Mybatis不明白?就这一篇带你轻松入门
引言:烧脑的我一直在烧脑的寻找资料,寻找网课,历经磨难让一个在大一期间只会算法的我逐渐走入Java前后端开发,也是一直在自学的道路上磕磕碰碰,也希望这篇文章对于也是同处于自学的你有所帮助,也希望你继续努力不要放弃,本文已经码了一万四千多字,也希望你可以耐心品读。话不多说,进入正题......
目录
一.什么是SSM框架?
二.Mybatis简介:
三.Mybatis环境:
1.配置文件(application.properties)
为什么要写配置文件?
为什么这个配置文件要这么写?
2.pom.xml
四.Mybatis开始启动:
1.创建数据库并新建一张表
2.创建JavaBean:
3.在Mapper包下创建EmpMapper接口:
4.测试类test来测试代码:
@Autowired:
原理:
五.Spring的实现流程(很重要,虽然文字多,但是是精髓):
依赖注入(DI):
Bean:
Ioc容器:
Spring实现流程分析:
六.利用MyBatis框架注解的方式实现增删改查操作:
准备操作的注意事项以及知识点:
动态获取:
数据封装:
1.增:
2.删:
3.改:
4.查:
七.利用Mybatis框架的xml配置文件的形式配置SQL语句(映射文件)
1.好处:
2.规范:
3.动态SQL:
(1)if
(2)foreach
3.,
总结:
首先,Mybatis这个词汇肯定对于你很陌生,学习开始也是需要写SQL语言以及一些JDBC基础,我先在SSM框架帮你逐渐了解Mybatis框架的使用位置。
一.什么是SSM框架?
SSM框架是由Spring,SpringMVC,Mybatis结合而成,而标准的SSM框架有四层,分别为dao层,service层,controller层,view层。其中的dao层就是Mybatis框架的体现。
根据这几句话 ,我们能看见Mybatis的影子以及其也是很重要的一层,所以咱们不会的小伙伴可以先从SSM框架入手,了解这个框架的大体是什么,然后进入Mybatis的学习,以免不理解这东西对于整体的前后端的项目的位置。
下面是我在网上找的流程图,可以参考一下,理解Mybatis的使用位置:

二.Mybatis简介:
Mybatis是一个基于Java的持久层框架,也是对于JDBC(操作数据库的语句)的一个封装,以此来使数据库的底层操作变得透明,并且我们可以用Mybatis通过配置文件(application.properties)关联每个Mapper文件,而在Mapper文件中定义了许多以xxxMapper这种格式命名的很多类并在每个类中进行对数据库所需进行的sql语句映射,也就是增删改查的操作,而为什么要以这种格式命名也是有原因的,这个我们后面会提及。
Mybatis能够通过注解以及xml的方式将要执行的各种statement配置起来,通过Java对象以及statement中的sql的动态参数进行映射,以此生成最终执行的sql语句,随后由Mybatis框架执行sql并将结果映射为Java对象并返回。
下面是官方的简介:MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。入门_MyBatis中文网

这些东西现在看肯定是有些看不懂的,所以咱们先往下来,然后在反过来往上面回味理解。如果就想看代码请从第五节看起,第五节非常有用。
这里采用ORM思想来解决实体与数据库映射问题。
三.Mybatis环境:
我们在练习or创建项目的时候首先要创建springboot工程,数据表,实体表,随后引入Mybatis的相关依赖,并配置Mybatis。
这里省略一堆的相关配置,挑重点的说明:
1.配置文件(application.properties)
#驱动类的名称
spring.datasource.driver-class-name = com.mysql.cj.jdbc.Driver
#数据库连接的url地址
spring.datasource.url = jdbc:mysql://localhost:3306/mybatis
#连接数据库的用户名
spring.datasource.username = root
#连接数据库的密码
spring.datasource.password = 1234为什么要写配置文件?
写配置文件是为了表明数据库的连接信息,注意我这里url后面的mybatis不是咱们说的Mybatis框架,而是自己新建的mybatis数据库名,里面含有user表,方便后面的代码展示。
而配置文件还有一种application.yml文件这里先不提及。
为什么这个配置文件要这么写?
学过JDBC的小伙伴肯定了解过,JDBC的标准四个步骤:
1.注册驱动
2.获取连接
3.获取执行SQL的对象Statement,执行SQL
4.释放资源
下面图片是JDBC的流程图:
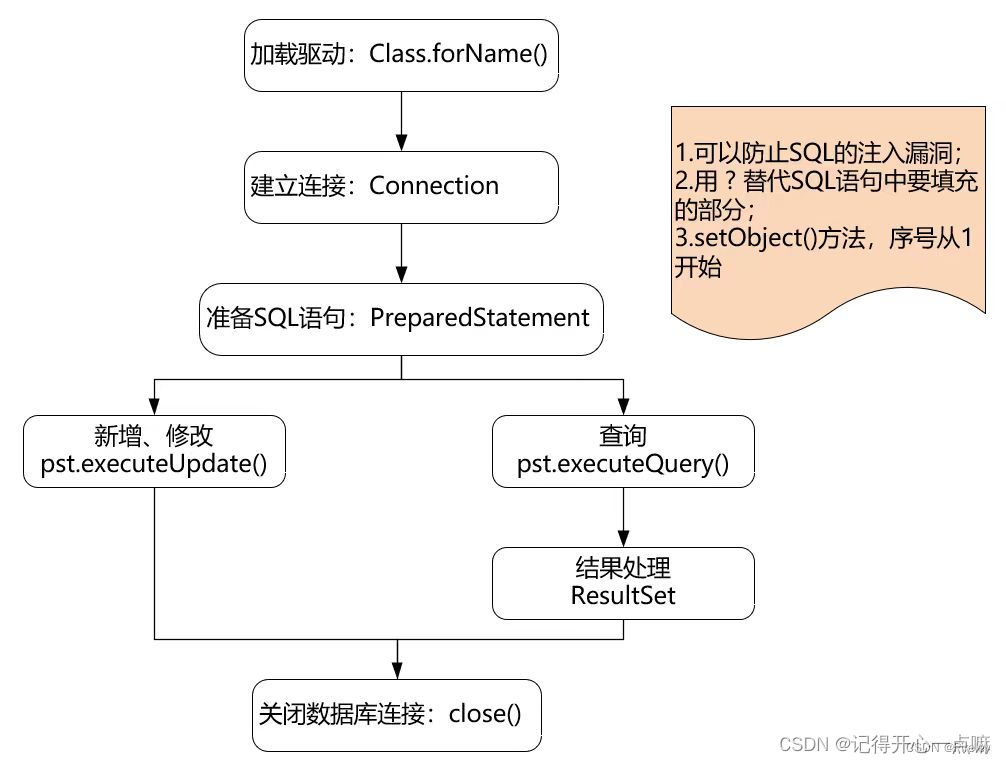
而我前面提及Mybatis框架是为了简化JDBC控制数据库的,所以这个框架大体就应该基于JDBC改造而成吧,而前两部整合一下就是上面的配置文件信息。
2.pom.xml
学过Maven肯定知道这是用来管理依赖包的,所以我们需要在SQL里面吧应该勾选的选上,以此来导入Mybatis依赖以及MySQL驱动依赖。

这个Lombok后面会提及,建议勾选。
四.Mybatis开始启动:

1.创建数据库并新建一张表
我们首先要创建一个数据库mybatis,这就是上面 url 后面要写这个的原因,为了跟这个数据库挂上关联。然后我们就再这个数据库内新建一张emp表存放成员信息。


这是这个表的大体信息,另外咱们现在这里注意一下每个字段名,不是驼峰命名,这里先注意一下,后面会根据这个有些注意事项。
2.创建JavaBean:
因为呢我们需要通过Java对象以及statement中的sql的动态参数进行映射,所以咱们要先在java包下创建一个标准的JavaBean(注意创建的包的大体格式以及包名,后面如果包名对不上xml与Mapper接口之间无法取得联系):

我这个JavaBean创建的名称是Emp,与表名一致方便理解。
import java.time.LocalDate;
import java.time.LocalDateTime;public class Emp {private Integer id;private String username;private String password;private String name;private Short gender;private String image;private Short job;private LocalDate entrydate;private Integer deptId;private LocalDateTime createTime;private LocalDateTime updateTime;//省略构造方法,get与set方法
}我们是不是觉得创建那么多的get与set方法及其麻烦,所以我们就需要Lombok。
看一下下面图片,上面介绍了Lombok:

既然看完Lombok,咱们就可以这样简写:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;import java.time.LocalDate;
import java.time.LocalDateTime;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Emp {private Integer id;private String username;private String password;private String name;private Short gender;private String image;private Short job;private LocalDate entrydate;private Integer deptId;private LocalDateTime createTime;private LocalDateTime updateTime;
}
3.在Mapper包下创建EmpMapper接口:
在此提醒一下,注意位置!!!
这个是一个持久层接口,并且注意命名规范!!!
@Mapper:程序会自动创建该接口的代理对象并且会将这个代理对象放在IOC容器中(后面介绍了什么是Ioc容器)。
@select等一些sql语句:表示我们要执行什么样的sql语句,随后括号内引号内加上对应想要执行的SQL语句,在程序执行调用该方法就会自动执行当前注解内的sql语句。(后面会讲述)
@Mapper //在运行时会自动生成该接口的实现类对象(代理对象),并将该对象交给IOC容器管理
public interface EmpMapper{//查@Select("select* from emp")public List<Emp> list();
}这里定义一个接口,我们都知道,Java在接口内定义方法实际上是定义规则。
4.测试类test来测试代码:
@SpringBootTest //springboot整合单元测试的注解
class SpringbootMybatis1ApplicationTest{@Autowired //依赖注入private EmpMapper empMapper;@Test //测试的注解public void testListemp(){List<User> emplist = empMapper.list();emplist.stream().forEach(emp -> {System.out.println(emp);});}
}我们在写测试类的时候要注意注解的使用:
@Autowired:
使用后可以对类成员变量,方法以及构造函数进行标注,以此来完成自动装配的工作。其实这也是Spring依赖注入(DI)的一种方式。(不知道什么是自动装配以及依赖注入的不要急,下面会介绍)
原理:
我们如果学过Spring就会知道Ioc容器(
不知道的继续往下看),当这个Ioc容器扫描到这个注解,就会在容器内自动查找需要的bean,并装配给该对象的属性。
五.Spring的实现流程(很重要,虽然文字多,但是是精髓):
依赖注入(DI):
它是Ioc容器的具体实现,就好比如一个Teacher类中有个People类对象,那么Teacher类就需要 依赖People类对象当中的方法,而People就是Teacher的依赖。
Bean:
在Spring中,构成应用程序主干并由SpringIoc容器管理的对象称为Bean。
Ioc容器:
控制反转(Ioc)通过依赖注入(DI)的方式实现对象之间的松耦合关系,它负责对象的生成与依赖的注入。就比如如果没有来的及对Teacher中的People绑定对象,却调用其方法的话,那么程序就会抛出空指针异常,所以Spring提供这个Ioc与DI这套机制是为了解耦。
Spring实现流程分析:
在Spring中,你不需要自己创建对象,只需要告诉哪些类需要创建出对象,然后再启动该项目的时候Spring就会自动的帮助你创建出该对象,并且仅仅存在一个类的实例,也就是Bean。而虽然创建出来了对象,但是Teacher同时也需要知道这个对象在哪里,于是就需要依赖注入(DI)这个Bean,所以我们就使用@Autowired这个注解,无需担心忘记绑定对象而出现空指针的问题了,它可以实现自动注入一个Bean。我们无需构建类,Spring启动时会把所需类实例化对象,如果需要依赖,则先实例化依赖然后实例化当前类,而依赖必须通过构建函数传入,所以实例化时,当前类就会接受并保存所有依赖的对象,这一步也就是所谓的依赖注入(DI)。而在Spring中,类的实例化,依赖的实例化,依赖的注入都是交给Ioc容器控制,以至于不是我们程序员控制,控制权交给程序管理了,这也就是控制反转
,倒反天罡。
六.利用MyBatis框架注解的方式实现增删改查操作:
首先我们要保证我们有Emp的JavaBean以及mybatis数据库下的emp表并注意配置文件url后面的数据库名是否正确,然后就开始操作:
准备操作的注意事项以及知识点:
执行这个接口的方法其实无非是执行这个注解引起来的SQL语句也就是JDBC的第三部获取执行SQL的对象Statement,执行SQL语句。
动态获取:
如果我们想获取id=17的信息,正常我们要写会写成下面的形式:
@Mapper
public interface EmpMapper {//删@Delete("delete from emp where id = 17") //获取id = 17的信息public void delete();
}
很显然我们只能查到emp表中的id = 17的信息,这是静止的,我们在写程序以及最后增删改查的操作不可能是写一个查一个吧,所以我们就要学习动态绑定,我们将我们想要动态获取的位置写成参数占位符这种格式:#{ },这种参数占位符会将#{...}替换成?,生成预编译的SQL语句,会自动设置其参数值。
而还有一种格式:${...},这个是直接将参数拼接在SQL语句当中,存在SQL注入(也就是因为拼接SQL语句导致利用拼接后的SQL语句执行的命令钻出的漏洞)这种危险的情况,如果对于表明or列表名进行动态设置的时候就可以使用这个。
随后给方法传参:
@Mapper
public interface EmpMapper {//删@Delete("delete from emp where id = #{id}") //#{id}动态获取public void delete(Integer id);
}
当使用下面的方法的时候我们就会自动执行上面的SQL语句,随后当形参传的是什么,#{id}代表的值就是什么。
数据封装:
如果我们JavaBean的属性名与表的字段名不一致的话就会造成Mybatis无法自动封装,这个也是回答了上面注意表名了,因为JavaBean的属性名是驼峰命名的规范性使得与表的字段名不一样。
为了解决这个问题我们有三种解决方法:起别名,手动结果映射,开启驼峰命名。
这里详细解释开启驼峰命名,如果想看前两个,就翻到用注解查找表的Mapper接口。
我们在配置文件加入:
mybatis.configuration.map-underscore-to-camel-case=true 这样就可以直接将数据库字段名映射到JavaBean的属性名了。
1.增:
Mapper接口:
@Mapper
public interface EmpMapper {//增@Options(useGeneratedKeys = true , keyProperty = "id") //自动将生成的主键值赋值给emp对象的id属性@Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) " +"VALUE (#{username},#{name},#{gender},#{image},#{job},#{entrydate},#{deptId},#{createTime},#{updateTime})")public void insert(Emp emp);}
测试类:
@SpringBootTest
class SpringbootMybatis2ApplicationTests {@Autowiredprivate EmpMapper empMapper;@Testpublic void testInsert(){Emp emp = new Emp();emp.setUsername("Tom");emp.setName("汤姆");emp.setImage("1.jpg");emp.setGender((short)1);emp.setJob((short)1);emp.setEntrydate(LocalDate.of(2000,1,1));emp.setCreateTime(LocalDateTime.now());emp.setUpdateTime(LocalDateTime.now());emp.setDeptId(1);empMapper.insert(emp);}
}2.删:
Mapper接口:
@Mapper
public interface EmpMapper {//删@Delete("delete from emp where id = #{id}") //#{id}动态获取public void delete(Integer id);
}
测试类:
@SpringBootTest
class SpringbootMybatis2ApplicationTests {@Autowiredprivate EmpMapper empMapper;@Testpublic void testDelete(){empMapper.delete(17);}
}
3.改:
Mapper接口:
@Mapper
public interface EmpMapper {//改@Update("update emp set username = #{username} , name = #{name} , gender = #{gender} , image = #{image} ," +" job = #{job} , entrydate = #{entrydate} , dept_id = #{deptId} , update_time = #{updateTime} where id = #{id}")public void update(Emp emp);}
测试类:
@SpringBootTest
class SpringbootMybatis2ApplicationTests {@Autowiredprivate EmpMapper empMapper;@Testpublic void testUpdate(){Emp emp = new Emp();emp.setId(18);emp.setUsername("Tom1");emp.setName("汤姆1");emp.setImage("1.jpg");emp.setGender((short)1);emp.setJob((short)1);emp.setEntrydate(LocalDate.of(2000,1,1));emp.setUpdateTime(LocalDateTime.now());emp.setDeptId(1);empMapper.update(emp);}
}
4.查:
Mapper接口:(注:这里将所有的查找方法全部写出来没有加注释,编译会报错的)
@Mapper
public interface EmpMapper {//查@Select("select* from emp where id = #{id}")public Emp getById(Integer id);//起别名@Select("select id,username,password,name,gender,image,job,entrydate," +"dept_id deptId,create_time createTime,update_time updateTime from emp where id = #{id}")public Emp getById(Integer id);//注解手动映射封装@Results({@Result(column = "dept_id" , property = "deptId"), // 字段@Result(column = "create_time" , property = "createTime"),@Result(column = "update_time" , property = "updateTime")})@Select("select* from emp where id = #{id}")public Emp getById(Integer id);public List<Emp> list(String name , Short gender , LocalDate begin , LocalDate end);
}测试类:
@SpringBootTest
class SpringbootMybatis2ApplicationTests {@Autowiredprivate EmpMapper empMapper;@Testpublic void testSelect(){Emp emp = empMapper.getById(18);System.out.println(emp);}
}
七.利用Mybatis框架的xml配置文件的形式配置SQL语句(映射文件)
1.好处:
我们在第六节学到了用注解进行一些简单的增删改查操作,如果想要实现复杂的SQL功能就要使用xml来配置映射语句,额类似就将注解的SQL语句写在xml文件内,只不过需要加上些许标签以及注意规范。
2.规范:
xml映射文件的名称要与Mapper接口的名称保持一致。
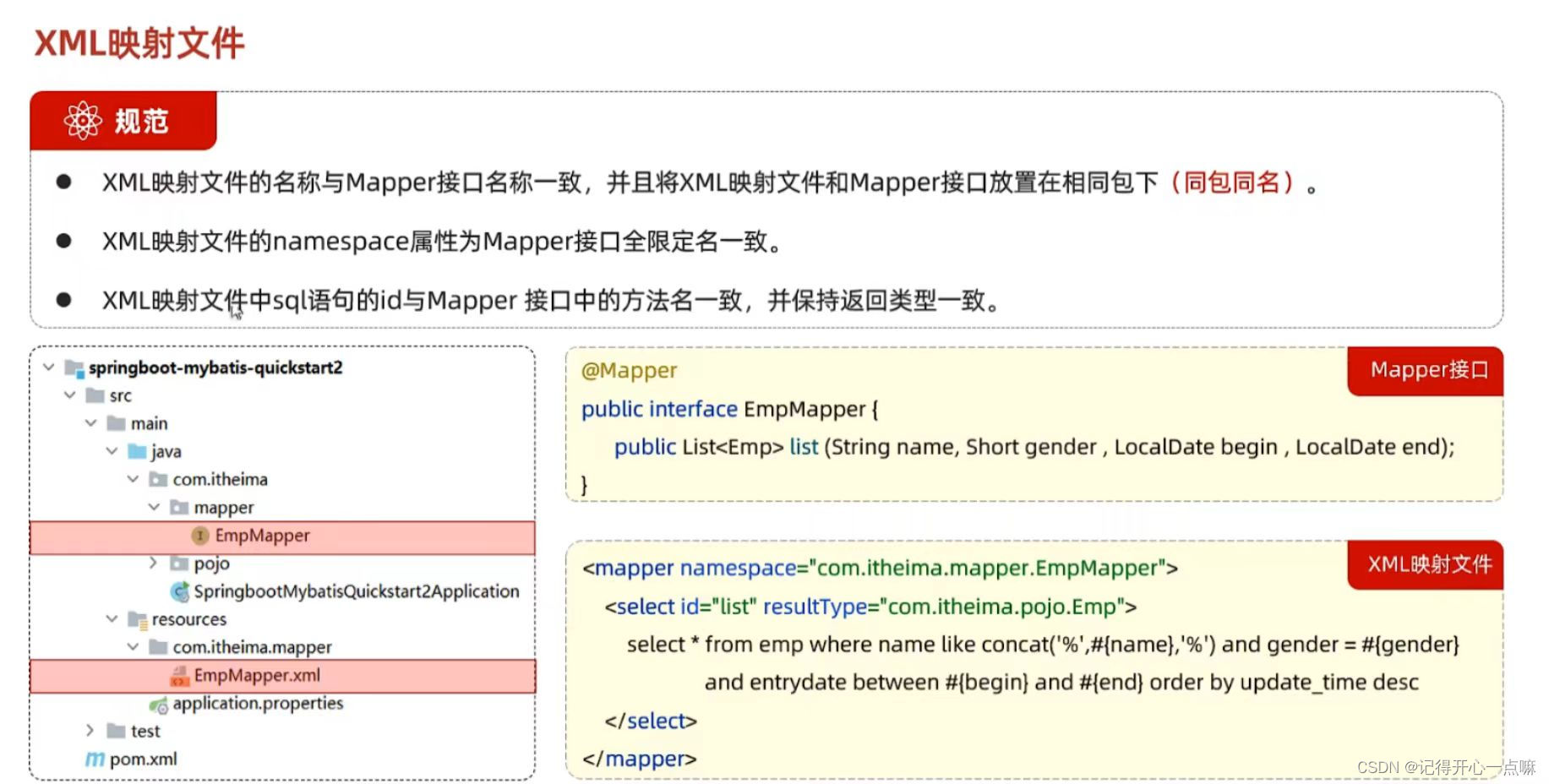
你是否好奇xml文件如何精准的映射的?
实际上,我们上面图片中提到的三条规范就是为了映射而用的。参考下面代码:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.Mapper.EmpMapper"><!--namespace:后面写Mapper接口的全类名--><!--id:与Mapper接口的方法名一致--><!--resultType:单挑记录所封装的类型,以此来保证返回类型一致--><select id="list" resultType="com.itheima.pojo.Emp">select * from emp where name like concat('%' , #{name} , '%') and gender = #{gender} andentrydate between #{begin} and #{end} order by update_time desc</select>
</mapper>
注意:我们想要的包结构要确保是一级一级的目录,应该用/而不是.来分隔。
下面的代码是配置XML文件的约束,这个应该去官网查找:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">随后我们就在<mapper></mapper>标签内添加想要实现的SQL语句,注意,这个标签是根标签!!!
<mapper namespace="com.itheima.Mapper.EmpMapper"><!--namespace:后面写Mapper接口的全类名--><!--id:与Mapper接口的方法名一致--><!--resultType:单挑记录所封装的类型,以此来保证返回类型一致--><select id="list" resultType="com.itheima.pojo.Emp">select * from emp where name like concat('%' , #{name} , '%') and gender = #{gender} andentrydate between #{begin} and #{end} order by update_time desc</select>
</mapper>
同时也是注意格式,相信你也看出来了,其实无外乎就是先写XML文件的约束然后通过标签加SQL语句就可以完成我们这一节的内容。
然后就写出Mapper接口:
public interface EmpMapper {public List<Emp> list(String name , Short gender , LocalDate begin , LocalDate end);
}最后写出测试类进行测试:
@SpringBootTest
class SpringbootMybatis2ApplicationTests {@Autowiredprivate EmpMapper empMapper;@Testpublic void testList(){List<Emp> empList = empMapper.list("张" , (short) 1 , LocalDate.of(2000,1,1),LocalDate.of(2022,1,1));System.out.println(empList);}
}3.动态SQL:
动态 SQL 是 MyBatis 的强大特性之一。如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。而利用动态 SQL,就可以彻底摆脱这种痛苦。
使用动态 SQL 并非一件易事,但借助可用于任何 SQL 映射语句中的强大的动态 SQL 语言,MyBatis 显著地提升了这一特性的易用性。
如果你之前用过 JSTL 或任何基于类 XML 语言的文本处理器,你对动态 SQL 元素可能会感觉似曾相识。在 MyBatis 之前的版本中,需要花时间了解大量的元素。借助功能强大的基于 OGNL 的表达式,MyBatis 3 替换了之前的大部分元素,大大精简了元素种类,现在要学习的元素种类比原来的一半还要少。
- if
- foreach
- sql,include
(1)if
用于判断条件是否成立。使用test属性进行条件判断,如果条件结果为true,则拼接SQL语句。
写成的XML映射文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.Mapper.EmpMapper"><!--id:与Mapper接口的方法名一致--><!--resultType:单挑记录所封装的类型,以此来保证返回类型一致--><select id="list" resultType="com.itheima.pojo.Emp">select * from empwhere<if test = "name != null">name like concat('%' , #{name} , '%')</if><if test = "gender != null">and gender = #{gender}</if><if test = "begin != null and end != null">and entrydate between #{begin} and #{end}</if>order by update_time desc</select>
</mapper>但是如果我们第一个 if 标签无法成立,而第二个标签成立,SQL语句在拼接时就会发生语法错误(where后面直接加and)又或者三个判断均不成立导致仅剩一个where造成SQL语句错误于是我们就引出使用<where></where>标签。
使用<where></where>标签有两个好处:
1.动态生成where关键字
2.自动出去条件前面多余的and关键字
随后XML映射文件改完就变成这样:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.Mapper.EmpMapper"><!--id:与Mapper接口的方法名一致--><!--resultType:单挑记录所封装的类型,以此来保证返回类型一致--><select id="list" resultType="com.itheima.pojo.Emp">select * from emp<where><if test = "name != null">name like concat('%' , #{name} , '%')</if><if test = "gender != null">and gender = #{gender}</if><if test = "begin != null and end != null">and entrydate between #{begin} and #{end}</if></where>order by update_time desc</select>
</mapper>如果要更新数据:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.Mapper.EmpMapper"><update id="update2"><set><if test="username != null"> username = #{username},</if><if test="name != null"> name = #{name},</if></set>where id = #{id}</update>
</mapper><set></set>标签跟<where></where>标签一样可以自动补全以及删除额外的','。
(2)foreach
动态 SQL 的另一个常见使用场景是对集合进行遍历(尤其是在构建 IN 条件语句的时候)。
foreach 元素的功能非常强大,它允许你指定一个集合,声明可以在元素体内使用的集合项(item)和索引(index)变量。它也允许你指定开头与结尾的字符串以及集合项迭代之间的分隔符。
你可以将任何可迭代对象(如 List、Set 等)、Map 对象或者数组对象作为集合参数传递给 foreach。当使用可迭代对象或者数组时,index 是当前迭代的序号,item 的值是本次迭代获取到的元素。当使用 Map 对象(或者 Map.Entry 对象的集合)时,index 是键,item 是值。
这个文字是官方文档上的,看不懂没关系,无外乎就是只要想进行批量操作就会用到这个foreach标签。
这里拿批量删除信息举例子:
首先是Mapper接口:
@Mapper
public interface EmpMapper {public void deleteByIds(List<Integer> ids);
}然后是XML文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.Mapper.EmpMapper"><delete id="deleteByIds">delete from emp where id in<foreach collection="ids" item = "id" separator="," open="(" close=")">#{id}</foreach></delete>
</mapper>
这里介绍一下foreach内的属性:
collection:集合名称,这里我在传参的时候传的是List<Integer> ids
item:集合遍历出来的元素/项
separator:每一次便利使用的分隔符
open:遍历开始前拼接的字段
close:遍历结束后拼接的字段
3.<sql>,<include>
在我们写一个XML文件过程难免会重复使用同一SQL语句,会导致代码维护性较差,而且还会臃肿,于是我们就可以利用<sql></sql>标签封装这个SQL语句,随后用<include>标签在每个需要使用封装SQL语句的标签内声明一下,就可以代替了。
下面看代码:
(这里直接展示XML文件)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.Mapper.EmpMapper"><sql id = "commonSelect">select id,username,password,name,gender,image,job,entrydate,dept_id,create_time,update_time from emp</sql><select id="list" resultType="com.itheima.pojo.Emp"><include refid="commonSelect"/><where><if test = "name != null">name like concat('%' , #{name} , '%')</if><if test = "gender != null">and gender = #{gender}</if><if test = "begin != null and end != null">and entrydate between #{begin} and #{end}</if></where>order by update_time desc</select>
</mapper>总结:
既然你看到了这里,想必你应该理解Mybatis框架有很深刻的理解了,基本上Mybatis已经不仅仅是入门程度了,主要还是理解咱们整个项目在哪里需要使用Mybatis框架,本文连续加载了六个小时,自己也是很多不会的地方不断整理, 码字不易,还请学会的你留下对于我珍贵的点赞收藏加评论吧,还有哪些不懂的地方欢迎在评论区留言。
相关文章:
Mybatis不明白?就这一篇带你轻松入门
引言:烧脑的我一直在烧脑的寻找资料,寻找网课,历经磨难让一个在大一期间只会算法的我逐渐走入Java前后端开发,也是一直在自学的道路上磕磕碰碰,也希望这篇文章对于也是同处于自学的你有所帮助,也希望你继续…...

pymupdf提取pdf表格及表格数据合并
pymupdf提取pdf表格非常快速,相比其他库是个更好的选择. 一个行列多的表格打印成pdf后会由于页宽分页原因变成多个表格,提取的多个表格需要合并为一个表格,再来处理数据. 下面代码中merge函数用于合并表格࿰…...

门外汉一次过软考中级(系统集成项目管理工程师)秘笈,请收藏!
24上软考考试已经结束,24下软考备考又要开启了!今年软考发生了改革,很多考试由一年考两次变成了一年考一次,比如高级信息系统项目管理师,比如中级系统集成项目管理工程师,这两科是高、中级里相对简单&#…...
[leetcode hot 150]第一百零八题,将有序数组转换为二叉搜索树
题目:给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 平衡二叉搜索树。 给定一个有序的整数数组,我们需要构建一棵平衡的二叉搜索树。平衡二叉树是指任意一个节点的左右子树的高度差不超过1。 由于给定的数组是有序的…...

科普丨什么是数字孪生灌区(平台)?如何建设?有何好处?
在农业发展的新时代,数字孪生灌区的概念逐渐走进大众视野,成为推动农业现代化、提升粮食安全保障能力的关键力量。那么,究竟什么是数字孪生灌区?它又是如何建设的?又能为我们带来哪些好处呢? 数字孪生灌区…...

Python爬虫如何入门:一步步走向精通的指南
Python爬虫如何入门:一步步走向精通的指南 在信息爆炸的时代,爬虫技术已经成为获取、整理和分析数据的必备技能。Python,以其简洁易懂的语法和强大的库支持,成为了爬虫开发的热门语言。那么,如何入门Python爬虫呢&…...

Linux用户和用户组的操作
用户管理 以Tom做为用户名 以dev做为用户组 增加用户 sudo adduser Tom #不建议使用useradd/userdel系列的命令删除用户 sudo deluser Tom --remove-home # 删除Tom用户及home目录 重置密码 sudo passwd Tom加入用户组 sudo usermod -a -G dev Tom # sudo usermod -aG …...
)
git命令行分支(增删改查)
文章目录 一、创建分支并推送到远程仓库二、拉取指定分支代码三、删除分支 一、创建分支并推送到远程仓库 初始化git git init如果有远程仓库就进行克隆远程仓库 origin 表示远程仓库地址 git clone origin# 如果没有远程仓库 就进行创建一个远程仓库 git remote add origin ht…...

地理加权回归GWR简介
地理加权回归GWR简介 一、定义: 地理加权回归(Geographically Weighted Regression,简称GWR)是一种空间数据分析方法,专门用于处理空间异质性(spatial heterogeneity)问题。以下是对GWR的详细简…...
康谋技术 | 自动驾驶:揭秘高精度时间同步技术(一)
众所周知,在自动驾驶中,主要涵盖感知、规划、控制三个关键的技术层面。在感知层面,单一传感器采集外界信息,各有优劣,比如摄像头采集信息分辨率高,但是受外界条件影响较大,一般缺少深度信息&…...
客户端被攻击怎么办,为什么应用加速这么适合
随着科技的进步和互联网的普及,游戏行业也正在经历前所未有的变革。玩家们不再满足于传统的线下游戏,而是转向了线上游戏。然而,随着游戏的线上化,游戏安全问题也日益凸显。游戏受到攻击是游戏开发者永远的痛点,谈“D“…...

Introduction to HAL3
目录 HAL3 behavior Overview of HAL1 v.s HAL3 HAL3 behavior: HAL3 - detail: HAL3 operation and pipeline Framework Diagram Problem of current code Operation mode Full v.s limited Do: Don’t: Metadata Manual control – ISP control...

Vue02-搭建Vue的开发环境
一、Vue.js的安装 1-1、直接用 <script> 引入(CDN) 1、CDN的说明 2、Vue的版本说明 生产版本是开发版本的压缩。 3、Vue的引入 验证是否存在Vue函数: 4、搭建Vue的开发环境 ①、下载开发版本的Vue,并在代码中引入 ②、安…...

Python | 句子缩写
字符串大小的比较Unicode码值 类似于asc|| 码 小写字母从 a 到 z 对应的 Unicode 码值是从 97 到 122,而大写字母从 A 到 Z 对应的 Unicode 码值是从 65 到 90, 大小写字母之间的差值为32,所以可以通过数学运算将小写字符减去32后转换为大写字符。 字…...
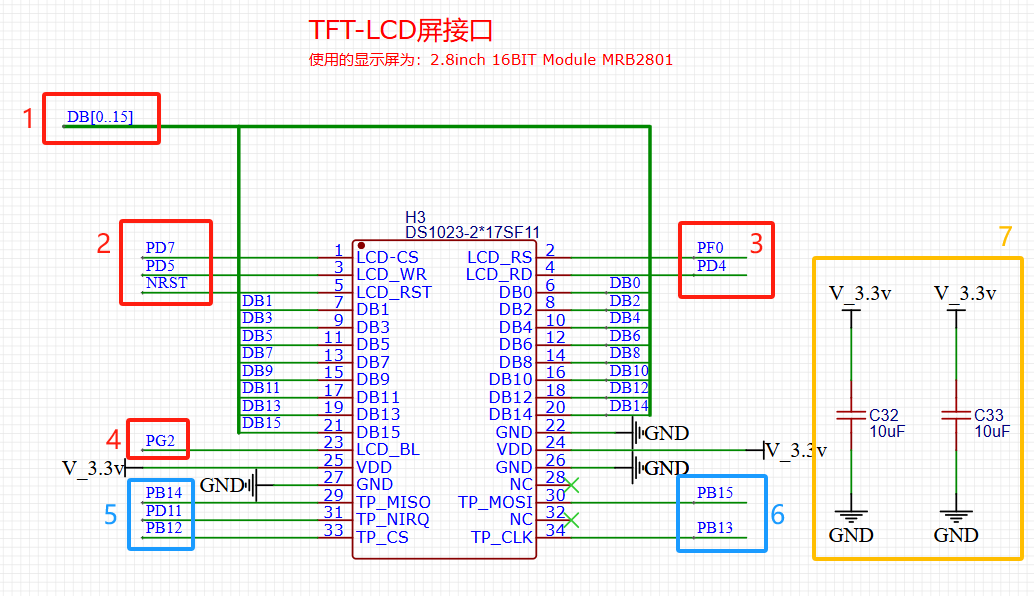
STM32自己从零开始实操04:显示电路原理图
一、TFT-LCD 屏接口 1.1指路 以下是该部分的设计出来后的实物图,我觉得看到实物图可能更方便理解这部分的设计。 图1 实物图 这部分设计的是一个屏幕的接口,很简单。使用的屏幕是:2.8inch 16BIT Module MRB2801。 1.2数据手册 ࿰…...

数分—AB测试
一、介绍 AB测试是一种常用于比较两种或多种不同版本的产品、服务或策略效果的实验方法。在AB测试中,被比较的版本被标记为A组和B组,然后两组被随机分配给不同的用户群体或实验对象。接着,针对每个组收集数据,比如用户行为、转化…...
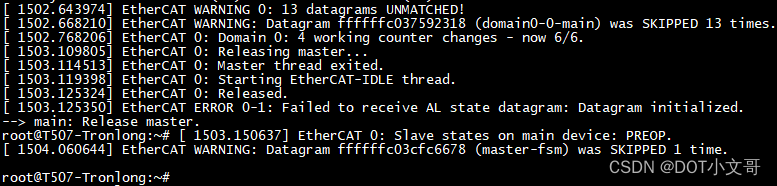
基于全志T507-H的Igh EtherCAT主站案例分享
基于全志T507-H的Linux-RT IgH EtherCAT主站演示 下文主要介绍基于全志T507-H(硬件平台:创龙科技TLT507-EVM评估板)案例,按照创龙科技提供的案例用户手册进行操作得出测试结果。 本次演示的开发环境: Windows开发环…...
)
刷题记录(20240605)
1.数组构造 题目描述 小红的数组构造小红希望你构造一个数组满足以下条件: 1.数组共有 n个元素,且所有元素两两不相等。 2.所有元素的最大公约数等于 k。 3.所有元素之和尽可能小。请你输出数组元素之和的最小值。 输入描述: 两个正整数 n 和 k。 输出描述ÿ…...

CUDA和OpenGL纹理texture结合
cuda和OpenGL纹理结合,并进行直方图计算 针对于单通道16位图像。结合方式在CUDA_equalizeHistogram_16函数中。 其他的为CUDA核函数。 #define HISTOGRAM_LENGTH 65536 // 2^16 表示16位深度定义直方图长度为65536,对应16位像素值的范围(0-65535)。 __global__ void com…...
市场凌乱,智能算法哪种效果好?
当我们在面对市场波动,个股震荡,无从下手的时候,不懂算法的朋友就只懂做t;懂算法的朋友这会儿就迷茫并不知道选择哪种智能算法交易?今天小编给大家整理一套性价比高的,适合个人投资者搞的算法交易ÿ…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...