Pytorch优化器Optimizer
优化器Optimizer
什么是优化器
pytorch的优化器:管理并更新模型中可学习参数的值,使得模型输出更接近真实标签
导数:函数在指定坐标轴上的变化率
方向导数:指定方向上的变化率(二元及以上函数,偏导数)
梯度:一个向量,方向是使得方向导数取得最大值的方向
Pytorch的Optimizer

参数
- defaults:优化器超参数
- state:参数的缓存,如momentum的缓存
param_groups:管理的参数组- _step_count:记录更新次数,学习率调整中使用
基本方法:
- zero_grad():清空所管理参数的梯度

pytorch特性:张量梯度不会自动清零
-
step():执行一步更新
-
add_param_group():添加参数组

-
state_dict():获取优化器当前状态信息字典

-
load_state_dict():加载状态信息字典
使用代码帮助理解和学习
import os
import torch
import torch.optim as optimBASE_DIR = os.path.dirname(os.path.abspath(__file__))weight = torch.randn((2, 2), requires_grad=True)
weight.grad = torch.ones((2, 2))# 需要传入一个可迭代对象
optimizer = optim.SGD([weight], lr=1)print("weight before step:{}".format(weight.data))
optimizer.step()
print("weight after step:{}".format(weight.data))weight before step:tensor([[-0.0606, -0.3197],[ 1.4949, -0.8007]])
weight after step:tensor([[-1.0606, -1.3197],[ 0.4949, -1.8007]])weight = weight - lr * weight.grad
上面学习率是1,把学习率改为0.1试一下
optimizer = optim.SGD([weight], lr=0.1)weight before step:tensor([[ 0.3901, 0.2167],[-0.3428, -0.7151]])
weight after step:tensor([[ 0.2901, 0.1167],[-0.4428, -0.8151]])
接着上面的代码,我们再看一下add_param_group方法
# add_param_group方法
print("optimizer.param_groups is \n{}".format(optimizer.param_groups))w2 = torch.randn((3, 3), requires_grad=True)
optimizer.add_param_group({"params": w2, "lr": 0.0001})
print("optimizer.param_groups is\n{}".format(optimizer.param_groups))optimizer.param_groups is
[{'params': [tensor([[ 0.1749, -0.2018],[ 0.0080, 0.3517]], requires_grad=True)], 'lr': 0.1, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}]optimizer.param_groups is
[{'params': [tensor([[ 0.1749, -0.2018],[ 0.0080, 0.3517]], requires_grad=True)], 'lr': 0.1, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}, {'params': [tensor([[ 0.4538, -0.8521, -1.3081],[-0.0158, -0.2708, 0.0302],[-0.3751, -0.1052, -0.3030]], requires_grad=True)], 'lr': 0.0001, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}]关于zero_grad()、step()、state_dict()、load_state_dict()这几个方法比较简单就不再赘述。
SGD随机梯度下降
learning_rate学习率

这里学习率为1,可以看到并没有达到梯度下降的效果,反而y值越来越大,这是因为更新的步伐太大。

我们以y = 4*x^2这个函数举例,将y值作为要优化的损失值,那么梯度下降的过程就是为了找到y的最小值(即此函数曲线的最小值);如果我们把学习率设置为0.2,就可以得到这样一个梯度下降的图
def func(x):return torch.pow(2*x, 2)x = torch.tensor([2.], requires_grad=True)
iter_rec, loss_rec, x_rec = list(), list(), list()
lr = 0.2
max_iteration = 20for i in range(max_iteration):y = func(x)y.backward()print("iter:{}, x:{:8}, x.grad:{:8}, loss:{:10}".format(i, x.detach().numpy()[0], x.grad.detach().numpy()[0], y.item()))x_rec.append(x.item())x.data.sub_(lr * x.grad)x.grad.zero_()iter_rec.append(i)loss_rec.append(y.item())plt.subplot(121).plot(iter_rec, loss_rec, '-ro')
plt.xlabel("Iteration")
plt.ylabel("Loss value")x_t = torch.linspace(-3, 3, 100)
y = func(x_t)
plt.subplot(122).plot(x_t.numpy(), y.numpy(), label="y = 4*x^2")
plt.grid()y_rec = [func(torch.tensor(i)).item() for i in x_rec]
plt.subplot(122).plot(x_rec, y_rec, '-ro')
plt.legend()
plt.show()

这里其实存在一个下降速度更快的学习率,那就是0.125,一步就可以将loss更新为0,这是因为我们已经了这个函数表达式,而在实际神经网络模型训练的过程中,是不知道所谓的函数表达式的,所以只能选取一个相对较小的学习率,然后以训练更多的迭代次数来达到最优的loss。

动量(Momentum,又叫冲量)
结合当前梯度与上一次更新信息,用于当前更新
为什么会出现动量这个概念?
当学习率比较小时,往往更新比较慢,通过引入动量,使得后续的更新受到前面更新的影响,可以更快的进行梯度下降。
指数加权平均:当前时刻的平均值(Vt)与当前参数值(θ)和前一时刻的平均值(Vt-1)的关系。

根据上述公式进行迭代展开,因为0<β<1,当前时刻的平均值受越近时刻的影响越大(更近的时刻其所占的权重更高),越远时刻的影响越小,我们可以通过下面作图来看到这一变化。
import numpy as np
import matplotlib.pyplot as pltdef exp_w_func(beta, time_list):return [(1-beta) * np.power(beta, exp) for exp in time_list]beta = 0.9
num_point = 100
time_list = np.arange(num_point).tolist()weights = exp_w_func(beta, time_list)plt.plot(time_list, weights, '-ro', label="Beta: {}\n = B * (1-B)^t".format(beta))
plt.xlabel("time")
plt.ylabel("weight")
plt.legend()
plt.title("exponentially weighted average")
plt.show()

这里β是一个超参数,设置不同的值,其对于过去时刻的权重计算如下图
beta_list = [0.98, 0.95, 0.9, 0.8]
w_list = [exp_w_func(beta, time_list) for beta in beta_list]
for i, w in enumerate(w_list):plt.plot(time_list, w, label="Beta: {}".format(beta_list[i]))plt.xlabel("time")plt.ylabel("weight")
plt.legend()
plt.show()

从图中可以得到这一结论:β值越小,记忆周期越短,β值越大,记忆周期越长。
pytorch中带有momentum参数的更新公式

对于y=4*x^2这个例子,在没有momentum时,我们对比学习率分别为0.01和0.03会发现,0.03收敛的更快。

如果我们给learning_rate=0.01增加momentum参数,会发现其可以先一步0.03的学习率到达loss的较小值,但是因为动量较大的因素,在达到了最小值后还会反弹到一个大的值。

Pytorch中的优化器
optim.SGD
主要参数:
params:管理的参数组lr:学习率- momentum:动量系数,贝塔
weight_decay:L2正则化系数nesterov:是否采用NAG,默认False
optim.Adagrad:自适应学习率梯度下降法
optim.RMSprop:Adagrad的改进
optim.Adadelta:Adagrad的改进
optim.Adam:RMSprop结合Momentum
optim.Adamax:Adam增加学习率上限
optim.SparseAdam:稀疏版的Adam
optim.ASGD:随机平均梯度下降
optim.Rprop:弹性反向传播
optim.LBFGS:BFGS的改进
学习率调整
前期学习率大,后期学习率小
pytorch中调整学习率的基类
class _LRScheduler
主要属性:
- optimizer:关联的优化器
- last_epoch:记录epoch数
base_lrs:记录初始学习率
主要方法:
- step():更新下一个epoch的学习率
get_lr():虚函数,计算下一个epoch的学习率
StepLR
等间隔调整学习率
主要参数:
- step_size:调整间隔数
- gamma:调整系数
调整方式:lr = lr * gamma
import torch
import torch.optim as optim
import matplotlib.pyplot as pltLR = 0.1
iteration = 10
max_epoch = 200weights = torch.randn((1,), requires_grad=True)
target = torch.zeros((1, ))optimizer = optim.SGD([weights], lr=LR, momentum=0.9)scheduler_lr = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1) # 设置学习率下降策略lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):lr_list.append(scheduler_lr.get_lr())epoch_list.append(epoch)for i in range(iteration):loss = torch.pow((weights-target), 2)loss.backward()optimizer.step()optimizer.zero_grad()scheduler_lr.step()plt.plot(epoch_list, lr_list, label='Step LR Scheduler')
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.legend()
plt.show()
MultiStepLR
功能:按给定间隔调整学习率
主要参数:
- milestones:设定调整时刻数
- gamma:调整系数
调整方式:lr = lr * gamma
# MultiStepLR
milestones = [50, 125, 160]
scheduler_lr = optim.lr_scheduler.MultiStepLR(optimizer, milestones=milestones, gamma=0.1)只需要改变这里代码,其他部分与StepLR中基本一致

ExponentialLR
功能:按指数衰减调整学习率
主要参数:
- gamma:指数的底
调整方式:lr = lr * gamma ** epoch
# Exponential LR
gamma = 0.95
scheduler_lr = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma)
CosineAnnealingLR
功能:余弦周期调整学习率
主要参数:
- T_max:下降周期
- eta_min:学习率下限
调整方式:

# CosineAnnealingLR
t_max = 50
scheduler_lr = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=t_max, eta_min=0)
ReduceLRonPlateau
功能:监控指标,当指标不再变化则调整学习率
主要参数:
mode:min/max,两种模式,min观察下降,max观察上升- factor:调整系数
- patience:“耐心”,接受几次不变化
cooldown:“冷却时间”,停止监控一段时间- verbose:是否打印日志
min_lr:学习率下限eps:学习率衰减最小值
# Reduce LR on Plateau
loss_value = 0.5
accuray = 0.9factor = 0.1
mode = 'min'
patience = 10
cooldown = 10
min_lr = 1e-4
verbose = Truescheduler_lr = optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=factor, mode=mode, patience=patience,cooldown=cooldown, min_lr=min_lr, verbose=verbose)
for epoch in range(max_epoch):for i in range(iteration):optimizer.step()optimizer.zero_grad()# if epoch == 5:# loss_value = 0.4# 把要监控的指标传进去scheduler_lr.step(loss_value)Epoch 12: reducing learning rate of group 0 to 1.0000e-02.
Epoch 33: reducing learning rate of group 0 to 1.0000e-03.
Epoch 54: reducing learning rate of group 0 to 1.0000e-04.LambdaLR
功能:自定义调整策略
主要参数:
lr_lambda:function or list
# lambda LRlr_init = 0.1
weights_1 = torch.randn((6, 3, 5, 5))
weights_2 = torch.ones((5, 5))optimizer = optim.SGD([{'params': [weights_1]},{'params': [weights_2]}
], lr=lr_init)lambda1 = lambda epoch: 0.1 ** (epoch // 20)
lambda2 = lambda epoch: 0.95 ** epochscheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):for i in range(iteration):optimizer.step()optimizer.zero_grad()scheduler.step()lr_list.append(scheduler.get_lr())epoch_list.append(epoch)print('epoch: {:5d}, lr:{}'.format(epoch, scheduler.get_lr()))相关文章:
Pytorch优化器Optimizer
优化器Optimizer 什么是优化器 pytorch的优化器:管理并更新模型中可学习参数的值,使得模型输出更接近真实标签 导数:函数在指定坐标轴上的变化率 方向导数:指定方向上的变化率(二元及以上函数,偏导数&am…...
如何在MySQL 8中实现数据迁移?这里有一个简单易用的方案
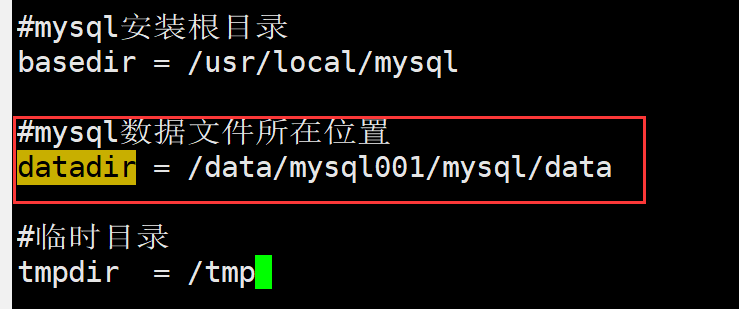
文章目录前言一. 致敬IT领域的那些女性二. 进制方式安装MySQL2.1 下载软件包2.2 配置环境:2.2.1 配置yum环境2.2.2 配置安全前的系统环境2.3 开始安装2.4 初始化MySQL2.5 修改配置文件2.6 将MySQL设为服务并启动测试三. MySQL数据迁移总结前言 正好赶上IT女神节&am…...
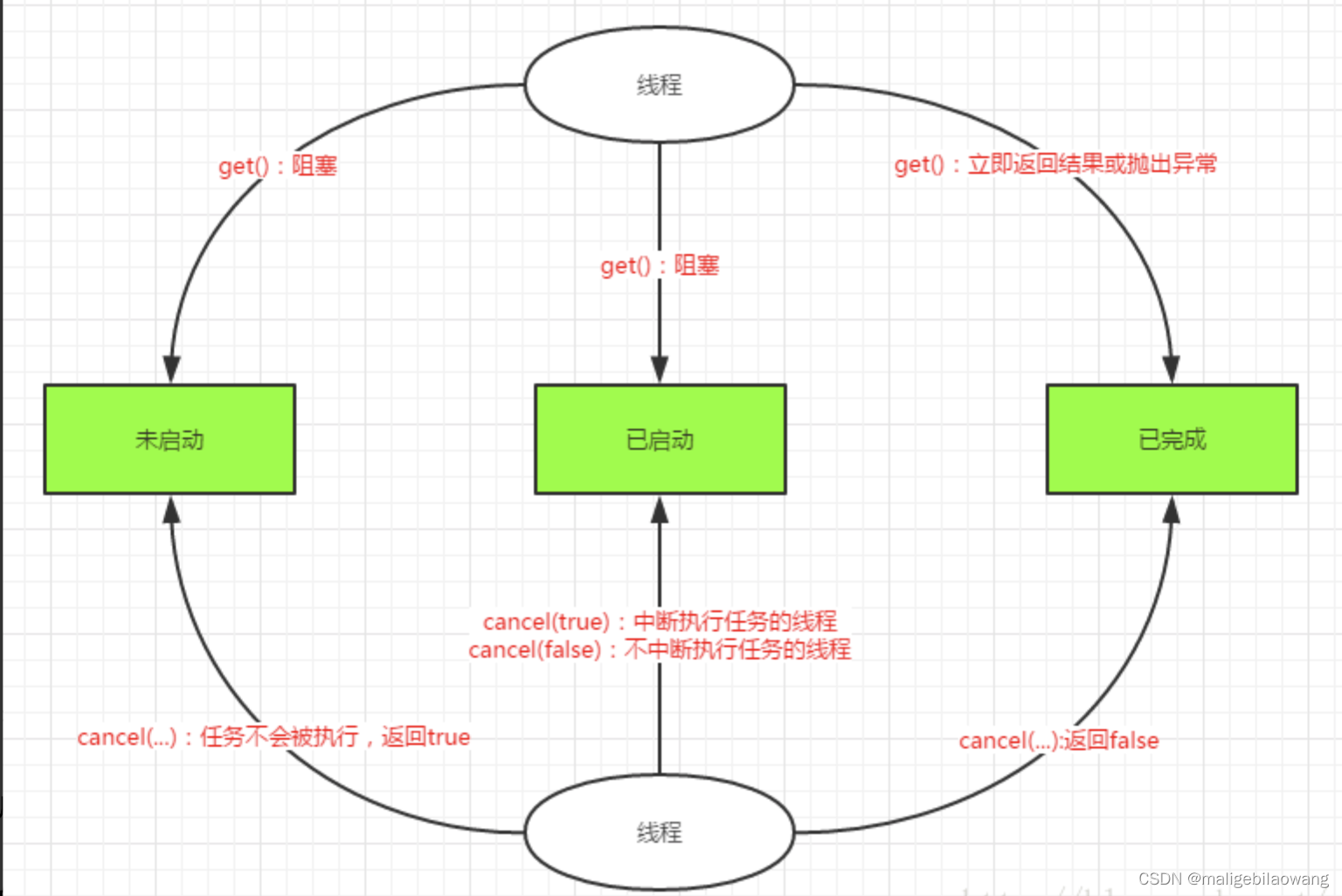
java多线程(二三)并发编程:Callable、Future和FutureTask
一、Callable 与 Runnable 先说一下java.lang.Runnable吧,它是一个接口,在它里面只声明了一个run()方法: public interface Runnable {public abstract void run(); }由于run()方法返回值为void类型,所以在执行完任务之后无法返…...

day4分支和循环作业
基础题 根据输入的成绩的范围打印及格 或者不及格。 score 58 if score > 90:print(及格) else:print(不及格)根据输入的年纪范围打印成年或者未成年,如果年龄不在正常范围内(0~150)打印这不是人!。 age 52 if 0 < age < 18:print(未成年) elif 18 &l…...

轮毂要怎么选?选大还是选小?
随着改装车的越来越火爆,汽车轮毂可选择的款式也越来越多,90%的人换轮毂,首先选的就是外观。大轮毂的款式多,外形大气好看,运动感十足, 那是不是选大轮毂就可以呢?不是的,汽车轮毂要…...

RabbitMq 使用说明
1. 声明交换机和队列,以及交换机和队列绑定 import lombok.extern.slf4j.Slf4j; import org.springframework.amqp.core.*; import org.springframework.beans.factory.annotation.Qualifier; import org.springframework.context.annotation.Bean; import org.spr…...
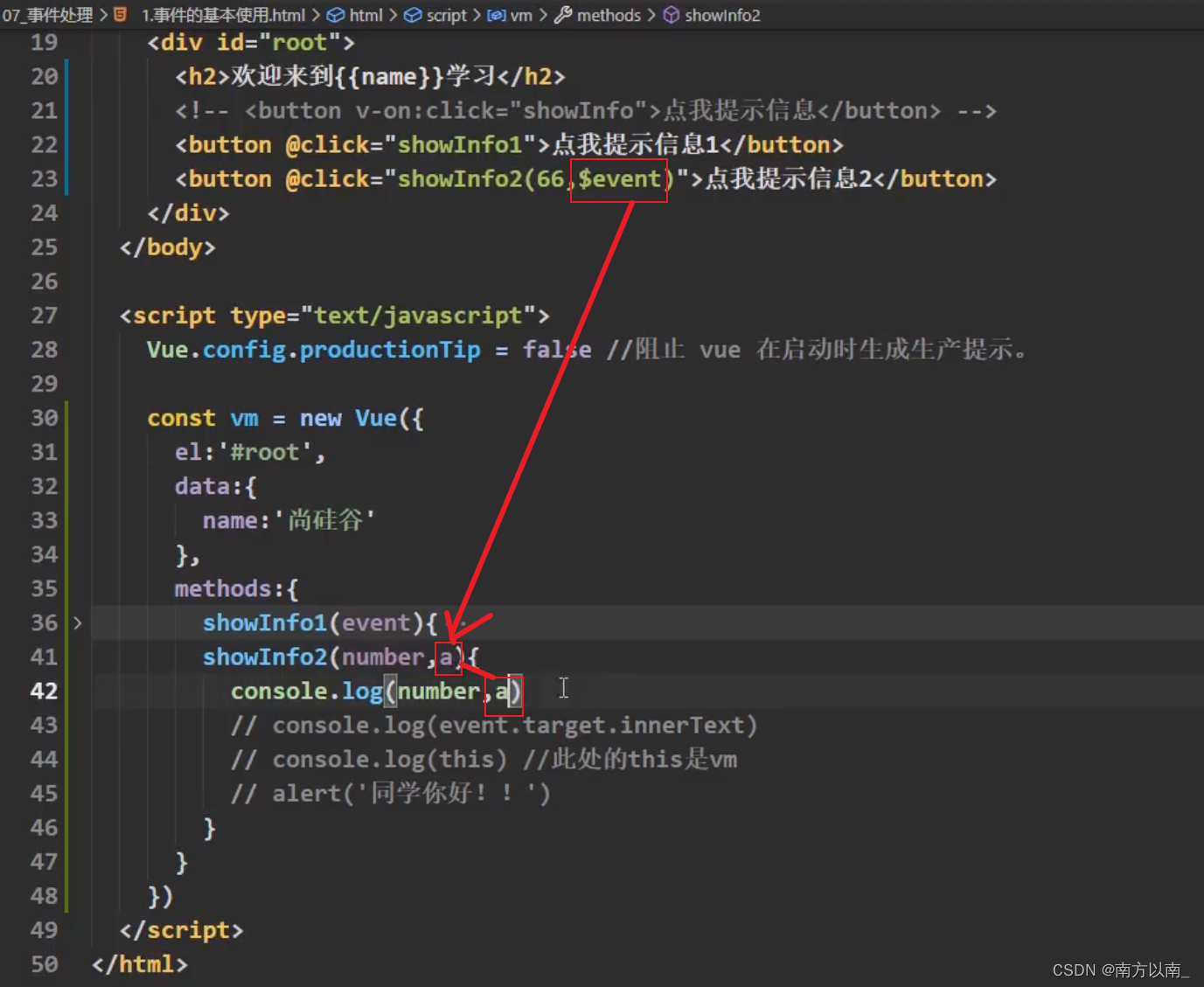
Vue(10-20)
1Vue赋值方式 Object.defineProperty <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" conten…...

C++-对四个智能指针:shared_ptr,unique_ptr,weak_ptr,auto_ptr的理解
回答如下: C的智能指针是一种特殊类型的“指针”,其主要目的是自动跟踪内存分配和释放,以避免程序中出现内存泄露或空悬指针等问题,主要采用的技术是:借助于类的生命周期,当超出了类的作用域时,…...

uni-app中使用vue3语法详解
全局创建 app.use(createPina()).mount 全局方法 通过app.config.globalProperties.xxx可以创建 这里我们写了一个字符串翻转的全局方法 main.js里面添加一个全局方法 不要忘了加$ 否则会报错 // #ifdef VUE3 //导入创建app import { createSSRApp } from vue //导入创建ap…...

三十四、MongoDB PHP
PHP 语言可是使用 mongo.so ( Windows 下是 mongo.dll ) 扩展访问 MongoDB 数据库 MongoDB PHP 在各平台上的安装及驱动包下载请查看: PHP 安装 MongoDB 扩展驱动 如果你使用的是 PHP7,请移步: PHP7 MongoDB 安装与使用 PHP 连接 MongoDB 和 选择一个…...

浅拷贝和深拷贝的区别
浅拷贝和深拷贝 总结:浅拷贝对象数据共享,深拷贝是一个完全独立的对象,因此对象数据不共享。 浅拷贝(Shallow Copy) 浅拷贝是指创建一个新的对象,但是该新对象只是原始对象的一个副本。具体而言…...

6个常用Pycharm插件推荐,老手100%都用过
人生苦短 我用python 有些插件是下载后需要重启Pycharm才生效的 免费领源码、安装包:扣扣qun 903971231 PyCharm 本身已经足够优秀, 就算不使用插件, 也可以吊打市面上 90%的 Python 编辑器。 如果硬要我推荐几款实用的话, 那么…...

TCP的11种状态
CLOSED状态:初始状态,表示TCP连接是“关闭的”或者“未打开的”LISTEN状态:表示服务端的某个端口正处于监听状态,正在等待客户端连接的到来SYN_SENT状态:当客户端发送SYN请求建立连接之后,客户端处于SYN_SE…...

new 指令简单过程 / 类加载简单过程初始化
例子:Person p new Person(“张三”,”23”); 因为new用到person.class,所以先找到person.class文件,并且加载到内存中(如果有父类先加载父类)执行static块以及static变量的初始化(如果有父类先初始化父类࿰…...

Asan基本原理及试用
概述 Asan是Google专门为C/C开发的内存错误探测工具,其具有如下功能 使用已释放内存(野指针)√堆内存越界(读写)√栈内存越界(读写)√全局变量越界(读写)函数返回局部变…...
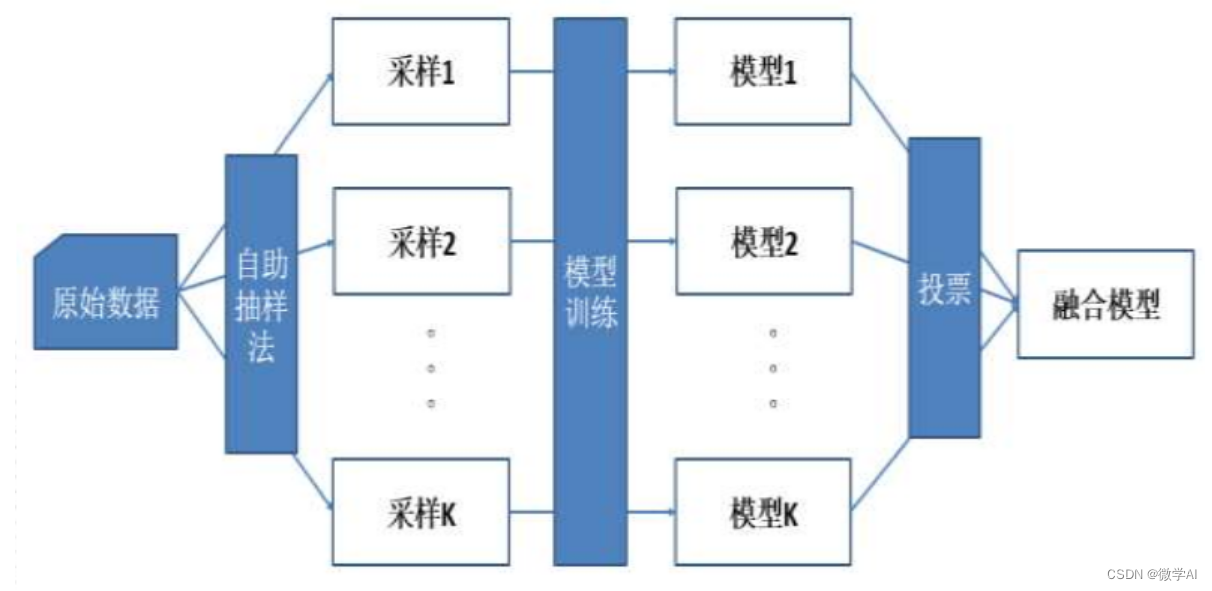
深度学习应用技巧4-模型融合:投票法、加权平均法、集成模型法
大家好,我是微学AI,今天给大家介绍一下,深度学习中的模型融合。它是将多个深度学习模型或其预测结果结合起来,以提高模型整体性能的一种技术。 深度学习中的模型融合技术,也叫做集成学习,是指同时使用多个…...

【并发编程】深入理解Java内存模型及相关面试题
文章目录优秀引用1、引入2、概述3、JMM内存模型的实现3.1、简介3.2、原子性3.3、可见性3.4、有序性4、相关面试题4.1、你知道什么是Java内存模型JMM吗?4.2、JMM和volatile他们两个之间的关系是什么?4.3、JMM有哪些特性/能说说JMM的三大特性吗?…...

C++编程语言STL之queue介绍
本文主要介绍C编程语言的STL(Standard Template Library)中queue(队列)的相关知识,同时通过示例代码介绍queue的常见用法。1 概述适配器(adaptor)是STL中的一个通用概念。容器、迭代器和函数都有…...

ACO优化蚁群算法
%% 蚁群算法(ant colony optimization,ACO) %清空变量 clear close all clc [ graph ] createGraph(); figure subplot(1,3,1) drawGraph( graph); %% 初始化参数 maxIter 100; antNo 50; tau0 10 * 1 / ( graph.n * mean( graph.edges(:) …...

SwiftUI 常用组件和属性(SwiftUI初学笔记)
本文为初学SwiftUI笔记。记录SwiftUI常用的组件和属性。 组件 共有属性(View的属性) Image("toRight").resizable().background(.red) // 背景色.shadow(color: .black, radius: 2, x: 9, y: 15) //阴影.frame(width: 30, height: 30) // 宽高 可以只设置宽或者高.…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

从深圳崛起的“机器之眼”:赴港乐动机器人的万亿赛道赶考路
进入2025年以来,尽管围绕人形机器人、具身智能等机器人赛道的质疑声不断,但全球市场热度依然高涨,入局者持续增加。 以国内市场为例,天眼查专业版数据显示,截至5月底,我国现存在业、存续状态的机器人相关企…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...