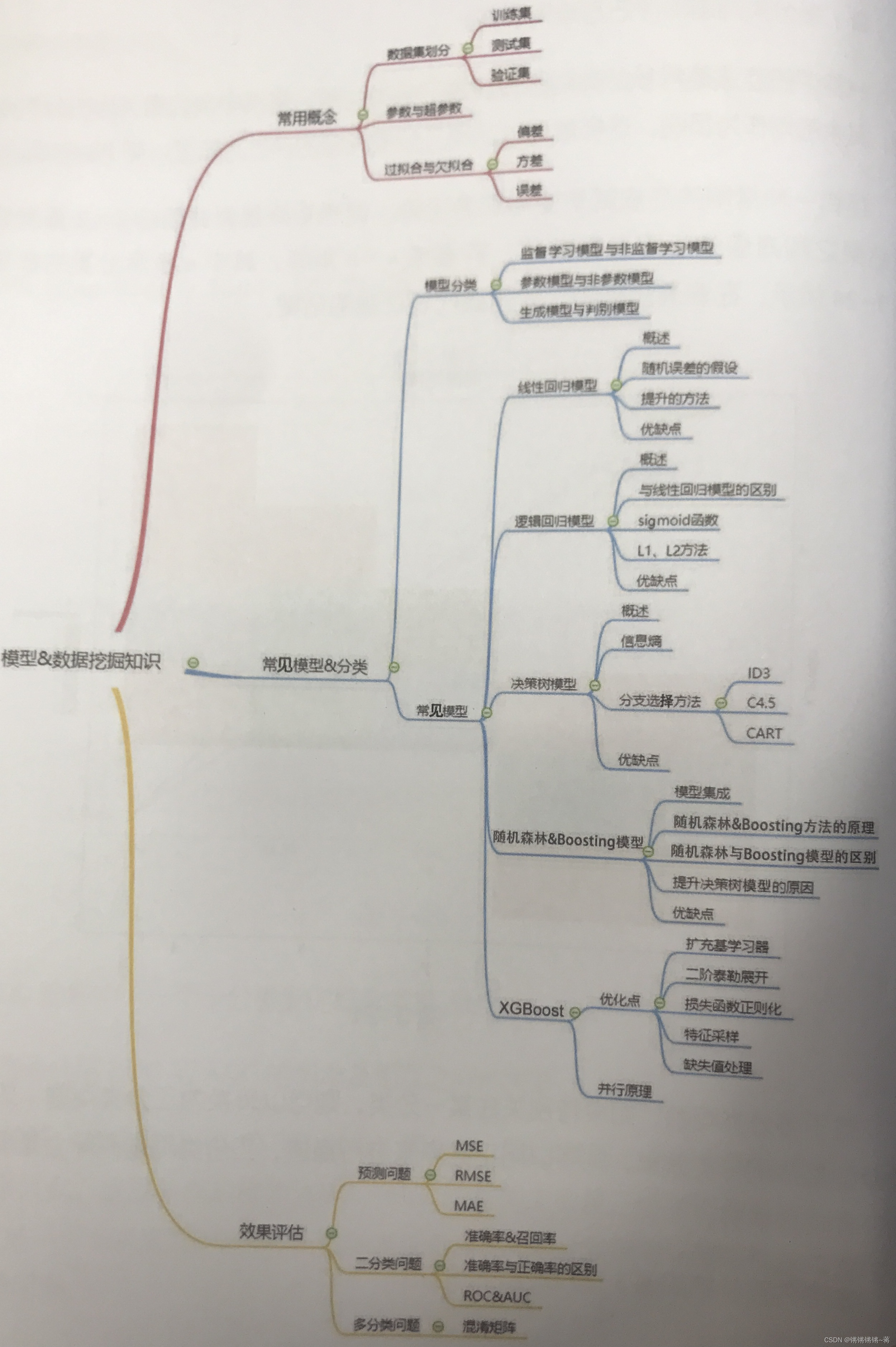
【数据分析师求职面试指南】必备基础知识整理
数据分析师基础知识
- 统计 数据分析知识
- 基础概念
- 随机变量常用特征
- 正态分布与大数定律、中心极限定律
- 假设检验
- 模型、数据挖掘知识
- 常用概念
- 数据集划分
- 欠拟合过拟合
- 模型分类方法
- 常见模型介绍
- 线性回归模型:
- 逻辑回归模型
- 决策树模型
- 随机森林模型
- Boosting模型
- XGBoost模型
- 模型效果评估方法
内容整理自《拿下offer 数据分析师求职面试指南》—徐粼著 第三章基础知识考查
其他内容:
【数据分析师求职面试指南】必备基础知识整理
【数据分析师求职面试指南】必备编程技能整理之Hive SQL必备用法
【数据分析师求职面试指南】实战技能部分
统计 数据分析知识
基础概念
随机试验:相同条件下对某随机现象进行大量重复观测
样本理解为每次随机试验的结果,xxx
随机变量XXX 离散型、连续型,区别在于描述的随机试验的所有可能结果是否可数。【不是有限】
常见的离散型随机变量的分布:伯努利分布(01分布);二项分布(n重伯努利分布);泊松分布:描述单位时间或空间内随机事件发生的次数。
常见连续型随机变量:需要定义分布函数F(x)F(x)F(x) 均匀分布;正态分布;只是分布:描述泊松过程中时间之见的时间的概率分布。
随机变量常用特征
数字特征:期望(随机变量X的平均水平),方差,标准差,分位数(中位数是特殊分位数)、协方差&相关系数(X,Y独立,协方差相关系数钧0)
协方差只表示相关的方向,方差时协方差的特殊情况,两个变量是相同的情况;
相关系数不仅表示线性相关的方向,还衡量相关程度
变量独立VS变量不相关:不相关:两者没有线性关系,不排除其他关系;独立指互不相关,没有关联。
正态分布与大数定律、中心极限定律
正态分布:非偏态分布,图形以期望为中心左右堆成,期望=中位数。
大数定律核心在于随机变量X对应的堆积实验重复多次,随着试验次数增加,X均值愈发趋近于E(X)
辛钦大数定律:是要求随机变量独立同分布,期望方差相同;伯努利大数定律:若辛钦中随机变量是特定的伯努利二次分布式(二项分布),期望方差相同;切比雪夫大数定律:要求随机变量相互独立或者不相关,有更强广泛性,期望方差存在。
中心极限定律的阐述:假设来自同一个随机试验的一组样本,随机变量X表示样本的二郡治,随着样本数量的增加,X的分布愈发趋近正态分布。
定理表明,随着实验次数增加,一组独立同分布的变量的均值可以近似看作正态分布,且方差随着次数增加而减少。
中心极限定理作用:
(1)在没有办法得到总体全部数据的情况下,我们可以用样本来估计总体。
(2)根据总体的平均值和标准差,判断某个样本是否属于总体。
假设检验
注:原假设H0,备择假设H1。备择假设是真正要证明的,具体选择是看实际需要不是随机选择。
基本思想:通过证明在原假设成立的前提下,检验统计量出现当前值或者更为极端的值【p-value】属于“小概率"事件,以此推翻原假设,接受备择假设。(小概率定义是将p-value与预先设定的显著性水平a机型对比,小于a,推翻原假设)
通俗解释:小概率反证法。 即为了检验一个假设是否成立,我们先假设它成立,在原假设成立的前提下,如果出现了不合理的事件,则说明样本与总体的差异是显著的,就拒绝原假设,如果没有出现不合理的事件,就不拒绝原假设。
两类错误:弃真原假设成立情况下错误地拒绝原假设;取伪没有成功地拒绝不成立的原假设。
如何平衡两类错误:先预定犯第一类错误的上线,即定义显著性水平a,再减少第二类错误β的发生概率,1-β对应规避第二类错误的概率–power,称检验效能,大小可通过增加样本量提高,通常要达到80%或更高。
置性度:1-a
模型、数据挖掘知识
常用概念
参数VS超参数:参数是通过模型对训练集的拟合获得。超参数在模型训练前需认为给出,如决策树深度、随机森林模型树的数量等
简述过拟合和欠拟合:模型误差是方差+偏差,偏差反映模型再训练集样本上的期望输出与真是结果的差距,即模型本身精确度,反应模型本身拟合能力。偏差过高反映欠拟合,表明模型过于简单,没有很好拟合训练变量之间的特咸亨。
方差反映模型在不同训练集下得到结果与真是结果之间误差的波动,即模型稳定性。模型复杂时,会大量学习训练集中噪声,导致模型泛化性能变差,就是过拟合产生的原因。
数据集划分
在数据挖掘中,通常将数据集分为三类:训练集、验证集合测试集,如上图所示。
训练集:结果已知,用于模型训练拟合的数据样本,在实际应用中这部分数据往往会占总体样本的70%~80%。
验证集:结果已知,不参与模型的训练拟合过程,用于验证通过训练集得到的模型效果,同时对模型中的超参数进行选择。
测试集:结果未知,最终利用模型输出结果的数据集。
这三部分构成了模型的整体数据集。模型上线后,输出模型在测试集上的结果,并与最终的实际结果进行对比。测试集后续可以转化为训练集或者验证集,实现模型的不断迭代和优化。
欠拟合过拟合
欠拟合(underfitting)是指相较于数据而言,模型参数过少或者模型结构过于简单,以至于无法捕捉到数据中的规律的现象。
欠拟合主要产生的原因:模型复杂度过低,无法很好的去拟合所有的训练数据,导致训练误差大。
增加模型复杂度,尝试使用核SVM、决策树、深度神经网络(DNN)
增加新特征,增加假设空间
如果有正则项,可以调小正则项参数
过拟合主要产生的原因:模型复杂度过高,训练数据少,训练误差小,但是测试误差大
增加训练数据可以有限的避免过拟合
正则化,L1、L2;如果有正则项,则考虑增大正则项参数
交叉验证
特征选择,减少特征数或使用较少的特征组合
模型训练所要做的就是平衡过拟合和欠拟合,通过在验证集中的验证工作,选择合适的超参数,最终降低误差。
模型分类方法
训练数据有特征有标签监督学习。
标签连续–预测(prediction)。 线性回归、时间序列、神经网络
离散–分类(classification):标签可数情况下判断结果所属类别。逻辑回归、SVM、决策树、随机森林、Boosting
只有特征:无监督学习。
通过数据内在联系和相似性将样本划分若干类–聚类(clustering)。K-Means 、DBSCAN
E-M
高位数据降维(dimension reduction) PCA
参数模型:y=f(x),训练前就确定了形式。如线性回归、逻辑回归、贝叶斯,
优点:可解释性、模型学习和训练速度相对快速,对数据量要求低,不需要特别大训练集。
缺点:要提前对目标函数做假设,而现实生活中问题很难真正应用某一目标函数,容易欠拟合。
非参数模型对目标函数不过多假设,当数据趋于无穷大可以逼近任意复杂模型。因此在数据量大、逻辑复杂的问题中效果好于参数模型
缺点:更复杂,计算量大,对问题可解释性更弱。如SVM、决策树、随机森林。
神经网络是半参数模型。
生成模型学习得到联合概率分布P(x,y),然后求条件概率分布。常见朴素贝叶斯模型、混合高斯模型、隐马尔可夫模型
判别模型学习得到条件概率分布P(x|y),常见决策树模型、SVM、逻辑回归。
生成模型需要更大计算量,准确率、适用范围也弱于判别模型,所以实际工作中使用判别模型为主。
常见模型介绍
线性回归模型:
y=w′x+ey=w'x+ey=w′x+e w为参数行列式,e为随机误差,且仿佛从期望为0的正态分布。
线性回归中对随机误差做出的假设:
随机误差是一个期望或平均值为0的随机变量;
对于解释变量的所有观测值,随机误差有相同方差;
随机误差彼此互不相关;
解释变量是确定型变量,不是随机变量,与随机误差彼此相互独立
;随机误差服从正态分布。
优点在于快速,能处理数据量不大的情况,有可解释性,可以有效指导业务部门进行决策。缺点是 需要提前对目标函数进行假设,数据量增加问题复杂时,模型往往无法很好的处理,此时需要其他模型。
提升效果:
一是引入高次项。 某些因变量与自变量本身并不存在线性关系,但是与其二次项或者更高次项存在线性关系,此时就需要引入高次项。需要注意的是,在引入某自变量的高次项之后,需要保留其相应的低次项。
二是引入交互项。 一个预测变量对模型结果的影响,在其他预测变量有不同值的时候是不同的,这称为变量之间的交互关系。引入交互项的方式通常是将两个预测变量相乘放入模型中作为交互项。将一个交互项放到模型中会极大地改善所有相关系数的可解释性。在引入交互项之后,需要保留组成交互项的自变量。
逻辑回归模型
与线性回归区别:逻辑回归主要用于解决二分类问题,而非预测类问题。
为避免过拟合,引入正则化方法L1–lasso,惩罚系数的绝对值,乘法后有的系数直接变成0,其他系数绝对值收缩;L2—ridge,惩罚系数的平方,惩罚后每个系数的绝对值收缩。
二者区别:L1可以筛选变量,变量较多时,能选择较为重要的变量。
有点:可解释性强,与线性回归模型相同,随着数据量增加,逻辑回归模型欠拟合,此时需要选择非参数模型训练。
决策树模型
非参数模型,无需对目标函数和变量做过多假设,使用更灵活,能处理更复杂场景下问题。
决策树模型如何确定每个节点选择的特征:
常用方法:ID3,C4.5,每一步特征的选取都是基于信息熵的,通过在节点上生成新的分支来降低信息熵。信息熵表示随机变量的不确定性。
比较:ID3 选择特征是会选择信息增益最大化的特征左节点。C4.5考虑信息增益比最大化,会避免选择有过多分枝的特征作为节点。
还有CART方法使用Gini系数代替信息熵。前两种方法只能处理分类,CART可以处理分类和预测,能处理连续纸,实际中应用更广泛(sklearn中就是)
调优方法:
- 控制树的深度和节点个数等等,避免过拟合;
- 运用交叉验证法,选择合适参数;
- 通过模型集成方法,基于决策树形成更复杂的模型。
ID3存在的问题在于会选择有比较多分支的特征作为节点,造成模型的过拟合。 相比于ID3,C4.5将单纯地考虑信息增益最大化变成了考虑信息增益比最大化。
优点:
- 决策树模型本身属于非参数模型,相比于线性回归模型和逻辑回归模型,它不需要对样本进行预先假设,因此能够处理更加复杂的样本。
- 它的计算速度较快,结果容易解释,可以同时处理分类问题和预测问题,并且对缺失值不敏感。
- 决策树模型具有非常强的可解释性,通过绘制分支,可以清晰地看出整体的模型选择流程,快速发现影响最终结果的因素,能够指导业务快速进行相应的修改、调整。
缺点:
- 决策树模型是一种“弱学习器”,即使通过调优方法进行了优化,也仍然容易产生过拟合的现象,造成最终结果误差较大
- 在处理特征关联性比较强的数据时表现得不是很好。
随机森林模型
模型集成:将多个弱学习器(基模型)进行组合,提高模型的学习泛化能力。常用的Bagging,Boosting,随机森林和GBDT是各自的代表。
模型融合:模型集成中需要将各个基模型的结果进行组合,得到最终结果。
常用方法:平均法(预测问题),投票法(分类问题)选预测较多的类别。
随机森林基本原理:通过对样本或变量的n次随机采样,就可以得到n个样本集。对于每个样本集,可以独立训练决策树模型,对于n个决策树模型的结果,通过集合策略得到最终的输出。n个决策树模型之间是相对独立不是完全独立。
可以Boostrap Sample(有放回采样)方法实现对样本的随机采样,每次约**63.2%**的样本被选中。
相比于决策树模型,随机森林效果好,因为:各个决策树相同的偏差和方差,通过将多个决策树模型的道德结果进行平均或投票,随机森林模型的偏差与单个决策树模型偏差基本相同,但是由于相对独立性,可以大幅度减少随机森林模型的方差,最终误差(偏差+方差)变小。
Boosting模型
将多个决策树集成后的一种模型,注意与随机森林区别:
分别运用模型集成中的Boosting和Bagging方法,最大区别在于:
- 随机森林的各个决策树模型的生成是相互独立的,是基于通过样本重采样方法得到不同训练集而产生不同的决策树模型的;
- 而Boosting模型是基于此前已经生成的决策树模型的结果,所以决策树的生成并不是相互独立的,每一个新的决策树模型都依赖于前一个决策树模型。
常见的包括AdaBoost、GBDT。区别:
- AdaBoost会加大此前决策树模型中分类错误的数据的权重,使得下一个生成的决策树模型能尽量将这些训练集分类正确;
- GBDT是通过计算损失函数梯度下降方向,定位模型的不足而建立新的决策树模型的。实际中后者应用广泛。
GBDT、随机森林都基于决策树模型的集成学习方法,能处理离散和连续变量同时存在的场景,能处理较复杂问题。但面对更大训练集时,训练速度较慢,需要更加快速方法。
XGBoost模型
基于GBDT模型优化的原因:
- GBDT以CART树做基学习器,XGBoost还支持==线性分类器==,基学习器可以是L1,L2政策画的逻辑回归模型或线性回归模型,提高模型的应用范围;
- GBDT优化时只用到损失函数一阶导数信息,XGBoost则对损失函数进行了二阶泰勒展开,得到了一阶导数和二阶导数,加快优化速度
- XGBoost模型在损失函数中加入正则项,用于控制模型的复杂度。从权衡方差和偏差的角度看,降低了方差,使学习的模型更简单,可防止过拟合,提高模型泛化能力。
- 生成决策树过程中支持列抽样,不仅防止过拟合,还减少计算量
- 能自动处理缺失值,将其单独作为一个分支
简述并行:
不是指模型上并行,指特征上并行。在训练之前,预先对数据进行排序,保存为块结构,后面迭代过程中重复使用此结构,减少了计算量。块也使并行化成为可能。此外,节点选择时,需要计算每个特征的增益,最终选择增益最大的特征作为节点,各个特征的增益计算就是基于 块结构实现并行操作的。
模型效果评估方法
- MSE(Mean Squared Error 均方误差):参数估计值与参数真值之差平方夫人期望值。可以用于评估数据的变化程度,越小,精确度越高。
- RMSE(均方根误差):MSE开算术平方根
- MAE(Mean Absolute Error,平均绝对误差):绝对误差的平均值,在一些问题上更好地反映预测值误差的实际情况。
二分类问题评估方法:
TP(True Positive)实际正例预测为正例
FP(False Positive)实际反例预测为正例
FN
TN
准确率:精度,实际正判断正/判断为正:TP/(TP+FP)
召回率:查全率,实际正判断正/实际正:TP/(TP+FN)
这里用警察抓小偷的例子进行解释。由于问题中需要关注的是小偷部分,所以将小偷的样本划为正例,将 😄
- 准确率解释为在抓到的人中小偷的占比,
- 将召回率解释为在所有小偷中被抓到的占比。
PR曲线用于可视化这两个指标,通常固定一个指标,比如固定20%召回率,然后提高准确率。【图像准确率斜向上,召回率斜向下,呈X】
正确率:(TP+TN)/(TP+FN+FP+TN) 同时考虑了正负样本预测情况,而实际中大多对正样本比较感兴趣。
ROC曲线:
横纵坐标:FPR(False Positive Rate):TP/TP+FN-- 正正/正正+负负;TPR(True Positive Rate):FP/FP+TN–负正/负正+正负
一定经过(0,0)(1,1)要使下方面积最大化–AUC
多分类问题
一种评估方法:转换为二分类问题,最关心的分类视为正。
另一种:混淆矩阵,将此前2x2预测值与实际结果之间对应矩阵扩展呈nxn,对角线是正确结果。
相关文章:
【数据分析师求职面试指南】必备基础知识整理
数据分析师基础知识统计 数据分析知识基础概念随机变量常用特征正态分布与大数定律、中心极限定律假设检验模型、数据挖掘知识常用概念数据集划分欠拟合过拟合模型分类方法常见模型介绍线性回归模型:逻辑回归模型决策树模型随机森林模型Boosting模型XGBoost模型模型…...
的原理与应用》)
《开关电源宝典 降压电路(BUCK)的原理与应用》
嗨,硬件攻城狮或电源工程师同行们,我想写本专门解析BUCK电源电路的书籍,以下是“前言”内容的部分摘录以及当前的目录,当前已经完成22万多字500多页了,即使如此,离真正出版书籍,还有很长的路要走…...

R语言基础(一):注释、变量
R语言用于统计分析和绘制图表等操作。不同于Java等其它语言,R用于统计,而不是做一个网站或者软件,所以R的一些开发习惯和其它语言不同。如果你是一个编程小白,那么可以放心大胆的学。如果你是一个有编程基础的人,那么需…...

Java 集合进阶(二)
文章目录一、Set1. 概述2. 哈希值3. 元素唯一性4. 哈希表5. 遍历学生对象6. LinkedHashSet7. TreeSet7.1 自然排序7.2 比较器排序8. 不重复的随机数二、泛型1. 概述2. 泛型类3. 泛型方法4. 泛型接口5. 类型通配符6. 可变参数7. 可变参数的使用一、Set 1. 概述 Set 集合特点&am…...

小孩用什么样的台灯比较好?2023眼科医生青睐的儿童台灯推荐
小孩子属于眼睛比较脆弱的人群,所以选购护眼台灯时,选光线温和的比较好,而且调光、显色效果、色温、防蓝光等方面也要出色,否则容易导致孩子近视。 1、调光。台灯首先是照度高,国AA级+大功率发光࿰…...
Ubuntu c++ MySQL数据库操作
mysql安装sudo apt-get install updatesudo apt-get install mysql-server libmysqlclient-dev mysql-workbenchmysql启动/重启/停止sudo service mysql start/restart/stop登录mysql命令:mysql -uroot -p错误异常:解决办法:修改mysqld.cnf配…...
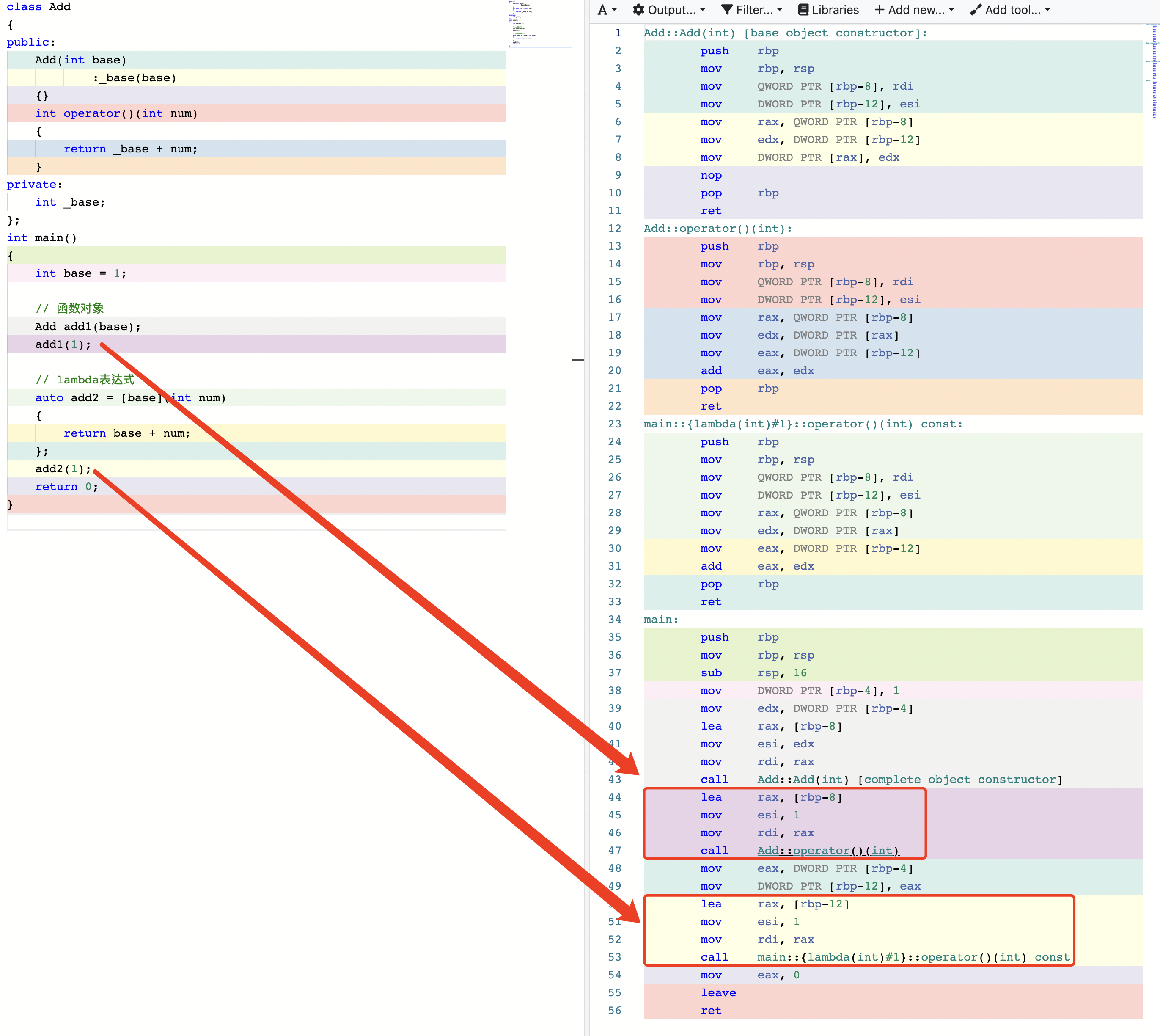
C++11:lambda表达式
文章目录1. 概念2. 语法3. 示例示例1示例2示例3示例44. 捕捉方式基本方式隐式和混合补充5. 传递lambda表达式示例6. 原理7. 内联属性1. 概念 lambda表达式实际上是一个匿名类的成员函数,该类由编译器为lambda创建,该函数被隐式地定义为内联。因此&#…...
【Android -- 开源库】表格 SmartTable 的基本使用
介绍 1. 功能 快速配置自动生成表格;自动计算表格宽高;表格列标题组合;表格固定左序列、顶部序列、第一行、列标题、统计行;自动统计,排序(自定义统计规则);表格图文、序列号、列标…...

自动化测试实战篇(9),jmeter常用断言方法,一文搞懂9种测试字段与JSON断言
Jmeter常用的断言主要有,JSON断言和响应断言这两种方式。 断言主要就是帮助帮助人工进行快速接口信息验证避免繁杂的重复的人工去验证数据 第一种响应断言Apply to:表示应用范围测试字段:针对响应数据进行不同的匹配响应文本响应代码响应信息…...

vue-virtual-scroll-list虚拟列表
当DOM中渲染的列表数据过多时,页面会非常卡顿,非常占用浏览器内存。可以使用虚拟列表来解决这个问题,即使有成百上千条数据,页面DOM元素始终控制在指定数量。 一、参考文档 https://www.npmjs.com/package/vue-virtual-scroll-li…...
C++学习笔记(以供复习查阅)
视频链接 代码讲义 提取密码: 62bb 文章目录1、C基础1.1 C初识(1) 第一个C程序(2)注释(3)变量(4)常量(5)关键字(6)标识符命名规则1.2 …...
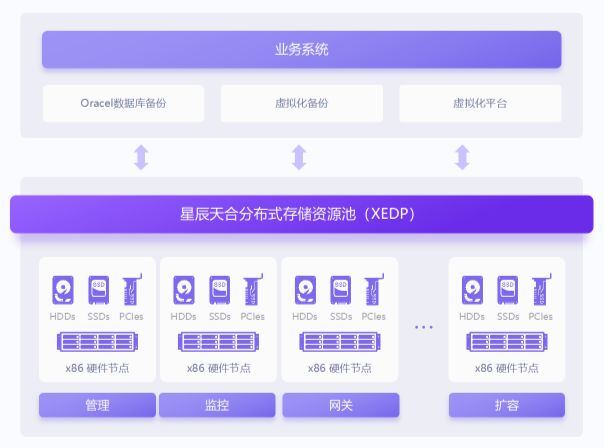
备份时间缩短为原来 1/4,西安交大云数据中心的软件定义存储实践
XEDP 统一数据平台为西安交通大学云平台业务提供可靠的备份空间和强大的容灾能力,同时确保数据安全。西安交通大学(简称“西安交大”)是我国最早兴办、享誉海内外的著名高等学府,是教育部直属重点大学。学校现有兴庆、雁塔、曲江和…...

我国近视眼的人数已经超过了六亿,国老花眼人数超过三亿人
眼镜是一种用于矫正视力问题、改善视力、减轻眼睛疲劳的光学器件,在我们的生活中不可忽略的一部分,那么我国眼镜市场发展情况是怎样了?下面小编通过可视化互动平台对我国眼镜市场的状况进行分析。我国是一个近视眼高发的国家,据统…...
设计模式(十八)----行为型模式之策略模式
1、概述 先看下面的图片,我们去旅游选择出行模式有很多种,可以骑自行车、可以坐汽车、可以坐火车、可以坐飞机。 作为一个程序猿,开发需要选择一款开发工具,当然可以进行代码开发的工具有很多,可以选择Idea进行开发&a…...
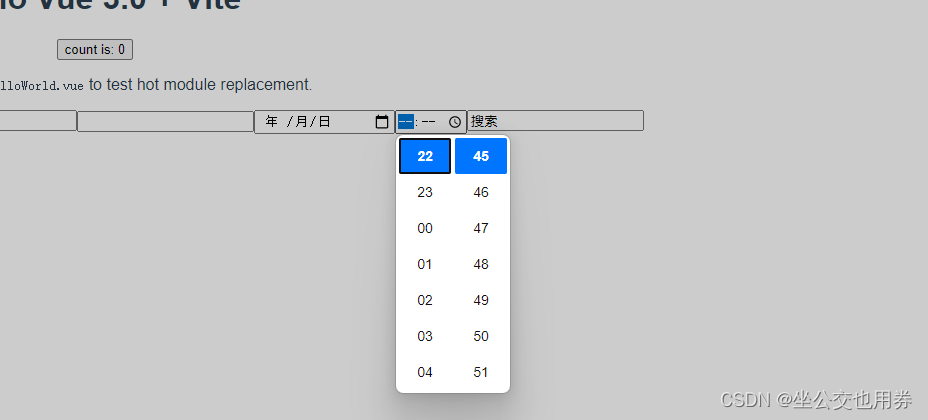
VUE3入门基础:input元素的type属性值说明
说明 在Vue 3中,<input>元素的type属性可以设置不同的类型,以适应不同的输入需求。 常见的type属性取值如下: text:默认值,用于输入文本。password:用于输入密码,输入内容会被隐藏。em…...

关于供应链,一文教你全面了解什么是供应链
什么是供应链?供应链是指产品生产和流通过程中所涉及的原材料供应商、生产商、分销商、零售商以及最终消费者等成员通过与上游、下游成员的连接 (linkage) 组成的网络结构。也即是由物料获取、物料加工、并将成品送到用户手中这一过程所涉及的企业和企业部门组成的一…...

Scope作用域简单记录分析
类型 singleton 单例作用域 prototype 原型作用域 request web作用域,请求作用域,生命周期跟request相同,请求开始bean被创建,请求结束bean被销毁 session web作用域,会话作用域,会话开始bean被创建,会话结束bean被销毁 application web作用域,应用程序作用域,应用程序创建…...

ChatGPT创作恋爱甜文
林欣是一个长相可爱、性格呆萌的小姑娘,她年纪轻轻就失去了父母,独自一人面对世界的冷漠和残酷。 虽然经历了这样的打击,但她并没有沉沦,反而更加努力地去生活。 她找到了一份服务员的工作,每天在餐厅里穿梭…...

贝叶斯优化及其python实现
贝叶斯优化是机器学习中一种常用的优化技术,其目的是在有限步数内寻找函数的最大值或最小值。它可以被视为在探索不同参数配置与观察这些配置结果之间寻求平衡点的过程。基本思想是将我们在过去的观察和体验,传递到下一个尝试中,从而在等待数…...

Lombok使用@Builder无法build父类属性
文章目录问题描述解决方案使用示例lombok Builder注解和build父类属性问题1、简介2.使用3、Builder注解对类做了什么?问题描述 实体类使用Lombok的Builder来实现Builder模式,但是如果使用了extend继承,则子类无法通过Builder来Build父类属性…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

FFmpeg:Windows系统小白安装及其使用
一、安装 1.访问官网 Download FFmpeg 2.点击版本目录 3.选择版本点击安装 注意这里选择的是【release buids】,注意左上角标题 例如我安装在目录 F:\FFmpeg 4.解压 5.添加环境变量 把你解压后的bin目录(即exe所在文件夹)加入系统变量…...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...