哈希表的实现
哈希表概念
二叉搜索树具有对数时间的表现,但这样的表现建立在一个假设上:输入的数据有足够的随机性。哈希表又名散列表,在插入、删除、搜索等操作上具有「常数平均时间」的表现,而且这种表现是以统计为基础,不需依赖输入元素的随机性。
听起来似乎不可能,倒也不是,例如:
假设所有元素都是 8-bits 的正整数,范围 0~255,那么简单得使用一个数组就可以满足上述要求。首先配置一个数组 Q,拥有 256 个元素,索引号码 0~255,初始值全部为 0。每一个元素值代表相应的元素的出现次数。如果插入元素 i,就执行 Q[i]++,如果删除元素 i,就执行 Q[i]--,如果查找元素 i,就看 Q[i] 是否为 0。
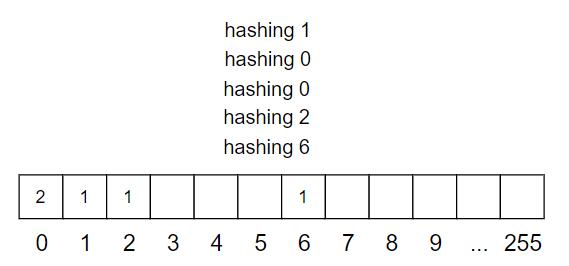
这个方法有两个很严重的问题。
- 如果元素是 32-bits,数组的大小就是 232=4GB2^{32} = 4 GB232=4GB,这就太大了,更不用说 64-bits 的数了
- 如果元素类型是字符串而非整数,就需要某种方法,使其可用作数组的索引
散列函数
如何避免使用一个太大的数组,以及如何将字符串转化为数组的索引呢?一种常见的方法就是使用某种映射函数,将某一元素映射为一个「大小可接受的索引」,这样的函数称为散列函数。
散列函数应有以下特性:
- 函数的定义域必须包含需要存储的全部关键字,当散列表有 m 个地址时,其值域在 0 到 m - 1 之间
- 函数计算出来的地址能均匀分布在整个空间
直接定址法
取关键字的某个线性函数为散列地址:Hash(Key)=A∗Key+BHash(Key) = A * Key + BHash(Key)=A∗Key+B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:数据范围比较集中的情况
除留余数法
设散列表的索引个数为 m,取一个不大于 m,但最接近 m 的质数 p 最为除数,按照散列函数:Hash(Key)=keyHash(Key) = key % pHash(Key)=key,将关键字转化为哈希地址
平方取中法
假设关键字为 1230,它的平方是 1512900,取中间的 3 位 129 作为哈希地址;
再比如关键字为 321,它的平方是 103041,取中间的 3 位 304(或 30)作为哈希地址。
哈希冲突
使用散列函数会带来一个问题:可能有不同的元素被映射到相同的位置。这无法避免,因为元素个数大于数组的容量,这便是「哈希冲突」。解决冲突问题的方法有很有,包括线性探测、二次探测、开散列等。
线性探测
当散列函数计算出某个元素的插入位置,而该位置上已有其他元素了。最简单的方法就是向下一一寻找(到达尾端,就从头开始找),直到找到一个可用位置。
进行元素搜索时同理,如果散列函数计算出来的位置上的元素值与目标不符,就向下一一寻找,直到找到目标值或遇到空。
至于元素的删除,必须采用伪删除,即只标记删除记号,实际删除操作在哈希表重新整理时再进行。这是因为哈希表中的每一个元素不仅表示它自己,也影响到其他元素的位置。
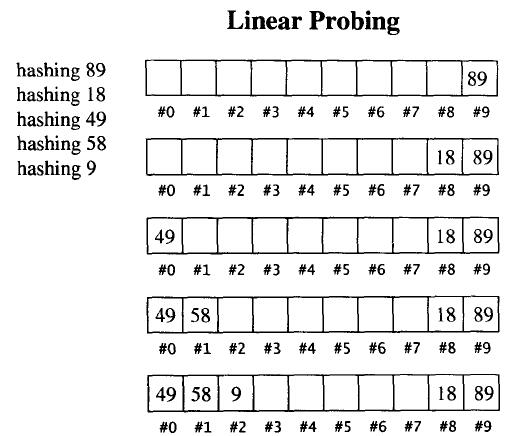
从上述插入过程我们可以看出,当哈希表中元素变多时,发生冲突的概率也变大了。由此,我们引出哈希表一个重要概念:负载因子。
负载因子定义为:Q = 表中元素个数 / 哈希表的长度
- 负载因子越大,剩余可用空间越少,发生冲突可能越大
- 负载因子越小,剩余可用空间越多,发生冲突可能越小,同时空间浪费更多
因此,控制负载因子是个非常重要的事。对于开放定址法(发生了冲突,就找下一个可用位置),负载因子应控制在 0.7~0.8 以下。超过 0.8,查找时的 CPU 缓存不命中按照指数曲线上升。
二次探测
线性探测的缺陷是产生冲突的数据会堆在一起,这与其找下一个空位置的方式有关,它找空位置的方式是挨着往后逐个去找。二次探测主要用来解决数据堆积的问题,其命名由来是因为解决碰撞问题的方程式 F(i)=i2F(i) = i^2F(i)=i2 是个二次方程式。
更具体地说,如果散列函数计算出新元素的位置为 H,而该位置实际已被使用,那么将尝试 H+12,H+22,H+32,...,H+i2H + 1^2, H + 2^2, H + 3^2, ... , H + i^2H+12,H+22,H+32,...,H+i2,而不是像线性探测那样依次尝试 H+1,H+2,H+3,...,H+iH + 1, H + 2, H + 3, ... , H + iH+1,H+2,H+3,...,H+i。
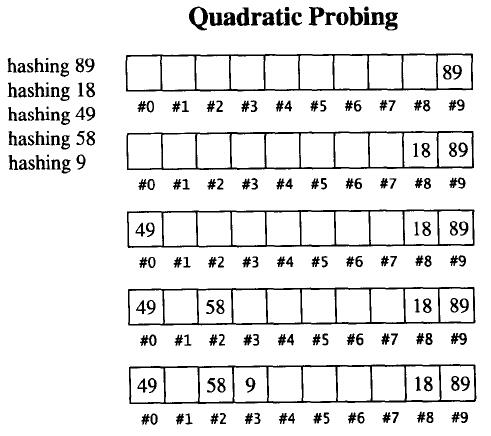
大量实验表明:当表格大小为质数,而且保持负载因子在 0.5 以下(超过 0.5 就重新配置),那么就可以确定每插入一个新元素所需要的探测次数不超过 2。
链地址法
这种方法是在每一个表格元素中维护一个链表,在呢个链表上执行元素的插入、查询、删除等操作。这时表格内的每个单元不再只有一个节点,而可能有多个节点。
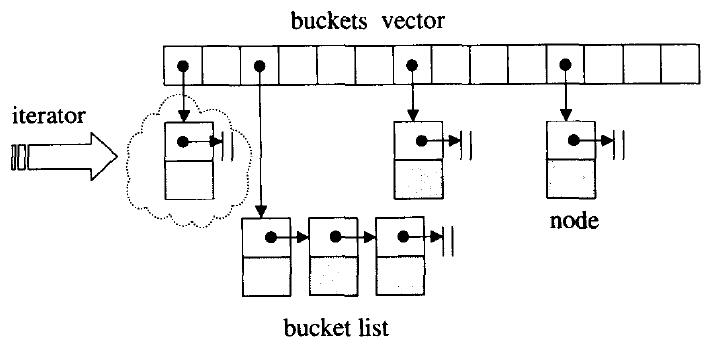
节点的定义:
template <class Value>
struct __hashtable_node {__hashtable_node* next;Value val;
};
哈希表的实现
闭散列
接口总览
template <class K, class V>
class HashTable {struct Elem {pair<K, V> _kv;State _state = EMPTY;};
public:Elem* Find(const K& key);bool Insert(const pair<K, V>& kv);bool Erase(const K& key);
private:vector<Elem> _table;size_t _n = 0;
};
节点的结构
因为在闭散列的哈希表中的每一个元素不仅表示它自己,也影响到其他元素的位置。所以要使用伪删除,我们使用一个变量来表示。
/// @brief 标记每个位置状态
enum State {EMPTY, // 空EXIST, // 有数据DELETE // 有数据,但已被删除
};
哈希表的节点结构,不仅存储数据,还存储状态。
/// @brief 哈希表的节点
struct Elem {pair<K, V> _kv; // 存储数据State _state; // 存储状态
};
查找
查找的思路比较简单:
- 利用散列函数获取映射后的索引
- 遍历数组看是否存在,直到遇到空表示查找失败
/// @brief 查找指定 key
/// @param key 待查找节点的 key 值
/// @return 找到返回节点的指针,没找到返回空指针
Elem* Find(const K& key) {if (_table.empty()) {return nullptr;}// 使用除留余数法的简化版本,并没有寻找质数// 同时,该版本只能用于正整数,对于字符串等需使用其他散列函数size_t start = key % _table.size(); size_t index = start;size_t i = 1;// 直到找到空位置停止while (_table[index]._state != EMPTY) {if (_table[index]._state == EXIST && _table[index]._kv.first == key) {return &_table[index];}index = start + i;index %= _table.size();++i;// 判断是否重复查找if (index == start) {return nullptr;}}return nullptr;
}
在上面代码的查找过程中,加了句用于判断是否重复查找的代码。理论上上述代码不会出现所有的位置都有数据,查找不存在的数据陷入死循环的情况,因为哈希表会扩容,闭散列下负载因子不会到 1。
但假如,我们插入了 5 个数据,又删除了它们,之后又插入了 5 个数据,将 10 个初始位置都变为非 EMPTY。此时我们查找的值不存在的话,是会陷入死循环的。
插入
插入的过程稍微复杂一些:
- 首先检查待插入的 key 值是否存在
- 其次需要检查是否需要扩容
- 使用线性探测方式将节点插入
/// @brief 插入节点
/// @param kv 待插入的节点
/// @return 插入成功返回 true,失败返回 false
bool Insert(const pair<K, V>& kv) {// 检查是否已经存在Elem* res = Find(kv.first);if (res != nullptr) {return false;}// 看是否需要扩容if (_table.empty()) {_table.resize(10);} else if (_n > 0.7 * _table.size()) { // 变化一下负载因子计算,可以避免使用除法HashTable backUp;backUp._table.resize(2 * _table.size());for (auto& [k, s] : _table) {// C++ 17 的结构化绑定// k 绑定 _kv,s 绑定 _stateif (s == EXIST) {backUp.Insert(k);}}// 交换这两个哈希表,现代写法_table.swap(backUp._table);}// 将数据插入size_t start = kv.first % _table.size();size_t index = start;size_t i = 1;// 找一个可以插入的位置while (_table[index]._state == EXIST) {index = start + i;index %= _table.size();++i;}_table[index]._kv = kv;_table[index]._state = EXIST;++_n;return true;
}
删除
删除的过程非常简单:
- 查找指定 key
- 找到了就将其状态设为 DELETE,并减少表中元素个数
/// @brief 删除指定 key 值
/// @param key 待删除节点的 key
/// @return 删除成功返回 true,失败返回 false
bool Erase(const K& key) {Elem* res = Find(key);if (res != nullptr) {res->_state = DELETE;--_n;return true;}return false;
}
开散列
接口总览
template <class K, class V>
class HashTable {struct Elem {Elem(const pair<K, V>& kv) : _kv(kv), _next(nullptr){}pair<K, V> _kv;Elem* _next;};
public:Elem* Find(const K& key);bool Insert(const pair<K, V>& kv);bool Erase(const K& key);
private:vector<Elem*> _table;size_t _n = 0;
};
节点的结构
使用链地址法解决哈希冲突就不再需要伪删除了,但需要一个指针,指向相同索引的下一个节点。
/// @brief 哈希表的节点
struct Elem {Elem(const pair<K, V>& kv) : _kv(kv), _next(nullptr){}pair<K, V> _kv; // 存储数据Elem* _next; // 存在下一节点地址
};
查找
查找的实现比较简单:
- 利用散列函数获取映射后的索引
- 遍历该索引位置的链表
/// @brief 查找指定 key
/// @param key 待查找节点的 key 值
/// @return 找到返回节点的指针,没找到返回空指针
Elem* Find(const K& key) {if (_table.empty()) {return nullptr;}size_t index = key % _table.size();Elem* cur = _table[index];// 遍历该位置链表while (cur != nullptr) {if (cur->_kv.first == key) {return cur;}cur = cur->_next;}return nullptr;
}
插入
开散列下的插入比闭散列简单:
- 首先检查待插入的 key 值是否存在
- 其次需要检查是否需要扩容
- 将新节点以头插方式插入
/// @brief 插入节点
/// @param kv 待插入的节点
/// @return 插入成功返回 true,失败返回 false
bool Insert(const pair<K, V>& kv) {// 检查是否已经存在Elem* res = Find(kv.first);if (res != nullptr) {return false;}// 检查是否需要扩容if (_table.size() == _n) {vector<Elem*> backUp;size_t newSize = _table.size() == 0 ? 10 : 2 * _table.size();backUp.resize(newSize);// 遍历原哈希表,将所有节点插入新表for (int i = 0; i < _table.size(); ++i) {Elem* cur = _table[i];while (cur != nullptr) {// 取原哈希表的节点放在新表上,不用重新申请节点Elem* tmp = cur->_next;size_t index = cur->_kv.first % backUp.size();cur->_next = backUp[index];backUp[index] = cur;cur = tmp;}_table[i] = nullptr;}_table.swap(backUp);}// 将新节点以头插的方式插入size_t index = kv.first % _table.size();Elem* newElem = new Elem(kv);newElem->_next = _table[index];_table[index] = newElem;++_n;return true;
}
删除
开散列的删除与闭散列有些许不同:
- 获取 key 对应的索引
- 遍历该位置链表,找到就删除
/// @brief 删除指定 key 值
/// @param key 待删除节点的 key
/// @return 删除成功返回 true,失败返回 false
bool Erase(const K& key) {size_t index = key % _table.size();Elem* prev = nullptr;Elem* cur = _table[index];while (cur != nullptr) {if (cur->_kv.first == key) {if (prev == nullptr) {// 是该位置第一个节点_table[index] = cur->_next;} else {prev->_next = cur->_next;}delete cur; // 释放该节点--_n;return true;}prev = cur;cur = cur->_next;}return false;
}
相关文章:
哈希表的实现
哈希表概念 二叉搜索树具有对数时间的表现,但这样的表现建立在一个假设上:输入的数据有足够的随机性。哈希表又名散列表,在插入、删除、搜索等操作上具有「常数平均时间」的表现,而且这种表现是以统计为基础,不需依赖…...

搞懂海明码
海明码搞懂之前先了解奇偶校验。例如:1111 对其进行奇偶校验。 奇检验:11111 奇校验使1的个数保持在奇数 偶校验:01111 偶校验使1的个数保持在偶数 海明码可以拆分为三步: 一、确定校验的位数 公式:2^k > k n …...
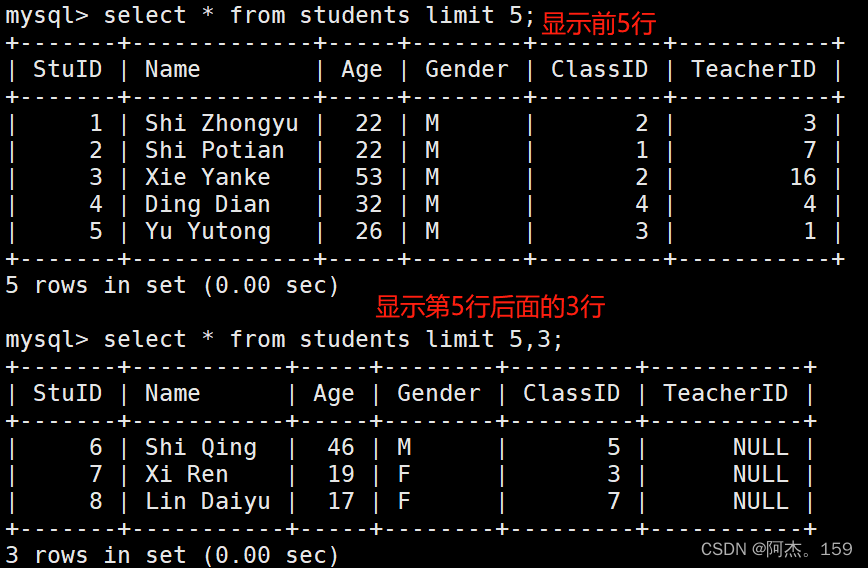
数据库:Mysql数据库安装及使用
目录 一、数据库介绍 1、基本概念 2、数据库类型 3、版本演变 二、Mysql安装 1、官网下载yum安装 2、手动配置yum安装 三、Mysql基本操作 1、登录与改密 2、检测数据库健康 3、 库的创建与使用 4、数据类型 5、修饰符 6、表的创建与使用 7、分组查询 8、查询排…...

【冲刺蓝桥杯的最后30天】day7
大家好😃,我是想要慢慢变得优秀的向阳🌞同学👨💻,断更了整整一年,又开始恢复CSDN更新,从今天开始更新备战蓝桥30天系列,一共30天,如果对你有帮助或者正在备…...

REG.EXE修改注册表-解决win10微软输入法默认中文,将其全局修改为英文
REG.EXE修改注册表-解决win10微软输入法默认中文,将其全局修改为英文 使用REG.EXE 可以直接强制修改注册表字段 修改注册表: REG.EXE ADD 注册表路径 /v 注册表项字段 /t 注册表字段类型 /d 注册表值 /f 例如: REG. EX ADD HKLM\System\C…...

hive之正则函数研究学习regex/regex_replace/regex_extract
首先学习这个之前要先知道一些正则的基本知识。 随便百度一下正则表达式 – 元字符 | 菜鸟教程 字符描述\ 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,n 匹配字符 "n"。\n 匹配一个换行符。序列 \\ 匹…...
 C、D1)
Codeforces Round 854 by cybercats (Div. 1 + Div. 2) C、D1
C. Double Lexicographically Minimum 题意 字符串sss,你可以把它按任意顺序组合,保留的是你组合的字符串和它的倒序之间大的那一个,问你在满足上面条件的前提下字典序最小的字符串。 思路 分析不难发现在没达到一个关键的点的时候肯定是…...

API 网关日志的价值,你了解多少?
本文介绍了 API 网关日志的价值,并以知名网关 Apache APISIX 为例,展示如何集成 API 网关日志。 作者钱勇,API7.ai 技术工程师,Apache APISIX Committer。 原文链接 网关日志的价值 在数字化时代,软件架构随着业务成…...
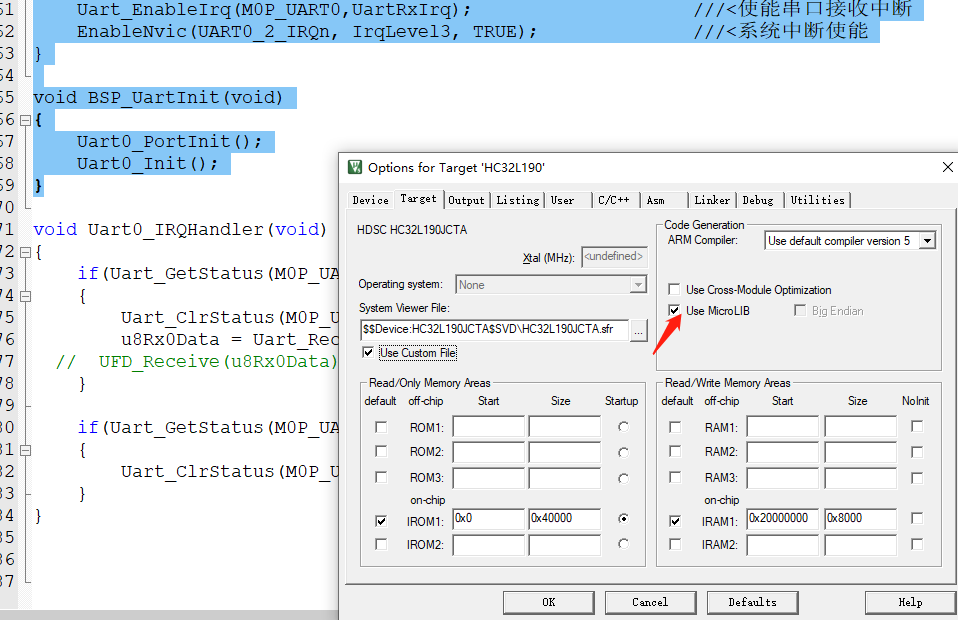
华大单片机、STM32单片机如何做printf串口打印格式化输出
第一种方法:使用标准C库,但使用标准C库你必须关闭半主机模式(1)添加下面代码就是关闭半主机模式/* 告知连接器不从C库链接使用半主机的函数 */ #pragma import(__use_no_semihosting)/* 定义 _sys_exit() 以避免使用半主机模式 */…...
unity 面试汇总
1、什么是协同程序?答:在主线程运行时同时开启另一段逻辑处理,来协助当前程序的执行。换句话说,开启协程就是开启一个可以与程序并行的逻辑。可以用来控制运动、序列以及对象的行为。2、Unity3D中的碰撞器和触发器的区别ÿ…...
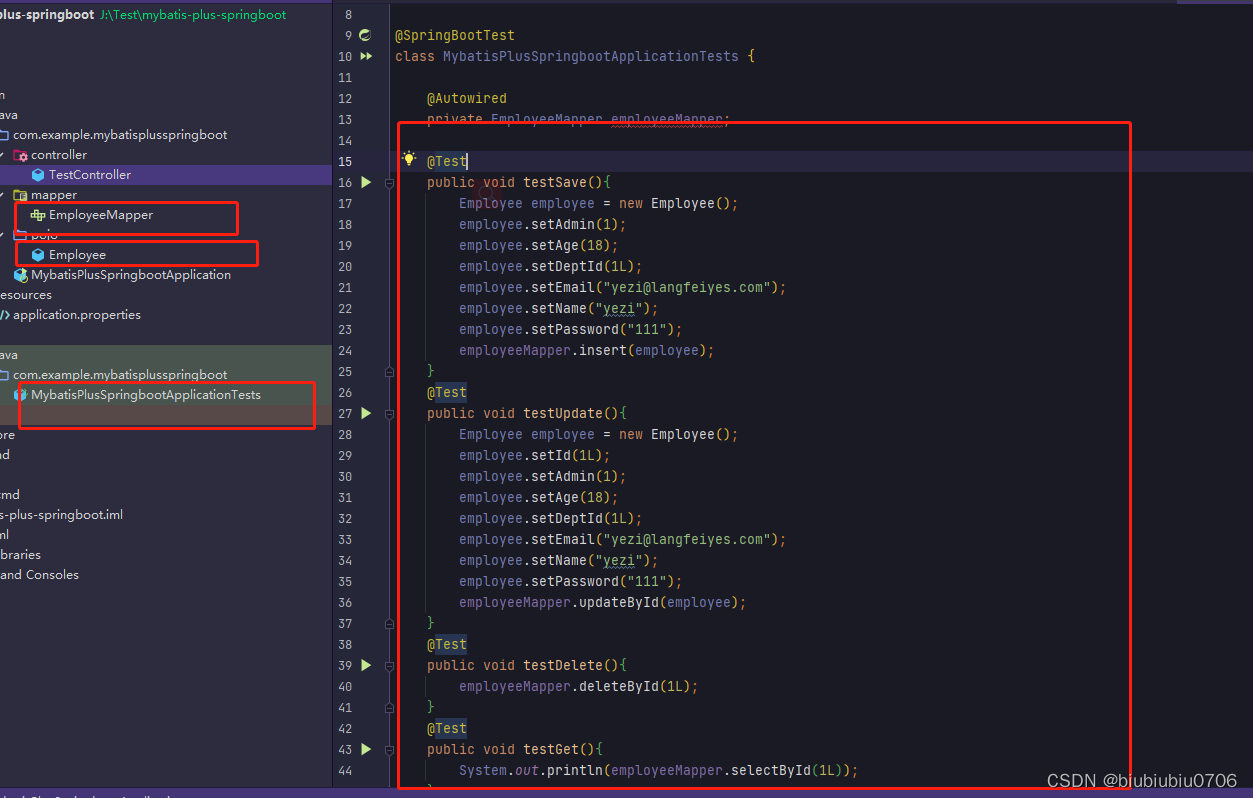
Spring SpringBoot中使用Mybatis-plusDemo1
官网:https://baomidou.com GitHub:GitHub - baomidou/mybatis-plus: An powerful enhanced toolkit of MyBatis for simplify development Gitee:mybatis-plus: mybatis 增强工具包,简化 CRUD 操作。 文档 http://baomidou.com低代码组件库 http://aizuda.com My…...
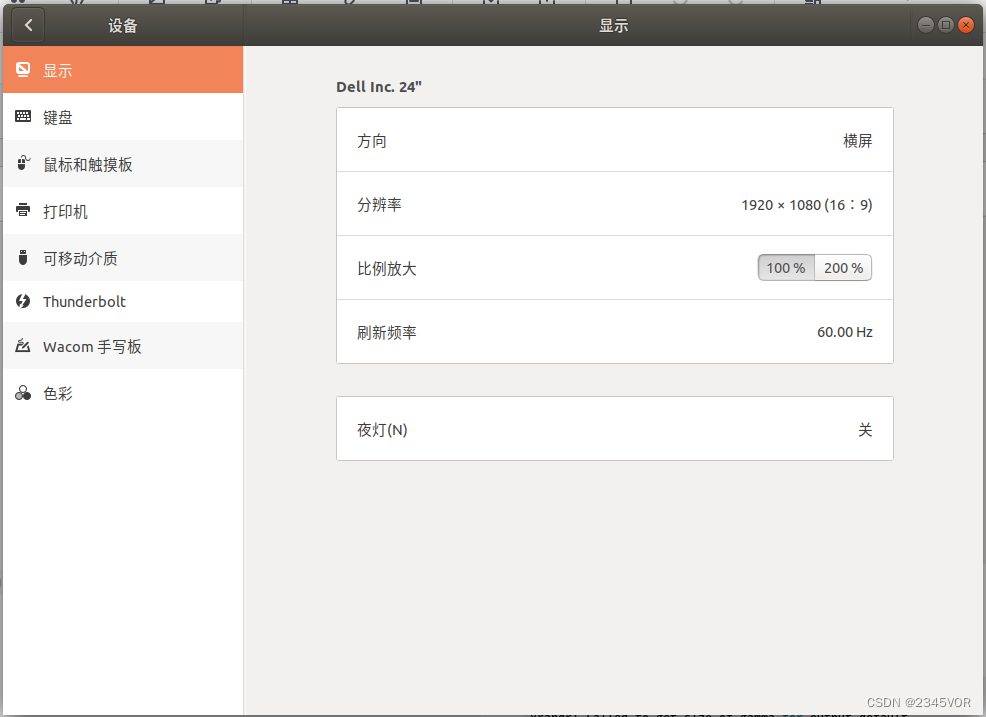
【18.04Ubuntu中解决无法识别显示屏】
【18.04Ubuntu中解决无法识别外接显示屏】1. 问题来源2. 检查Ubuntu是否识别出外接显示器3. 解决没有识别出外接显示器问题4. 显示器扩展屏幕设置1. 问题来源 实验室的一个dell显示器,通过HDMI连接电脑后,在Windows上连接上就直接可以使用了。由于我电脑…...
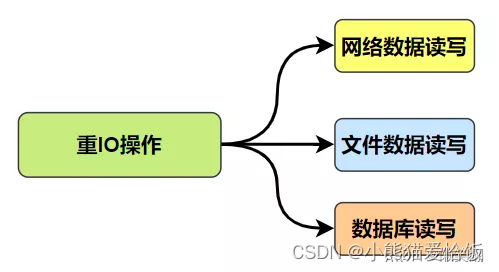
Python 协程详解,都在这里了
什么是协程 协程(co-routine,又称微线程、纤程) 是一种多方协同的工作方式。 协程不是进程或线程, 其执行过程类似于 Python 函数调用, Python 的 asyncio 模块实现的异步IO编程框架中, 协程是对使用 asy…...

百家号如何写文章赚钱,百家号写文章真的赚钱?
随着互联网的快速发展,越来越多的人开始关注到写文章赚钱这个领域。而在众多写作平台中,头条号无疑是最受欢迎的一个。那么,百家号写文章赚钱是真的吗?如何写文章赚钱呢?下面我们就来一一解答。 首先,百家号…...

【HDFS】datanodeReport RPC优化
cat datanodeReport.txt | awk ‘{print $8}’ | sort | uniq | wc -l 结果15,说明我们有15个router。 每15秒一个router8次调用这个rpc。15秒是我们的监控采集间隔。 看下router为什么要调用这个rpc。 顺着这个配置项去寻找:dfs.federation.router.dn-report.time-out 一…...
【数据结构】研究链表带环问题
💯💯💯💯 本篇主要研究的是链表带环问题,快慢指针的应用,分析不同解法对带环链表的处理,梳理完本篇你将对链表的理解更加透彻Ⅰ.研究链表带环问题Ⅱ.扩展带环问题1.为什么慢指针和快指针一定会相…...
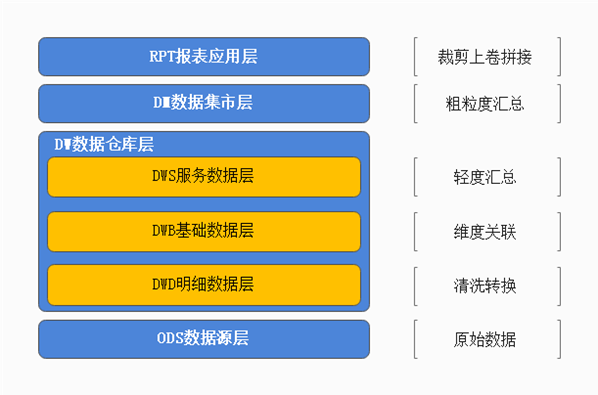
数据仓库的设计思想
数据仓库设计 知识点01:设计大纲与学习目标 #内容大纲1、数据仓库基础知识(回顾)什么是数仓为什么有数仓数仓的特点是什么OLTP和OLAP系统区别(数据库和数仓的区别)2、数仓系统的架构与核心流程核心1:ETL核…...

【JavaSE】数组的定义与使用详解
目录 1.数组的基本概念 1.1数组的好处 1.2什么是数组 1.3数组的定义及初始化 1.3.1数组的创建 1.3.2数组的初始化 1.4数组的使用 1.4.1访问数组中的元素 1.4.2遍历数组 2.数组的类型 2.1认识JVM的内存分布 2.2基本类型变量与引用类型变量 2.3认识null 3.数组的应…...
Kubernetes14:Helm为了部署像微服务这种的大型项目
Kubernetes14:Helm介绍(为了部署像微服务这种的大型项目) 1、Helm的引入 (1)之前方式部署应用基本过程 编写yaml文件 1、deployment kubectl create deployment nginx --imagenginx --dryrun -o yaml > nginx.yaml2、Service kubect…...

2.3操作系统-存储管理:页式存储、逻辑地址、物理地址、物理地址逻辑地址之间的地址关系、页面大小与页内地址长度的关系、缺页中断、内存淘汰规则
2.3操作系统-存储管理:页式存储、逻辑地址、物理地址、物理地址逻辑地址之间的地址关系、页面大小与页内地址长度的关系、缺页中断、内存淘汰规则页式存储逻辑地址、物理地址如何判断物理地址和逻辑地址它们之间的地址关系?页面大小与页内地址长度的关系…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...