5、Elasticsearch优化
一、Elasticsearch集群配置
1、硬件选择
Elasticsearch的基础是 Lucene ,所有的索引和文档数据是存储在本地的磁盘中,
具体的路径可在 ES 的配置文件 ../config/elasticsearch.yml 中配置,如下:磁盘在现代服务器上通常都是瓶颈。Elasticsearch 重度使用磁盘,你的磁盘能处理的吞吐量越大,你的节点就越稳定。这里有一些优化磁盘 I/O 的技巧:1、使用 SSD。就像其他地方提过的, 他们比机械磁盘优秀多了。2、使用 RAID 0。条带化 RAID 会提高磁盘 I/O,代价显然就是当一块硬盘故障时整个就故障了。
不要使用镜像或者奇偶校验 RAID 因为副本已经提供了这个功能。3、另外,使用多块硬盘,并允许 Elasticsearch 通过多个 path.data
目录配置把数据条带化分配到它们上面。4、不要使用远程挂载的存储,比如 NFS 或者 SMB/CIFS 。这个引入的延迟对性能来说完全是背道而驰的。2、分片策略
2.1、分片大小保持在10GB-50GB之间
分片大小保持在10GB-50GB之间,大的分片在故障恢复时会占用较长的时间。当某个节点发生故障时,Elasticsearch会根据剩余节点的数据自动的重新平衡分片。恢复进程通常是在网络之间拷贝分片的内容,因此一个100GB的分片会比50GB的分片花费更多的时间。相比之下,小分片的开销更大,搜索效率也更低。搜索50个1GB分片将比搜索一个包含相同数据的50GB分片占用更多资源。分片的大小并没有强制的限制。但经验值是10-50GB之间的分片通常在日志和时间序列的数据流索引上表现更好。 总结:打分片性能好,故障恢复慢,小分片性能差,故障恢复快。
2.2、每GB堆内存对应少于20个分片
数据节点可以容纳的分片数与节点的堆内存成比例。例如,具有30GB堆内存的节点最多应该有600个分片。越是低于此比例,就越能保持节点性能。如果发现节点超过每GB 20个以上的分片,请考虑添加另一个节点。单节点分片数计算=JVM堆大小*20
2.3、避免节成为热点
如果分配给特定节点的分片太多,该节点可能会成为热点。例如,如果单个节点包含的分片太多,索引量太大,则该节点可能会出现问题。
3、推迟分片分配
推迟因通讯中断导致分片再次检测平衡。
对于节点瞬时中断的问题,默认情况,集群会等待一分钟来查看节点是否会重新加入,如果这个节点在此期间重新加入,重新加入的节点会保持其现有的分片数据,不会触发新的分片分配。这样就可以减少 ES 在自动再平衡可用分片时所带来的极大开销。通过修改参数delayed_timeout ,可以延长再均衡的时间,可以全局设置也可以在索引级别进行修改:#PUT /_all/_settings
{"settings": {"index.unassigned.node_left.delayed_timeout": "5m"}
}4、路由选择
当我们查询文档的时候,Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?
它其实是通过下面这个公式来计算出来
shard = hash(routing) % number_of_primary_shards
routing默认值是文档的 id ,也可以采用自定义值,比如用户 id 。
不带routing 查询
在查询的时候因为不知道要查询的数据具体在哪个分片上,所以整个过程分为2 个步骤
1. 分发:请求到达协调节点后,协调节点将查询请求分发到每个分片上。
2. 聚合 : 协调节点搜集到每个分片上查询结果,在将查询的结果进行排序,之后给用户返回结果。
带routing 查询
查询的时候,可以直接根据routing 信息定位到某个分片查询,不需要查询所有的分片,经过协调节点排序。
向上面自定义的用户查询,如果routing 设置为 userid 的话,就可以直接查询出数据来,效率提升很多。
5、写入速度优化
ES的默认配置,是综合了数据可靠性、写入速度、搜索实时性等因素。实际使用时,我们需要根据公司要求,进行偏向性的优化。
针对于搜索性能要求不高,但是对写入要求较高的场景,我们需要尽可能的选择恰当写优化策略。
综合来说,可以考虑以下几个方面来提升写索引的性能:
1、加大 Translog Flush ,目的是降低 Iops 、 Writeblock 。
2、增加 Index Refresh 间隔,目的是减少 Segment Merge 的次数。
3、调整 Bulk 线程池和队列。
4、优化节点间的任务分布。
5、优化 Lucene 层的索引建立,目的是降低 CPU 及 IO
5.1、批量数据提交
ES提供了 Bulk API 支持批量操作,当我们有大量的写任务时,可以使用 Bulk 来进行批量写入。
通用的策略如下:
Bulk 默认设置批量提交的数据量不能超过 100M 。数据条数一般是根据文档的大小和服务器性能而定的,但是单次批处理的数据大小应从 5MB 15MB 逐渐增加,当性能没有提升时,把这个数据量作为最大值。
5.2 优化存储设备
ES是一种密集使用磁盘的应用,在段合并的时候会频繁操作磁盘,所以对磁盘要求较高,当磁盘速度提升之后,集群的整体性能会大幅度提高。
5.3 合理使用段合并
1、segment段创建过程
当我们往 ElasticSearch 写入数据时,数据是先写入 memory buffer,然后定时(默认每隔1s)将 memory buffer 中的数据写入一个新的 segment 文件中,并进入 Filesystem cache(同时清空 memory buffer),这个过程就叫做 refresh;每个 Segment 事实上是一些倒排索引的集合, 只有经历了 refresh 操作之后,数据才能变成可检索的。
ElasticSearch 每次 refresh 一次都会生成一个新的 segment 文件,这样下来 segment 文件会越来越多。那这样会导致什么问题呢?因为每一个 segment 都会占用文件句柄、内存、cpu资源,更加重要的是,每个搜索请求都必须访问每一个segment,这就意味着存在的 segment 越多,搜索请求就会变的更慢。
每个 segment 是一个包含正排(空间占比90~95%)+ 倒排(空间占比5~10%)的完整索引文件,每次搜索请求会将所有 segment 中的倒排索引部分加载到内存,进行查询和打分,然后将命中的文档号拿到正排中召回完整数据记录。如果不对segment做配置,就会导致查询性能下降
那么 ElasticSearch 是如何解决这个问题呢? ElasticSearch 有一个后台进程专门负责 segment 的合并,定期执行 merge 操作,将多个小 segment 文件合并成一个 segment,在合并时被标识为 deleted 的 doc(或被更新文档的旧版本)不会被写入到新的 segment 中。合并完成后,然后将新的 segment 文件 flush 写入磁盘;然后创建一个新的 commit point 文件,标识所有新的 segment 文件,并排除掉旧的 segement 和已经被合并的小 segment;然后打开新 segment 文件用于搜索使用,等所有的检索请求都从小的 segment 转到 大 segment 上以后,删除旧的 segment 文件,这时候,索引里 segment 数量就下降了。如下
2、segment的merge 对性能的影响
segment 合并的过程,需要先读取小的 segment,归并计算,再写一遍 segment,最后还要保证刷到磁盘。可以说,合并大的 segment 需要消耗大量的 I/O 和 CPU 资源,同时也会对搜索性能造成影响。所以 Elasticsearch 在默认情况下会对合并线程进行资源限制,确保它不会对搜索性能造成太大影响。
默认情况下,归并线程的限速配置 indices.store.throttle.max_bytes_per_sec 是 20MB。对于写入量较大,磁盘转速较高,甚至使用 SSD 盘的服务器来说,这个限速是明显过低的。对于 ELK Stack 应用,建议可以适当调大到 100MB或者更高。设置方式如下:
PUT /_cluster/settings
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}
或者不限制:PUT /_cluster/settings
{
"transient" : {
"indices.store.throttle.type" : "none"
}
}
5.4 减少Refresh的次数
Lucene在新增数据时,采用了延迟写入的策略,默认情况下索引的 refresh_interval 为1 秒。
Lucene将待写入的数据先写到内存中,超过 1 秒(默认 )时就会触发一次 Refresh,然后 Refresh 会把内存中的的数据刷新到操作系统的文件缓存系统中。
如果我们对搜索的实效性要求不高,可以将Refresh 周期延长,例如 30 秒。
这样还可以有效地减少段刷新次数,但这同时意味着需要消耗更多的Heap 内存。
5.5、加大Flush设置
Flush的主要目的是把文件缓存系统中的段持久化到硬盘,当 Translog 的数据量达到512MB 或者 30 分钟时,会触发一次 Flush。index.translog.flush_threshold_size 参数的默认值是 512MB ,我们进行修改。增加参数值意味着文件缓存系统中可能需要存储更多的数据,所以我们需要为操作系统的文件缓存系统留下足够的空间。
5.6、减少副本的数量
ES为了保证集群的可用性,提供了 Replicas (副本)支持,然而每个副本也会执行分析、索引及可能的合并过程,所以 Replicas 的数量会严重影响写索引的效率。当写索引时,需要把写入的数据都同步到副本节点,副本节点越多,写索引的效率就越慢,查询并发越高。
如果我们需要大批量进行写入操作,可以先禁止Replica 复制,设置index.number_of_replicas: 0 关闭副本。在写入完成后, Replica 修改回正常的状态。
6、内存设置
Xmx 和 Xms 的大小是相同的。其目的是为了能够在 Java 垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源,可以减轻伸缩堆大小带来的压力。
假设你有一个64G 内存的机器,按照正常思维思考,你可能会认为把 64G 内存都给ES 比较好,但现实是这样吗, 越大越好?
虽然内存对 ES 来说是非常重要的,但是答案是否定的!
因为ES 堆内存的分配需要满足以下两个原则:
不要超过物理内存的 50%。 Lucene 的设计目的是把底层 OS 里的数据缓存到内存中。
Lucene的段是分别存储到单个文件中的,这些文件都是不会变化的,所以很利于缓存,同时操作系统也会把这些段文件缓存起来,以便更快的访问。如果我们设置的堆内存过大,Lucene 可用的内存将会减少,就会严重影响降低 Lucene 的全文本查询性能。
堆内存的大小最好不要超过 32GB 。在 Java 中,所有对象都分配在堆上,然后有一个 Klass Pointer 指针指向它的类元数据。这个指针在64 位的操作系统上为 64 位
7、集群模式
7.1、集群类型
1、master node节点
整个集群的管理者、索引管理、分片管理,以及整个集群的状态的管理,master节点是从master候选节点中选出的,成为master候选节点的方式:node.master:true 默认(true)
data node:数据节点,存储主要数据,负责索引的数据的检索和聚合等操作,设置data node的方式如下:
node.master:true
node.data:false
2、data node节点
该节点和应用创建连接、接收索引请求,会存储分配在该node上的shard的数据并负责这些shard的写入、查询等,ES集群的性能取决于该节点的个数(每个节点最优配置的情况下),data节点会占用大量的CPU、io和内存;data节点的分片执行查询语句、获得查询结果后将结果反馈给Coordinating,此过程较消耗硬件资源;设置成为data节点的方式
node.data:true
node.master:false
3、coordinating node节点
协调节点,所有节点都可以接受来自客户端的请求进行转发,因为每个节点都知道集群的所有索引分片的分布情况,但是别的节点,都还肩负着别的工作,如果请求压力过大,可能会拖垮整个集群的响应速度,所以就专门有了这个协调节点,他什么都不用做,只处理请求和请求结果,这种设计的好处是,如果集群资源不足,被干死的是coordinating node, marster、data节点安全,设置成为coordinating node节点的方式:
node.data:false
node.master:false
4、ingest node节点
预处理节点,主要是对数据进行预处理,比如对字段重命名,分解字段内容,增加字段等,类似于Logstash, 就是对数据进行预处理,ingest里面可以定义pipeline(管道),pipeline可以由很多个processor(官方预定义28个)构成,用来出来预处理数据,使用方式:先定义好预处理pipeline,然后在存储数据的时候指定pipeline,如:成为ingest node的方式 node.ingest:true 默认(true)
7.2、稳定压倒一切的配置
3个master(参与选主)、N个data(存储、计算)、coordinating(高并发请求场景需要设置次节点)
8、其他设置
1、cluster.name配置ES 的集群名称。建议改成与所存数据相关的名称,ES 会自动发现在同一网段下的集群名称相同的节点
2、node.name集群中的节点名,在同一个集群中不能重复。节点的名称一旦设置,就不能再改变了。当然,也可以设置成服务器的主机名称
3、node.data指定该节点是否存储索引数据。默认为True 。数据的增、删、改、查都是在 Data 节点完成的。
4、index.number_of_shards设置都索引分片个数。也可以在创建索引时设置该值,具体设置为多大的值要根据数据量的大小来定。如果数据量不大,则设置成 1 时效率最高
5、index.number_of_replicas设置默认的索引副本个数。副本数越多,集群的可用性越 好,但是写索引时需要同步的数据越多。
6、transport.tcp.compress设置在节点间传输数据时是否压缩,默认为False不压缩
7、discovery.zen.minimum_master_nodes设置在选举Master 节点时需要参与的最少的候选主节点数,默认为 1 。如果使用默认值,则当网络不稳定时有可能会出现脑裂。合理的数值为
(master_eligible_nodes/2)+1 ,其中master_eligible_nodes 表示集群中的候选主节点数
8、discovery.zen.ping.timeout 设置在集群中自动发现其他节点时Ping 连接的超时时间,默认为 3 秒。在较差的网络环境下需要设置得大一点,防止因误判该节点的存活状态而导致分片的转移
二、开发注意优化
1、客户端选择
目前支持客户端有sql、dml、dml。为了开发效率建议选择sql方式,es7版本对sql支持度比较友好,其他版本可以安装es-sql插件实现sql效果。
2、字段类型设置
无分词需求字段类型设置为keyworld不会被分词
3、搜索的深度分页设置
索引深度不易过深入,否则会导致分页性能低。如果是数据导出需求可以用游标实现,如果数据量过大可以通过设置新索引的方式做。比如:index_2021_电器、index_2021_食品....
4、创建索引
1、Mapping设置与Query查询优化问题
在ES中创建Mappings时,默认_source是enable=true,会存储整个document的值,当执行search操作的时,会返回整个document的信息。如果只想返回document的部分fields,但_source会返回原始所有的内容,当某些不需要返回的field很大时,ES查询的性能会降低,这时候可以考虑使用store结合_source的enable=false来创建mapping。
2、设置索引刷新频率
index.refresh_interval:刷新操作频率,最近对索引的更改既可见,默认1s。-1关闭刷新操作。设置符合自己项目需求越大性能越好。
5、explain分析慢查询
#es 性能分析语句
GET online_exercise/_doc/_search
{"explain" : true,"query": {"match_all": {}}
}相关文章:

5、Elasticsearch优化
一、Elasticsearch集群配置 1、硬件选择 Elasticsearch的基础是 Lucene ,所有的索引和文档数据是存储在本地的磁盘中, 具体的路径可在 ES 的配置文件 ../config/elasticsearch.yml 中配置,如下:磁盘在现代服务器上通常都是瓶颈。…...

地质灾害防治单位资质
地质灾害危险性评估,是指在地质灾害易发区进行工程建设或者编制地质灾害易发区内的国土空间规划时,对建设工程或者规划区遭受山体崩塌、滑坡、泥石流、地面塌陷、地裂缝、地面沉降等地质灾害的可能性和建设工程引发地质灾害的可能性作出评估,…...
打怪升级之发送单个UDP包升级版
目标 1.message的输入由edit_control进行,需要捕获输入。 2.用户的主机地址和发送地址不一样,需要分别设置并绑定。 设计RC外观 必备组件:主机IP与端口,从机IP与端口,消息框,发送,连接按钮。…...

MyBatis开发
MyBatis开发入门搭建MyBatis框架开发环境在自己建的的项目建立个lib文件然后导入包3.两个jar包部署到项目中和为项目添加测试类库4.配置数据库mybatis-config.xml里面的配置:<?xml version"1.0" encoding"UTF-8"?> <!DOCTYPE config…...
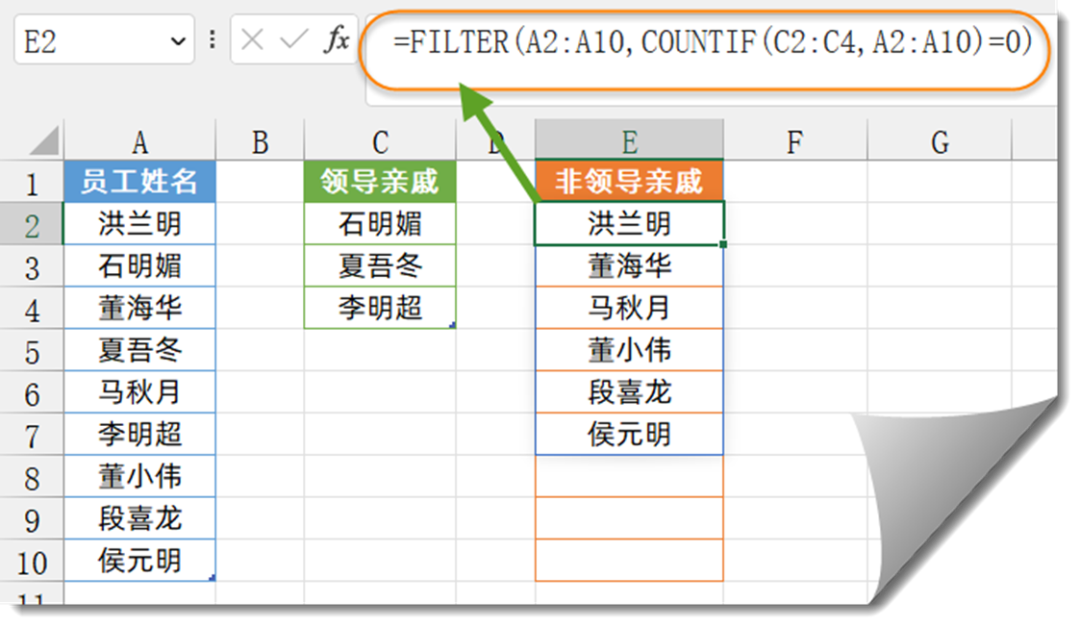
excel 数据查询,几个模式化公式请收好
1、一对多查询 所谓一对多,就是符合某个指定条件的有多个结果,要把这些结果都提取出来。 如下图所示,希望根据F2单元格中指定的部门,提取出左侧列表中“生产部”的所有人员姓名。 Excel 2019及以下版本:在H2单元格输…...

Prometheus MySQL 性能监控
一、 介绍 Prometheus 是一种开源的监控系统和时序数据库,旨在收集和处理大量数据并提供可视化、监控警报等功能。它支持多种语言、多种部署方式,并且非常灵活,而且社区支持非常活跃,为用户提供了很多优秀的解决方案。 MySQL 是一…...

刷题记录:牛客NC24261[USACO 2019 Feb G]Cow Land
传送门:牛客 题目描述 Cow Land 总共有 NNN 个不同的景点( 2≤N≤1052 \leq N \leq 10^52≤N≤105 )。 一共有 n−1n-1n−1 条道路连接任意两个景点,这意味着任意两个景点间只有一条简单路径。 每个景点 iii 都有一个享受值 eie_iei &…...

MYSQL开发误区
一、表、列、索引设计误区 1、现象:在线业务系统出现了三张表以上的关联查询 建议:说明业务逻辑在表设计上的实现不合理,需要进行表结构调整,或进行列的冗余,或进行业务改造。 2、现象:大表拆成多张小表之…...
k8s学习之路 | k8s 工作负载 DaemonSet
文章目录1. DaemonSet 基础1.1 什么是 DS1.2 DS 的典型用法1.3 如何编写 DS 资源1.4 DS 示例文件1.5 DS Pod 是如何被调度的1.6 更新 DS1.7 DS 替代方案1.8 DS 工作负载字段描述2. DaemonSet 的使用2.1 每个节点运行一个2.2 DS 更新策略2.3 滚动更新2.4 OnDelete 更新2.6 更新回…...
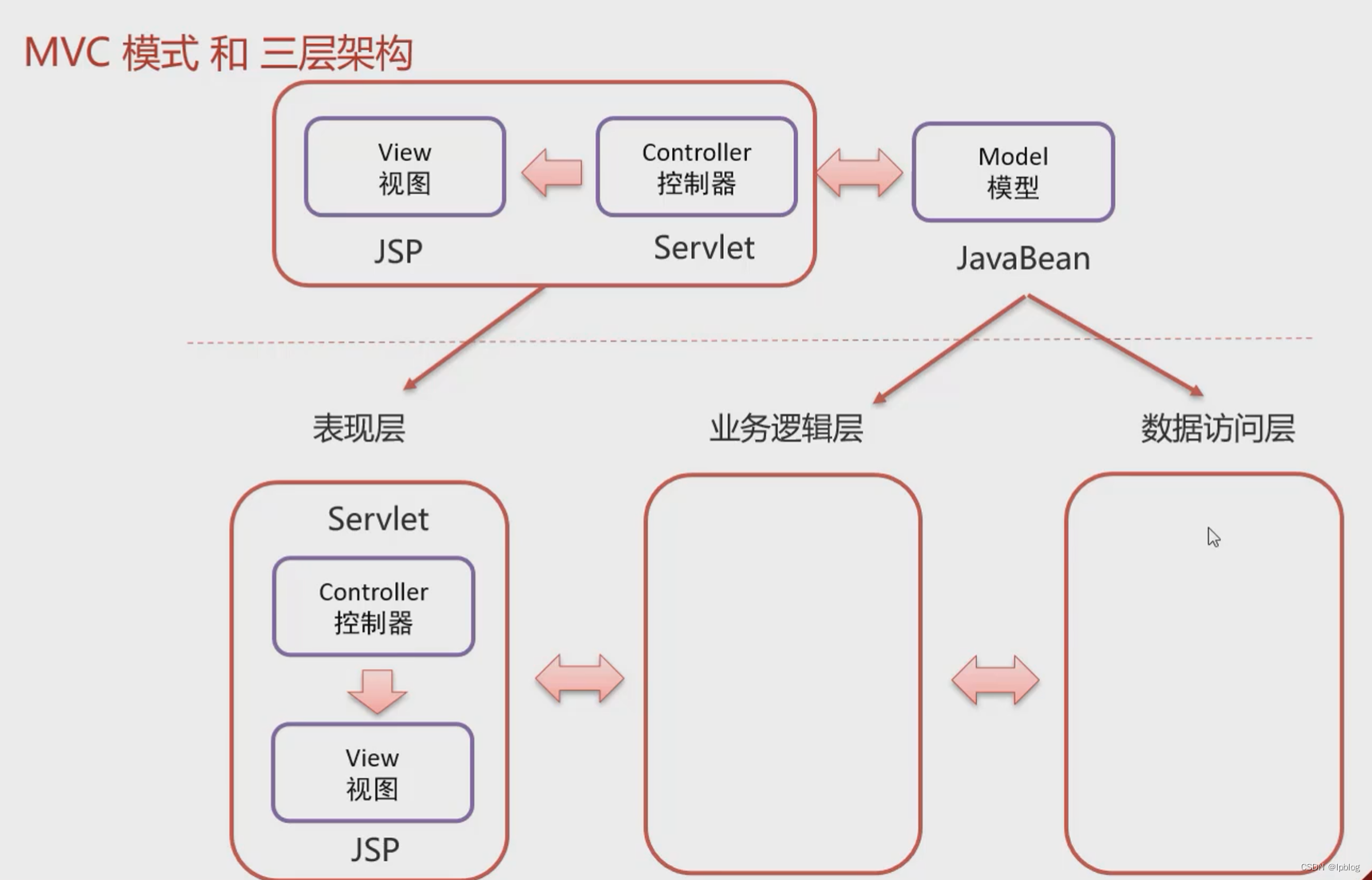
Javaweb MVC模式和三层架构
MVC 模式和三层架构是一些理论的知识,将来我们使用了它们进行代码开发会让我们代码维护性和扩展性更好。 7.1 MVC模式 MVC 是一种分层开发的模式,其中: M:Model,业务模型,处理业务 V:View&am…...

综合考虑,在客户端程序中嵌入网页程序,首选CefSharp。
综合考虑,在客户端程序中嵌入网页程序,首选CefSharp。 CefSharp 是一种将全功能符合标准的 Web 浏览器嵌入 C# 或 VB.NET 应用程序的简单方法。 https://www.jianshu.com/p/3f50cc747606 WinForm嵌入Web网页的解决方案 Microsoft Edge WebView2诞生较晚…...

【Java基础 下】 030 -- 网络编程
目录 一、什么是网络编程 1、常见的软件架构(CS & BS) ①、BS架构的优缺点 ②、CS架构的优缺点 2、小结 二、网络编程三要素 1、IP ①、IPv4 ②、IPv6 ③、小结 ④、IPv4的一些细节 ⑤、InetAddress的使用 2、端口号 3、协议 ①、TCP & UDP 三、…...
 T3打拳)
2021牛客OI赛前集训营-提高组(第三场) T3打拳
2021牛客OI赛前集训营-提高组(第三场) 题目大意 有2n2^n2n个选手参加拳击比赛,每个人都有一个实力,所有选手的实力用一个111到2n2^n2n的排列表示。 淘汰赛的规则是:每次相邻的两个选手进行比赛,实力值大…...

C++面向对象编程之四:成员变量和成员函数分开存储、this指针、const修饰成员和对象
在C中,成员变量和成员函数是分开存储的,只有非静态成员变量才存储在类中或类的对象上。通过该类创建的所有对象都共享同一个函数#include <iostream> using namespace std;class Monster {public://成员函数不占对象空间,所有对象共享同…...
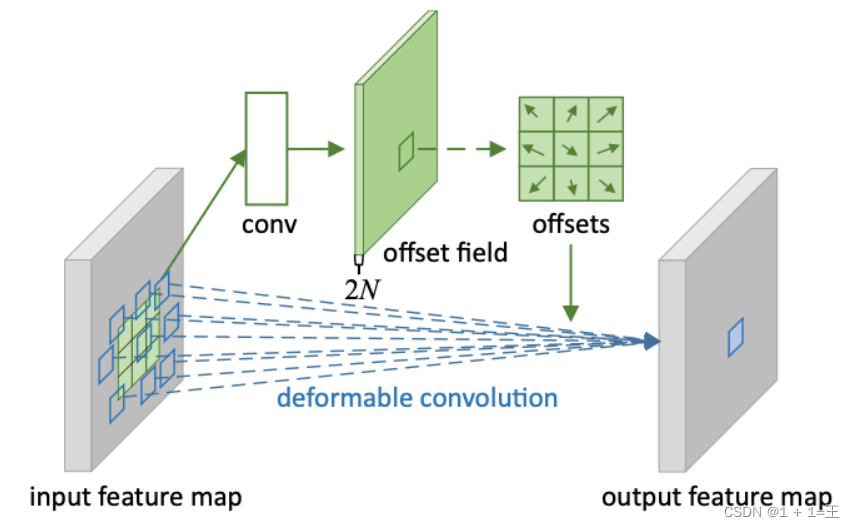
卷积神经网络(CNN)基础知识
文章目录CNN的组成层卷积层卷积运算卷积的变种分组卷积转置卷积空洞卷积可变形卷积卷积层的输出尺寸和参数量CNN的组成层 在卷积神经⽹络中,⼀般包含5种类型的⽹络层次结构:输入层、卷积层、激活层、池化层和输出层。 输入层(input layer&a…...

opencv+python 常见图像预处理
import os import cv2 import numpy as np import pandas as pd from PIL import Image import matplotlib.pylab as plt """图像预处理"""#缩放 #灰度化 #二值化-otsu,自定义,自适应 #均值滤波 #中值滤波 #自定义滤波 #高斯/双倍滤波…...

如何实现一个单例模式
目录 前言 1.饿汉式 2.懒汉式 3.双重检测 4.静态内部类 5.枚举 总结: 前言 单例模式是我们日常开发过程中,遇到的最多的一种设计模式。通过这篇文章主要分享是实现单例的几种实现方式。 1.饿汉式 饿汉式的实现方式比较简单。在类加载的时候&#…...
传输线的物理基础(四):传输线的驱动和返回路径
驱动一条传输线对于将信号发射到传输线的高速驱动器,传输线在传输时间内的输入阻抗将表现得像一个电阻,相当于线路的特性阻抗。鉴于此等效电路模型,我们可以构建驱动器和传输线的电路,并计算发射到传输线中的电压。等效电路如下图…...

Java多态性
文章目录对象的多态性多态的理解举例7.2 多态的好处和弊端7.3 虚方法调用(Virtual Method Invocation)7.4 成员变量没有多态性7.5 向上转型与向下转型7.6 为什么要类型转换呢?7.7 如何向上转型与向下转型7.8 instanceof关键字7.9 复习:类型转换7.10 练习…...

算法拾遗二十七之窗口最大值或最小值的更新结构
算法拾遗二十七之窗口最大值或最小值的更新结构滑动窗口题目一题目二题目三题目四滑动窗口 第一种:R,R右动,数会从右侧进窗口 第二种:L,L右动,数从左侧出窗口 题目一 arr是N,窗口大小为W&…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

为什么要创建 Vue 实例
核心原因:Vue 需要一个「控制中心」来驱动整个应用 你可以把 Vue 实例想象成你应用的**「大脑」或「引擎」。它负责协调模板、数据、逻辑和行为,将它们变成一个活的、可交互的应用**。没有这个实例,你的代码只是一堆静态的 HTML、JavaScript 变量和函数,无法「活」起来。 …...

深入理解Optional:处理空指针异常
1. 使用Optional处理可能为空的集合 在Java开发中,集合判空是一个常见但容易出错的场景。传统方式虽然可行,但存在一些潜在问题: // 传统判空方式 if (!CollectionUtils.isEmpty(userInfoList)) {for (UserInfo userInfo : userInfoList) {…...