大模型Prompt-Tuning技术进阶
LLM的Prompt-Tuning主流方法

面向超大规模模型的Prompt-Tuning

近两年来,随之Prompt-Tuning技术的发展,有诸多工作发现,对于超过10亿参数量的模型来说,Prompt-Tuning所带来的增益远远高于标准的Fine-tuning,小样本甚至是零样本的性能也能够极大地被激发出来,得益于这些模型的 参数量足够大 ,训练过程中使用了 足够多的语料 ,同时设计的 预训练任务足够有效 。最为经典的大规模语言模型则是2020年提出的GPT-3,其拥有大约1750亿的参数,且发现只需要设计合适的模板或指令即可以 实现免参数训练的零样本学习 。
2022年底到2023年初,国内外也掀起了AIGC的浪潮,典型代表是OpenAI发布的ChatGPT、GPT-4大模型,Google发布的Bard以及百度公司发布的文心一言等。超大规模模型进入新的纪元,而这些轰动世界的产物,离不开强大的Prompt-Tuning技术。本文默认以GPT-3为例,介绍几个面向超大规模的Prompt-Tuning方法,分别为:
- 上下文学习 In-Context Learning(ICL) :直接挑选少量的训练样本作为该任务的提示;
- 指令学习 Instruction-Tuning :构建任务指令集,促使模型根据任务指令做出反馈;
- 思维链 Chain-of-Thought(CoT) :给予或激发模型具有推理和解释的信息,通过线性链式的模式指导模型生成合理的结果。

1. In-Context Learning(上下文学习)
In-Context learning(ICL)最早在GPT-3中提出, 旨在从训练集中挑选少量的标注样本,设计任务相关的指令形成提示模板,用于指导测试样本生成相应的结果。
常用的In-context learning方法包括:
- zero-shot learning
- 定义: 给出任务的描述, 然后提供测试数据对其进行预测, 直接让预训练好的模型去进行任务测试.
- 示例: 向模型输入“这个任务要求将中文翻译为英文. 销售->”, 然后要求模型预测下一个输出应该是什么, 正确答案应为“sell”.
- one-shot learning
- 定义: 在预训练和真正翻译的样本之间, 插入一个样本做指导. 相当于在预训练好的结果和所要执行的任务之间, 给一个例子, 告诉模型英语翻译为法语, 应该这么翻译.
- 示例: 向模型输入“这个任务要求将中文翻译为英文. 你好->hello, 销售->”, 然后要求模型预测下一个输出应该是什么, 正确答案应为“sell”.
- few-shot learning
- 定义: 在预训练和真正翻译的样本之间, 插入多个样本(一般10-100条)做指导. 相当于在预训练好的结果和所要执行的任务之间, 给多个例子, 告诉模型应该如何工作.
- 示例: 向模型输入“这个任务要求将中文翻译为英文. 你好->hello, 再见->goodbye, 购买->purchase, 销售->”, 然后要求模型预测下一个输出应该是什么, 正确答案应为“sell”.
目前In-context Learning依然与普通的fine-tuning有一定差距,且预测的结果方差很大,同时也需要花费时间考虑template的构建。

2. Instruction-Tuning(指令学习)
面向超大规模模型第二个Prompt技术是指令学习。其实Prompt-Tuning本质上是对下游任务的指令,简单的来说:就是告诉模型需要做什么任务,输出什么内容。上文我们提及到的离散或连续的模板,本质上就是一种对任务的提示。因此,在对大规模模型进行微调时,可以为各种类型的任务定义指令,并进行训练,来提高模型对不同任务的泛化能力。
什么是Instruction-Tuning? 让我们先抛开脑子里的一切概念,把自己当成一个模型。我给你两个任务:
-
1.带女朋友去了一家餐厅,她吃的很开心,这家餐厅太__了!
-
2.判断这句话的情感:带女朋友去了一家餐厅,她吃的很开心。选项:A=好,B=一般,C=差
-
你觉得哪个任务简单?想象一下:做判别是不是比做生成要容易?Prompt就是第一种模式,Instruction就是第二种。
Instruction-Tuning和Prompt-Tuning的核心一样,就是去发掘语言模型本身具备的知识。而他们的不同点就在于:
- Prompt是去激发语言模型的补全能力,比如给出上半句生成下半句、或者做完形填空。
- Instruction-Tuning则是激发语言模型的理解能力,通过给出更明显的指令/指示,让模型去理解并做出正确的action.
- Promp-Tuningt在没有精调的模型上也能有一定效果,但是Instruct-Tuning则必须对模型精调,让模型知道这种指令模式。
举例说明:
- 例如在对电影评论进行二分类的时候,最简单的提示模板(Prompt)是“. It was [mask].”,但是其并没有突出该任务的具体特性,我们可以为其设计一个能够突出该任务特性的模板(加上Instruction),例如“The movie review is . It was [mask].”,然后根据mask位置的输出结果通过Verbalizer映射到具体的标签上。这一类具备任务特性的模板可以称之为指令Instruction.
如何实现Instruction-Tuning?
为每个任务设计10个指令模版,测试时看平均和最好的表现.

3. Chain-of-Thought(思维链)
思维链 (Chain-of-thought,CoT) 的概念是在 Google 的论文 “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” 中被首次提出。思维链(CoT)是一种改进的提示策略,用于提高 LLM 在复杂推理任务中的性能,如算术推理、常识推理和符号推理。
CoT 没有像 ICL 那样简单地用输入输出对构建提示,而是结合了中间推理步骤,这些步骤可以将最终输出引入提示。简单来说,思维链是一种离散式提示学习,更具体地,大模型下的上下文学习(即不进行训练,将例子添加到当前样本输入的前面,让模型一次输入这些文本进行输出完成任务),相比于之前传统的上下文学习(即通过x1,y1,x2,y2,…xtest作为输入来让大模型补全输出ytest),思维链多了中间的中间的推导提示。
以一个数学题为例:
-
模型无法做出正确的回答。但如果说,我们给模型一些关于解题的思路,就像我们数学考试,都会把解题过程写出来再最终得出答案,不然无法得分。CoT 做的就是这件事
-
类似的算术题,思维链提示会在给出答案之前,还会自动给出推理步骤:
“罗杰先有5个球,2盒3个网球等于6个,5 + 6 = 11”
“食堂原来有23个苹果,用了20个,23-20=3;又买了6个苹果,3+6=9
上述例子证明了思维链提示给出了正确答案,而直接给出答案的传统提示学习,结果是错的,连很基本的数学计算都做不好。简单来说,语言模型很难将所有的语义直接转化为一个方程,因为这是一个更加复杂的思考过程,但可以通过中间步骤,来更好地推理问题的每个部分。
CoT分类:
- Few-shot CoT :是 ICL 的一种特殊情况,它通过融合 CoT 推理步骤,将每个演示〈input,output〉扩充为〈input,CoT,output〉。
- Zero-shot CoT:与 Few-shot CoT 不同 在 prompt 中不包括人工标注的任务演示。相反,它直接生成推理步骤,然后使用生成的 CoT 来导出答案。(其中 LLM 首先由 “Let’s think step by step” 提示生成推理步骤,然后由 “Therefore, the answer is” 提示得出最终答案。他们发现,当模型规模超过一定规模时,这种策略会大大提高性能,但对小规模模型无效,显示出显著的涌现能力模式)。
一个有效的思维链应该具有以下特点:
-
逻辑性:思维链中的每个思考步骤都应该是有逻辑关系的,它们应该相互连接,从而形成一个完整的思考过程。
-
全面性:思维链应该尽可能地全面和细致地考虑问题,以确保不会忽略任何可能的因素和影响。
-
可行性:思维链中的每个思考步骤都应该是可行的,也就是说,它们应该可以被实际操作和实施。
-
可验证性:思维链中的每个思考步骤都应该是可以验证的,也就是说,它们应该可以通过实际的数据和事实来验证其正确性和有效性。

PEFT(大模型参数高效微调)
目前在工业界应用大模型主流方式:参数高效微调方法(Parameter-Efficient Fine-Tuning,PEFT),PEFT 方法仅微调少量或额外的模型参数,固定大部分预训练参数,大大降低了计算和存储成本,同时最先进的 PEFT 技术也能实现了与全量微调相当的性能。
该方法可以使 PLM 高效适应各种下游应用任务,而无需微调预训练模型的所有参数,且让大模型在消费级硬件上进行全量微调(Full Fine-Tuning)变得可行。
目前应用较多的PEFT方法主要分为三大类:
- Prefix/Prompt-Tuning:在模型的输入或隐层添加 k k k个额外可训练的前缀 tokens(这些前缀是连续的伪 tokens,不对应真实的 tokens),只训练这些前缀参数;
- Adapter-Tuning:将较小的神经网络层或模块插入预训练模型的每一层,这些新插入的神经模块称为 adapter(适配器),下游任务微调时也只训练这些适配器参数;
- LoRA:通过学习小参数的低秩矩阵来近似模型权重矩阵 W W W的参数更新,训练时只优化低秩矩阵参数;
此外Huggface 开源的一个高效微调大模型的库PEFT,该算法库支持上述三类方法,可以直接调用。
1. Prefix Tuning
Prefix-Tuning 在模型输入前添加一个连续的且任务特定的向量序列(continuous task-specific vectors),称之为前缀(prefix)。前缀被视为一系列“虚拟 tokens”,但是它由不对应于真实 tokens 的自由参数组成。与更新所有 PLM 参数的全量微调不同,Prefix-Tuning 固定 PLM 的所有参数,只更新优化特定任务的 prefix。因此,在生产部署时,只需要存储一个大型 PLM 的副本和一个学习到的特定任务的 prefix,每个下游任务只产生非常小的额外的计算和存储开销。
Fine-tuning 更新所有 PLM 参数,并且需要为每个任务存储完整的模型副本。Prefix-tuning 冻结了 PLM 参数并且只优化了 prefix。因此,只需要为每个任务存储特定 prefix,使 Prefix-tuning 模块化且节省存储空间。
以 GPT2 的自回归语言模型为例,将输入 x x x 和输出 y y y 拼接为 z = [ x ; y ] z=[x;y] z=[x;y] ,经过 LM 的某一层计算隐层表示 h = [ h 1 , . . . , h i , . . . . , h n ] h=[h_1,...,h_i,....,h_n] h=[h1,...,hi,....,hn] , h i = L M Ø ( z i , h < i ) h_i=LM_Ø(z_i, h<i) hi=LMØ(zi,h<i) ,其中, X i d x X_{idx} Xidx 和 Y i d x Y_{idx} Yidx分别为输入和输出序列的索引。
Prefix-Tuning 在输入前添加前缀,即 z = [ P r e f i x , x , y ] z=[Prefix,x,y] z=[Prefix,x,y] , P i d x P_{idx} Pidx为前缀序列的索引, ∣ P i d x ∣ |P_{idx}| ∣Pidx∣ 为前缀的长度。前缀索引对应着由 θ θ θ参数化的向量矩阵 P θ P_θ Pθ ,维度为 ∣ P i d x ∣ × d i m ( h i ) |P_{idx}|×dim(h_i) ∣Pidx∣×dim(hi)。隐层表示的:若索引为前缀索引 P i d x P_{idx} Pidx,直接从 P θ P_θ Pθ 复制对应的向量作为 h i h_i hi (在模型每一层都添加前缀向量);否则直接通过 LM 计算得到,同时,经过 LM 计算的 h i h_i hi也依赖于其左侧的前缀参数 P θ P_θ Pθ ,即通过前缀来影响后续的序列隐层激化值。
但是直接优化 P θ P_θ Pθ 会导致训练不稳定,通过一个更小的矩阵 P w P_w Pw和一个更大的前馈神经网络 M L P θ MLP_θ MLPθ 对 P θ P_θ Pθ 进行重参数化: P θ [ i , : ] = M L P θ ( P w [ i , : ] ) P_θ[i,:]=MLP_θ(P_w[i,:]) Pθ[i,:]=MLPθ(Pw[i,:]) 。在训练时,LM 的参数 Ø Ø Ø 被固定,只有前缀参数 θ θ θ 为可训练的参数。训练完成后,只有前缀 P θ P_θ Pθ被保存。
P-Tuning 与 Prefix-Tuning 的方法思路很相近,P-Tuning 利用少量连续的 embedding 参数作为 prompt使 GPT 更好的应用于 NLU 任务,而 Prefix-Tuning 是针对 NLG 任务设计,同时,P-Tuning 只在 embedding 层增加参数,而 Prefix-Tuning 在每一层都添加可训练参数。
Prompt Tuning 方式可以看做是 Prefix Tuning 的简化,固定整个预训练模型参数,只允许将每个下游任务的额外 k k k个可更新的 tokens 前置到输入文本中,也没有使用额外的编码层或任务特定的输出层。
2. Adapter Tuning
与 Prefix Tuning 和 Prompt Tuning 这类在输入前可训练添加 prompt embedding 参数来以少量参数适配下游任务,Adapter Tuning 则是在预训练模型内部的网络层之间添加新的网络层或模块来适配下游任务。
假设预训练模型函数表示为 Ø w ( x ) Ø_w(x) Øw(x),对于 Adapter Tuning ,添加适配器之后模型函数更新为 Ø w , w 0 ( x ) Ø_{w,w_0}(x) Øw,w0(x), w w w是预训练模型的参数, w 0 w_0 w0是新添加的适配器的参数,在训练过程中, w w w被固定,只有 w 0 w_0 w0被更新。 ∣ w 0 ∣ < < ∣ w ∣ |w_0|<<|w| ∣w0∣<<∣w∣ ,这使得不同下游任务只需要添加少量可训练的参数即可,节省计算和存储开销,同时共享大规模预训练模型。
Series Adapter的适配器结构和与 Transformer 的集成如上图所示。适配器模块被添加到每个 Transformer 层两次:多头注意力映射之后和两层前馈神经网络之后。适配器是一个 bottleneck(瓶颈)结构的模块,由一个两层的前馈神经网络(由向下投影矩阵、非线性函数和向上投影矩阵构成)和一个输出输出之间的残差连接组成。

3. LoRA
上述Adapter Tuning 方法在 PLM 基础上添加适配器层会引入额外的计算,带来推理延迟问题;而 Prefix Tuning 方法难以优化,其性能随可训练参数规模非单调变化,更根本的是,为前缀保留部分序列长度必然会减少用于处理下游任务的序列长度。因此微软推出了LoRA方法。
低秩适应(Low-Rank Adaptation)是一种参数高效的微调技术,其核心思想是对大型模型的权重矩阵进行隐式的低秩转换,也就是:通过一个较低维度的表示来近似表示一个高维矩阵或数据集。
基本原理:LoRA技术冻结预训练模型的权重,并在每个Transformer块中注入可训练层(称为秩分解矩阵),即在模型的Linear层的旁边增加一个“旁支”A和B。其中,A将数据从d维降到r维,这个r是LoRA的秩,是一个重要的超参数;B将数据从r维升到d维,B部分的参数初始为0。模型训练结束后,需要将A+B部分的参数与原大模型的参数合并在一起使用。
python伪代码
input_dim = 768 # 例如,预训练模型的隐藏大小
output_dim = 768 # 例如,层的输出大小
rank = 8 # 低秩适应的等级'r'
W = ... # 来自预训练网络的权重,形状为 input_dim x output_dim
W_A = nn.Parameter(torch.empty(input_dim, rank)) # LoRA权重A
W_B = nn.Parameter(torch.empty(rank, output_dim)) # LoRA权重B初始化LoRA权重
nn.init.kaiming_uniform_(W_A, a=math.sqrt(5))
nn.init.zeros_(W_B)def regular_forward_matmul(x, W):h = x @ Wreturn hdef lora_forward_matmul(x, W, W_A, W_B):h = x @ W # 常规矩阵乘法h += x @ (W_A @ W_B) * alpha # 使用缩放的LoRA权重,alpha缩放因子return h
LoRA方法是目前最通用、同时也是效果最好的微调方法之一。
相关文章:
大模型Prompt-Tuning技术进阶
LLM的Prompt-Tuning主流方法 面向超大规模模型的Prompt-Tuning 近两年来,随之Prompt-Tuning技术的发展,有诸多工作发现,对于超过10亿参数量的模型来说,Prompt-Tuning所带来的增益远远高于标准的Fine-tuning,小样本甚至…...

统一响应,自定义校验器,自定义异常,统一异常处理器
文章目录 1.基本准备(构建一个SpringBoot模块)1.在A_universal_solution模块下创建新的子模块unified-processing2.pom.xml引入基本依赖3.编写springboot启动类4.启动测试 2.统一响应处理1.首先定义一个响应枚举类 RespBeanEnum.java 每个枚举对象都有co…...

完整状态码面试背
{"100": "继续","101": "切换协议","102": "处理中","103": "早期提示","200": "成功","201": "已创建","202": "已接受",&qu…...
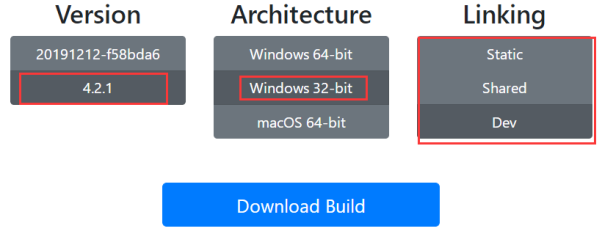
QT+FFmpeg+Windows开发环境搭建(加薪点)
01、Windows 环境搭建 FFMPEG官网:http://ffmpeg.org/ 02、下载4.2.1版本源码 源码:https://ffmpeg.org/releases/ffmpeg-4.2.1.tar.bz2 03、下载4.2.1编译好的文件 下载已经编译好的FFMPEG)(迅雷下载很快) 网址:https://ffmpeg.zeranoe.com/builds/ 32位下载地址:(迅雷…...

Linux 主机一键安全整改策略
为防止linux主机被恶意攻击,和受到攻击后能更快定位到源头,需要对linux主机做一些参数配置。 比如禁用root的远程登录、用户多次密码验证失败后被锁、禁止系统账号交互式登录等等。 下面是linux主机安全整改的一些简单介绍,最后会通过脚本一…...

Hot100——二叉树
树的定义: public static class TreeNode{int val;TreeNode left;TreeNode right;TreeNode(){};TreeNode(int val){ this.val val; };TreeNode(int val, TreeNode left, TreeNode right){this.val val;this.left left;this.right right;}} 深度优先遍历&#x…...

C++ static_cast、dynamic_cast、const_cast 和 reinterpret_cast 用处和区别
在 C 中,static_cast、dynamic_cast、const_cast 和 reinterpret_cast 是四种类型转换运算符,它们各自有不同的用途和行为: static_cast 用于编译时已知类型的转换,如基本数据类型转换、派生类到基类的转换、指针和引用的转换等…...
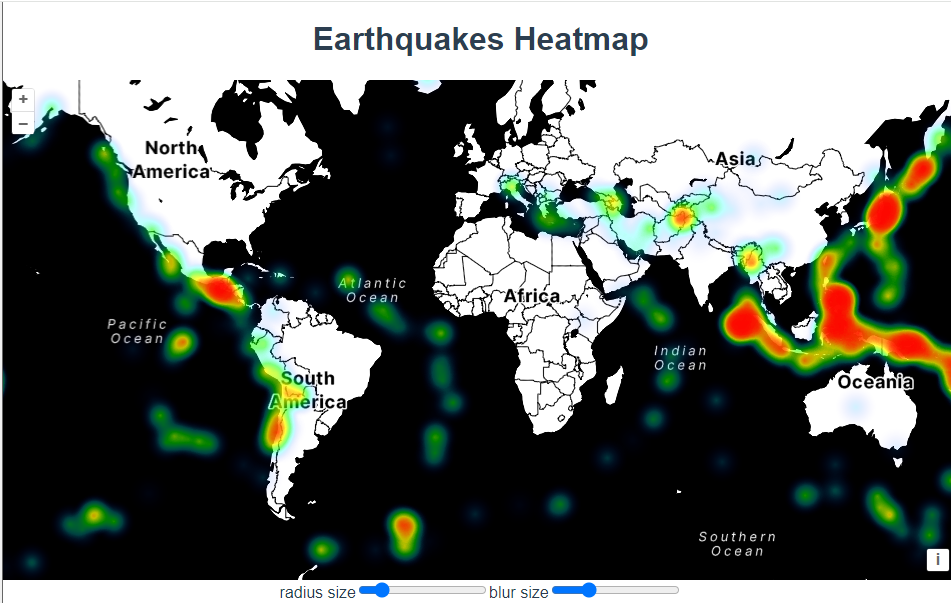
三十七、openlayers官网示例Earthquakes Heatmap解析——在地图上加载热力图
官网demo地址: Earthquakes Heatmap 这篇主要介绍了热力图HeatmapLayer HeatmapLayer 是一个用于在地图上显示热力图的图层类型,通常用于表示地理数据中的密度或强度。例如,它可以用来显示地震、人口密度或其他空间数据的热点区域。在这个示…...

curl 92 HTTP/2 stream 5 was not closed cleanly: CANCEL
source ~/.bash_profile flutter clean Command exited with code 128: git fetch --tags Standard error: 错误:RPC 失败。curl 92 HTTP/2 stream 5 was not closed cleanly: CANCEL (err 8) 错误:预期仍然需要 2737 个字节的正文 fetch-pack: unexpec…...
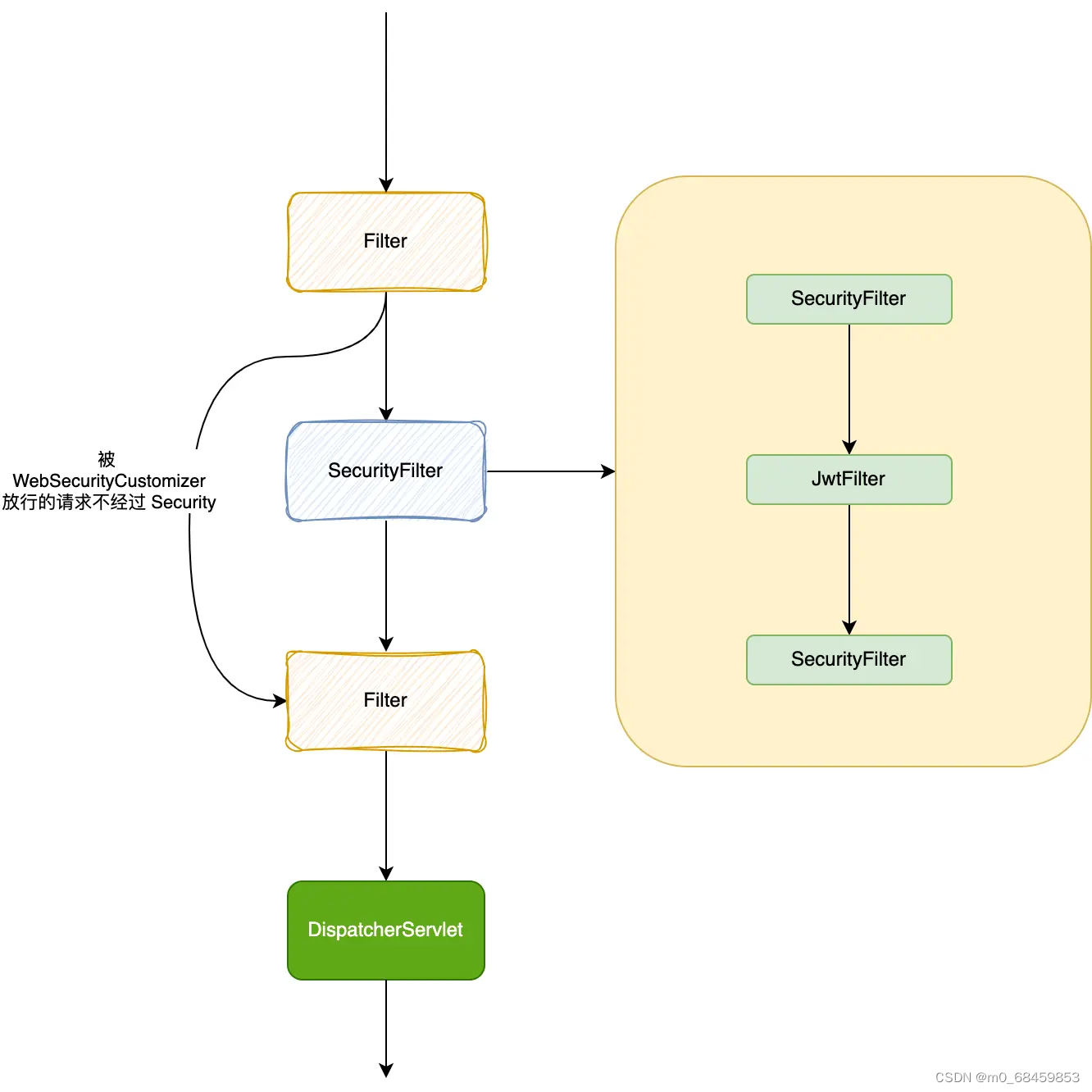
Spring Security 注册过滤器关键点与最佳实践
在 Spring Security 框架中,注册过滤器是实现身份验证和授权的关键组件。正确配置和使用注册过滤器对于确保应用程序的安全性至关重要。以下是一些关于 Spring Security 注册过滤器的注意事项和最佳实践。 过滤器链顺序: 注册过滤器通常位于过滤器链的末…...

力扣2024.考试的最大困扰度
力扣2024.考试的最大困扰度 注意同时>k才处理 class Solution {public:int maxConsecutiveAnswers(string answerKey, int k) {int n answerKey.size(),res0;unordered_map<int,int> cnt;for(int i0,j0;i<n;i){cnt[answerKey[i] - a] ;while(cnt[T - a] > k …...

java配置文件解析yml/xml/properties文件
XML 以mybatis.xml:获取所有Environment中的数据库并连接session为例 import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException;import javax.xml.parsers.DocumentBuilder; impo…...
grpc接口调用
grpc接口调用 准备依赖包clientserver 参考博客: Grpc项目集成到java方式调用实践 gRpc入门和springboot整合 java 中使用grpc java调用grpc服务 准备 因为需要生成代码,所以必备插件 安装后重启 依赖包 <?xml version"1.0" encoding&…...
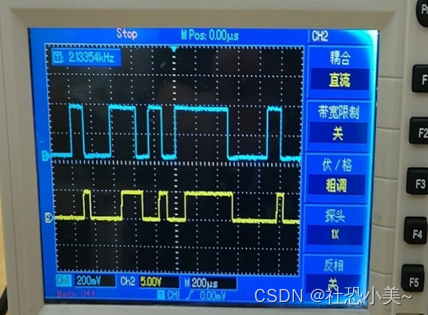
通信技术振幅键控(ASK)调制与解调硬件实验
一、实验目的 1. 掌握用键控法产生ASK信号的方法; 2. 掌握ASK非相干解调的原理。 二、实验内容 1. 观察ASK已调信号的波形; 2. 观察ASK解调信号的波形。 三、实验器材 1. 双踪示波器; 2. 通信原理实验箱信号源模块、③、④、⑦号模块。…...
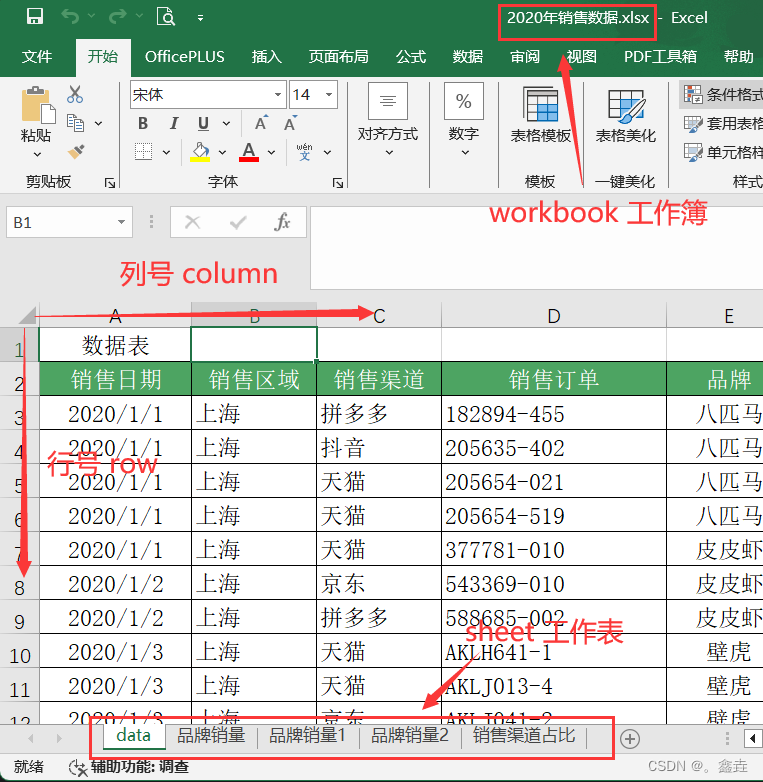
自动化办公02 用openpyxl库操作excel.xlsx文件(新版本)
目录 一、文件读操作 二、文件写操作 三、修改单元格样式 openpyxl 是一个处理Excel表格的第三方库。openpyxl 库可以处理Excel2010以后的电子表格格式,包括:xlsx/xlsm/xltx/xltm。 openpyxl教程 一、文件读操作 工作簿(workbook): excel文件 工作表…...

用户反馈解决方案 —— 兔小巢构建反馈功能
目录 01: 前言 02: 用户反馈整体实现方案分析 03: 兔小巢全解析 04: 基于兔小巢实现用户反馈 05: 总结 01: 前言 在前台系统中,用户反馈 功能也是一个非常常见的需求。 通过反馈功能,我们可以知道当前的应用存在的一些不足和用户相应的一些诉求。…...

git 下载失败
-- 错误0 加 sudo git config --global http.postBuffer 524288000 -- 错误 $ git clone https://github.com/espressif/arduino-esp32.git -b release/v2.x arduino Cloning into arduino... remote: Enumerating objects: 53886, done. remote: Counting objects: 100% (1…...

力扣1438.绝对差不超过限制的最长连续子数组
力扣1438.绝对差不超过限制的最长连续子数组 难点:保存数组缩小后的最大最小值 用两个单调队列分别处理最大值和最小值 class Solution {public:int longestSubarray(vector<int>& nums, int limit) {deque<int> quemax,quemin;int n nums.size…...

如何避免Python中默认参数带来的陷阱
Python编程中,我们有时会给函数或方法提供默认参数。然而,这种做法在某些情况下可能会导致意想不到的行为,尤其是当默认参数是可变对象(例如列表、字典或类实例对象)时。本文将通过几个具体的例子来解释这个问题&#…...

代码随想录算法训练营第五十天|198.打家劫舍、213.打家劫舍II、337.打家劫舍III
代码随想录算法训练营第五十天 198.打家劫舍 题目链接:198.打家劫舍 确定dp数组以及下标的含义:dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷窃的金额为dp[i]。确定递推公式:max(dp[i - 1],…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...

tomcat入门
1 tomcat 是什么 apache开发的web服务器可以为java web程序提供运行环境tomcat是一款高效,稳定,易于使用的web服务器tomcathttp服务器Servlet服务器 2 tomcat 目录介绍 -bin #存放tomcat的脚本 -conf #存放tomcat的配置文件 ---catalina.policy #to…...