【scikit-learn009】异常检测系列:单类支持向量机(OC-SVM)实战总结(看这篇就够了,已更新)
1.一直以来想写下机器学习训练AI算法的系列文章,作为较火的机器学习框架,也是日常项目开发中常用的一款工具,最近刚好挤时间梳理、总结下这块儿的知识体系。
2.熟悉、梳理、总结下scikit-learn框架OCSVM模型相关知识体系。
3.欢迎批评指正,欢迎互三,跪谢一键三连!
4.欢迎批评指正,欢迎互三,跪谢一键三连!
5.欢迎批评指正,欢迎互三,跪谢一键三连!
文章目录
- 1.环境前置说明
- 1.`OC-SVM`简要总结
- 2.`scikit-learn`中`One-Class SVM`常用方法及参数含义
- 2.1 `One-Class SVM`中常用方法
- 2.2 参数含义
- 3.`scikit-learn`中`One-Class SVM`实战测试
- 3.1 训练、预测、边界距离计算
- 3.2 训练集数据正常异常点占比分布
- 3.3 测试集上预测
- 3.4 训练集点位分布可视化
- 3.5 测试集点位分布可视化
- 4 奇怪问题
1.环境前置说明
-
import sklearn print( sklearn.__version__ ) # 0.19.2!python --version # Python 3.7.0 # 版本过高,部署至生产环境会产生N多问题,暂时不使用过高版本,实战总结为主 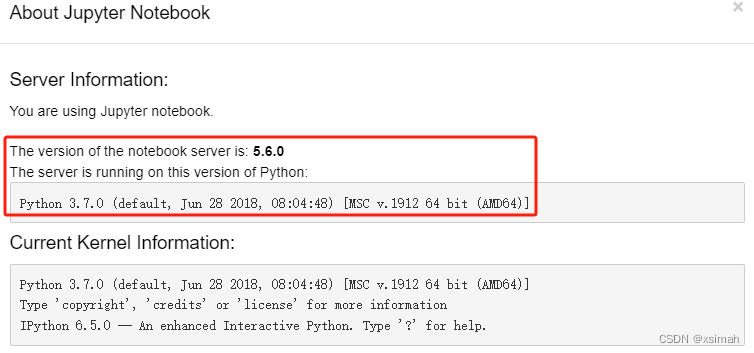
1.OC-SVM简要总结
OC-SVM(One-Class Support Vector Machine)是一种无监督学习算法,支持向量机(Support Vector Machine,SVM)的变体,广泛应用于异常检测、离群点检测、网络安全、图像处理等领域。它可以帮助识别潜在的异常情况,对于保护系统的安全和发现异常行为具有重要的作用。- OC-SVM旨在通过仅使用正常数据来建模,识别出与正常模式不同的异常数据点。即仅使用正例样本来学习一个描述正例样本特征的超平面,并尽可能将负例样本远离该超平面(也可以仅使用负样本)。
- 工作原理及相关术语
- 数据映射:将正常数据映射到高维特征空间,使得正常数据点能够被一个超平面所包围(决策边界
margin)。 - 寻找最优超平面:通过最大化超平面与正常数据之间的间隔,寻找一个最优的分割超平面,使得异常点尽可能远离该超平面。即决策边界要尽可能远离正常数据点。
异常检测:对于新数据点,通过计算其与超平面的距离,来判断该数据点是否为异常。距离较大的数据点更有可能是异常点。
- 数据映射:将正常数据映射到高维特征空间,使得正常数据点能够被一个超平面所包围(决策边界
- 模型重要参数
- nu参数控制异常点的比例。它限制在模型中允许存在的异常点的比例。
较小的nu值表示更少的异常点,较大的nu值表示更多的异常点。 - kernel参数定义了用于计算样本之间
相似度核函数,例如线性核、高斯核等。
- nu参数控制异常点的比例。它限制在模型中允许存在的异常点的比例。
- 优缺点总结
- [S] 不需要异常数据进行训练,只需要正常数据即可。
- [S] 对于高维数据和复杂的数据分布具有较好的适应性。
- [S] 调整模型参数控制异常点的检测灵敏度。
- [W] 在处理高维数据和大规模数据时,
计算复杂度较高 - [W]
数据分布不均匀或存在噪声的情况,效果可能不理想 - [W] 需要谨慎选择模型参数,以避免过拟合或欠拟合的情况
- 工作原理及相关术语
TSNEt-SNE( t-distributed Stochastic Neighbor Embedding)是目前来说效果最好的数据降维与可视化方法,它能够将高维的数据降维到2维或3维,然后画成图的形式表现出来。目前来看,t-SNE是效果相对比较好,并且实现比较方便的方法。- 过于高维一般不使用,当数据维数过高时,两个矩阵的计算量是很大的。所以一般来说,我们会先用
PCA降维到 10 维左右,再使用t-SNE降维到 2 或 3 维空间进行可视化。如果在低维空间中具有可分性,则数据是可分的;如果在高维空间中不具有可分性,可能是数据不可分,也可能仅仅是因为不能投影到低维空间。 t-SNE(TSNE)的原理是将数据点之间的相似度转换为概率。原始空间中的相似度由高斯联合概率表示,嵌入空间的相似度由“学生t分布”表示。
2.scikit-learn中One-Class SVM常用方法及参数含义
2.1 One-Class SVM中常用方法
- fit(X):输入训练样本进行训练。
- predict(X):返回预测值,+1就是正常样本,-1就是异常样本。
- decision_function(X):返回各样本点到超平面的函数距离(signed distance),正的为正常样本,负的为异常样本。
- set_params(**params):设置这个评估器的参数。
- get_params([deep]):获取这个评估器的参数。
-
| Methods defined here:| | decision_function(self, X)| Signed distance to the separating hyperplane.| | Signed distance is positive for an inlier and negative for an outlier.| | Parameters| ----------| X : array-like, shape (n_samples, n_features)| | Returns| -------| X : array-like, shape (n_samples,)| Returns the decision function of the samples.| | fit(self, X, y=None, sample_weight=None, **params)| Detects the soft boundary of the set of samples X.| | Parameters| ----------| X : {array-like, sparse matrix}, shape (n_samples, n_features)| Set of samples, where n_samples is the number of samples and| n_features is the number of features.| | sample_weight : array-like, shape (n_samples,)| Per-sample weights. Rescale C per sample. Higher weights| force the classifier to put more emphasis on these points.| | Returns| -------| self : object| Returns self.| | Notes| -----| If X is not a C-ordered contiguous array it is copied.| | predict(self, X)| Perform classification on samples in X.| | For an one-class model, +1 or -1 is returned.| | Parameters| ----------| X : {array-like, sparse matrix}, shape (n_samples, n_features)| For kernel="precomputed", the expected shape of X is| [n_samples_test, n_samples_train]| | Returns| -------| y_pred : array, shape (n_samples,)| Class labels for samples in X.| Methods inherited from sklearn.base.BaseEstimator:| | __getstate__(self)| | __repr__(self)| Return repr(self).| | __setstate__(self, state
相关文章:
【scikit-learn009】异常检测系列:单类支持向量机(OC-SVM)实战总结(看这篇就够了,已更新)
1.一直以来想写下机器学习训练AI算法的系列文章,作为较火的机器学习框架,也是日常项目开发中常用的一款工具,最近刚好挤时间梳理、总结下这块儿的知识体系。 2.熟悉、梳理、总结下scikit-learn框架OCSVM模型相关知识体系。 3.欢迎批评指正,欢迎互三,跪谢一键三连! 4.欢迎…...

网络管理与运维
文章目录 网络管理与运维概念:传统网络管理:基于SNMP集中管理:基于iMaster NCE的网络管理:传统网络管理方式: 基于SNMP集中管理:交互方式:MIB:版本:SNMPv3配置网管平台&a…...

数据库查询字段在哪个数据表中
问题的提出 当DBA运维多个数据库以及多个数据表的时候,联合查询是必不可少的。则数据表的字段名称是需要知道在哪些数据表中存在的。故如下指令,可能会帮助到你: 问题的处理 查找sysinfo这个字段名称都存在哪个数据库中的哪个数据表 SELEC…...

第 400 场 LeetCode 周赛题解
A 候诊室中的最少椅子数 计数:记录室内顾客数,每次顾客进入时,计数器1,顾客离开时,计数器-1 class Solution {public:int minimumChairs(string s) {int res 0;int cnt 0;for (auto c : s) {if (c E)res max(res, …...
数据结构与算法之Floyd弗洛伊德算法求最短路径
目录 前言 Floyd弗洛伊德算法 定义 步骤 一、初始化 二、添加中间点 三、迭代 四、得出结果 时间复杂度 代码实现 结束语 前言 今天是坚持写博客的第18天,希望可以继续坚持在写博客的路上走下去。我们今天来看看数据结构与算法当中的弗洛伊德算法。 Flo…...

Ubuntu系统设置Redis与MySQL登录密码
Ubuntu系统设置Redis与MySQL登录密码 在Ubuntu 20.04系统中配置Redis和MySQL的密码,您需要分别对两个服务进行配置。以下是详细步骤: 配置Redis密码 打开Redis配置文件: Redis的配置文件通常位于/etc/redis/redis.conf。 sudo nano /etc/redis/redis.c…...

数据库连接池的概念和原理
目录 一、什么是数据库连接池 二、数据库连接池的工作原理 1.初始化阶段: 2.获取连接: 3.使用连接: 4.管理和优化: 三、数据库连接池的好处 一、什么是数据库连接池 数据库连接池(Database Connection Pooling&…...

国内常用的编程博客网址:技术资源与学习平台
一、国内常用的编程博客网址:技术资源与学习平台 大家初入编程,肯定会遇到各种各样的问题。我们除了找 AI 工具以外,我们还能怎么迅速解决问题呢? 大家可以通过谷歌,百度,必应,github…...
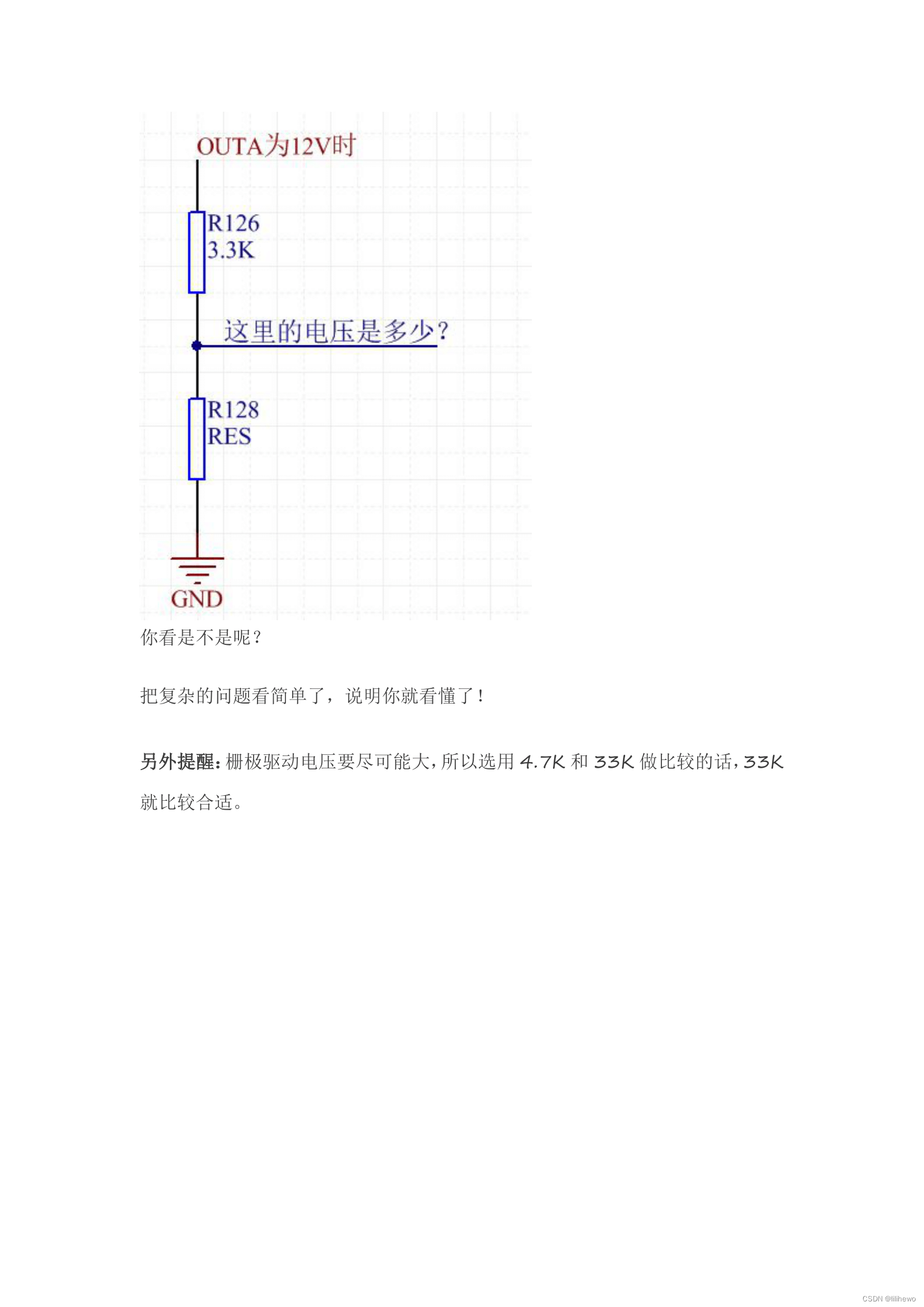
怎么给三极管基极或者MOS管栅极接下拉电阻
文章是瑞生网转载,PDF格式文章下载: 怎么给三极管基极或者MOS管栅极接下拉电阻.pdf: https://url83.ctfile.com/f/45573183-1247189078-52e27b?p7526 (访问密码: 7526)...

Java Web学习笔记5——基础标签和样式
<!DOCTYPE html> html有很多版本,那我们应该告诉用户和浏览器我们现在使用的是HMTL哪个版本。 声明为HTML5文档。 字符集: UTF-8:现在最常用的字符编码方式。 GB2312:简体中文 BIG5:繁体中文、港澳台等方式…...
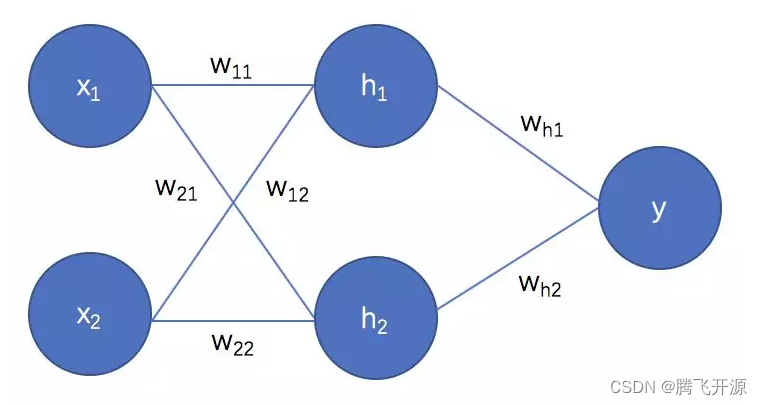
01_深度学习基础知识
1. 感知机 感知机通常情况下指单层的人工神经网络,其结构与 MP 模型类似(按照生物神经元的结构和工作原理造出来的一个抽象和简化了模型,也称为神经网络的一个处理单元) 假设由一个 n 维的单层感知机,则: x 1 x_1 x1 至 x n x_n xn 为 n 维输入向量的各个分量w 1 j…...

60、最大公约数
最大公约数 题目描述 给定n对正整数ai,bi,请你求出每对数的最大公约数。 输入格式 第一行包含整数n。 接下来n行,每行包含一个整数对ai,bi。 输出格式 输出共n行,每行输出一个整数对的最大公约数。 数据范围 1 ≤ n ≤ 1 0 5 , 1≤n≤…...

设计模式在芯片验证中的应用——迭代器
一、迭代器设计模式 迭代器设计模式(iterator)是一种行为设计模式, 让你能在不暴露集合底层表现形式 (列表、 栈和树等数据结构) 的情况下遍历集合中所有的元素。 在验证环境中的checker会收集各个monitor上送过来的transactions࿰…...

imx6ull - 制作烧录SD卡
1、参考NXP官方的手册《i.MX_Linux_Users_Guide.pdf》的这一章节: 1、SD卡分区 提示:我们常用的SD卡一个扇区的大小是512字节。 先说一下i.MX6ULL使用SD卡启动时的分区情况,NXP官方给的镜像布局结构如下所示: 可以看到,…...

使用chatgpt api快速分析pdf
需求背景 搞材料的兄弟经常要分析pdf,然后看到国外有产品是专门调用chatpdf来分析pdf的,所以就来问我能不能帮他也做一个出来。正好我有chatgpt的api,所以就研究了一下这玩意怎么弄。 需求分析 由于chatgpt是按字符算钱的,所以…...

Vue:状态管理pinia
安装 npm install pinia在 main.js 中注册 // main.jsimport { createApp } from vue import { createPinia } from "pinia"; import App from ./app.vueconst app createApp(App) const pinia createPinia(); app.use(pinia).mount(#app)创建 store // stores/…...

【Android Studio】导入import android.support.v7.app.AppcompatActivity;时报错
一、问题描述 在进行安卓项目开发时使用import android.support.v7.app.AppcompatActivity;报错: 运行后会有乱码出现: 二、解决办法 将import android.support.v7.app.AppcompatActivity;改为import androidx.appcompat.app.AppCompatActivity;基本上…...

汽车区域控制器技术分析
汽车区域控制器的起源与发展 随着汽车技术的不断发展,汽车电子电气架构也在经历着深刻的变革。汽车区域控制器作为一种新兴的技术,正逐渐成为汽车电子电气架构的重要组成部分。 在早期,汽车电子电气架构主要采用分布式架构。这种架构下,各个电子控制单元(ECU)分别负责不…...

myEclipse新手使用教程
myEclipse新手使用教程 一、引言 myEclipse是一款流行的Java集成开发环境(IDE),它集成了众多的开发工具,为Java开发者提供了一个强大的开发平台。本文将详细介绍如何下载、安装和配置myEclipse,以及如何创建一个简单…...

【WPF编程宝典】第6讲:资源
研究了 WPF 资源系统使得在应用不同部分可以重用相同对象的原理,介绍了如何在代 码和标记中声明资源,如何提取系统资源,以及如何使用类库程序集在应用程序之间共享资源。 1.资源基础 1.1静态资源和动态资源 区别:静态资源只从资…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...

深度学习之模型压缩三驾马车:模型剪枝、模型量化、知识蒸馏
一、引言 在深度学习中,我们训练出的神经网络往往非常庞大(比如像 ResNet、YOLOv8、Vision Transformer),虽然精度很高,但“太重”了,运行起来很慢,占用内存大,不适合部署到手机、摄…...

用鸿蒙HarmonyOS5实现中国象棋小游戏的过程
下面是一个基于鸿蒙OS (HarmonyOS) 的中国象棋小游戏的实现代码。这个实现使用Java语言和鸿蒙的Ability框架。 1. 项目结构 /src/main/java/com/example/chinesechess/├── MainAbilitySlice.java // 主界面逻辑├── ChessView.java // 游戏视图和逻辑├──…...

Python网页自动化Selenium中文文档
1. 安装 1.1. 安装 Selenium Python bindings 提供了一个简单的API,让你使用Selenium WebDriver来编写功能/校验测试。 通过Selenium Python的API,你可以非常直观的使用Selenium WebDriver的所有功能。 Selenium Python bindings 使用非常简洁方便的A…...

Visual Studio Code 扩展
Visual Studio Code 扩展 change-case 大小写转换EmmyLua for VSCode 调试插件Bookmarks 书签 change-case 大小写转换 https://marketplace.visualstudio.com/items?itemNamewmaurer.change-case 选中单词后,命令 changeCase.commands 可预览转换效果 EmmyLua…...