使用Python实现深度学习模型:序列到序列模型(Seq2Seq)
序列到序列(Seq2Seq)模型是一种深度学习模型,广泛应用于机器翻译、文本生成和对话系统等自然语言处理任务。它的核心思想是将一个序列(如一句话)映射到另一个序列。本文将详细介绍 Seq2Seq 模型的原理,并使用 Python 和 TensorFlow/Keras 实现一个简单的 Seq2Seq 模型。
1. 什么是序列到序列模型?
Seq2Seq 模型通常由两个主要部分组成:编码器(Encoder)和解码器(Decoder)。编码器将输入序列编码成一个固定长度的上下文向量(context vector),然后解码器根据这个上下文向量生成目标序列。
1.1 编码器(Encoder)
编码器是一个循环神经网络(RNN),如 LSTM 或 GRU,用于处理输入序列,并生成一个上下文向量。这个向量总结了输入序列的全部信息。
1.2 解码器(Decoder)
解码器也是一个 RNN,使用编码器生成的上下文向量作为初始输入,并逐步生成目标序列的每一个元素。
1.3 训练过程
在训练过程中,解码器在每一步生成一个单词,并使用该单词作为下一步的输入。这种方法被称为教师强制(Teacher Forcing)。
2. 使用 Python 和 TensorFlow/Keras 实现 Seq2Seq 模型
我们将使用 TensorFlow/Keras 实现一个简单的 Seq2Seq 模型,进行英法翻译任务。
2.1 安装 TensorFlow
首先,确保安装了 TensorFlow:
pip install tensorflow
2.2 数据准备
我们使用一个简单的英法翻译数据集。每个句子对由英语句子和其对应的法语翻译组成。
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences# 示例数据集
data = [("Hello, how are you?", "Bonjour, comment ça va?"),("I am fine.", "Je vais bien."),("What is your name?", "Quel est ton nom?"),("Nice to meet you.", "Ravi de vous rencontrer."),("Thank you.", "Merci.")
]# 准备输入和目标句子
input_texts = [pair[0] for pair in data]
target_texts = ['\t' + pair[1] + '\n' for pair in data]# 词汇表大小
num_words = 10000# 使用 Keras 的 Tokenizer 对输入和目标文本进行分词和编码
input_tokenizer = Tokenizer(num_words=num_words)
input_tokenizer.fit_on_texts(input_texts)
input_sequences = input_tokenizer.texts_to_sequences(input_texts)
input_sequences = pad_sequences(input_sequences, padding='post')target_tokenizer = Tokenizer(num_words=num_words, filters='')
target_tokenizer.fit_on_texts(target_texts)
target_sequences = target_tokenizer.texts_to_sequences(target_texts)
target_sequences = pad_sequences(target_sequences, padding='post')# 输入和目标序列的最大长度
max_encoder_seq_length = max(len(seq) for seq in input_sequences)
max_decoder_seq_length = max(len(seq) for seq in target_sequences)# 创建输入和目标数据的 one-hot 编码
encoder_input_data = np.zeros((len(input_texts), max_encoder_seq_length, num_words), dtype='float32')
decoder_input_data = np.zeros((len(input_texts), max_decoder_seq_length, num_words), dtype='float32')
decoder_target_data = np.zeros((len(input_texts), max_decoder_seq_length, num_words), dtype='float32')for i, (input_seq, target_seq) in enumerate(zip(input_sequences, target_sequences)):for t, word_index in enumerate(input_seq):encoder_input_data[i, t, word_index] = 1for t, word_index in enumerate(target_seq):decoder_input_data[i, t, word_index] = 1if t > 0:decoder_target_data[i, t-1, word_index] = 1
2.3 构建 Seq2Seq 模型
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Dense# 编码器
encoder_inputs = Input(shape=(None, num_words))
encoder_lstm = LSTM(256, return_state=True)
encoder_outputs, state_h, state_c = encoder_lstm(encoder_inputs)
encoder_states = [state_h, state_c]# 解码器
decoder_inputs = Input(shape=(None, num_words))
decoder_lstm = LSTM(256, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states)
decoder_dense = Dense(num_words, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)# 定义模型
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)# 编译模型
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')# 训练模型
model.fit([encoder_input_data, decoder_input_data], decoder_target_data, batch_size=64, epochs=100, validation_split=0.2)
2.4 推理模型
为了在预测时生成译文,我们需要单独定义编码器和解码器模型。
# 编码器模型
encoder_model = Model(encoder_inputs, encoder_states)# 解码器模型
decoder_state_input_h = Input(shape=(256,))
decoder_state_input_c = Input(shape=(256,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)decoder_model = Model([decoder_inputs] + decoder_states_inputs,[decoder_outputs] + decoder_states
)
2.5 定义翻译函数
我们定义一个函数来使用训练好的模型进行翻译。
def decode_sequence(input_seq):# 编码输入序列得到状态向量states_value = encoder_model.predict(input_seq)# 生成的序列初始化一个开始标记target_seq = np.zeros((1, 1, num_words))target_seq[0, 0, target_tokenizer.word_index['\t']] = 1.# 逐步生成译文序列stop_condition = Falsedecoded_sentence = ''while not stop_condition:output_tokens, h, c = decoder_model.predict([target_seq] + states_value)# 取概率最大的词作为下一个词sampled_token_index = np.argmax(output_tokens[0, -1, :])sampled_word = target_tokenizer.index_word[sampled_token_index]decoded_sentence += sampled_word# 如果达到结束标记或者最大序列长度,则停止if (sampled_word == '\n' or len(decoded_sentence) > max_decoder_seq_length):stop_condition = True# 更新目标序列target_seq = np.zeros((1, 1, num_words))target_seq[0, 0, sampled_token_index] = 1.# 更新状态states_value = [h, c]return decoded_sentence# 测试翻译
for seq_index in range(10):input_seq = encoder_input_data[seq_index: seq_index + 1]decoded_sentence = decode_sequence(input_seq)print('-')print('Input sentence:', input_texts[seq_index])print('Decoded sentence:', decoded_sentence)
3. 总结
在本文中,我们介绍了序列到序列(Seq2Seq)模型的基本原理,并使用 Python 和 TensorFlow/Keras 实现了一个简单的英法翻译模型。希望这篇教程能帮助你理解 Seq2Seq 模型的工作原理和实现方法。随着对 Seq2Seq 模型的理解加深,你可以尝试实现更复杂的模型和任务,例如注意力机制和更大规模的数据集。
相关文章:
)
使用Python实现深度学习模型:序列到序列模型(Seq2Seq)
序列到序列(Seq2Seq)模型是一种深度学习模型,广泛应用于机器翻译、文本生成和对话系统等自然语言处理任务。它的核心思想是将一个序列(如一句话)映射到另一个序列。本文将详细介绍 Seq2Seq 模型的原理,并使…...

力扣283. 移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 示例 1: 输入: nums [0,1,0,3,12] 输出:[1,3,12,0,0] 示例 2: 输入: nums [0] …...
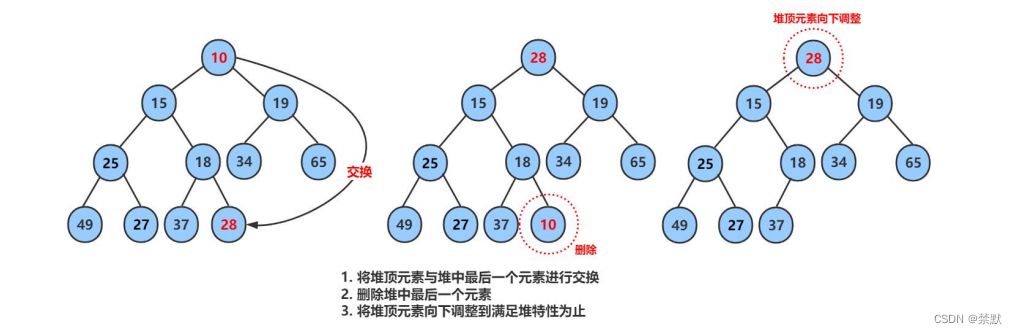
二叉树的顺序结构(堆的实现)
前言 普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结 构存储。 现实中我们通常把堆 ( 一种二叉树 ) 使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统 虚拟进程地址空间中的堆是两回事&…...

2024大模型如何学习【附学习资料】
摘要: 通过深入了解本文中的这些细节,并在实际项目中应用相关知识,将能够更好地理解和利用大模型的潜力,不仅在学术研究中,也在工程实践中。通过不断探索新方法、参与项目和保持热情,并将其应用于各种领域&…...
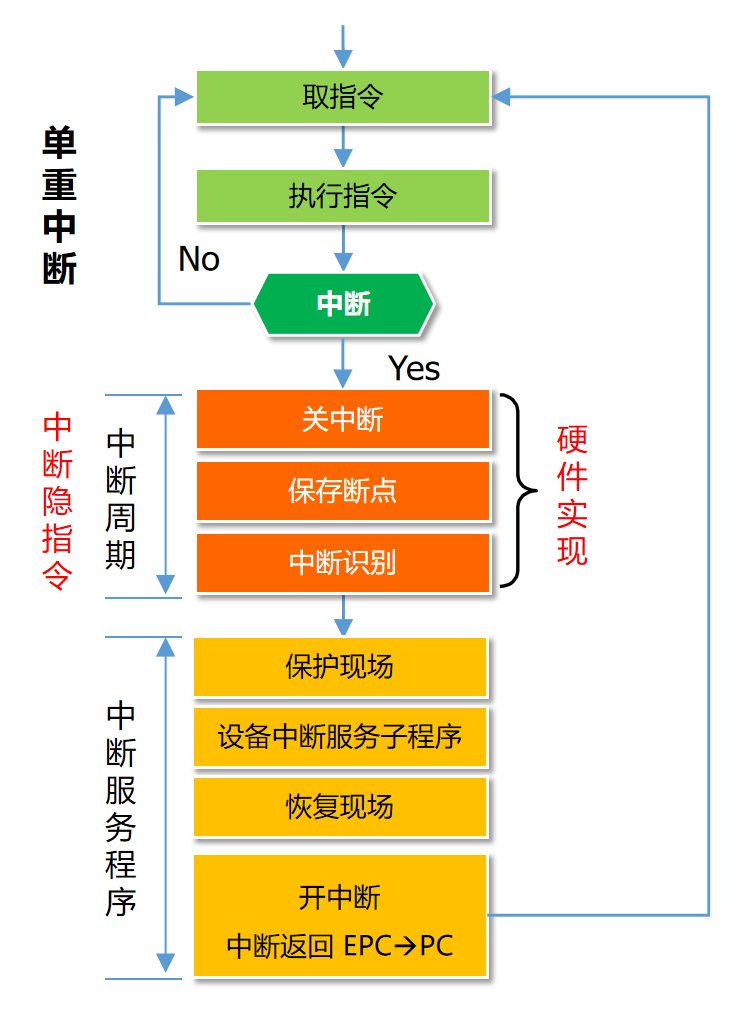
计算机组成原理·考点知识点整理
根据往年考试题,对考点和知识点的一个整理。 校验编码 码距 一种编码的最小码距,其实就是指这种编码的码距。码距有两种定义: 码距所描述的对象含义 2 2 2 个特定的码其二进制表示中不同位的个数一种编码这种编码中任意 2 2 2 个合法编码的…...

python-datetime模块时间戳常用方法汇总
文章目录 datetime模块常用方法1、导入模块2、获取当前日期和时间3、获取当前日期4、创建特定日期或时间5、日期和时间的运算6、使用timedelta运算日期时间创建 timedelta 对象timedelta 的加减运算timedelta 的属性timedelta 的比较示例代码格式化日期和时间获取日期和时间的各…...
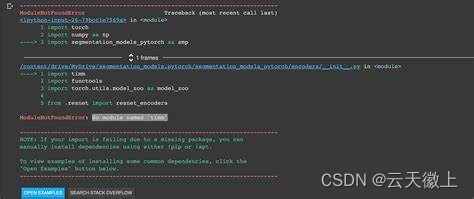
【Python报错】已解决ModuleNotFoundError: No module named ‘timm’
成功解决“ModuleNotFoundError: No module named ‘timm’”错误的全面指南 一、引言 在Python编程中,经常会遇到各种导入模块的错误,其中“ModuleNotFoundError: No module named ‘timm’”就是一个典型的例子。这个错误意味着你的Python环境中没有安…...
⭐⭐⭐)
【设计模式】适配器模式(结构型)⭐⭐⭐
文章目录 1.概念1.1 什么是适配器模式1.2 优点与缺点 2.实现方式2.1 类适配器模式2.2 对象适配器模式 3 Java 哪些地方用到了适配器模式4 Spring 哪些地方用到了适配器模式 1.概念 1.1 什么是适配器模式 简单来说,适配器模式就是作为两个不兼容接口之间的桥梁。 1.…...

云原生周刊:Gateway API v1.1 发布 | 2024.6.3
开源项目推荐 Grafana Tanka Tanka 是 Grafana 开发的一款用于 Kubernetes 的灵活、可重用和简洁的配置工具,是使用 YAML 进行 Kubernetes 配置的一种替代方案。 pv-migrate pv-migrate 是一个 CLI 工具/kubectl 插件,可以轻松地将一个 Kubernetes PersistentVo…...

KotlinConf 2024:深入了解Kotlin Multiplatform (KMP)
KotlinConf 2024:深入了解Kotlin Multiplatform (KMP) 在近期的Google I/O大会上,我们推荐了Kotlin Multiplatform (KMP)用于跨移动、网页、服务器和桌面平台共享业务逻辑,并在Google Workspace中采用了KMP。紧接着,KotlinConf 2…...

探索ChatGPT-4在解决化学知识问题上的研究与应用
1. 概述 近年来,人工智能的发展主要集中在 GPT-4 等大型语言模型上。2023 年 3 月发布的这一先进模型展示了利用广泛知识应对从化学研究到日常问题解决等复杂挑战的能力。也开始进行研究,对化学的各个领域,从化学键到有机化学和物理化学&…...

性能狂飙:SpringBoot应用优化实战手册
在数字时代,速度就是生命,性能就是王道!《极速启航:SpringBoot性能优化的秘籍》带你深入SpringBoot的内核,探索如何打造一个飞速响应、高效稳定的应用。从基础的代码优化到高级的数据库连接池配置,再到前端…...
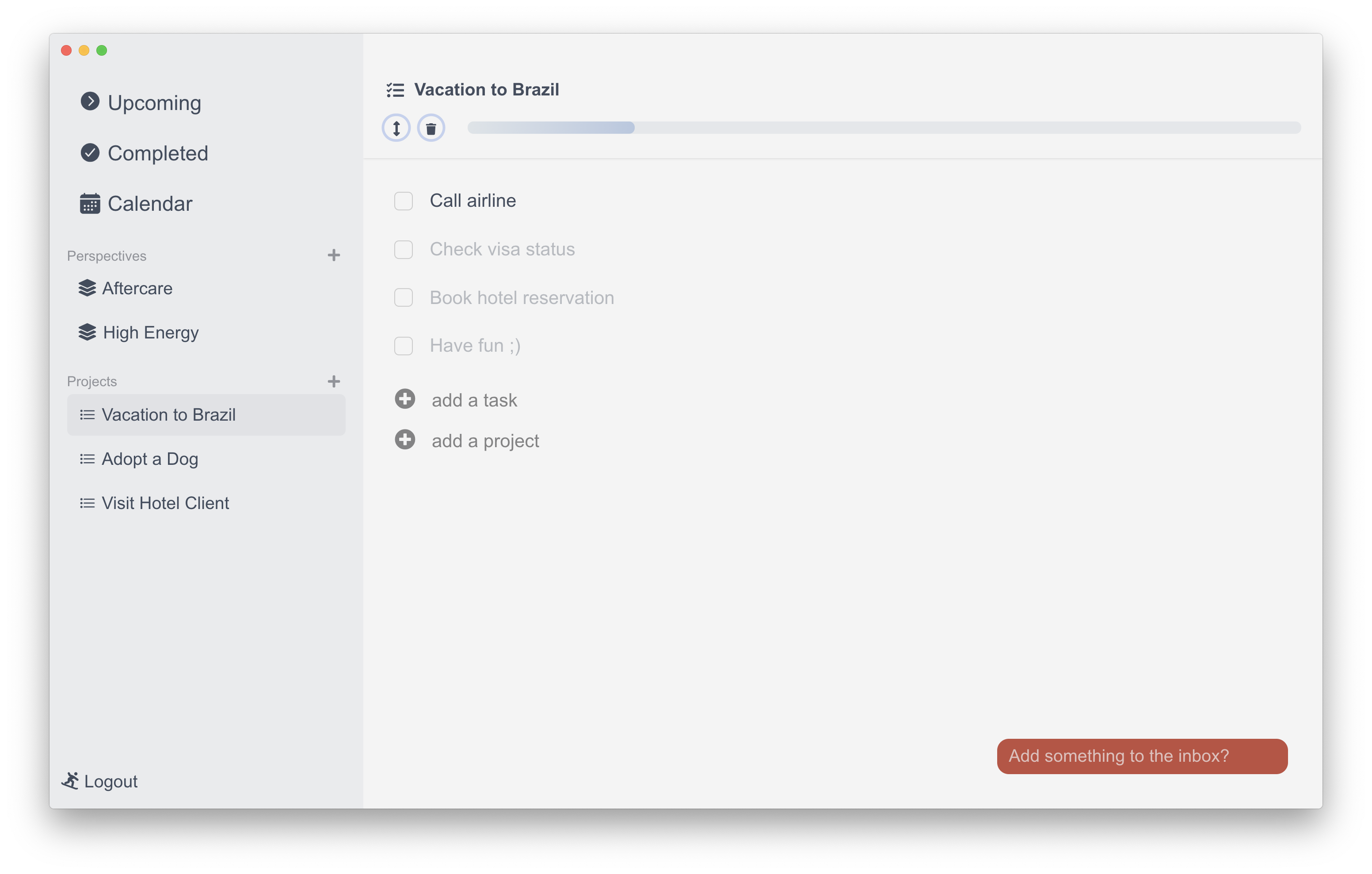
Github上一款开源、简洁、强大的任务管理工具:Condution
Condution 是一款开源任务管理工具,它以简洁易用、功能强大著称。它旨在为用户提供一个简单高效的平台,帮助他们管理日常任务、提高工作效率。 1. Condution 的诞生背景 现如今,市面上存在着许多任务管理软件,但它们往往价格昂贵…...

LeetCode-2938. 区分黑球与白球【贪心 双指针 字符串】
LeetCode-2938. 区分黑球与白球【贪心 双指针 字符串】 题目描述:解题思路一:贪心解题思路二:一次遍历统计1的个数,找0后累加左边的1的个数解题思路三: 题目描述: 桌子上有 n 个球,每个球的颜色…...

深度神经网络——什么是扩散模型?
1. 概述 在人工智能的浩瀚领域中,扩散模型正成为技术创新的先锋,它们彻底改变了我们处理复杂问题的方式,特别是在生成式人工智能方面。这些模型基于高斯过程、方差分析、微分方程和序列生成等坚实的数学理论构建。 业界巨头如Nvidia、Google…...

有代码冗余的检查工具嘛
是的,有一些代码质量工具可以帮助检查冗余代码。这些工具可以分析代码库,并识别出重复、冗余或不必要的代码片段。一些流行的代码质量工具包括: PMD: PMD 是一个开源的静态代码分析工具,支持多种编程语言,包括 Java、…...

3D培训大师:快速输出标准3D课件,打造沉浸式培训体验
随着技术的日新月异和市场的迅猛扩张,企业对员工专业技能培训的需求日益凸显。传统的培训方式往往依赖于实地操作、现场指导,这不仅需要大量的人力、物力和时间成本,而且存在安全风险。特别是化工、机械制造等行业,实操培训的成本…...
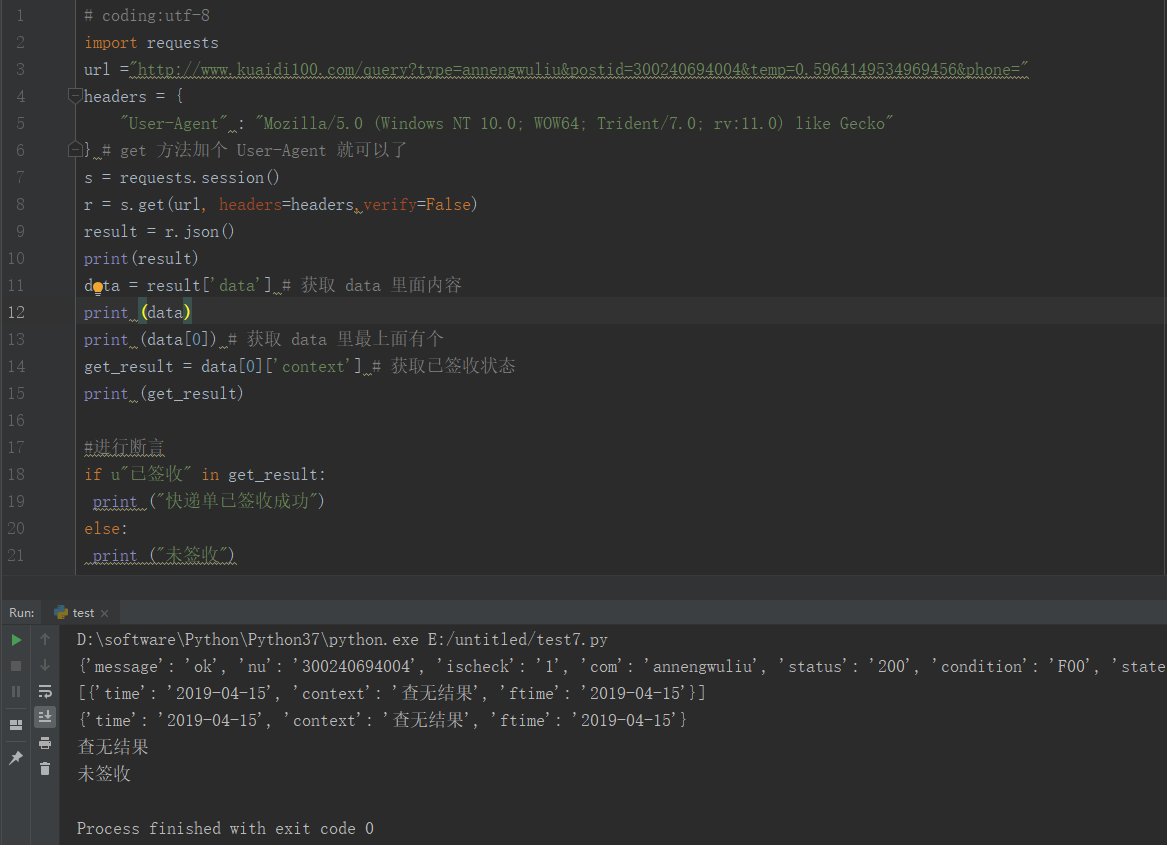
Python接口自动化测试:Json 数据处理实战
🍅 视频学习:文末有免费的配套视频可观看 🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 上一篇说了关于json数据处理,是为了断言方便,这篇就带各位小伙伴实战一下…...
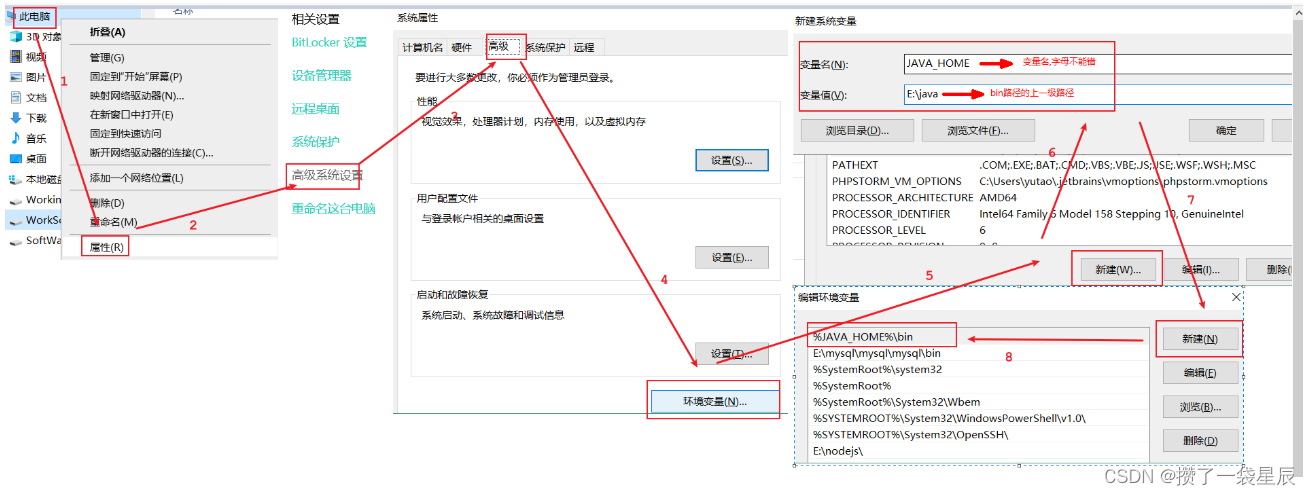
Java概述 , Java环境安装 , 第一个Hello World
环境变量,HelloWorld 1.会常用的dos命令 2.会安装java所需要的环境(jdk) 3.会配置java的环境变量 4.知道java开发三步骤 5.会java的入门程序(HelloWorld) 6.会三种注释方式 7.知道Java入门程序所需要注意的地方 8.知道println和print的区别第一章 Java概述 1.1 JavaSE体系介绍…...
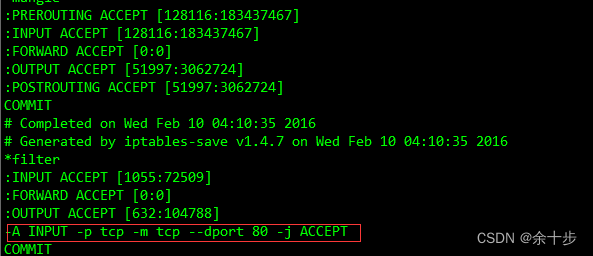
查看Linux端口占用和开启端口命令
查看端口的使用的情况 lsof 命令 比如查看80端口的使用的情况 lsof -i tcp:80列出所有的端口 netstat -ntlp查看端口的状态 /etc/init.d/iptables status开启端口以开启端口80为例。 1 用命令开启端口 iptables -I INPUT -p tcp --dport 80 -j accpet --写入要开放的端口/…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

Vue ③-生命周期 || 脚手架
生命周期 思考:什么时候可以发送初始化渲染请求?(越早越好) 什么时候可以开始操作dom?(至少dom得渲染出来) Vue生命周期: 一个Vue实例从 创建 到 销毁 的整个过程。 生命周期四个…...
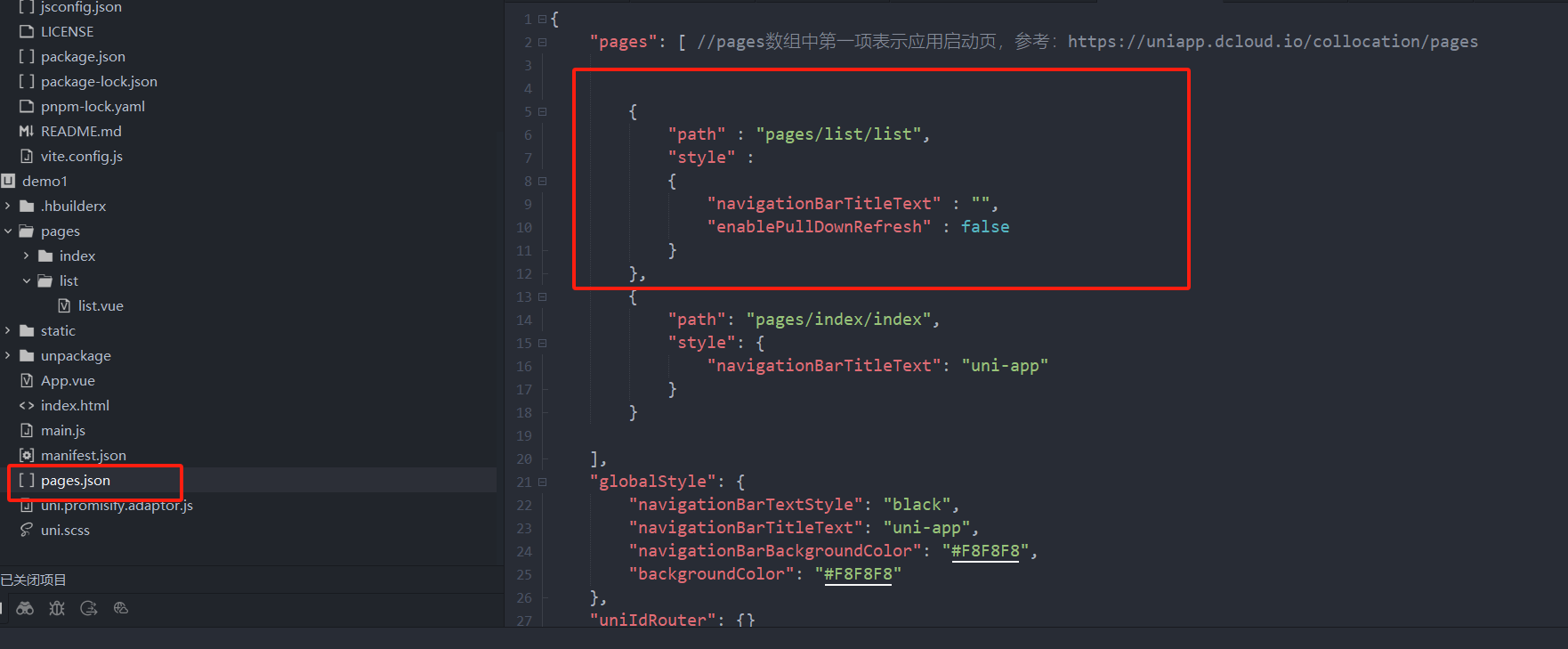
uniapp 小程序 学习(一)
利用Hbuilder 创建项目 运行到内置浏览器看效果 下载微信小程序 安装到Hbuilder 下载地址 :开发者工具默认安装 设置服务端口号 在Hbuilder中设置微信小程序 配置 找到运行设置,将微信开发者工具放入到Hbuilder中, 打开后出现 如下 bug 解…...
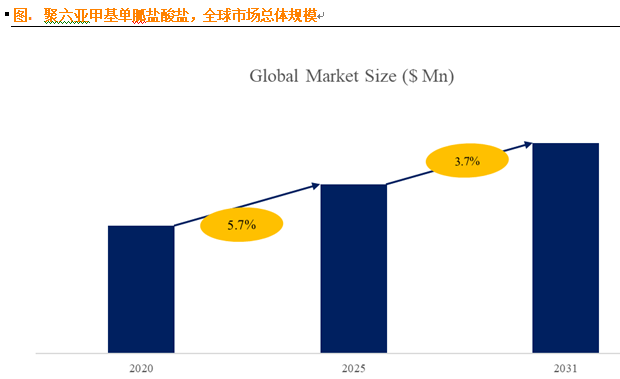
聚六亚甲基单胍盐酸盐市场深度解析:现状、挑战与机遇
根据 QYResearch 发布的市场报告显示,全球市场规模预计在 2031 年达到 9848 万美元,2025 - 2031 年期间年复合增长率(CAGR)为 3.7%。在竞争格局上,市场集中度较高,2024 年全球前十强厂商占据约 74.0% 的市场…...