自动化办公02 用openpyxl库操作excel.xlsx文件(新版本)
目录
一、文件读操作
二、文件写操作
三、修改单元格样式
openpyxl 是一个处理Excel表格的第三方库。openpyxl 库可以处理Excel2010以后的电子表格格式,包括:xlsx/xlsm/xltx/xltm。
openpyxl教程
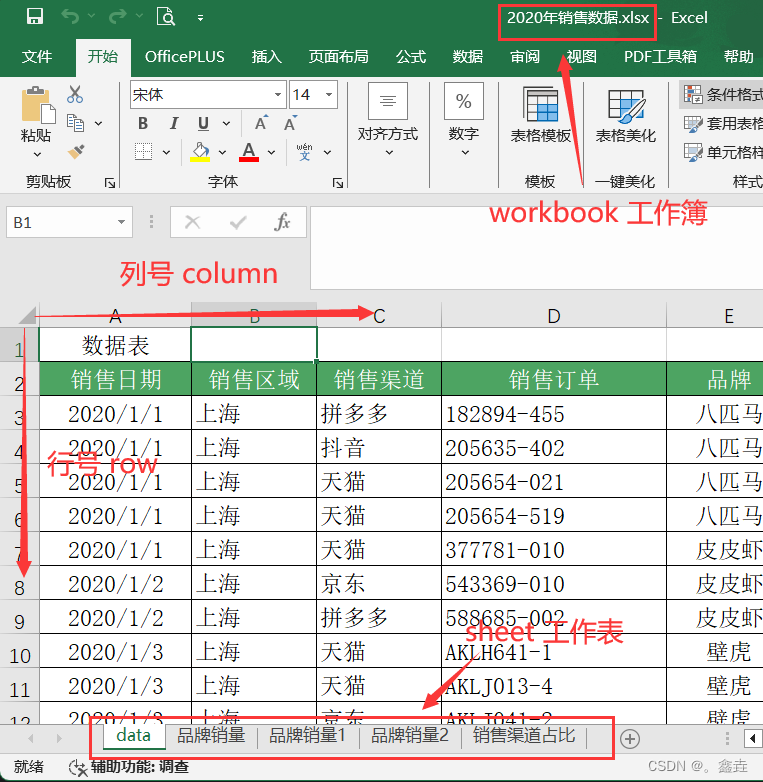
一、文件读操作
工作簿(workbook): excel文件
工作表(worksheet): 工作簿中的每一个活动就是一个工作表
单元格(cell): 工作表中用来存储数据的每个格子
注意:openpyxl只能操作新版本的excel文件(后缀为.xlsx)
1. 打开excel文件,得到一个工作簿对象
openpyxl.load_workbook(excel文件路径)
2. 获取工作簿相关信息
1)获取工作簿中所有的工作表的名称
变量 = 工作簿.sheetnames
2) 获取所有的工作表,返回值是一个列表,列表中的元素是工作表对象
变量 = 工作簿.worksheets
3) 获取指定工作表:
变量 = 工作簿对象[表名]
4) 获取活跃表(当前处于选中状态的工作表)
变量 = 工作簿.active
3. 获取工作表的相关信息
1) 获取数据的最大行数和列数
工作表对象.max_row - 获取最大行数
工作表对象.max_column - 获取最大列数
2) 获取指定单元格(注意这里写的是行号和列号,都是从1开始)
变量 = 工作表.cell(row, column)
4. 获取单元格相关信息
获取单元格内容
变量 = 工作表.cell(row, column).value
import openpyxl
# 注意:openpyxl只能操作新版本的excel文件(后缀为.xlsx)# 工作簿(workbook): excel文件
# 工作表(worksheet): 工作簿中的每一个活动就是一个工作表
# 单元格(cell): 工作表中用来存储数据的每个格子# 1. 打开excel文件,得到一个工作簿对象
# openpyxl.load_workbook(excel文件路径)
workbook = openpyxl.load_workbook('files/2020年销售数据.xlsx')# 2. 获取工作簿相关信息
# 1)获取工作簿中所有的工作表的名称
names = workbook.sheetnames
print(names)# 2)获取所有的工作表,返回值是一个列表,列表中的元素是工作表对象
all_sheet = workbook.worksheets
print(all_sheet)# 3)获取指定工作表: 工作簿对象[表名]
sheet1 = workbook['data']
print(sheet1)# 4)获取活跃表(当前处于选中状态的工作表)
sheet2 = workbook.active
print(sheet2)# 3. 获取工作表的相关信息
# 1)获取数据的最大行数和列数
# 工作表对象.max_row - 获取最大行数
# 工作表对象.max_column - 获取最大列数
print(sheet1.max_row, sheet1.max_column)
print(sheet2.max_row, sheet2.max_column)# 2)获取指定单元格
# 注意这里写的是行号和列号,都是从1开始
cell1 = sheet1.cell(7, 4)
print(cell1)# 4. 获取单元格相关信息
# 获取单元格内容
result = cell1.value
print(result)练习:
import openpyxl# 获取工作簿
wb = openpyxl.load_workbook('files/2020年销售数据.xlsx')
# 获取工作表
datasheet = wb['data']# 案例:获取第五行
max_col = datasheet.max_column # 最大列数
data = []
for col in range(1, max_col + 1):cell = datasheet.cell(5, col)data.append(cell.value)
print(data)print('-----------------------分------割------线-----------------------')# 练习1:获取data中第5列所有的数据
data1 = []
max_row = datasheet.max_row
for row in range(1, max_row + 1):cell = datasheet.cell(row, 5)data1.append(cell.value)
print(data1)print('-----------------------分------割------线-----------------------')# 练习2:获取所有的品牌(列表去重)
brand_list = []
max_row = datasheet.max_row
for row in range(3, max_row + 1):value = datasheet.cell(row, 5).valueif value not in brand_list:brand_list.append(value)
print(brand_list)print('-----------------------分------割------线-----------------------')# 练习3:计算不同品牌的总的销售额
# 方法1:使用上面已经搜索出来的品牌列表
sale = {}
for b in brand_list:sum1 = 0for row in range(3, max_row+1):if datasheet.cell(row, 5).value == b:sum1 += datasheet.cell(row, 8).valuesale[b] = sum1
print(sale)print('-----------------------分------割------线-----------------------')# print(type(datasheet.cell(row, 5).value))
# 方法2:
dic = {}
for row in range(3, max_row + 1):brand = datasheet.cell(row, 5).valuesale = datasheet.cell(row, 8).value# a.使用setdefault函数添加键值对# dic.setdefault(brand, 0)# dic[brand] += sale# b.使用if判断# if brand in dic:# dic[brand] += sale# else:# dic[brand] = sale# c.使用.get()方法读取第一个数据,则不会报错dic[brand] = dic.get(brand, 0) + sale
print(dic)print('-----------------------分------割------线-----------------------')dic = {'八匹马': 0, '皮皮虾': 0, '壁虎': 0, '花花姑娘': 0, '啊哟喂': 0}
# dic = {}
max_row = datasheet.max_row
for row in range(3, max_row + 1):value = datasheet.cell(row, 5).valuefor d in list(dic.keys()):if value == d:dic[d] += datasheet.cell(row, 8).value
print(dic)print('-----------------------分------割------线-----------------------')# data2 = []
# for row in range(1, max_row):
# temp = []
# for col in range(1, max_col):
# cell = datasheet.cell(row, col)
# temp.append(cell.value)
# data2.append(temp)
# print(data2)二、文件写操作
注意:所有写操作在保存后才会有效
1. 新建工作簿(创建一个工作簿对象)
新建的工作簿中默认有一个工作表
变量 = openpyxl.Workbook()
2. 添加工作表
工作簿对象.create_sheet() - 在工作簿的最后添加一个名字为Sheet?的工作表
工作簿对象.create_sheet(表名) - 在工作簿的最后添加一个名字为指定值的工作表
工作簿对象.create_sheet(表名,下标) - 在指定下标对应位置添加名字为指定值的工作表
3. 删除工作表
工作簿对象.remove(工作簿[表名])
del 工作簿[表名]
4.修改单元格内容
工作表.cell(row, column, 修改/添加内容)
工作表.cell(row, column).value = 修改/添加内容
import openpyxl# 1. 新建工作簿(创建一个工作簿对象)
wb = openpyxl.Workbook()# 2. 添加工作表
wb.create_sheet()# 注意:添加工作表的逻辑 - 不存在才添加
if 'students' not in wb.sheetnames:wb.create_sheet('students')wb.create_sheet('teachers', 0)# 3. 删除工作表
# 工作簿对象.remove(工作簿[表名])
# del 工作簿[表名]
if 'Sheet' in wb.sheetnames:wb.remove(wb['Sheet'])if 'Sheet1' in wb.sheetnames:del wb['Sheet1']# 4.修改单元格内容
students_sheet = wb['students']
students_sheet.cell(1, 1, '姓名') # 方法1
students_sheet.cell(1, 2).value = '年龄' # 方法2wb.save('files/school.xlsx')案例:
import openpyxl# 1.将data数据写深入到新建的excel中默认的工作表中的第二行
data = ['2020-1-1', '上海', '天猫', '205654-021', '八匹马', 169, 85, 14365]# 准备工作表
wb1 = openpyxl.Workbook()
sheet = wb1.active# 写入数据
for x in range(len(data)):value = data[x]col = x + 1sheet.cell(2, col, value)wb1.save('files/data1.xlsx')练习:
练习1:将data中的写入到新建的表中的第3列中
# 练习1:将data中的写入到新建的表中的第3列中
data = ['八匹马', '皮皮虾', '壁虎', '花花姑娘', '啊哟喂']
sheet1 = wb1.create_sheet('练习1')for x in range(len(data)):row = x + 1value = data[x]sheet1.cell(row, 3, value)wb1.save('files/data1.xlsx')
练习2:将class1中所有学生的信息以合理方式保存到新建的'学生表'中
# 练习2:将class1中所有学生的信息以合理方式保存到新建的'学生表'中
class1 = {'name': 'python2402','address': '6教室','lecturer': {'name': '余婷', 'age': 18, 'gender': '女', 'qq': '726550822'},'head_teacher': {'name': '舒嚒嚒', 'age': 18, 'gender': '女', 'tel': '110'},'students': [{'name': 'stu1', 'age': 17, 'gender': '男', 'score': 89, 'link_man': {'name': '张三', 'tel': '122334'}},{'name': 'stu2', 'age': 28, 'gender': '女', 'score': 99, 'link_man': {'name': '李四', 'tel': '29833'}},{'name': 'stu3', 'age': 22, 'gender': '女', 'score': 65, 'link_man': {'name': '王五', 'tel': '22223'}},{'name': 'stu4', 'age': 22, 'gender': '男', 'score': 77, 'link_man': {'name': '赵六', 'tel': '6544'}},{'name': 'stu5', 'age': 21, 'gender': '男', 'score': 46, 'link_man': {'name': '何七', 'tel': '664322'}},{'name': 'stu6', 'age': 16, 'gender': '女', 'score': 82, 'link_man': {'name': '李八', 'tel': '12278334'}}]
}
data = ['姓名', '年龄', '性别', '分数', '联系人', '联系人电话']
sheet2 = wb1.create_sheet('学生表')
for x in range(len(data)):col = x + 1value = data[x]sheet2.cell(1, col, value)
student_list = class1['students']
for x in range(len(student_list)):stu = student_list[x]row = x + 2stu_value = list(stu.values())link_man = stu_value.pop()# print(stu_value,link_man) # ['stu1', 17, '男', 89] {'name': '张三', 'tel': '122334'}stu_value.append(link_man['name'])stu_value.append(link_man['tel'])# print(stu_value) # ['stu1', 17, '男', 89, '张三', '122334']for y in range(len(stu_value)):col = y + 1value = stu_value[y]sheet2.cell(row, col, value)
wb1.save('files/data1.xlsx')练习3:将所有的0分都替换成补考;添加总分列,并且计算出每个学生的总分
import openpyxl# 练习3:将所有的0分都替换成补考;添加总分列,并且计算出每个学生的总分
wb = openpyxl.load_workbook('files/data2.xlsx')sheet1 = wb['Sheet1']max_row = sheet1.max_row # 19
max_col = sheet1.max_column # 5
sheet1.cell(1, max_col + 1, '总分')
for row in range(2, max_row + 1):sum1 = 0for col in range(2, max_col + 1):value = sheet1.cell(row, col).valuesum1 += valueif value == 0:sheet1.cell(row, col).value = '补考'sheet1.cell(row, max_col + 1).value = sum1wb.save('files/data2.xlsx')三、修改单元格样式
import openpyxl
from openpyxl.styles import Font, PatternFill, Border, Side, Alignment# 1.打开工作簿
wb = openpyxl.load_workbook('files/school.xlsx')
sheet = wb.active# 2.设置单元格字体样式
"""
Font(name=None, # 字体名,可以用字体名字的字符串strike=None, # 删除线,True/Falsecolor=None, # 文字颜色size=None, # 字号bold=None, # 加粗, True/Falseitalic=None, # 倾斜,Tue/Falseunderline=None # 下划线, 'singleAccounting', 'double', 'single', 'doubleAccounting'
)
"""
# 1) 创建字体对象
font1 = Font(size=20,italic=True,color='ff0000',bold=True,strike=True
)
# 2) 设置指定单元格的字体
# 单元格对象.font = 字体对象
sheet['B2'].font = font1# 3. 设置单元格填充样式
"""
PatternFill(fill_type=None, # 设置填充样式: 'darkGrid', 'darkTrellis', 'darkHorizontal', 'darkGray', 'lightDown', 'lightGray', 'solid', 'lightGrid', 'gray125', 'lightHorizontal', 'lightTrellis', 'darkDown', 'mediumGray', 'gray0625', 'darkUp', 'darkVertical', 'lightVertical', 'lightUp'start_color=None # 设置填充颜色
)
"""
# 1) 设置填充对象
fill = PatternFill(fill_type='solid',start_color='ffff00'
)
# 2)设置单元格的填充样式
# 单元格对象.fill = 填充对象
sheet['B2'].fill = fill# 4. 设置单元格对齐样式
# 1)创建对象
al = Alignment(horizontal='right', # 水平方向:center, left, rightvertical='top' # 垂直方向: center, top, bottom
)
# 2) 设置单元格的对齐方式
sheet['B2'].alignment = al# 5. 设置边框样式
# 1)设置边对象(四个边的边可以是一样的也可以不同,如果不同就创建对个Side对象)
side = Side(border_style='thin', color='0000ff')
# 2) 设置边框对象
# 这儿的left、right、top、bottom表示的是边框的四个边,这儿四个边使用的是一个边对象
bd = Border(left=side, right=side, top=side, bottom=side)
# 3)设置单元格的边框
sheet['B2'].border = bd# 6.设置单元格的宽度和高度
# 设置指定列的宽度
sheet.column_dimensions['A'].width = 20
# 设置指定行的高度
sheet.row_dimensions[1].height = 45# 7. 保存
wb.save('files/school.xlsx')
简单示例:
"""
Author: 余婷
Create Time: 2024/5/28 16:58
你只管努力,时间会给你惊喜!
"""
import openpyxl
from openpyxl.styles import Font, PatternFill, Border, Side, Alignmentwb = openpyxl.load_workbook('files/data1.xlsx')
sheet1 = wb['Sheet']# 1. 设置字体
# 1)创建字体对象
f1 = Font(name='楷体',color='990033',size=20,bold=True
)
# 2)设置单元格的字体
sheet1.cell(2, 2).font = f1# 2. 填充单元格
# 1)创建填充对象
fill1 = PatternFill(fill_type='solid',start_color='FFFFCC'
)
# 2)设置单元格的填充样式
sheet1.cell(2, 2).fill = fill1# 3. 设置边框样式
# 1)创建边对象
s1 = Side(border_style='medium',color='663366'
)
s2 = Side(border_style='mediumDashDot',color='009966'
)
# 2)创建边框对象
border1 = Border(bottom=s1,top=s1,left=s2,right=s2
)# 3)设置单元格的边框
sheet1.cell(2, 2).border = border1wb.save('files/data1.xlsx')
相关文章:
自动化办公02 用openpyxl库操作excel.xlsx文件(新版本)
目录 一、文件读操作 二、文件写操作 三、修改单元格样式 openpyxl 是一个处理Excel表格的第三方库。openpyxl 库可以处理Excel2010以后的电子表格格式,包括:xlsx/xlsm/xltx/xltm。 openpyxl教程 一、文件读操作 工作簿(workbook): excel文件 工作表…...

用户反馈解决方案 —— 兔小巢构建反馈功能
目录 01: 前言 02: 用户反馈整体实现方案分析 03: 兔小巢全解析 04: 基于兔小巢实现用户反馈 05: 总结 01: 前言 在前台系统中,用户反馈 功能也是一个非常常见的需求。 通过反馈功能,我们可以知道当前的应用存在的一些不足和用户相应的一些诉求。…...

git 下载失败
-- 错误0 加 sudo git config --global http.postBuffer 524288000 -- 错误 $ git clone https://github.com/espressif/arduino-esp32.git -b release/v2.x arduino Cloning into arduino... remote: Enumerating objects: 53886, done. remote: Counting objects: 100% (1…...

力扣1438.绝对差不超过限制的最长连续子数组
力扣1438.绝对差不超过限制的最长连续子数组 难点:保存数组缩小后的最大最小值 用两个单调队列分别处理最大值和最小值 class Solution {public:int longestSubarray(vector<int>& nums, int limit) {deque<int> quemax,quemin;int n nums.size…...

如何避免Python中默认参数带来的陷阱
Python编程中,我们有时会给函数或方法提供默认参数。然而,这种做法在某些情况下可能会导致意想不到的行为,尤其是当默认参数是可变对象(例如列表、字典或类实例对象)时。本文将通过几个具体的例子来解释这个问题&#…...

代码随想录算法训练营第五十天|198.打家劫舍、213.打家劫舍II、337.打家劫舍III
代码随想录算法训练营第五十天 198.打家劫舍 题目链接:198.打家劫舍 确定dp数组以及下标的含义:dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷窃的金额为dp[i]。确定递推公式:max(dp[i - 1],…...

VB.net 进行CAD二次开发(二)
利用参考文献2,添加面板 执行treeControl New UCTreeView()时报一个错误: 用户代码未处理 System.ArgumentException HResult-2147024809 Message控件不支持透明的背景色。 SourceSystem.Windows.Forms StackTrace: 在 System.Windows…...

安徽某高校数据挖掘作业6
1 根据附件中year文件,编辑Python程序绘制年销售总额分布条形图和年净利润分布条形图,附Python程序和图像。 2 根据附件中quarter和quarter_b文件,编辑Python程序绘制2018—2020年销售额和净利润折线图,附Python程序和图像。 3 …...

CMakeLists.txt和Package.xml
CMakeLists.txt和Package.xml CMakeLists.txt 总览 CMakeLists.txt 是用于定义如何构建 ROS (Robot Operating System) 包的 CMake 脚本文件。CMake 是一个跨平台的构建系统,用于自动化编译过程。在 ROS 中,CMakeLists.txt 文件指定了如何编译代码和链…...

Debian常用命令详解
Debian常用命令详解 Debian是一个流行的Linux发行版,它以其稳定性、强大的包管理系统和丰富的软件仓库而著称。对于Debian用户来说,掌握一些常用的命令行工具和命令是日常系统管理和维护的基础。下面,我们将介绍一些Debian系统中常用的命令。…...
代码随想录算法训练营day29|491.递增子序列、46.全排列、47.全排列II
递增子序列 491. 非递减子序列 - 力扣(LeetCode) 非递减子序列,则答案的子集中,需保持下一个元素大于等于前一个元素的顺序,由于题目中指出,所有的子序列长度需大于等于2,考虑当条件为path.siz…...

【ARM Cache 与 MMU 系列文章 7.8 – ARMv8/v9 MMU Table 表分配原理及其代码实现 2】
请阅读【ARM Cache 及 MMU/MPU 系列文章专栏导读】 及【嵌入式开发学习必备专栏】 文章目录 MMU Table 表分配原理及其代码实现MMU Table 分配代码实现MMU Table 表分配原理及其代码实现 在做映射的时候所映射的地址范围最大只能是某一级 level table 中 entry 所能支持的最大…...
SAP PP学习笔记17 - MTS(Make-to-Stock) 按库存生产(策略70)
上几章讲了几种策略,策略10,11,30,40。 SAP PP学习笔记14 - MTS(Make-to-Stock) 按库存生产(策略10),以及生产计划的概要-CSDN博客 SAP PP学习笔记15 - MTS(Make-to-St…...
网页音频提取在线工具有哪些 网页音频提取在线工具下载
别再到处去借会员账号啦。教你一招,无视版权和地区限制,直接下载网页中的音频文件。没有复杂的操作步骤,也不用学习任何代码。只要是网页中播放的音频文件,都可以把它下载到本地保存。 一、网页音频提取在线工具有哪些 市面上的…...

【ARM Cache 系列文章 2.1 -- Cache PoP 及 PoDP 介绍】
请阅读【ARM Cache 及 MMU/MPU 系列文章专栏导读】 及【嵌入式开发学习必备专栏】 文章目录 PoP 及 PoDPCache PoDPCache PoP应用和影响PoP 及 PoDP Cache PoDP 点对深度持久性(Point of Deep Persistence, PoDP)是内存系统中的一个点,在该点达到的任何写操作即使在系统供电…...

一文了解JVM面试篇(上)
Java内存区域 1、如何解释 Java 堆空间及 GC? 当通过 Java 命令启动 Java 进程的时候,会为它分配内存。内存的一部分用于创建 堆空间,当程序中创建对象的时候,就从对空间中分配内存。GC 是 JVM 内部的一 个进程,回收无效对象的内存用于将来的分配。 2、JVM 的主要组成…...

C#WPF控件Textbox绑定浮点型数据限制小数位方法
本文讲解C#WPF控件Textbox绑定浮点型数据限制小数位方法。 XAML中,使用StringFormat来格式化TextBox的文本 <Window x:Class="WpfApp.MainWindow"xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x="http://schemas.m…...
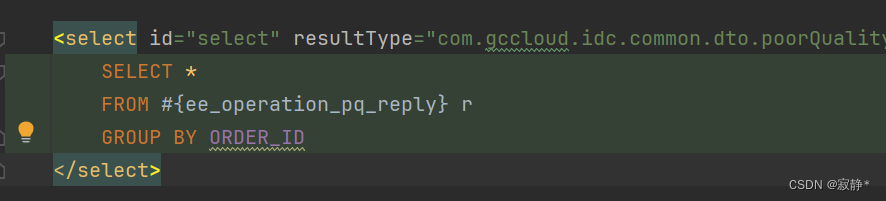
mysql引入表名称的注意事项
1、遇到问题 mapper中的文件是这样的 解析出来的sql是这样的 sql显示为:select * from ‘tableName’ 2、解决方法 mapper文件种使用${tableName}而不是#{tableName}...
C语言数据结构快速排序的非递归、归并排序、归并排序的非递归等的介绍
文章目录 前言一、快速排序非递归二、归并排序五、归并排序非递归总结 前言 C语言数据结构快速排序的非递归、归并排序、归并排序的非递归等的介绍 一、快速排序非递归 快速排序非递归的定义 快速排序非递归,需要使用栈来实现。将左右下标分别push到栈中。在栈为…...

学生成绩管理系统(大一大作业)
功能 实现添加,排序,修改,保存等功能 库函数 #include<stdio.h> #include<stdlib.h> #include<windows.h> #include<string.h> 头文件 #define functioncreate(major) void major##compare(mana mn){\int i,j,s…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...