基于LSTM的文本情感分析(Keras版)
一、前言
文本情感分析是自然语言处理中非常基本的任务,我们生活中有很多都是属于这一任务。比如购物网站的好评、差评,垃圾邮件过滤、垃圾短信过滤等。文本情感分析的实现方法也是多种多样的,可以使用传统的朴素贝叶斯、决策树,也可以使用基于深度学习的CNN、RNN等。本文使用IMDB电影评论数据集,基于RNN网络来实现文本情感分析。
二、数据处理
2.1 数据预览
首先需要下载对应的数据:http://ai.stanford.edu/~amaas/data/sentiment/。点击下图位置:
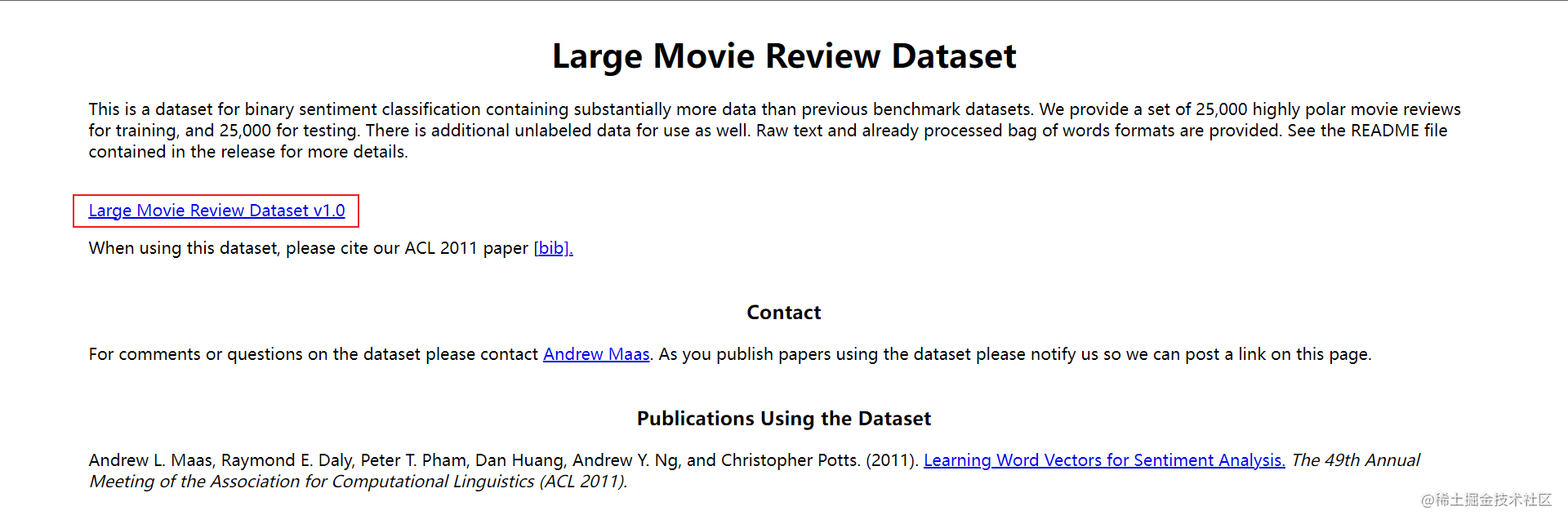
数据解压后得到下面的目录结构:
- aclImdb- test- neg- pos- labeledBow.feat- urls_neg.txt- urls_pos.txt- train- neg- pos
这是一个电影影评数据集,neg中包含的评论是评分较低的评论,而pos中包含的是评分较高的评论。我们需要的数据分别是test里面的neg和pos,以及train里面的neg和pos(neg表示negative,pos表示positive)。下面我们开始处理。
2.2 导入模块
在开始写代码之前需要先导入相关模块:
import os
import re
import stringimport numpy as np
from tensorflow.keras import layers
from tensorflow.keras.models import Model
我的环境是tensorflow2.7,部分版本的tensorflow导入方式如下:
from keras import layers
from keras.models import Model
可以根据自己环境自行替换。
2.3 数据读取
这里定义一个函数读取评论文件:
def load_data(data_dir=r'/home/zack/Files/datasets/aclImdb/train'):"""data_dir:train的目录或test的目录输出:X:评论的字符串列表y:标签列表(0,1)"""classes = ['pos', 'neg']X, y = [], []for idx, cls in enumerate(classes):# 拼接某个类别的目录cls_path = os.path.join(data_dir, cls)for file in os.listdir(cls_path):# 拼接单个文件的目录file_path = os.path.join(cls_path, file)with open(file_path, encoding='utf-8') as f:X.append(f.read().strip())y.append(idx)return X, np.array(y)
上述函数会得到两个列表,便于我们后面处理。
2.4 构建词表
在我们获取评论文本后,我们需要构建词表。即统计所有出现的词,给每个词一个编号(也可以统计一部分,多余的用unk表示)。这一步会得到一个词到id的映射和id到词的映射,具体代码如下:
def build_vocabulary(sentences):"""sentences:文本列表输出:word2idx:词到id的映射idx2word:id到词的映射"""word2idx = {}idx2word = {}# 获取标点符号及空字符punctuations = string.punctuation + "\t\n "for sentence in sentences:# 分词words = re.split(f'[{punctuations}]', sentence.lower())for word in words:# 如果是新词if word not in word2idx:word2idx[word] = len(word2idx)idx2word[len(word2idx) - 1] = wordreturn word2idx, idx2word
有了上面的两个映射后,我们就可以将句子转换成id序列,也可以把id序列转换成句子,在本案例中只需要前者。
2.5 单词标记化(tokenize)
因为我们模型需要固定长度的数据,因此在标记化时我们对句子长度进行限制:
def tokenize(sentences, max_len=300):"""sentences:文本列表tokens:标记化后的id矩阵,形状为(句子数量, 句子长度)"""# 生产一个形状为(句子数量, 句子长度)的矩阵,默认用空字符的id填充,类型必须为inttokens = np.full((len(sentences), max_len),fill_value=word2idx[''], dtype=np.int32)punctuations = string.punctuation + "\t\n "for row, sentence in enumerate(sentences):# 分词words = re.split(f'[{punctuations}]', sentence.lower())for col, word in enumerate(words):if col >= max_len:break# 把第row个句子的第col个词转成idtokens[row, col] = word2idx.get(word, word2idx[''])return tokens
使用该函数就可以将句子列表转换成ndarray了。
三、构建模型并训练
3.1 构建模型
这里使用RNN来实现,模型结构如下图:
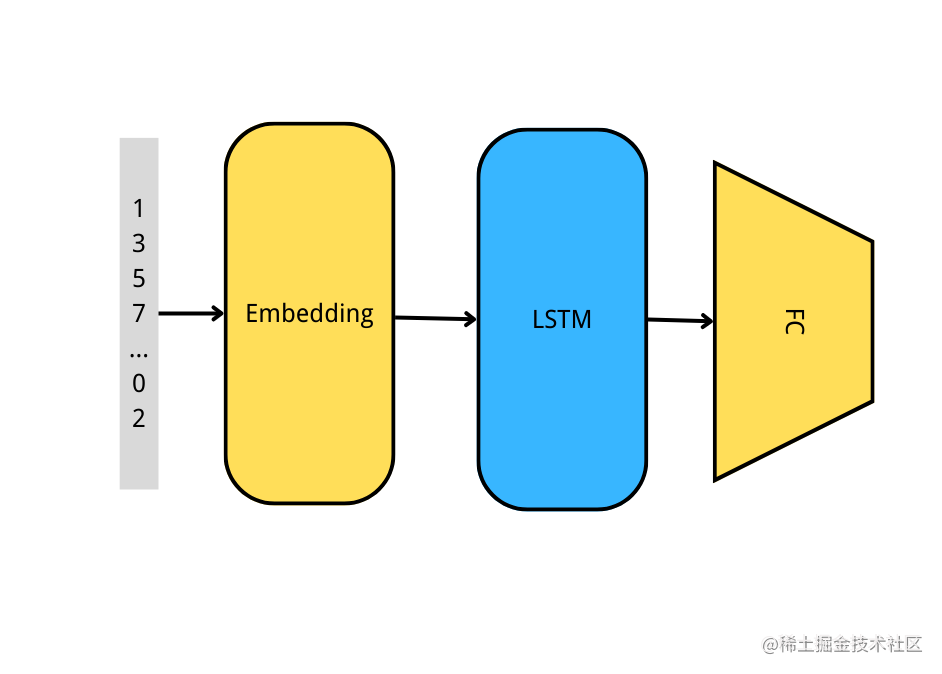
下面我们用程序实现这个模型:
def build_model():vocab_size = len(word2idx)# 构建模型inputs = layers.Input(shape=max_len)x = layers.Embedding(vocab_size, embedding_dim)(inputs)x = layers.LSTM(64)(x)outputs = layers.Dense(1, activation='sigmoid')(x)model = Model(inputs, outputs)return model
这里需要注意下面几个地方:
- Embedding层的输入是(batch_size,max_len),输出是(batch_size,max_len,embedding_dim)
- LSTM层的输入是(batch_size,max_len,embedding_dim),输出是(batch_size,units),units就是LSTM创建时传入的值。
3.2 训练模型
下面就可以使用前面实现好的几个方法开始训练模型了,代码如下:
# 超参数
max_len = 200
batch_size = 64
embedding_dim = 256
# 加载数据
X_train, y_train = load_data()
X_test, y_test = load_data('/home/zack/Files/datasets/aclImdb/test')
X = X_train + X_test
word2idx, idx2word = build_vocabulary(X)
X_train = tokenize(X_train, max_len=max_len)
X_test = tokenize(X_test, max_len=max_len)# 构建模型
model = build_model()
model.summary()
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train,batch_size=batch_size,epochs=20,validation_data=[X_test, y_test],
)
经过20个epoch的训练后,训练集准确率可以达到99%,而验证集准确率在80%左右,模型有一定程度的过拟合,可以通过修改模型结构或调节超参数来进行优化。
比如修改max_len的大小、使用预训练的词嵌入、修改RNN中units的大小、修改embedding_dim的大小等。还可以添加BatchNormalization、Dropout层。
四、使用模型
模型训练好后,可以用predict来预测,predict的输入和embedding层的输入是一样的:
while True:sentence = input("请输入句子:")tokenized = tokenize([sentence], max_len)output = model.predict(tokenized)print('消极' if output[0][0] >= 0.5 else '积极')
下面是一些测试结果:
请输入句子:this is a bad movie
消极
请输入句子:this is a good movie
积极
请输入句子:i like this movie very much
积极
请输入句子:i hate this movie very much
积极
请输入句子:i will never see this movie again
积极
效果不是特别理想,因为训练样本通常为长文本,而现在测试的是短文本。
相关文章:
基于LSTM的文本情感分析(Keras版)
一、前言 文本情感分析是自然语言处理中非常基本的任务,我们生活中有很多都是属于这一任务。比如购物网站的好评、差评,垃圾邮件过滤、垃圾短信过滤等。文本情感分析的实现方法也是多种多样的,可以使用传统的朴素贝叶斯、决策树,…...

2023年全国最新机动车签字授权人精选真题及答案17
百分百题库提供机动车签字授权人考试试题、机动车签字授权人考试预测题、机动车签字授权人考试真题、机动车签字授权人证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 三、多选题 1.注册登记安全检验时,送检乘用…...
PowerShell远程代码执行漏洞(CVE-2022-41076)分析与复现
漏洞概述PowerShell(包括Windows PowerShell和PowerShell Core)是微软公司开发的任务自动化和配置管理程序,最初只是一个 Windows 组件,由命令行 shell 和相关的脚本语言组成。后于2016年8月18日开源并提供跨平台支持。PowerShell…...

Mybatis中的一级缓存和二级缓存
Mybatis作为一款强大的ORM框架,其中也用到了缓存来加速查询,今天我们一起来探讨下。 Mybatis可以使用懒加载来提高查询的效率,并且可以通过缓存来提高查询的效率。其中包括有一级缓存和二级缓存。 一级缓存是sqlSession级别的缓存,…...
【Java】SpringBoot中实现异步编程
前言 首先我们来看看在Spring中为什么要使用异步编程,它能解决什么问题? 什么是异步? 首先我们先来看看一个同步的用户注册例子,流程如下: 异步的方式如下: 在用户注册后将成功结果返回,…...
(2023/03/09))
ASCII 文件与 TIFF 文件互转(Python 实现)(2023/03/09)
ASCII 文件与 TIFF 文件互转(Python 实现) 文章目录ASCII 文件与 TIFF 文件互转(Python 实现)1. 环境1.1 Linux1.2 Windows2. 代码1. 环境 1.1 Linux $ pip3 install --index-url https://mirrors.aliyun.com/pypi/simple --tru…...

思科模拟器 | 交换机与路由器的配置汇总【收藏备用】
文章目录一、vlan配置【实现同一vlan的主机通信】1、基本配置和接线2、vlan配置与端口连接3、测试连接二、truck配置【实现连接在不同交换机上的同一vlan的主机通信】1、基本配置和接线2、vlan配置与端口连接3、打truck做连接3、测试连接三、静态路由配置1、自定义IP地址2、基本…...

电子台账:软件运行环境要求与功能特点
1 运行环境要求为满足大部分应用环境,软件开发时综合考虑各种各种不同因素影星,包括:操作系统、硬件、辅助软件、安装、运行、补丁、数据库、网络、人员等因素。目前台账软件需求为:操作系统:目前能运行的任意版本wind…...

计算机科学导论笔记(六)
目录 八、算法 8.1 概念 8.1.1 非正式定义 8.1.2 示例 8.1.3 定义动作 8.1.4 细化 8.1.5 泛化 8.2 三种结构 8.2.1 顺序 8.2.2 判断 8.2.3 循环 8.3 算法的表示 8.3.1 UML 8.3.2 伪代码 8.4 更正式的定义 8.5 基本算法 8.5.1 求和 8.5.2 求积 8.5.3 最大和最…...

嵌入式从业10年,聊聊我对工业互联网和消费物联网的看法 | 文末赠书4本
嵌入式从业10年,聊聊我对工业互联网和消费物联网的看法 工业互联网和消费物联网,有何异常点?本文,博主将结合自己的亲身经历,现身说法,聊聊博主对工业互联网和消费物联网的看法。 文章目录1 写在前面2 我眼…...

python的django框架从入门到熟练【保姆式教学】第一篇
当今,Python已成为最受欢迎的编程语言之一。而Django是一个基于Python的Web框架,它能够帮助你快速、高效地开发Web应用程序。如果你是一名初学者,学习Django框架可能会让你感到有些困惑。不过,不用担心,我们将为你提供…...

浏览记录或者购物车的去重处理
saveHistory(){// 获取缓存数据let historyArr uni.getStorageSync(historyArr) || []//需要添加的数据let item{id:this.detail.id,classid:this.detail.classid,title:this.detail.title,picurl:this.detail.picurl,looktime:parseTime(Date.now())};// forEach和findIndex的…...
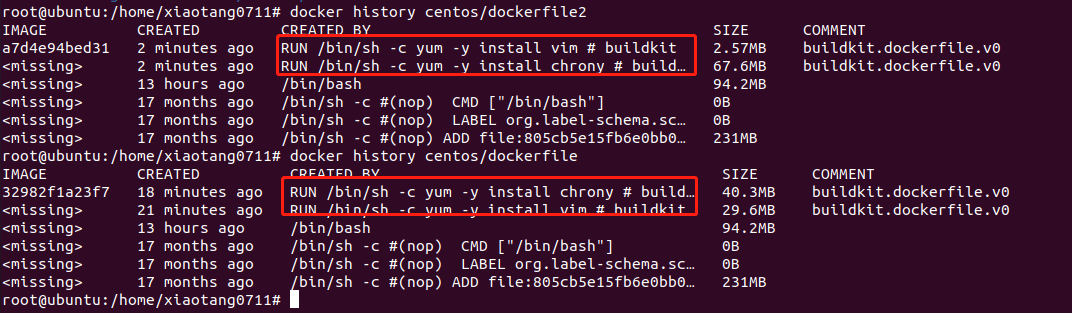
Ubantu docker学习笔记(二)拉取构建,属于你的容器
文章目录一、拉取启动容器二、本地镜像初解三、构建镜像3.1使用docker commit构建镜像切换阿里镜像3.2使用dockerfile构建镜像四、总个结吧这里的话,就详细说说小唐对于容器的配置,对了!小唐参考的书籍是Linux容器云实战!…...
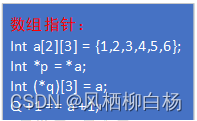
指针数组 数组指针 常量指针 指针常量 函数指针 指针函数
一、指针常量与常量指针 1、指针常量 本质上是一个常量,常量的类型是指针,表示该常量是一个指针类型的常量。在指针常量中,指针本身的值是一个常量,不可以改变,始终指向同一个地址。在定义的时候,必须要初…...

前端js学习
1. js入门 1.1 js是弱类型语言 1.2 js使用方式 1.2.1 在script中写 1.2.2 引入js文件 1.2.3 优先级 1.3 js查错方式 1.4 js变量定义 1.4 js数据类型 数据类型英文表示示例数值类型number1.1 1字符串类型string‘a’ ‘abc’ “abc”对象类型object布尔类型booleannumber函数…...
)
“华为杯”研究生数学建模竞赛2007年-【华为杯】A题:食品卫生安全保障体系数学模型及改进模型(附获奖论文)
赛题描述 我国是一个拥有13亿人口的发展中国家,每天都在消费大量的各种食品,这批食品是由成千上万的食品加工厂、不可计数的小作坊、几亿农民生产出来的,并且经过较多的中间环节和长途运输后才为广大群众所消费,加之近年来我国经济发展迅速而环境治理没有能够完全跟上,以至…...

转战C#---day2
定义数组: using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;namespace Relay_Sin_Com {class Program{static void Main(string[] args){int[] ages1 {3240,242,34};Console.WriteLine(age…...

【vue2源码学习】— diff
vue更新还是调用了 vm._update 会进入下面这一步 vm.$el vm.__patch__(prevVnode, vnode) 又回到了patch方法 会通过sameVnode 判断是不是相同的vnode// patch代码片段 const isRealElement isDef(oldVnode.nodeType) if (!isRealElement && sameVnode(oldVnode, vno…...

更换 Linux 自带的 jdk 环境
如下,我要把 Linux 默认的 jdk 版本换成我自己的 jdk 版本。 Linux 自带的 jdk 环境: 要更换的 jdk 环境: 1、切换到 root 用户进行操作; 2、在根目录下创建一个 /export/server/ 目录; [rootcentos /]# mkdir -p /e…...
MySQL8读写分离集群
文章目录前言MySQL读写分离原理搭建MySQL读写分离集群MySQL8.0之前MySQL8.0之后后记前言 上一期介绍并实现了MySQL的主从复制,由于主从复制架构仅仅能解决数据冗余备份的问题,从节点不对外提供服务,依然存在单节点的高并发问题 所以在主从复…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

(一)单例模式
一、前言 单例模式属于六大创建型模式,即在软件设计过程中,主要关注创建对象的结果,并不关心创建对象的过程及细节。创建型设计模式将类对象的实例化过程进行抽象化接口设计,从而隐藏了类对象的实例是如何被创建的,封装了软件系统使用的具体对象类型。 六大创建型模式包括…...
零知开源——STM32F103RBT6驱动 ICM20948 九轴传感器及 vofa + 上位机可视化教程
STM32F1 本教程使用零知标准板(STM32F103RBT6)通过I2C驱动ICM20948九轴传感器,实现姿态解算,并通过串口将数据实时发送至VOFA上位机进行3D可视化。代码基于开源库修改优化,适合嵌入式及物联网开发者。在基础驱动上新增…...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...
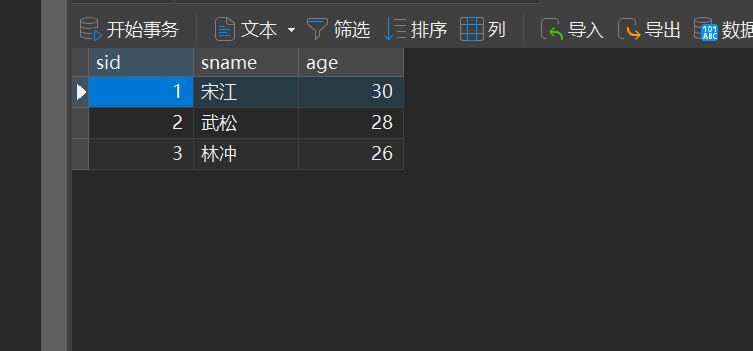
MySQL的pymysql操作
本章是MySQL的最后一章,MySQL到此完结,下一站Hadoop!!! 这章很简单,完整代码在最后,详细讲解之前python课程里面也有,感兴趣的可以往前找一下 一、查询操作 我们需要打开pycharm …...