数据结构:哈夫曼树及其哈夫曼编码
目录
1.哈夫曼树是什么?
2.哈夫曼编码是什么?
3.哈夫曼编码的应用
4.包含头文件
5.结点设计
6.接口函数定义
7.接口函数实现
8.哈夫曼编码测试案列
哈夫曼树是什么?
哈夫曼树(Huffman Tree)是一种特殊的二叉树,由David A. Huffman在1952年发明的,用于数据压缩领域。哈夫曼树是一种最优的二叉树,因为它具有最小的加权路径长度。这里的“最优”是指在给定的一组权重(通常是字符出现频率)下,哈夫曼树的加权路径长度(即树中所有叶节点的权重乘以其到根节点的距离)是最小的,以下是哈夫曼树的特点:
1.完全二叉树:除了最后一层外,每一层都是满的
2.加权路径长度最小:所有叶节点的权重乘以其到根节点的距离之和是最小的
3.每个节点都有权重:叶节点代表单个字符,非叶节点代表字符的集合
哈夫曼编码是什么?
哈夫曼编码是一种使用哈夫曼树进行编码的方法。它将每个字符映射为一个唯一的二进制串,这些二进制串的长度不同,且是根据字符出现频率来确定的。频率越高的字符,其编码越短;频率越低的字符,其编码越长。这种编码方式可以有效地减少数据的存储空间或传输时间。实现哈夫曼编码的步骤如下:
1.统计字符频率:首先统计数据集中每个字符出现的频率
2.构建哈夫曼树:
1.将每个字符及其频率作为叶子节点放入优先队列(通常是最小堆)
2.从队列中取出两个权重最小的节点,创建一个新的内部节点,其权重为这两个节点权重之和
3.将新节点重新加入队列。重复上述步骤,直到队列中只剩下一个节点,这个节点就是哈夫曼树的根节点
3.生成编码:从根节点开始,向左子树走标记为0,向右子树走标记为1,直到到达叶节点,此时叶节点对应的字符的路径标记就是其哈夫曼编码
哈夫曼编码的应用
哈夫曼编码是一种非常实用的编码技术,它通过利用数据的内在特性来优化存储和传输效率:
1.数据压缩:用于无损数据压缩,特别是在文本压缩中非常有效。
2.文件压缩:如ZIP文件格式就使用了哈夫曼编码。
3.通信协议:在某些通信协议中,用于减少传输数据的大小。
包含头文件
#include<stdio.h>
#include<stdlib.h>
#include<string.h>结点设计
#define Initsize 100
typedef int Elemtype;
int Node[Initsize][2]; //定义二维数组Node存储输入的字符和字符所含的权值
int NodeValue[Initsize]; //定义一维数组NodeValue存储经排序过的字符的权值
int Hand = 0; //定义整形变量Hand作为数组NodeValue的头指针
int CodeHead = 0; //定义int类型变量CodeHead作为指针数组Code的头指针typedef struct HTree {Elemtype value; //存储结点权值Elemtype Lvalue, Rvalue; //存储孩子标识struct HTree* lchild; //存储左孩子树struct HTree* rchild; //存储右孩子树
}HTree,*HfmTree;HfmTree Head; //定义全局变量Head作为哈夫曼树的根节点指针
HfmTree Code[Initsize]; //定义HTree类型的指针数组Code,存储结点的地址接口函数定义
void InitHTree(HfmTree& A); //用于初始化哈夫曼树
void InsertNode(int A); //用于输入字符和其权值
void SortNodeV(int A); //用于对输入的权值进行排序
void InitLHfm(HfmTree& A); //用于哈夫曼树的左子树进行初始化并赋值
void InitRHfm(HfmTree& A); //用于哈夫曼树的右子树进行初始化并赋值
void InsertHTree(HfmTree& A,int B); //用于创建哈夫曼树
void PostOrder(HfmTree A); //用于对哈夫曼树进行后序遍历
void InputBTree(HfmTree A); //用于对哈夫曼树的结点权值输出
void SeekHTreeL(HfmTree A, int B); //用于单独寻找哈夫曼树的左子树的字符及权值
void SeekHTreeR(HfmTree A, int B); //用于寻找哈夫曼树的右子树的字符及权值
void InputHfmCode(HfmTree A,int B); //用于输出哈夫曼编码
void InitRootHfm(HfmTree& A,HfmTree &B,HfmTree &C); //用于对哈夫曼树的根结点进行初始化并赋值接口函数实现
void InputHfmCode(HfmTree A,int B) { //用于输出哈夫曼编码int i,j;while (A != NULL) { //对哈夫曼树的左子树进行进栈操作Code[CodeHead] = A;A = A->lchild;CodeHead++;}printf("\n");SeekHTreeL(A, B); //使用函数SeekHtreeL对其哈夫曼树进行寻找左子树的字符及权值for (i = 1; i < CodeHead; i++) {printf("%d", Code[i]->Lvalue); //对栈里结点所含的Lvalue进行输出(从根结点开始输出其含有的LvaLue)}CodeHead--; //出栈操作while (CodeHead != 0) { //判断栈是否为空printf("\n");SeekHTreeR(A, B); //使用函数SeekHTreeR对其哈夫曼树进行寻找右子树的字符及权值for (i = 0; i <= CodeHead - 1; i++) { //对栈里结点所含的Lvalue进行输出(从根结点开始输出其含有的LvaLue)if (i == CodeHead - 1) { //若为栈尾结点则输出其右子树printf("%d", Code[i]->Rvalue); break;}printf("%d", Code[i]->Lvalue);}CodeHead--; //出栈操作}
}void SeekHTreeR(HfmTree A, int B) { //用于寻找哈夫曼树的右子树的字符及权值int i,j;for (i = CodeHead - 1; i >= 0; i++){ //遍历栈if (i == CodeHead-1) { //判断是否为栈的倒数第二个结点(跟定义的结点的有关)for (j = 0; j < B; j++) { //遍历存储字符及权值的数组,寻找对应的字符和权值if (Node[j][1] == Code[i]->rchild->value) {Node[j][1] = -1; //未防止字符不一样,但权值相同的出现,造成输出哈夫曼编码错误printf("%c的哈夫曼编码为:", Node[j][0]);break; }}}break; }
}void SeekHTreeL(HfmTree A, int B){ //用于单独寻找哈夫曼树的左子树的字符及权值int i,j;for (i = 0; i < CodeHead; i++) { //遍历栈if (i == CodeHead - 1) { //判断是否为栈的倒数第二个结点(跟定义的结点的有关)for (j = 0; j < B; j++) { //遍历存储字符及权值的数组,寻找对应的字符和权值if (Node[j][1] == Code[i]->value) { Node[j][1] = -1; //未防止字符不一样,但权值相同的出现,造成输出哈夫曼编码错误printf("%c的哈夫曼编码为:", Node[j][0]);break;}}}}
}void InputBTree(HfmTree A) { //用于对哈夫曼树的结点权值输出 printf("%d ", A->value);
}void PostOrder(HfmTree A) { //用于对哈夫曼树进行后序遍历 if (A != NULL) {PostOrder(A->lchild); PostOrder(A->rchild); InputBTree(A); }
}void InsertHTree(HfmTree& A,int B) {//用于创建哈夫曼树if(Hand<B-1){ //判断是否已将所有字符及权值进行构建对应的哈夫曼树的结点if (A == NULL) { HfmTree Q = (HTree*)malloc(sizeof(HTree)); HfmTree W = (HTree*)malloc(sizeof(HTree)); InitLHfm(Q); //使用函数InitLHfm对其左子树初始化Hand++;InitRHfm(W); //使用函数InitRHfm对其右子树初始化InitRootHfm(A, Q, W); //使用函数InitRootHfm对其根结点初始化Head = A; //更新哈夫曼树的头指针的指向InsertHTree(A, B); }else {HfmTree Q = (HTree*)malloc(sizeof(HTree)); HfmTree W = (HTree*)malloc(sizeof(HTree)); Hand++;InitRHfm(Q); //使用函数InitRHfm对其右子树初始化InitRootHfm(W, A, Q); //使用函数InitRootHfm对其根结点初始化Head = W;InsertHTree(W, B);}}
}void InitRootHfm(HfmTree& A, HfmTree& B, HfmTree& C) {//用于对哈夫曼树的根结点进行初始化并赋值A = (HTree*)malloc(sizeof(HTree));A->value = B->value + C->value; //根结点的权值为两个子结点的权值之和A->Lvalue = 1; //添加左子树标识A->Rvalue = 0;A->lchild = B; //添加根结点指向的左子树A->rchild = C; //添加根结点指向的右子树printf("新建的根结点的权值数据为%d\n", A->value);
}void InitRHfm(HfmTree& A) { //用于哈夫曼树的右子树进行初始化并赋值A->value = NodeValue[Hand]; //对结点所含的权值进行更新A->Lvalue = 0;A->Rvalue = 1; //添加右子树标识A->lchild = NULL; A->rchild = NULL;printf("新建的右孩子的权值数据为%d\n", A->value);
}void InitLHfm(HfmTree& A) { //用于哈夫曼树的左子树进行初始化并赋值A->value = NodeValue[Hand]; //对结点所含的权值进行更新A->Lvalue = 1; //添加左子树标识A->Rvalue = 0;A->lchild = NULL;A->rchild = NULL;printf("新建的左孩子的权值数据为%d\n", A->value);
}void SortNodeV(int A) { //用于对输入的权值进行排序int i, j, Q;for (i = 0; i < A - 1; i++) { //冒泡排序for (j = 0; j < A - 1 - i; j++)if (NodeValue[j] > NodeValue[j + 1]) {Q = NodeValue[j];NodeValue[j] = NodeValue[j + 1];NodeValue[j + 1] = Q;}}
}void InsertNode(int A) { //用于输入字符和其权值int i, j;char Q;for (i = 0; i < A; i++) {j = 0;printf("请输入结点的字符");getchar(); //清除缓冲区,防止赋值脏数据Q=getchar();Node[i][j] = (int) Q;j++;printf("请输入结点的权值");scanf_s("%d", &Node[i][j]);NodeValue[i] = Node[i][j];}
}void InitHTree(HfmTree& A) { //用于初始化哈夫曼树A = NULL;printf("初始化哈夫曼树成功\n");
}哈夫曼编码测试案列
void main() {int NodeSize,i;HfmTree X;InitHTree(X);printf("请问需要输入多少个字符");scanf_s("%d", &NodeSize);InsertNode(NodeSize);SortNodeV(NodeSize);InsertHTree(X, NodeSize);printf("创建哈夫曼树成功\n");printf("后序遍历的哈夫曼树为:");PostOrder(Head);printf("\n");InputHfmCode(Head,NodeSize);
}相关文章:

数据结构:哈夫曼树及其哈夫曼编码
目录 1.哈夫曼树是什么? 2.哈夫曼编码是什么? 3.哈夫曼编码的应用 4.包含头文件 5.结点设计 6.接口函数定义 7.接口函数实现 8.哈夫曼编码测试案列 哈夫曼树是什么? 哈夫曼树(Huffman Tree)是一种特殊的二叉树…...
微信如何防止被对方拉黑删除?一招教你解决!文末附软件!
你一定不知道,微信可以防止被对方拉黑删除,秒变无敌。只需一招就能解决!赶快来学!文末有惊喜! 惹到某些重要人物(比如女朋友),被删除拉黑一条龙,那真的是太令人沮丧了&a…...

jar增量打包
jar增量打包 Linux环境下: 1.解压缩 jar -xvf jarname.jar(解压)2.打包 这时可以把要替换的lib包的内容粘帖进去,然后重新打jar包 jar -cvf0M jarname.jar .(重新压缩,-0是主要的)jar命令: …...

智慧医院物联网建设-统一管理物联网终端及应用
近年来,国家卫健委相继出台的政策和评估标准体系中,都涵盖了强化物联网建设的内容。物联网建设已成为智慧医院建设的核心议题之一。 作为医院高质量发展的关键驱动力,物联网的顶层设计与网络架构设计规划,既需要结合现代信息技术的…...

Debian的常用命令
Debian作为一个稳定、安全且高效的Linux发行版,被广泛应用于服务器和桌面操作系统中。对于系统管理员和开发者来说,熟练掌握Debian的常用命令能够大大提升工作的效率和系统的管理水平。本文将详细介绍一些常见且实用的Debian命令,帮助新手更好地管理和操作Debian系统。 系统…...

矩阵1-范数与二重求和的求和可交换
矩阵1-范数与二重求和的求和可交换 1、矩阵1-范数 A [ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n ] A \begin{bmatrix} a_{11} &a_{12} &\cdots &a_{1n} \\ a_{21} &a_{22} &\cdots &a_{2n} \\ \vdots &\vdots …...

Python笔记 - *args和**kwargs
探索Python的*args和**kwargs 在Python中,函数可以接受任意数量的参数,而这要归功于*args和**kwargs的强大功能。这两个特性使得函数在处理不同数量的输入时变得更加灵活和高效。在这篇博客中,我们将详细介绍*args和**kwargs,并展…...

微信小程序实现图片转base64
在微信小程序中,图片转base63可以引入第三方插件; 也可以通过下边的方法转base64。 转换方法: imgToBase64(filePath) {return new Promise((resolve, reject) > {let baseFormat data:image/png;base64,let base64 wx.getFileSystem…...

os和os.path模块
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 目录也称文件夹,用于分层保存文件。通过目录可以分门别类地存放文件。我们也可以通过目录快速找到想要的文件。在Python中,并…...
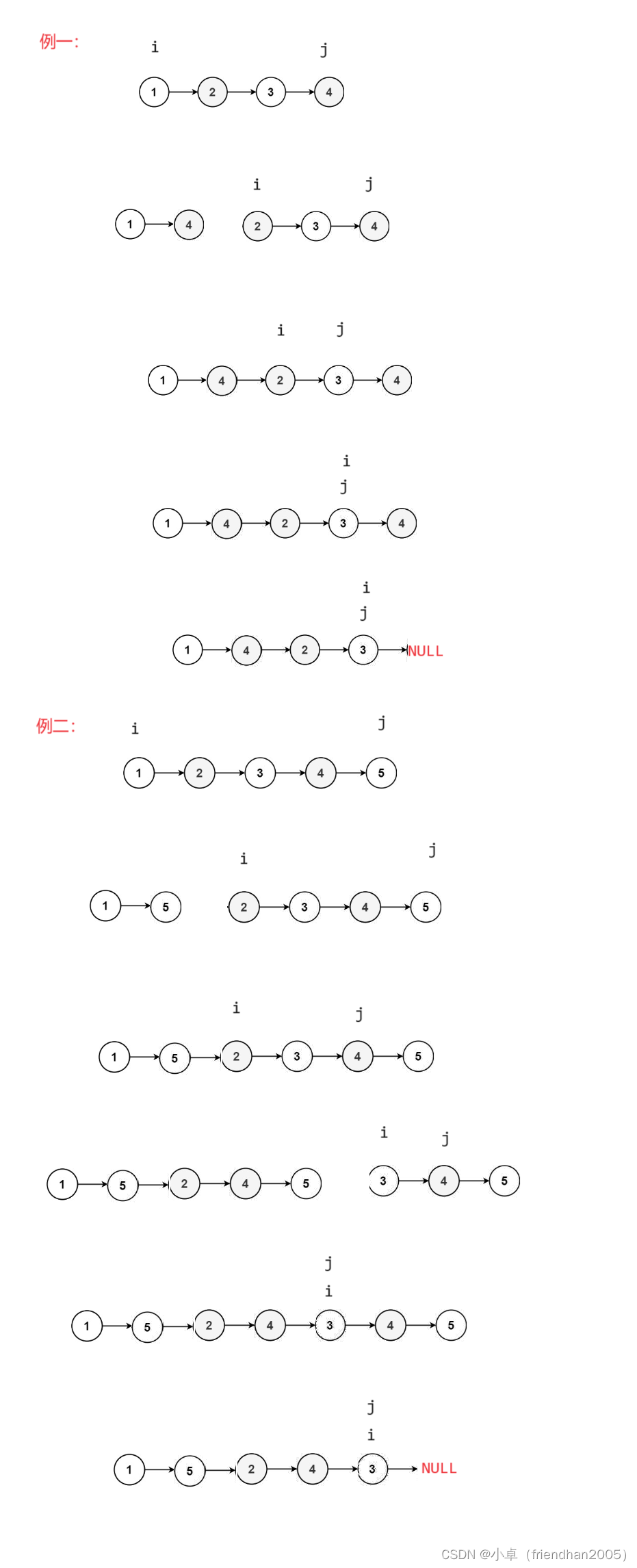
链表题目练习----重排链表
这道题会联系到前面写的一篇文章----快慢指针相关经典问题。 重排链表 指针法 这道题乍一看,好像有点难处理,但如果仔细观察就会发现,这道题是查找中间节点反转链表链表的合并问题,具体细节有些不同,这个在反装中间链…...

【杂记-浅谈XSS跨站脚本攻击】
一、什么是XSS? XSS,Cross-site Scripting,跨站脚本攻击,是一种典型的Web程序漏洞利用攻击,攻击者利用Web程序对用户输入检查不足的漏洞将可执行恶意脚本注入网站或Web应用,当用户访问网页时触发恶意脚本的…...
VMware虚拟机与MobaXterm建立远程连接失败
VMware虚拟机与MobaXterm建立远程连接失败 首先可以检查一下是不是虚拟机的ssh服务并不存在 解决方法: 1.更新镜像源 yum -y update 这个过程会有点久,请耐心等待 2.安装ssh yum install openssh-server 3.启动ssh systemctl restart sshd 4.查…...

mysql undolog管理
在MySQL中,Undo Log(撤销日志)用于支持事务的回滚和MVCC(多版本并发控制)。为了避免Undo Log不断增长,影响系统性能,需要进行合理的清理。MySQL的Undo Log清理策略主要依赖于系统的配置参数和后…...

【Linux】进程2——管理概念,进程概念
1.什么是管理? 那在还没有学习进程之前,就问大家,操作系统是怎么管理进行进程管理的呢? 很简单,先把进程描述起来,再把进程组织起来! 我们拿大学为例子 最典型的管理者——校长最典型的被管理…...

【C++】植物大战僵尸杂交版自动存档——防闪退存档消失
植物大战僵尸杂交版现已更新到v2.0.88,闪退问题还是偶有发生,参考网上现有的方案,简单实现了一个。 原理就是监控存档目录的文件变化,一旦有新的存档,则将其备份。如发生闪退,则还原备份即可。 原目录&…...
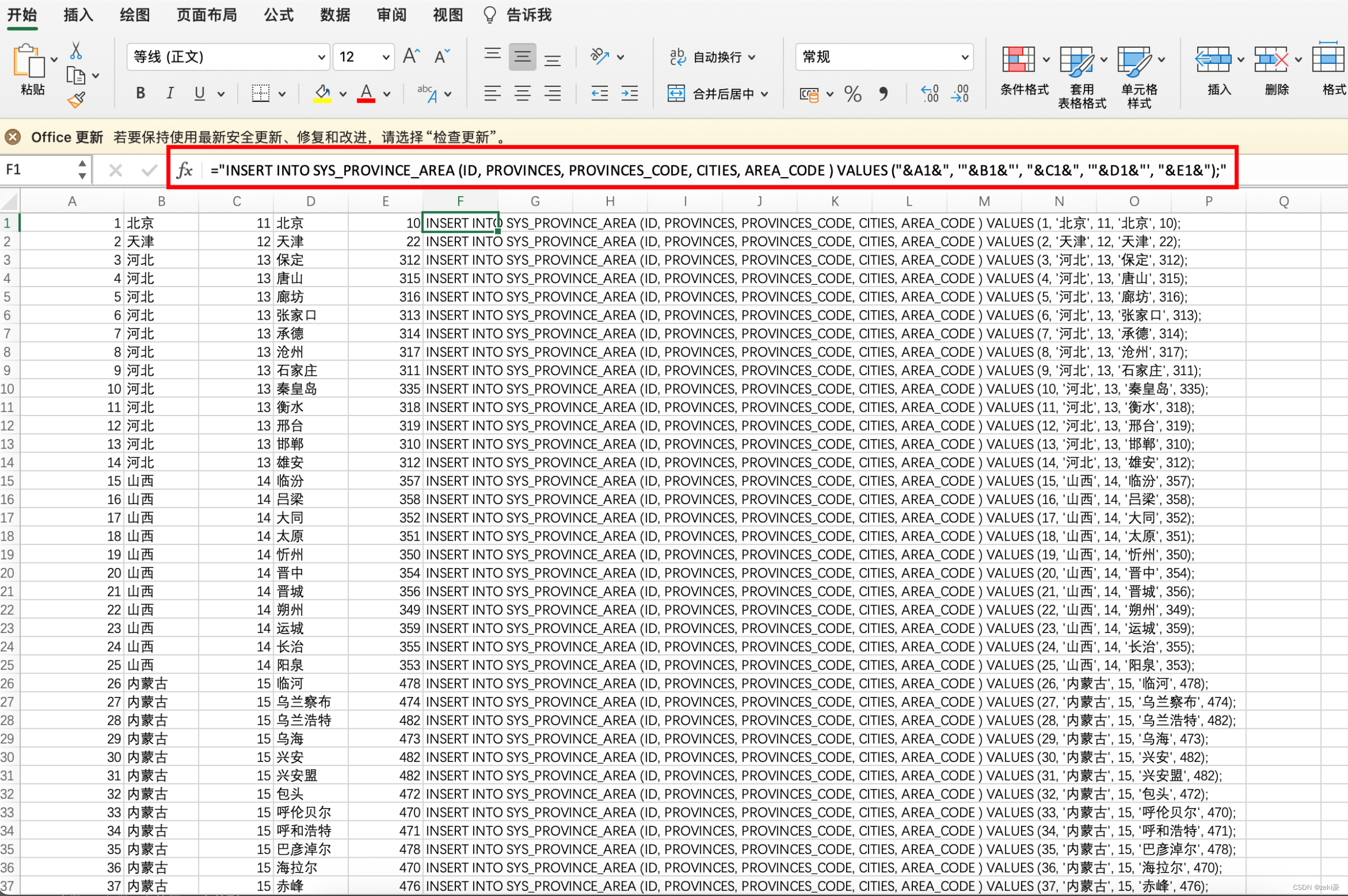
通过Excel,生成sql,将A表数据插入B表
文章目录 投机取巧的方式,进行表数据初始化通过navicat搜索A表数据,然后复制进excel中通过excel的函数方式,将该批量数据自动生成插入B表的sql语句然后一次性拷贝生成的sql语句,放进navicat中一次执行,直接完成数据初始化...

如何在MySQL中实现upsert:如果不存在则插入?
目录 1 使用 REPLACE 2 使用 INSERT ... ON DUPLICATE KEY UPDATE 使用 INSERT IGNORE 有效会导致 MySQL 在尝试执行语句时忽略执行错误 INSERT 。这意味着 包含 索引或 字段 INSERT IGNORE 中重复值的语句 不会 产生错误,而只是完全忽略该特定 命令。其明显目的是…...
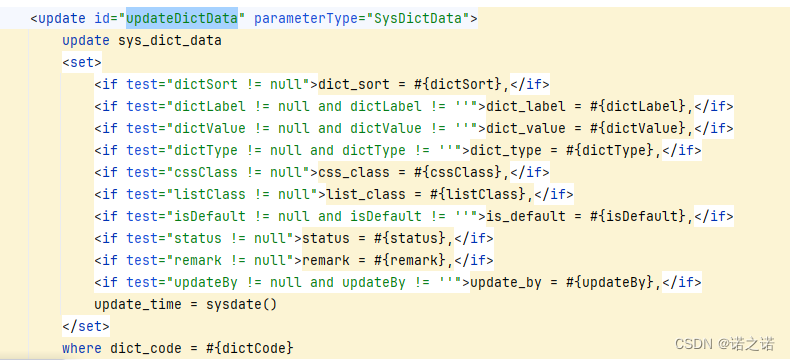
MyBatis中 set标签
1、set标签特点: set标签用于更新语句中set标签解析为set关键字set可以去除跟新语句中无用的逗号通常是和if标签一起使用 2、set标签的使用 编写接口方法编写sql语句 注意 当set标签中有条件成立时就会附加set关键字,字段为null时该列不会被更新。se…...

mysql自带分页
select 查询列表 from 表 limit offset,pagesize; offset代表的是起始的条目索引,默认从0开始size代表的是显示的条目数offset(n-1)*pagesize -- 第-页 limit 0 5 -- 第二页 limit 5,5 -- 第三页 limit 10,5 -- 第n页limit(n-1)*pagesize,pagesize -- pages…...

小学一年级数学上册,我终于学完了
目录 一、背景二、过程1.我对课程中的一些知识的思考2.我对于产品的思考3.我对自己儿子与知识产品结合的思考4.产品反馈的那些有意思的数据 三、总结 一、背景 简约而不简单,即是曾经的再现,也是未来的延伸,未来已来,就在脚下。 …...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...

系统掌握PyTorch:图解张量、Autograd、DataLoader、nn.Module与实战模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程&#…...