推荐系统三十六式学习笔记:原理篇.近邻推荐07|人以群分,你是什么人就看到什么世界
目录
- 协同过滤
- 基于用户的协同过滤
- 背后的思想
- 原理
- 实践
- 1、构造矩阵
- 2、相似度计算
- 3、推荐计算
- 4、一些改进
- 应用场景:
- 总结
谈及推荐系统,不得不说大名鼎鼎的协同过滤。协同过滤的重点在于协同,所谓协同,也就是群体互帮互助,互相支持是群体智慧的体现,协同过滤也是这般简单直接,历久弥新。
协同过滤
当你的推荐系统过了只能使用基于内容的推荐阶段后,就有了可观的用户行为了。这时候的用户行为通常是正向的,也就是用户或明或暗地表达着喜欢的行为。这些行为可以表达成一个用户和物品的关系矩阵,或是网络,或是图,本质是一个东西。
这个用户物品关系矩阵中填充的就是用户对物品的态度,但并不是每个位置都有,需要的就是把那些还没有的地方填充起来。这个关系矩阵是协同过滤的关键,一切都围绕它来进行;
协同过滤是一个比较大的算法范畴。通常划分为两类;
1、基于记忆的协同过滤(Memory-Based)
2、基于模型的协同过滤(Model-Based)
基于记忆的协同过滤,就是记住每个人消费过什么东西,然后推荐相似的东西,或者推荐相似的人消费的东西。基于模型的协同过滤则是从用户物品关系矩阵中去学习一个模型,从而把那些矩阵空白处填满;
今天先讲一下基于基于的协同过滤的一种:基于用户,或者叫做User-Based;
基于用户的协同过滤
背后的思想
你有没有过这种感觉,你遇到一个人,你发现你喜欢的书,他也喜欢,你喜欢的音乐,他也在听,你喜欢看的电影,他也至少看了两三遍,你们这叫什么,志同道合。所以问题来了,他又看了一本书,又听了一首歌,你会不会正好也喜欢呢?
这个感觉非常的自然,这就是基于用户的协同过滤背后的思想。详细来说就是:先根据历史消费行为帮你找到一群和你口味相似的用户,然后根据这些和你很相似的用户消费了什么新的、你没见过的物品、都可以推荐给你。
这就是我们常说的物以类聚人以群分,你是什么人,你就会遇到什么人。
这其实也是一个用户聚类的过程,把用户按照兴趣口味聚类成不同的群体,给用户产生的推荐就来自这个群体的平均值;所以要做好这个推荐,关键是如何量化口味相似这个指标。
原理
我们来说一下基于用户的协同过滤具体是怎么做的,核心是那个用户物品的关系矩阵,这个矩阵是最原始的材料。
第一步,准备用户向量,从这个矩阵中,理论上可以给每一个用户得到一个向量 。为什么说要是理论上呢?因为得到向量的前提是:用户需要在我们产品里有行为数据,否则就得不到这个向量。
这个向量有这么三个特点:
1、向量的维度就是物品的个数;
2、向量是稀疏的,也就是说并不是每个位置都有值;
3、向量维度上的取值可以是简单的0或1,1表示喜欢过,0表示没有;
第二步,用每一个用户的向量,两两计算用户之间的相似度,设定一个相似度阈值,为每个用户保留与其最相似的用户。
第三步,为每一个用户产生推荐结果。
把和他相似的用户们喜欢过的物品汇总起来,去掉用户自己已经消费过的物品,剩下的排序输出就是推荐结果。
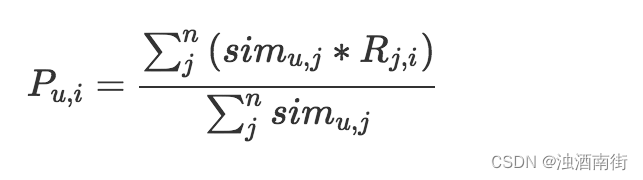
这个公式,等号左边就是计算一个物品i和一个用户u的匹配分数,等号右边是这个分数的计算过程,分母是把用户u相似的n个用户的相似度累加起来分子是把这n个用户各自对物品i的态度,按照相似度加权求和。这里的态度最简单就是0或1,1表示喜欢过,0表示没有,如果是评分,则可以是0到5的取值。整个公式就是相似用户们的态度加权平均值。
实践
原理看上去很简单,但是在实现上却有一些坑,需要非常小心;
1、只有原始的用户行为日志,需要从中构造矩阵,怎么做?
2、如果用户的向量很长,计算一个相似度则耗时很久,怎么办?
3、如果用户量很大,而且通常如此,而且两两计算用户相似度也是一个大坑,怎么办?
4、在计算推荐时,看上去要为每一个用户计算他和每一个物品的分数,又是一个大坑,怎么办?
1、构造矩阵
我们在做协同过滤计算时,所用的矩阵是稀疏的,也就是说很多矩阵元素不用存,都是0,这里介绍典型的稀疏矩阵存储格式。
1.CSR:这个存储稍微复杂点,是一个整体编码方式。它有三个组成:数值,列号和行偏移共同编码。COO
2.COO:这个存储方式很简单,每个元素由三元组表示(行号,列号,数值),只存储有值的元素,缺失值不存储。
这些存储格式,在常见的计算框架里面都是标准的,如Spark中,Python的Numpy包中。把你的原始行为日志转换为上述的格式,就可以使用常用的计算框架的标准输入了。
2、相似度计算
相似度计算是个问题。
首先是单个相似度计算问题,如果碰上向量很长,无论什么相似度计算方法,都要遍历向量。所以通常下降相似度计算复杂度的办法有两种。
1、对向量采样计算。如果两个100维向量的相似度是0.7,我们牺牲一些精度,随机从取出10维计算,以得到的值作为其相似度值,虽然精度下降,但执行效率明显快了很多。这个算法由Twitter提出,叫做DIMSUM算法,已经在spark中实现了。
2、向量化计算,与其说是一个技巧,不如说是一种思维。在机器学习领域,向量之间的计算时家常便饭,现代的线性代数库都支持直接的向量计算,比循环快很多。一些常用的向量库都天然支持,比如python中的numpy库。
其次的问题就是,如果用户量很大,两两之间计算代价很大。
有两个办法来缓解这个问题:
第一个办法是:将相似度拆成Map Reduce任务,将原始矩阵Map成键为用户对,值为两个用户对同一个物品的评分之积,Reduce阶段对这些乘积再求和,map reduce任务结束后再对这些值归一化;
第二个办法是:不用基于用户的协同过滤。
这种计算对象两两之间的相似度的任务,如果数据量不大,而且矩阵还是稀疏的,有很多工具可以使用:比如KGraph 、GraphCHI等;
3、推荐计算
得到用户之间的相似度之后,接下来就是计算推荐分数。显然未每一个用户计算每一个物品的推荐分数,这个代价有点大。不过,有几点我们可以来利用一下:
1.只有相似用户喜欢过的物品才需要计算,这样就减少很多物品量。
2、把计算过程拆成Map Reduce 任务。
拆Map Reduce任务的做法是:
1、遍历每个用户喜欢的用户列表;
2、获取该用户的相似用户列表;
3、把每一个喜欢的物品Map成两个记录发射出去,一个键为<相似用户ID,物品ID,1>三元组,值为<相似度>,另一个键为<相似用户ID,物品ID,0>三元组,值为<喜欢程度相似度>,其中1和0是为了区分两者,会在最后一步中用到。
4、Reduce阶段,求和后输出;
5、<相似用户ID,物品ID,0>的值除以<相似用户ID,物品ID,1>的值
因为map过程,其实就是将原来耦合的计算过程解耦了,这样的话我们可以利用多线程技术实现Map效果。
4、一些改进
对于基于用户的协同过滤有一些常用的改进办法,改进主要集中在用户对物品的喜欢程度上:
1.惩罚对热门物品的喜欢程度,这是因为热门的东西很难反应出用户的真实兴趣,更可能是被煽动,或者无聊随便点击的情形,这是群体行为的常见特点。
2.增加喜欢程度的时间衰减,一般使用一个指数函数,指数是一个负数,值和喜欢行为发生时间间隔正相关即可,比如 e ( − x ) e^{(-x)} e(−x),x代表喜欢时间距今的时间间隔。
应用场景:
最后说一下基于用户的协同过滤有哪些应用场景。基于用户的协同过滤有两个产出:
1、相似用户列表
2、基于用户的推荐结果
所以,我们不仅可以推荐物品,还可以推荐用户,比如我们在一些社交平台看到的,相似粉丝、和你口味类似的人等等都可以这样计算。
对于这个方法计算出来的推荐结果本身,由于是基于口味计算得出,所以在更强调个人隐私场景中应用更佳,在这样的场景下,不受大v影响,更能反应真实的兴趣群体。
总结
今天,我与你聊了基于用户的协同过滤方法,也顺便普及了一下协同过滤这个大框架的思想。基于用户的协同过滤算法非常简单,但非常有效。
在实现这个方法时,有许多需要注意的地方,比如:
1、相似度计算本身如果遇到超大维度向量怎么办?
2、两两计算用户相似度遇到用户量很大时怎么办?
同时,我也聊到了如何改进这个推荐算法,希望能够帮到你。
相关文章:
推荐系统三十六式学习笔记:原理篇.近邻推荐07|人以群分,你是什么人就看到什么世界
目录 协同过滤基于用户的协同过滤背后的思想原理实践1、构造矩阵2、相似度计算3、推荐计算4、一些改进 应用场景:总结 谈及推荐系统,不得不说大名鼎鼎的协同过滤。协同过滤的重点在于协同,所谓协同,也就是群体互帮互助,…...

要改进单例模式的实现以确保线程安全并优化性能,有几种常见的方法
要改进单例模式的实现以确保线程安全并优化性能,有几种常见的方法。以下是几种改进 ThreadUtil 单例实现的方法: ### 1. 懒汉式(线程安全版) 使用同步机制来确保线程安全,但只在第一次创建实例时同步,这样…...
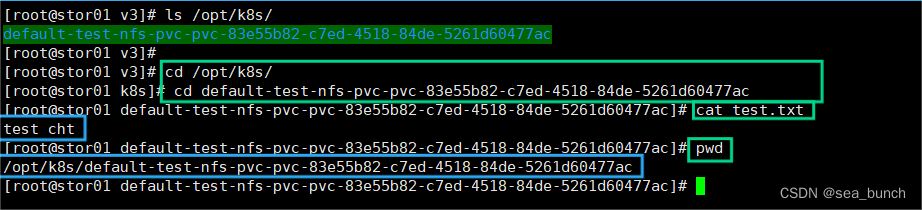
k8s——Pod容器中的存储方式及PV、PVC
一、Pod容器中的存储方式 需要存储方式前提:容器磁盘上的文件的生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。 首先,当容器崩溃时,kubelet 会重启它,但是容器中的文件将丢失——容器以干净的状态&…...

Java/Golang:活用interface,增加程序扩展性
场景 在paas中间件众多的场景下,做一款用于巡检多个paas组件健康状态的工具。工具的编写需要具备一定的扩展性,便于后续新增某个paas组件巡检的功能。 管理多个paas组件,需要方便扩展新增。 思路 使用面向对象编程思想,首先对…...
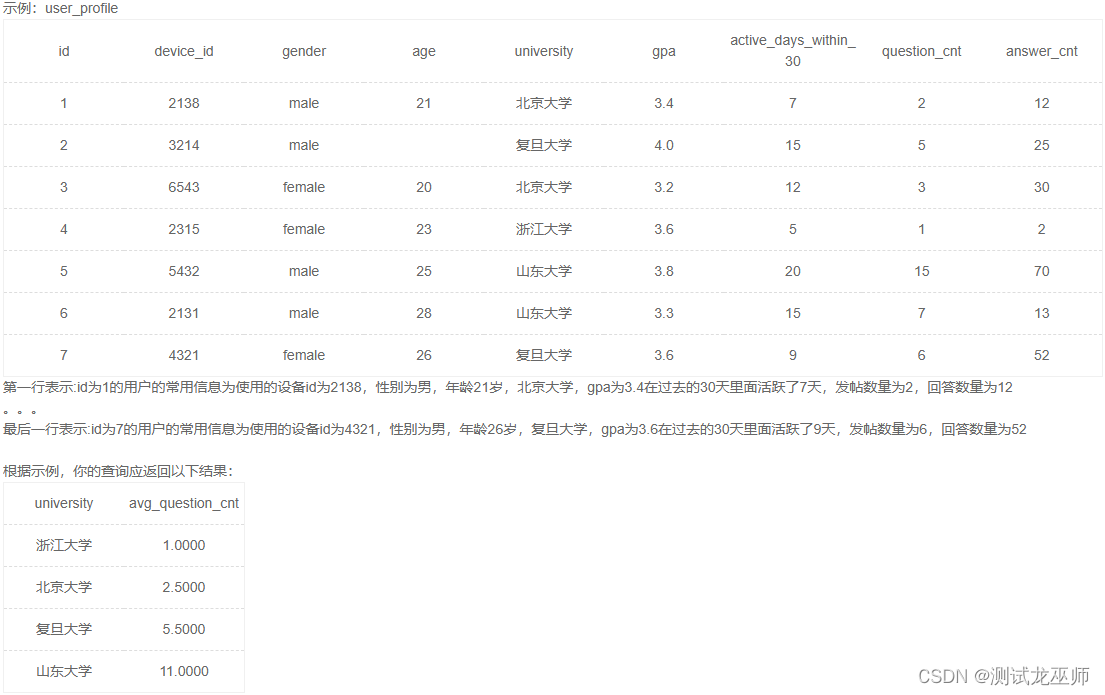
SQL语句练习每日5题(四)
题目1——查找GPA最高值 想要知道复旦大学学生gpa最高值是多少,请你取出相应数据 题解: 1、使用MAX select MAX(gpa) FROM user_profile WHERE university 复旦大学 2、使用降序排序组合limit select gpa FROM user_profile WHERE university 复…...
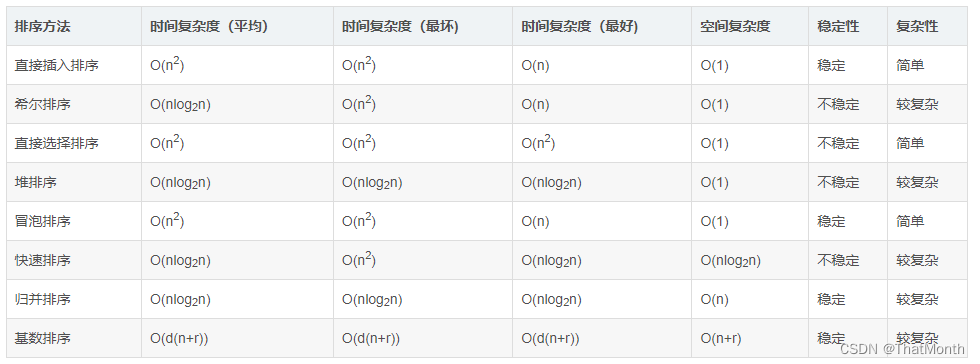
Java排序算法汇总篇,八种排序算法
排序算法汇总: Java排序算法(一):冒泡排序 Java排序算法(二):选择排序 Java排序算法(三):插入排序 Java排序算法(四):快速排序 Java排序算法(五):归并排序 Java排序算法(六):希尔排序 Java排序算法(…...
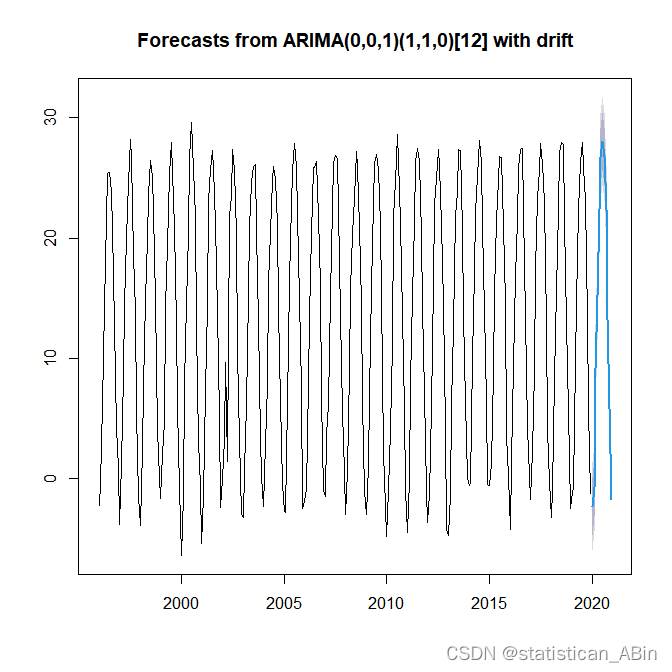
R语言探索与分析20-北京市气温预测分析
一、序言 近年来,人类大量燃烧煤炭、天然气等含碳燃料导致温室气 体过度排放,大量温室气体强烈吸收地面辐射中的红外线,造 成温室效应不断累积,使得地球温度上升,造成全球气候变暖。气象温度的预测一直以来都是天气预…...

2024年安全现状报告
2024 年安全现状报告有些矛盾。尽管安全专业人员的道路困难重重,比如说严格的合规要求、不断升级的地缘政治紧张局势和更复杂的威胁环境,但整个行业还是在取得进展。 许多组织表示,与前几年相比,网络安全变得更容易管理。组织之间…...

OV通配符ssl证书是什么
通配符https证书的产品比较丰富,为了方便区分,可以按照验证方式将通配符https证书分为DV基础型通配符https证书和OV企业型通配符https证书两种。其中OV通配符https证书申请条件高,审核也比较严格,相比于DV基础型通配符https证书&a…...

Selenium三种等待方式的使用!
UI自动化测试,大多都是通过定位页面元素来模拟实际的生产场景操作。但在编写自动化测试脚本中,经常出现元素定位不到的情况,究其原因,无非两种情况:1、有frame;2、没有设置等待。 因为代码运行速度和浏览器…...

websockets怎么工作的呢?
WebSockets是一种在单个TCP连接上进行全双工通信的协议,使得客户端和服务器之间的数据交换变得更加简单,并允许服务端主动向客户端推送数据。下面是WebSockets的工作原理: 1. **握手阶段**: - 客户端发起一个HTTP请求到服务器&…...

栈 数组和链表实现
stack 栈 LIFO后进先出 应用 实现递归 编辑器的撤回工作(按下ctrl z) 数组实现 // 列表的插入和删除从一端实现 那么就得到了栈 // array和linked lists//stack-Array based implementation #include<stdio.h> #include<stdlib.h> #def…...
如何备份和恢复华为手机?
智能手机已成为我们日常生活中不可或缺的一部分,它们存储着大量敏感数据。因此,确保数据安全,定期备份至关重要,以防手机意外丢失、损坏或被盗。 如果您拥有华为设备,并且正在寻找如何将华为手机备份到PC的方法&#…...

微波电路S参数测量实验方案
一、实验目的 用矢量分析仪测S参数,验证电磁波,检测电磁波在波导中的传播模式。 二、实验内容 用矢量分析仪测试微波滤波器的二端口S参数, 三、基本 四、实验步骤 1对矢量网络分析仪进行参数设置 2矢量网络分析仪进行校准 单端口校准…...

SpringTask Cron表达式
Cron表达式格式 1.Cron表达式格式 Cron表达式是一个字符串,字符串以5或6个空格隔开,分为6或7个域,每一个域代表一个含义,Cron有如下两种语法格式: 秒 分 时 一个月第几天 月 一个星期第几天 年 &…...

docker与docker-compose安装
1.1 安装工具 sudo yum install -y yum-utils device-mapper-persistent-data lvm21.2 添加docker的yum库 yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo sudo yum makecache fast1.3 安装Docker sudo yum install docke…...

跨境反向海淘系统:业务流程解析与未来发展展望
随着全球化的深入发展和互联网技术的飞速进步,跨境购物已经成为越来越多消费者日常生活中的一部分。在这个过程中,反向海淘系统以其独特的优势,逐渐崭露头角,成为跨境电商领域的新星。作为一名在跨境反向海淘系统业务中耕耘了10年…...

Python语言字母:深度解析与魅力探索
Python语言字母:深度解析与魅力探索 Python,作为一种广泛使用的编程语言,其字母背后蕴含着丰富的内涵和深厚的魅力。本文将从四个方面、五个方面、六个方面和七个方面,深入剖析Python语言字母所蕴含的秘密和魅力,带您…...
基于JSP技术的社区疫情防控管理信息系统
你好呀,我是计算机学长猫哥!如果有相关需求,文末可以找到我的联系方式。 开发语言:JSP 数据库:MySQL 技术:JSPJavaBeans 工具:MyEclipse、Tomcat、Navicat 系统展示 首页 用户注册与登录界…...
区间预测 | Matlab实现QRBiTCN分位数回归双向时间卷积神经网络注意力机制时序区间预测
Matlab实现QRBiTCN分位数回归双向时间卷积神经网络注意力机制时序区间预测 目录 Matlab实现QRBiTCN分位数回归双向时间卷积神经网络注意力机制时序区间预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 Matlab实现QRBiTCN分位数回归双向时间卷积神经网络注意力机制时序…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...