一文看懂llama2(原理模型训练)
自从Transformer架构问世以来,大型语言模型(Large Language Models, LLMs)以及AIGC技术的发展速度惊人,它们不仅在技术层面取得了重大突破,还在商业应用、社会影响等多个层面展现出巨大潜力。随着ChatGPT的推出,这一技术日益走进大众视野,这也预示着一个由生成式AI塑造的未来正在加速到来。
与此同时,Meta AI Meta AI在2023年推出了LLama(Large Language Model Meta AI)系列大语言模型,这一模型初期是以较为封闭的形式面向特定研究人员开放。之后,又开源LLama系列模型LLama2。
什么是LLama2?
LLama2是Meta AI公司在2023年推出的一款半开源LLM(所谓半开源即为只有Inference没有Train过程),它是Llama的下一代版本,训练数据集2万亿token,上下文长度由llama的2048扩展到4096,可以理解和生成更长的文本,包括7B、13B、70B三个模型,展现出了卓越的性能,使其迅速在基准测试中崭露头角,标志着生成式人工智能领域的一次重要进步。
LLama2模型的任务是在给定前n个单词的基础上预测句子中下一个单词。该模型的核心特点是其预测过程依赖于过去和当前的输入信息,而不考虑未来的信息。
该模型生成文本的过程中,每次迭代不仅需要提供当前待预测位置前n个单词作为输入,还需要将模型在前一次迭代中生成的单词作为新的输入的一部分。
例如,假设我们想要使用LLama2模型生成一句话,设定n=3,即模型每次基于前3个单词预测下一个单词。生成过程如下:
-
初始输入:提供一个初始前缀,“今天天气”;模型接收到“今天天气”作为输入,预测下一个单词为“晴朗”。
-
第二次迭代:将前一次的预测结果加入到输入序列,形成新的输入:“今天天气晴朗”;模型接收到“今天天气晴朗”作为输入,预测下一个单词为“,”。
-
第三次迭代:将上一次预测的逗号“,”加入到输入序列中,形成新的输入:“今天天气晴朗,”;模型接收到“今天天气晴朗,”作为输入,预测下一个单词为“适合”。
-
后续迭代:以此类推,每次模型预测出一个单词后,都将该单词添加到输入序列中,继续预测下一个单词,直到达到预设的终止条件(如生成一定长度的文本、遇到特定结束符等)。
如下图所示。

相比之下,CV模型在进行图像分类、目标检测等任务时,通常只需要一次性接收整个图像作为输入,然后经过一次推理过程就得出最终结果,无需像llama2这样的语言模型这样进行多次迭代和递归预测。
处理流程
在深入理解LLama2模型结构之前,我们先回顾一下LLM的一般处理流程:
输入
LLM的输入数据通常是一段或多段自然语言文本,可以是一个简单的句子或一段话。文本被表示成单词或字符的序列。
❝[岱宗夫如何?齐鲁青未了。造化钟神秀,阴阳割昏晓。]
❞
tokenization
文本被切分为单词或字符,形成token序列。token序列进一步被序列化为列表或数组,并通过语料库进行索引化,将每个token映射到一个唯一的整数索引,便于模型内部计算。
❝序列化->
['BOS','岱','宗','夫','如','何','?','齐','鲁'...'阴','阳','割','昏','晓','EOS']
假设语料库索引化->
['BOS','10','3','67','89','21','45','55','61'...'7869','9','3452','563','56','EOS']
❞
Embedding
tokenization之后的文本信息变为数字形式的token序列,然后通过Embedding层将数字token映射为一个实数向量Embeding Vector。其中,每个token对应的向量通常具有固定的维度d(如50、100、300、768等),向量中的每个元素(实数)表示token在特定语义空间中的某个属性或特征。
具体来说,Embedding Vector可以表示为一个二维数组或矩阵,其形状与token序列长度相同,每个元素是一个固定维度的向量。这里假设使用一个维度为d=10的Embedding向量,则经过Embedding层后得到的向量表示如下:
'BOS'-> [p_{00},p_{01},p_{02},...,p_{09}]
'10' -> [p_{10},p_{11},p_{12},...,p_{09}]
'3' -> [p_{20},p_{21},p_{22},...,p_{09}]
...
'EOS'-> [p_{n0},p_{n1},p_{n2},...,p_{09}]
位置编码
位置编码(Positional Encoding)用于标识每个token在序列中的位置。让模型在处理不同位置的token时,能够区分它们的相对位置,并为模型提供上下文关系信息。
对于每个位置i,预先计算一个固定的位置向量pe_i,其维度与Embedding相同。在输入模型前,将每个token的Embedding与对应位置的PE相加,得到包含位置信息的token表示:
token_i_with_pe=Embedding_i+pe_i
其中,Embedding_i是第i个token的Embedding,pe_i是第i个位置的位置编码向量。二者相加如下:
[p_{00},p_{01},p_{02},...,p_{09}] [pe_{00},pe_{01},pe_{02},...,pe_{09}]
[p_{10},p_{11},p_{12},...,p_{09}] [pe_{10},pe_{11},pe_{12},...,pe_{09}]
[p_{20},p_{21},p_{22},...,p_{09}] + [pe_{20},pe_{21},pe_{22},...,pe_{09}]
... ...
[p_{n0},p_{n1},p_{n2},...,p_{09}] [pe_{n0},pe_{n1},pe_{n2} ,...,pe_{09}]
transformer
目前大语言模型都是基于transformer结构。在生成任务中,如文本生成、对话响应生成、摘要生成等,模型(比如GPT、llama)通常只使用Transformer架构中的Decoder部分,也就是所谓的Decoder-Only结构。
自回归生成
在生成输出序列任务中,使用自回归(Autoregressive)方式,即每次只生成一个token,并且这个token的生成依赖于之前已经生成的所有token。例如下面的代码:
# 定义使用的LLaMA2模型
model = LLaMA2()
# 定义自回归生成函数
def generate(inputs, n_tokens_to_generate):
# 自回归解码循环,迭代次数等于要生成的token数量
for _ in range(n_tokens_to_generate):
# 将当前输入传入模型进行前向传播
output = model(inputs)
# 使用贪婪采样(Greedy Sampling)策略,选取概率最高的token作为下一个预测结果
next = np.argmax(output[-1])
# 将预测的token添加到输入序列中,供下次迭代使用
inputs.append(next)
# 返回最后生成的n_tokens_to_generate个token
return inputs[len(inputs) - n_tokens_to_generate :]
# 给定初始输入,包含特殊token 'BOS' 和两个汉字 '岱' '宗'
input = [p0, p1, p2]
# 请求生成3个新token
output_ids = generate(input, 3) # 假设生成 ['p3','p4','p5']
# 将生成的token ID解码为实际字符
output_ids = decode(output_ids) # 通过tokenization解码
# 将解码后的token ID转换为词汇表中的词汇(此处假设vocab是一个字典)
output_tokens = [vocab[i] for i in output_ids] # 得到 '夫' '如' '何'
输出处理
生成的token序列通过一个输出层,将每个位置的概率分布转换为对应token的概率。根据概率,选择概率最高的token作为模型预测输出。
'''
从给定的概率分布中采样一个token,采用top-p策略
probs: 表示给定的概率分布
p: 表示概率阈值,在采样过程中,只保留累积概率小于p的部分
'''
def sample_top_p(probs, p):# 1.概率降序排序:对输入的 probs 张量按最后一个维度(即每个概率向量内部)进行降序排序probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True) #给定的概率降序排序# 2. 计算概率的累计和:对排序后的概率向量进行累计求和,得到一个新的张量,表示每个概率向量的累计概率probs_sum = torch.cumsum(probs_sort, dim=-1)# 3. 计算累积概率减去当前概率值是否大于p# 生成一个布尔型张量 mask,其中 True 表示该位置的累积概率减去当前概率值大于p,False则反之mask = probs_sum - probs_sort > p# 4. 在 probs_sort 张量中,将 mask 为 True 的位置(累积概率超过p 的部分)的值置为0。# 这样就实现了仅保留累积概率小于p的部分probs_sort[mask] = 0.0# 5. 归一化处理:对经过截断处理后的probs_sort张量进行归一化,使其概率总和为1# 使用 sum(dim=-1, keepdim=True) 计算每个概率向量的总和,并保持维度不变。然后进行元素级除法操作,使每个概率向量成为一个合法的概率分布。probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))# 6. 随机采样:进行一次随机抽样,得到一个形状为 (batch_size, 1) 的张量,表示每个批次数据采样到的 token 索引next_token = torch.multinomial(probs_sort, num_samples=1)# 7. 还原原始索引:根据next_token中的索引,从probs_idx中提取对应的原始索引next_token = torch.gather(probs_idx, -1, next_token)return next_token
模型结构
目前主流的LLM模型大多都是基于Transformer构建,llama2也不例外。LLM是根据给定输入文本序列的上下文信息预测下一个token,因此通常只需要Transformer Decoder部分。而Decoder与Encoder的本质区别就是在计算Q*V时引入Mask以确保当前位置只关注前面已经生成的内容。

llama2的模型结构与Transformer Decoder部分基本一致,主要由32个Transformer Block组成。

同时在Transformer Decoder基础上做了如下改进:
-
前置归一化,使用RMSNorm
-
Q与K相乘之前,使用旋转位置编码ROPE(Rotary Position Embeddings)
-
KV Cache,并采用Group Multi-Query Attention
-
Feed Forward SwiGLU
前置归一化-RMSNorm
「为什么要进行归一化?」
❝归一化(Normalization)是指将数据按照比例缩放,使其落入一个小的特定区间,通常是0-1,这样做有助于加快模型训练速度,提高模型性能。比如某模型训练场合,一些特征数值是远大于其他特征值的,像人的身高(eg:180cm)与体重(eg:75kg),这样直接训练,可能会影响损失函数梯度,导致优化过程困难,同时容易造成梯度消失或爆炸。
❞
前置归一化是指在每一层神经网络计算之前先进行归一化操作,与传统后置归一化(即在每一层计算之后进行归一化)相对。具体实现如下:
-
第一层归一化:先对输入进行归一化,再送入多头注意力层(Multi-Head Attention, MHA)进行计算。
-
第二层归一化:先对从MHA输出的特征进行归一化,然后再输入到全连接前馈神经网络(Feedforward Neural Network, FNN)进行计算。
-
残差连接:多头注意力层的原始输出会与经过第一层归一化后的输入相加,然后再输入到全连接层。
Transformer中的Normalization层一般都是采用LayerNorm来对Tensor进行归一化,LayerNorm的公式如下:
其中,
llama的前置归一化采用RMSNorm(Root Mean Square Normalization),省去了求均值的过程,也没有了偏置。
其中,是可学习的参数,且:
代码实现如下:
# RMSNorm
class RMSNorm(torch.nn.Module):
'''
RMSNorm:归一化
:param dim: int,待归一化的特征维度(通常是通道数)
:param eps: float,默认值为 1e-6,用于防止除法运算时分母过小导致数值不稳定
'''
def __init__(self, dim: int, eps: float = 1e-6):
# 初始化父类(即 torch.nn.Module)的属性和方法
super().__init__()
self.eps = eps # ε
# 初始值为全1向量
self.weight = nn.Parameter(torch.ones(dim)) #可学习参数γ
'''
_norm 是一个私有方法,仅在 RMSNorm 类内部使用
'''
def _norm(self, x):
# RMSNorm
'''
:param x: 待归一化的tensor,通常为模型某一层的输出,形状为 (batch_size, ..., dim)
'''
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
# 前向传播
# 返回经过标度的归一化张量作为RMSNorm层的输出
def forward(self, x):
# 将输入张量 x 转换为浮点类型(float),确保计算精度
# 调用私有方法 _norm 对 x 进行根均方归一化,得到归一化后的张量 output
# 将 output 的数据类型恢复为与输入 x 相同,以保持数据类型一致性
output = self._norm(x.float()).type_as(x)
# 将归一化后的张量 output 与可学习权重参数 self.weight 相乘,对归一化结果进行标度
return output * self.weight
其中,计算RMSNorm的具体步骤如下:
-
对输入x按照最后一个维度(即dim维)计算元素平方x.pow(2)。
-
在最后一个维度上计算平均值mean(-1),保留维度大小(keepdim=True),得到形状为 (batch_size, ..., 1) 的均方值向量。
-
向均方值向量中添加 eps 平滑项,避免除以过小的数值。
-
使用torch.rsqrt计算均方值向量的逆平方根,得到归一化因子。
-
将归一化因子逐元素与输入x相乘,完成根均方归一化RMSNorm计算。
RoPE-rotary positional embeddings
Transformer模型通常在输入序列经过Embedding层后只做一次位置编码,而lamma2模型选择在每个Attention层中分别对Query(Q)和Key(K)进行旋转位置编码(Rotary Positional Embedding, RoPE),即每次计算Attention时,都需要对当前层的Q和K进行位置编码。
RoPE是为了解决什么问题?用提出者苏大神的话来说,“就是'通过绝对位置编码的方式实现相对位置编码’,这样做既有理论上的优雅之处,也有实践上的实用之处,比如它可以拓展到线性Attention中就是主要因为这一点。”。
假设通过下述运算来给q,k添加绝对位置信息:
上述函数处理后,使得是带有位置m、n的绝对位置信息。
Attention的核心运算是内积,所以我们希望的内积的结果带有相对位置信息,因此假设存在恒等关系:
$$= g(x_m, x_n, m - n) $$
接下来的目标就是找到一个等价的位置编码方式,从而使得上述关系成立。
假定现在词嵌入向量的维度是两维d=2,这样就可以利用二维平面上的向量的几何性质,然后论文中提出了一个满足上述关系的f和g的形式如下:
乍一看挺复杂哈,怎么理解呢?
首先我们先回顾一下复数基础。f和g公式中都有一个指数函数,这不是欧拉公式么,x表示任意实数,e是自然对数的底数,i是复数中的虚数单位,则根据欧拉公式可知:
因而,上述指数函数可以表示为实部为cos(x),虚部为sin(x)的一个复数,从而建立了指数函数、三角函数和复数之间的桥梁。则:
此时再回看:
其中,是一个二维矩阵,是二维向量,二者相乘也是二维向量,用表示如下:
然后将表为复数形式:
接着,
其实就是两个复数相乘:
由复数的性质,且可以得到:
因此,
将结果重新表达成实数向量形式就是:
读到这里,我们就会发现,这不就是向量乘了一个旋转矩阵么!
「这也就是为什么叫做旋转式位置编码!!!」
同理可得向量:
最后还有个函数g:
其中,Re[x]表示一个复数x的实数部分,而表示复数的共轭,共轭复数的定义如下:
由此可得,
继而,
那么,你可能还有一个疑问,g函数是怎么来的呢?
首先回顾一下attention操作,位置m的query和位置n的key会做一个内积操作:
由三角函数性质:
由此可得,
这就证明上述关系是成立的,位置m的query和位置n的key的内积就是函数g。
如上推理证明是假设词嵌入是二维向量,对于d>=2的情况,则是将词嵌入向量元素按照两两分组,每组应用同样的旋转操作且每组旋转角度计算方式如下:
RoPE应用于Self-Attention操作的流程是:
-
对于输入的token序列,首先为每个词嵌入向量计算对应的q和k向量。
-
为每个token位置计算对应的旋转位置编码。
-
对每个token位置的q和k向量的元素进行两两一组的旋转变换。具体来说,将向量的每一组连续元素视为一个复数(实部和虚部),然后根据该位置的旋转角度对这个复数进行旋转操作。
-
对每个q向量与所有k向量的对应元素进行内积运算,得到注意力分数。
整个选择变换的过程如下图所示

代码实现如下:
# 计算词向量元素两两分组以后,每组元素对应的旋转角度
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):'''Precompute the frequency tensor for complex exponentials (cis) with given dimensions.This function calculates a frequency tensor with complex exponentials using the given dimension 'dim'and the end index 'end'. The 'theta' parameter scales the frequencies.The returned tensor contains complex values in complex64 data type.Args:dim (int): Dimension of the frequency tensor.end (int): End index for precomputing frequencies.theta (float, optional): Scaling factor for frequency computation. Defaults to 10000.0.Returns:torch.Tensor: Precomputed frequency tensor with complex exponentials.'''# dim = 128# end = 4096# torch.arange(0, dim, 2) [0, 2, 4, 6, 8, 10,..., 124, 126] 共64个# torch.arange(0, dim, 2)[: (dim // 2)] 保证是64个# 计算了从0到dim-1间隔为2的整数序列(共dim//2个元素),然后将这些整数除以 dim 并取指数,# 再除以 theta 的幂,以此得到一个表示频率的序列 freqsfreqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))# freqs = [1/10000.0^(0/128), 1/10000.0^(2/128), 1/10000.0^(4/128), ..., 1/10000.0^(126/128)]# 创建一个从0到end-1的整数序列tt = torch.arange(end, device=freqs.device) # type: ignore# t = [0, 1, 2, ..., 4095]# 计算t与freqs的外积,生成一个形状为 (end, dim//2)的张量,其中每一行对应一个时间步下的频率。将结果转换为浮点类型。freqs = torch.outer(t, freqs).float() # type: ignore# freqs 得到 freqs和t的笛卡尔积,维度为(4096,64)# freqs = [[0, 0, 0,..., 0],# [1/10000.0^(0/128), 1/10000.0^(2/128), 1/10000.0^(4/128), ..., 1/10000.0^(126/128)],# [2/10000.0^(0/128), 2/10000.0^(2/128), 2/10000.0^(4/128), ..., 2/10000.0^(126/128)],# ...,# [4095/10000.0^(0/128), 4095/10000.0^(2/128), 4095/10000.0^(4/128), ..., 4095/10000.0^(126/128)]]# 使用 torch.polar 函数将形状为 (end, dim//2) 的全1张量与 freqs 作为输入,# 生成形状相同的复数张量 freqs_cis。复数张量的模为1,幅角为 freqs 中的值。数据类型为 complex64freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64# freqs_cis的维度为(4096,64),相当于半径为1,角度为freqs的极坐标的复数表示return freqs_cis# 重塑freqs_cis形状
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):'''Reshape frequency tensor for broadcasting it with another tensor.This function reshapes the frequency tensor to have the same shape as the target tensor 'x'for the purpose of broadcasting the frequency tensor during element-wise operations.Args:freqs_cis (torch.Tensor): Frequency tensor to be reshaped.x (torch.Tensor): Target tensor for broadcasting compatibility.Returns:torch.Tensor: Reshaped frequency tensor.Raises:AssertionError: If the frequency tensor doesn't match the expected shape.AssertionError: If the target tensor 'x' doesn't have the expected number of dimensions.'''# freqs_cis.shape = [1024, 64]# x.shape = [2, 1024, 32, 64]# 获取x的维度数ndim# 并检查freqs_cis的形状是否与x的第二个维度(索引为1)和最后一个维度(索引为 ndim-1)相匹配ndim = x.ndim# 断言条件 0 <= 1 < ndim,确保第二个维度(索引为1)存在且有效。此处断言意义不大,因为已知 ndim 至少为2,该条件始终成立assert 0 <= 1 < ndim# 断言 freqs_cis.shape == (x.shape[1], x.shape[-1]),# 即 freqs_cis 的形状应与 x 的第二个维度(序列长度)和最后一个维度(词向量两两分组后的维度)相匹配assert freqs_cis.shape == (x.shape[1], x.shape[-1])# 将freqs_cis.shape变为[1, 1024, 1, 64]# 创建一个列表shape,其元素基于 x 的原始形状# 对于x的每个维度,若索引为1(对应序列长度)或 ndim - 1(对应词向量两两分组后的维度),则保留原维度大小;# 否则,设置为1。# 这样构造出的 shape 如注释所示,形如 [1, x.shape[1], 1, x.shape[-1]]shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]# 对 freqs_cis 进行重塑,使其形状符合 shape 中指定的格式return freqs_cis.view(*shape)# 对给定的查询张量 xq 和关键张量 xk 应用旋转嵌入(Rotary Embeddings)
def apply_rotary_emb(xq: torch.Tensor,xk: torch.Tensor,freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:'''Apply rotary embeddings to input tensors using the given frequency tensor.This function applies rotary embeddings to the given query 'xq' and key 'xk' tensors using the providedfrequency tensor 'freqs_cis'. The input tensors are reshaped as complex numbers, and the frequency tensoris reshaped for broadcasting compatibility. The resulting tensors contain rotary embeddings and arereturned as real tensors.Args:xq (torch.Tensor): Query tensor to apply rotary embeddings.xk (torch.Tensor): Key tensor to apply rotary embeddings.freqs_cis (torch.Tensor): Precomputed frequency tensor for complex exponentials.Returns:Tuple[torch.Tensor, torch.Tensor]: Tuple of modified query tensor and key tensor with rotary embeddings.'''# 将xq和xk的最后一个维度进行复数运算,得到新的xq和xk# 为了进行复数运算,需要将xq和xk的最后一个维度展开为2维# 例如,xq的形状为[2, seq_len, 32, 128], reshape后为[2, seq_len, 32 , 64, 2]# view_as_complex函数可以将张量中的最后一维的两个元素作为实部和虚部合成一个复数xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))# 将freqs_cis广播到xq和xk的最后一个维度freqs_cis = reshape_for_broadcast(freqs_cis, xq_)# freqs_cis.shape = [1, 1024, 1, 64]# view_as_real和view_as_complex相反,可以将张量中最后一维的复数拆出实部和虚部# (xq_ * freqs_cis).shape = [2, seq_len, 32 , 64]# torch.view_as_real(xq_ * freqs_cis).shape = [2, seq_len, 32 , 64, 2]# flatten(3)将张量展平为[2, seq_len, 32 , 128],3代表从的第3个维度开始展平xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)return xq_out.type_as(xq), xk_out.type_as(xk)
Attention
这部分简言之就是Transform经典的Multi-headed Self-attention,然后融合了一些模型并行机制(这个在后面梳理)。此外为了加速模型训练和推理过程,还用到了KV Cache和GQA。
KV Cache
大模型推理性能优化的一个常用技术是KV Cache,那么什么是KV Cache呢?
-
K: 在Transformer模型的自注意力机制中,每个输入位置(通常是一个词向量或子词向量)会被映射成三个向量:Query(Q)、Key(K)和Value(V)。Key向量用于衡量一个位置与其他所有位置之间的关联性,通常通过计算Query与各个Key的点积或相似度得分来确定注意力权重。
-
V: Value向量包含了每个位置的有用信息,根据注意力权重进行加权求和,以此来聚合全局信息,生成对当前位置的上下文感知表示。
-
Cache: 在自回归生成任务中,模型需要逐个生成序列中的tokens,每次生成一个新token时,都会更新输入序列并重新计算自注意力。然而,已生成的部分(历史tokens)对应的Key和Value向量在生成后续token时往往保持不变或变化较小。KV Cache正是利用了这一性质,通过将这些历史tokens对应的Key和Value向量「存储起来(缓存)」,在后续计算中直接复用,而不是每次都重新计算。

举个例子,假设有这样一个生成任务:
In [1]: {prompt:'岱宗夫如何?齐鲁青未了。造化钟神秀,阴阳割昏晓。'}
Out [1]: 岱宗夫如何?齐
In [2]: 岱宗夫如何?齐
Out [2]: 岱宗夫如何?齐鲁
In [3]: 岱宗夫如何?齐鲁
Out [3]: 岱宗夫如何?齐鲁青
In [4]: 岱宗夫如何?齐鲁青
Out [4]: 岱宗夫如何?齐鲁青未
In [5]: 岱宗夫如何?齐鲁青未
Out [5]: 岱宗夫如何?齐鲁青未了
而第四次的处理过程是用'岱宗夫如何?齐鲁青' 来预测下一个'未'字,所以需要把'岱宗夫如何?齐鲁青'进行token化后再进行Attention计算,即,如下图所示。

不难发现在第三次处理的时候,就已经把'岱宗夫如何?齐鲁'所对应的Q,K,V向量进行了运算,所以没必要再对他们进行Attention计算,这样就能节省大部分算力,由此KV Cache便是来解决这个问题的:通过将每次计算的K和V缓存下来,之后新的序列进来时只需要从KV Cache中读取之前的KV值即可,就不需要再去重复计算之前的KV了。此外,对于Q也不用将序列对应的所有都计算出来,只需要计算最新的,(即此时句子长度为1), K V同理,所以我们用简易代码描述一下这个过程就是:
def mha(x, c_attn, c_proj, n_head, kvcache=None): # [n_seq, n_embd] -> [n_seq, n_embd]# qkv projection# when we pass kvcache, n_seq = 1. so we will compute new_q, new_k and new_vx = linear(x, **c_attn) # [n_seq, n_embd] -> [n_seq, 3*n_embd]# split into qkvqkv = np.split(x, 3, axis=-1) # [n_seq, 3*n_embd] -> [3, n_seq, n_embd]if kvcache:# qkvnew_q, new_k, new_v = qkv # new_q, new_k, new_v = [1, n_embd]old_k, old_v = kvcachek = np.vstack([old_k, new_k]) # k = [n_seq, n_embd], where n_seq = prev_n_seq + 1v = np.vstack([old_v, new_v]) # v = [n_seq, n_embd], where n_seq = prev_n_seq + 1qkv = [new_q, k, v]
那么为什么不用缓存Q呢?我理解的这是一种单向注意力机制,只管每次进来的token和past tokens的注意力,而past tokens不会管后面token的注意力,所以不需要,也就不需要缓存Q。
MQA & GQA
但是,如上面所述,K、V真的能缓存了吗?
以llama7B模型为例,hidden_size为4096,也就是每个K、V有4096个数据,假设半精度浮点数数据float16,一个Transformer Block中就有409622=16KB的单序列KV缓存空间,而llama2一共32个Transformer Block,所以单序列整个模型需要16*32=512KB的缓存空间,那多序列呢?如果此时句子长度为1024,那就得512MB的缓存空间了。而现在英伟达最好的卡H100的SRAM缓存大概是50MB,A100则是40MB. 7B模型都这样,175B模型就更不用说了。
既然SRAM放不下,我们放到DRAM(GPU显存)行不行呢?答案是可以,但要牺牲性能。我们知道全局内存(GPU)的读写速度要要远低于共享内存和寄存器,由此便会导致一个问题: Memory Wall(内存墙)。所谓内存墙简单点说就是你处理器ALU太快,但是你内存读写速度太慢跟不上,这就会导致ALU算晚之后在那等着你数据搬运过来,进而影响性能。
那么该如何解决呢?
「硬件层面」:可以使用HBM(High Bandwidth Memory,高速带宽内存)提高读取速度,或者抛弃冯诺依曼架构,改变计算单元从内存读数据的方式,不再以计算单元为中心,而以存储为中心,做成计算和存储一体的“存内计算”,比如'忆阻器'。
「软件层面」:就是优化算法,由此便引入了llama2所使用的GQA (Group Query Attention)。
如下图所示。多头注意力机制MHA就是多个头各自拥有自己的Q,K,V来计算各自的self-attention。而MQA(Multi Query Attention)就是Q依然保持多头,但是K,V只有一个,所有多头的Q共享一个K,V ,这样做虽然能最大程度减少KV Cache所需的缓存空间,但是可想而知参数的减少意味着精度的下降,所以为了在精度和计算之间做一个trade-off,GQA (Group Query Attention)应运而生,即Q依然是多头,但是分组共享K,V,既减少了K,V缓存所需的缓存空间,也暴露了大部分参数不至于精度损失严重。

代码实现如下。
'''
将key和value的head维度重复n_rep次,以匹配query的head数
'''
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
'''torch.repeat_interleave(x, dim=2, repeats=n_rep)'''
bs, slen, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (
x[:, :, :, None, :]
# 将输入张量在第四个维度上扩展 n_rep 次
.expand(bs, slen, n_kv_heads, n_rep, head_dim)
# 调整为适当的形状
.reshape(bs, slen, n_kv_heads * n_rep, head_dim)
)
class Attention(nn.Module):
'''Multi-head attention module.'''
def __init__(self, args: ModelArgs):
'''
Initialize the Attention module.
Args:
args (ModelArgs): Model configuration parameters.
Attributes:
n_kv_heads (int): Number of key and value heads.
n_local_heads (int): Number of local query heads.
n_local_kv_heads (int): Number of local key and value heads.
n_rep (int): Number of repetitions for local heads.
head_dim (int): Dimension size of each attention head.
wq (ColumnParallelLinear): Linear transformation for queries.
wk (ColumnParallelLinear): Linear transformation for keys.
wv (ColumnParallelLinear): Linear transformation for values.
wo (RowParallelLinear): Linear transformation for output.
cache_k (torch.Tensor): Cached keys for attention.
cache_v (torch.Tensor): Cached values for attention.
'''
# ColumnParallelLinear是一个在大规模并行训练中使用的术语,特别是在训练大型的深度学习模型,
# 如Transformer模型时。在模型并行训练中,一个大型的矩阵(例如神经网络的权重矩阵)会被分割成不同的列,
# 并分散到不同的计算设备(如GPU)上。
#
# 在ColumnParallelLinear的情况下,每个计算设备存储权重矩阵的一部分列,而不是整个矩阵。
# 每个设备计算它自己的前向传播部分,并将结果发送给其他设备以进行进一步的处理或合并结果。
# 对于反向传播和梯度计算,每个设备计算其自己列的梯度,并可能需要与其他设备交换信息以更新权重。
#
# 这种方式可以显著减少每个设备上的内存需求,并允许训练更大的模型,因为模型的不同部分可以分布在多个设备上。
# ColumnParallelLinear和RowParallelLinear(另一种将权重矩阵按行划分的方法)是实现模型并行的两种常见策略。
super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
model_parallel_size = fs_init.get_model_parallel_world_size()
#Q的头数
self.n_local_heads = args.n_heads // model_parallel_size
#KV的头数
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = args.dim // args.n_heads
# Q的头数* head_dim
self.wq = ColumnParallelLinear(args.dim,args.n_heads * self.head_dim,bias=False,gather_output=False,
init_method=lambda x: x,)
# K的头数* head_dim
self.wk = ColumnParallelLinear(args.dim,self.n_kv_heads * self.head_dim,bias=False, gather_output=False,
init_method=lambda x: x,)
# V的头数* head_dim
self.wv = ColumnParallelLinear(args.dim,self.n_kv_heads * self.head_dim,bias=False,gather_output=False,init_method=lambda x: x,)
self.wo = RowParallelLinear(args.n_heads * self.head_dim,args.dim,bias=False,input_is_parallel=True,init_method=lambda x: x,)
# kv_cache是缓存键值对,在训练过程中,我们只保存最近n个键值对
self.cache_k = torch.zeros((args.max_batch_size,args.max_seq_len,self.n_local_kv_heads,self.head_dim,)).cuda()
self.cache_v = torch.zeros((args.max_batch_size,args.max_seq_len,self.n_local_kv_heads,self.head_dim,)).cuda()
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
'''
Forward pass of the attention module.
Args:
x (torch.Tensor): Input tensor.
start_pos (int): Starting position for caching.
freqs_cis (torch.Tensor): Precomputed frequency tensor.
mask (torch.Tensor, optional): Attention mask tensor.
Returns:
torch.Tensor: Output tensor after attention.
'''
# 假设当前x为(1, 1, dim),也就是上一个预测的token
# self-attention的输入,标准的(bs, seqlen, hidden_dim)
bsz, seqlen, _ = x.shape
# 计算当前token的qkv
# q k v分别进行映射,注意这里key, value也需要先由输入进行映射再和kv_cache里面的key, value进行拼接
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
# 对当前输入的query和key进行RoPE,注意kv_cache里面的key已经做过了RoPE
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
# 缓存当前token的kv
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos: start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos: start_pos + seqlen] = xv
# 取出前seqlen个token的kv缓存
# 取出全部缓存的key和value(包括之前在cache里面的和本次输入的),作为最终的key和value
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
# 将kv重复填充,使kv和q的头数个数相同
# repeat k/v heads if n_kv_heads < n_heads,对齐头的数量
# 读取新进来的token所计算得到的k和v
keys = repeat_kv(keys, self.n_rep) # (bs, cache_len + seqlen, n_local_heads, head_dim)
values = repeat_kv(values, self.n_rep) # (bs, cache_len + seqlen, n_local_heads, head_dim)
# 计算当前token的attention score,,注意mask需要加上,另外维度要对应上
xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)
keys = keys.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)
values = values.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)
#计算q*k
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
#加入mask,使得前面的token在于后面的token计算attention时得分为0,mask掉
scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
return self.wo(output)
「参数之间关系理解」
n_heads是注意力头的总个数,由于并行机制,每个进程会有n_local_heads个注意力头。由于计算当前位置的Attention Score依赖于之前所有的kv,因此需要将kv缓存下来。为了减少空间复杂度,可以对kv的头个数n_kv_heads进行调整,这个值一般小于等于n_heads,n_heads是n_kv_heads的整数倍,这个倍数也就是n_rep。相应的,每个进程会有n_local_kv_heads个注意力头。每个头的维度为head_dim=dim//n_heads。
例如:n_heads=32,model_parallel_size(并行数量)= 4,n_kv_heads = 8,n_local_heads = 32/4, n_local_kv_heads = 8/4,n_rep = 32/8。

FeedForward
与标准的Transformer一样,经过Attention层之后就进行FeedForward层的处理llama2采用的是SwiGLU(SiLU)激活函数。
class FeedForward(nn.Module):def __init__(self,dim: int,hidden_dim: int,multiple_of: int,ffn_dim_multiplier: Optional[float],):super().__init__()hidden_dim = int(2 * hidden_dim / 3)# custom dim factor multiplierif ffn_dim_multiplier is not None:hidden_dim = int(ffn_dim_multiplier * hidden_dim)hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)# Linear 1self.w1 = ColumnParallelLinear(...)# Linear 2self.w2 = RowParallelLinear(...)# Linear 3self.w3 = ColumnParallelLinear(...)def forward(self, x):return self.w2(F.silu(self.w1(x)) * self.w3(x))
Transformer Block
前面是将llama2 Transformer Block中的每一个小组件分别梳理了一下,接下来将他们按照一定的顺序和位置拼接即可组成llama2网络结构中的一层Transformer,也称Decoder Layer。

代码实现如下:
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
'''
Initialize a TransformerBlock.
Args:
layer_id (int): Identifier for the layer.
args (ModelArgs): Model configuration parameters.
Attributes:
n_heads (int): Number of attention heads.
dim (int): Dimension size of the model.
head_dim (int): Dimension size of each attention head.
attention (Attention): Attention module.
feed_forward (FeedForward): FeedForward module.
layer_id (int): Identifier for the layer.
attention_norm (RMSNorm): Layer normalization for attention output.
ffn_norm (RMSNorm): Layer normalization for feedforward output.
'''
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = Attention(args)
self.feed_forward = FeedForward(
dim=args.dim,
hidden_dim=4 * args.dim,
multiple_of=args.multiple_of,
ffn_dim_multiplier=args.ffn_dim_multiplier,
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
'''
Perform a forward pass through the TransformerBlock.
Args:
x (torch.Tensor): Input tensor.
start_pos (int): Starting position for attention caching.
freqs_cis (torch.Tensor): Precomputed cosine and sine frequencies.
mask (torch.Tensor, optional): Masking tensor for attention. Defaults to None.
Returns:
torch.Tensor: Output tensor after applying attention and feedforward layers.
'''
h = x + self.attention.forward(
self.attention_norm(x), start_pos, freqs_cis, mask
)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
相关文章:
一文看懂llama2(原理模型训练)
自从Transformer架构问世以来,大型语言模型(Large Language Models, LLMs)以及AIGC技术的发展速度惊人,它们不仅在技术层面取得了重大突破,还在商业应用、社会影响等多个层面展现出巨大潜力。随着ChatGPT的推出&#x…...

Sui基金会公布2024年3–4月资助项目名单
Sui基金会宣布3月和4月的资助项目名单,在这两个月中,共有10个项目获得了资助,以加速Sui的整合和发展。其中有八个项目专注于为开发者创造更好的体验,从开发强大的集成开发环境(IDE)到使用零知识证明保护用户…...

Spring Security3.0.1版本
前言: 抽象Spring Security3.0上一篇 在上一篇中,我们完成了对Security导入,快速入门,和对自动配置的简单验证 对登录流程的分析和Security基本原理 补充: 先解决上一篇留下的问题,端口和端点的区别 端…...
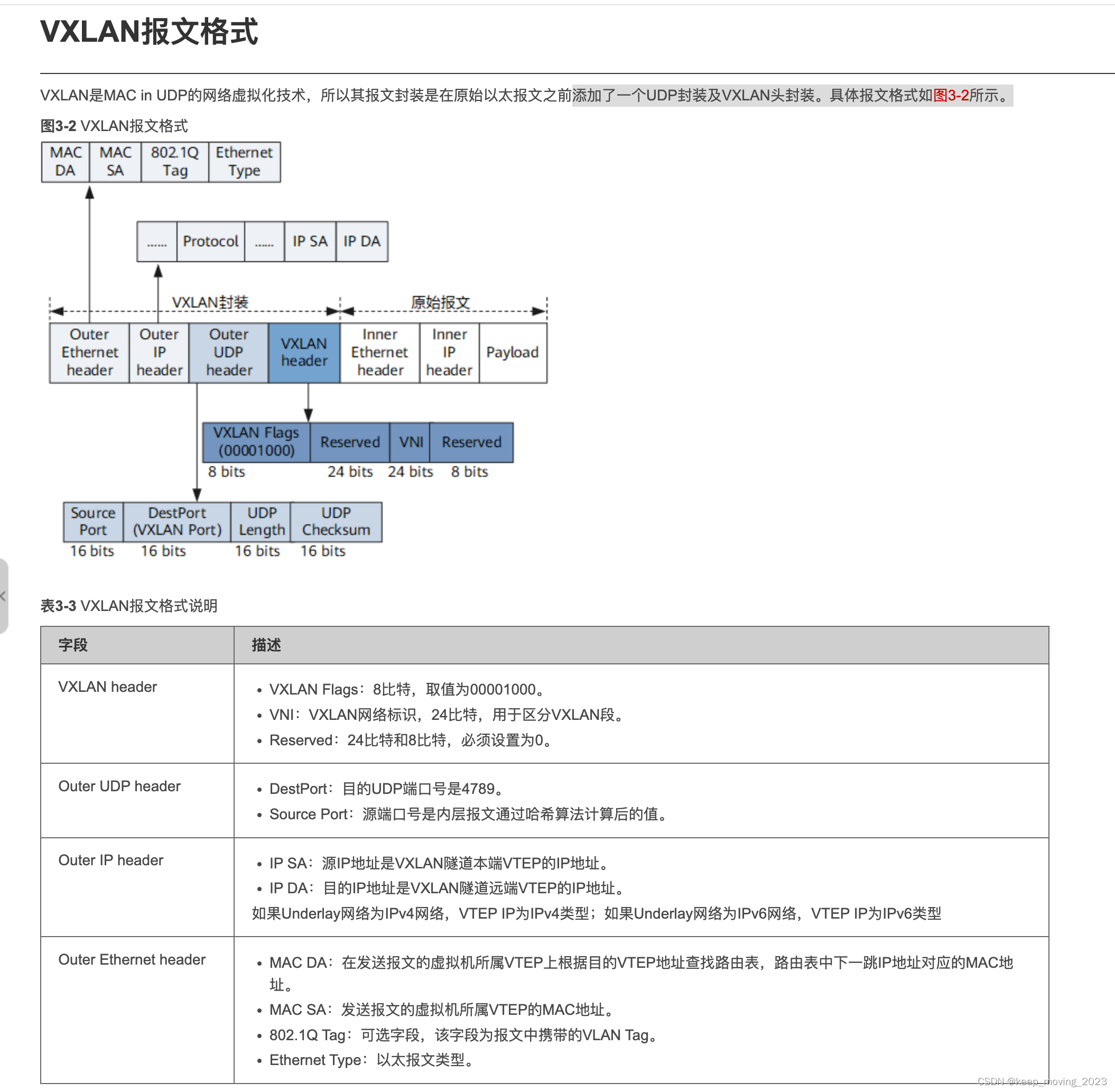
网络报文协议头学习
vxlan:就是通过Vxlan_header头在原始报文前面套了一层UDPIP(4/6)Eth_hdr 需求背景:VXLAN:简述VXLAN的概念,网络模型及报文格式_vxlan报文格式-CSDN博客 如果服务器作为VTEP,那从服务器发送到接…...

颜色与纹理
1 将非坐标数据传入顶点着色器 当执行gl.drawArrays()函数时,存储在缓冲区对象中的数据将按照其在缓冲区中的顺序依次传给对应的attribute变量。在顶点着色器中,我们将这两个attribute变量分别赋值给的gl_Position和gl_PointSize,就在指定的位置绘制出指定大小的点了。 1.…...

pytest-playwright 插件的使用
引言 在自动化测试领域,Playwright 是一个强大的工具,它支持 Chromium、Firefox 和 WebKit 三大浏览器引擎。Playwright 提供了与 Pytest 集成的插件,使得编写端到端测试变得更加简单和高效。本文将介绍如何使用 Pytest Playwright 插件来编…...
基于springboot实现智慧校园之家长子系统项目【项目源码】计算机毕业设计
基于springboot实现智慧校园之家长子系统演示 SpringBoot框架介绍 本课题程序开发使用到的框架技术,英文名称缩写是SpringBoot,在JavaWeb开发中使用的流行框架有SSH、SpringBoot、SpringMVC等,作为一个课题程序采用SSH框架也可以,…...

云WAF的安全审计功能
云WAF(Cloud Web Application Firewall)是一种部署在云端的专业网络安全解决方案,它为Web应用程序提供强力的保护,通过检测和阻止恶意流量、攻击和漏洞,确保Web应用程序的安全性和可用性。在安全审计方面,云…...

第十七章 创建Web客户端 - 其他调整
文章目录 第十七章 创建Web客户端 - 其他调整其他调整使用生成的 Web 客户端类示例 1:使用使用包装消息的客户端示例 2:使用使用未包装消息的客户端 第十七章 创建Web客户端 - 其他调整 其他调整 如果 WSDL 未指定 Web 服务的位置,则 SOAP …...

学习java的日子 Day52 多表联合查询,DCL,数据类型,约束,索引,视图
Day52 1.DML-多表联合查询(重要) 1.1 一对一情况 略 1.2 一对多情况 当需要查询多个表中的字段时,就可以使用表连接来实现。表联接分为内连接和外连接 内连接:将两个表中存在联结关系的字段符合联结关系的那些记录形成记录集的联结 外连接:…...
的教程、相关项目)
计算机视觉(CV)的教程、相关项目
计算机视觉(CV)是一个广泛而深入的领域,其教程和项目众多。以下是针对计算机视觉(CV)的教程和相关项目的一个清晰概述: 教程 入门教程: OpenCV入门:OpenCV是一个开源的计算机视觉库,提供了大量用于图像和视频处理的函数。可以通过OpenCV的官方文档或在线教程来学习其…...
方法的使用))
mysql in 逗号分隔_数据库字段是逗号分隔的查询(FIND_IN_SET(str,strlist)方法的使用)
使用函数FIND_IN_SET(str,strlist)--(推荐) 函数介绍:返回在strlist中str字符串通过“,”分隔成列表后所在的位置(索引),如 SELECT FIND_IN_SET("c", "a,b,c,d,e"); 返回3(索引从1开始) 有了这个方法再回到之前的sql语句可以变成如下: select name,bra…...

【Python】 将日期转换为 datetime 对象在 Python 中
基本原理 在 Python 中,处理日期和时间的库是 datetime,它提供了广泛的功能来处理日期和时间。datetime 模块中有一个 datetime 类,它可以用来表示日期和时间。有时,我们可能会遇到需要将日期字符串转换为 datetime 对象的情况&a…...

dpdk-19.11 arm64 环境适配 Mellanox CX4 网卡
环境信息 cpu: arm64 架构 dpdk 版本:19.11 glibc 版本:2.17 网卡型号: Mellanox CX4 网卡,详细 pci 信息如下: 02:00.0 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx] 02:00.1 Ether…...

1141. 查询近30天活跃用户数
1141. 查询近30天活跃用户数 题目链接:1141. 查询近30天活跃用户数 代码如下: # Write your MySQL query statement below select activity_date as day,count(distinct user_id) as active_users from Activity where activity_date between 2019-06-…...
11_JavaWeb监听器
文章目录 监听器1.监听器的分类2.application域监听器案例 监听器 概念:后端要发生一些事情的时候,自动触发一些代码的执行; 1.监听器的分类 web中定义八个监听器接口作为监听器的规范,这八个接口按照不同的标准可以形成不同的分类 按监听的…...

jmeter常用的断言
包括(Contains):响应内容包括需要匹配的内容即代表响应成功,支持正则表达式 匹配(Matches):响应内容要完全匹配需要匹配的内容即代表响应成功,大小写不敏感,支持正则表达…...

Opencv Python图像处理笔记二:图像变换、卷积、形态学变换
文章目录 前言一、几何变换1.1 缩放1.2 平移1.3 旋转1.4 翻转1.5 仿射1.6 透视 二、低通滤波2.1 均值滤波2.2 高斯滤波2.3 中值滤波2.4 双边滤波2.5 自定义滤波 三、高通滤波3.1 Sobel3.2 Scharr3.3 Laplacian3.4 Canny 四、图像金字塔4.1 高斯金字塔4.2 拉普拉斯金字塔 五、形…...
)
使用若依框架RuoYi前后端分离版+运行+自动生成页面进行导入进行开发+工具(完整版)
若依后台预览 摘要: 随着前后端分离开发模式的流行,越来越多的开发者开始将项目的前端和后端分离开发,以提高开发效率和项目的灵活性。若依框架作为一款优秀的开源后台管理系统,提供了强大的权限管理和代码生成功能,非常适合前后端分离开发。 一、若依框架介绍 若依框架…...

开源博客项目Blog .NET Core源码学习(29:App.Hosting项目结构分析-17)
本文学习并分析App.Hosting项目中后台管理页面的按钮管理页面。 按钮管理页面用于显示、新建、编辑、删除页面按钮数据,以便配置后台管理页面中每个页面的工具栏、操作栏、数据列中的按钮的事件及响应url。按钮管理页面附带一新建及编辑页面,以支撑新…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...

系统掌握PyTorch:图解张量、Autograd、DataLoader、nn.Module与实战模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程&#…...