机器学习18个核心算法模型
1. 线性回归(Linear Regression)
用于建立自变量(特征)和因变量(目标)之间的线性关系。
核心公式:
简单线性回归的公式为: , 其中
是预测值,
是截距,
是斜率,
是自变量。
代码案例:
from sklearn.linear_model import LinearRegression
import numpy as np# 创建一些随机数据
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])# 拟合模型
model = LinearRegression().fit(X, y)# 预测
y_pred = model.predict(X)print("预测值:", y_pred)
2. 逻辑回归(Logistic Regression)
用于处理分类问题,通过一个 S 形的函数将输入映射到 0 到 1 之间的概率。
核心公式:
逻辑回归的公式为: 其中
是给定输入
下预测
为 1 的概率,
是截距,
是权重,
是自然常数。
代码案例:
from sklearn.linear_model import LogisticRegression
import numpy as np# 创建一些随机数据
X = np.array([[1], [2], [3], [4]])
y = np.array([0, 0, 1, 1])# 拟合模型
model = LogisticRegression().fit(X, y)# 预测
y_pred = model.predict(X)print("预测值:", y_pred)
3. 决策树(Decision Tree)
通过一系列决策来学习数据的分类规则或者数值预测规则,可解释性强。
核心公式:
决策树的核心在于树的构建和节点分裂的规则,其本身没有明确的数学公式。
代码案例:
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 载入数据
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = DecisionTreeClassifier()
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)4. 支持向量机(Support Vector Machine,SVM)
用于分类和回归分析的监督学习模型,能够在高维空间中构造超平面或超平面集合,实现对数据的有效分类。
核心公式:
SVM 的目标是找到一个最优超平面,使得两个类别的间隔最大化。分类器的决策函数为:
。 其中
是要分类的样本,
是支持向量,
是对应支持向量的系数,
是支持向量的标签,
是核函数,
是偏置。
代码案例:
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 载入数据
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = SVC()
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
5. 朴素贝叶斯(Naive Bayes)
基于贝叶斯定理和特征条件独立假设的分类算法,常用于文本分类和垃圾邮件过滤。
核心公式:
朴素贝叶斯分类器基于贝叶斯定理计算后验概率,其公式为:其中
是给定特征
下类别
的后验概率,
是类别
的先验概率
是在类别
下特征
的条件概率,
是特征
的联合概率。
代码案例:
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 载入数据
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = GaussianNB()
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)6. K近邻算法(K-Nearest Neighbors,KNN)
一种基本的分类和回归方法,它的基本假设是“相似的样本具有相似的输出”。
核心公式:
KNN 的核心思想是根据输入样本的特征,在训练集中找到与之最接近的 个样本,然后根据这 个样本的标签来预测输入样本的标签。没有明确的数学公式,其预测公式可以简单表示为投票机制。
代码案例:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 载入数据
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = KNeighborsClassifier()
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
7. 聚类算法(Clustering)
聚类是一种无监督学习方法,将数据集中的样本划分为若干组,使得同一组内的样本相似度较高,不同组之间的样本相似度较低。
核心公式:
常见的聚类算法包括 K 均值聚类和层次聚类等,它们的核心在于距离计算和簇的更新规则。
代码案例:
这里以 K 均值聚类为例。
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt# 创建一些随机数据
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)# 训练模型
model = KMeans(n_clusters=4)
model.fit(X)# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=model.labels_, s=50, cmap='viridis')
centers = model.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.5)
plt.show()8. 神经网络(Neural Networks)
神经网络是一种模拟人脑神经元网络的计算模型,通过调整神经元之间的连接权重来学习数据的复杂关系。
核心公式:
神经网络的核心在于前向传播和反向传播过程,其中涉及到激活函数、损失函数等。
代码案例:
这里以使用 TensorFlow 实现一个简单的全连接神经网络为例。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 创建一些随机数据
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建神经网络模型
model = Sequential([Dense(64, activation='relu', input_shape=(20,)),Dense(64, activation='relu'),Dense(1, activation='sigmoid')
])# 编译模型
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print("准确率:", accuracy)
9. 集成方法(Ensemble Methods)
集成方法通过组合多个基分类器(或回归器)的预测结果来改善泛化能力和准确性。
核心公式:
集成方法的核心在于不同的组合方式,常见的包括 Bagging、Boosting 和随机森林等。
代码案例:
这里以随机森林为例。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 载入数据
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
10. 降维算法(Dimensionality Reduction)
降维算法用于减少数据集的维度,保留数据集的重要特征,可以用于数据可视化和提高模型性能。
核心公式:
主成分分析(PCA)是一种常用的降维算法,其核心是通过线性变换将原始数据映射到一个新的坐标系中,选择新坐标系上方差最大的方向作为主要特征。
代码案例:
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris# 载入数据
iris = load_iris()
X = iris.data# 使用 PCA 进行降维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)print("降维后的数据维度:", X_pca.shape)11. 主成分分析(Principal Component Analysis,PCA)
主成分分析是一种常用的降维算法,用于发现数据中的主要特征。
核心公式:
PCA 的核心是特征值分解,将原始数据的协方差矩阵分解为特征向量和特征值,通过选取特征值较大的特征向量进行降维。
代码案例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris# 载入数据
iris = load_iris()
X = iris.data
y = iris.target# 使用 PCA 进行降维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)# 可视化降维结果
plt.figure(figsize=(8, 6))
for i in range(len(np.unique(y))):
plt.scatter(X_pca[y == i, 0], X_pca[y == i, 1], label=iris.target_names[i])
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of IRIS dataset')
plt.legend()
plt.show()
12. 支持向量回归(Support Vector Regression,SVR)
SVR 是一种使用支持向量机(SVM)进行回归分析的方法,能够有效处理线性和非线性回归问题。
核心公式:
SVR 的核心在于损失函数的定义和对偶问题的求解,其目标是最小化预测值与真实值之间的误差,同时保持预测值尽可能接近真实值。具体公式比较复杂,无法简单表示。
代码案例:
from sklearn.svm import SVR
import numpy as np
import matplotlib.pyplot as plt# 创建一些随机数据
X = np.sort(5 * np.random.rand(100, 1), axis=0)
y = np.sin(X).ravel()# 添加噪声
y[::5] += 3 * (0.5 - np.random.rand(20))# 训练模型
model = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=.1)
model.fit(X, y)# 预测
X_test = np.linspace(0, 5, 100)[:, np.newaxis]
y_pred = model.predict(X_test)# 可视化结果
plt.scatter(X, y, color='darkorange', label='data')
plt.plot(X_test, y_pred, color='navy', lw=2, label='prediction')
plt.xlabel('data')
plt.ylabel('target')
plt.title('Support Vector Regression')
plt.legend()
plt.show()
13. 核方法(Kernel Methods)
核方法是一种通过在原始特征空间中应用核函数来学习非线性模型的方法,常用于支持向量机等算法。
核心公式:
核方法的核心在于核函数的选择和应用,常见的核函数包括线性核、多项式核和高斯核等,其具体形式取决于核函数的选择。
代码案例:
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np# 创建一些随机数据
X, y = make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定义一个高斯核支持向量机模型
model = SVC(kernel='rbf', gamma='scale', random_state=42)# 训练模型
model.fit(X_train, y_train)# 可视化决策边界
plt.figure(figsize=(8, 6))
h = .02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title('SVM with RBF Kernel')
plt.show()13. 核方法(Kernel Methods)
核方法是一种通过在原始特征空间中应用核函数来学习非线性模型的方法,常用于支持向量机等算法。
核心公式:
核方法的核心在于核函数的选择和应用,常见的核函数包括线性核、多项式核和高斯核等,其具体形式取决于核函数的选择。
代码案例:
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np# 创建一些随机数据
X, y = make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定义一个高斯核支持向量机模型
model = SVC(kernel='rbf', gamma='scale', random_state=42)# 训练模型
model.fit(X_train, y_train)# 可视化决策边界
plt.figure(figsize=(8, 6))
h = .02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title('SVM with RBF Kernel')
plt.show()
15. 随机森林(Random Forest)
随机森林是一种集成学习方法,通过构建多个决策树来提高分类性能,具有良好的抗过拟合能力和稳定性。
核心公式:
随机森林的核心在于决策树的集成方式和随机性的引入,具体公式比较复杂,涉及到决策树的建立和集成规则。
代码案例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score# 载入数据
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定义一个随机森林模型
model = RandomForestClassifier(n_estimators=100, random_state=42)# 训练模型
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
16. 梯度提升(Gradient Boosting)
梯度提升是一种集成学习方法,通过逐步训练新模型来改善已有模型的预测能力,通常使用决策树作为基础模型。
核心公式:
梯度提升的核心在于损失函数的优化和模型的更新规则,其核心思想是在每一步迭代中拟合一个新模型来拟合之前模型的残差,从而逐步减小残差。
代码案例:
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 载入数据
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)17. AdaBoost(Adaptive Boosting)
AdaBoost 是一种集成学习方法,通过串行训练多个弱分类器,并加大误分类样本的权重来提高分类性能。
核心公式:
AdaBoost 的核心在于样本权重的更新规则和基分类器的组合方式,具体公式涉及到样本权重的调整和分类器权重的更新。
代码案例:
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 载入数据
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = AdaBoostClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
18. 深度学习(Deep Learning)
深度学习是一种基于人工神经网络的机器学习方法,其核心思想是通过多层非线性变换来学习数据的表示。
核心公式:
深度学习涉及到多层神经网络的构建和优化,其中包括前向传播和反向传播等过程,具体公式和算法较为复杂。
代码案例:
这里以使用 TensorFlow 实现一个简单的深度神经网络(多层感知器)为例。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 创建一些随机数据
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建深度神经网络模型
model = Sequential([Dense(64, activation='relu', input_shape=(20,)),Dense(64, activation='relu'),Dense(1, activation='sigmoid')
])# 编译模型
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print("准确率:", accuracy)
相关文章:
机器学习18个核心算法模型
1. 线性回归(Linear Regression) 用于建立自变量(特征)和因变量(目标)之间的线性关系。 核心公式: 简单线性回归的公式为: , 其中 是预测值, 是截距, 是斜…...
)
平滑值(pinghua)
平滑值 题目描述 一个数组的“平滑值”定义为:相邻两数差的绝对值的最大值。 具体的,数组a的平滑值定义为 f ( a ) m a x i 1 n − 1 ∣ a i 1 − a i ∣ f(a)max_{i1}^{n-1}|a_{i1}-a_i| f(a)maxi1n−1∣ai1−ai∣ 现在小红拿到了一个数组…...
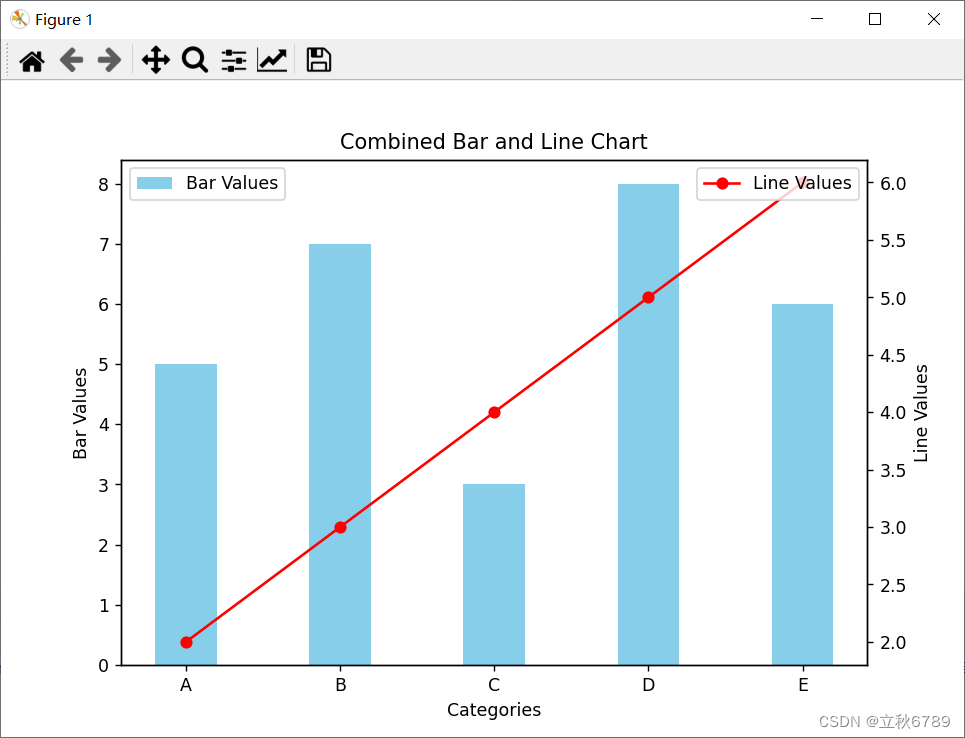
使用matplotlib绘制折线条形复合图
使用matplotlib绘制折线条形复合图 介绍效果代码 介绍 在数据可视化中,复合图形是一种非常有用的工具,可以同时显示多种数据类型的关系。在本篇博客中,我们将探讨如何使用 matplotlib 库来绘制包含折线图和条形图的复合图。 效果 代码 imp…...

云计算中网络虚拟化的核心组件——NFV、NFVO、VIM与VNF
NFV NFV(Network Functions Virtualization,网络功能虚拟化),是一种将传统电信网络中的网络节点设备功能从专用硬件中解耦并转换为软件实体的技术。通过运用虚拟化技术,NFV允许网络功能如路由器、防火墙、负载均衡器、…...

# SpringBoot 如何让指定的Bean先加载
SpringBoot 如何让指定的Bean先加载 文章目录 SpringBoot 如何让指定的Bean先加载ApplicationContextInitializer使用启动入口出注册配置文件中配置spring.factories中配置 BeanDefinitionRegistryPostProcessor使用 使用DependsOn注解实现SmartInitializingSingleton接口使用P…...

家用洗地机哪个品牌好?洗地机怎么选?这几款全网好评如潮
如今,人们家里越来越多的智能清洁家电,小到吸尘器、电动拖把,大到扫地机器人、洗地机,作为一个用过所有这些清洁工具的家庭主妇,我觉得最好用的还是洗地机。它的清洁效果比扫地机器人更好,功能也比吸尘器更…...

iOS与前端:深入解析两者之间的区别与联系
iOS与前端:深入解析两者之间的区别与联系 在数字科技高速发展的今天,iOS与前端技术作为两大热门领域,各自在移动应用与网页开发中扮演着不可或缺的角色。然而,这两者之间究竟存在哪些差异与联系呢?本文将从四个方面、…...
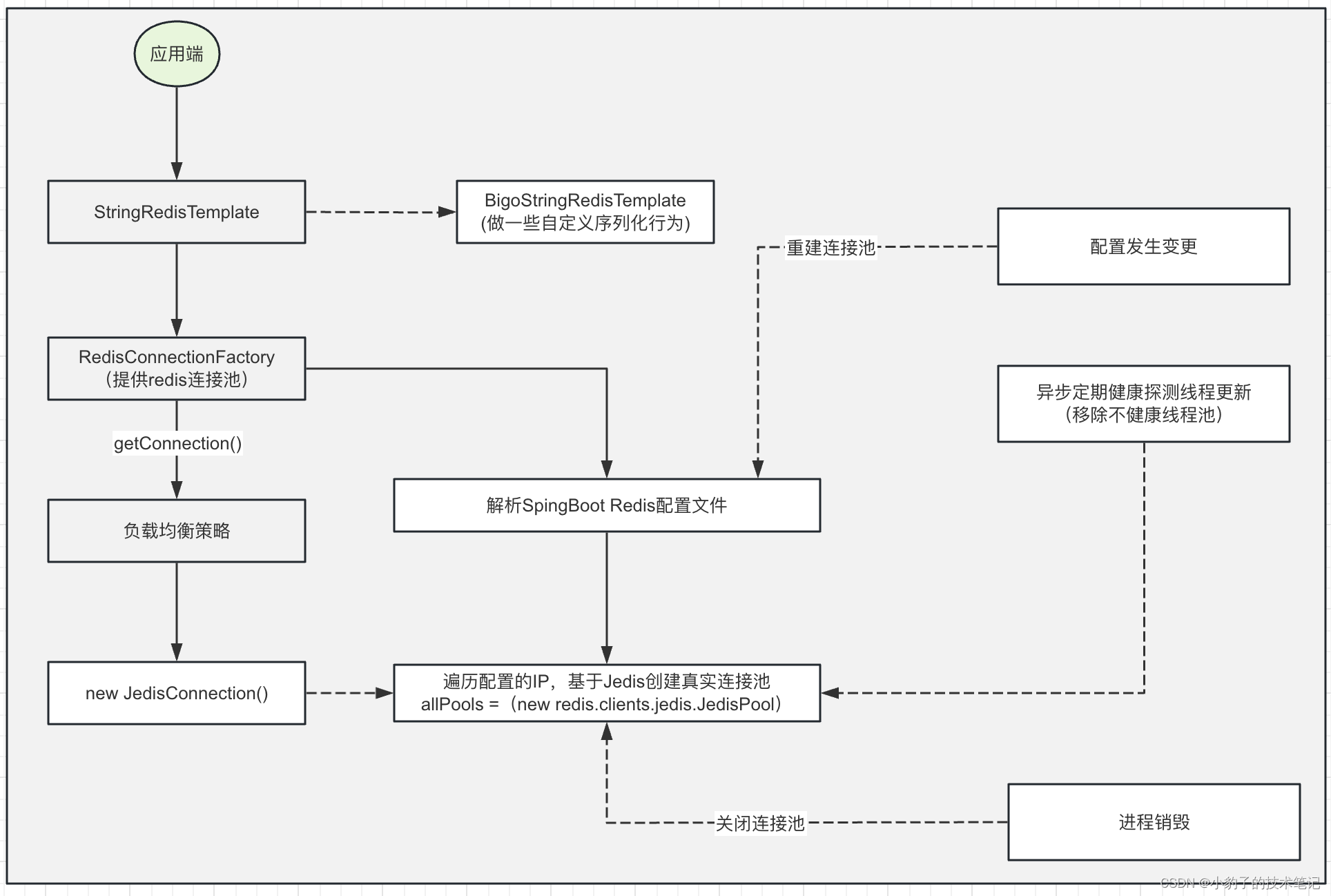
SpringBoot 基于jedis实现Codis高可用访问
codis与redis的关系 codis与redis之间关系就是codis是基于多个redis实例做了一层路由层来进行数据的路由,每个redis实例承担一定的数据分片。 codis作为开源产品,可以很直观的展示出codis运维成本低,扩容平滑最核心的优势. 其中࿰…...

力扣108. 将有序数组转换为二叉搜索树
108. 将有序数组转换为二叉搜索树 - 力扣(LeetCode) 找割点,一步一步将原数组分开。妙极了!!!!! /*** Definition for a binary tree node.* public class TreeNode {* int val;…...
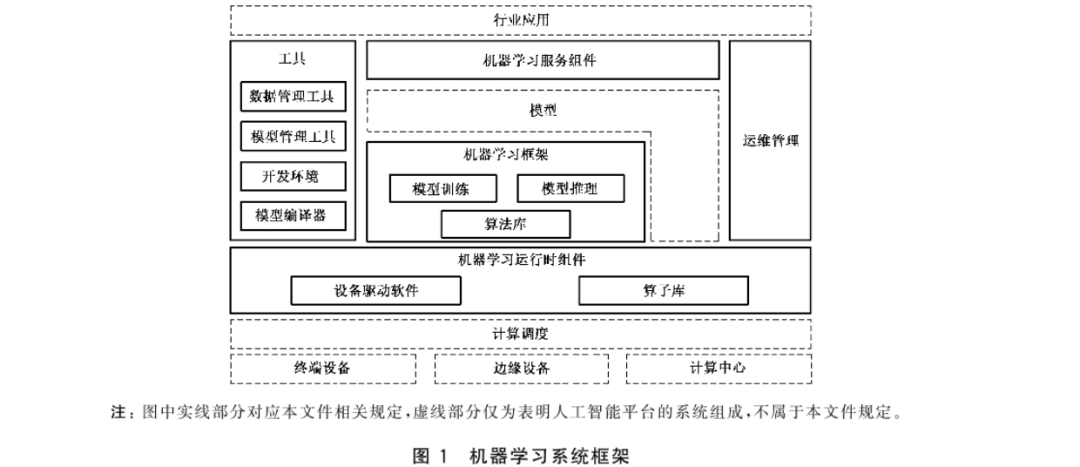
人工智能机器学习系统技术要求
一 术语和定义 1.1机器学习系统 machinelearningsystem 能运行或用于开发机器学习模型、算法和相关应用的软件系统。 1.2机器学习框架 machinelearningframework 利用预先构建和优化好的组件集合定义模型,实现对机器学习算法封装、数据调用处理和计算资源使用的软件库。 1…...

学习整理使用JavaScript中如何判断变量是否存在的四种常用方法
学习整理使用JavaScript中如何判断变量是否存在的四种常用方法 前言1. 使用 typeof 运算符判断变量类型2. 使用全局对象 window 或 global 判断变量是否存在3. 使用 in 关键字判断变量是否存在4. 使用 try…catch 块判断变量是否存在5. 综合示例总结 前言 在 JavaScript 中&am…...
docker实现jenkins+git+naocas一体化自动部署
一、jenkins安装 1.1 docker 安装jenkins docker pull jenkins/jenkins 1.2 docker 启动jenkins docker run --name myjenkins -d -p 8081:8080 -p 8085:8085 jenkins/jenkins –name 指定容器名称为myjenkins -d 表示后台运行 -p 8081:8080 表示Docker Host(运行Do…...

Flutter 中的 PerformanceOverlay 小部件:全面指南
Flutter 中的 PerformanceOverlay 小部件:全面指南 Flutter 是一个由 Google 开发的跨平台 UI 框架,它允许开发者使用 Dart 语言构建高性能、美观的应用。在 Flutter 的开发过程中,性能监控是一个重要的方面。PerformanceOverlay 是 Flutter…...
es的总结
es的collapse es的collapse只能针对一个字段聚合(针对大数据量去重),如果以age为聚合字段,则会展示第一条数据,如果需要展示多个字段,需要创建新的字段,如下 POST testleh/_update_by_query {…...

React常见的一些坑
文章目录 两个基础知识1. react的更新问题, react更新会重新执行react函数组件方法本身,并且子组件也会一起更新2. useCallback和useMemo滥用useCallback和useMemo要解决什么3. react的state有个经典的闭包,导致拿不到最新数据的问题.常见于useEffect, useMemo, useCallback4. …...
Java基础29(编码算法 哈希算法 MD5 SHA—1 HMac 算法 堆成加密算法)
目录 一、编码算法 1. 常见编码 2. URL编码 3. Base64编码 4. 小结 二、哈希算法 1. 哈希碰撞 2. 常用哈希算法 MD5算法 SHA-1算法 自定义HashTools工具类 3. 哈希算法的用途 校验下载文件 存储用户密码 4. 小结 三、Hmac算法 小结: 四、对称加密…...
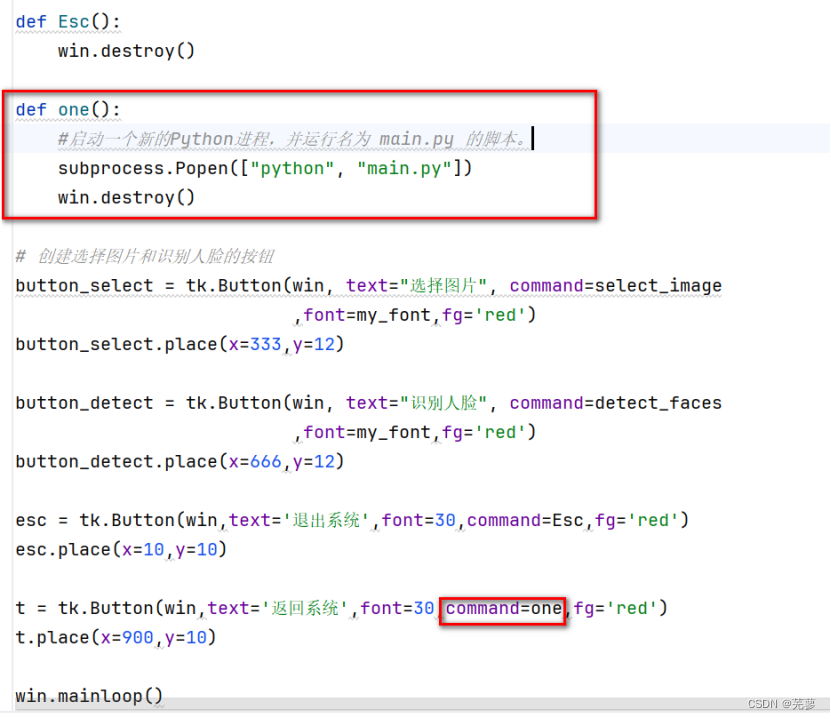
人脸识别——OpenCV
人脸识别 创建窗口创建按钮设置字体定义标签用于显示图片选择并显示图片检测图片中的人脸退出程序返回主界面 创建窗口 导入tkinter库,创建窗口,设置窗口标题和窗口大小。 import tkinter as tkwin tk.Tk() win.title("人脸识别") win.geom…...

深入探索容器:什么是容器及其在现代软件开发中的作用
深入探索容器:什么是容器及其在现代软件开发中的作用 引言 在今天的软件开发和运维领域,容器技术已经成为了一个不可或缺的工具。从初创企业到大型企业,从Web应用到微服务架构,容器都在发挥着其独特的作用。那么,什么…...
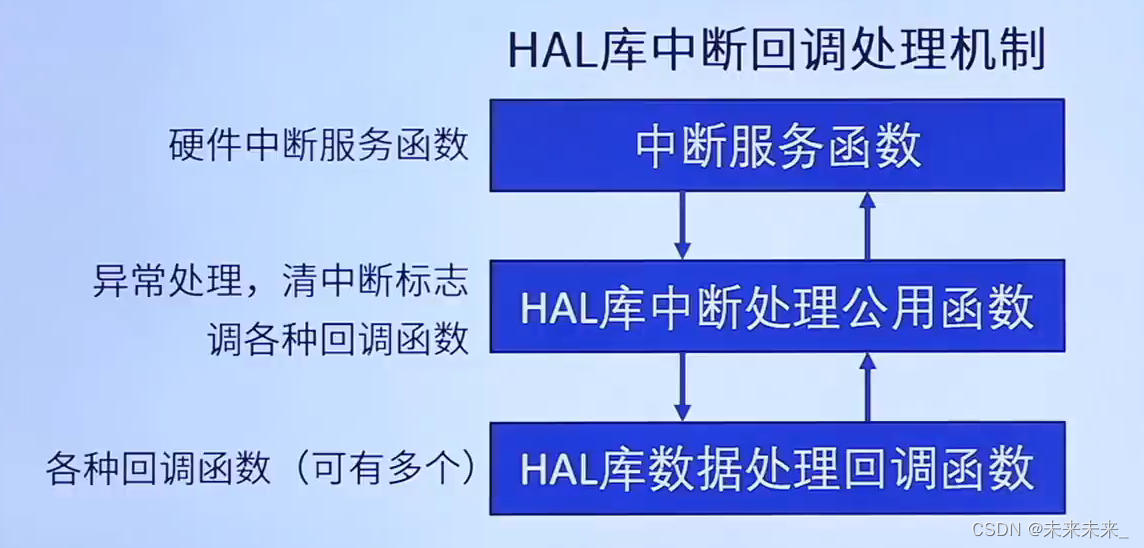
STM32-- GPIO->EXTI->NVIC中断
一、NVIC简介 什么是 NVIC ? NVIC 即嵌套向量中断控制器,全称 Nested vectored interrupt controller 。它 是内核的器件,所以它的更多描述可以看内核有关的资料。M3/M4/M7 内核都是支持 256 个中断,其中包含了 16 个系统中…...

【介绍下WebStorm开发插件】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

QT3D学习笔记——圆台、圆锥
类名作用Qt3DWindow3D渲染窗口容器QEntity场景中的实体(对象或容器)QCamera控制观察视角QPointLight点光源QConeMesh圆锥几何网格QTransform控制实体的位置/旋转/缩放QPhongMaterialPhong光照材质(定义颜色、反光等)QFirstPersonC…...