C语言(结构体)
Hi~!这里是奋斗的小羊,很荣幸各位能阅读我的文章,诚请评论指点,欢迎欢迎~~
💥个人主页:小羊在奋斗
💥所属专栏:C语言
本系列文章为个人学习笔记,在这里撰写成文一为巩固知识,二为一些学友们展示一下我的学习过程及理解。文笔、排版拙劣,望见谅。
1、结构体类型的声明
2、结构体内存对齐
3、结构体传参
4、结构体实现位段
1、结构体类型的声明
1.1结构体变量的创建和初始化
其实之前在C语言(操作符)2中,我们已经比较详细地介绍过结构体变量的创建和初始化,这里再补充一个特殊的初始化方法——按照指定的顺序初始化。
前面我们学到的初始化方法是按结构体成员的顺序初始化,就像下面这样:
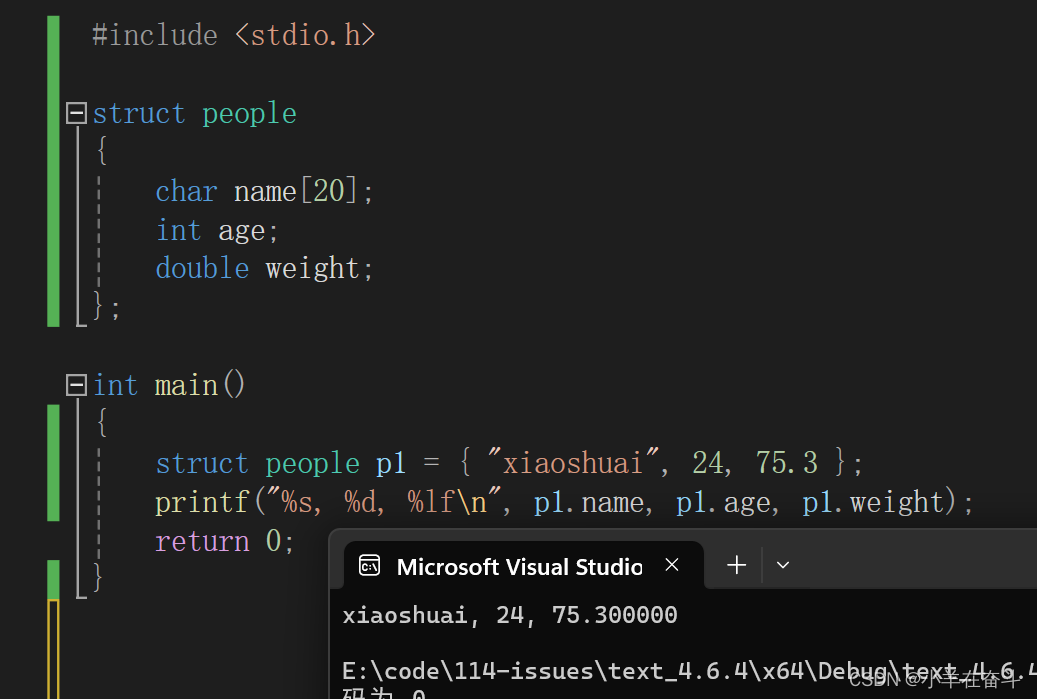
除了按顺序初始化,我们也可以按指定的顺序初始化:
这两种初始化方法得到的效果是一样的。
1.2结构体的特殊声明
我们之前学过的结构声明常规形式是这样的:

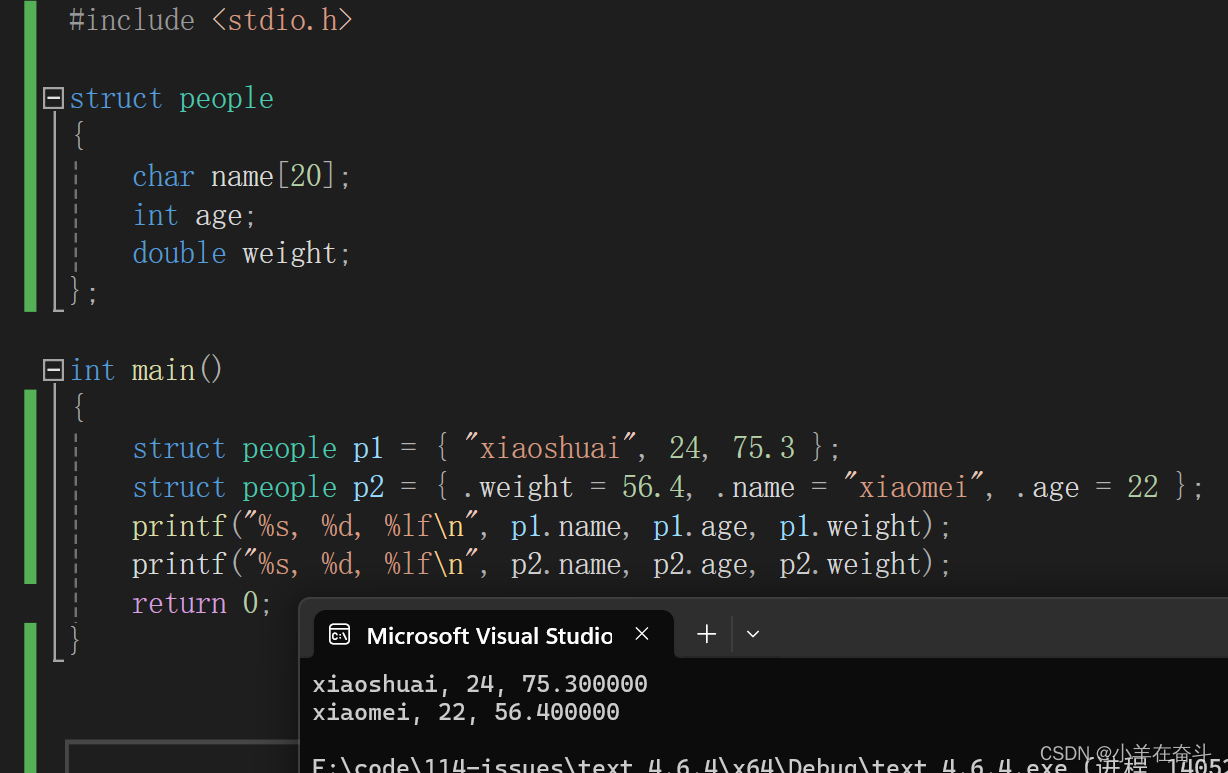
但在声明结构的时候,还可以不完全声明,就是省略掉自定义名。

但是这种不完全的结构体声明必须在声明的同时直接创建变量,并且这个类型只能使用一次,也就是创建一次变量,但是一次可以创建多个。
下面这个代码的问题在哪儿呢?用这个不完全的结构类型创建一个指针p,将p1的地址赋给p。
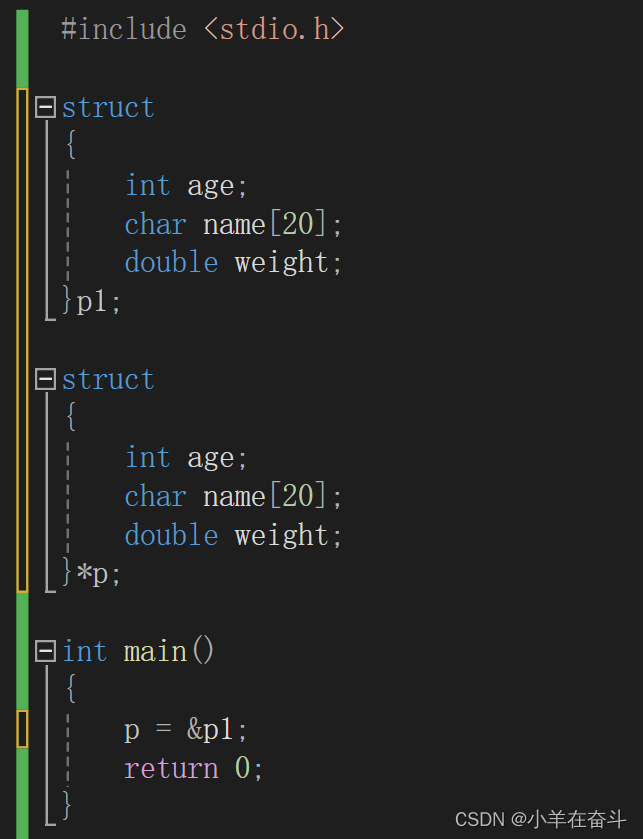
当我们运行起来就会发现编译器报警告,说两个指针类型不兼容。

这是因为我们创建的结构体类型是没有名字的,虽然两个成员一样,但编译器认为它们两个的地址类型是不一样的。
1.3结构的自引用
什么是结构的自引用呢?说白了就是结构自己引用自己,有点递归的意思。举个例子,当我们想将一个数据存到内存中时,可以按顺序存,也可以随机地存,只要能找到就行。那当我们随机存的时候,找到第一个数怎么找到第二个数就是一个问题。
这时候我们可以定义一个结构体类型,有两个成员名,一个存数据,另一个存下一个数据的地址,这样的话当我们找到第一个数就能找到第二个数,以此类推。

在结构体的自引用过程中,夹杂了 typedef 对不完全结构体类型声明的重命名,也容易引出问题。

上面的代码是否正确呢?我们重命名了结构体类型名,并且在结构体成员中也用了重命名后的类型名。这样做是不对的,因为我们是要重定义这个结构体类型的类型名,上面的代码是在没有重定义之前就使用了,打破了顺序的问题。
2、结构体内存对齐
2.1对齐现象
在介绍之前我们可以先猜一下结构体类型是怎么计算大小的呢?

上面两个结构体类型成员变量相同,都是两个char类型和一个int类型,那两个结构体类型的大小会是6个字节吗?
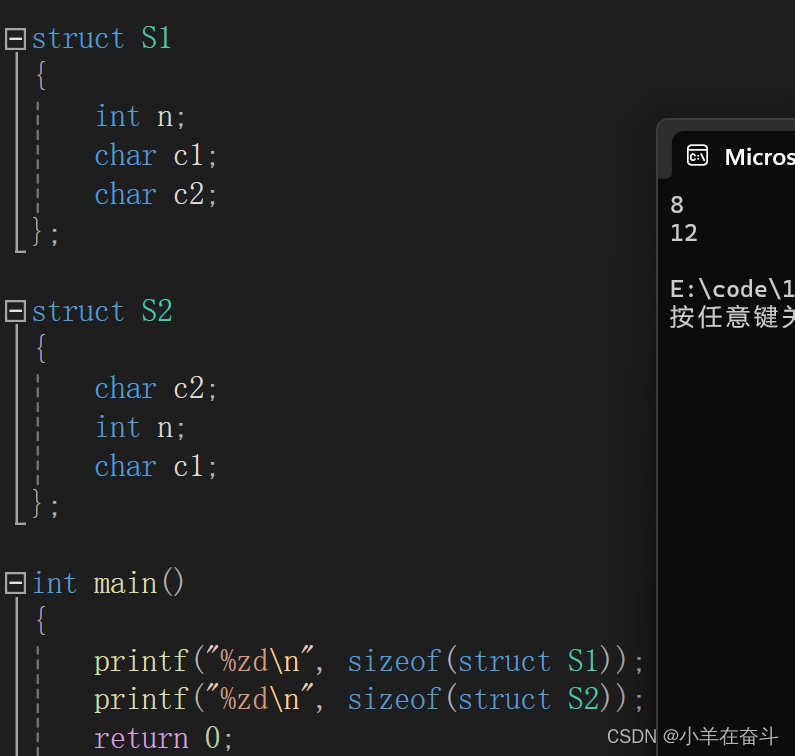
可以看到结果并不是我们猜测的,而且上面两个结构体类型只是改变了成员变量的顺序,它们的大小就发生了变化。那我们可以得到的结论是,结构体类型的大小并不是单纯的成员变量类型大小之和,而且结构体类型的大小还跟成员顺序有关系。这是为什么呢?
其实,结构体的成员在内存中是存在对齐现象的。

接着我们就来探讨一下上面两个结构体类型的大小为什么是8个字节和12个字节。假设上面是一块内存,一小格表示一个字节,第一个字节相较于起始位置偏移量为1,第二个字节相较于起始位置偏移量为2,以此类推,这就是偏移量的概念。
用结构体类型 struct S1 创建一个结构体变量s,假设s从第0个字节开始,我们知道s的大小是8个字节,那其成员n、c1、c2分别在哪个位置呢?这里再介绍一个宏 offsetof ,它的作用是计算结构体成员相较于结构体变量起始位置的偏移量。
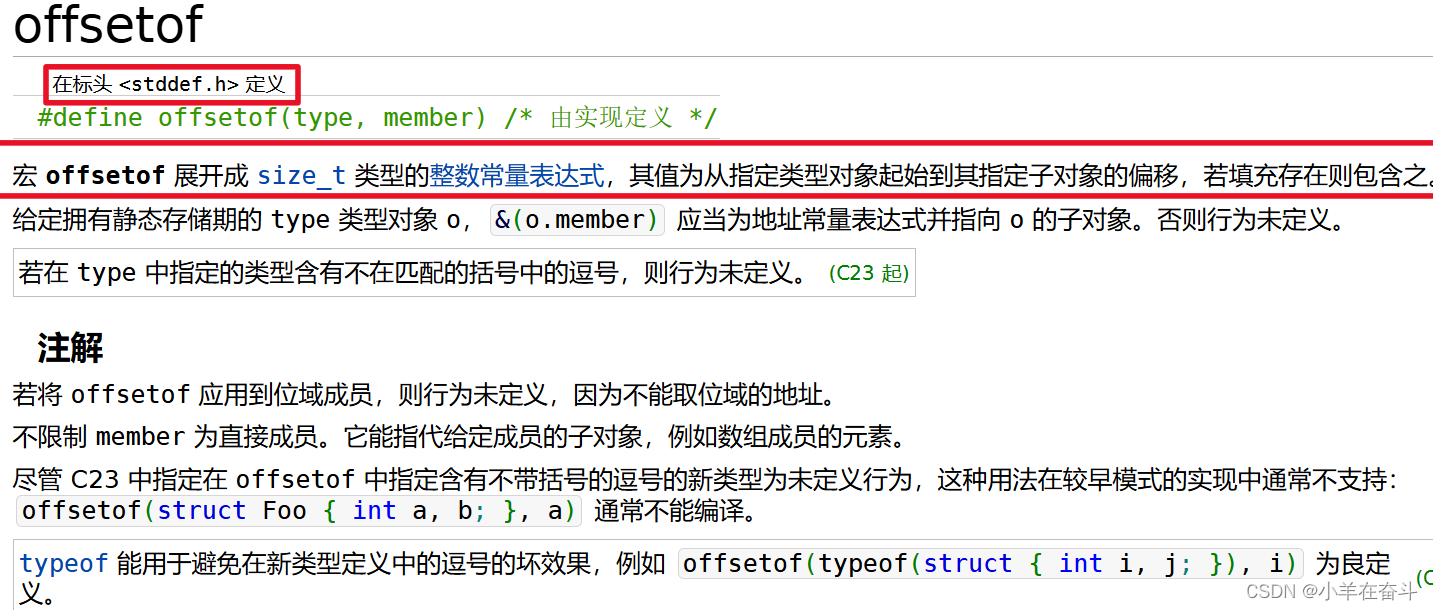

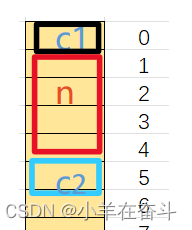
可以看到n的偏移量为0,c1的偏移量为4,c2的偏移量为5。也就是说这三个结构体成员在内存是像下面这样存的。
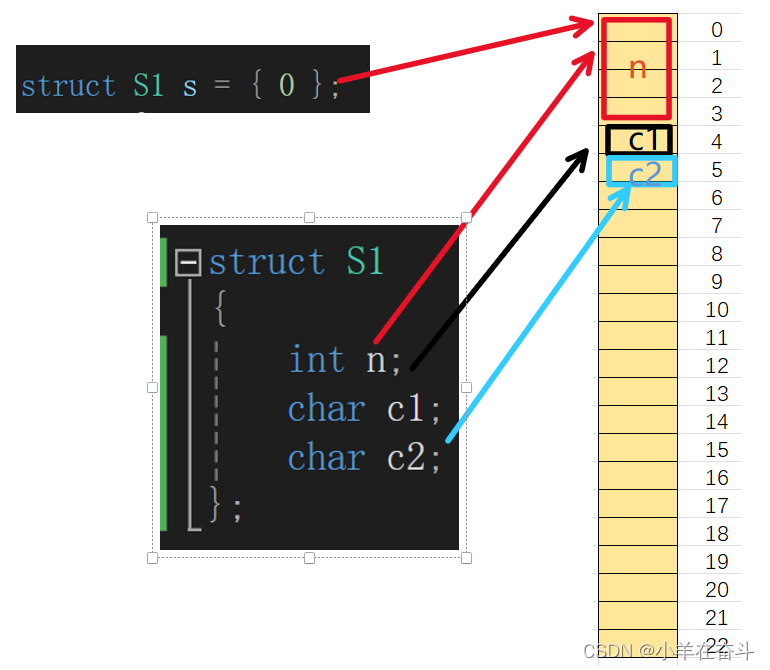
但是,这也不够8个字节啊,难道说结构体变量s即使用不到第6、7个字节但还是将这两个字节霸占了吗?是的,这两个字节就相当于浪费掉了。
那用结构体类型 struct S2 创建的结构体变量所占的12个字节里n、c1、c2三个成员变量是存在哪些位置呢?

可以看到c2的偏移量为0,n的偏移量为4,c1的偏移量为8。也就是说这三个结构体成员在内存中是像下面这样存的。
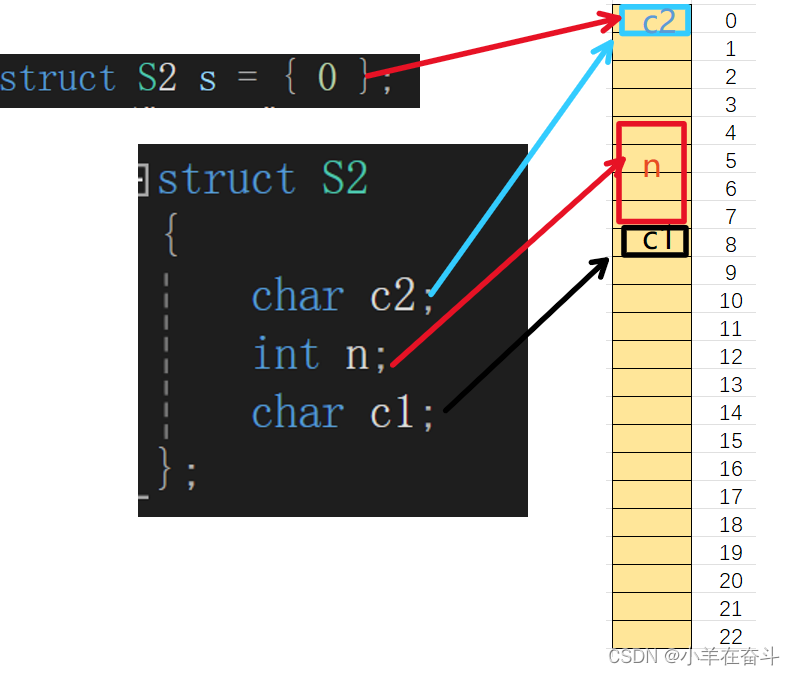
可以看到上面也没有12个字节,并且把第1、2、3、9、10、11个字节都浪费了。那这又是为什么呢?
通过上面的内容我们可以得到的结论是,结构体成员在内存中存的时候并不是一个挨着一个存的,而是按一定的规则存储的,这个规则就是结构内存对齐。
2.2对齐规则
如果我们想要计算结构体类型的大小,就必须要先了解结构体的内存对齐,才能知道结构体类型在内存中究竟是如何开辟空间的。具体的对齐规则如下:
(1)结构体的第一个成员(不管是什么类型)对齐到和结构体变量起始位置偏移量为0的地址处;
(2)其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处;
对齐数 = 编译器默认的一个对齐数 与 该成员变量大小的较小值,VS中默认的值为8,Linux中gcc没有默认对齐数,对齐数就是成员自身的大小.
(3)结构体总大小为最大对齐数(结构体中每个成员变量都有一个对齐数,所有对齐数中最大的)的整数倍;
(4)如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍。
了解了对齐规则,我们就来解释一下上面两个结构体类型的大小为什么是8个字节和12个字节。
先看结构体类型 struct S1,根据规则(1),我们知道n存在第0、1、2、3这四个字节中。根据规则(2),VS默认对齐数是8,c1的大小为1小于默认对齐数,c1要对齐到1的整数倍的地址处,所以c1存到了第4个字节中;再看c2,c2的大小也是1小于默认对齐数,c2要对齐到1的整数倍的地址处,所以c2存到了第5个字节中。根据规则(3),结构体成员中最大对齐数为4,此时结构体成员所占6个字节,不是4的倍数,所以还要再额外占用两个字节的空间,那这两个字节的空间就被浪费掉了。所以最终这个结构体类型的大小就是8个字节。
再看结构体类型 struct S2,根据规则(1),我们知道c2存在第0个字节中。根据规则(2),VS默认对齐数是8,n的大小为4小于默认对齐数,n要对齐到4的整数倍的地址处,所以n存到了第4、5、6、7个字节中,那第1、2、3个字节就被浪费掉了;再看c1,c1的大小是1小于默认对齐数,c1要对齐到1的整数倍的地址处,所以c1存到了第8个字节中。根据规则(3),结构体成员中最大对齐数为4,此时结构体成员所占9个字节,不是4的倍数,所以还要再额外占用三个字节的空间,那这三个字节的空间也被浪费掉了。所以最终这个结构体类型的大小就是12个字节。
再来通过下面这个练习理解规则(4):

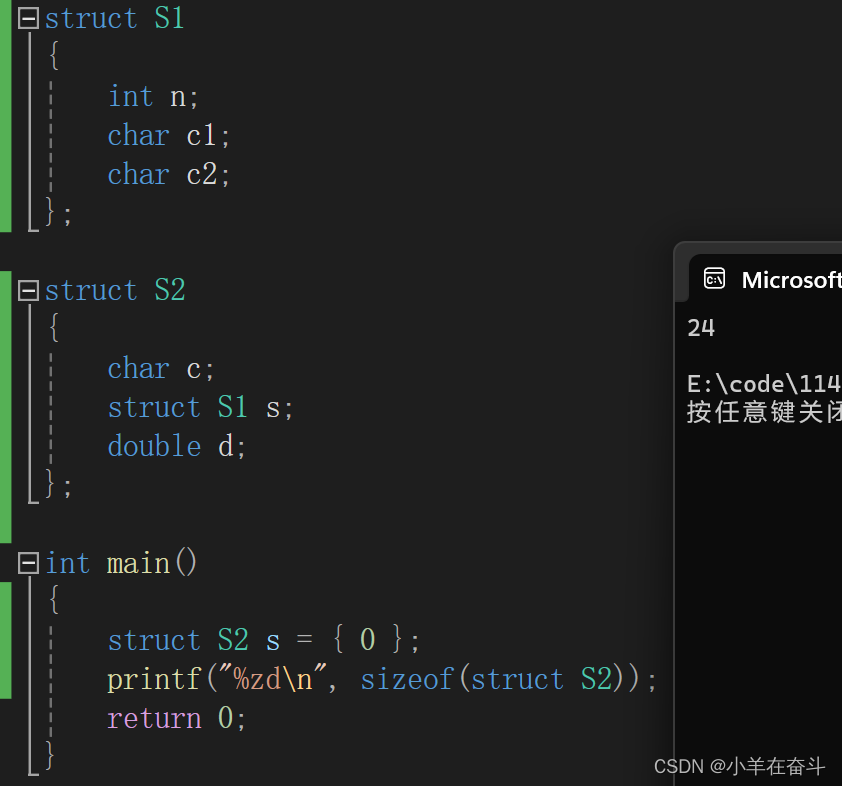
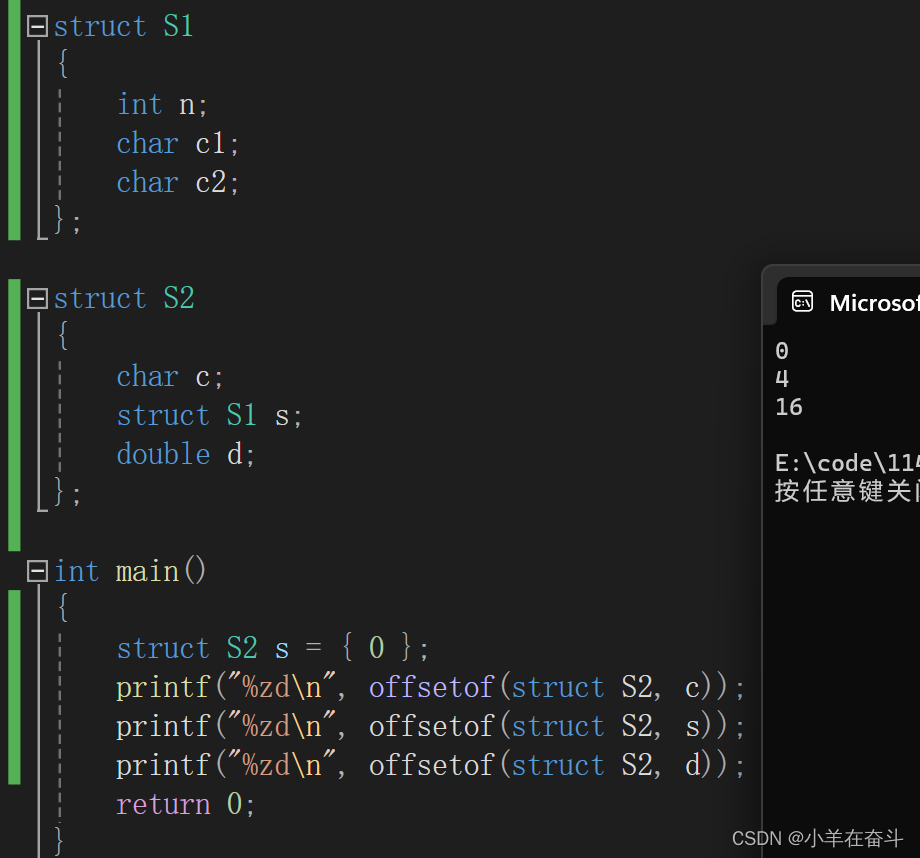
可以看到结构体类型 struct S2 的大小是24个字节,三个结构体成员的偏移量分别为0、4和16。那么其成员变量在内存中的存储就应该是这样:

其中结构体变量s的大小是8个字节,其结构体类型中成员变量最大对齐数为4,而对于结构体类型 struct S2 其成员变量中最大对齐数为8,所以最终结构体类型的大小就是24。
2.3为什么存在内存对齐
通过上面的学习我们知道内存对齐的时候很容易就浪费了内存空间,那为什么还要存在内存对齐呢? 大部分的参考资料都是这样说的:
(1)平台原因(移植原因)
不是所有的硬件平台都能访问任意地址上的任意数据的,某些硬件平台只能在某些地址处取某些特定类型的数据,比如只能取int类型,那就只能访问4的倍数的内存空间,否则抛出硬件异常。
(2)性能原因
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要做两次内存访问,而对齐的内存访问仅需要一次访问。假设一个处理器总是从内存中取8个字节,则地址必须是8的倍数。如果我们能保证将所有的double类型的数据的地址都对齐成8的倍数,那么就可以用一个内存操作来读或写了。否则,我们可能需要执行两次内存访问,因为对象可能被分在两个8字节内存块中。
什么意思呢?假设创建一个结构体类型,其中成员变量为char类型的c和int类型的n。
下面是不考虑对齐的情况,直接在c后面存n:

下面是考虑对齐的情况:

因为n为int类型,考虑对齐的话c后面三个字节的空间就浪费掉了。
假设我们现在要用一个32位的机器去访问这个结构体的成员变量n,32位的机器一次能访问4个字节的内存,那在开始位置访问不考虑对齐的情况时需要访问两次才能读取完整的n,但是在访问考虑对齐的情况时只需要访问一次就行了,因为n前面刚好是4个字节可以跳过就没有必要访问前面的内存了,这样的话效率就会提高。
总的来说:结构体的内存对齐是拿空间来换取时间的做法。
那在设计结构体的时候,我们既要满足对齐,又要节省空间,如何做到呢?
有一个小技巧:让占用空间小的成员尽量集中在一起。就像前面我们创建的 struct S1 和 struct S2 一样,虽然两个成员一样,但是成员顺序不一样最终两个结构体类型的大小也就不一样了。
2.4修改默认对齐数
#pragma 这个预处理指令,可以改变编译器的默认对齐数。

上面结构体类型 struct S 的大小在默认对齐数下是12个字节。
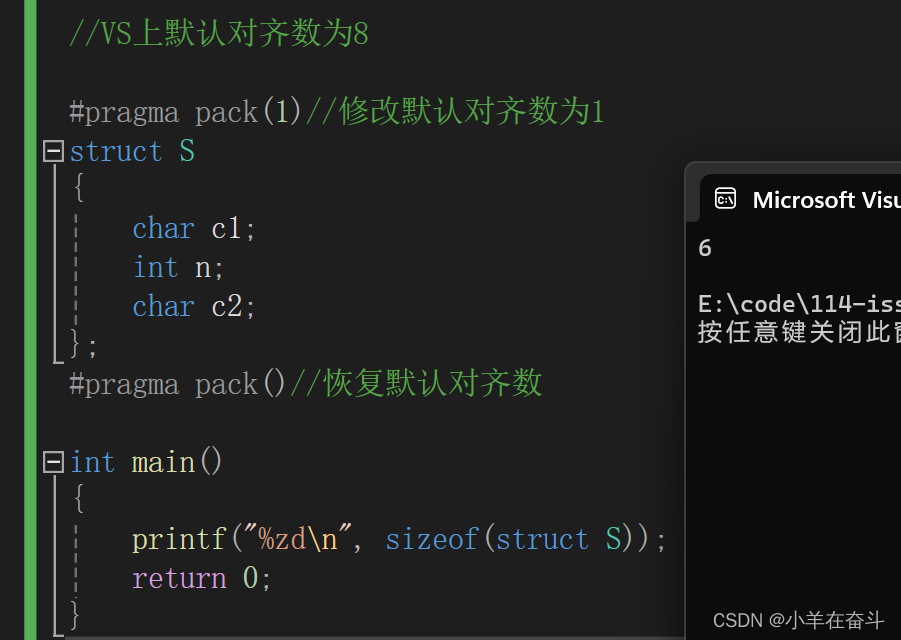
当我们将默认对齐数改为1时,结构体类型 struct S 的大小就变成了6个字节。因为结构体成员c1、n、c2的大小分别为1、4、1,而默认对齐数是1的时候,其每个成员的对齐数都为1,就相当于没有对齐,是紧挨着存储的。
默认对齐数一般修改的都是2的次方数。
3、结构体传参
来看下面的代码:
#include <stdio.h>struct S
{int arr[1000];char ch;int n;
};void print1(struct S tmp)
{int i = 0;for (i = 0; i < 10; i++){printf("%d ", tmp.arr[i]);}printf("\n");printf("ch = %c\n", tmp.ch);printf("n = %d\n", tmp.n);
}void print2(struct S* tmp)
{int i = 0;for (i = 0; i < 10; i++){printf("%d ", tmp->arr[i]);}printf("\n");printf("ch = %c\n", tmp->ch);printf("n = %d\n", tmp->n);
}int main()
{struct S s = { {1,2,3,4,5,6,7,8,9,10}, 'a', 8 };print1(s);print2(&s);return 0;
}上面写了两个函数print1和print2打印结构体变量s的内容,print1用的是传值调用,print2用的是传址调用,哪个更好呢?
答案是传址调用更好。传值调用时形参tmp是拷贝了一份结构体变量s,需要压栈,要开辟一块和s大小相等的内存空间,而且拷贝的过程也是需要时间的,所以时间和空间上都要消耗;而传址调用指针tmp只需要接收一个4个字节或8个字节的地址就行,并不需要额外开辟新的空间,并且还没有拷贝过程中时间的消耗。
另外,传值调用能做到的传址调用都能做到,但是传址调用能做到的传值调用未必都能做到,比如间接修改内存中的值。要是我们不想指针指向的对象被修改也可以加上const修饰,这样就没什么后顾之忧了。
所以,结构体传参的时候,要传结构体的地址。
4、结构体实现位段
4.1什么是位段
位段的声明和结构体是类似的,有两个不同:
(1)位段的成员必须是 int、unsigned int 或 signed int,在c99中位段成员的类型也可以选择其他类型。
(2)位段的成员名后边有一个冒号和一个数字。
来看结构体和位段声明的比较:

位段中的位指的是二进制位也就是比特位,所以能想到的是位段中冒号后面的数字指的就是比特位,其中_a占2个比特位,_b占5个比特位,_c占10个比特位,_d占30个比特位。(成员名前面的_只是编程习惯没有特殊意思)。而int型大小是4个字节最大32位,所以不能超过这个数。
为什么要有位段呢?
以前我们在写代码的时候,有没有想过这样一个问题。就是说我们创建了一个整型变量_a,它占4个字节,但是这个_a我们只是想让它表示0、1、2、3这四个值,而这四个值二进制表示为00、01、10、11只需要2个比特位就行了,那我们还给它开辟一个32位的空间是不是太浪费了。同样的如果_b只需要5个比特位就够了,_c只需要10个比特位就够了,_d只需要30个比特位就够了,那我们就没有必要给它们都开辟4个字节的内存空间了。
为了实现这种比较精准的内存大小的开辟,位段就出现了。我们只需要按它们的需求开辟相应大小的内存空间,就能避免很多不必要的浪费。我们用上面声明的结构体和位段来做个验证,结构体的大小是16个字节,位段是不是真的变小了呢?

可以看到位段所占内存是结构体的一半。但是_a_b_c_d加起来一共是47个比特位,按道理来说6个字节就够了,为什么是8个字节呢?这跟位段的内存分配有关。
4.2位段的内存分配
(1)位段的成员可以是 int、unsigned int、signed int 或者是 char 类型;
(2)位段的空间上是按照需要以4个字节(int)或1个字节(char)的方式来开辟的;
(3)位段涉及很多不确定的因素,位段是不跨平台的,注重可移植的程序应避免使用位段。
那位段到底是如何分配内存的呢?
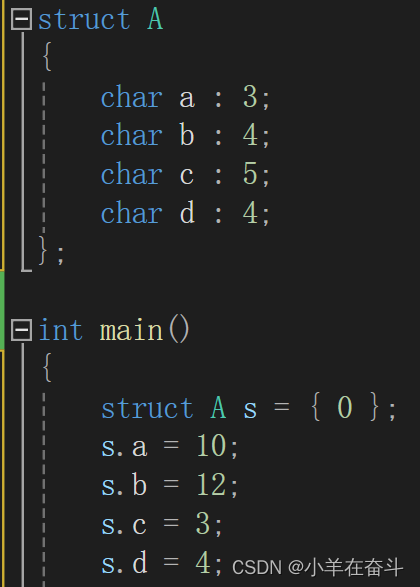
以上面这个位段为例,char类型一次开辟8个比特位,而a只需要占用3个比特位就行,但是这时候就有个问题,a是从左往右存呢还是从右往左存呢(左右或上下都是一样的,这里以左右为例),这是不确定的,不妨假设是从右向左存的。a存好占用了3个比特位,剩下的5个比特位还足够存b,存好b后只剩下1个比特位不够存c了,还需要再开辟8个比特位,那这时候又有个问题,剩下的那一个比特位是浪费掉呢还是存一部分c呢,这也是不确定的,不妨我们再假设不够存下一个数据的话就浪费掉。在开辟的第二个字节中存好c后还剩3个比特位不足以存d,还需要再开辟一个字节存d,按我们的假设需要开辟3个字节的空间。
开辟好内存空间后,就需要给相应的成员变量赋值,10的二进制表示是1010,但是a只有3个比特位,所以a中只存了010;12的二进制表示是1100,所以b中存了1100;3的二进制表示是11,所以c中存了00011;4的二进制表示是100,所以d中存了0100。
如果真按如上我们假设的存储方式存储,那在内存中应该是下面这样:

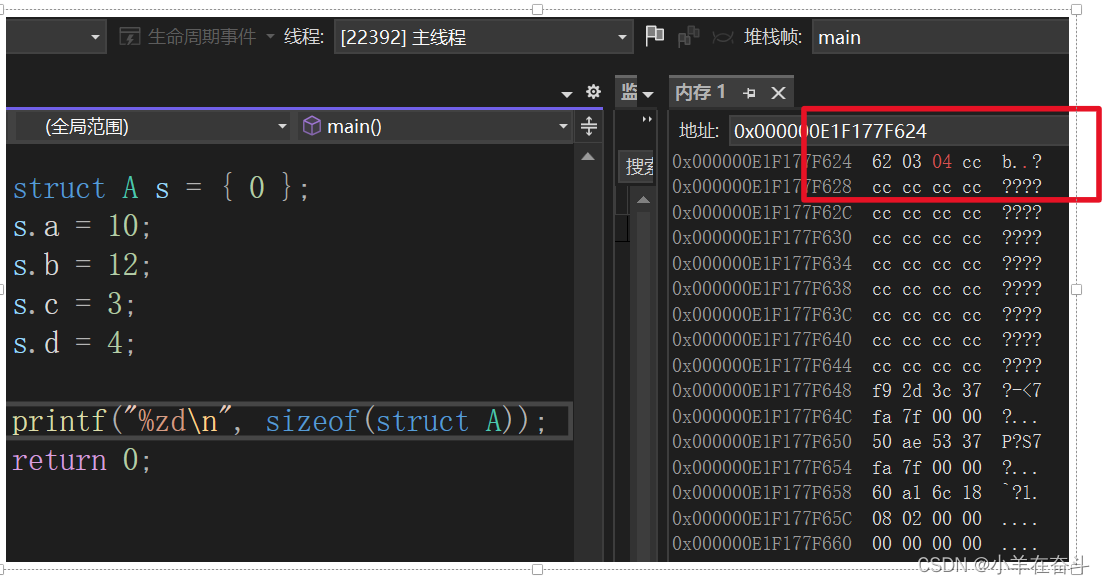
可以看到,在当前VS环境下,我们的分析是正确的。了解了位段的内存分配,我们再回到上面的问题,为什么下面这个位段是8个字节而不是6个字节。
一个int类型是32位,存好_a_b_c需要17个比特位,剩下15个比特位显然不足以存_d,所以还需要再开辟4个字节的空间存_d,所以总共需要8个字节,而不是6个字节。
4.3位段的跨平台问题
(1)int 位段被当成有符号数还是无符号数是不确定的;
(2)位段中最大位的数目不能确定(16位机器最大16,32位机器最大32,写成27,在16位机器中会出问题);
(3)位段中的成员在内存中从左向右分配,还是从右向左分配,标准尚未定义;
(4)当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余位还是利用,这是不确定的。
总结:跟结构相比,位段可以达到同样的效果,并且可以很好的节省空间,但是有夸平台的问题。
4.4位段使用的注意事项
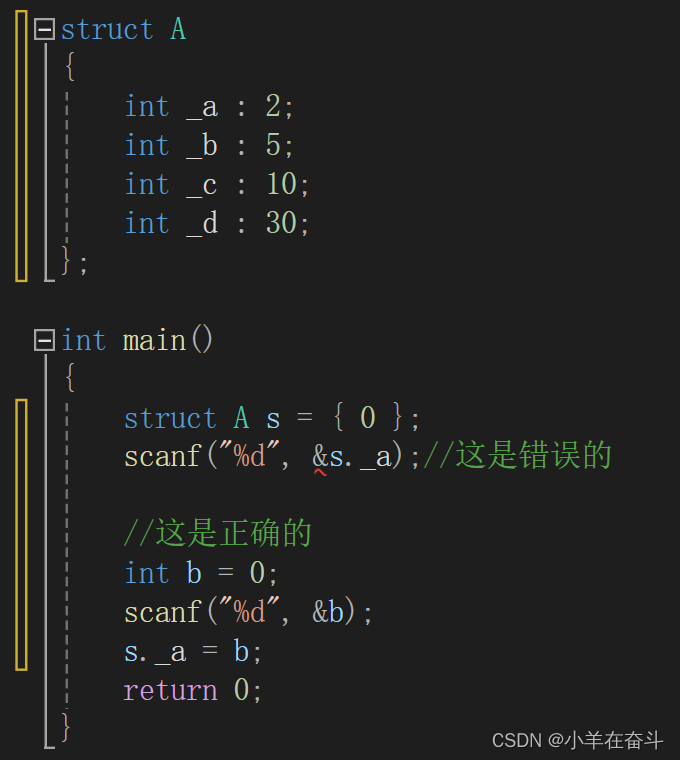
位段的几个成员可能共有同一个字节的地址,这样有些成员的起始位置并不是某个字节的起始位置,那么这些位置处是没有地址的。内存中每个字节分配一个地址,一个字节内部的比特位是没有地址的。
所以不能对位段的成员使用&操作符,这样就不能使用scanf直接给位段的成员输入值,只能是先输入放在一个变量中,然后赋值给位段的成员。
如果觉得我的文章还不错,请点赞、收藏 + 关注支持一下,我会持续更新更好的文章。
相关文章:
C语言(结构体)
Hi~!这里是奋斗的小羊,很荣幸各位能阅读我的文章,诚请评论指点,欢迎欢迎~~ 💥个人主页:小羊在奋斗 💥所属专栏:C语言 本系列文章为个人学习笔记,在这里撰写成文一…...
用法:深入解析与实战应用)
Python filter()用法:深入解析与实战应用
Python filter()用法:深入解析与实战应用 在Python编程中,filter() 函数是一个内置的高阶函数,它用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该函数在数据处理和筛选时非常有用࿰…...
k8s集群的存储卷、pvc和pv
目录 简介 简介 PV 全称叫做 Persistent Volume,持久化存储卷。它是用来描述或者说用来定义一个存储卷的,这个通常都是由运维工程师来定义。 PVC 的全称是 Persistent Volume Claim,是持久化存储的请求。它是用来描述希望使用什么样的或者说…...

二分搜索树深度优先遍历
二分搜索树深度优先遍历 二分搜索树(Binary Search Tree,简称BST)是一种特殊的二叉树,它具有以下特性:对于树中的任意节点,其左子树中的所有元素都小于该节点的值,其右子树中的所有元素都大于该…...

ImportError: cannot import name ‘packaging‘ from ‘pkg_resources‘‘
参考自: [Bug]: ImportError: cannot import name packaging from pkg_resources (/usr/local/lib/python3.10/dist-packages/pkg_resources/__init__.py) Issue #15863 AUTOMATIC1111/stable-diffusion-webui GitHub ImportError: cannot import name packaging from pkg…...

灯塔歌曲音乐下载官网
灯塔歌曲音乐下载官网网址:www.dengtamp3.com 灯塔音乐下载上线以“用心服务,认真负责”为核心价值。 我们的团队是一个青春的团队,朝气蓬勃。我们采用最新的服务模式,以网为媒为广大客户提供服务,我们坚持以“用心&a…...

数据结构的归并排序(c语言版)
一.归并排序的基本概念 1.基本概念 归并排序是一种高效的排序算法,它采用了分治的思想。它的基本过程如下: 将待排序的数组分割成两个子数组,直到子数组只有一个元素为止。然后将这些子数组两两归并,得到有序的子数组。不断重复第二步,直到最终得到有序的整个数组。 2.核心…...

ubuntu使用Docker笔记
一、参考资料 1、B站视频 尚硅谷Docker实战教程 2、有心人整理的笔记 Docker笔记(周阳版) 3、菜鸟教程 Docker 教程 以下是本人的折腾实践。 二、Docker的安装 2.1、使用清华源安装docker,清华源官方教程。 本人是在ubuntu20.04下安装的…...

PHP编程入门:揭开Web开发的神秘面纱
PHP编程入门:揭开Web开发的神秘面纱 在数字化时代,PHP作为一种广泛使用的服务器端脚本语言,为Web开发领域注入了强大的活力。无论你是编程新手还是有一定经验的开发者,掌握PHP编程都将为你开启一扇通往Web开发新世界的大门。接下…...
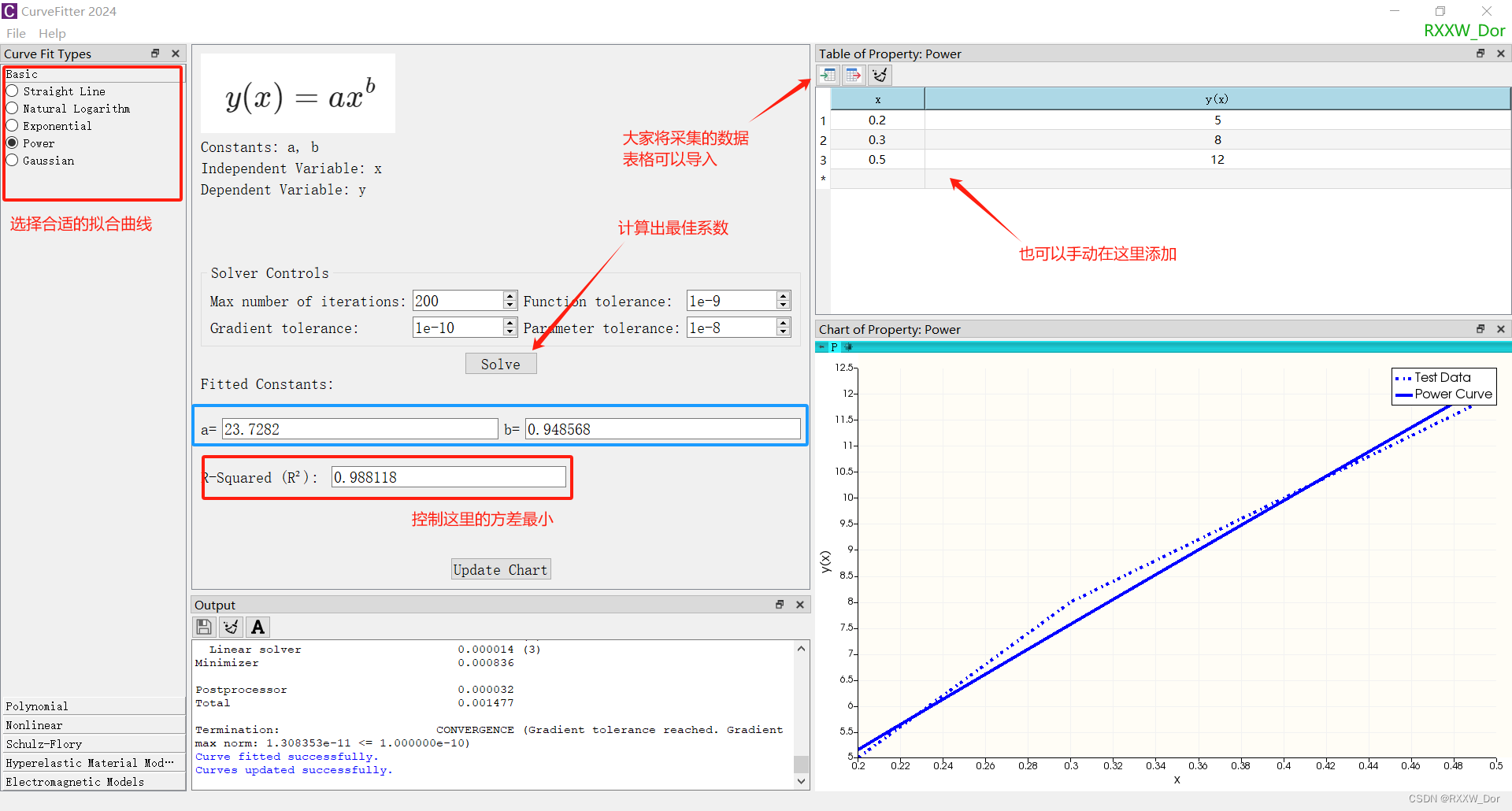
曲线拟合工具软件(免费)
曲线拟合是数据处理中经常用到的数值方法,本质是使用某一个模型(方程或者方程组)将一系列离散的数据拟合成平滑的曲线或者曲面,数值求解出对应的函数参数,大家可以利用MATLAB的曲线拟合工具箱也可以使用第三方的拟合软件,今天我们介绍Welsim免费的曲线拟合软件 1、MATLA…...
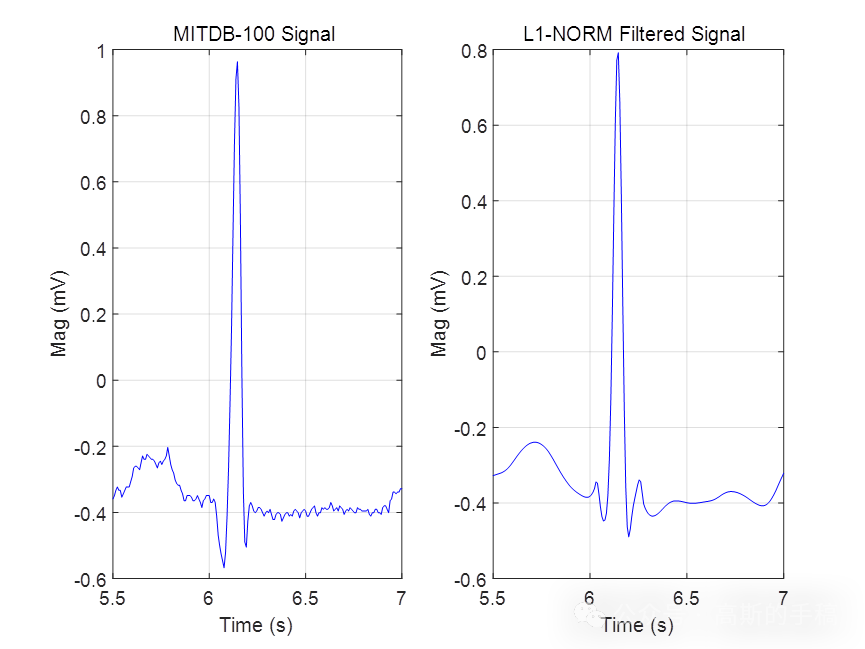
基于L1范数惩罚的稀疏正则化最小二乘心电信号降噪方法(Matlab R2021B)
L1范数正则化方法与Tikhonov正则化方法的最大差异在于采用L1范数正则化通常会得到一个稀疏向量,它的非零系数相对较少,而Tikhonov正则化方法的解通常具有所有的非零系数。即:L2范数正则化方法的解通常是非稀疏的,并且解的结果在一…...
)
Bitbucket的原理及应用详解(一)
本系列文章简介: 在数字化和全球化的今天,软件开发和项目管理已经成为企业成功的关键因素之一。随着团队规模的扩大和项目的复杂化,如何高效地协同开发、管理代码和确保代码质量成为了开发者和管理者面临的重要挑战。Bitbucket作为一款功能强…...

企业级win10电脑下同时存在Python3.11.7Python3.6.6,其中Python3.6.6是后装的【过程与踩坑复盘】
背景: 需要迁移原始服务器的上的Python3.6.6+Flask项目到一个新服务器上, 新服务器上本身存在一个Python3.11.7, 所以这涉及到了一个电脑需要装多个Python版本的问题 过程: 1-确定新电脑版本【比如是32还是64位】 前面开发人员存留了两个包,是python-3.6.6.exe和pytho…...

泛微开发修炼之旅--03常用数据表结构讲解
文章链接:泛微开发修炼之旅--03常用数据表结构讲解...

MySQL8找不到my.ini配置文件以及报sql_mode=only_full_group_by解决方案
一、找不到my.ini配置文件 MySQL 8 安装或启动过程中,如果系统找不到my.ini文件,通常意味着 MySQL服务器没有找到其配置文件。在Windows系统上,MySQL 8 预期使用my.ini作为配置文件,而不是在某些情况下用到的my.cnf文件。 通过 …...

Android 13 亮度调节代码分析
frameworks\base\packages\SystemUI\res\layout\quick_settings_brightness_dialog.xml 进度条控件 <com.android.systemui.settings.brightness.BrightnessSliderViewxmlns:android"http://schemas.android.com/apk/res/android"android:id"id/brightness…...
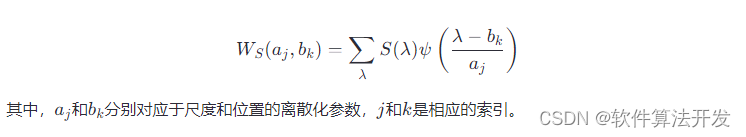
基于小波变换和峰值搜索的光谱检测matlab仿真,带GUI界面
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 基于小波变换和峰值搜索的光谱检测matlab仿真,带GUI界面.对光谱数据的成分进行提取,分析CO2,SO2,CO以及CH4四种成分比例。 2.…...

【初识Objective-C】
Objective-C学习 什么是OCOC的特性OC跑的第一个程序helloworld OC的一些基础知识标识符OC关键字数据类型字符型c字符串为什么NSString类型定义时前面要加和普通的c对象有什么区别 一些基础知识if语句switch语句三种循坏语句for循环:用于固定次数的循环while循环&…...
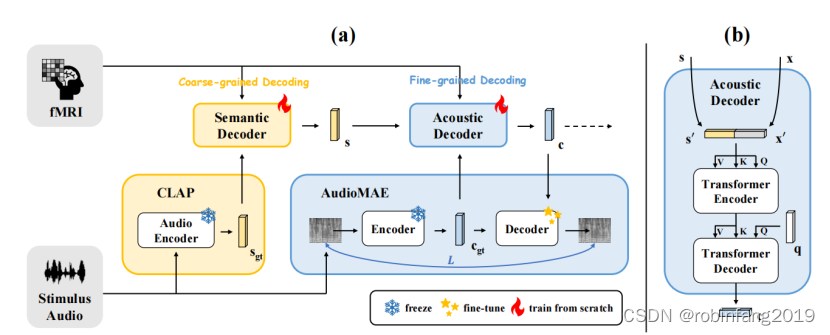
从功能性磁共振成像(fMRI)数据重建音频
听觉是人类最重要的感官之一,它负责接收外部的听觉刺激,并将这些信息传递给大脑进行处理和理解。研究人员正致力于从神经科学和计算机科学两个领域探索人脑的听觉感知机制。一个关键目标是从人脑中解码神经信息,并重建原始的刺激。常见的大脑…...

前端Vue小兔鲜儿电商项目实战Day04
一、二级分类 - 整体认识和路由配置 1. 配置二级路由 ①准备组件模板 - src/views/SubCategory/index.vue <script setup></script><template><div class"container"><!-- 面包屑 --><div class"bread-container">…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...