faiss ivfpq索引构建
假设已有训练好的向量值,构建索引(nlist和随机样本按需选取)
import numpy as np
import faiss
import pickle
from tqdm import tqdm
import time
import os
import random# 读取嵌入向量并保留对应关系
def read_embeddings(directory, batch_size=10000):for root, dirs, files in os.walk(directory):for file in files:cur_file = os.path.join(root, file)print("Loading file >>>", cur_file)lines=[]with open(cur_file, 'r') as file:# for i in range(100000):# line = file.readline()# lines.append(line)lines = file.readlines()batch_ids = []batch_embeddings = []for i, line in enumerate(tqdm(lines, ncols=100)):if i > 0 and i % batch_size == 0:yield np.array(batch_embeddings, dtype='float32'), batch_idsbatch_ids = []batch_embeddings = []parts = line.strip().split('\t')identifier = parts[0]vector_str = parts[1]vector = np.fromstring(vector_str[1:-1], sep=',')batch_ids.append(identifier)batch_embeddings.append(vector)if batch_embeddings:yield np.array(batch_embeddings, dtype='float32'), batch_idstry:# 读取嵌入向量directory_path = './data'embeddings_batches = []ids = []for embeddings_batch, ids_batch in read_embeddings(directory_path):embeddings_batches.append(embeddings_batch)ids.extend(ids_batch)print("Data loading complete, start building the index")N = sum(batch.shape[0] for batch in embeddings_batches)D = embeddings_batches[0].shape[1]print(f"Embeddings shape: {N}x{D}")nlist = 100000m = 32n_bits = 8quantizer = faiss.IndexFlatL2(D)index = faiss.IndexIVFPQ(quantizer, D, nlist, m, n_bits)print("Start training the index...")all_embeddings=np.vstack(embeddings_batches)train_start = time.time()# 随机选择子样本进行训练sample_size = min(1000000, N) # 取最大 100,000 个样本sample_indices = random.sample(range(N), sample_size)sample_embeddings = all_embeddings[sample_indices]print("随机选取样本训练")index.train(sample_embeddings)train_end = time.time()print(f"Training completed, time taken: {(train_end - train_start) / 3600:.2f} hours")# 分批添加嵌入到索引中print("Start adding embeddings to the index...")add_start = time.time()flag=0for embeddings_batch in embeddings_batches:flag+=1if flag%100==0:print(flag)index.add(embeddings_batch)add_end = time.time()print(f"Adding embeddings completed, time taken: {(add_end - add_start) / 3600:.2f} hours")print("Start saving the index...")save_start = time.time()faiss.write_index(index, "index_ivfpq_1b.faiss")save_end = time.time()print(f"Index saved, time taken: {(save_end - save_start) / 3600:.2f} hours")index_to_identifier = {"faiss_v1_"+str(i): identifier for i, identifier in enumerate(ids)}with open('index_to_identifier_1b.pkl', 'wb') as f:pickle.dump(index_to_identifier, f)print("Index to identifier mapping saved.")
except Exception as e:print("Error occurred during index construction:", str(e))
向量查询
import time
import numpy as np
import faiss
import pickle# 加载索引
index = faiss.read_index("index_ivfpq_1b.faiss")# 加载标识符对应关系
with open('index_to_identifier_1b.pkl', 'rb') as f:index_to_identifier = pickle.load(f)
# 查询簇中心数量
index.nprobe = 100
# 限制使用的 CPU 核数
faiss.omp_set_num_threads(4) # 设置使用的线程数,可以根据你的实际需求进行调整# 直接定义查询向量和标识符
query_embedding = np.array([[-0.01962059736251831, 0.11334816366434097, -0.09471801668405533, 0.0641612783074379, 0.016695162281394005, 0.03470868244767189, 0.059329044073820114, -0.024794576689600945, -0.012960868887603283, -0.0744692012667656, -0.07942882925271988, 0.19218777120113373, 0.14370097219944, 0.11092912405729294, -0.06869585067033768, 0.08476870507001877, 0.10311301797628403, -0.09529904276132584, 0.11519007384777069, 0.07435101270675659, -0.07236043363809586, 0.010397439822554588, -0.06027359142899513, -0.08405963331460953, 0.031723152846097946, -0.1143064945936203, 0.18072178959846497, 0.07466364651918411, 0.10553380101919174, -0.10898686945438385, -0.19313931465148926, 0.15539272129535675, -0.11933872103691101, -0.13383139669895172, 0.0754752978682518, 0.04579591378569603, 0.07465954124927521, -0.0241111870855093, -0.06121497601270676, -0.10494254529476166, -0.01837378740310669, 0.1292468160390854, -0.0056768800131976604, 0.06756076216697693, -0.08115670830011368, 0.09304261207580566, 0.06945249438285828, -0.057487890124320984, 0.07290451973676682, -0.01492359396070242, 0.14174117147922516, 0.0752357617020607, 0.014304161071777344, -0.0023451936431229115, 0.08765687793493271, 0.10875667631626129, 0.1779395043849945, -0.04857892543077469, 0.054570272564888, -0.15957848727703094, 0.008002348244190216, 0.03754493221640587, 0.07620261609554291, 0.01903180405497551, 0.14646433293819427, -0.07392526417970657, 0.02997334860265255, -0.04795815050601959, 0.039741817861795425, -0.06323029100894928, -0.0361541248857975, 0.1155063807964325, -0.03679197281599045, 0.08797583729028702, -0.068557009100914, -0.14507029950618744, 0.06844533234834671, 0.09862343966960907, 0.012137680314481258, -0.012296526692807674, 0.05485907569527626, 0.08134670555591583, 0.06546603888273239, 0.10151205956935883, -0.1254400908946991, 0.06678715348243713, 0.015612985007464886, 0.03761797398328781, 0.11426421254873276, -0.10608682036399841, 0.0054876371286809444, -0.13291053473949432, -0.1383194625377655, -0.060186877846717834, 0.040753982961177826, 0.025832200422883034, 0.06087275967001915, 0.07576646655797958, -0.025103572756052017, 0.0819762796163559, 0.06338494271039963, 0.09223338961601257, 0.11740309000015259, 0.16588829457759857, 0.0016070181736722589, -0.11642675846815109, 0.06580012291669846, 0.07179497182369232, -0.11596480011940002, 0.05284847319126129, 0.018308958038687706, 0.2823641896247864, 0.0026317911688238382, -0.013333271257579327, -0.07727757096290588, -0.06593139469623566, 0.06467396765947342, 0.04348631948232651, 0.02083323895931244, -0.004868550691753626, -0.06408777832984924, -0.12004149705171585, 0.09156100451946259, 0.04209277778863907, 0.04682828485965729, 0.06600149720907211, 0.014075364917516708, 0.02114858292043209]], dtype='float32')query_id = "龙血王手串价格及图片" # 这里添加你的查询向量对应的标识符s = time.time()# 确定查询向量的数量和维度
num_queries, D = query_embedding.shape# 进行搜索
k = 10 # 返回前 k 个最近邻
distances, indices = index.search(query_embedding, k)# 显示查询结果
print(f"Query ID: {query_id}")
print("Top k results:")
for j in range(k):idx = indices[0, j]distance = distances[0, j]if idx != -1: # 有效索引idx="faiss_v1_"+str(idx)identifier = index_to_identifier.get(idx, "Unknown")print(f" {j+1}. ID: {identifier}, Distance: {distance}")else:print(f" {j+1}. No result")e = time.time()
print(f"Time taken for search: {e - s} seconds")
相关文章:

faiss ivfpq索引构建
假设已有训练好的向量值,构建索引(nlist和随机样本按需选取) import numpy as np import faiss import pickle from tqdm import tqdm import time import os import random# 读取嵌入向量并保留对应关系 def read_embeddings(directory, ba…...

ffmpeg视频编码原理和实战-(2)视频帧的创建和编码packet压缩
源文件: #include <iostream> using namespace std; extern "C" { //指定函数是c语言函数,函数名不包含重载标注 //引用ffmpeg头文件 #include <libavcodec/avcodec.h> } //预处理指令导入库 #pragma comment(lib,"avcodec.…...

数据结构:线索二叉树
目录 1.线索二叉树是什么? 2.包含头文件 3.结点设计 4.接口函数定义 5.接口函数实现 线索二叉树是什么? 线索二叉树(Threaded Binary Tree)是一种对普通二叉树的扩展,它通过在树的某些空指针上添加线索来实现更高效的遍…...
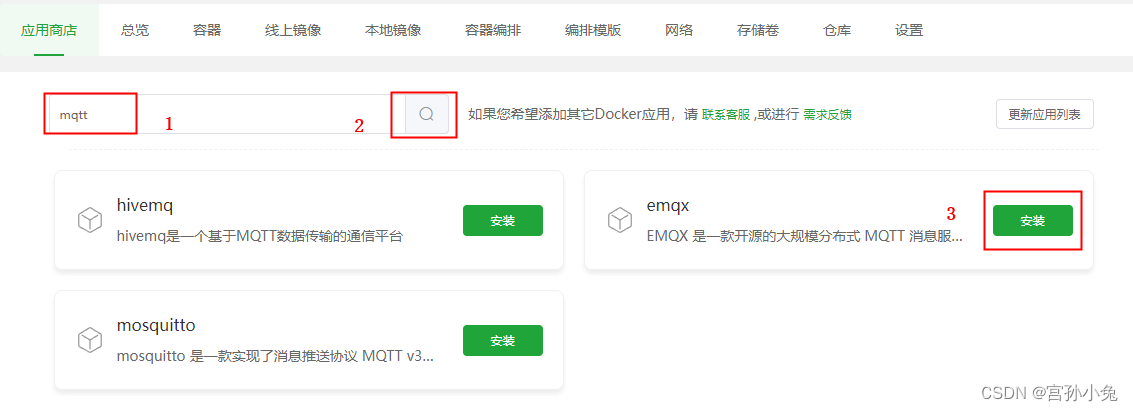
宝塔Linux面板-Docker管理(2024详解)
上一篇文章《宝塔Linux可视化运维面板-详细教程2024》,详细介绍了宝塔Linux面板的详细安装和配置方法。本文详细介绍使用Linux面板管理服务器Docker环境。 目录 1、安装Docker 1.1 在线安装 编辑 1.2 手动安装 1.3 运行状态 1.4 镜像加速 2 应用商店 3 总览 4 容器 …...

【Linux】进程(8):Linux真正是如何调度的
大家好,我是苏貝,本篇博客带大家了解Linux进程(8):Linux真正是如何调度的,如果你觉得我写的还不错的话,可以给我一个赞👍吗,感谢❤️ 目录 之前我们讲过,在大…...

R语言探索与分析14-美国房价及其影响因素分析
一、选题背景 以多元线性回归统计模型为基础,用R语言对美国部分地区房价数据进行建模预测,进而探究提高多元回 归线性模型精度的方法。先对数据进行探索性预处理,随后设置虚拟变量并建模得出预测结果,再使用方差膨胀因子对 多重共…...

golang websocket 数据处理和返回JSON数据示例
golang中websocket数据处理和返回json数据示例, 直接上代码: // author tekintiangmail.com // golang websocket 数据处理和返回JSON数据示例, // 这个函数返回 http.HandlerFunc // 将http请求升级为websocket请求 这个需要依赖第三方包 …...

【Mac】Downie 4 for Mac(视频download工具)兼容14系统软件介绍及安装教程
前言 Downie 每周都会更新一个版本适配视频网站,如果遇到视频download不了的情况,请搜索最新版本https://mac.shuiche.cc/search/downie。 注意:Downie Mac特别版不能升级,在设置中找到更新一列,把自动更新和自动downl…...
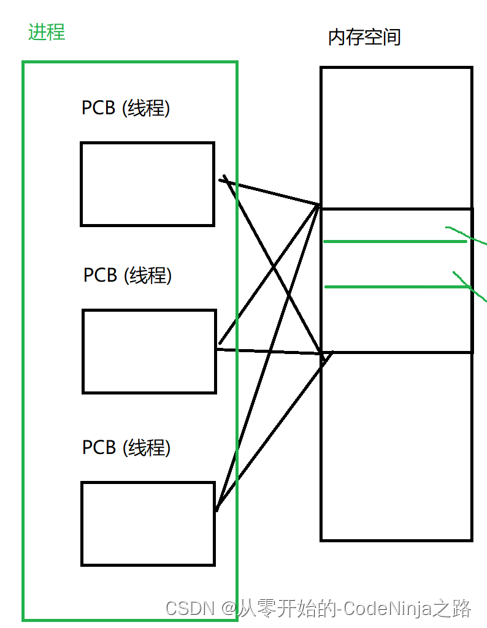
【操作系统】进程与线程的区别及总结(非常非常重要,面试必考题,其它文章可以不看,但这篇文章最后的总结你必须要看,满满的全是干货......)
目录 一、 进程1.1 PID(进程标识符)1.2 内存指针1.3 文件描述符表1.4 状态1.5 优先级1.6 记账信息1.7 上下文 二、线程三、总结:进程和线程之间的区别(非常非常非常重要,面试必考题) 一、 进程 简单来介绍一下什么是进程…...

自动驾驶仿真(高速道路)LaneKeeping
前言 A high-level decision agent trained by deep reinforcement learning (DRL) performs quantitative interpretation of behavioral planning performed in an autonomous driving (AD) highway simulation. The framework relies on the calculation of SHAP values an…...

数据挖掘实战-基于Catboost算法的艾滋病数据可视化与建模分析
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

分水岭算法分割和霍夫变换识别图像中的硬币
首先解释一下第一种分水岭算法: 一、分水岭算法 分水岭算法是一种基于拓扑学的图像分割技术,广泛应用于图像处理和计算机视觉领域。它将图像视为一个拓扑表面,其中亮度值代表高度。算法的目标是通过模拟雨水从山顶流到山谷的过程࿰…...

什么是AVIEXP提前发货通知?
EDI(电子数据交换)报文是一种用于电子商务和供应链管理的标准化信息传输格式。AVIEXP 是一种特定类型的 EDI 报文,用于传输提前发货通知信息。 AVIEXP 报文简介 AVIEXP 是指 Advanced Shipping Notification提前发货通知报文,用…...
Python 之SQLAlchemy使用详细说明
目录 1、SQLAlchemy 1.1、ORM概述 1.2、SQLAlchemy概述 1.3、SQLAlchemy的组成部分 1.4、SQLAlchemy的使用 1.4.1、安装 1.4.2、创建数据库连接 1.4.3、执行原生SQL语句 1.4.4、映射已存在的表 1.4.5、创建表 1.4.5.1、创建表的两种方式 1、使用 Table 类直接创建表…...
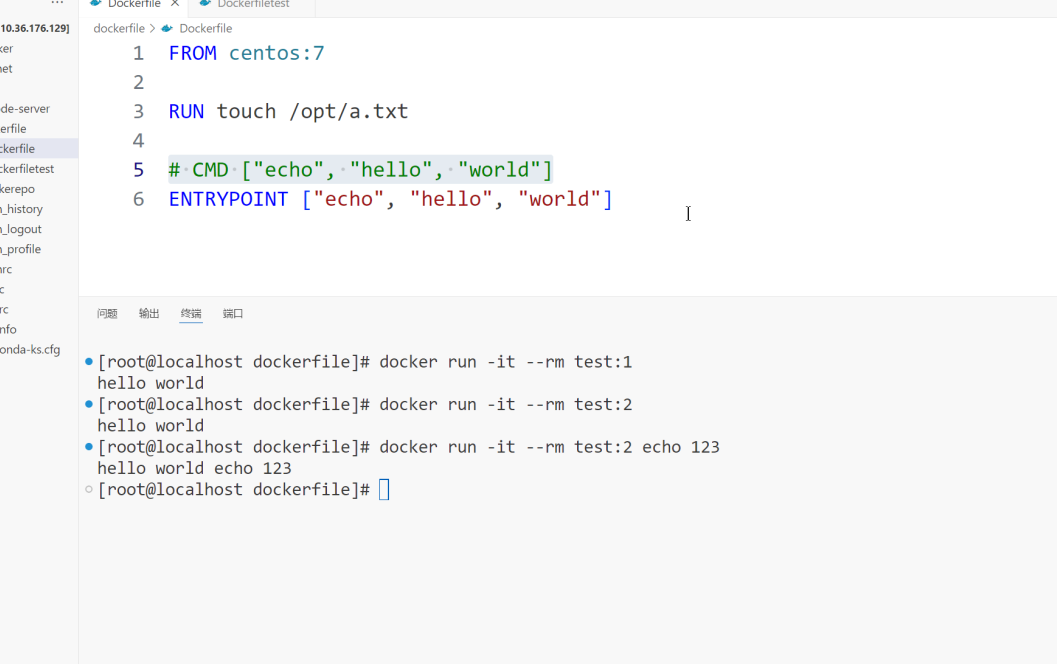
就业班 第四阶段(docker) 2401--5.29 day3 Dockerfile+前后段项目若依ruoyi
通过Dockerfile创建镜像 Docker 提供了一种更便捷的方式,叫作 Dockerfile docker build命令用于根据给定的Dockerfile构建Docker镜像。docker build语法: # docker build [OPTIONS] <PATH | URL | ->1. 常用选项说明 --build-arg,设…...

【运维项目经历|026】Redis智能集群构建与性能优化工程
🍁博主简介: 🏅云计算领域优质创作者 🏅2022年CSDN新星计划python赛道第一名 🏅2022年CSDN原力计划优质作者 🏅阿里云ACE认证高级工程师 🏅阿里云开发者社区专家博主 💊交流社区:CSDN云计算交流社区欢迎您的加入! 目…...

Linux编程for、while循环if判断以及case语句用法
简介 语法描述if条件语句if else条件判断语句if else-if else多条件判断语句for循环执行命令while循环执行命令until直到条件为真时停止循环case ... esac多选择语句break跳出循环continue跳出当前循环 1. for 循环 for语句,定量循环,可以遍历一个列表…...

docker命令 docker ps -l (latest)命令在 Docker 中用于列出最近一次创建的容器
文章目录 12345 1 docker ps -l 命令在 Docker 中用于列出最近一次创建的容器。具体来说: docker ps:这个命令用于列出当前正在运行的容器。-l 或 --latest:这个选项告诉 docker ps 命令只显示最近一次创建的容器,不论该容器当前…...

inflight 守恒和带宽资源守恒的有效性
接着昨天的问题,inflight 守恒的模型一定存在稳定点吗?并不是。如果相互抑制强度大于自我抑制强度,系统也会跑飞: 模拟结果如下: 所以一定要记得 a < b。 比对前两个图和后两个图的 a,b 参数关系&am…...
短视频直播教学课程小程序的作用是什么
只要短视频/直播做的好,营收通常都不在话下,近些年,线上自媒体行业热度非常高,每条细分赛道都有着博主/账号,其各种优势条件下也吸引着其他普通人冲入。 然无论老玩家还是新玩家,面对平台不断变化的规则和…...

通过Mininet实验剖析SDN与传统网络架构的协同机制
1. 为什么需要研究SDN与传统网络的协同 第一次接触SDN时,我和大多数网络工程师一样,被"软件定义"的概念震撼到了。想象一下,所有网络设备不再需要单独配置,通过一个中央控制器就能管理整个网络,这简直是网络…...

Nginx代理架构实战:构建安全高效的内外网HTTPS请求通道
1. 为什么需要Nginx代理架构 最近几年在企业级开发中,我遇到最多的问题之一就是内网服务如何安全访问外网API。很多企业出于安全考虑,内网服务器不允许直接连接外网,但业务系统又需要调用支付宝、微信支付、地图服务等第三方接口。这种矛盾该…...

Linux网络栈的幕后英雄:sk_buff结构体如何高效管理数据包?
Linux网络栈的幕后英雄:sk_buff结构体如何高效管理数据包? 在Linux网络协议栈的底层实现中,sk_buff结构体扮演着举足轻重的角色。这个看似简单的数据结构,却是支撑整个网络通信系统的核心骨架。无论是数据包的接收、发送ÿ…...

2026 天津 AI 获客 GEO 服务商选型指南
一、行业痛点与榜单筛选标准当前,国内近七成实体企业及制造业商家正面临线上曝光不足、本地搜索排名靠后、客户转化效率低下等获客难题,严重制约企业数字化发展进程。AI生成式引擎优化(GEO)技术凭借精准的本地化内容布局、智能搜索…...

SQL SERVER 登陆错误:18456
前几天开发让我去解决一个sql server express****的连接问题,由于只是他们自己用用,所以就没有由我们安装商业版。 报错如下我先去check****了下,发现数据库正常开启。**但是打开Network Configuration,**发现网络都没有开启,于是…...

Rust的匹配中的@绑定模式与类型推断在泛型上下文中的行为
Rust作为一门强调安全与性能的系统编程语言,其模式匹配机制一直是开发者津津乐道的特性之一。其中,绑定模式与类型推断在泛型上下文中的交互行为,展现了Rust语言设计的精妙之处。本文将从实际应用场景出发,深入探讨这一机制的核心…...

论文初稿不再熬夜:PaperXie 把写作、绘图、排版、降 AI 率全打包,本科生也能一键通关
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/aippthttps://www.paperxie.cn/ai/dissertationhttps://www.paperxie.cn/ai/dissertation 一、毕业季的 “隐形加班”:谁在为论文的细枝末节买单? 凌晨两点的宿舍灯还亮着ÿ…...

春日桌搭新首选!ROG魔霸9 Mini:3L 迷你机身,塞下锐龙 9+RTX5070
三月春意渐浓,很多人都开始给自己的桌面焕新升级,而一款体积小巧、性能够强的主机,绝对是桌搭升级的核心。最近 ROG 推出的魔霸 9 Mini 电竞迷你主机,就精准命中了玩家与办公人群的核心需求 —— 仅 3L 的超小体积,却塞…...

Venera漫画下载管理:全场景管理与高效离线阅读指南
Venera漫画下载管理:全场景管理与高效离线阅读指南 【免费下载链接】venera A comic app 项目地址: https://gitcode.com/gh_mirrors/ve/venera 用户场景:离线阅读的现实需求 长途旅行中网络信号不稳定?通勤路上想继续追更࿱…...
)
从零开始:如何用Embedding和LLM构建一个智能问答系统(附代码示例)
从零构建基于Embedding与LLM的智能问答系统实战指南 引言 在信息爆炸的时代,如何快速准确地获取所需知识成为技术团队的核心诉求。传统的关键词匹配搜索早已无法满足复杂语义查询的需求,而结合Embedding技术与大语言模型(LLM)的智…...