python爬虫之JS逆向——网页数据解析
目录
一、正则
1 正则基础
元字符
基本使用
通配符: '.'
字符集: '[]'
重复
位置
管道符和括号
转义符
转义功能
转义元字符
2 正则进阶
元字符组合(常用)
模式修正符
re模块的方法
有名分组
compile编译
二、bs4
1 四种对象
2 导航文档树
嵌套选择
子节点、子孙节点
父节点、祖先节点
兄弟节点
3 搜索文档树
name参数
标签名
正则表达式
列表
函数(精致过滤)
关键字参数
文本参数
4 CSS选择器
三、xpath
1 路径表达式
2 谓语
3 通配符
4 其他用法
5 文件操作
文件句柄
读操作
写操作
覆盖写
追加写
一、正则
是描述一段文本排列规则的表达式
正则表达式并不是python的一部分,而是一套独立于编程语言,用于处理复杂文本信息的强大的高级文本操作工具。
python提供re模块或regex模块来调用正则处理引擎
正则对字符串的操作:分割、匹配、查找和替换
1 正则基础
元字符
元字符是具有特殊含义的字符
| 元字符 | 描述 |
|---|---|
| [] | 匹配一个中括号中出现的任意一个原子 |
| [^原子] | 匹配一个没有在中括号中出现的任意原子 |
| \ | 转义字符,可以把原子转换特殊元字符,也可以把特殊元字符转换成原子 |
| ^ | 叫开始边界符或开始锚点符,匹配一行的开头位置 |
| $ | 叫结束边界符或开始锚点符,匹配一行的结束位置 |
| . | 叫通配符、万能通配符或通配元字符,匹配一个除了换行符\n以外任何原子 |
| * | 叫星号贪婪符,指定左边原子出现0次或多次 |
| ? | 叫非贪婪符,指定左边原子出现0次或1次 |
| + | 叫加号贪婪符,指定左边原子出现1次或多次 |
| {n,m} | 叫数量范围贪婪符,指定左边原子的数量范围,有{n},{n,},{,m},{n,m}四种写法, 其中n与m必须是非负整数 |
| | | 指定原子或正则模式进行二选一或多选一 |
| () | 对原子或正则模式进行捕获提取和分组划分整体操作 |
举例和一些特殊组合如下所示
基本使用
import reret1 = re.findall("a", "a,b,c,d,e") # ['a']通配符: '.'
ret2 = re.findall(".", "a,b,c,d,e") # ['a', ',', 'b', ',', 'c', ',', 'd', ',', 'e']
ret2 = re.findall("a.b", "a,b,c,d,e,acb,abb,a\nb,a\tb") # ['a,b', 'acb', 'abb', 'a\tb']字符集: '[]'
ret3 = re.findall("[ace]", "a,b,c,d,e") # ['a', 'c', 'e']
ret3 = re.findall("a[bce]f", "af,abf,abbf,acef,aef") # ['abf', 'aef']
ret3 = re.findall("[a-zA-Z]", "a,b,c,d,e,A,V") # ['a', 'b', 'c', 'd', 'e', 'A', 'V']
ret3 = re.findall("[a-zA-Z0-9]", "a,b,c,d,1,e,A,V") # ['a', 'b', 'c', 'd', '1', 'e', 'A', 'V']
ret3 = re.findall("[^0-9]", "a,2,b,c,d,1,e,A,V") # ['a', ',', ',', 'b', ',', 'c', ',', 'd', ',', ',', 'e', ',', 'A', ',', 'V']
# [0-9] == \d [a-zA-Z0-9] == \w重复
'*' :1-多次
'+' :0-多次
'?' :0/1次, 也可取消贪婪匹配
'{m,n}' :m-n次
贪婪匹配,每次为最多次匹配
?取消贪婪匹配
ret4 = re.findall("\d+", "a,b,234,d,6,888") # ['234', '6', '888']
# ?取消贪婪匹配
ret4 = re.findall("\d+?", "a,b,234,d,6,888") # ['2', '3', '4', '6', '8', '8', '8']+
ret4 = re.findall("\w", "apple,banana,orange,melon") # ['a', 'p', 'p', 'l', 'e', 'b', 'a', 'n', 'a', 'n', 'a', 'o', 'r', 'a', 'n', 'g', 'e', 'm', 'e', 'l', 'o', 'n']
ret4 = re.findall("\w+", "apple,banana,orange,melon") # ['apple', 'banana', 'orange', 'melon']
ret4 = re.findall("\w+?", "apple,banana,orange,melon") # ['a', 'p', 'p', 'l', 'e', 'b', 'a', 'n', 'a', 'n', 'a', 'o', 'r', 'a', 'n', 'g', 'e', 'm', 'e', 'l', 'o', 'n']注:"\w*" == ""和"\w"
*
ret4 = re.findall("\w*", "apple,banana,orange,melon") # ['apple', '', 'banana', '', 'orange', '', 'melon', '']
ret4 = re.findall("abc*", "abc,abcc,abe,ab") # ['abc', 'abcc', 'ab', 'ab']?
ret4 = re.findall("\w{6}", "apple,banana,orange,melon") # ['banana', 'orange']{m,n}
ret4 = re.findall("abc?", "abc,abcc,abe,ab") # ['abc', 'abc', 'ab', 'ab']
ret4 = re.findall("abc??", "abc,abcc,abe,ab") # ['ab', 'ab', 'ab', 'ab']位置
'^' :匹配开头符合条件的字符
'$' :匹配结尾符合条件的字符
^
ret5 = re.findall("^\d+", "34,banana,255,orange,5434") # ['34']
ret5 = re.findall("^\d+", "peath,34,banana,255,orange,5434") # []$
ret5 = re.findall("\d+$", "34,banana,255,orange,5434") # ['5434']
ret5 = re.findall("\d+$", "peath,34,banana,255,orange") # []管道符和括号
|:或
():优先提取/括号
(?:) 取消模式捕获
ret6 = re.findall(",(\w{5}),", ",apple,banana,peach,orange,melon,") # ['apple', 'peach', 'melon']
ret6 = re.findall("\w+@(163|qq)\.com", "123abc@163.com...789xyz@qq.com") # ['163', 'qq']
ret6 = re.findall("\w+@(?:163|qq)\.com", "123abc@163.com...789xyz@qq.com") # ['123abc@163.com', '789xyz@qq.com']转义符
转义的两个功能
将一些普通符号赋予特殊功能 \d \w ...
将特殊符号取消其特殊功能 * . + ...
转义功能
ret7 = re.findall("\(abc\)", "(abc)...") # ['(abc)']转义元字符
| 特殊模式 | 描述 |
|---|---|
| \d | 匹配任意一个数字(0-9)[0-9] |
| \D | 匹配任意一个非数字字符[^0-9]/[^\d] |
| \w | 匹配任意一个字母、数字或下划线(单词字符)[A-Za-z0-9_] |
| \W | 匹配任意一个非字母、非数字、非下划线字符[^A-Za-z0-9_]\[^\w] |
| \s | 匹配任意一个空白字符(空格、制表符、换行符等)[ \f\n\r\t\v] |
| \S | 匹配任意一个非空白字符[^ \f\n\r\t\v]\[\s] |
| \b | 匹配单词边界 |
| \B | 匹配非单词边界[^\b] |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
| \f | 匹配一个换页符 |
| \\ | 匹配一个反斜杠 |
| \0 | 匹配一个 NULL 字符 |
2 正则进阶
元字符组合(常用)
.*?
.+?
text1 = '<12> <xyz> <!@#$%> <1a!#e2> <>'
ret1 = re.findall("<\d+>", text1) # ['<12>']
ret1 = re.findall("<\w+>", text1) # ['<12>', '<xyz>']
ret1 = re.findall("<.+>", text1) # ['<12> <xyz> <!@#$%> <1a!#e2> <>']
ret1 = re.findall("<.+?>", text1) # ['<12>', '<xyz>', '<!@#$%>', '<1a!#e2>']
ret1 = re.findall("<.*?>", text1) # ['<12>', '<xyz>', '<!@#$%>', '<1a!#e2>', '<>']text2 = '''<12
><xyz><!@#$%><1a!#
e2><>
'''ret2 = re.findall("<.*?>", text2) # ['<!@#$%>', '<>']
ret2 = re.findall("<.*?>", text2, re.S) # ['<12\n>', '<x\n yz>', '<!@#$%>', '<1a!#\ne2>', '<>']模式修正符
| 修正符 | re模块提供的变量 | 描述 |
|---|---|---|
| i | re.I | 使模式对大小写不敏感,也就是不区分大小写 |
| m | re.M | 使模式在多行文本中可以多个行头和行位,影响^和$ |
| s | re.S | 让通配符,可以代表所有的任意原子(包括换行符\n在内) |
import reret = re.findall('.*?<span class="title">(.*?)</span>.*?<span class=\"rating_num\".*?>(.*?)</span>',s,re.S,
)
print(ret)
print(len(ret))re模块的方法
re.Match对象对应两个方法
ret.span() 返回符合规则的字符串的出现位置,为元组
ret.group() 返回第一个匹配字符串
| 函数 | 描述 |
|---|---|
| findall | 按指定的正则模式查找文本中符合正则模式的匹配项,以列表格式返回结果 |
| search | 在字符串的任何位置查找首个符合正则模式的匹配项,存在返回re.Match对象,不存在返回None |
| match | 判定字符串开始位置是否匹配正则模式的规则,匹配返回re.Match对象,不匹配返回None |
| split | 按指定的正则模式来分割字符串,返回一个分割后的列表 |
| sub/subn | 把字符串按指定的正则模式来查找符合正则模式的匹配项,并可以替换一个或多个匹配项成其他内容 |
| compile | 将规则编译,可以重复使用 |
有名分组
<name>
search和match的区别:
search在任何位置找,match从开头找
ret3 = re.search("(?P<tel>1[3-9]\d{9}).*?(?P<email>\d+@qq\.com)", "我的手机号是18793437893,我的邮箱是123@qq.com")print(ret3.group()) # 18793437893,我的邮箱是123@qq.com
print(ret3.group("tel")) # 18793437893
print(ret3.group("email")) # 123@qq.comcompile编译
s1 = "12 apple 34 peach 21 banana"
s2 = "18 apple 12 peach 33 banana"
reg = re.compile(r"\d+")print(reg.findall(s1))
print(reg.findall(s2))二、bs4
bs4:Beautiful Soup是python的一个库,主要功能是从网页抓取数据。
需要安装两个库
pip install bs4
pip install lxml
基本使用顺序如下所示:
# 调用bs4库
from bs4 import BeautifulSoup# 读文件
with open("第一阶段-爬虫\\JS逆向\\3-网页数据解析\\bs4\\demo.html", "r", encoding="utf-8") as f:s = f.read()# 创建bs4对象
soup = BeautifulSoup(s, 'html.parser')# 或者使用如下方式
soup = BeautifulSoup(open("第一阶段-爬虫\\JS逆向\\3-网页数据解析\\bs4\\demo.html", encoding="utf-8"), "html.parser")1 四种对象
BeautifulSoup
Tag
NavigableString
Comment
主要使用BeautifulSoup和Tag对象
from bs4 import BeautifulSoupwith open("第一阶段-爬虫\\JS逆向\\3-网页数据解析\\bs4\\demo.html", "r", encoding="utf-8") as f:s = f.read()soup = BeautifulSoup(s, 'html.parser')# Tag查找标签
# 如果查到,一定是一个Tag对象
print(soup.body)
print(type(soup.body))print(soup.div.a) # <a class="nav-login" href="https://accounts.douban.com/passport/login?source=movie" rel="nofollow">登录/注册</a>
print(soup.div.a.name) # aprint(soup.a["href"]) # https://accounts.douban.com/passport/login?source=movie
print(soup.a.attrs) # {'href': 'https://accounts.douban.com/passport/login?source=movie', 'class': ['nav-login'], 'rel': ['nofollow']}# 拿取文本
print(soup.a.string) # 登录/注册
print(soup.a.text) # 登录/注册print({link.text:link["href"] for link in soup.find_all("a")})2 导航文档树
嵌套选择
子节点、子孙节点
父节点、祖先节点
兄弟节点
导入文件并创建对象
from bs4 import BeautifulSoupwith open("第一阶段-爬虫\\JS逆向\\3-网页数据解析\\bs4\\demo.html", "r", encoding="utf-8") as f:s = f.read()soup = BeautifulSoup(s, 'html.parser')嵌套选择
# 嵌套选择
print(soup.head.title.text)
print(soup.body.a.text)
子节点、子孙节点
# 子节点、子孙节点
print(soup.p.contents) # p下所有子节点
print(soup.p.children) # 得到一个迭代器,包含p下所有子节点
print(soup.p.descendants) # 获取子孙节点,p下所有标签都会选择出来父节点、祖先节点
# 父节点、祖先节点
print(soup.a.parent) # 获取a标签的父节点
print(soup.a.parents) # 获取a标签所有祖先节点,父亲、爷爷等等兄弟节点
# 兄弟节点
print(soup.a.next_sibling) # 下一个兄弟
print(soup.a.next_sibling.next_sibling) # 下下一个兄弟,以此类推
print(soup.a.previous_sibling) # 上一个兄弟
print(soup.a.previous_sibling.previous_sibling) # 上上一个兄弟3 搜索文档树
fand_all()
name参数(标签名过滤):字符串、正则表达式、列表、方法
字符串:即标签名关键字参数(属性过滤)
文本参数(文本过滤)
find()
与find_all()的区别:find()只查找第一个
参数完全一样
find_parents() 找所有父亲标签
find_parent() 找父亲标签
优点:只包含兄弟标签
find_next_siblings() 找下边所有兄弟标签
find_next_sibling() 找下边一个兄弟标签
find_previous_siblings() 找上边所有兄弟标签
find_previous_sibling() 找上边一个兄弟标签
find_all_next() 找下边所有相同标签
find_next() 找下边相同标签
这里使用find_all()方法举例,其余搜索使用方法几乎相同
name参数
标签名
# name参数:标签名
ret1 = soup.find_all(name="a") # 查找所有a标签
print(ret1)正则表达式
# name参数:正则表达式
ret2 = soup.find_all(name=re.compile("^a"))
print(ret2)列表
# name参数:列表
ret3 = soup.find_all(name=["a", "b"])
print(ret3)函数(精致过滤)
# name参数:函数(精致过滤)# 表示拥有class和id两个属性的标签
def has_class_has_id(tag):return tag.has_attr("class") and tag.has_attr("id")print(soup.find_all(name=has_class_has_id))关键字参数
ret4 = soup.find_all(href="https://img1.doubanio.com/cuphead/movie-static/pics/apple-touch-icon.png"
)
ret4 = soup.find_all(attrs={"href": "https://img1.doubanio.com/cuphead/movie-static/pics/apple-touch-icon.png"}
)
ret4 = soup.find_all(href=re.compile("^https://"), class_="download-android", id="id1")
print(ret4)文本参数
ret5 = soup.find_all(string="豆瓣")
ret5 = soup.find_all(string=re.compile("豆瓣")) # 查找含有"豆瓣"的文本
ret5 = soup.find_all(string=re.compile("豆瓣"), limit=1) # 查找含有"豆瓣"的文本,只取第一个
print(ret5)4 CSS选择器
与CSS中选择器用法相同
select()方法或者在搜索中使用from lxml import etree selector = etree.HTML(源码) # 将源码转换为能被XPath匹配的格式 ret = selector.xpath(表达式) # 返回为一列表
例:soup.select("body a")
from bs4 import BeautifulSoup
import resoup = BeautifulSoup(open("第一阶段-爬虫\\JS逆向\\3-网页数据解析\\正则\\豆瓣top250.html", encoding="utf-8"), "html.parser")items = soup.find_all(class_="item")
print(len(items))for item in items:title = item.find(class_="title").stringrating_num = item.find(class_="rating_num").stringstar = item.find(class_="star").find_all("span")[-1].stringprint(title, rating_num, star)三、xpath
xpath:一种小型的查询语言,属于lxml库模块
使用方式:
from lxml import etree
selector = etree.HTML(源码) # 将源码转换为能被XPath匹配的格式
ret = selector.xpath(表达式) # 返回为一列表1 路径表达式
| 表达式 | 描述 | 实例 | 解析 |
|---|---|---|---|
| / | 从根节点选取 | /body/div[1] | 选取根节点下的body下的第一个div标签 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 | //a | 选取文档中所有的a标签 |
| ./ | 从当前节点再次进行xpath | ./a | 选取当前节点下的所有a标签 |
| @ | 选取属性 | //@class | 选取所有的class属性 |
2 谓语
是放在方括号[]里,用来查找某个特定的节点或者包含某个指定值的节点
| 路径表达式 | 结果 |
|---|---|
| /ul/li[1] | 选取属于ul元素的第一个li元素 |
| /ul/li[last()] | 选取属于ul元素的最后一个li元素 |
| /ul/li[last-1] | 选取属于ul元素的倒数第二个li元素 |
| /ul/li[position()<3] | 选取最前面的两个属于ul元素的子元素的li元素 |
| //a[@title] | 选取所有拥有名为title属性的a元素 |
| //a[@title='xx'] | 选取所有拥有title属性,并且属性值为'xx'的a元素 |
| //a[@title>10] > < >= <= != | 选取所有拥有title属性,并且属性值为大于10的a元素 |
| /body/div[@price>35.00] | 选取body下price元素值大于35的div节点 |
3 通配符
xpath的通配符可以选取未知节点
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型节点 |
4 其他用法
| 表达式 | 结果 |
|---|---|
| //xx[@id="" and @class=""] | 获取满足两者要求的元素 |
| //xx | //xx | 获取若干路径的元素 |
| //xx[id/@class=""] | 获取xx标签中包含或者对应id/class的元素 |
| //xx[n] | 获取xx标签的第n个元素,索引从1开始,last()获取最后一个 |
| //xx[starts-with(@id, "ll")] | 获取xx标签中id属性中以ll开头的,class类似 |
| //xx[contains(@id, "ll")] | 获取xx标签中id属性中包含ll的,class类似 |
| //xx/text() | 获取xx标签中的文本值 |
| //div/a/@href | 获取a标签中的href属性值 |
| //* | 获取所有,例//*[@class="xx"]:获取所有class为xx的标签 |
获取节点内容转换成字符串
c = tree.xpath('//li/a')[0]
result = etree.tostring(c, encoding='utf-8')
print(result.decode('utf-8'))5 文件操作
文件句柄
open()方法
mode参数为对文件的操作,r只读,w只写,rw读写...
encoding表示编码方式
绝对路径
filer = open("D:/桌面/Python自学/第一阶段-爬虫/JS逆向/3-网页数据解析/xpath/豆瓣top250.html",mode="r",encoding="utf-8",
)相对路径
file = open("/豆瓣top250.html", mode="r",encoding="utf-8",)读操作
| 方法 | 功能 |
|---|---|
| file.read() | 直接获取文件内容,参数为整型数字,光标按字移动 |
| file.readline() | 按行获取文件内容,参数为整型数字,光标按字移动 |
| file.readlines() | 获取文件所有行,放在列表中,参数为整型数字,光标按行移动 |
通常以以下方式循环高效获取数据:
for line in file:print(line)写操作
覆盖写
会将源文件内容清空再存入
filew = open("write.txt",mode="w",encoding="utf-8",
)filew.write("")
filew.close()追加写
filew = open("write.txt",mode="a",encoding="utf-8",
)filew.write("")
filew.close()相关文章:

python爬虫之JS逆向——网页数据解析
目录 一、正则 1 正则基础 元字符 基本使用 通配符: . 字符集: [] 重复 位置 管道符和括号 转义符 转义功能 转义元字符 2 正则进阶 元字符组合(常用) 模式修正符 re模块的方法 有名分组 compile编译 二、bs4 1 四种对象 2 导航文档树 嵌套选择 子节点、…...
VL53L4CX TOF开发(2)----修改测距范围及测量频率
VL53L4CX TOF开发.2--修改测距范围及测量频率 概述视频教学样品申请完整代码下载测距范围测量频率硬件准备技术规格系统框图应用示意图生成STM32CUBEMX选择MCU串口配置IIC配置 XSHUTGPIO1X-CUBE-TOF1app_tof.c详细解释测量频率修改修改测距范围 概述 最近在弄ST和瑞萨RA的课程…...

C++之noexcept
目录 1.概述 2.noexcept作为说明符 3.noexcept作为运算符 4.传统throw与noexcept比较 5.原理剖析 6.总结 1.概述 在C中,noexcept是一个关键字,用于指定函数不会抛出异常。如果函数保证不会抛出异常,编译器可以进行更多优化,…...
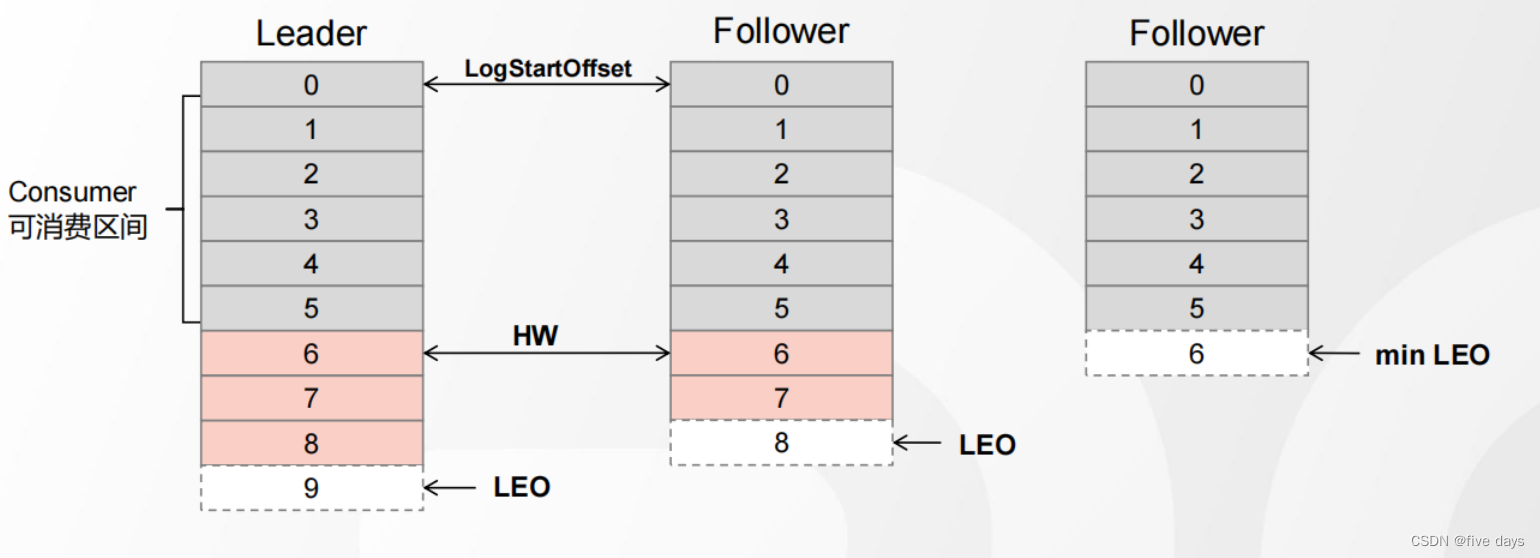
Kafka之Broker原理
1. 日志数据的存储 1.1 Partition 1. 为了实现横向扩展,把不同的数据存放在不同的 Broker 上,同时降低单台服务器的访问压力,我们把一个Topic 中的数据分隔成多个 Partition 2. 每个 Partition 中的消息是有序的,顺序写入&#x…...

RabbitMQ docker安装及使用
1. docker安装RabbitMQ docker下载及配置环境 docker pull rabbitmq:management # 创建用于挂载的目录 mkdir -p /home/docker/rabbitmq/{data,conf,log} # 创建完成之后要对所创建文件授权权限,都设置成777 否则在启动容器的时候容易失败 chmod -R 777 /home/doc…...

篇3:Mapbox Style Specification
接《篇2:Mapbox Style Specification》,继续解读Mapbox Style Specification。 目录 Spec Reference Root 附录: MapBox Terrain-RGB...
C#WPF数字大屏项目实战11--质量控制
1、区域划分 2、区域布局 3、视图模型 4、控件绑定 5、运行效果 走过路过,不要错过,欢迎点赞,收藏,转载,复制,抄袭,留言,动动你的金手指,财务自由...

第九十七节 Java面向对象设计 - Java Object.Finalize方法
Java面向对象设计 - Java Object.Finalize方法 Java提供了一种在对象即将被销毁时执行资源释放的方法。 在Java中,我们创建对象,但是我们不能销毁对象。 JVM运行一个称为垃圾收集器的低优先级特殊任务来销毁不再引用的所有对象。 垃圾回收器给我们一个…...
【scikit-learn009】异常检测系列:单类支持向量机(OC-SVM)实战总结(看这篇就够了,已更新)
1.一直以来想写下机器学习训练AI算法的系列文章,作为较火的机器学习框架,也是日常项目开发中常用的一款工具,最近刚好挤时间梳理、总结下这块儿的知识体系。 2.熟悉、梳理、总结下scikit-learn框架OCSVM模型相关知识体系。 3.欢迎批评指正,欢迎互三,跪谢一键三连! 4.欢迎…...

网络管理与运维
文章目录 网络管理与运维概念:传统网络管理:基于SNMP集中管理:基于iMaster NCE的网络管理:传统网络管理方式: 基于SNMP集中管理:交互方式:MIB:版本:SNMPv3配置网管平台&a…...

数据库查询字段在哪个数据表中
问题的提出 当DBA运维多个数据库以及多个数据表的时候,联合查询是必不可少的。则数据表的字段名称是需要知道在哪些数据表中存在的。故如下指令,可能会帮助到你: 问题的处理 查找sysinfo这个字段名称都存在哪个数据库中的哪个数据表 SELEC…...

第 400 场 LeetCode 周赛题解
A 候诊室中的最少椅子数 计数:记录室内顾客数,每次顾客进入时,计数器1,顾客离开时,计数器-1 class Solution {public:int minimumChairs(string s) {int res 0;int cnt 0;for (auto c : s) {if (c E)res max(res, …...
数据结构与算法之Floyd弗洛伊德算法求最短路径
目录 前言 Floyd弗洛伊德算法 定义 步骤 一、初始化 二、添加中间点 三、迭代 四、得出结果 时间复杂度 代码实现 结束语 前言 今天是坚持写博客的第18天,希望可以继续坚持在写博客的路上走下去。我们今天来看看数据结构与算法当中的弗洛伊德算法。 Flo…...

Ubuntu系统设置Redis与MySQL登录密码
Ubuntu系统设置Redis与MySQL登录密码 在Ubuntu 20.04系统中配置Redis和MySQL的密码,您需要分别对两个服务进行配置。以下是详细步骤: 配置Redis密码 打开Redis配置文件: Redis的配置文件通常位于/etc/redis/redis.conf。 sudo nano /etc/redis/redis.c…...

数据库连接池的概念和原理
目录 一、什么是数据库连接池 二、数据库连接池的工作原理 1.初始化阶段: 2.获取连接: 3.使用连接: 4.管理和优化: 三、数据库连接池的好处 一、什么是数据库连接池 数据库连接池(Database Connection Pooling&…...

国内常用的编程博客网址:技术资源与学习平台
一、国内常用的编程博客网址:技术资源与学习平台 大家初入编程,肯定会遇到各种各样的问题。我们除了找 AI 工具以外,我们还能怎么迅速解决问题呢? 大家可以通过谷歌,百度,必应,github…...
怎么给三极管基极或者MOS管栅极接下拉电阻
文章是瑞生网转载,PDF格式文章下载: 怎么给三极管基极或者MOS管栅极接下拉电阻.pdf: https://url83.ctfile.com/f/45573183-1247189078-52e27b?p7526 (访问密码: 7526)...

Java Web学习笔记5——基础标签和样式
<!DOCTYPE html> html有很多版本,那我们应该告诉用户和浏览器我们现在使用的是HMTL哪个版本。 声明为HTML5文档。 字符集: UTF-8:现在最常用的字符编码方式。 GB2312:简体中文 BIG5:繁体中文、港澳台等方式…...
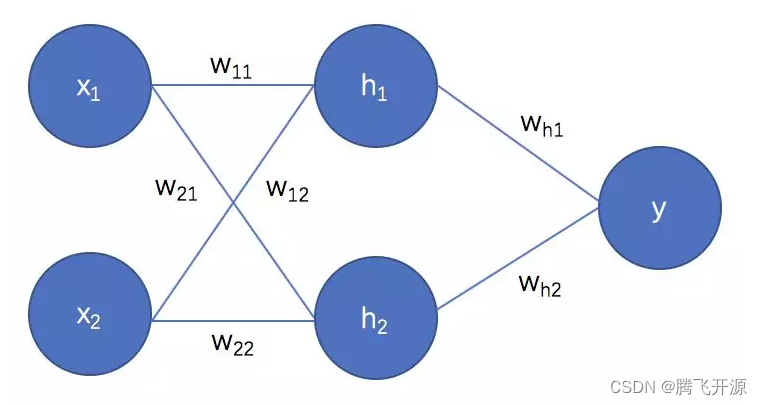
01_深度学习基础知识
1. 感知机 感知机通常情况下指单层的人工神经网络,其结构与 MP 模型类似(按照生物神经元的结构和工作原理造出来的一个抽象和简化了模型,也称为神经网络的一个处理单元) 假设由一个 n 维的单层感知机,则: x 1 x_1 x1 至 x n x_n xn 为 n 维输入向量的各个分量w 1 j…...

60、最大公约数
最大公约数 题目描述 给定n对正整数ai,bi,请你求出每对数的最大公约数。 输入格式 第一行包含整数n。 接下来n行,每行包含一个整数对ai,bi。 输出格式 输出共n行,每行输出一个整数对的最大公约数。 数据范围 1 ≤ n ≤ 1 0 5 , 1≤n≤…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

第7篇:中间件全链路监控与 SQL 性能分析实践
7.1 章节导读 在构建数据库中间件的过程中,可观测性 和 性能分析 是保障系统稳定性与可维护性的核心能力。 特别是在复杂分布式场景中,必须做到: 🔍 追踪每一条 SQL 的生命周期(从入口到数据库执行)&#…...