spark的简单学习二
一 spark sql基础
1.1 Dataframe
1.介绍:
DataFrame也是一个分布式数据容器。然而DataFrame更像传统数据库的二维表 格,除了数据以外,还掌握数据的结构信息,即schema。同时,与Hive类似,DataFrame也支 持嵌套数据类型(struct、array和map)。
1.2 基础的spark-sql程序
1.2.1创建spark sql入口
1.使用SparkSession类,并设置其相关东西
.builder() :创建环境
.master() :明确部署
.appName :给任务取个名字
.getOrCreate() :创建
1.2.2 构建DF
使用SparkSession中的read方法并设置相关属性创建DF
.format("csv") //指定读取数据的格式
.schema("line STRING") //指定列的名和列的类型,多个列之间使用,分割
.option("sep", "\n") //指定分割符,csv格式读取默认是英文逗号
.load("spark/data/words.txt") // 指定要读取数据的位置,可以使用相对路径
1.2.3 创建视图
使用DF里面的方法
linesDF.createOrReplaceTempView("lines") // 起一个表名,后面的sql语句可以做查询分析
1.2.4 编写sql语句
使用SparkSession中的sql方法创建sql查询后的DF:
sparkSession.sql(".....................................")
1.2.5 查看
使用DF里面的show方法查看内容
使用DF里面的printSchema查看结构
1.2.6 写入
1.设置分区数,可以设置也可以不设置,使用的是DF中的方法,但是返回值是Dataset类型
val resDS: Dataset[Row] = resDF.repartition(1)
2.如果设置了分区使用DataSet中的write,没有使用DF中的write
.format("csv") //指定输出数据文件格式
.option("sep","\t") // 指定列之间的分隔符
.mode(SaveMode.Overwrite) // 使用SaveMode枚举类,设置为覆盖写
.save("spark/data/sqlout1") // 指定输出的文件夹
下面是完整代码
/*** 在新版本的spark中,如果想要编写spark sql的话,需要使用新的spark入口类:SparkSession*/val session: SparkSession = SparkSession.builder() //创建环境.master("local") //明确部署.appName("单词统计") //取名.getOrCreate() //创建/*** spark sql和spark core的核心数据类型不太一样** 1、读取数据构建一个DataFrame,相当于一张表*/val wordCountDataFrame: DataFrame = session.read //使用read构建DataFrame.format("csv") //指定读取文件的格式.schema("line STRING") //指定创建好的DataFrame中的列名和列的类型.option("sep", "\n") //指定分隔符,csv默认以逗号形式.load("spark/data/words.txt") //读取文件的路径// wordCountDataFrame.show()//查看DF的内容
// wordCountDataFrame.printSchema()//查看DF结构/*** 2、DF本身是无法直接在上面写sql的,需要将DF注册成一个视图,才可以写sql数据分析*/wordCountDataFrame.createOrReplaceTempView("words")//给DF取一个表名/*** 3、可以编写sql语句 (统计单词的数量)* spark sql是完全兼容hive sql*/val resFrame: DataFrame = session.sql("""|select|t1.word as word,|count(1) as counts|from|(select| explode(split(line,'\\|')) as word from words) t1| group by t1.word|""".stripMargin)// frame.show()/*** 4、将计算的结果DF保存到*/val resDataset: Dataset[Row] = resFrame.repartition(1)//指定分区,指定完后类型变成了Dataset类型resDataset.write.format("csv")//指定写入文件的格式.option("sep","\t")//指定分隔符.mode(SaveMode.Overwrite)//使用SaveMode枚举类,设置为覆盖写.save("spark/data/sqlout1")//指定输出路径1.3 DSL
1.3.1 基础的DSL
1.使用SparkSession类,并设置其相关东西
.builder() :创建环境
.master() :明确部署
.appName :给任务取个名字
.getOrCreate() :创建
2.使用SparkSession中的read方法并设置相关属性创建DF
.format("csv") //指定读取数据的格式
.schema("line STRING") //指定列的名和列的类型,多个列之间使用,分割
.option("sep", "\n") //指定分割符,csv格式读取默认是英文逗号
.load("spark/data/words.txt") // 指定要读取数据的位置,可以使用相对路径
3.导入相关包
导入Spark sql中所有的sql隐式转换函数
import org.apache.spark.sql.functions._
导入另一个隐式转换,后面可以直接使用$函数引用字段进行处理
import sparkSession.implicits._
4.写DSL语句
可以直接使用$函数引用字段进行处理例如 $"id"
5.保存数据
设置分区数,可以设置也可以不设置,使用的是DF中的方法,但是返回值是Dataset类型
val resDS: Dataset[Row] = resDF.repartition(1)
如果设置了分区使用DataSet中的write,没有使用DF中的write
.format("csv") //指定输出数据文件格式
.option("sep","\t") // 指定列之间的分隔符
.mode(SaveMode.Overwrite) // 使用SaveMode枚举类,设置为覆盖写
.save("spark/data/sqlout1") // 指定输出的文件夹
相关代码如下
/*** 在新版本的spark中,如果想要编写spark sql的话,需要使用新的spark入口类:SparkSession*/val session: SparkSession = SparkSession.builder().master("local").appName("DSL").getOrCreate()/*** spark sql和spark core的核心数据类型不太一样** 1、读取数据构建一个DataFrame,相当于一张表*/val wordDF: DataFrame = session.read.format("csv").schema("line STRING").option("sep", "\n").load("spark/data/words.txt")/*** DSL: 类SQL语法 api 介于代码和纯sql之间的一种api* spark在DSL语法api中,将纯sql中的函数都使用了隐式转换变成一个scala中的函数* 如果想要在DSL语法中使用这些函数,需要导入隐式转换*///导入Spark sql中所有的sql隐式转换函数import org.apache.spark.sql.functions._//导入另一个隐式转换,后面可以直接使用$函数引用字段进行处理//session.implicits 这个却决去上面的SparkSession的对象名字import session.implicits._/*** 开始写DSL*/val wordCountDF: DataFrame = wordDF.select(explode(split($"line", "\\|")) as "word").groupBy($"word").agg(count($"word") as "count")/*** 保存数据*/wordCountDF.repartition(1).write.format("csv").option("sep","\t").mode(SaveMode.Overwrite).save("spark/data/sparkout2")1.3.2 DataFrame的补充
1.可以读json文件,不需要手动指定列名
val session: SparkSession = SparkSession.builder().master("local").appName("DSL的基本语句").getOrCreate()val jsonDF: DataFrame = session.read.json("spark/data/students.json")jsonDF.show(100,truncate = false)2.show的方法可以传入展示总条数,并完全显示数据内容
1.3.3 select
1.select 直接加字段,这样只能查看信息,不能做如何操作
select("id","name","age")
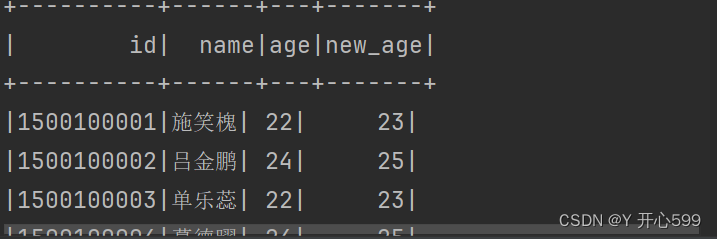
2.selectExpr可以修改字段的值
electExpr("id","name","age","age + 1 as new_age").show()
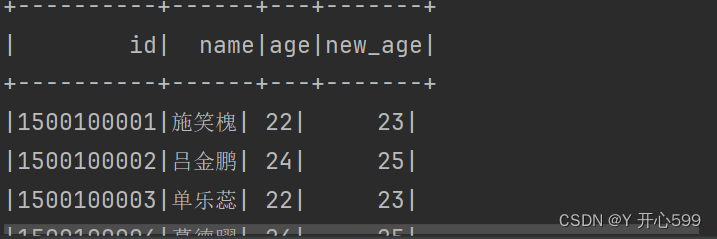
3.select+$ 将字段变成对象,更加贴切sql
select($"id",$"name",$"age",$"age" + 1 as "new_age").show()
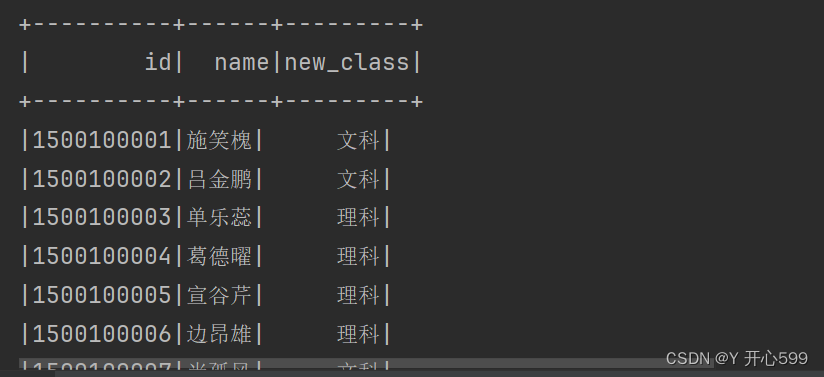
4.select可以加上sql的函数使用
stuDF.select($"id",$"name",substring($"clazz",0,2) as "new_class").show()
1.3.4 where
1.直接过滤
where("gender='女' and age=23")
2.将字段名作为对象
where($"gender" === "女" and $"age" === 23)
3.===是判断2个值是否相等,=!=判断2个值不相等
1.3.5 分组聚合
1.groupBy与agg函数要在一起用,分组聚合之后的结果DF中只会包含分组字段和聚合字段
2.分组的字段是出现比较多的字段
stuDF.groupBy($"clazz")
.agg(count($"clazz") as "number",round(avg($"age"),2) as "avg_age").show()
1.3.6 排序
1.排序的操作优先级很低
2.desc:降序,默认是升序
stuDF.groupBy($"clazz")
.agg(count($"clazz") as "number")
.orderBy($"number").show()
1.3.7 join
1.关联字段名相同的
stuDF.join(scoreDF,"id")
2.关联字段名不相同的
stuDF.join(scoreDF, $"id" === $"sid")
3.join后面还可以传一个参数,表示是啥连接的,默认是内连接
stuDF.join(scoreDF, $"id" === $"sid", "inner")
1.3.8 开窗
1.sql开窗
使用开窗函数
DF.select($"id", $"clazz", $"sum_score", row_number() over (Window partitionBy $"clazz" orderBy $"sum_score".desc) as "rn")
2.DSL开窗 使用withColumn函数(”列名“,sql语句)
.withColumn("rn",row_number() over (Window partitionBy $"clazz" orderBy $"sum_score".desc))
1.4 读取文件的类型
1.4.1 csv
1.读文件需要指定文件的类型,还要定义列的类型,还有分隔符,最后指定文件路径
.format("csv")
.schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
.option("sep", ",")
.load("spark/data/students.csv")
2.写文件需要指定分隔符
1.4.2 Json
1.读文件,指定类型与位置即可
.format("json")
.load("spark/data/students2.json")
2.写文件
2.读文件也是一样
1.4.3 arquet
1.读写文件跟json文件一样
1.5 jcbc
1.连接,MySQL数据库的时候,连接不成功,url加参数
/*** 读取数据库中的数据,mysql* 数据库连接不是加一个useSSL=false* 如果还是不行加这个 useUnicode=true&allowPublicKeyRetrieval=true&characterEncoding=utf8&useSSL=false*/val jodDF: DataFrame = session.read.format("jdbc").option("url", "jdbc:mysql://192.168.73.100:3306?useSSL=false").option("dbtable", "bigdata29.job_listing").option("user", "root").option("password", "123456").load()jodDF.show(10,truncate = false)1.6 RDD与DF的转化
1.6.1 RDD转DF
1.SparkSession包含了SparkContext,直接才用.点形式获取SparkContext对象
2.直接.toDF直接飙车DF类型,如果后续需要做sql查询,需要加上表名
DF.createOrReplaceTempView("表名")
val context: SparkContext = session.sparkContextval stuRDD: RDD[String] = context.textFile("spark/data/ws/students.csv")val linesRDD: RDD[(String, String, String, String, String)] = stuRDD.map((line: String) => {val stuList: Array[String] = line.split(",")val id: String = stuList(0)val name: String = stuList(1)val age: String = stuList(2)val gender: String = stuList(3)val clazz: String = stuList(4)(id, name, age, gender, clazz)})val frame: DataFrame = linesRDD.toDF("id","name","age","gender","clazz")frame.createOrReplaceTempView("students")val frame1: DataFrame = session.sql("""|select|clazz,|count(1) as num|from|students|group by clazz|""".stripMargin)1.6.2 DF转RDD
1.直接使用DF.rdd()方法即可,但是数据类型是Row类型
2.在Row的数据类型中 所有整数类型统一为Long 小数类型统一为Double
/*** 在Row的数据类型中 所有整数类型统一为Long 小数类型统一为Double* 转RDD*/val rdd: RDD[Row] = frame1.rddrdd.map{case Row(clazz:String,num:Long)=>(clazz,num)}.foreach(println)二 spark sql 的执行方式
2.1 代码打包运行
1.编写代码
val sparkSession: SparkSession = SparkSession.builder()//如果是提交到linux中执行,不用这个设置// .master("local").appName("spark sql yarn submit").config("spark.sql.shuffle.partitions", 1) //优先级:代码的参数 > 命令行提交的参数 > 配置文件.getOrCreate()import sparkSession.implicits._import org.apache.spark.sql.functions._//读取数据,如果是yarn提交的话,默认读取的是hdfs上的数据val studentsDF: DataFrame = sparkSession.read.format("csv").option("sep", ",").schema("id STRING,name STRING,age INT,gender STRING,clazz STRING").load("/bigdata29/spark_in/data/student")val genderCountsDF: DataFrame = studentsDF.groupBy($"gender").agg(count($"gender") as "counts")//将DF写入到HDFS中genderCountsDF.write.format("csv").option("sep",",").mode(SaveMode.Overwrite).save("/bigdata29/spark_out/out2")2.代码中读的数据是hdfs中的,保证hdfs中有这个文件
3.将代码打包好放到linux中
4.执行命令
spark-submit --master yarn --deploy-mode client --class com.shujia.sql.Demo8SubmitYarn --conf spark.sql.shuffle.partitions=100 spark-1.0.jar
master yarn:提交模式
deploy-mode client :执行方式
class com.shujia.sql.Demo8SubmitYarn:主类名
conf spark.sql.shuffle.partitions=1:设置分区
spark-1.0.jar:jar包名
5. 我代码里面设置了 分区数是1,但是我执行命令又写了100,最后执行结果是只有一个分区,故可以得到优先级:代码的参数 > 命令行提交的参数 > 配置文件
2.2 spark shell (repl)
1.输入命令 spark-shell --master yarn --deploy-mode client后可以来到这个交互式页面
输入一行执行一行命令
2.直接在这里输入spark代码运行,不过这里没有提示,不推荐
3.不能使用yarn-cluster Driver必须再本地启动
2.3 spark-sql
1.输入命令 spark-sql --master yarn --deploy-mode client后进入这个页面
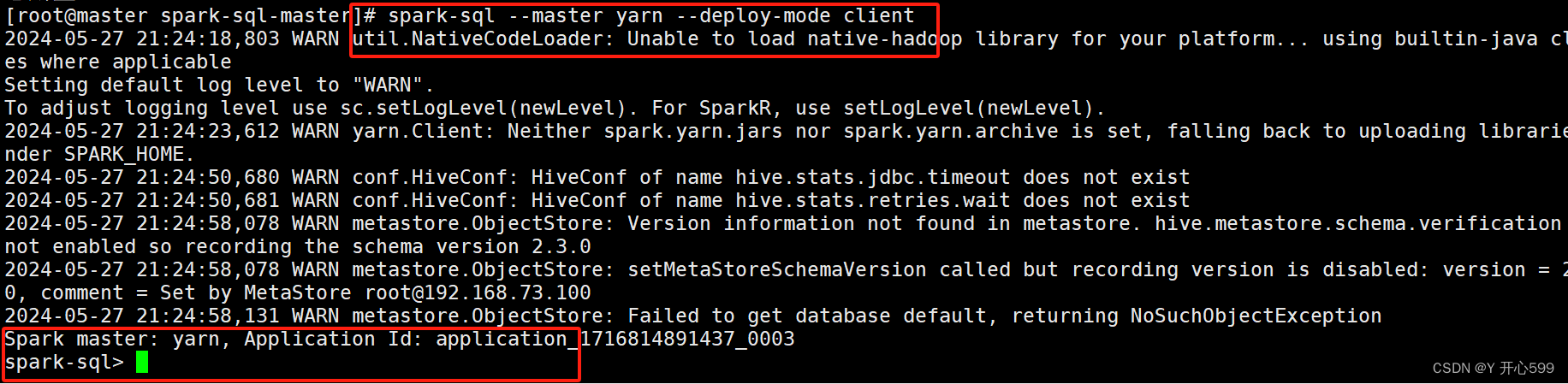
2.注意输入这个命令,在哪个目录下,那个目录就有以下数据
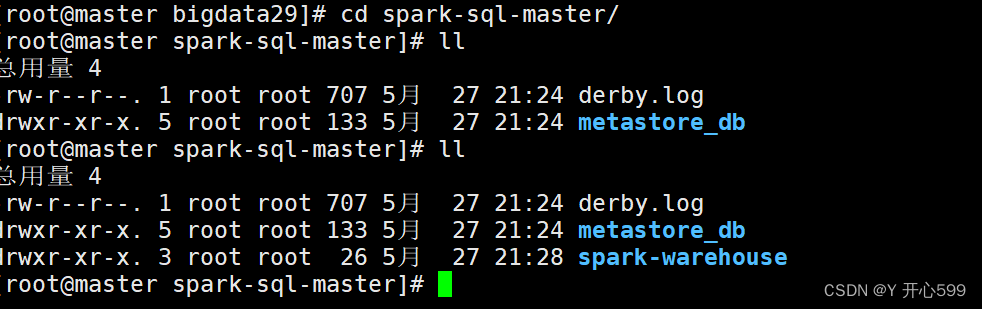
这些数据就是你在spark sql里面创建的库或者表的数据,如果把这个目录删了,在重新输入这个命令,里面的数据也不存在了
3.在spark-sql时完全兼容hive sql的
spark-sql底层使用的时spark进行计算的
hive 底层使用的是MR进行计算的
2.4 spark与hive的整合
1.配置hive-1.2.1中的conf
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
2.将hive-site.xml 复制到spark conf目录下
3.将mysql 驱动包复制到spark jars目录下
4.配置好了过后启动spark-sql --master yarn --deploy-mode client 就可以在spark sql里面看见hive中的数据了
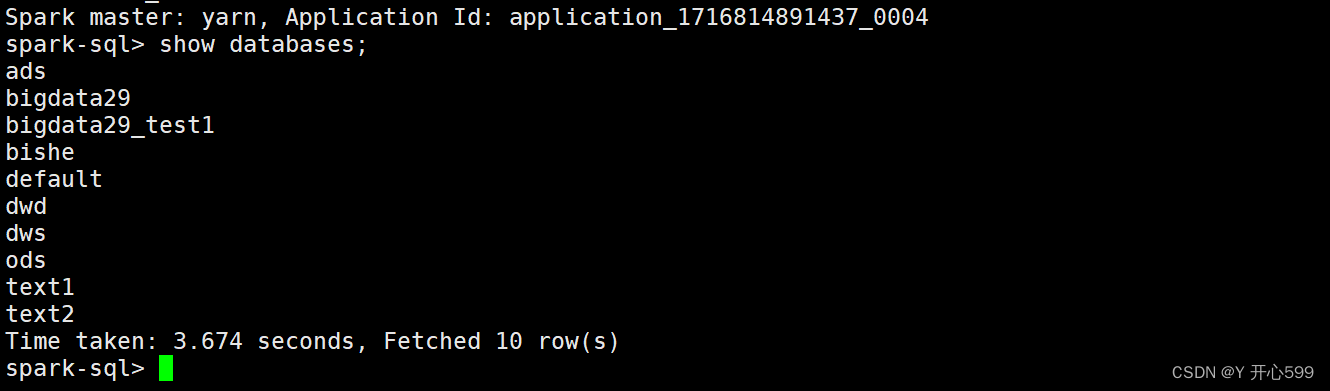
5.如果不想看到那么多的日志信息,可以去修改spark中的conf文件夹中的log4j文件,修改之前最好先复制一份将这个改成ERROR即可

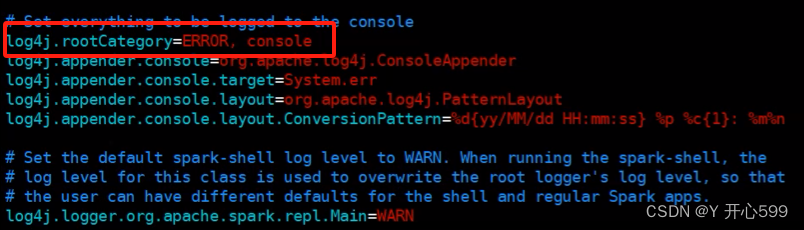
6.再不进入客户端使用spark-hive sql查询
spark-sql -e "select * from student",他执行完自动退出
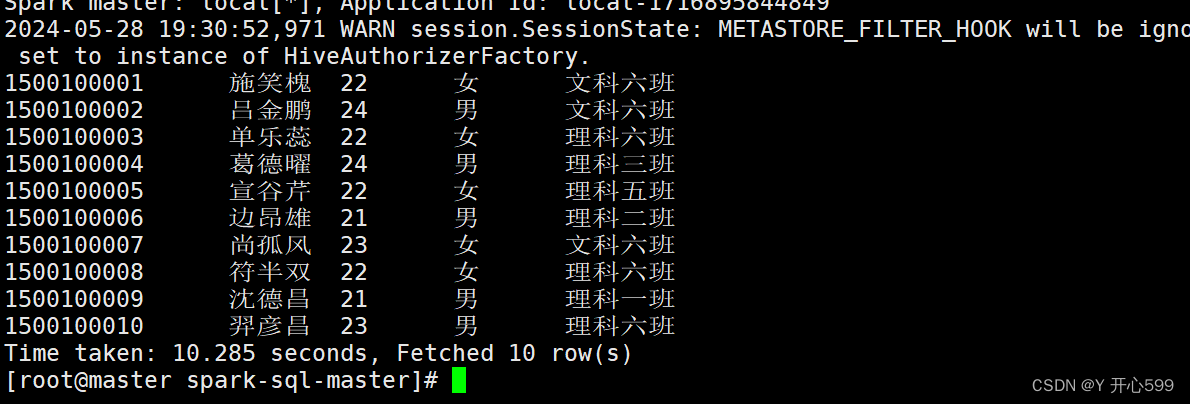
7.还可以编写一个sql脚本,里面是sql的语句
spark-sql -f 脚本名.sql
2.5 spark-hive
1.导入依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId></dependency>
2.编写spark-hive代码
这里记得添加开启支持hive的
val sparkSession: SparkSession = SparkSession.builder().master("local").appName("spark读取hive数据")//开启hive支持.enableHiveSupport().config("spark.sql.shuffle.partitions", 1).getOrCreate()import sparkSession.implicits._import org.apache.spark.sql.functions._sparkSession.sql("use text2")sparkSession.sql("select clazz,count(1) as counts from students group by clazz").show()2.6 自定义函数
2.6.1 使用Scala编写
1.使用udf中的方法,里面可以传很多参数,如果你的函数只需要一个,那么选0那个
2.如果使用不成功,可以将scala的依赖提高一个版本
val hjx: UserDefinedFunction = udf((str: String) => "hjx" + str)2.6.2 spark-sql编写
1.先要2.6.1中的函数存在
2.再使用sparkSession.udf.register("shujia_str", hjx),将hjx函数在sql中命名为shujia_str的函数
3.再使用sql就可以使用shujia_str这个函数了
studentsDF.createOrReplaceTempView("students")//将自定义的函数变量注册成一个函数sparkSession.udf.register("shujia_str", hjx)sparkSession.sql("""|select clazz,shujia_str(clazz) as new_clazz from students|""".stripMargin).show()2.6.3 打包
1.编写一个Scala类继承 UDF,编写想要的函数
2.将类打包,放在linux中spark的jars目录下
3.进入spark-sql的客户端
4.使用上传的jar中的udf类来创建一个函数,这个命令在客户端输入
create function shujia_str as 'com.shujia.sql.Demo12ShuJiaStr';
5.然后客户端就可以使用shujia_str的函数
package com.shujia.sqlimport org.apache.hadoop.hive.ql.exec.UDFclass Demo12ShuJiaStr extends UDF {def evaluate(str: String): String = {"shujia: " + str}
}/*** 1、将类打包,放在linux中spark的jars目录下* 2、进入spark-sql的客户端* 3、使用上传的jar中的udf类来创建一个函数* create function shujia_str as 'com.shujia.sql.Demo12ShuJiaStr';*/相关文章:
spark的简单学习二
一 spark sql基础 1.1 Dataframe 1.介绍: DataFrame也是一个分布式数据容器。然而DataFrame更像传统数据库的二维表 格,除了数据以外,还掌握数据的结构信息,即schema。同时,与Hive类似,DataFrame也支 持…...

测试文章27-这是一篇测试文章请忽略
这是一篇测试文章请忽略 这是测试的文字,如有打扰请谅解。稍后测试完毕会删除 测试代码块 public static void main(String[] args){System.out.println("Hello, World!"); } aaa...

卡方分布和 Zipf 分布模拟及 Seaborn 可视化教程
卡方分布 简介 卡方分布是一种连续概率分布,常用于统计学中进行假设检验。它描述了在独立抽样中,每个样本的平方偏差之和的分布。卡方分布的形状由其自由度 (df) 参数决定,自由度越大,分布越平缓。 参数 卡方分布用两个参数来…...

音视频开发13 FFmpeg 音频 相关格式分析 -- AAC ADTS格式分析
这一节,我们学习常用的音频的格式 AAC,重点是掌握 AAC的传输格式 ADTS 头部的信息,目的是 : 当音频数据有问题的时候,如果是AAC的编码,在分析 头部信息的时候能够根据头部信息 判断问题是否出现在 头部。 A…...
周三晚19:00 | 数据资源入表案例拆解,他们如何应对入表难点?
数据资源入表的具体场景是怎样的?如何应对数据资源入表难点? 6月5日,即周三晚19:00,讲师-星光数智首席数据架构师 魏战松将继续带来关于《数据要素资产运营》的主题直播,为大家拆解数据资源入表的具体案例。 累计77…...

树的知识总结
一:树的基本术语(只写了查漏的部分 1 双亲:就是父节点 2 层序编号 3 有序无序树 4 森林 二:逻辑结构上与线性结构的比较 三:树的存储结构 ①双亲表示节点法:...

工业安全智勇较量,赛宁网安工业靶场决胜工业网络攻防对抗新战场
2024年1月30日,工信部发布《工业控制系统网络安全防护指南》(工信部网安〔2024〕14号),围绕安全管理、技术防护、安全运营、责任落实四方面提出安全防护要求,强调聚焦安全薄弱关键环节,强化技术应对策略&am…...
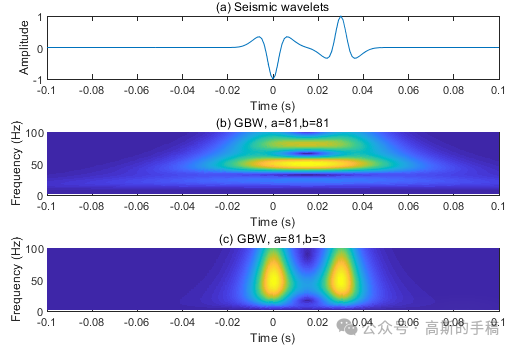
一种一维时间序列信号的广义小波变换方法(MATLAB)
地震波在含油气介质中传播时,其高频分量往往比低频分量衰减更快。据此,地震波的高频分量和低频分量之间的差异值可以用于分析含油气衰减位置,从而间接指示出含油气储层。对于时频域中的地震波衰减分析,一般地,利用地震…...

【GIC400】——驱动代码实现
文章目录 驱动代码实现IRQ 中断处理GIC 驱动GIC 使用使用示例系列文章 【ARMv7-A】——异常与中断 【ARMv7-A】——异常中断处理概述 【ARMv7-A】——进入和退出异常中断的过程 【GIC400】——PLIC,NVIC 和 GIC 中断对比 【GIC400】——GIC 简介 【GIC400】——GIC 相关的 CP1…...

如何在 Vue 组件中正确地使用 data 函数?
在 Vue 组件中正确使用 data 函数有以下几点需要注意: 返回一个对象: data 函数必须返回一个对象,这个对象包含了组件实例需要用到的所有数据属性。export default {data() {return {message: Hello, Vue!,count: 0}} }不要使用箭头函数: data 函数不应该使用箭头函数 () >…...

.Net 基于MiniExcel的导入功能接口示例
/// <summary>/// 导入/// </summary>/// <param name"formFile"></param>/// <returns></returns>[HttpPost("Import")]public async Task<ExecResult> Import(IFormFile formFile){try{if (formFile null) t…...

流量焦虑?别担心,Xinstall一站式App推广解决方案来了!
在移动互联网时代,App已经成为人们日常生活中不可或缺的一部分。然而,对于众多开发者来说,如何有效地推广自己的App,吸引更多的用户,却是一个不小的挑战。今天,我们将为大家介绍一款强大的App推广工具——X…...

降薪潮要开始了么?
互联网要全面迎来降薪潮了么,最近这个观念一直冲击着我 起因就是,前一段一位朋友降薪40%拿到了offer;还有一位金融机构的人力资源负责人朋友告诉我,最近来的很多互联网人都是降薪来的,普遍降30-50%不等 我就在想&…...

网络服务DHCP的安装
DHCP的安装 检查并且安装dhcp有关软件包 rpm -qc dhcp #检查是否存在dhcp yum install -y dhcp #进行yum安装查看系统的配置文件 切换到对应目录查看相关文件配置,发现是空目录。 将官方提供的example复制到原配置文件中 cp /usr/share/doc/dhcp-4.2.5/dhcpd.…...

SELinux:安全增强型Linux
SELinux:安全增强型Linux 作用: 可以保护linux系统的安全为用户分配最小的权限 状态: Enforcing:强制保护Permissive:宽松状态Disabled:禁用 为了安全性考虑,希望SELinux设置为Enforcing状态…...

.NET Redis限制接口请求频率 滑动窗口算法
在.NET中使用Redis来限制接口请求频率(每10秒只允许请求一次) NuGet setup StackExchange.Redis 实现速率限制逻辑: 在控制器或服务层中,编写Redis速率限制计数器。 设置Redis键: 为每个用户或每个IP地址设置一个唯一…...

Java List数据结构与常用方法
1.1 数据结构概述 Java的集合框架其实就是对数据结构的封装,在学习集合框架之前,有必要先了解下数据结构。 1.1.1 什么是数据结构 所谓数据结构,其实就是计算机存储、组织数据的方式。 数据结构是用来分析研究数据存储操作的,其实…...
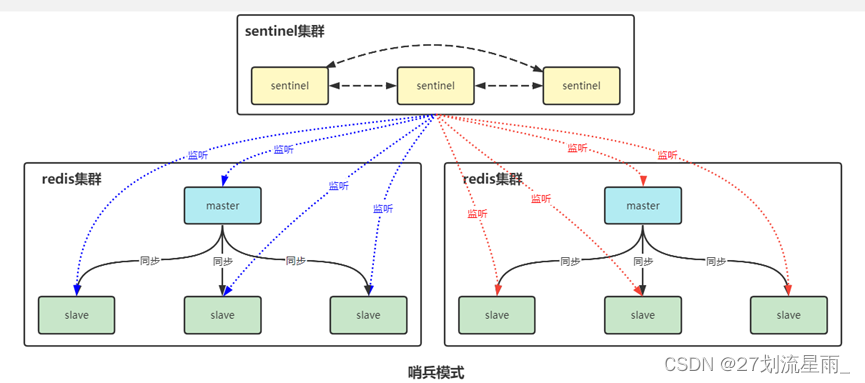
Docker搭建redis-cluster集群
1. 前期准备 1.1 拉redis镜像 docker search redis docker pull redis1. 2 创建网卡 docker network create myredis --subnet 172.28.0.0/16#查看创建的网卡 docker network inspect myredisdocker network rm myredis #删除网卡命令 多个中间 空格隔开 docker network --h…...

实验室类管理平台LIMS系统的ui设计实例
实验室类管理平台LIMS系统的ui设计实例...

<PLC><西门子><工控>西门子博图V18中使用SCL语言编写一个CRC16-modbus校验程序
前言 本系列是关于PLC相关的博文,包括PLC编程、PLC与上位机通讯、PLC与下位驱动、仪器仪表等通讯、PLC指令解析等相关内容。 PLC品牌包括但不限于西门子、三菱等国外品牌,汇川、信捷等国内品牌。 除了PLC为主要内容外,PLC相关元器件如触摸屏(HMI)、交换机等工控产品,如…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

Ubuntu Cursor升级成v1.0
0. 当前版本低 使用当前 Cursor v0.50时 GitHub Copilot Chat 打不开,快捷键也不好用,当看到 Cursor 升级后,还是蛮高兴的 1. 下载 Cursor 下载地址:https://www.cursor.com/cn/downloads 点击下载 Linux (x64) ,…...

Kafka主题运维全指南:从基础配置到故障处理
#作者:张桐瑞 文章目录 主题日常管理1. 修改主题分区。2. 修改主题级别参数。3. 变更副本数。4. 修改主题限速。5.主题分区迁移。6. 常见主题错误处理常见错误1:主题删除失败。常见错误2:__consumer_offsets占用太多的磁盘。 主题日常管理 …...

车载诊断架构 --- ZEVonUDS(J1979-3)简介第一篇
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...

算法250609 高精度
加法 #include<stdio.h> #include<iostream> #include<string.h> #include<math.h> #include<algorithm> using namespace std; char input1[205]; char input2[205]; int main(){while(scanf("%s%s",input1,input2)!EOF){int a[205]…...
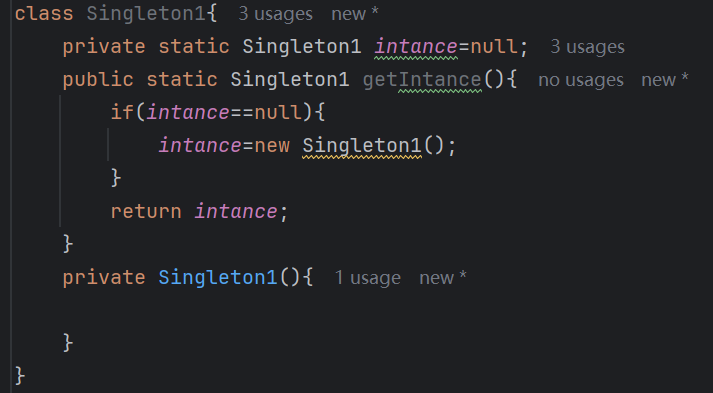
【Java多线程从青铜到王者】单例设计模式(八)
wait和sleep的区别 我们的wait也是提供了一个还有超时时间的版本,sleep也是可以指定时间的,也就是说时间一到就会解除阻塞,继续执行 wait和sleep都能被提前唤醒(虽然时间还没有到也可以提前唤醒),wait能被notify提前唤醒…...