Spark关于 ExpressionEncoder[T] 以及 RowEncoder 以及Spark怎么做外部数据和内部数据的转换
背景
本文基于 Spark 3.3, 最近在用 Spark Api 做 DataSet[Row] 转换的时候遇到了一些 Spark内部转换的问题, 在此记录一下。
杂谈
我们知道在Spark中分为 InternalRow和Row, 前者是 Spark 内部的使用的一行数据的表示,后者是给Spark开发者使用的行数据表示。
在Spark中如果涉及到 InternalRow和Row 转换的时候,这个时候就会用到 ExpressionEncoder[Row] 来做序列化和反序列化,而获取 ExpressionEncoder[Row]的方式一般就是调用RowEncoder.apply(StructType)方法。比如在delta 1.0.0 用到的 Row转换:
val joinedRowEncoder = RowEncoder(joinedPlan.schema)val outputRowEncoder = RowEncoder(deltaTxn.metadata.schema).resolveAndBind()val processor = new JoinedRowProcessor(targetRowHasNoMatch = resolveOnJoinedPlan(Seq(col(SOURCE_ROW_PRESENT_COL).isNull.expr)).head,sourceRowHasNoMatch = resolveOnJoinedPlan(Seq(col(TARGET_ROW_PRESENT_COL).isNull.expr)).head,matchedConditions = matchedClauses.map(clauseCondition),matchedOutputs = matchedClauses.map(matchedClauseOutput),notMatchedConditions = notMatchedClauses.map(clauseCondition),notMatchedOutputs = notMatchedClauses.map(notMatchedClauseOutput),noopCopyOutput =resolveOnJoinedPlan(targetOutputCols :+ Literal.FalseLiteral :+ incrNoopCountExpr),deleteRowOutput =resolveOnJoinedPlan(targetOutputCols :+ Literal.TrueLiteral :+ Literal.TrueLiteral),joinedAttributes = joinedPlan.output,joinedRowEncoder = joinedRowEncoder,outputRowEncoder = outputRowEncoder)val outputDF =Dataset.ofRows(spark, joinedPlan).mapPartitions(processor.processPartition)(outputRowEncoder)logDebug("writeAllChanges: join output plan:\n" + outputDF.queryExecution)这里会涉及到两个ROW的转换,两个ROW的 Schema 是不一致的,如果要涉及到两个ROW之间的转换的时候,而且spark.implicits._也没对应的隐式参数的时候,就得自己构造ExpressionEncoder[Row],其实 说到底 spark序列化和反序列化用的都是Expression表达式,下面就来分析一下这里的序列化和反序列化是怎么做的。
分析
直接上代码:
object RowEncoder {def apply(schema: StructType, lenient: Boolean): ExpressionEncoder[Row] = {val cls = classOf[Row]val inputObject = BoundReference(0, ObjectType(cls), nullable = true)val serializer = serializerFor(inputObject, schema, lenient)val deserializer = deserializerFor(GetColumnByOrdinal(0, serializer.dataType), schema)new ExpressionEncoder[Row](serializer,deserializer,ClassTag(cls))}...
}
经过serializerFor方法以后,返回 CreateNamedStruct(Seq(GetExternalRowField(BoundReference(0, ObjectType(cls), nullable = true),index,name))),注意如果,存在String类型的话,在序列化的时候会调用 StaticInvoke(classOf[UTF8String],"fromString")进行反射调用序列化。
而经过deserializerFor方法以后,返回CreateExternalRow(Seq(GetStructField(GetColumnByOrdinal(0, serializer.dataType)))),注意对于 String类型的,在反序列化的时候会调用Invoke("toString") 反射调用反序列化。
而真正在进行行处理的时候,会调用ExpressionEncoder[Row].createSerializer和ExpressionEncoder[Row].createDeserializer。对于ExpressionEncoder[Row].createDeserializer调用之前,还得调用resolveAndBind进行参数的绑定。
对于序列化
主要是如下方法:
def createSerializer(): Serializer[T] = new Serializer[T](optimizedSerializer)
class Serializer[T](private val expressions: Seq[Expression])extends (T => InternalRow) with Serializable {@transientprivate[this] var inputRow: GenericInternalRow = _@transientprivate[this] var extractProjection: UnsafeProjection = _override def apply(t: T): InternalRow = try {if (extractProjection == null) {inputRow = new GenericInternalRow(1)extractProjection = GenerateUnsafeProjection.generate(expressions)}inputRow(0) = textractProjection(inputRow)} catch {case e: Exception =>throw QueryExecutionErrors.expressionEncodingError(e, expressions)}}
可以看到在apply的方法中会进行如下操作:
// 新建一个只有一列数据的ROW,并赋值为输入的值。
inputRow = new GenericInternalRow(1)
inputRow(0) = t
这里就和序列化的表达式BoundReference(0, ObjectType(cls), nullable = true)吻合了: 取行数据中第一列的值.extractProjection 最终会根据 表达式计算出结果并返回 UnsafeRow
对于反序列化
在反序列化的时候,得先调用resolveAndBind方法,进行Schema的绑定,便于从一样数据中取对应的数据。
def resolveAndBind(attrs: Seq[Attribute] = schema.toAttributes,analyzer: Analyzer = SimpleAnalyzer): ExpressionEncoder[T] = {val dummyPlan = CatalystSerde.deserialize(LocalRelation(attrs))(this)val analyzedPlan = analyzer.execute(dummyPlan)analyzer.checkAnalysis(analyzedPlan)val resolved = SimplifyCasts(analyzedPlan).asInstanceOf[DeserializeToObject].deserializerval bound = BindReferences.bindReference(resolved, attrs)copy(objDeserializer = bound)}
这个CatalystSerde.deserialize方法获取deserializer变量:
val deserializer: Expression = {if (isSerializedAsStructForTopLevel) {// We serialized this kind of objects to root-level row. The input of general deserializer// is a `GetColumnByOrdinal(0)` expression to extract first column of a row. We need to// transform attributes accessors.objDeserializer.transform {case UnresolvedExtractValue(GetColumnByOrdinal(0, _),Literal(part: UTF8String, StringType)) =>UnresolvedAttribute.quoted(part.toString)case GetStructField(GetColumnByOrdinal(0, dt), ordinal, _) =>GetColumnByOrdinal(ordinal, dt)case If(IsNull(GetColumnByOrdinal(0, _)), _, n: NewInstance) => ncase If(IsNull(GetColumnByOrdinal(0, _)), _, i: InitializeJavaBean) => i}} else {// For other input objects like primitive, array, map, etc., we deserialize the first column// of a row to the object.objDeserializer}}
这里会把表达式变成CreateExternalRow(Seq(GetColumnByOrdinal(index))),最终会
得到DeserializeToObject(UnresolvedDeserializer(CreateExternalRow(Seq(GetColumnByOrdinal(index)))),LocalRelation(attrs)) 计划。
该计划经过ResolveDeserializer 规则解析, 会把 GetColumnByOrdinal(index)变成对应的属性值。
最终 BindReferences.bindReference(resolved, attrs)转换成Seq(BoundReference(ordinal, a.dataType, input(ordinal).nullable))可执行表达式,最最终绑定到表的特定属性上,从而获取对应的值。
真正时机进行操作的时候,调用的是createDeserializer方法:
def createDeserializer(): Deserializer[T] = new Deserializer[T](optimizedDeserializer)
class Deserializer[T](private val expressions: Seq[Expression])extends (InternalRow => T) with Serializable {@transientprivate[this] var constructProjection: Projection = _override def apply(row: InternalRow): T = try {if (constructProjection == null) {constructProjection = SafeProjection.create(expressions)}constructProjection(row).get(0, anyObjectType).asInstanceOf[T]} catch {case e: Exception =>throw QueryExecutionErrors.expressionDecodingError(e, expressions)}}
可以看到 最终的表达式CreateExternalRow(Seq(BoundReference(ordinal, a.dataType, input(ordinal).nullable))) 会生成 GenericRowWithSchema类型的ROW,
constructProjection = SafeProjection.create(expressions)
constructProjection(row).get(0, anyObjectType).asInstanceOf[T]
其中 constructProjection 返回的是 SpecificInternalRow类型的ROW。
所以constructProjection(row)返回的是SpecificInternalRow(GenericRowWithSchema)的值,所以get(0)是 GenericRowWithSchema类型的ROW,也就是ROW类型。
额外的话
对于BoundReference(ordinal, a.dataType, input(ordinal).nullable)该方法,该方法是用来把表示涉及的属性,给映射到对应的计划的属性值上,这样我们计算的时候,就可以获取到对应的值,一般是调用BindReferences.bindReference方法,这也是为什么表达式能获取到对应的属性值的原因。
相关文章:

Spark关于 ExpressionEncoder[T] 以及 RowEncoder 以及Spark怎么做外部数据和内部数据的转换
背景 本文基于 Spark 3.3, 最近在用 Spark Api 做 DataSet[Row] 转换的时候遇到了一些 Spark内部转换的问题, 在此记录一下。 杂谈 我们知道在Spark中分为 InternalRow和Row, 前者是 Spark 内部的使用的一行数据的表示,后者是给Spark开发者使用的行数…...

D-Day 上海站回顾丨以科技赋能量化机构业务
5月31日下午,DolphinDB 携手光大证券,在上海成功举办 D-Day 行业交流会。三十余位来自私募机构的核心策略研发、量化交易员、数据分析专家们齐聚现场,深入交流量化投研交易过程中的经验、挑战及解决方案。 DolphinDB 赋能机构业务平台 来自光…...

业财一体化的重点、难点和模式
业财一体化的内涵是企业将经营活动、财务管理、经营决策等进行科学的融合和管理,进而提高企业经营管理和财务决策的科学性,同时,基于IT技术、流程再造和组织重构更好的保障企业价值创造功能的实现。其涵盖管理循环、业务循环、信息循环三个双…...

gorse修改开源项目后,如何使用Docker compose发布
代码修改 git checkout v0.4.15 修改代码后提交。 镜像构建 export GOOSlinux export GOARCHamd64 export GOMAXPROCS8go build -ldflags"-s -w -X github.com/zhenghaoz/gorse/cmd/version.Version$(git describe --tags $(git rev-parse HEAD)) -X github.com/zhengh…...

Bowyer-Watson算法
数学原理及算法过程 Delaunay 三角剖分是一种特殊的三角剖分方法,它满足以下两个重要性质: 最大化最小角性质:Delaunay 三角剖分通过避免细长的三角形来最大化所有三角形的最小角。空外接圆性质:在 Delaunay 三角剖分中…...

计算机基础之:fork进程与COW机制
在Unix-like操作系统中,fork()是一个系统调用,用于创建一个与调用进程(父进程)几乎完全相同的新进程(子进程),包括父进程的内存空间、环境变量、文件描述符等。这个过程是通过写时复制ÿ…...
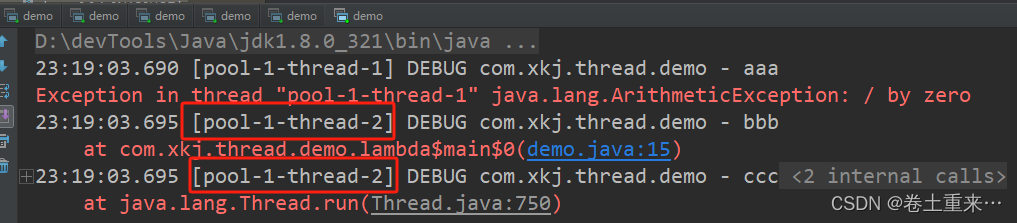
47.各种类型的线程池
线程池继承体系 Executor(interface)->ExecutorService(interface)->ThreadPoolExecutor(class) Executors.newFixedThreadPool 核心线程数最大线程数(没有救急线程被创建),所以也无需超时时间阻塞队列LinkedBlockingQueue,可以放任意…...

多目标优化-NSGA-II
文章目录 一、前置知识NSGA-II帕累托前沿 二、算法流程1.NSGA2.NSGA-II 一、前置知识 1.NSGA(非支配排序遗传算法):旨在同时优化多个冲突的目标函数,寻找帕累托前沿上的解集。 什么是多个冲突的目标: 比如你看上了一辆车,你既想要它便宜,又…...

元宇宙数字藏品交易所,未来发展的大趋势
随着科技的飞速进步,元宇宙以其独特的魅力为数字世界绘制了一幅前所未有的宏伟蓝图。在这一宏大的背景下,数字藏品交易所作为连接虚拟与现实的桥梁,正以其卓越的优势,引领着数字藏品市场迈向新的高度。 首先,元宇宙为…...

通配符https数字证书260
随着越来越多的人开始使用互联网,互联网上的信息变得繁杂,用户很难识别网站信息的真实性,为了维护互联网的环境,开发者开始使用https证书对网站传输数据进行加密和身份认证,以此来保护用户的隐私以及标示网站的真实性。…...
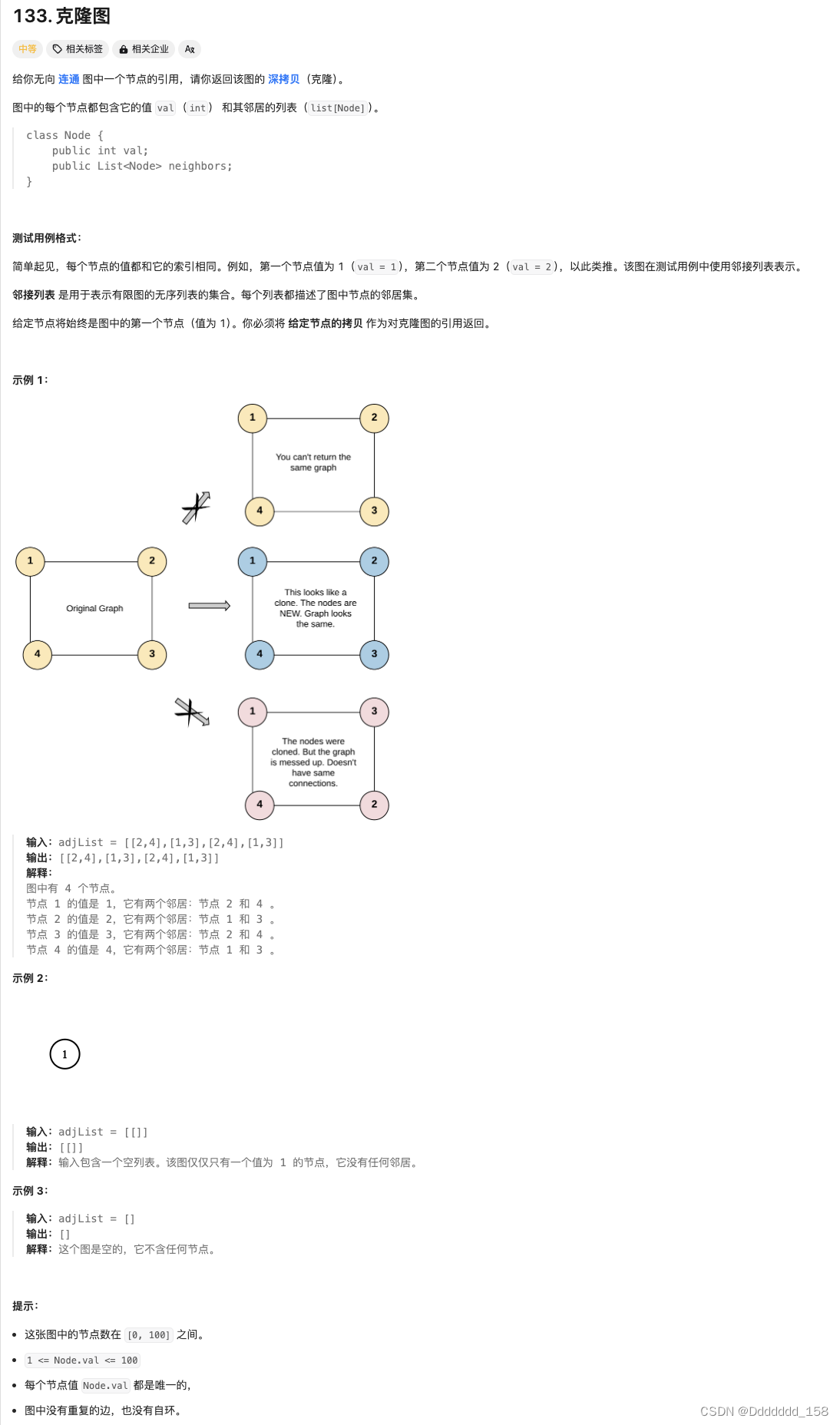
C++ | Leetcode C++题解之第133题克隆图
题目: 题解: class Solution { public:Node* cloneGraph(Node* node) {if (node nullptr) {return node;}unordered_map<Node*, Node*> visited;// 将题目给定的节点添加到队列queue<Node*> Q;Q.push(node);// 克隆第一个节点并存储到哈希…...

yangwebrtc x86_64环境搭建
版本:5.0.099 sudo apt-get install libxext-dev sudo apt-get install x11proto-xext-dev sudo apt-get install libxi-dev sudo apt install libasound2-dev sudo apt install libgl1-mesa-dev sudo apt-get install libxtst-dev 用qt打开以下两个项目的.pro met…...

前端面试题日常练-day53 【面试题】
题目 希望这些选择题能够帮助您进行前端面试的准备,答案在文末 1. 在PHP中,以下哪个函数可以用于从一个数组的末尾删除一个元素并返回被删除的元素? a) array_pop() b) array_push() c) array_shift() d) array_unshift() 2. 在PHP中&…...
空间不够用了怎么办
空间告急啊哥们 整理一下清理空间有用的一些blog吧。 【linux】公共服务器如何清理过多的.cache缓存 linux根目录空间不足,追加空间到根目录下 【linux】linux磁盘空间 目录查看清理 和 文件查看清理...

pytorch数学操作
文章目录 1.torch.bitwise_not()2.torch.bitwise_and()3.torch.ceil()3.torch.clamp()4.torch.torch.floor() 1.torch.bitwise_not() 在 PyTorch 中,torch.bitwise_not() 是一个函数,用于执行逐元素的位非(bitwise NOT)操作。 t…...
如何做好电子内窥镜的网络安全管理?
电子内窥镜作为一种常用的医疗器械,其网络安全管理对于保护患者隐私和医疗数据的安全至关重要。以下是一些基本原则和步骤,用于确保电子内窥镜的网络安全: 1. 数据加密 为了防止数据泄露,电子内窥镜在传输患者图像数据时应采取有…...

Spring Boot项目中,如何在yml配置文件中读取maven pom.xml文件中的properties标签下的属性值
一、前言 在最近的项目开发过程中,有一个需求,需要在Spring Boot项目的yml配置文件中读取到mave的 pom.xml文件中的properties标签下的属性值,这个要怎么实现呢? 二、技术实践 pom.xml文件中增加测试属性 <properties><…...

C++:模板进阶
✨✨✨学习的道路很枯燥,希望我们能并肩走下来! 文章目录 文章目录 前言 一 非类型模板参数 二 模板的特化 2.1 概念 2.2 函数模板特化 函数模板的易错点 2.3 类模板特化 2.3.1 全特化 2.3.2 偏特化 部分特化 参数更进一步的限制 2.3.3 类模板特化应用示例…...

Linux 磁盘分区步骤
1.lsblk用于查看磁盘分区情况,lsblk -f用于查看uuid字符串以及挂载点。 以下是虚拟机部分添加磁盘的步骤。 其余没展示的都按照默认设置进入下一步即可。 2.添加完成后使用reboot重新进入后再使用lsblk就会发现磁盘sdb已经有了,但是没有分区。现在添加分…...
【TB作品】 51单片机8x8点阵显示滚动汉字仿真
功能 题目5基于51单片机LED8x8点阵显示 流水灯 直接滚动显示HELLO 直接滚动显示老师好 代码 void main( void ) {/** 移位后,右边的是第一个595,接收0X02,显示出0X02* 移位后,左边的是第2个595,接收0Xfe,…...

RBTray完全指南:Windows任务栏清理终极解决方案
RBTray完全指南:Windows任务栏清理终极解决方案 【免费下载链接】rbtray A fork of RBTray from http://sourceforge.net/p/rbtray/code/. 项目地址: https://gitcode.com/gh_mirrors/rb/rbtray 你是否经常感到Windows任务栏拥挤不堪?各种后台程序…...

YOLOFuse效果惊艳:红外热成像+可见光,极端环境下的检测利器
YOLOFuse效果惊艳:红外热成像可见光,极端环境下的检测利器 1. 多模态检测的技术突破 在智能安防、自动驾驶和工业检测等关键领域,视觉系统常常面临极端环境的挑战:漆黑的夜晚、弥漫的烟雾、刺眼的强光...传统基于RGB图像的目标检…...

网络设备唯一身份证:MAC地址原理与作用全网最详解析
网络设备唯一身份证:MAC地址原理与作用全网最详解析 前言一、MAC地址:核心定义1.1 标准定义1.2 通俗理解1.3 核心特性 二、MAC地址:表示格式2.1 标准格式2.2 组成结构(两大部分)2.3 结构流程图 三、MAC地址:…...

Phi-3-Mini-128K入门必看:轻量化开源大模型本地部署全流程
Phi-3-Mini-128K入门必看:轻量化开源大模型本地部署全流程 1. 项目概述 Phi-3-Mini-128K是一款基于微软Phi-3-mini-128k-instruct模型开发的轻量化对话工具。它专为本地环境优化设计,无需云端依赖,普通配备GPU的电脑即可流畅运行。这个工具…...

Windows系统优化终极指南:用Win11Debloat一键清理臃肿系统
Windows系统优化终极指南:用Win11Debloat一键清理臃肿系统 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter an…...

如何让你的10美元鼠标秒变Mac神器?Mac Mouse Fix终极指南
如何让你的10美元鼠标秒变Mac神器?Mac Mouse Fix终极指南 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 还在为Mac上的第三方鼠标发…...

高考数学97分,我的“数学直觉“比140分更好用:链表指针操作的代数思维:从离散数学看单链表
目录 一,序言 二,数学思维 三,核心概念 1. 节点(Node) 2. 头指针(Head Pointer) 3. 链式存储 4. 链表类型 5. 核心操作 6. 内存管理 7. 与顺序表的对比 数学思维: 8. 应用场景 四…...

揭秘OZON热销榜:这些国货好口碑品牌,凭什么让老外也抢购?
近年来,俄罗斯电商平台OZON已成为中国卖家出海的新蓝海。一个有趣的现象是,许多在国内司空见惯的国货品牌,竟在OZON上掀起抢购热潮,成为俄罗斯消费者眼中的“香饽饽”。它们究竟凭什么征服了万里之外的消费者?今天&…...

突破网盘限速壁垒:ctfileGet实现技术民主化的创新实践
突破网盘限速壁垒:ctfileGet实现技术民主化的创新实践 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 在数字资源高速流通的今天,网盘服务已成为信息传递的重要基础设施。然而&a…...

抖音直播数据采集技术:WebSocket逆向与实时弹幕抓取解决方案
抖音直播数据采集技术:WebSocket逆向与实时弹幕抓取解决方案 【免费下载链接】DouyinLiveWebFetcher 抖音直播间网页版的弹幕数据抓取(2025最新版本) 项目地址: https://gitcode.com/gh_mirrors/do/DouyinLiveWebFetcher 在直播电商和…...