DETR论文重点
DETR就是 DEtection TRansformer 的缩写。
论文原名:End-to-End Object Detection with Transoformers。
重点有两个:端到端、Transformer结构
论文概述
注意:斜体的文字为论文原文,其他部分内容则是为增进理解而做的解释。
我们提出了一种将目标检测视为直接集合预测问题的新方法。
如何理解集合预测?
假设一张图像中有 N 个目标,那这 N 个 目标就是一个集合,DETR这个算法就是可以一次性从图像中预测出这个包含 N 个 目标的集合。
我们的方法简化了检测流程,有效地消除了许多手工设计的组件,如非极大值抑制过程或锚生成,这些组件明确地编码了我们关于任务的先验知识。
之前的算法一般都要在最后得到的一堆预测框中做NMS去删除冗余的预测框,或者是手工设计锚,这就需要我们使用先验知识,比如说对于一些像素,我们需要为它去设计产生几个锚,比如说产生三个锚,那么这三个锚的尺寸和高宽比是什么样的,这些都需要使用先验知识去进行设计,而 DETR 则不需要这些,它是一个端到端的网络。

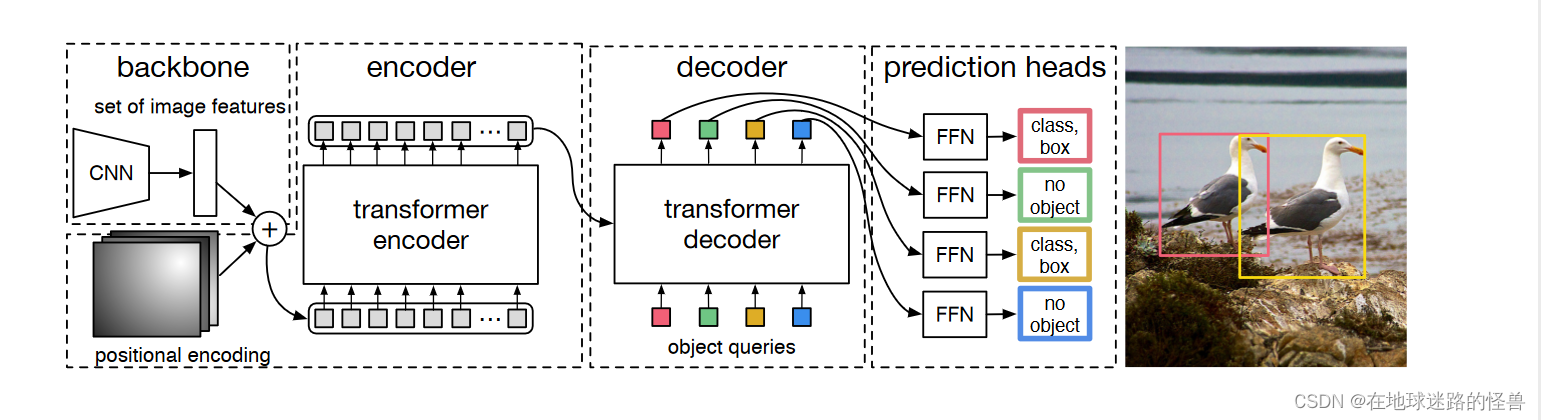
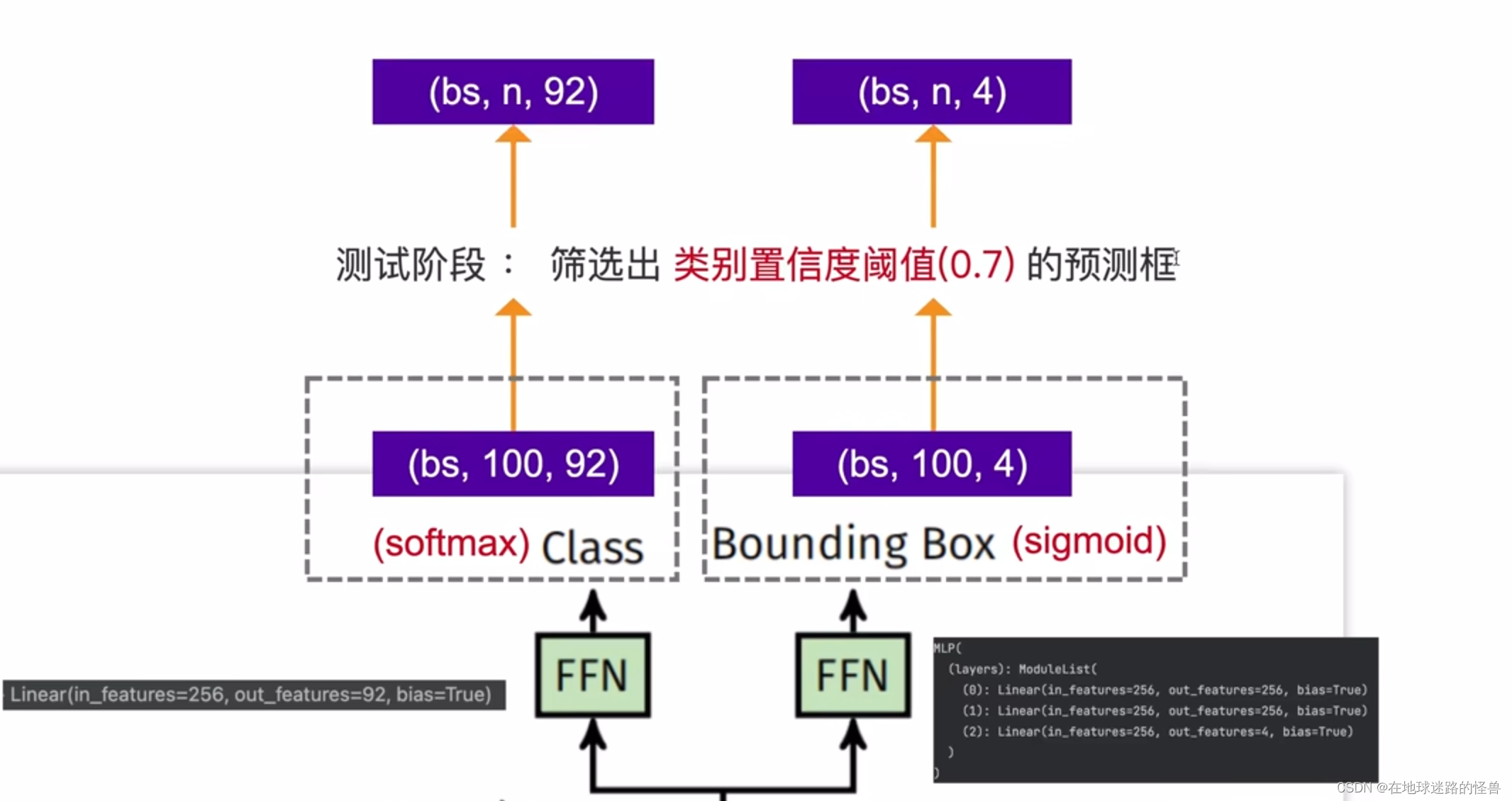
DETR训练和测试的框架示意图:
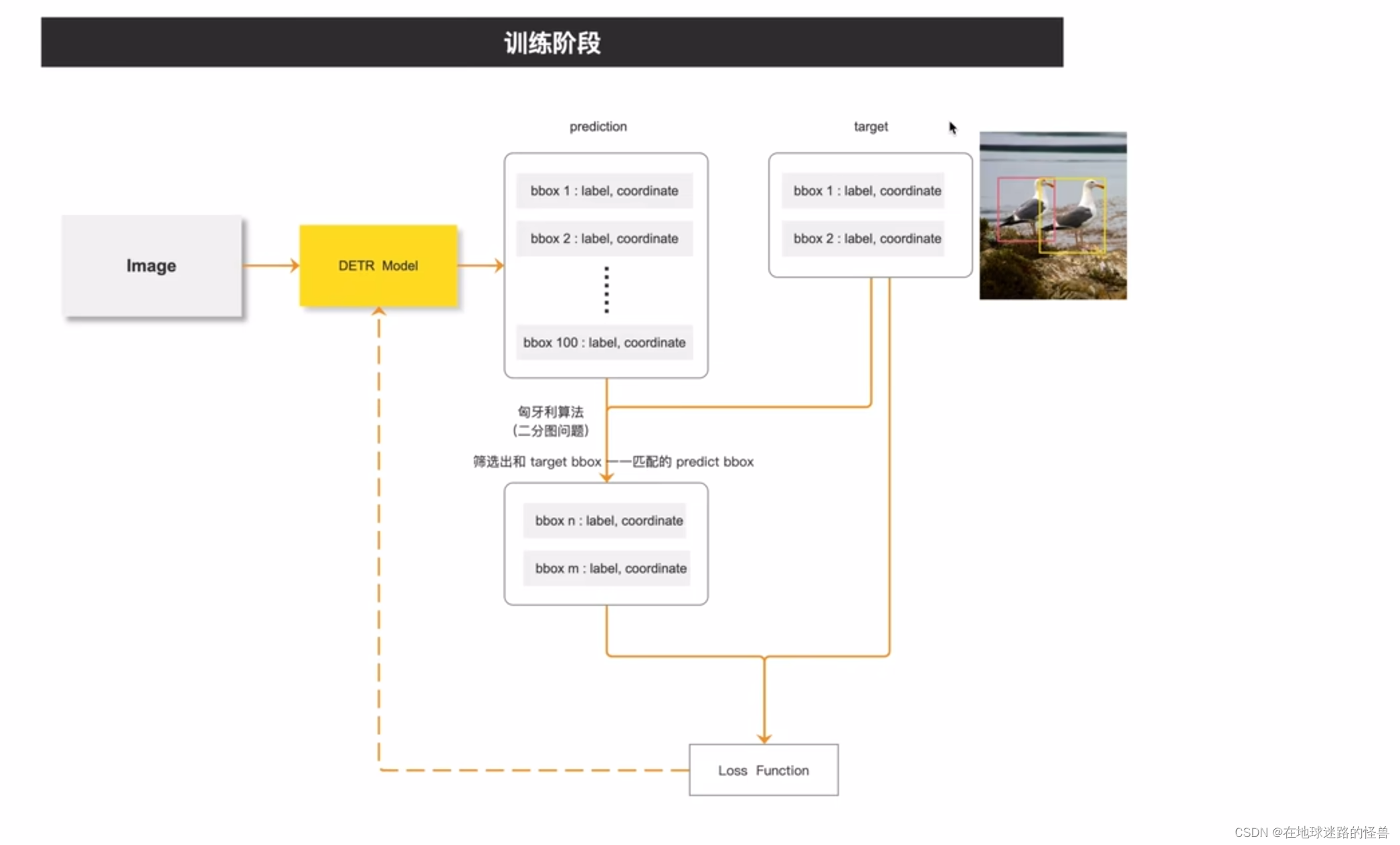
从上图可以看到,在训练阶段中,将一张图像扔入 DETR 模型,然后会得到一百(这个一百数值是个超参数,因为大部分图像中的 object 的数量都不会超过一百个,所以这里选择一百)个预测框,其中包括了这一百个预测框的类别信息和坐标信息。
然后从标注信息中我们可以知道这张图像中总共有两个 object ,然后就使用匈牙利算法从预测出的一百个候选框当中筛选中两个预测框,这两个预测框和这两个标注框是一一对应的关系,最后再使用筛选出的这两个预测框和这两个标注框一起去计算损失,然后再反向传播(图中虚线位置)去优化模型。
测试阶段:
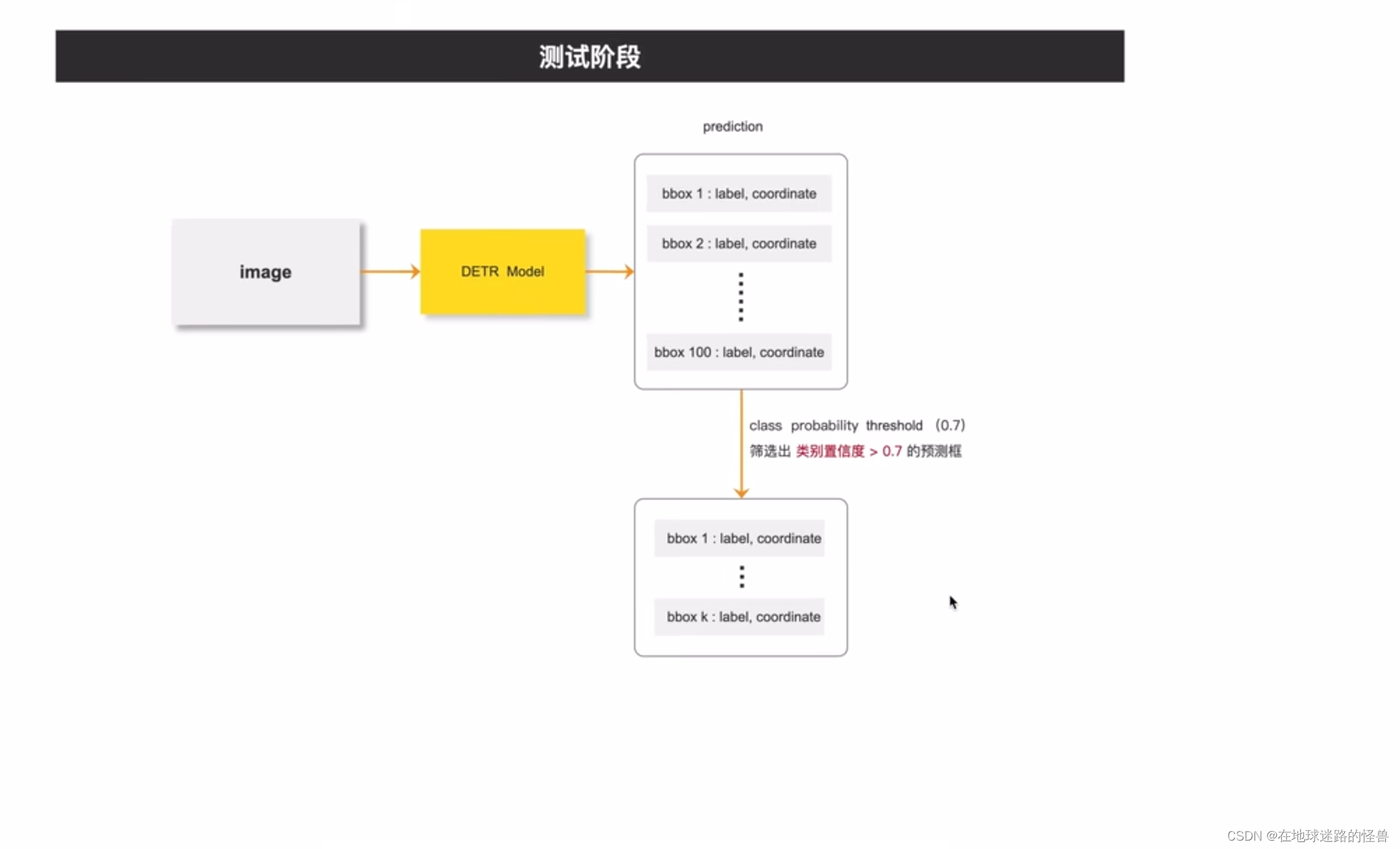
上图是测试阶段,在测试阶段,同样通过网络预测出一百个预测框之后,将这一百个预测框的类别的置信度和类别置信度阈值进行对比,大于阈值的预测框我们进行保留,小于阈值的就排除掉,所以通过训练阶段框架和测试阶段框架我们可以知道,在 DETR 里我们是不用手动设计anchor的。
同样,也没有用到 NMS 。
新框架的主要成分称为DEtect TRansformer或DETR,是一个基于集合的全局损失,通过二分匹配强制进行唯一预测,以及一个转换器编码器-解码器架构。给定一个固定的小的学习对象查询集合,DETR推理对象之间的关系和全局图像上下文直接并行输出最终的预测集合。
然后摘要给出了算法中的两个重点:一个是损失函数,另一个是 Transformer 框架。
对于损失函数,其是一个基于集合的全局损失,通过二分类匹配得到独一无二的预测结果,这个也就是刚刚上文在训练阶段说的通过匈牙利算法去解决这个二分图匹配问题,然后就得到了一个和标注框一一对应的匹配的独一无二的预测结果。
然后是对于 Transformer 的 编解码框架,在 Decoder 模块中,其设定了一个 learned object queries,通过这个 learned object queries ,DETR就可以对 objects 和图像的全局信息的关系进行推理,并行的直接的输出最后的预测结果。
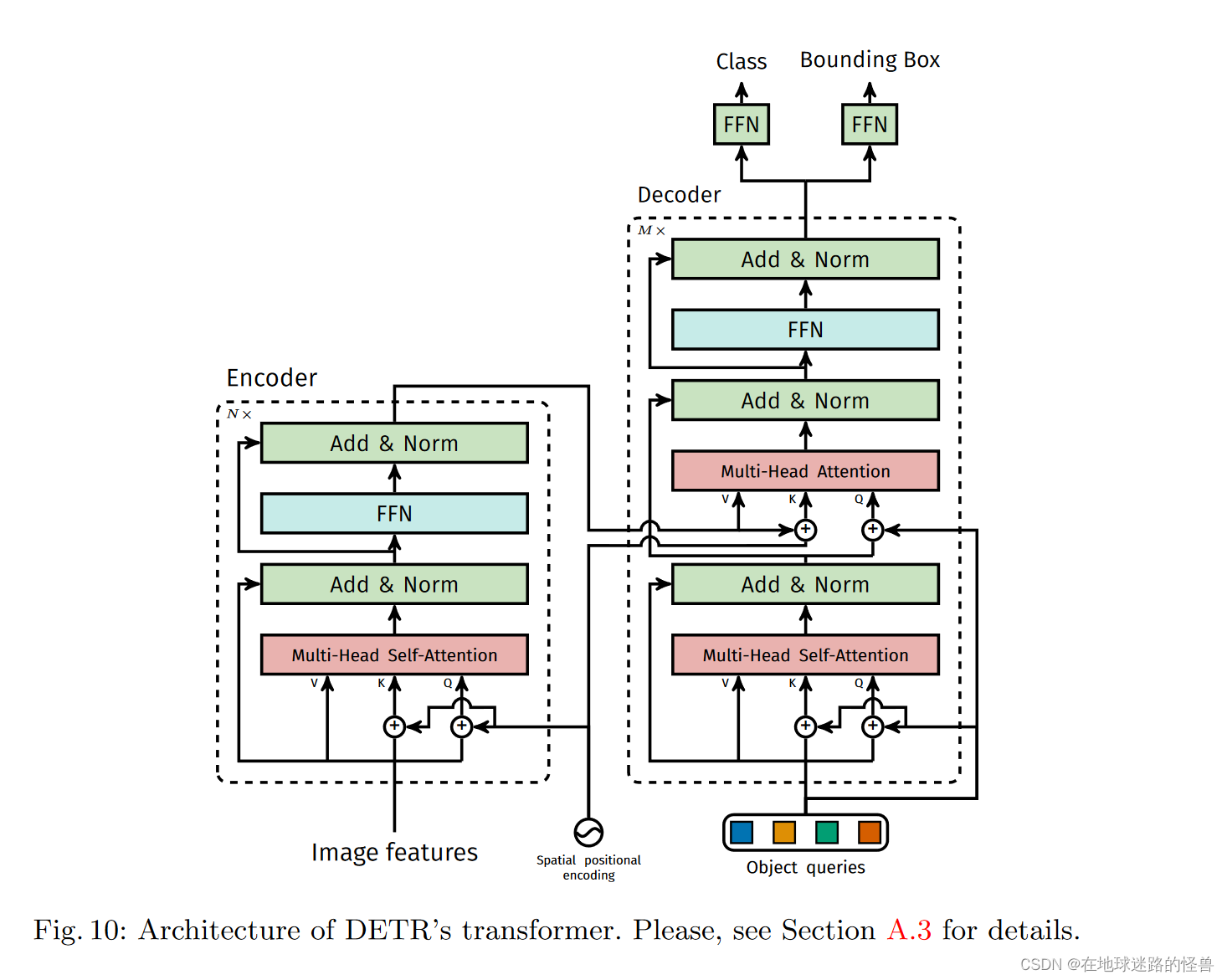
其网络的结构图如下:
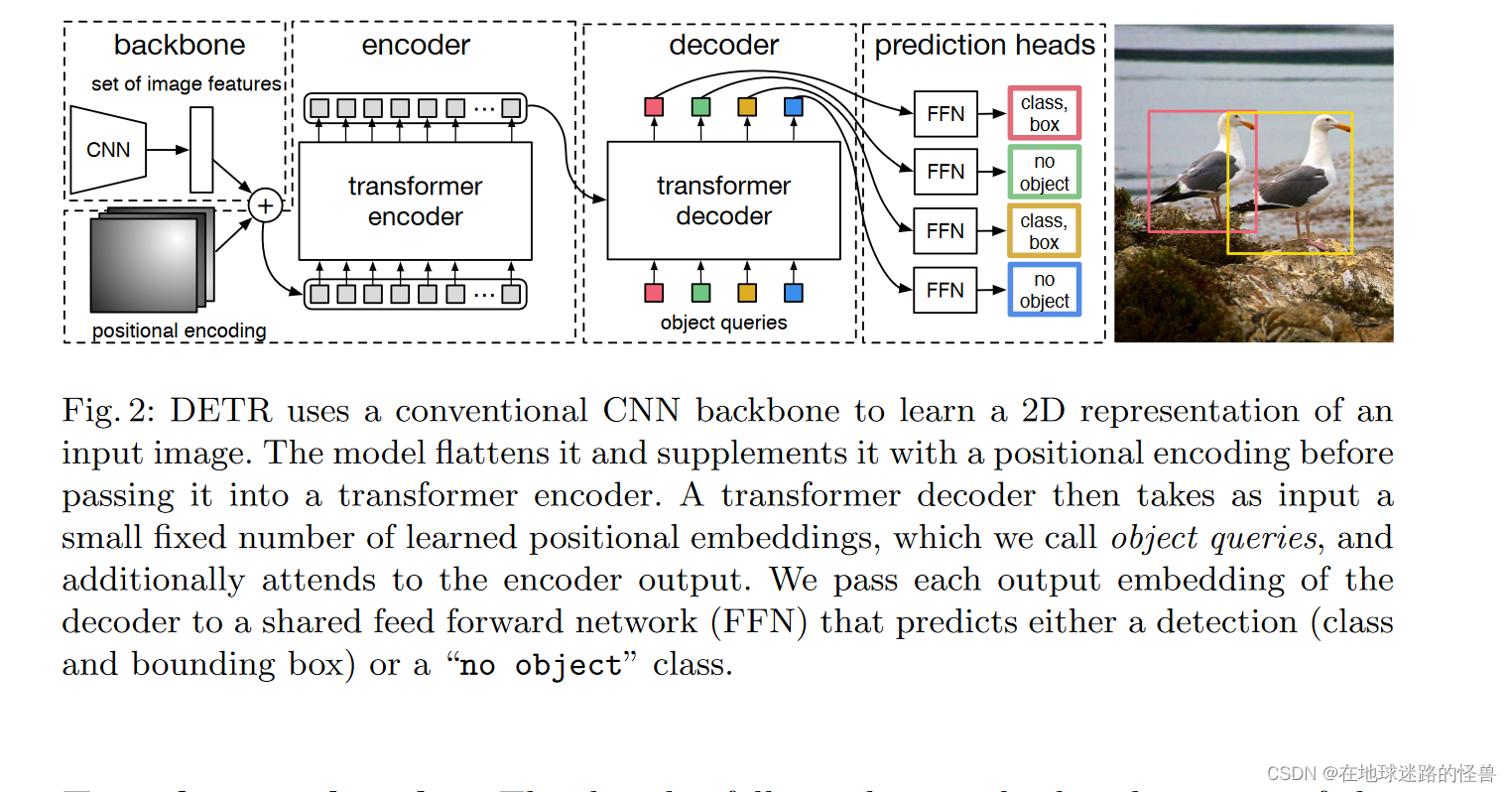
DETR使用传统的CNN主干来学习输入图像的2D表示。该模型将其拉平,并在传递到 Transformer 编码器之前用位置编码进行补充。然后,一个 Transformer 解码器将少量固定数量的学习位置嵌入作为输入,我们称之为对象查询,并附加到编码器输出。我们将解码器的每个输出嵌入传递给一个共享前馈网络( FFN ),该网络预测一个检测(类和边界框)或一个"无对象"类。
在上图的 decoder 模块中的 object queries 是一个可以学习的参数,同时我们也用它来指定输出的预测框的个数,是通过它的尺寸来指定的,在 transformer 中输出 token 个数是等于输入 token 个数的,如果我们把 object queries 的个数设置为一百,那么在输出就可以得到一百个预测框。
原图像通过 CNN 和 Transformer 中的 encoder 模块之后就可以得到一个图像的全局信息,transformer 的 decoder 模块就用于让 object 的预测框和图像的全局信息做自注意力操作,然后得到预测框的集合的输出,还有一点就是 decoder 在生成输出的时候那些 token 的计算是并行的,也就是这一百个预测框的结果是并行计算得到的。
新模型在概念上简单,不需要专门的库,与许多其他现代检测器不同。DETR在具有挑战性的COCO目标检测数据集上表现出与公认的、高度优化的更快速的区域卷积神经网络基线相当的准确性和运行时性能。此外,DETR可以很容易地推广,以统一的方式产生全景分割。我们表明它明显优于竞争性基线。
模型结构
论文中提供了下面两幅图,第一幅是模型的整体结构图,包含一个 CNN 的 backbone 结构,一个 Transformer (编解码器以及位置编码)结构和检测头结构(两个检测头,一个用于预测 bounding box 的类别,另一个用于预测 bounding box 的坐标)。
第二张图则是论文附录部分的内容,是 DETR 模型所使用的 Transformer 结构中的编解码器架构的细节图,其与原本的 Transformer 有些许不同,一会儿我们会仔细学习。
为了便于学习,将这两幅图给合整合在一起变成下面这副模型细节结构图:
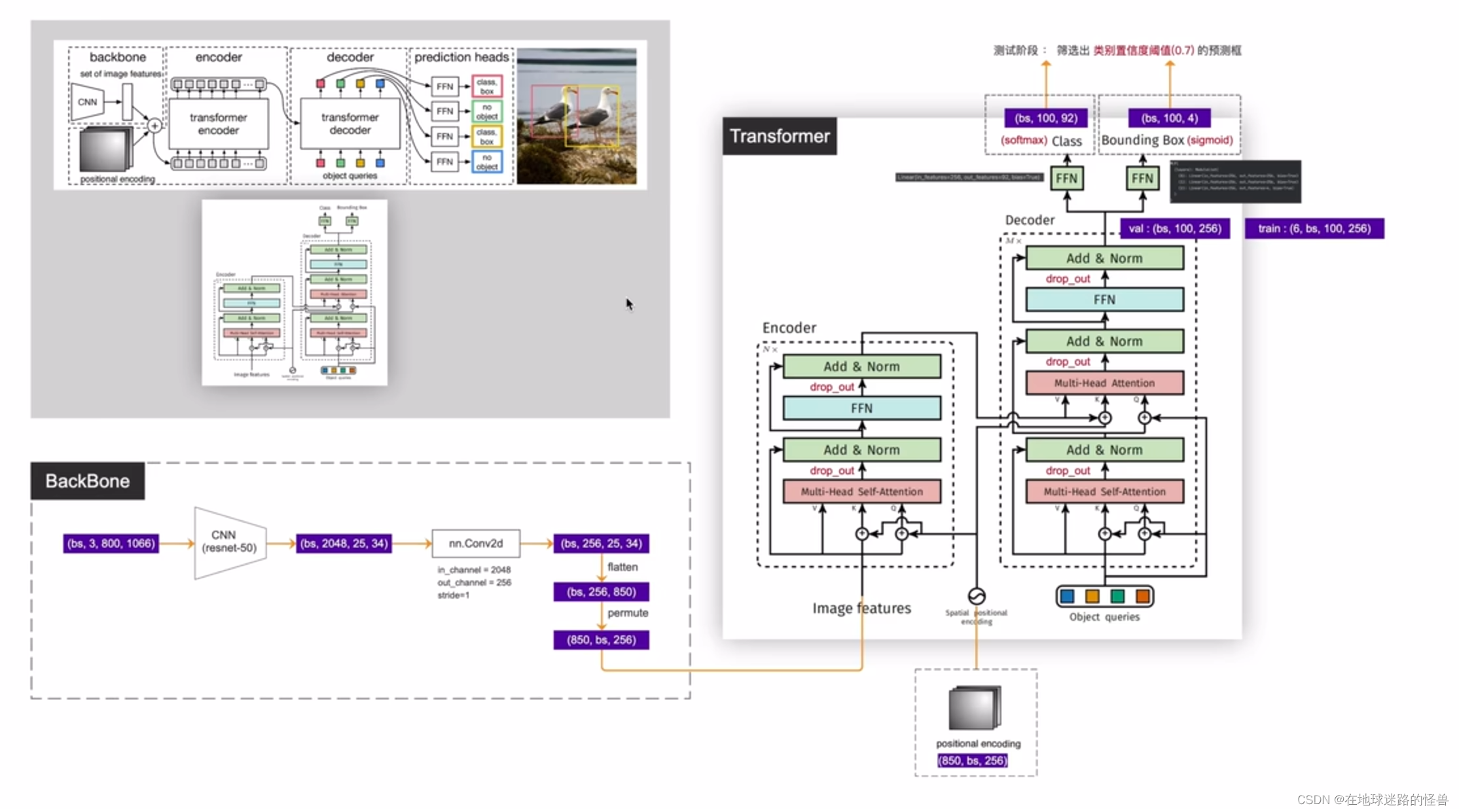
上图的左侧可以看到,拿到一张 image 之后经过 CNN 网络学习之后得到的特征为(850, batchsize, 256),其中 850 就是稍后使用 transformer 的 token 的个数,而 256 就是每一个 token 的特征向量长度,然后输出结果到上图右侧的 transformer 结构中。
在输入时,图片的特征向量还要结合位置编码之后,才能进入 transformer 中的 Encoder 编码器中。这里和标准 transformer 有些许不同:
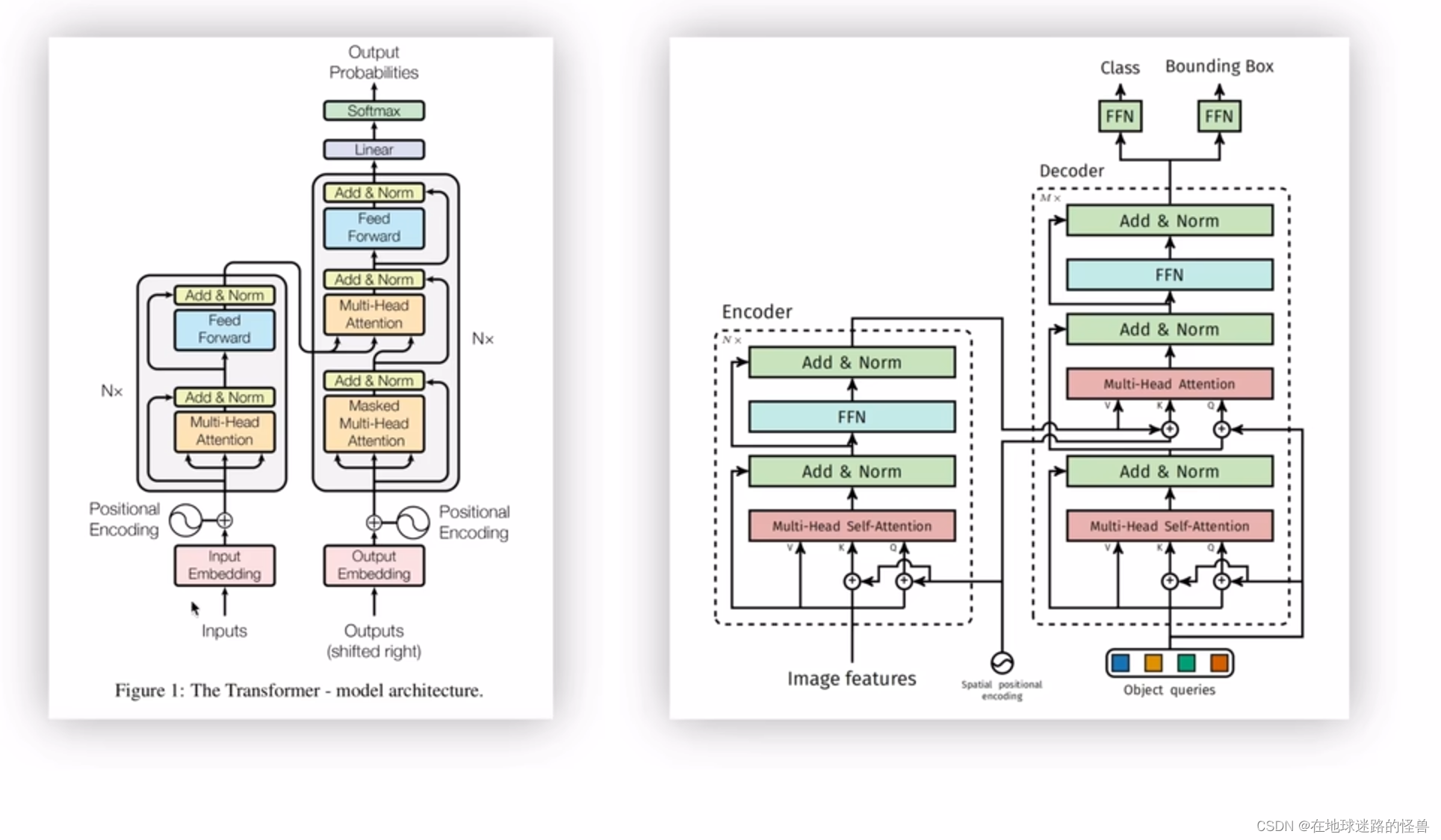
在标准的 transformer 中(上图左侧),位置编码是直接加在 inputs 上的并且只在 inputs 上操作了一次,而 DETR 的 transformer 里位置编码是在每个堆叠的 Encoder、Decoder 中都要使用的,比如假设 Encoder 有六层,也就是上图右侧的编码器框图中的 N 为6,说明 Encoder 模块需要堆叠六次,那么对于每个 Encoder 模块中的 Multi-Head Self-Attention 层位置编码则都需要加在其对应的输入上然后生成 Key 和 Query 值。因为输入是一样的,位置编码也是一样的,因此这里得到的 Key 和 Query 也是一样的,而 Value 就等于 Image Features,也就是输入。然后在这六个 Encoder 当中,每个 Encoder 都需要这样子操作一次,而 Decoder 模块也同样有六块,也需要堆叠六次,然后在每个 Decoder 模块中位置编码都需要和 Encoder 的输出进行相加,然后得到 Decoder 模块中的 Key,这个操作同样要执行六次。
这就是 DETR 的 Tramsformer 所不一样的地方。
然后是 Decoder,可以看到其接受三个输入,第一个是 queries,初始值是 0,第二个是 output positional encoding,也就是 object queries,而第三个则是encoder memory,也就是我们刚刚说的 encoder 的输出加上位置编码后形成了 encoder memory 成为了 decoder 模块的第三个输入(图像的全局特征信息)。
经过多个多头自注意力机制层、编码器解码器层之后就生成了预测类别标签和 bounding box 的坐标,确切的说就是通过最后两个检测头得到的。
整个 Decoder 部分可以分成上下两部分来看,上图右侧的下面这一部分(也就是在得到 encoder memory 之前的部分),我们可以理解成 Multi-Head Self-Attention 在学习 anchor 的特征,然后上面这一部分我们可以理解成其在拿到图像的全局特征信息以及 anchor 特征的基础上进行预测或者是学习图像中的 bounding box 的坐标以及物体的类别。
注意,论文原文中有一句:Decoder 模块中的第一个 self-attention 层是可以被省略掉的(也就是刚刚说的在拿到 encoder memory 之前的部分)。
结合关键代码片段理解
encoder 部分
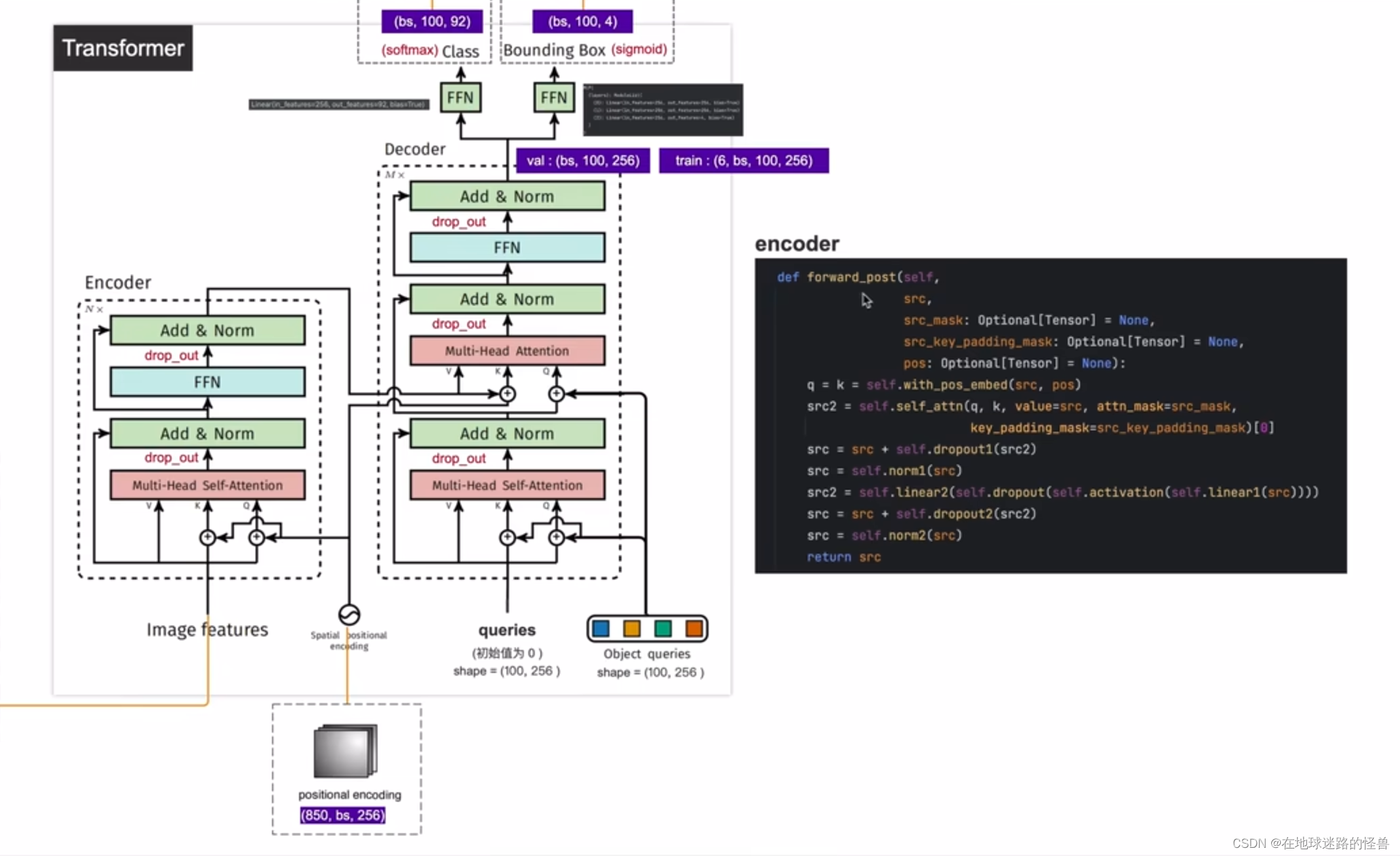
函数包括两个参数,一个是 src,也就是从 CNN 的 backbone 中得到的输出 image features,另一个是 pos,也就是 positional encoding位置编码,而上图中间还有两个参数我们用不到,其是用来做分割任务的,和我们没关系,不管即可。
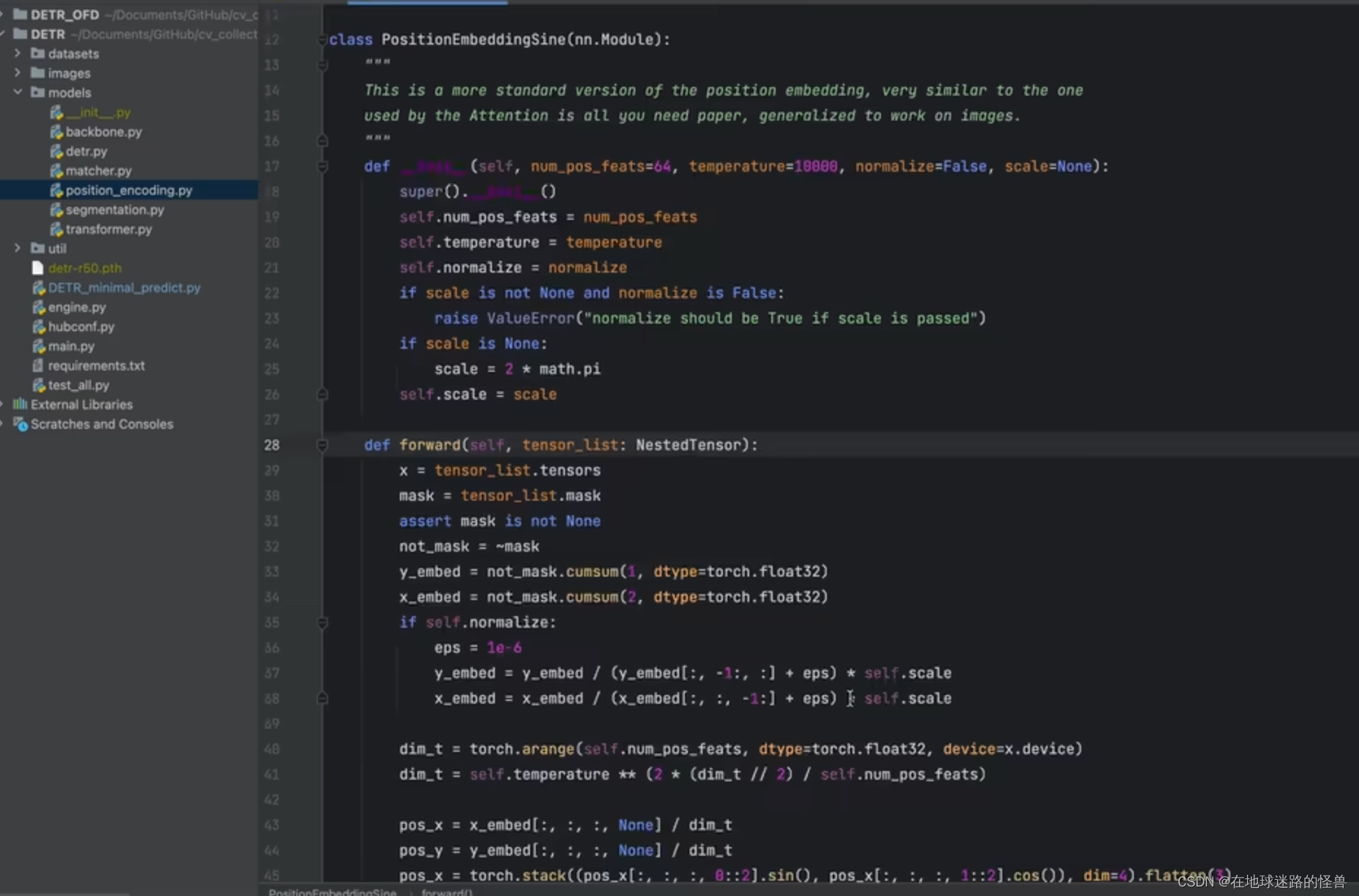
对于怎么生成位置编码,作者给了两种方法,第一种是使用 sin 和 cos 函数来实现的:
第二个方式是可学习的位置编码:
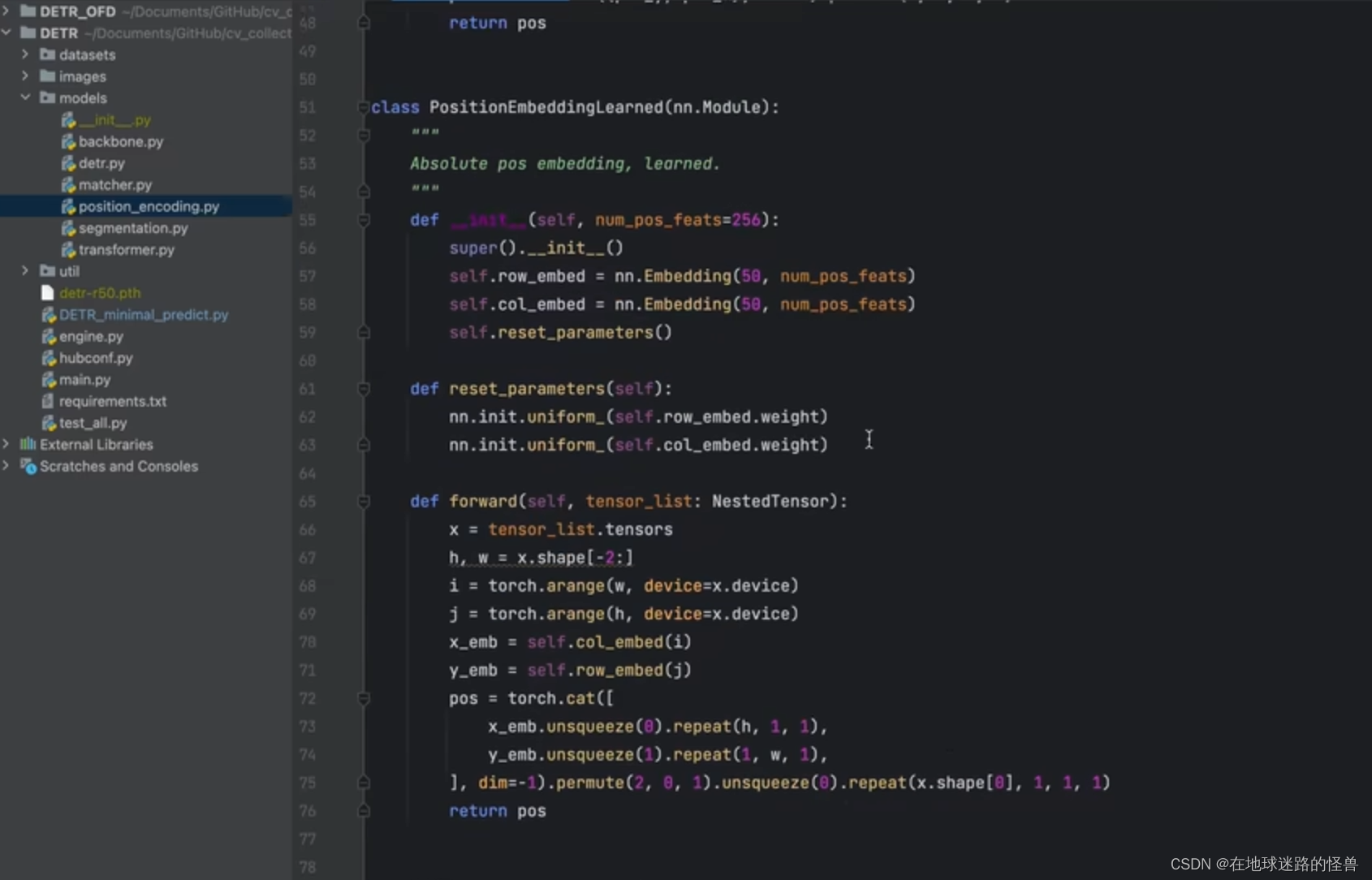
可以随便选一个,但作者源码种所使用的是第一种基于三角函数的方式。
有了这两个参数之后,在函数内部使用了 with_pos_embed,也就是像我们之前在理论时讲的,将 image features 和 位置编码进行相加生成 Queries 和 Key 值,而 Value 值就是直接等于 Image Features 。
第二步按照流程就是调用 self_attn 函数,也就是进行 Multi-Head Self-Attention 操作,向该函数中输入 q、k、v 的值即可(后面两个多余的参数不用管,我们用不到),该函数执行完拿到一个 src2。
然后 src2 进行 dropout 操作,再加上原来的 src 更新成新的 src(就是做一个类似于残差网络的跨层连接),然后进行一个归一化操作,然后再进行一个 FFN 的操作,也就是图中的下面这行代码:
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
即 src 先进行一个全连接层 linear1,然后再进行一个 Relu 激活层 activation,然后 dropout 最后再进行一个全连接层 linear2,得到一个值 src2,也就是 FFN 层的输出。
然后对该输出进行 dropout的同时还要加上原来的 src(跨层连接),最后再进行一个归一化 norm2 层就可以拿到 encoder 模块的输出了,这就是 encoder 模块的整体结构。
decoder 部分
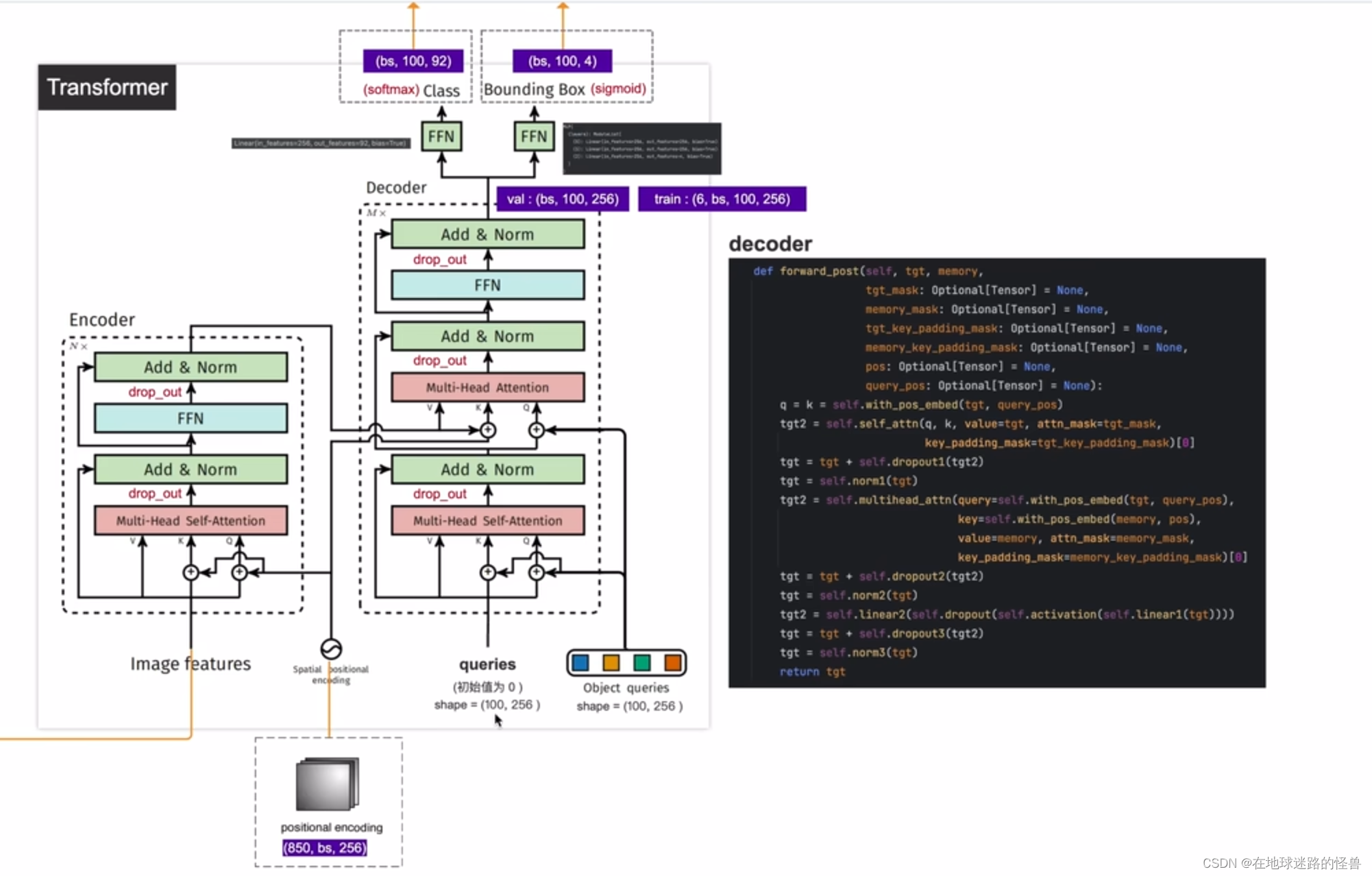
从上图可以看出,其反向传播函数的参数有第一个 tgt,也就是上图左侧的 queries,第二个参数是 memory,这个 memory 就是 encoder 的输出,中间带有 mask 字样的参数我们都不需要管,是用来做分割任务的,然后是第三个参数 pos,即位置编码,第四个参数是 query_pos,即 object queries 对象查询参数。对于函数的执行流程的化也和之前将的 encoder 部分比较相似,是比较好理解的因此就不再赘述。
FFN 部分
比较简单就没什么好说的了,简单介绍一下 MLP:
相关文章:
DETR论文重点
DETR就是 DEtection TRansformer 的缩写。 论文原名:End-to-End Object Detection with Transoformers。 重点有两个:端到端、Transformer结构 论文概述 注意:斜体的文字为论文原文,其他部分内容则是为增进理解而做的解释。 …...
slf4j等多个jar包冲突绑定的排查方法使用IDEA的maven help解决
1.安装 2.使用maven help解决,找到对应包存在的冲突 使用exclude直接解决即可...

MySQL主从的延迟怎么解决呢?
以下是一些减少或解决MySQL主从延迟的策略: 优化查询和索引: 确保所有的查询都经过优化,以减少主服务器上的负载。使用合适的索引来加速查询速度,减少锁的时间。 分散复制负载: 使用多个从服务器分散读取负载。使用并…...
【一百】【算法分析与设计】N皇后问题常规解法+位运算解法
N皇后问题 链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 题目描述 给出一个nnn\times nnn的国际象棋棋盘,你需要在棋盘中摆放nnn个皇后,使得任意两个皇后之间不能互相攻击。具体来说,不能存在两个皇后位于同…...

GPT-4:人工智能领域的新里程碑
近期,OpenAI推出了备受瞩目的GPT-4。作为GPT系列的最新成员,GPT-4在自然语言处理(NLP)领域再次刷新了记录,引发了广泛的关注和讨论。在试用GPT-4之后,我深感其在技术能力、应用场景等方面都取得了显著的进步…...

mysql inset bug
在 SQL 中,日期值需要用单引号包围,这是因为 SQL 将日期值视为字符串格式。数据库引擎在处理这些值时会将它们解析为适当的日期类型。如果不使用单引号,数据库引擎会将它们视为数字或列名,从而导致语法错误。 日期格式 MySQL 支…...

oracle查看序列
在Oracle数据库中,查看序列的方式主要有以下几种: 查看当前用户下的所有序列名称: sql复制代码 SELECT sequence_name FROM user_sequences; 查看所有用户的序列: sql复制代码 SELECT sequence_name FROM all_sequences; 查看…...
flask-slqalchemy使用详解
目录 1、flask-sqlalchemy 1.1、flask_sqlalchemy 与sqlalchemy 的关系 1.1.1、 基本定义与用途 1.2、flask_sqlalchemy 的使用 1.2.1、安装相关的库 1.2.2、项目准备 1.2.3、创建ORM模型 1.2.3.1、使用db.create_all()创建表的示例 1.2.3.2、创建多表关联ORM模型 1.…...

Scala学习笔记8: 包
目录 第八章 包1- 包2- 包的作用域3- 串联式包语句4- 包对象5- 引入end 第八章 包 在Scala中, 包(Package) 用于组织和管理代码, 类似与 Java 中的包 ; 包可以包含类、对象、特质等Scala代码, 并通过层次结构来组织代码 ; 可以使用 package 关键字来定义包, 并使用 . 来表示…...

分享一份糟糕透顶的简历,看看跟你写的一样不
最近看了一个人的简历,怎么说呢,前几年这么写没问题,投出去就有回复,但从现在开始,这么写肯定不行了。下面我给大家分享一下内容: 目录 🤦♀️这是简历文档截图 🤷♀️这是基本…...
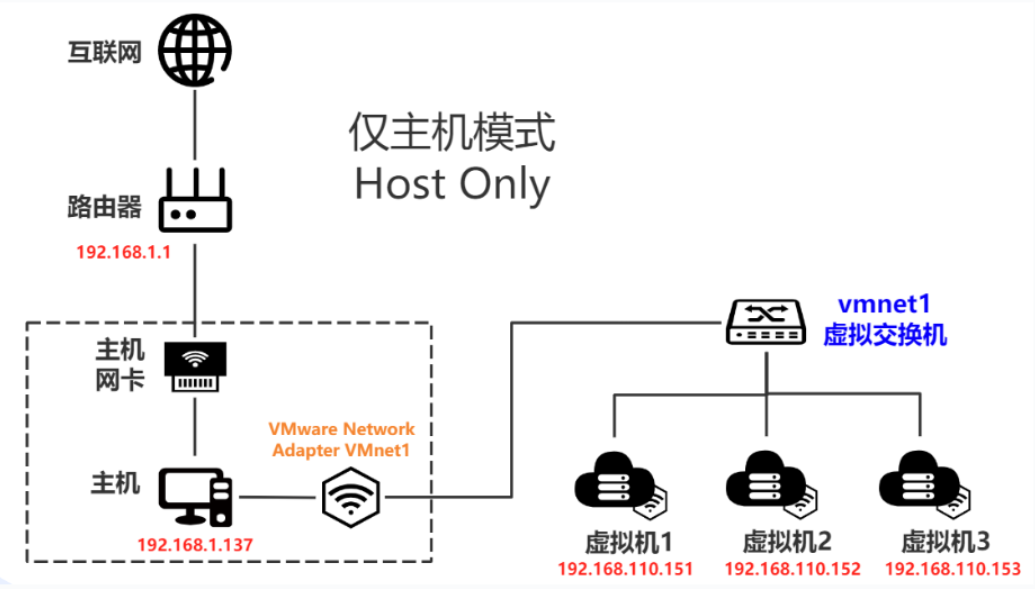
VMware 三种网络模式
目录 一、网卡、路由器、交换机 二、虚拟网络编辑器 三、网络模式 1.桥接模式 通信方式 特点 配置 连通情况 使用场景 2.NAT模式 通信方式 特点 配置 连通情况 使用场景 3.仅主机 通信方式 特点 配置 连通情况 使用场景 一、网卡、路由器、交换机 网卡(Ne…...

红绿二分查找
《英雄算法零基础》之 二分查找 https://articles.zsxq.com/id_ib4xgs0cogic.html 在写模版之前我们先搞清楚二分查找是怎样运行的,我们把一个数组分成红绿两种颜色,可以理解为绿色就是符合情况的,红色就是不符合情况的(类似红绿灯…...
C51单片机 串口打印printf重定向
uart.c文件 #include "uart.h"void UartInit(void) //4800bps11.0592MHz {PCON | 0x80; //使能波特率倍速位SMODSCON 0x50; //8位数据,可变波特率。使能接收TMOD & 0x0F; //清除定时器1模式位TMOD | 0x20; //设定定时器1为8位自动重装方式TL1 0xF4; //设…...
PieCloudDB Database Flink Connector:让数据流动起来
面对客户环境中长期运行的各种类型的传统数据库,如何优雅地设计数据迁移的方案,既能灵活地应对各种数据导入场景和多源异构数据库,又能满足客户对数据导入结果的准确性、一致性、实时性的要求,让客户平滑地迁移到 PieCloudDB 数据…...

主机CPU访问PCIe设备内存空间和PCIe设备访问主机内存空间
在x86体系架构中,主机CPU访问PCIe设备内存空间和PCIe设备访问主机内存空间的过程涉及多个层次的地址映射和转换。以下是详细的解释: 主机CPU访问PCIe设备内存空间 1. CPU生成虚拟地址(Virtual Address, VA): 在x86架构中&#…...

在家AIAA(美国航空航天学会)文献如何查找下载
今天有位同学的求助文献来自AIAA(美国航空航天学会),下面就讲一下不用求助他人自己就可搞定文献下载的途径并实例操作演示。 首先我们先对AIAA(美国航空航天学会)数据库做个简单的了解: 美国航空航天学会…...

dnf手游版游玩感悟
dnf手游于5月21号正式上线,作为一个dnf端游老玩家,并且偶尔上线ppk,自然下载了手游版,且玩了几天。 不得不说dnf手游的优化做到了极好的程度。 就玩法系统这块,因为dnf属于城镇地下城模式,相比…...
安卓如何书写注册和登录界面
一、如何跳转一个活动 左边的是本活动名称, 右边的是跳转界面活动名称 Intent intent new Intent(LoginActivity.this, RegisterActivity.class); startActivity(intent); finish(); 二、如果在不同的界面传递参数 //发送消息 SharedPreferences sharedPreferen…...

黄仁勋的AI时代:英伟达GPU革命的狂欢与挑战
在最近的COMPUTEX 2024大会上,英伟达创始人黄仁勋发布了最新的Blackwell GPU。这次发布不仅标志着英伟达在AI领域的又一次飞跃,也展示了其对未来技术发展的战略规划。本文将详细解析英伟达最新技术的亮点,探讨其在AI时代的市场地位和未来挑战…...

Linux云计算架构师涨薪班课程内容包含哪些?
第一阶段:Linux云计算运维初级工程师 目标 云计算工程师,Linux运维工程师都必须掌握Linux的基本功,这是一切的根本,必须全部掌握,非常重要,有了这些基础,学习上层业务和云计算等都非常快&#x…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...
django blank 与 null的区别
1.blank blank控制表单验证时是否允许字段为空 2.null null控制数据库层面是否为空 但是,要注意以下几点: Django的表单验证与null无关:null参数控制的是数据库层面字段是否可以为NULL,而blank参数控制的是Django表单验证时字…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...
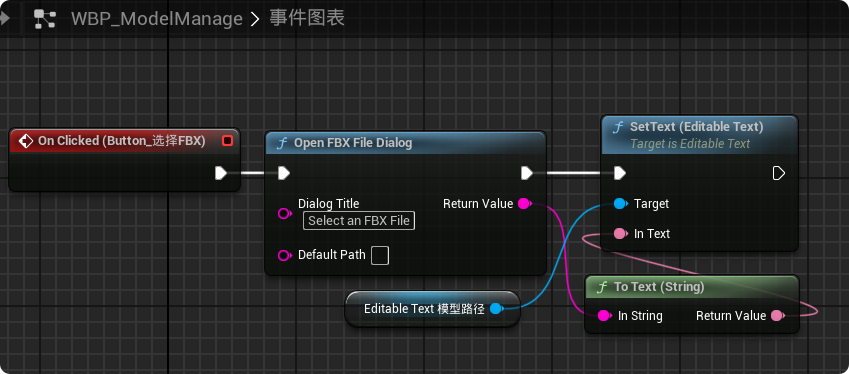
【UE5 C++】通过文件对话框获取选择文件的路径
目录 效果 步骤 源码 效果 步骤 1. 在“xxx.Build.cs”中添加需要使用的模块 ,这里主要使用“DesktopPlatform”模块 2. 添加后闭UE编辑器,右键点击 .uproject 文件,选择 "Generate Visual Studio project files",重…...

【HarmonyOS 5】鸿蒙中Stage模型与FA模型详解
一、前言 在HarmonyOS 5的应用开发模型中,featureAbility是旧版FA模型(Feature Ability)的用法,Stage模型已采用全新的应用架构,推荐使用组件化的上下文获取方式,而非依赖featureAbility。 FA大概是API7之…...