]) torch.float32
zeros_like.default:102400
torch.Size([100, 256]) torch.float32
zeros_like.default:102400
torch.Size([128, 100]) torch.float32
torch.Size([256, 128]) torch.float32
torch.Size([100, 256]) torch.float32
_foreach_sqrt.default:284672
[INFO]Other:854016
[INFO]Number of model parameters: 71168
相关文章:

跟踪一个Pytorch Module在训练过程中的内存分配情况
跟踪一个Pytorch Module在训练过程中的内存分配情况 代码输出 目的:跟踪一个Pytorch Module在训练过程中的内存分配情况 方法: 1.通过pre_hook module的来区分module的边界 2.通过__torch_dispatch__拦截所有的aten算子,计算在该算子中新创建tensor的总内存占用量 3.通过tensor…...
空间方法×3))
LeetCode 2965.找出缺失和重复的数字:小数据?我选择暴力(附优化方法清单:O(1)空间方法×3)
【LetMeFly】2965.找出缺失和重复的数字:小数据?我选择暴力(附优化方法清单:O(1)空间方法3) 力扣题目链接:https://leetcode.cn/problems/find-missing-and-repeated-values/ 给你一个下标从 0 开始的二维…...
)
【运维】VMware Workstation 虚拟机内无网络的解决办法(或许可行)
【使用桥接模式】 【重置网络】 这个过程涉及管理Linux系统中的网络驱动程序和网络管理工具。以下是每个步骤的详细解释: 卸载网络驱动模块: sudo rmmod e1000 sudo rmmod e1000e sudo rmmod igb这些命令使用 rmmod(remove moduleÿ…...
如何使用Dora SDK完成Fragment流式切换和非流式切换
我想大家对Fragment都不陌生,它作为界面碎片被使用在Activity中,如果只是更换Activity中的一小部分界面,是没有必要再重新打开一个新的Activity的。有时,即使要更换完整的UI布局,也可以使用Fragment来切换界面。 何…...
低代码开发平台(Low-code Development Platform)的模块组成部分
低代码开发平台(Low-code Development Platform)的模块组成部分主要包括以下几个方面: 低代码开发平台的模块组成部分可以按照包含系统、模块、菜单组织操作行为等维度进行详细阐述。以下是从这些方面对平台模块组成部分的说明: …...

Java网络编程(上)
White graces:个人主页 🙉专栏推荐:Java入门知识🙉 🙉 内容推荐:Java文件IO🙉 🐹今日诗词:来如春梦几多时?去似朝云无觅处🐹 ⛳️点赞 ☀️收藏⭐️关注💬卑微小博主&a…...

Spring Kafka 之 @KafkaListener 注解详解
我们在开发的过程中当使用到kafka监听消费的时候会使用到KafkaListener注解,下面我们就介绍下它的常见属性和使用。 一、介绍 KafkaListener 是 Spring Kafka 提供的一个注解,用于声明一个方法作为 Kafka 消息的监听器 二、主要参数 1、topic 描述&…...
【量算分析工具-贴地距离】GeoServer改造Springboot番外系列九
【量算分析工具-概述】GeoServer改造Springboot番外系列三-CSDN博客 【量算分析工具-水平距离】GeoServer改造Springboot番外系列四-CSDN博客 【量算分析工具-水平面积】GeoServer改造Springboot番外系列五-CSDN博客 【量算分析工具-方位角】GeoServer改造Springboot番外系列…...
文件操作及vi)
【linux】(1)文件操作及vi
文件和目录的创建 创建文件 touch 命令:创建一个新的空文件。 touch filename.txtecho 命令:创建一个文件并写入内容。 echo "Hello, World!" > filename.txtcat 命令:将内容写入文件。 cat > filename.txt然后输入内容&…...
【5】MySQL数据库备份-XtraBackup - 全量备份
MySQL数据库备份-XtraBackup-全量备份 前言环境版本 安装部署下载RPM 包二进制包 安装卸载 场景分析全量备份 | 恢复备份恢复综合 增量备份 | 恢复部分备份 | 恢复 前言 关于数据库备份的一些常见术语、工具等,可见《MySQL数据库-备份》章节,当前不再重…...

数据治理-数据标准演示
数据字典 数据标准-数据字典 词根 数据标准-词根 业务字典映射 数据标准-业务字典映射 标准文档 数据标准-标准文档...
基于Chisel的FPGA流水灯设计
Chisel流水灯 一、Chisel(一)什么是Chisel(二)Chisel能做什么(三)Chisel的使用(四)Chisel的优缺点1.优点2.缺点 二、流水灯设计 一、Chisel (一)什么是Chise…...

LabVIEW齿轮调制故障检测系统
LabVIEW齿轮调制故障检测系统 概述 开发了一种基于LabVIEW平台的齿轮调制故障检测系统,实现齿轮在恶劣工作条件下的故障振动信号的实时在线检测。系统利用LabVIEW的强大图形编程能力,结合Hilbert包络解调技术,对齿轮的振动信号进行精确分析…...

AI帮写:探索国内AI写作工具的创新与实用性
随着AI技术的快速发展,AI写作正成为创作的新风口。但是面对GPT-4这样的国际巨头,国内很多小伙伴往往望而却步,究其原因,就是它的使用门槛高,还有成本的考量。 不过,随着GPT技术的火热,国内也涌…...

n后问题 回溯笔记
问题描述 在nn格的棋盘上放置彼此不受攻击的n个皇后。 按照国际象棋的规则,皇后可以攻击与之处在同 一行或同一列或同一斜线上的棋子。n后问题等价于在nn格的棋盘上放置n个皇后,任何2个皇后不放在同一行或同一列或同一斜线上。 代码 import java.uti…...

简述Java中实现Socket通信的步骤
在Java中,实现Socket通信通常涉及客户端和服务器端两个角色。以下是它们各自的基本步骤: 服务器端(Server) 创建ServerSocket对象: 在服务器端,首先需要创建一个ServerSocket对象。这个对象会监听来自客户…...
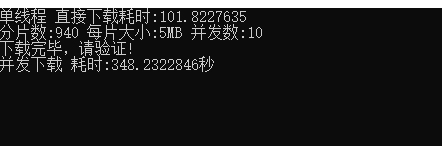
Asp.Net Core 实现分片下载的最简单方式
技术群里的朋友遇到了这个问题,起初的原因是他对文件增加了一个属性配置 fileResult.EnableRangeProcessing true;这个属性我从未遇到过,然后,去F1查看这个属性的描述信息也依然少的可怜,只有简单的描述为(获取或设置为 启用范围…...

[Mac软件]Leech for Mac v3.2 - 轻量级mac下载工具
黑果魏叔推荐Leech是由Many Tricks开发的适用于Mac OS X的轻量级且功能强大的下载管理器。 Leech让您完全控制下载,并与浏览器完全集成。您可以将下载排队,暂停和恢复,从受密码保护的服务器下载,并将密码存储在系统范围的安全钥匙…...
留给“端侧大模型”的时间不多了
端侧大模型(Edge AI models),也就是只在设备本地(如智能手机、IoT设备、嵌入式系统等)运行的大模型,过去一两年来非常流行。 具体表现在,终端设备厂商,如苹果、荣耀、小米、OV等&…...
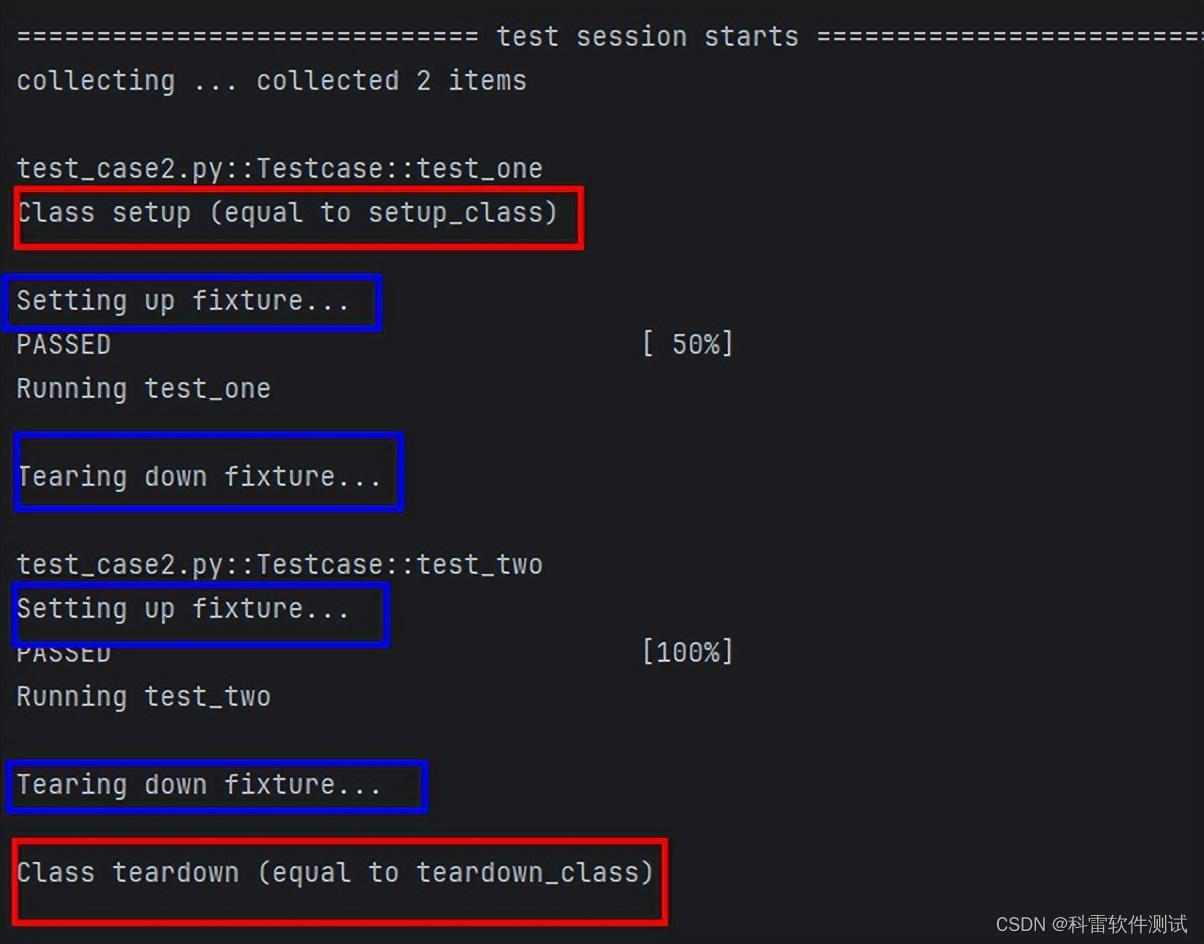
Pytest框架中的Setup和Teardown功能
在 pytest 测试框架中,setup 和 teardown是用于在每个测试函数之前和之后执行设置和清理的动作,而pytest 实际上并没有内置的 setup 和 teardown 函数,而是使用了一些装饰器或钩子函数来实现类似的功能。 学习目录 钩子函数(Hook…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

自制BLE112串口编程器:基于Bootloader的免调试器烧录方案
1. 项目概述:为BLE112模块打造一款免调试器的RS232编程器在嵌入式开发,特别是早期的蓝牙低功耗(BLE)模块应用中,我们常常会遇到一个棘手的问题:官方开发工具链的依赖和限制。以Silicon Labs(当时…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

别再手动维护接口文档了!用Spring Boot 3和Swagger 3实现代码与文档的自动同步
Spring Boot 3与Swagger 3:构建零维护成本的API文档工作流 每次接口变更都要手动更新文档?团队成员总是抱怨文档与实际接口不一致?在敏捷开发时代,传统文档维护方式已成为拖累工程效率的典型痛点。本文将揭示如何通过Spring Boot …...

LPCM框架:大模型驱动的计算机架构设计革命
1. LPCM框架:计算机系统架构设计的范式革命计算机系统架构设计正站在历史性的转折点上。过去八十年来,从ENIAC的真空管到现代7纳米制程的异构计算芯片,架构设计始终遵循着"专家经验EDA工具"的传统范式。但随着摩尔定律逼近物理极限…...
提升你的图表专业度?)
从科研图表到商业报表:如何用Matplotlib的legend()提升你的图表专业度?
从科研图表到商业报表:如何用Matplotlib的legend()提升你的图表专业度? 在数据驱动的决策时代,图表不仅是科研论文中的证据载体,更是商业汇报中的说服工具。我曾见证一位生物统计学家将同一组临床试验数据呈现给三种不同受众&…...

基于特征工程的电力系统虚假数据注入攻击检测方案
1. 项目概述与核心挑战在电力系统这个庞大而精密的“交响乐团”中,自动发电控制(AGC)系统扮演着指挥家的角色。它的核心任务是根据电网频率和联络线功率的微小波动,实时调整各发电机的出力,确保整个电网的频率稳定在50…...

DamaiHelper:大麦网演唱会抢票脚本终极指南
DamaiHelper:大麦网演唱会抢票脚本终极指南 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为抢不到心仪演唱会门票而烦恼吗?面对秒光的票源和黄牛的高价,…...

机器学习赋能组合优化:全局退火算法在三维伊辛模型上的实战超越
1. 项目概述:当机器学习遇上组合优化,一场算法效率的革命在计算机科学和运筹学的核心地带,组合优化问题无处不在。从决定物流公司如何安排数千辆卡车的路线,到芯片设计时如何摆放数十亿个晶体管以实现最佳性能,再到为复…...