21.过拟合和欠拟合示例
1. 背景介绍
在机器学习和深度学习中,过拟合和欠拟合是两个非常重要的概念。过拟合指的是模型在训练数据上表现很好,但在新的测试数据上效果变差的情况。欠拟合则是指模型无法很好地拟合训练数据的情况。这两种情况都会导致模型无法很好地泛化,影响最终的预测和应用效果。
为了帮助大家更好地理解过拟合和欠拟合的概念及其应对方法,我将通过一个基于PyTorch的代码示例来演示这两种情况的具体表现。我们将生成一个抛物线数据集,并定义三种不同复杂度的模型,分别对应欠拟合、正常拟合和过拟合的情况。通过可视化训练和测试误差的曲线图,以及预测结果的散点图,我们可以直观地观察到这三种情况下模型的拟合效果。
2. 核心概念与联系
过拟合和欠拟合是机器学习和深度学习中两个相互对应的概念:
1. 过拟合(Overfitting): 模型在训练数据上表现很好,但在新的测试数据上效果变差的情况。这通常是由于模型过于复杂,过度拟合了训练数据中的噪声和细节,导致无法很好地推广到未知数据。
2. 欠拟合(Underfitting): 模型无法很好地拟合训练数据的情况。这通常是由于模型过于简单,无法捕捉训练数据中的复杂模式和关系。
这两种情况都会导致模型在实际应用中无法很好地泛化,因此需要采取相应的措施来防止和缓解过拟合和欠拟合。常见的应对方法包括:
- 增加训练样本数量
- 减少模型复杂度(比如调整网络层数、神经元个数等)
- 使用正则化技术(如L1/L2正则化、Dropout等)
- 调整超参数(如学习率、批量大小等)
- 特征工程(如特征选择、降维等)
通过合理的模型设计和超参数调优,我们可以寻找到一个恰当的模型复杂度,使其既能很好地拟合训练数据,又能在新数据上保持良好的泛化性能。这就是机器学习中的**bias-variance tradeoff**,也是我们在实际应用中需要权衡的一个关键点。
3. 核心算法原理和具体操作步骤
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split# 生成数据
np.random.seed(42)
X = np.random.uniform(-5, 5, 500)
y = X**2 + 1 + np.random.normal(0, 1, 500)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 定义三种不同复杂度的模型
class UnderFitModel(nn.Module):def __init__(self):super(UnderFitModel, self).__init__()self.fc = nn.Linear(1, 1)def forward(self, x):return self.fc(x)class NormalFitModel(nn.Module):def __init__(self):super(NormalFitModel, self).__init__()self.fc1 = nn.Linear(1, 8)self.fc2 = nn.Linear(8, 1)self.activation = nn.ReLU()def forward(self, x):x = self.fc1(x)x = self.activation(x)x = self.fc2(x)return xclass OverFitModel(nn.Module):def __init__(self):super(OverFitModel, self).__init__()self.fc1 = nn.Linear(1, 32)self.fc2 = nn.Linear(32, 32)self.fc3 = nn.Linear(32, 1)self.activation = nn.ReLU()def forward(self, x):x = self.fc1(x)x = self.activation(x)x = self.fc2(x)x = self.activation(x)x = self.fc3(x)return x# 训练模型并记录误差
def train_and_evaluate(model, train_loader, test_loader):optimizer = torch.optim.SGD(model.parameters(), lr=0.005)criterion = nn.MSELoss()train_losses = []test_losses = []for epoch in range(100):model.train()train_loss = 0.0for inputs, targets in train_loader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()train_loss += loss.item()train_loss /= len(train_loader)train_losses.append(train_loss)model.eval()test_loss = 0.0with torch.no_grad():for inputs, targets in test_loader:outputs = model(inputs)loss = criterion(outputs, targets)test_loss += loss.item()test_loss /= len(test_loader)test_losses.append(test_loss)return train_losses, test_losses# 训练三种模型并可视化
under_fit_model = UnderFitModel()
normal_fit_model = NormalFitModel()
over_fit_model = OverFitModel()under_fit_train_losses, under_fit_test_losses = train_and_evaluate(under_fit_model, train_loader, test_loader)
normal_fit_train_losses, normal_fit_test_losses = train_and_evaluate(normal_fit_model, train_loader, test_loader)
over_fit_train_losses, over_fit_test_losses = train_and_evaluate(over_fit_model, train_loader, test_loader)plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(under_fit_train_losses, label='Under-fit Train Loss')
plt.plot(under_fit_test_losses, label='Under-fit Test Loss')
plt.plot(normal_fit_train_losses, label='Normal-fit Train Loss')
plt.plot(normal_fit_test_losses, label='Normal-fit Test Loss')
plt.plot(over_fit_train_losses, label='Over-fit Train Loss')
plt.plot(over_fit_test_losses, label='Over-fit Test Loss')
plt.xlabel('Epoch')
plt.ylabel('MSE Loss')
plt.title('Training and Test Loss Curves')
plt.legend()plt.subplot(1, 2, 2)
plt.scatter(X_test, y_test, label='True')
plt.scatter(X_test, under_fit_model(X_test).detach().numpy(), label='Under-fit Prediction')
plt.scatter(X_test, normal_fit_model(X_test).detach().numpy(), label='Normal-fit Prediction')
plt.scatter(X_test, over_fit_model(X_test).detach().numpy(), label='Over-fit Prediction')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Test Set Predictions')
plt.legend()plt.show()这个代码示例涵盖了我们之前讨论的各个步骤:
数据生成: 我们生成了一个抛物线形状的数据集,并使用train_test_split函数将其划分为训练集和测试集。
模型定义: 我们定义了三种不同复杂度的PyTorch模型,分别对应欠拟合、正常拟合和过拟合的情况。
训练与评估: 我们实现了一个train_and_evaluate函数,该函数负责训练模型并记录训练集和测试集上的损失。
可视化: 最后,我们使用matplotlib绘制了训练损失和测试损失的曲线图,以及在测试集上的预测结果。
欠拟合模型:训练误差和测试误差都较大,说明模型无法很好地拟合数据。在测试集上的预测结果也存在较大偏差。
正常拟合模型:训练误差和测试误差较为接近,说明模型的拟合效果较好。在测试集上的预测也比较准确。
过拟合模型:训练误差很小,但测试误差较大,说明模型在训练集上表现很好,但在新数据上泛化能力较差。在测试集上的预测结果存在一定偏差。
通过这个实例,我们可以直观地观察到不同复杂度模型在训练和泛化性能上的差异。欠拟合模型在训练集和测试集上的损失都较大,说明模型无法很好地拟合数据。正常拟合模型在训练集和测试集上的损失较为接近,说明模型具有较好的泛化能力。而过拟合模型在训练集上的损失很小,但在测试集上的损失较大,说明模型过于复杂,在新数据上泛化性能较差。
通过这种观察训练误差和测试误差的方法,我们可以及时发现模型存在的问题,并针对性地调整模型结构、添加正则化等手段来优化模型性能。这是机器学习和深度学习中非常基础和重要的实践技能。
相关文章:

21.过拟合和欠拟合示例
1. 背景介绍 在机器学习和深度学习中,过拟合和欠拟合是两个非常重要的概念。过拟合指的是模型在训练数据上表现很好,但在新的测试数据上效果变差的情况。欠拟合则是指模型无法很好地拟合训练数据的情况。这两种情况都会导致模型无法很好地泛化ÿ…...

使用import语句导入模块
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 创建模块后,就可以在其他程序中使用该模块了。要使用模块需要先以模块的形式加载模块中的代码,这可以使用import语句实现。im…...

一台FreeBSD笔记本突然鼠标乱动=>pf防火墙设置@FreeBSD
缘起 一台FreeBSD的笔记本,突然鼠标乱动 思考了下,可能原因有三: 1 无线鼠标干扰 正巧没带鼠标,但是插着无线鼠标usb,不知道是不是别人的鼠标跟这个usb串台了。 2 触摸板机械故障 也许是天热触摸板开始有故障了&…...

身份证OCR识别功能介绍
身份证OCR识别功能是一种基于光学字符识别(OCR)技术的解决方案,专门用于从身份证图像中快速、准确地提取和识别信息。以下是关于身份证OCR识别功能的详细介绍: 功能概述 身份证OCR识别功能通过高分辨率的摄像头或扫描仪获取身份证…...
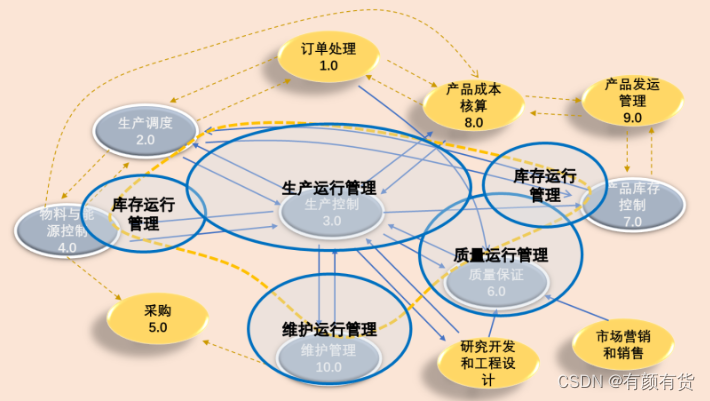
一文看懂:MES定义和功能是什么,以及在数字化工厂的应用
MES应该是继ERP之后制造企业信息化最热门的管理软件,它适应产品个性化与敏捷化制造需求,满足生产过程精益管理而产生和发展起来的信息系统。 作为企业实现数字化与智能化的核心支撑技术与重要组成部分,MES在帮助制造企业走向数字化、智能化等…...

对 SQL 说“不”~
开发人员注意! 您在当前的应用程序架构中是否面临这些问题? 对 SQL 数据库的高吞吐量。SQL 数据库中的瓶颈。 内存数据存储将是解决问题的方案。Redis 是市场上最受欢迎的内存数据存储和缓存选项。Redis 拥有广泛的生态系统,因为主要科技巨…...
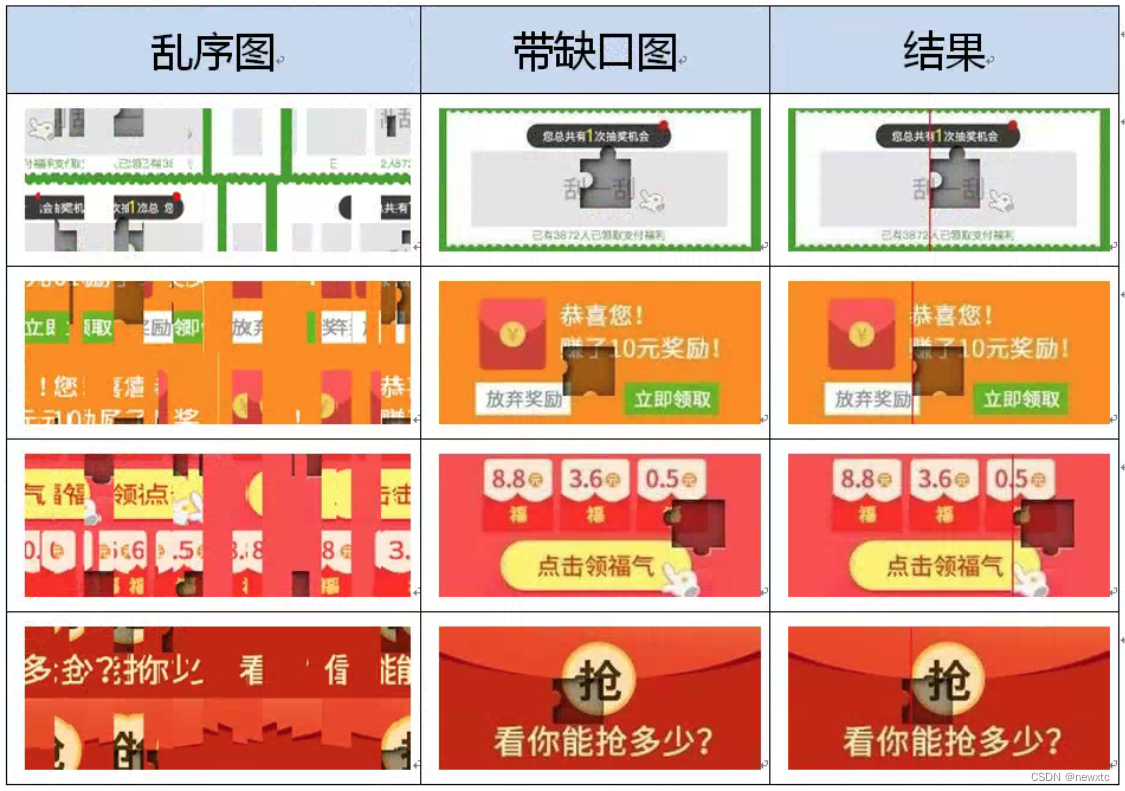
【爱空间_登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞 …...

web前端三大主流框架
一、介绍 目前,前端开发领域的三大主流框架是: React:React是由Facebook开发并维护的开源JavaScript库,用于构建用户界面。它提供了一种声明式的组件化开发方式,能够高效地创建交互性的用户界面。React具有高性能、可…...
git获取的项目无法运行
一、Unsupported engine 问题:在使用命令npm install下载依赖项的时候就遇到了这个问题,有帖子说多试几次,其实这是提示node版本问题,版本的更新出现兼容性问题,多试几次也没用。 解决方案: 更新node.js的…...
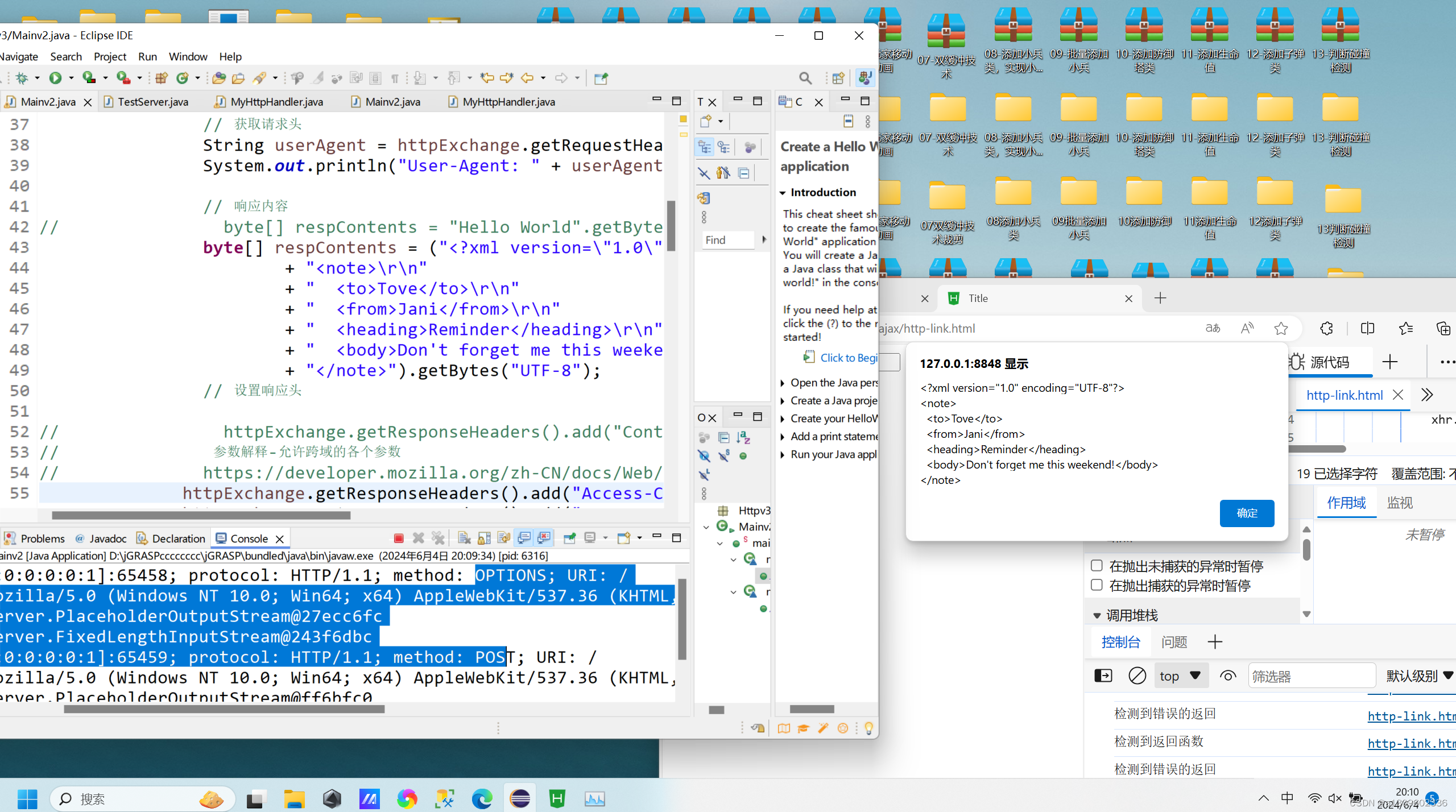
java 原生http服务器 测试JS前端ajax访问实现跨域
后端 package Httpv3;import com.sun.net.httpserver.Headers; import com.sun.net.httpserver.HttpExchange; import com.sun.net.httpserver.HttpHandler; import com.sun.net.httpserver.HttpServer;import java.io.IOException; import java.io.OutputStream; import java…...
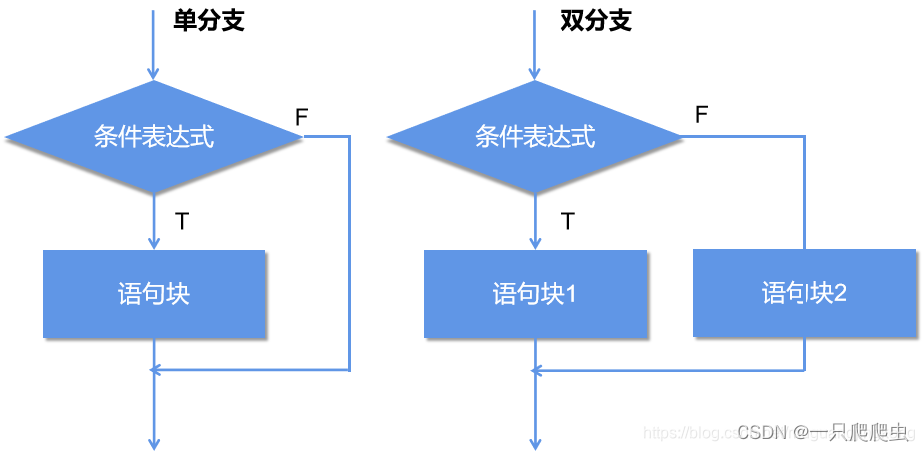
捋一捋C++中的逻辑运算(一)——表达式逻辑运算
注意,今天要谈的逻辑运算是C语言编程中的“与或非”逻辑运算,不是数学集合中的“交并补”逻辑运算。而编程中的逻辑运算又包括表达式逻辑运算和位逻辑运算,本章介绍表达式逻辑运算,下一章介绍位逻辑运算。 目录 一、几个基本的概…...
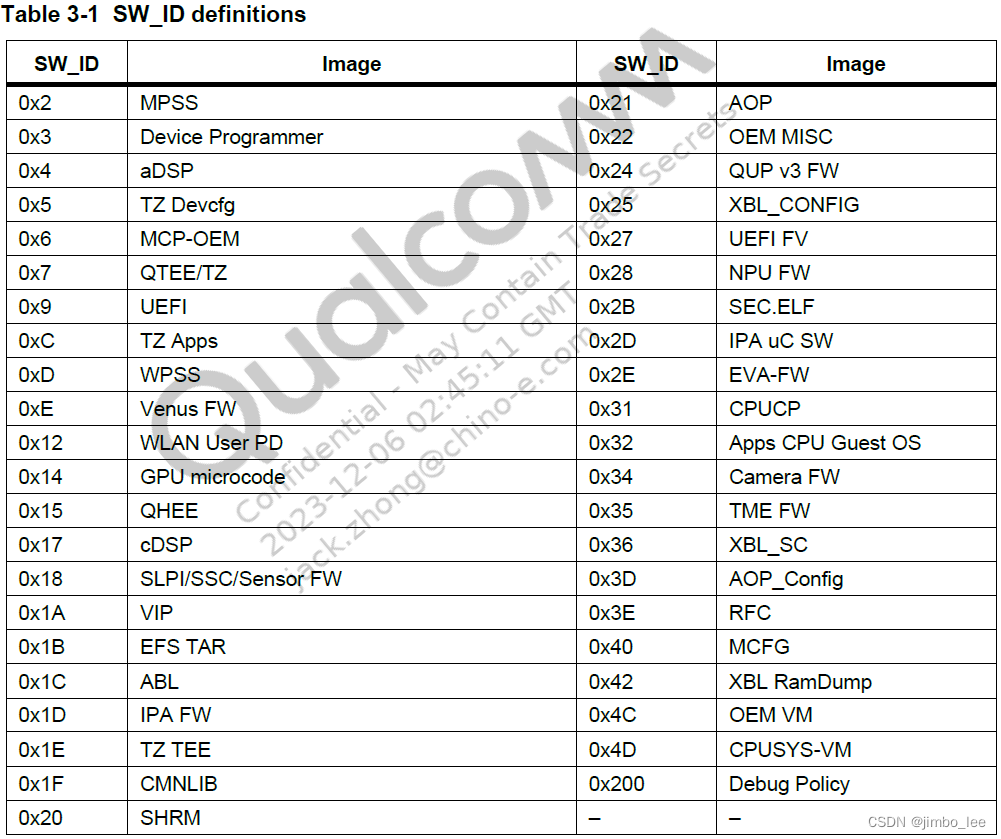
qcom 平台系统签名流程
security boot 平台的东东,oem 可定制的功能有限,只能参考平台文档,可以在高通的网站上搜索:Secure Boot Enablement,然后找对应平台的文档xxx-Secure Boot Enablement User Guide, step by step 操作即可 开机校验流…...

从零开始实现自己的串口调试助手(5) -实现HEX显示/发送/接收
实现HEX显示: HEX 显示 -- 其实就是 十六进制显示 --> a - 97(10) --> 61(16) 添加槽函数(bool): 实现槽函数: 注意: 注意QString 没有处理HEX显示的相关API 需要使用 toUtf-8 来 转换位QByteArry 类型, 利用其中的API 来处理HEX格式(toHex fromHex) vo…...

【计算机毕设】基于SpringBoot的民宿在线预定平台设计与实现 - 源码免费(私信领取)
免费领取源码 | 项目完整可运行 | v:chengn7890 诚招源码校园代理! 1. 研究目的 本研究旨在设计并实现一个基于SpringBoot的民宿在线预定平台。通过信息化手段提高民宿预定效率,方便用户查询房源、预定房间、在线支付和…...

大数据—数据分析概论
一、什么是数据分析 数据分析是指使用统计、数学、计算机科学和其他技术手段对数据进行清洗、转换、建模和解释的过程,以提取有用的信息、发现规律、支持决策和解决问题。数据分析可以应用于各种领域,包括商业、医学、工程、社会科学等。 二、数据分析步…...

centos7下卸载MySQL,Oracle数据库
📑打牌 : da pai ge的个人主页 🌤️个人专栏 : da pai ge的博客专栏 ☁️宝剑锋从磨砺出,梅花香自苦寒来 操作系统版本为CentOS 7 使⽤ MySQ…...

Spring解决循环依赖
Spring框架为了解决循环依赖问题,设计了一套三级缓存机制: 一级缓存singletonObjects:这个是最常规的缓存,用于存放完成初始化好的bean,如果某个bean已经在这个缓存了直接返回。二级缓存earlySigletonObjects:这个用于存放早期暴…...

RUST运算符重载
在 Rust 中,可以使用特征(traits)来实现运算符重载。运算符重载是通过实现相应的运算符特征(如 Add、Sub、Mul 等)来完成的。这些特征定义在 std::ops 模块中。下面是一个简单的示例,展示如何为一个自定义结…...
 循环和 Array.map() 方法之间的主要区别)
描述一下 Array.forEach() 循环和 Array.map() 方法之间的主要区别
Array.forEach() 和 Array.map() 都是 JavaScript 数组中常用的方法,但它们之间有一些重要的区别: 返回值:forEach():没有返回值,它只是对数组中的每个元素执行提供的函数。map():返回一个新的数组,其元素是通过对原数组的每个元素执行提供的函数后的结…...
)
在GEE中显示矢量或栅格数据的边界(包含样式设计)
需要保证最后显示的数据是一个 FeatureCollection 对象。 如果数据是一个 Geometry 或 Image,我们也可以使用 style 方法来设置样式并将其添加到地图上。以下是针对不同类型对象的处理方式: 1 Geometry对象 如果 table 是一个 Geometry 对象ÿ…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...
 error)
【前端异常】JavaScript错误处理:分析 Uncaught (in promise) error
在前端开发中,JavaScript 异常是不可避免的。随着现代前端应用越来越多地使用异步操作(如 Promise、async/await 等),开发者常常会遇到 Uncaught (in promise) error 错误。这个错误是由于未正确处理 Promise 的拒绝(r…...
uni-app学习笔记三十五--扩展组件的安装和使用
由于内置组件不能满足日常开发需要,uniapp官方也提供了众多的扩展组件供我们使用。由于不是内置组件,需要安装才能使用。 一、安装扩展插件 安装方法: 1.访问uniapp官方文档组件部分:组件使用的入门教程 | uni-app官网 点击左侧…...

ArcGIS Pro+ArcGIS给你的地图加上北回归线!
今天来看ArcGIS Pro和ArcGIS中如何给制作的中国地图或者其他大范围地图加上北回归线。 我们将在ArcGIS Pro和ArcGIS中一同介绍。 1 ArcGIS Pro中设置北回归线 1、在ArcGIS Pro中初步设置好经纬格网等,设置经线、纬线都以10间隔显示。 2、需要插入背会归线…...