Spark单机伪分布式环境搭建、完全分布式环境搭建、Spark-on-yarn模式搭建
搭建Spark需要先配置好scala环境。三种Spark环境搭建互不关联,都是从零开始搭建。
如果将文章中的配置文件修改内容复制粘贴的话,所有配置文件添加的内容后面的注释记得删除,可能会报错。保险一点删除最好。
Scala环境搭建
上传安装包解压并重命名
rz上传
如果没有安装rz可以使用命令安装:
yum install -y lrzsz
这里我将scala解压到/opt/module目录下:
tar -zxvf /opt/tars/scala-2.12.0.tgz -C /opt/module
重命名:
mv scala-2.12.0 scala
2、vi /etc/profile
在最后添加:
export SCALA_HOME=/opt/module/scala
export PATH=$PATH:$SCALA_HOME/bin
刷新使文件生效:
source /etc/profile
搭建单机伪分布式环境(单机)
spark单机伪分布是在一台机器上既有Master,又有Worker进程。spark单机伪分布式环境可以在hadoop伪分布式的基础上进行搭建
上传安装包解压并重命名
rz上传
解压:
tar -zxvf /opt/tars/spark-3.1.1-bin-hadoop3.2.tgz -C /opt/module
重命名:
mv spark-3.1.1-bin-hadoop3.2 spark
进入spark/conf,将spark-env.sh.template 重命名为spark-env.sh
cd /opt/module/spark/conf
mv spark-env.sh.template spark-env.sh
打开spark-env.sh:
vi spark-env.sh
在末尾添加:
export JAVA_HOME=/opt/module/jdk # java的安装路径
export HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop # hadoop的安装路径
export HADOOP_HOME=/opt/module/hadoop # hadoop配置文件的路径
export SPARK_MASTER_IP=master # spark主节点的ip或机器名
export SPARK_LOCAL_IP=master # spark本地的ip或机器名
4、vi /etc/profile
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
刷新:
source /etc/profile
5、切换到/sbin目录下,启动集群:
cd /opt/module/spark/sbin
./start-all.sh
6、通过jps查看进程,既有Master进程又有Worker进程
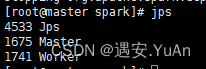
搭建完全分布式环境
搭建Spark完全分布式环境的前提是已经搭建好了hadoop完全分布式,如果没有搭建hadoop完全分布式且不会搭建,可以前往博主主页寻找hadoop完全分布式搭建的文章进行搭建。
博主的三台机器名:主节点:master,从节点:slave1,slave2
1、上传安装包解压并重命名(前面已经讲解过,就不多说了)
2、进入spark/conf,将spark-env.sh.template 重命名 spark-env.sh
cd /opt/module/spark/conf
mv spark-env.sh.template spark-env.sh
3、vi spark-env.sh,在末尾添加:
export JAVA_HOME=/opt/module/jdk # java的安装路径
export HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop # hadoop配置文件的路径
export SPARK_MASTER_IP=master # spark主节点的ip或机器名
export SPARK_MASTER_PORT=7077 # spark主节点的端口号
export SPARK_WORKER_MEMORY=512m # Worker节点能给予Executors的内存数
export SPARK_WORKER_CORES=1 # 每台节点机器使用核数
export SPARK_EXECUTOR_MEMORY=512m # 每个Executors的内存
export SPARK_EXCUTOR_CORES=1 # Executors的核数
export SPARK_WORKER_INSTANCES=1 # 每个节点的Worker进程数
4、spark2.x是配置slaves文件,将slaves.template重命名为slaves
mv slaves.template slaves
添加三个节点的机器名(如果只要两个work的话可以不写master):
vi slaves
master
slave1
slave2
spark3.x是配置works文件:
mv works.template works
vi works
master
slave1
slave2
5、配置spark-default.conf文件,将spark-defaults.conf.template重命名为spark-default.conf:
mv spark-defaults.conf.template spark-default.conf
修改配置文件:
vi /opt/module/spark/conf/spark-default.conf
spark.master spark://master:7077 <!--spark主节点所在机器及端口,默认写法是spark://-->
spark.eventLog.enabled true <!--是否打开任务日志功能,默认为false,即打不开-->
spark.eventLog.dir hdfs://master:8020/spark-logs <!--任务日志默认存放位置,配置一个HDFS路径即可-->
spark.history.fs.logDirectory hdfs://master:8020/spark-logs <!--存放历史应用日志文件的目录-->
注意:8020是HDFS的连接端口,需要填自己的,可以去hadoop的webui查看,hadoop2.x端口是50070,hadoop3.x端口是9870
6、分发:
scp -r /opt/module/spark slave1:/opt/module
scp -r /opt/module/spark slave2:/opt/module
7、创建spark-logs目录
hdfs dfs -mkdir /spark-logs
8、vi /etc/profile
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
刷新:
source /etc/profile
9、分发:
scp -r /etc/profile slave1:/etc
scp -r /etc/profile slave2:/etc
刷新使文件生效:
source /etc/profile
进入Spark的/sbin目录下,启动Spark独立集群
cd /opt/module/spark/sbin
sbin/start-all.sh
启动历史服务器(可以不启动,不启动则没有HistoryServer进程)
sbin/start-history-server.sh
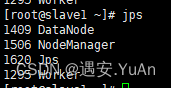
通过jps查看进程:
master节点:
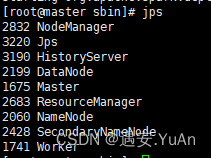
slave1/slave2节点:

完成以上步骤,Spark环境则搭建完成。
可以通过http://master:8080访问主节点,可以看到webui的监控画面
http://master:18080可以看到历史任务
启动Spark交互页面:
bin/spark-shell
启动YARN客户端模式:bin/spark-shell --master yarn-client
启动YARN集群模式:bin/spark-shell --master yarn-cluster
Spark on Yarn模式
1、解压并重命名:
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-yarn
2、修改hadoop配置文件yarn-site.xml并分发
vi /opt/module/hadoop/etc/hadoop/yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,
如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,
如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
分发:
scp -r /opt/module/hadoop/etc/hadoop/yarn-site.xml slave1:/opt/module/hadoop/etc/hadoop/
scp -r /opt/module/hadoop/etc/hadoop/yarn-site.xml slave2:/opt/module/hadoop/etc/hadoop/
3、修改spark-yarn/conf/spark-env.sh配置文件:
vi /opt/module/spark-yarn/conf/spark-env.sh
export JAVA_HOME=/opt/module/jdk
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
4、vi /etc/profile
export SPARK_HOME=/opt/module/spark-yarn
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
刷新:
source /etc/profile
5、分发:
scp -r /etc/profile slave1:/etc
scp -r /etc/profile slave2:/etc
刷新使文件生效:
source /etc/profile
完成以上步骤,Spark-on-yarn便搭建完成了
时间同步
在跑任务时可能会报错:
Note: System times on machines may be out of sync. Check system time and time zones.
这个是因为三台机子时间不同步的原因
安装NTP服务(三个机子都要):
yum install ntp
手动同步时间(三个机子都要):
ntpdate -u ntp1.aliyun.com
相关文章:
Spark单机伪分布式环境搭建、完全分布式环境搭建、Spark-on-yarn模式搭建
搭建Spark需要先配置好scala环境。三种Spark环境搭建互不关联,都是从零开始搭建。如果将文章中的配置文件修改内容复制粘贴的话,所有配置文件添加的内容后面的注释记得删除,可能会报错。保险一点删除最好。Scala环境搭建上传安装包解压并重命…...
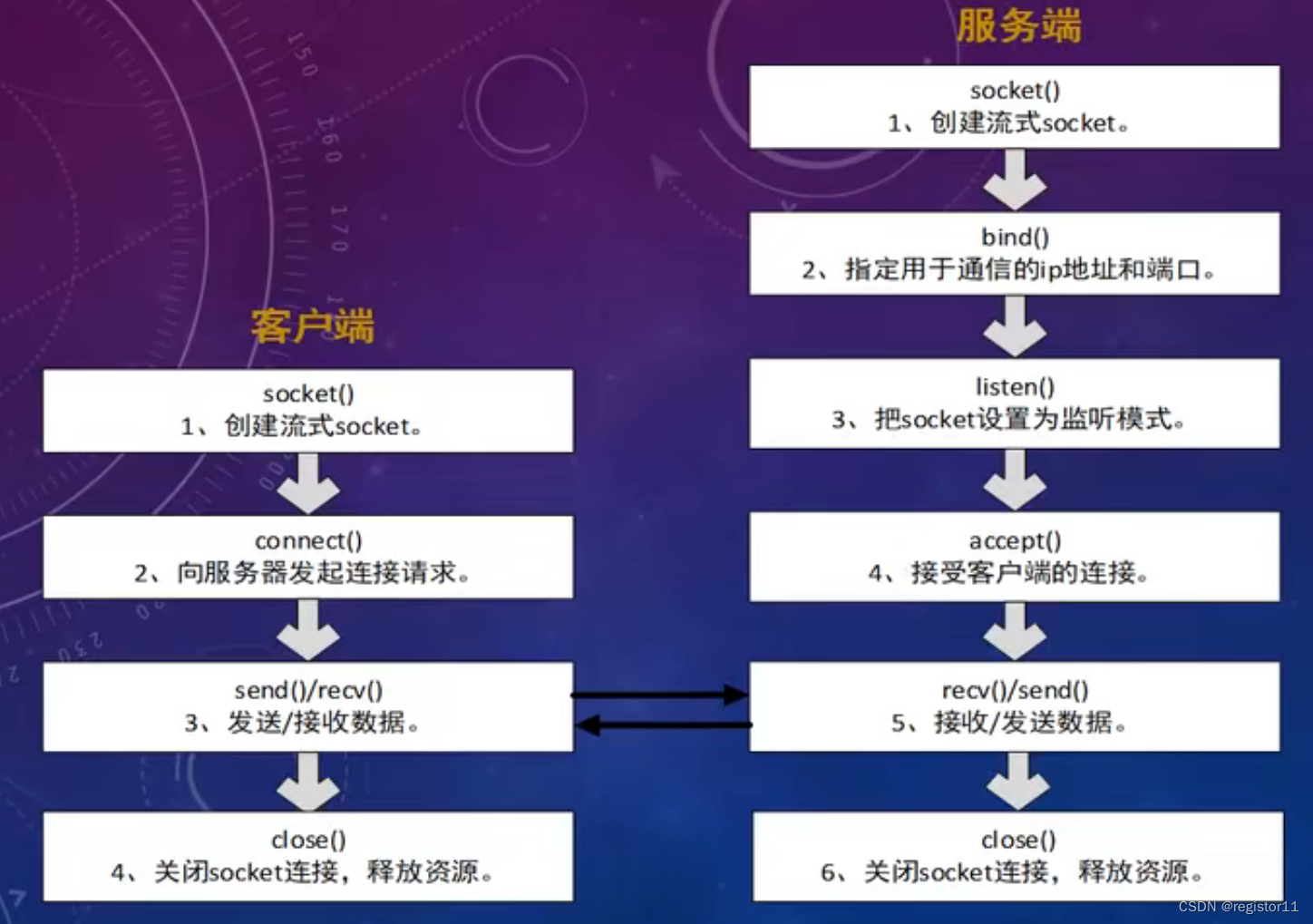
C++网络编程(一)本地socket通信
C网络编程(一) socket通信 前言 本次内容简单描述C网络通信中,采用socket连接客户端与服务器端的方法,以及过程中所涉及的函数概要与部分函数使用细节。记录本人C网络学习的过程。 网络通信的Socket socket,即“插座”,在网络中译作中文“套接字”,应…...

【Docker】Linux下Docker安装使用与Docker-compose的安装
【Docker】的安装与启动 sudo yum install -y yum-utils device-mapper-persistent-data lvm2 sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo sudo yum install docker-cesudo systemctl enable dockersudo systemct…...
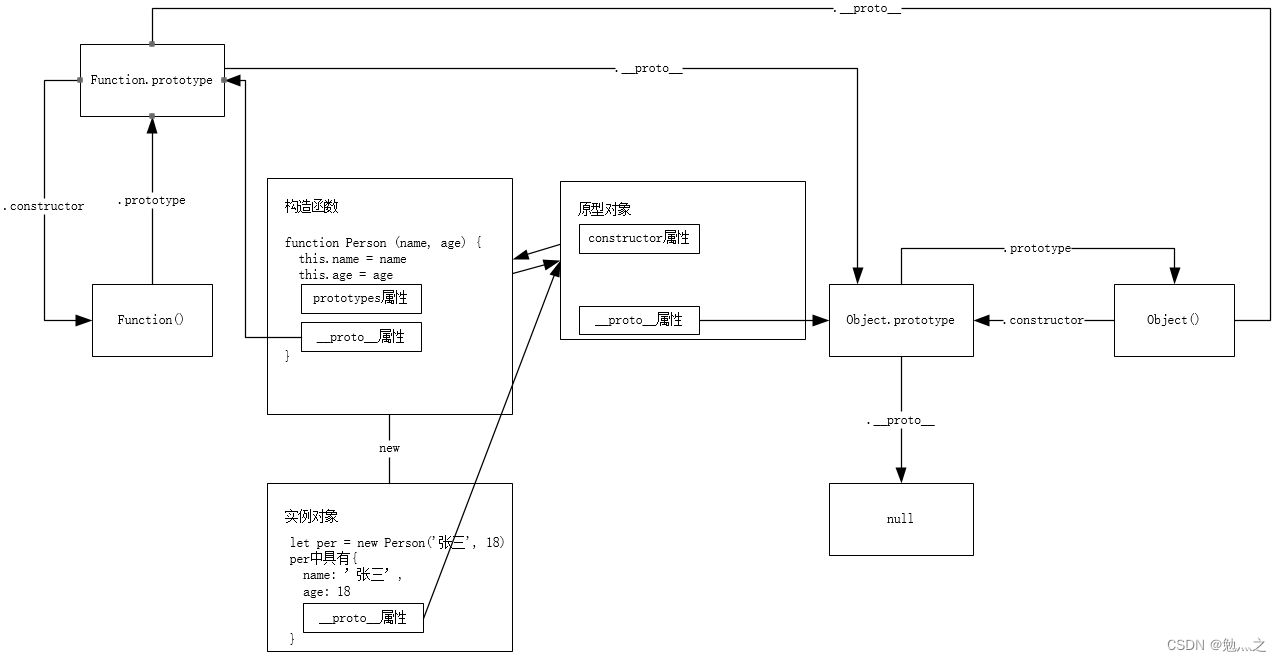
构造函数与普通函数,显式原型与隐式原型,原型与原型链
原型与原型链1 学前先了解一些概念1.1 构造函数和普通函数的区别1.1.1 调用方式1.1.2 函数中this的指向不同1.1.3 写法不同1.2 问题明确2 原型与原型链2.1 原型2.2 显式原型与隐式原型2.3 原型链3 原型链环形结构1 学前先了解一些概念 1.1 构造函数和普通函数的区别 构造函数…...

跨过社科院与杜兰大学金融管理硕士项目入学门槛,在金融世界里追逐成为更好的自己
没有人不想自己变得更优秀,在职的我们也是一样。当我们摸爬滚打在职场闯出一条路时,庆幸的是我们没有沉浸在当下,而是继续攻读硕士学位,在社科院与杜兰大学金融管理硕士项目汲取能量,在金融世界里追逐成为更好的自己。…...
macOS 13.3 Beta 3 (22E5236f)With OpenCore 0.9.1开发版 and winPE双引导分区原版镜像
原文地址:http://www.imacosx.cn/112494.html(转载请注明出处)镜像特点完全由黑果魏叔官方制作,针对各种机型进行默认配置,让黑苹果安装不再困难。系统镜像设置为双引导分区,全面去除clover引导分区&#x…...
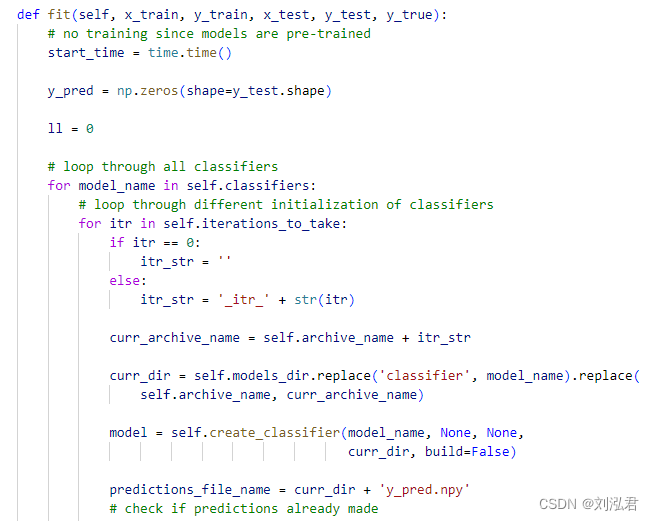
InceptionTime 复现
下载数据集: https://www.cs.ucr.edu/~eamonn/time_series_data/ 挂梯子,开全局模式即可 配置环境 虚拟环境基于python3.9, tensorflow下载:pip install tensorflow,不需要tensorflow-gpu(高版本python&…...
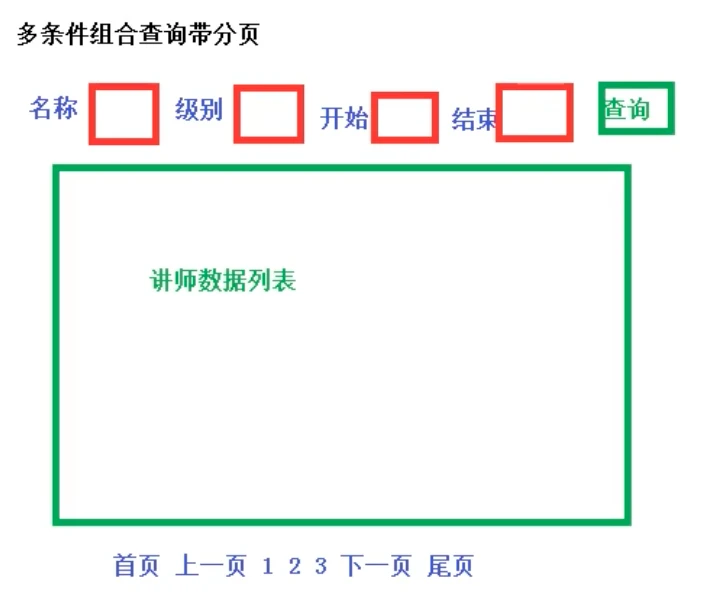
谷粒学院开发(二):教师管理模块
前后端分离开发 前端 html, css, js, jq 主要作用:数据显示 ajax后端 controller service mapper 主要作用:返回数据或操作数据 接口 讲师管理模块(后端) 准备工作 创建数据库,创建讲师数据库表 CREATE TABLE edu…...

2021牛客OI赛前集训营-提高组(第三场) T4扑克
2021牛客OI赛前集训营-提高组(第三场) 题目大意 小A和小B在玩扑克牌游戏,规则如下: 从一副52张牌(没有大小王)的扑克牌中随机发3张到每个玩家手上,每个玩家可以任意想象另外两张牌࿰…...

【OJ比赛日历】快周末了,不来一场比赛吗? #03.11-03.17 #12场
CompHub 实时聚合多平台的数据类(Kaggle、天池…)和OJ类(Leetcode、牛客…)比赛。本账号同时会推送最新的比赛消息,欢迎关注!更多比赛信息见 CompHub主页 或 点击文末阅读原文以下信息仅供参考,以比赛官网为准目录2023-03-11&…...

C++-说一说异常机制
C异常机制是一种处理程序错误的高级方法。当程序出现错误时,可以通过抛出异常来通知调用者进行处理,或者在异常对象被捕获之后终止程序执行。 异常处理语法 在C中,可以使用 throw 抛出异常, try-catch 处理异常,try块中…...

k8s CSI插件浅析
Kubernetes CSI (Container Storage Interface)插件是一种可插拔的存储插件,可以将外部存储系统的功能集成到Kubernetes集群中。它允许Kubernetes管理员动态地将外部存储系统映射到容器中,以满足应用程序对持久化存储的需求。 CSI插件基于一组规范定义的…...

九、CSS3新特性三
文章目录一、逐帧动画二、flex弹性盒子三、少量元素侧轴对齐方式四、折行侧轴对齐方式五、项目属性六、网格布局七、网格布局的对齐方式八、网格布局的项目合并一、逐帧动画 一张背景图,改变back-position-x的位置让他动起来 step-start 逐帧动画 animation: play …...

Dynamics365 本地部署整体界面
昨天已经登陆上去了然后今天开机突然又登陆不上去了 具体原因也不知道 然后我把注册插件删除又重新下载结果还是登陆不上去于是返回之前的断点就可以登陆上去了重复昨天的操作这里就不截图了6、注册新步骤右键单击(插件)BasicPlugin.FollowUpPlugin&…...
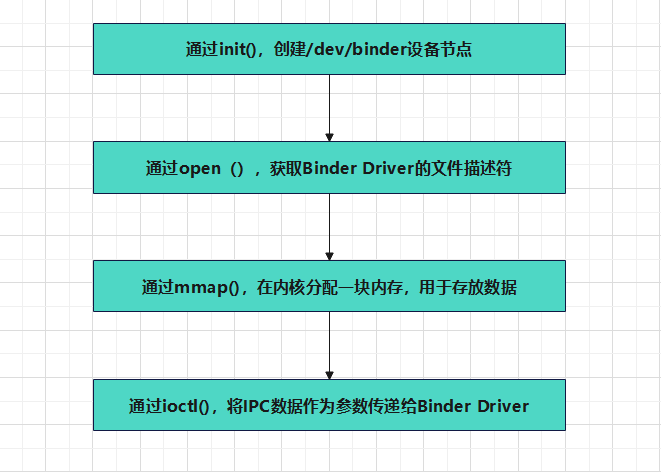
Binder ——binder的jni注册和binder驱动
环境:Android 11源码Android 11 内核源码源码阅读器 sublime textbinder的jni方法注册zygote启动1-1、启动zygote进程zygote是由init进程通过解析init.zygote.rc文件而创建的,zygote所对应的可执行程序是app_process,所对应的源文件是app_mai…...

Python+Yolov8目标识别特征检测
Yolov8目标识别特征检测如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助!前言这篇博客针对<<Yolov8目标识别特征检测>>编写代码,代码整洁,规则,易读。 学习与应用推荐…...
欢迎使用Markdown编辑器
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注…...
Mac环境安装python
一、介绍: Python是跨平台的,它可以运行在Windows、Mac和各种Linux/Unix系统上。在Windows上写Python程序,放到Linux上也是能够运行的。 要开始学习Python编程,首先就得把Python安装到你的电脑里。安装后,你会得到Pyt…...

2023年全国最新交安安全员精选真题及答案16
百分百题库提供交安安全员考试试题、交安安全员考试预测题、交安安全员考试真题、交安安全员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 一、判断题: 1.施工单位应当向作业人员提供安全防护用具和安全防护服…...
项目实战-瑞吉外卖day02(B站)持续更新
瑞吉外卖-Day02课程内容完善登录功能新增员工员工信息分页查询启用/禁用员工账号编辑员工信息1. 完善登录功能1.1 问题分析前面我们已经完成了后台系统的员工登录功能开发,但是目前还存在一个问题,接下来我们来说明一个这个问题, 以及如何处理…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...
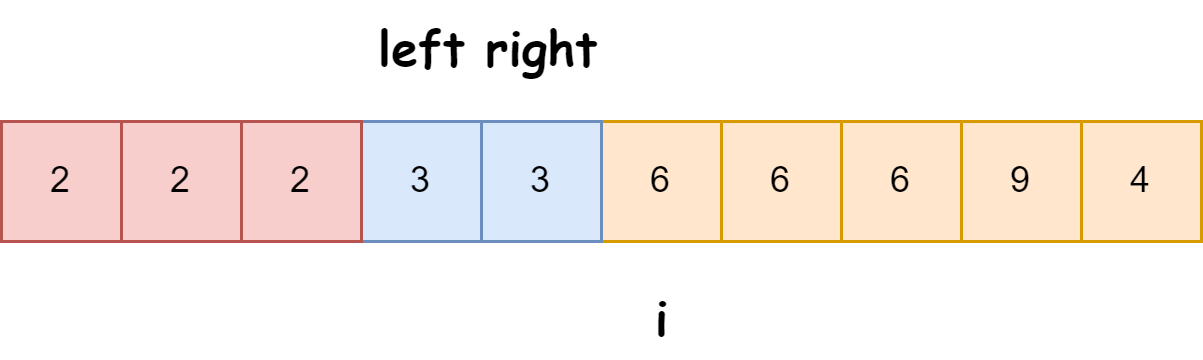
快速排序算法改进:随机快排-荷兰国旗划分详解
随机快速排序-荷兰国旗划分算法详解 一、基础知识回顾1.1 快速排序简介1.2 荷兰国旗问题 二、随机快排 - 荷兰国旗划分原理2.1 随机化枢轴选择2.2 荷兰国旗划分过程2.3 结合随机快排与荷兰国旗划分 三、代码实现3.1 Python实现3.2 Java实现3.3 C实现 四、性能分析4.1 时间复杂度…...

【实施指南】Android客户端HTTPS双向认证实施指南
🔐 一、所需准备材料 证书文件(6类核心文件) 类型 格式 作用 Android端要求 CA根证书 .crt/.pem 验证服务器/客户端证书合法性 需预置到Android信任库 服务器证书 .crt 服务器身份证明 客户端需持有以验证服务器 客户端证书 .crt 客户端身份…...