【大数据】计算引擎:Spark核心概念

目录
前言
1.什么是Spark
2.核心概念
2.1.Spark如何拉高计算性能
2.2.RDD
2.3.Stage
3.运行流程
前言
本文是作者大数据系列中的一文,专栏地址:
https://blog.csdn.net/joker_zjn/category_12631789.html?spm=1001.2014.3001.5482
该系列会成体系的聊一聊整个大数据的技术栈,绝对干货,欢迎订阅。
1.什么是Spark
整个大数据的计算引擎是先有了MapReduce,再有的其它,可以理解为后面出现的其它计算引擎都是对MapReduce的一个补足与升级。
Spark就是对MapReduce的一个补足与升级,其弥补了MapReduce在迭代计算上孱弱的缺陷。其核心就是将数据内存中来,而不是每次都要去读磁盘,进行磁盘IO。
spark是什么:
spark是基于内存的计算引擎,它不是指单个技术,而是指一个技术栈,一个构建于spark core上面的全套的用来处理各种计算的技术栈。
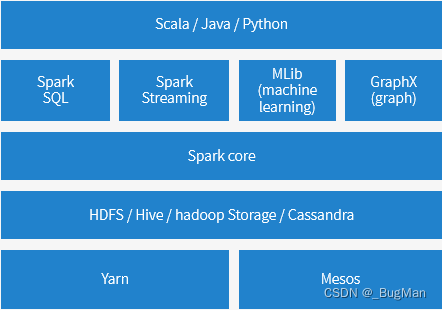
Spark Core提供了什么能力:
Spark既然是补足,就要先说MapReduce在计算这一方面的不足,MapReduce在计算性能上存在的核心问题是迭代计算性能不好,原因是结果需要写入HDFS中。要用到这个结果的后续作业要先去读HDFS,拿到数据,这无疑是十分缓慢的。
我们反过来想,MapReduce为什么要这样干?
MapReduce不是想这么干,而是只能这么干,因为如果不将结果写入HDFS中,全局怎么能找得到这个数据喃?要是写入HDFS,就能通过NameNode找到数据。
要更好的支持迭代计算,无疑将计算结果放在内存中是最好的,读内存毕竟比读磁盘快多了。落磁盘是因为HDFS帮我们管理了分布式的磁盘资源,我们可以找它拿数据,落内存还要找到分布式系统中存储的数据,这就需要另一套内存管理机制来帮我们管理分布式内存了。这套内存管理机制叫RDD,就是Spark Core提供的。
Spark的特点总结:
spark是基于内存的计算引擎,其也是mapreduce模式的,但是相较于mapreducce:
-
spark支持更多种数据集操作,编程模型更灵活。
-
由于是在内存中流转的,不像mapreducce的结果是落在分布式文件系统中的,所以spark的速度更快。
-
天生基于DAG,比MapReduce过程更简洁高效。

在大数据领域一般存在以下几种使用场景:
-
复杂的批量数据处理,用mapreduce,一般业务耗时需求能忍受在数十分钟到数小时
-
基于历史数据的交互式查询,用数据仓库,一般业务耗时需求能忍受在数十秒到数分钟
-
基于实时数据流的数据处理,用spark,一般业务耗时需求能忍受在数百毫秒到数秒
Spark其实是一个全套的基于内存的技术栈,其基于spark core可以完成各种各样数据的计算。Spark提供了一组什么能力?就是接下来我们在下一节要讲的核心概念的内容。
2.核心概念
2.1.Spark如何拉高计算性能
Spark对比MapReuce之所以做迭代计算性能好,是因为两个核心点:
-
有向无环图
-
基于内存
以上就是Spark Core提供的东西,接下来会通过一个例子来逐步带大家一点点的推出Spark Core的这两个核心概念。
首先是计算任务的过程有两种,一种是要分前后阶段,前后阶段之间有依赖关系,一种是不分前后阶段,可以并行执行的。
分前后阶段的:
ALTER TABLE PR_EXPERT_PEOPLE DROP COLUMN description_bak;
这个查询会有两个阶段。首先k会执行子查询(过滤年龄大于18的记录),这个操作产生一个中间结果。然后,它会在中间结果上执行第二个过滤操作(筛选性别为男性的记录)。由于这两个操作是连续的,它们之间存在依赖关系,必须按照顺序执行。
可以并行执行的:
这个查询可以分成两个子任务,去查a的数据。去查b的数据,这两个任务是可以并行执行的,最后合在一起就可以了。
SELECT * FROM a JOIN b ON a.type=b.type
上面的例子主要是带大家感受一下,计算任务的子流程无非就是两种,要么有先后依赖关系,要么可以并行执行。
对于一个计算任务而言,最高效的方式就是将能并行的子流程并行执行,有依赖关系的子流程串行执行,也就是说逻辑关系上子任务之间组成这样的有向无环图,效率上是最佳的:
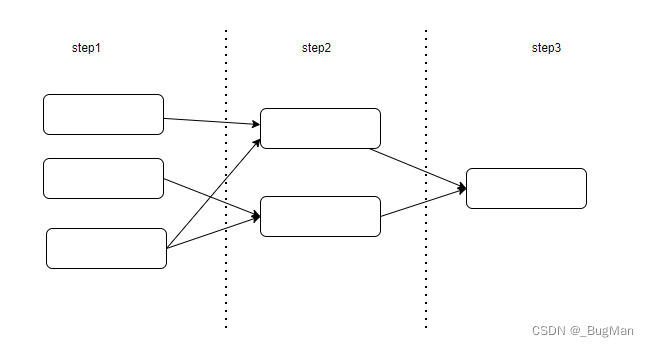
OK,其实把上面聊完,Spark的核心概念就已经出来了:
-
RDD
-
Stage
2.2.RDD
RDD其实就是有向无环图的节点。我们想一想这些节点会是什么?其实就是计算任务,但是光有任务是无法完成工作的,还需要对应数据,所以这个有向无环图上的节点就是任务+数据的一个抽象,理解为一个单独可以完成的子任务即可。
RDD里面存的其实也不是数据:
Spark肯定不能去操作HDFS,走磁盘IO的方式读数据,本来Spark就是要解决这个问题的。所以要把内存利用起来,内存里也不能直接装数据,毕竟数据量那么大,内存肯定也装不下,所以内存中只能装要用到的数据在磁盘中的位置信息,也就是一个映射。总结起来RDD里面存的其实就是计算任务和数据映射。
总结一下RDD是什么:
-
RDD 是理解成集合就行了,它是只读的、可分区的数据集合,其成员分布在集群的不同节点上。
-
每个RDD对应着HDFS中的一个或者多个文件。
-
每个 RDD 被分成多个分区(Partition),每个分区对应一个或多个数据块。
-
RDD 不可修改,可以通过操作其他 RDD 生成,这些操作包括转换(如 map、filter)和动作(如 count、save)。
-
RDD并不直接存储数据,而是由其分块记录着对应的HDFS的数据分区中参与运算的数据信息
-
数据(叫运算结果更准确点)是在RDD的分区中流转的,RDD只是一个抽象概念,具体干活的分区,数据是在不同RDD的不同分区中流转的。
RDD如何生成:
2.3.Stage
观察下面一幅图:

可以看到有些任务之间没有交叉的依赖关系,所以其实是可以并行计算的,比如Stage1和Stage2,这样并行计算无疑也拉高了计算速度。Spark中将一组可以关起门来自己玩儿和其它任务之间没有交叉依赖关系的任务叫做Stage,理解为一个任何集合即可。
stage划分的依据是什么?
首先有两个概念:
窄依赖:每一个父RDD的分区最多被一个子RDD的分区所使用。这意味着数据的转换可以在分区级别上直接进行,而不需要跨分区的数据重组。
宽依赖:一个父RDD的分区可能被多个子RDD的分区所使用,或者一个父RDD的所有分区数据需要被重组以供应给子RDD的某些分区。
从节点出发,窄依赖为一个stage,遇到第一个宽依赖就断开,作为stage的边界。
RDD、RDD分区、Stage三者之间的关系:
RDD是Spark中最基本的数据抽象,代表一个不可变、可分区、且元素可并行计算的集合,直接理解成为分布式内存的抽象即可。RDD的数据是分布存储的,意味着Spark集群中的每个节点上只存储了RDD的部分数据,这些数据被划分为多个分区。
分区是RDD的一个重要概念,它指的是将数据划分为多个逻辑部分,以便于在集群的不同节点上进行并行处理。分区的数量和大小可以影响Spark作业的性能,因此通常需要根据具体情况进行合理配置。每个分区在物理上可能存储在集群的一个或多个节点上,这样Spark就可以利用集群的并行计算能力来处理数据。
Stage是Spark作业执行过程中的一个逻辑阶段,代表了一组具有依赖关系的任务集合。在Spark中,一个作业(Job)通常会被划分为多个阶段(Stage),每个阶段包含一组可以并行执行的任务(Task)。阶段的划分主要基于RDD之间的依赖关系,特别是宽依赖(即一个分区的计算依赖于多个父RDD的分区)。宽依赖会导致新的Stage的产生,因为需要在不同的节点上重新组合数据。
因此,RDD、分区和Stage在Spark中构成了数据处理和执行的关键组件。RDD提供了数据的分布式表示,分区实现了数据的并行处理,而Stage则代表了作业执行的逻辑阶段。这三者相互协作,使得Spark能够高效地处理大规模数据集。
3.运行流程
spark的架构和工作流程其实就是map reduce2.0那一套。map reduce2.0也算是玩明白了,靠谱的分布式计算引擎就应该是:
- 做流程上的优化(DAG),以保证有个最有的依赖路径
- 每个计算任务内部的调度和监控独立(每个作业一个executor或者application master之类的东西) spark其实就是完整的实现了这一套。
所以Spark的整体运行流程如下:
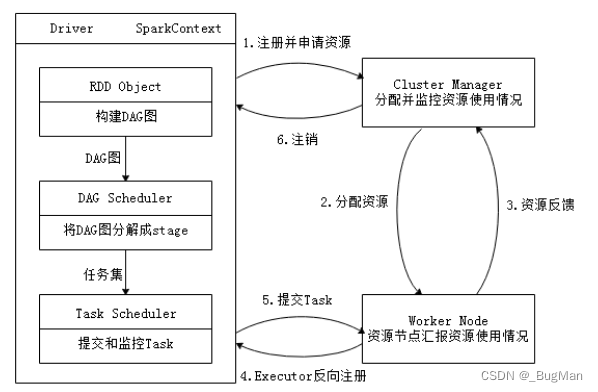
Spark的运行流程可以概括为以下几个主要步骤:
-
启动 Spark Application: 用户编写一个Spark应用程序并提交给Spark集群运行。 Spark集群初始化,启动一个Driver进程。Driver是Spark应用的主控进程,负责管理和协调整个应用的执行。
-
建立运行环境: Driver启动后,会创建一个SparkContext(Spark上下文)实例。SparkContext是Spark与Cluster Manager(集群管理器)进行通信的桥梁,也是整个应用的主要入口点。 SparkContext向Cluster Manager注册应用,并请求资源,比如申请Executor进程来执行具体任务。
-
资源分配与Executor启动: Cluster Manager(如YARN、Mesos或Standalone)接收到资源请求后,根据当前集群状况为应用分配资源,并启动Executor进程。 Executor是Spark应用在工作节点(Worker Node)上运行的进程,负责在分配给它们的资源上执行任务,并将结果返回给Driver。
-
构建DAG与Stage划分: SparkContext根据应用程序中的RDD操作构建DAG(有向无环图),代表了操作之间的依赖关系。 DAG Scheduler分析DAG,将其拆分成多个Stage。通常,Stage的边界发生在shuffle操作处,因为shuffle操作会导致数据重分布。
-
任务调度与执行: Task Scheduler(任务调度器)根据Stage内的任务集(TaskSet)进一步安排任务到各个Executor上执行。 Executor向SparkContext申请Task,Task Scheduler分配任务并发送代码(来自应用的Jar包)到Executor。 Executor在本地线程中执行Task,并处理数据,可能涉及读取、转换、写入数据等操作。
-
结果收集与输出: Executor完成任务后,将结果返回给Task Scheduler,再转交给Driver。 如果是Action操作,如collect,最终结果会被收集到Driver上;如果是Transformation,则结果可能继续留在Executor内存中供进一步处理。
-
资源清理与应用结束: 应用程序执行完毕,SparkContext向Cluster Manager注销,释放所有Executor资源。 Executor进程停止,相关资源回收,集群准备服务于下一个应用。
相关文章:
【大数据】计算引擎:Spark核心概念
目录 前言 1.什么是Spark 2.核心概念 2.1.Spark如何拉高计算性能 2.2.RDD 2.3.Stage 3.运行流程 前言 本文是作者大数据系列中的一文,专栏地址: https://blog.csdn.net/joker_zjn/category_12631789.html?spm1001.2014.3001.5482 该系列会成体…...

Python | C# | MATLAB 库卡机器人微分运动学 | 欧拉-拉格朗日动力学 | 混合动力控制
🎯要点 🎯正向运动学几何矩阵,Python虚拟机器人模拟动画二连杆平面机械臂 | 🎯 逆向运动学几何矩阵,Python虚拟机器人模拟动画三连杆平面机械臂 | 🎯微分运动学数学形态,Python模拟近似结果 | …...
Signac|成年小鼠大脑 单细胞ATAC分析(1)
引言 在本教程中,我们将探讨由10x Genomics公司提供的成年小鼠大脑细胞的单细胞ATAC-seq数据集。本教程中使用的所有相关文件均可在10x Genomics官方网站上获取。 本教程复现了之前在人类外周血单核细胞(PBMC)的Signac入门教程中执行的命令。…...

【POSIX】运行时so库动态加载
运行时可以自己自定义so库的动态加载框架,主动去加载某些库,并调用其中的某些方法 首先写一些方法,并生成so库 // hello.cpp#include <iostream>/*使用 nm 命令查看 so 库的内容 */// 1. 使用extern // dlsym(handle, "hello&qu…...
爱普生SG2520CAA汽车电子中控专用晶振
随着汽车电子技术的飞速发展,汽车中控系统变得越来越智能化和复杂化。为了确保这些系统的高性能和高可靠性,选择符合AEC-Q200标准的高品质晶振至关重要。爱普生SG2520CAA晶振凭借其优异的特性,成为汽车电子中控系统的理想选择。 爱普生晶振SG…...
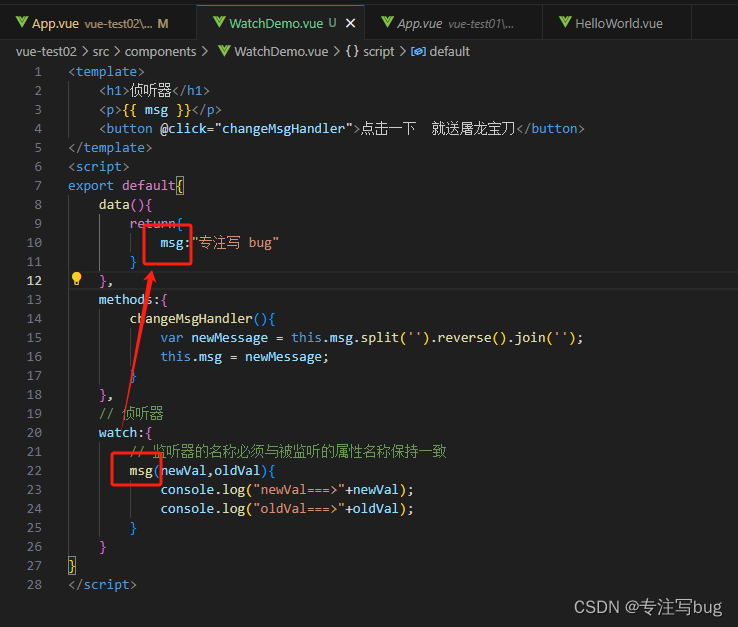
Vue——监听器简单使用与注意事项
文章目录 前言编写简单demo注意事项 前言 监听器,在官网中称为侦听器,个人还是喜欢称之为监听器。官方文档如下: vue 官网 侦听器 编写简单demo 侦听器在项目中通常用于监听某个属性变量值的变化,并根据该变化做出一些处理操作。…...

OpenCV的“画笔”功能
类似于画图软件的自由笔刷功能,当按住鼠标左键,在屏幕上画出连续的线条。 定义函数: import cv2 import numpy as np# 初始化参数 drawing False # 鼠标左键按下时为True ix, iy -1, -1 # 鼠标初始位置# 鼠标回调函数 def mouse_paint(…...
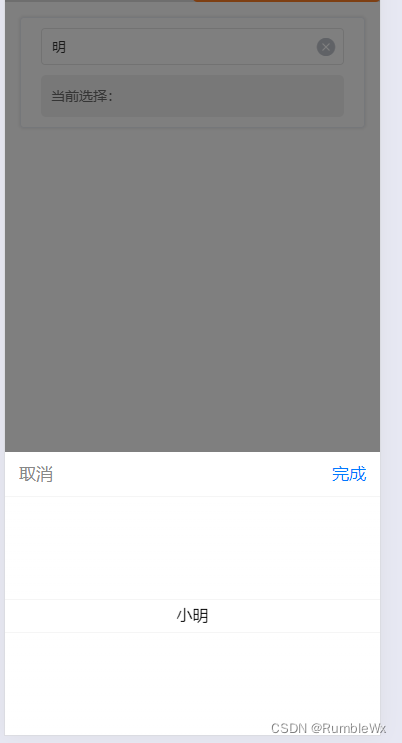
uniapp封装picker选择器组件,支持关键字查询
CommonPicker.vue组件 路径在 components\CommonPicker.vue <template><view><uni-easyinput v-model"searchQuery" :placeholder"placeholder" /><picker :range"filteredOptions" :range-key"text" v-model&…...
智慧城市的规划与实施:科技引领城市运行效率新飞跃
随着信息技术的飞速发展,智慧城市的构想正逐步成为现实。作为地理信息与遥感领域的研究者,我深知在这一转型过程中,技术的创新与应用是提升城市运行效率的关键。本文旨在探讨如何利用地理信息系统(GIS)、遥感技术、大数…...
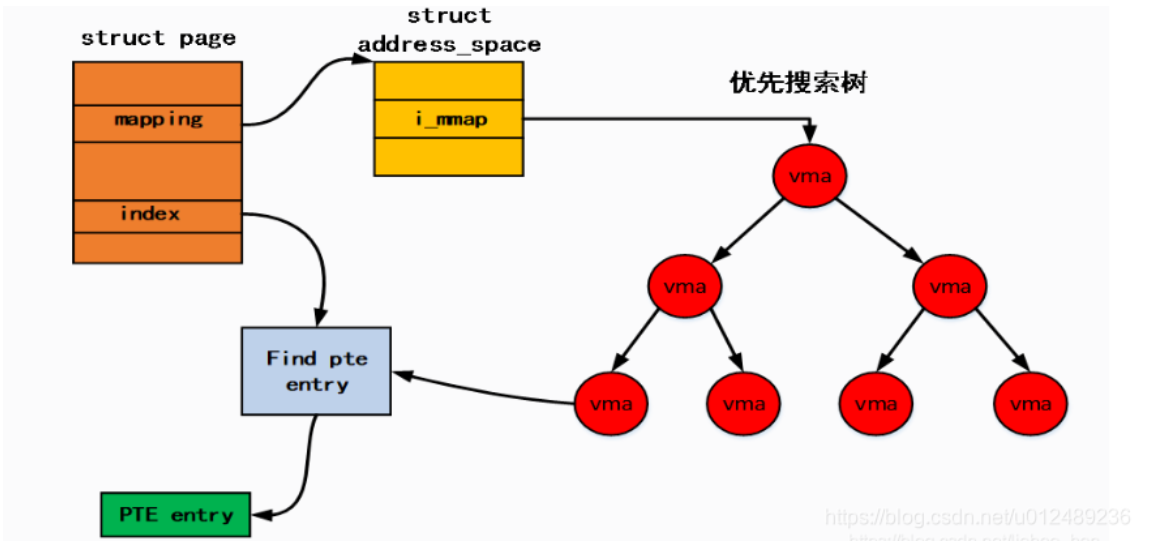
Linux——内存管理代码分析
虚空间管理 页框和页的关系 页框 将内存空间分为一个个大小相等的分区(比如:每个分区4KB),每个分区就是一个页框,也叫页帧,即物理页面,是linux划分内存空间的结果。 每个页框都有一个页框号,即内存块号、物理块号。 页 将用户…...
手机自动化测试:4.通过appium inspector 获取相关app的信息,以某团为例,点击,搜索,获取数据等。
0.使用inspector时,一定要把不相关的如weditor啥的退出去,否则,净是事。 1.从0开始的数据获取 第一个位置,有时0.0.0.0,不可以的话,你就用这个。 第二个位置,抄上。 直接点击第三个启动。不要…...
个人项目———密码锁的实现
布局组件 布局效果 组件绑定 密码锁的实现代码 using TMPro; using UnityEngine; using UnityEngine.UI;public class PasswordPanel : MonoBehaviour {// public Button button;// 所有按键的父物体public Transform buttonPanel;// 输入字符串的文本框public TMP_Text input…...

关于Input【type=number】可以输入e问题及解决方案
一、为什么 因为在数学里e 代表无理数,e是自然对数的底数,同时它又是一个无限不循环小数,所以我们在输入 e 时,输入框会默认 e 是数字,从而没有对它进行限制。 二、解决方案 小提示:vue下监听事件需要加n…...
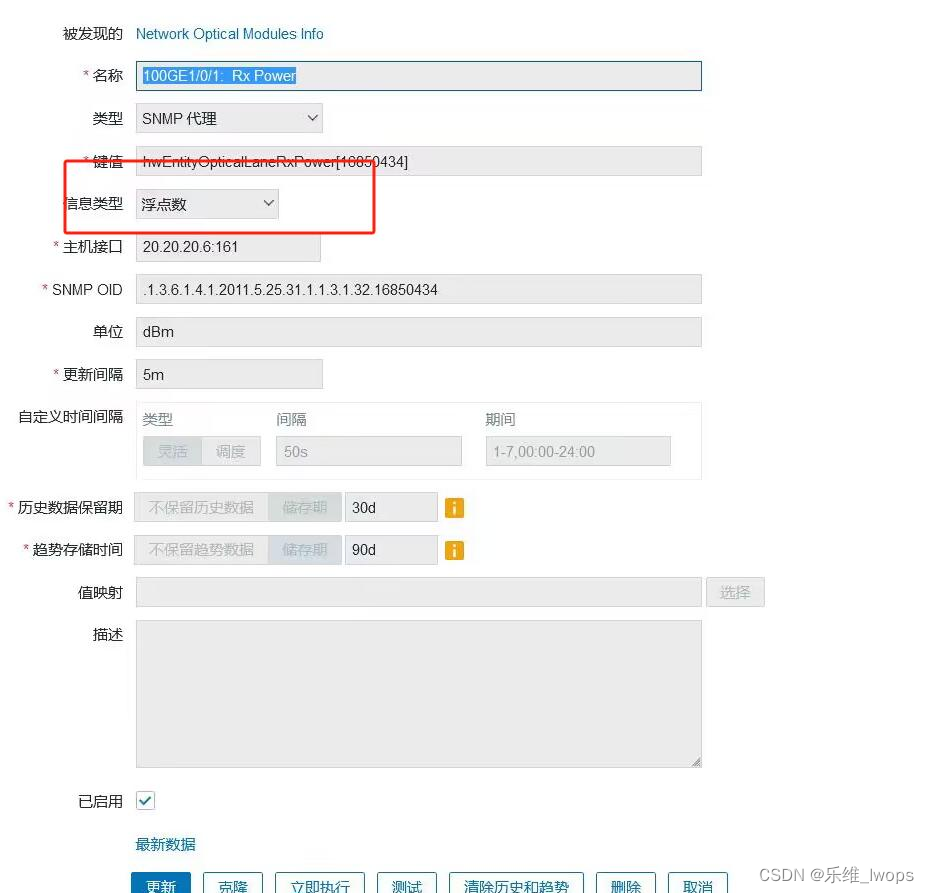
zabbix“专家坐诊”第241期问答
问题一 Q:华为交换机的100GE 1/0/1口的光模块收光值监测不到,有没有人碰到过这个问题呢?其他的端口都能监测到收光值,但是100GE 1/0/1口监测不到收光值。底层能查到,zabbix 6.0监控不到,以下是端口的报错信…...
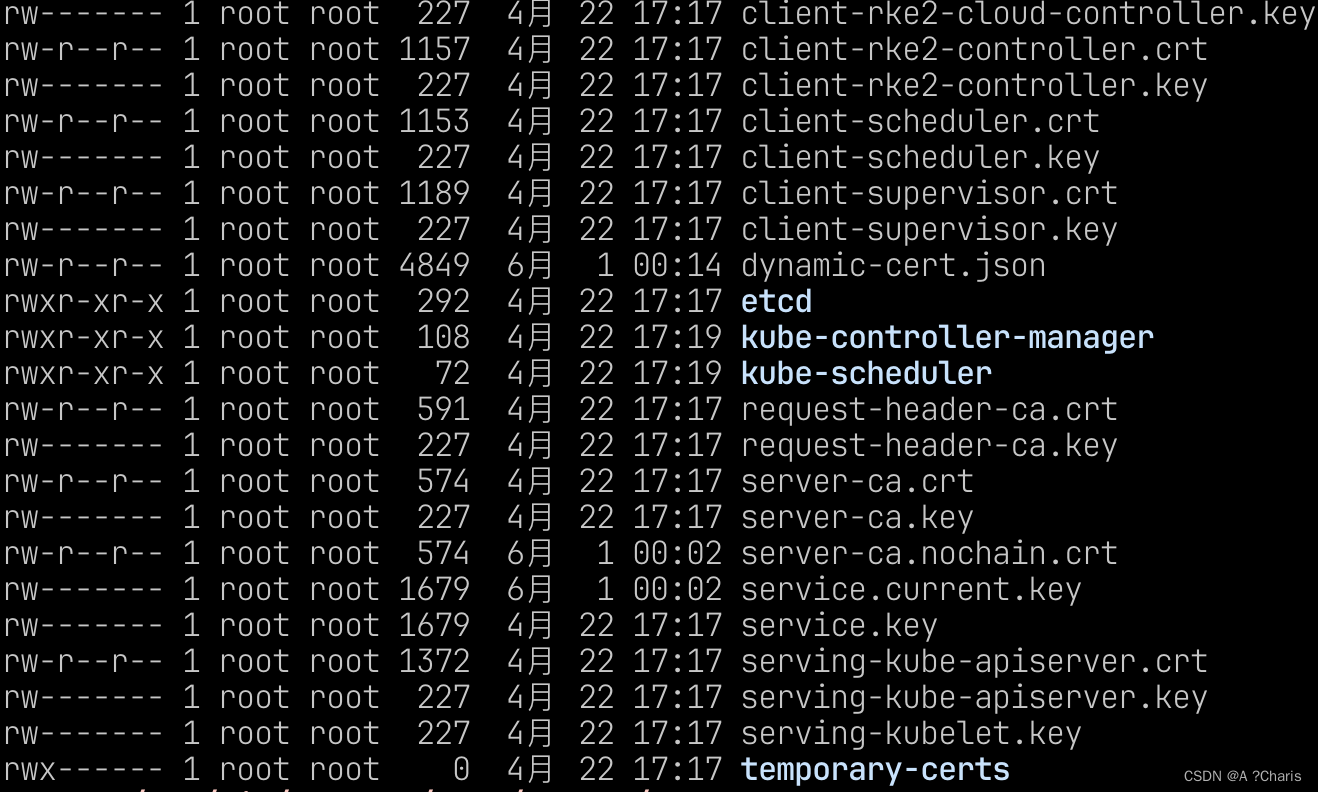
了解Kubernetes-RKE2的PKI以及证书存放位置
一、什么是PKI? 简称:证书基础设施。 可以方便理解为当你的集群有Server,Client架构,那么为了安全加密之间的通信,则需要使用证书进行交互,那么利用PKI架构可以安全加密组件之间的通信。 二、Kubernetes的PKI架构什…...

利用大语言模型进行事实匹配
论文地址:Automated Claim Matching with Large Language Models: Empowering Fact-Checkers in the Fight Against Misinformation | Companion Proceedings of the ACM on Web Conference 2024 WWW 2024 Automated Claim Matching with Large Language Models: Empowering F…...

【Stable Diffusion】(基础篇一)—— Stable Diffusion的安装
本系列笔记主要参考B站nenly同学的视频教程,传送门:B站第一套系统的AI绘画课!零基础学会Stable Diffusion,这绝对是你看过的最容易上手的AI绘画教程 | SD WebUI 保姆级攻略_哔哩哔哩_bilibili **Stable Diffusion(简称…...

维纳运动的概念
维纳运动(Wiener Process),也称为标准布朗运动,是一种重要的随机过程,广泛应用于数学、物理学和金融学等领域。它是一个连续时间的随机过程,具有一些特殊的性质,使其成为描述随机动态系统的经典…...
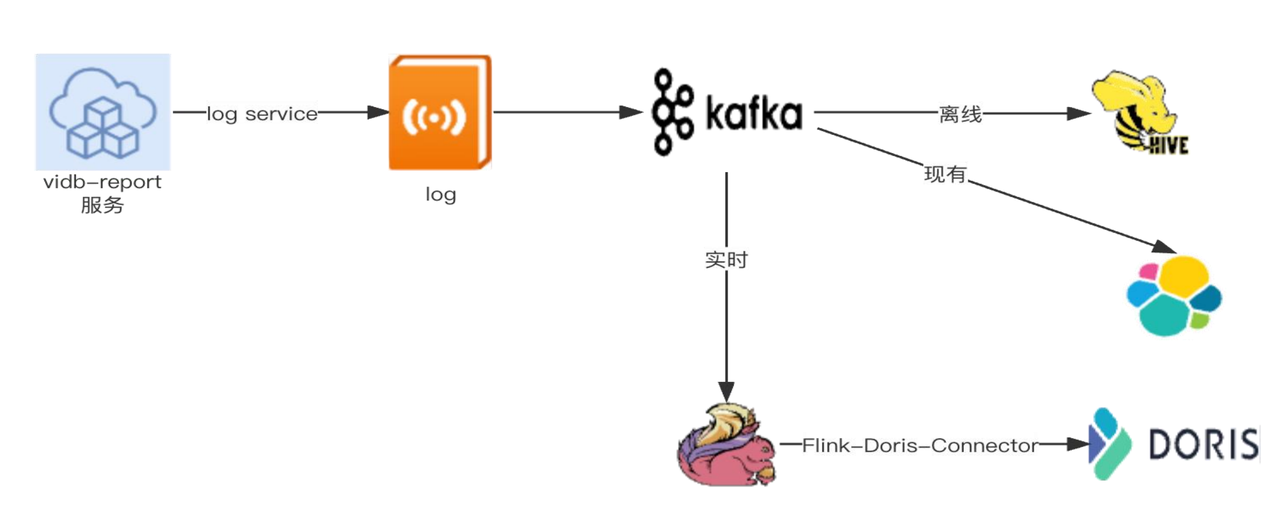
毫秒级查询性能优化实践!Apache Doris 在极越汽车数字化运营和营销方向的解决方案
作者:韩同阳,极越汽车大数据架构师,Apache Doris Active Contributor 编辑整理:SelectDB 技术团队 导读:极越是高端智能汽车机器人品牌,基于领先的百度 AI 能力和吉利 SEA 浩瀚架构生态赋能,致…...

vllm 大模型量化微调推理使用: lora、gptq、awq
1)微调lora模型推理 docker run --gpus all -v /ai/Qwen1.5-7B-Chat:/qwen-7b -v /ai/lora:/lora -p 10860:10860 --...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...