【人工智能】流行且重要的智能算法整理

✍🏻记录学习过程中的输出,坚持每天学习一点点~
❤️希望能给大家提供帮助~欢迎点赞👍🏻+收藏⭐+评论✍🏻+指点🙏
小记:
今天在看之前写的文档时,发现有人工智能十大算法的内容,考虑一下觉得之前写的不够严谨,于是找语言模型问了一下,这里就讲新学到的知识做一个汇总。

决策树(Decision Tree)
定义
基于树形结构进行决策判断的算法,通过每个节点的特征判断将数据划分到不同的类别。是一种常用的监督学习算法,用于分类和回归任务。
特点
简单易懂、容易解释、可视化、适用性广、容易过拟合、数据中的小变化会影响结果、每一个节点的选择都是贪婪算法,不能保证全局最优解。
应用
分类问题,如根据病人的症状预测疾病类型。
说明
在这一算法中,训练模型通过学习树表示(Treerepresentation)的决策规则来学习预测目标变量的值。树是由具有相应属性的节点组成的。
在每个节点上,我们根据可用的特征询问有关数据的问题。左右分支代表可能的答案。最终节点(即叶节点)对应于一个预测值。
每个特征的重要性是通过自顶向下方法确定的。节点越高,其属性就越重要。下图为决定是否在餐厅等候的决策树示例。
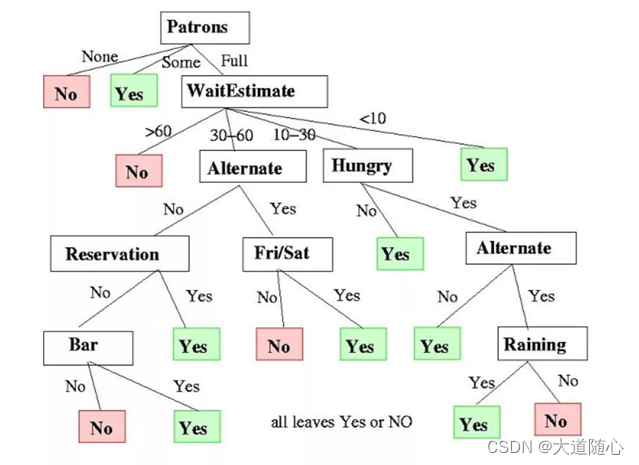
随机森林(Random Forest)
定义
基于多棵决策树的集成学习算法,通过投票或平均方式提高预测精度。
特点
可以处理高维特征数据,防止过拟合。
应用
分类、回归和特征选择等问题。
说明
为了对新对象进行分类,我们从每个决策树中进行投票,并结合结果,然后根据多数投票做出最终决定。
在训练过程中,每个决策树都是基于训练集的引导样本来构建的。
在分类过程中,输入实例的决定是根据多数投票做出的。
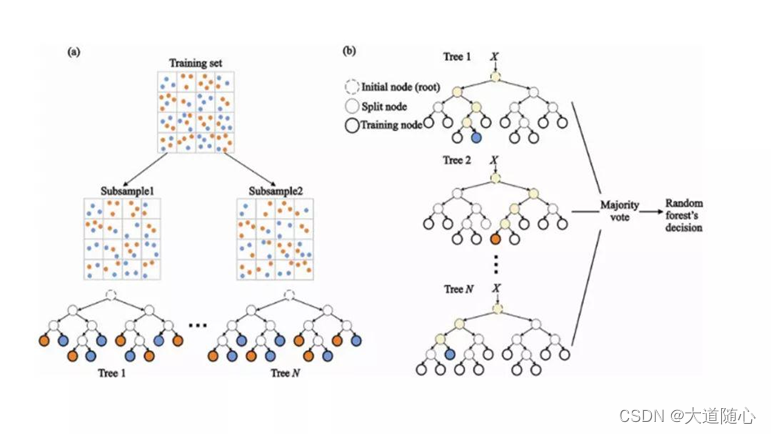
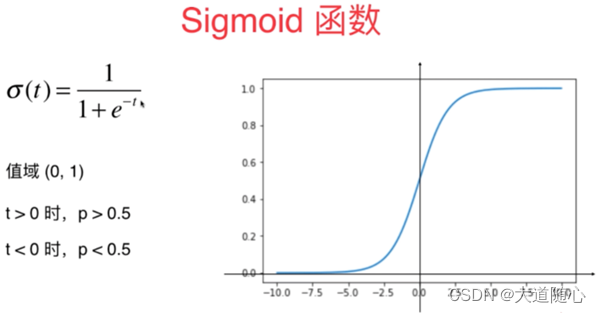
逻辑回归(Logistic Regression)
定义
一种广义的线性回归模型,用于处理因变量为二分类或多分类的分类问题。
特点
简单、易于实现,速度快,可解释性强。
应用
信用评分、疾病预测等。
说明
逻辑回归(Logisticregression)与线性回归类似,但它是用于输出为二进制的情况(即当结果只能有两个可能的值)。对最终输出的预测是一个非线性的S型函数,称为logisticfunction,g()。
这个逻辑函数将中间结果值映射到结果变量Y,其值范围从0到1。然后,这些值可以解释为Y出现的概率。S型逻辑函数的性质使得逻辑回归更适合用于分类任务。
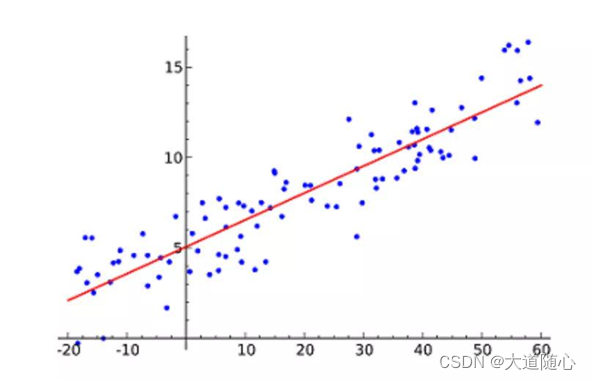
线性回归(Linear Regression)
定义
通过拟合自变量和因变量之间的线性关系来进行预测。
特点
直观易懂,计算简单。
应用
房价预测、销售预测等。
说明
线性回归(LinearRegression)是利用数理统计中的回归分析,来确定两种或两种以上变量间,相互依赖的定量关系的一种统计分析方法。它可能是最流行的机器学习算法。它试图通过将直线方程与该数据拟合来表示自变量(x 值)和数值结果(y 值),然后就可以用这条线来预测未来的值。
这种算法最常用的技术是最小二乘法(Leastofsquares)。这个方法计算出最佳拟合线,以使得与直线上每个数据点的垂直距离最小。总距离是所有数据点的垂直距离(绿线)的平方和。其思想是通过最小化这个平方误差或距离来拟合模型。
支持向量机(SVM, Support Vector Machine)
定义
一种监督学习算法,通过寻找超平面来对数据进行分类。
特点
对小样本、高维数据有较好效果,能处理非线性问题。
应用
图像识别、文本分类等。
说明
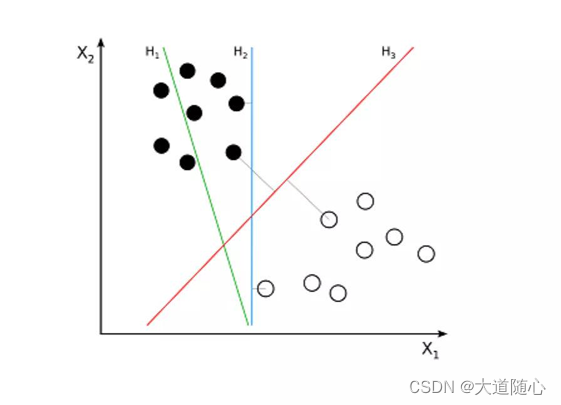
支持向量机(SupportVectorMachine,SVM)是一种用于分类问题的监督算法。支持向量机试图在数据点之间绘制两条线,它们之间的边距最大。为此,我们将数据项绘制为n维空间中的点,其中,n是输入特征的数量。在此基础上,支持向量机找到一个最优边界,称为超平面(Hyperplane),它通过类标签将可能的输出进行最佳分离。
超平面与最近的类点之间的距离称为边距。最优超平面具有最大的边界,可以对点进行分类,从而使最近的数据点与这两个类之间的距离最大化。
例如,H1没有将这两个类分开。但H2有,不过只有很小的边距。而H3以最大的边距将它们分开了。
朴素贝叶斯(Naive Bayes)
定义
基于贝叶斯定理和特征条件独立假设的分类方法。
特点
简单、高效,常用于文本分类。
应用
垃圾邮件过滤、情感分析等。
说明
朴素贝叶斯(NaiveBayes)是基于贝叶斯定理。它测量每个类的概率,每个类的条件概率给出 x 的值。这个算法用于分类问题,得到一个二进制“是 / 非”的结果。看看下面的方程式。
朴素贝叶斯分类器是一种流行的统计技术,可用于过滤垃圾邮件。

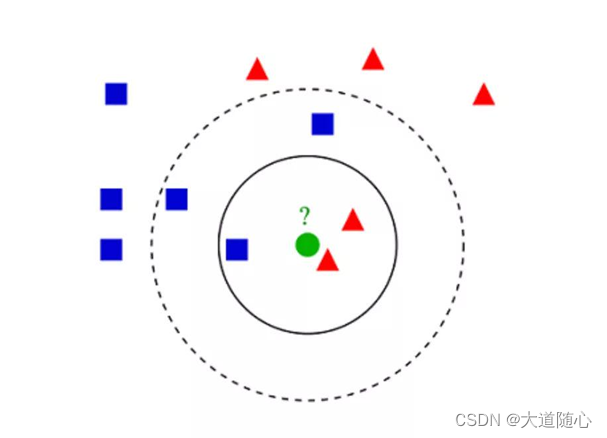
K最近邻算法(K-NN, K-Nearest Neighbors)
定义
根据样本在特征空间中的k个最相邻样本的类别来预测新样本的类别。
特点
简单易懂,无需训练模型,但计算量大。
应用
图像识别、推荐系统等。
说明
K-均值(K-means)是通过对数据集进行分类来聚类的。例如,这个算法可用于根据购买历史将用户分组。它在数据集中找到K个聚类。K-均值用于无监督学习,因此,我们只需使用训练数据X,以及我们想要识别的聚类数量K。
该算法根据每个数据点的特征,将每个数据点迭代地分配给K个组中的一个组。它为每个K-聚类(称为质心)选择K个点。基于相似度,将新的数据点添加到具有最近质心的聚类中。这个过程一直持续到质心停止变化为止。
人工神经网络(Artificial Neural Networks)
定义
模拟人脑神经元连接结构的一种算法,通过多层网络结构学习数据的内在规律。
特点
具有强大的学习能力,可以处理复杂问题。
应用
图像识别、语音识别、自然语言处理等。
说明
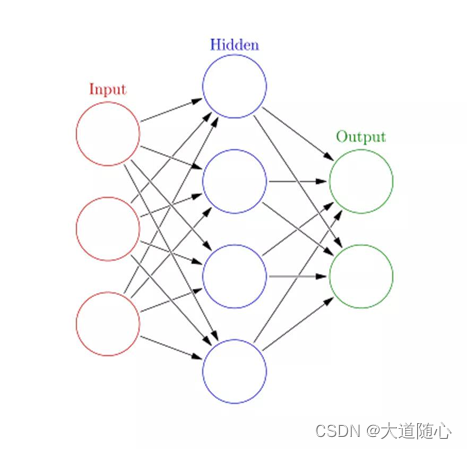
人工神经网络(Artificial Neural Networks,ANN)可以处理大型复杂的机器学习任务。神经网络本质上是一组带有权值的边和节点组成的相互连接的层,称为神经元。在输入层和输出层之间,我们可以插入多个隐藏层。人工神经网络使用了两个隐藏层。除此之外,还需要处理深度学习。
人工神经网络的工作原理与大脑的结构类似。一组神经元被赋予一个随机权重,以确定神经元如何处理输入数据。通过对输入数据训练神经网络来学习输入和输出之间的关系。在训练阶段,系统可以访问正确的答案。
如果网络不能准确识别输入,系统就会调整权重。经过充分的训练后,它将始终如一地识别出正确的模式。
每个圆形节点表示一个人工神经元,箭头表示从一个人工神经元的输出到另一个人工神经元的输入的连接。
卷积神经网络(CNN, Convolutional Neural Network)
定义
专门用于处理具有类似网格结构数据的神经网络,如图像和视频。
特点
局部连接、权值共享,能够有效降低网络复杂度。
应用
图像识别、物体检测、人脸识别等。
说明
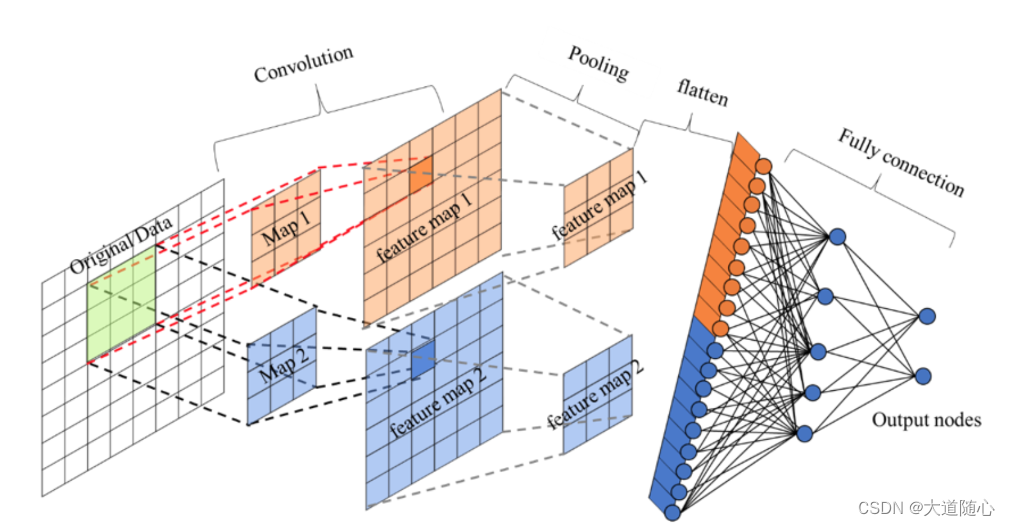
卷积操作:通过卷积核对输入图像进行滑动窗口式的计算,提取出图像中的局部特征。
特征提取:卷积层通过卷积操作从输入数据中提取出局部特征,这些特征被存储在特征图中。
特征映射:池化层对特征图进行下采样,降低数据维度,同时保留主要特征。
分类:全连接层将学到的特征映射到样本标记空间,实现分类任务。
循环神经网络(RNN, Recurrent Neural Network)
定义
用于处理序列数据的神经网络,能够捕捉序列中的长期依赖关系。
特点
能够处理任意长度的序列数据,但存在梯度消失和梯度爆炸的问题。
应用
自然语言处理、机器翻译、语音识别等。
说明
循环连接:RNN通过循环连接在序列的各个位置共享参数,从而捕捉序列中的时序依赖关系。
隐藏状态:隐藏状态在RNN中起着关键作用,它存储了序列的历史信息,并用于影响后续的输出。
训练过程:RNN的训练通常使用反向传播算法和梯度下降算法。然而,由于RNN中存在梯度消失和梯度爆炸等问题,因此需要采用一些特殊的训练方法,如梯度裁剪、LSTM等。
K-均值(K-means)
定义
一种无监督学习算法,用于将数据点划分为K个集群。
特点
简单、高效,且易于理解和实现。
应用
聚类分析、图像处理、推荐系统等。
说明
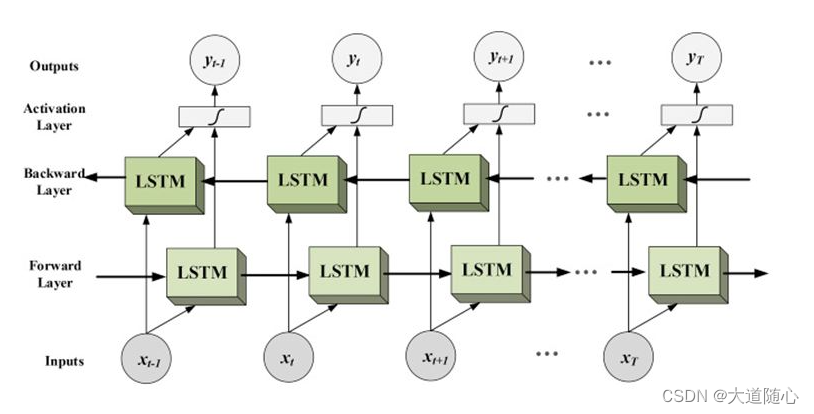
K-均值(K-means)是通过对数据集进行分类来聚类的。例如,这个算法可用于根据购买历史将用户分组。它在数据集中找到K个聚类。K-均值用于无监督学习,因此,我们只需使用训练数据X,以及我们想要识别的聚类数量K。
该算法根据每个数据点的特征,将每个数据点迭代地分配给K个组中的一个组。它为每个K-聚类(称为质心)选择K个点。基于相似度,将新的数据点添加到具有最近质心的聚类中。这个过程一直持续到质心停止变化为止。
以下是对200X2的数组做的均值处理。
降维
定义
用于减少数据维度的技术,同时尽可能保留数据的主要特征。
流行方法
主成分分析(PCA)、t-分布邻域嵌入(t-SNE)等。
特点
有助于可视化高维数据、提高计算效率、减少过拟合等。
应用
数据预处理、特征提取、异常检测等。
说明
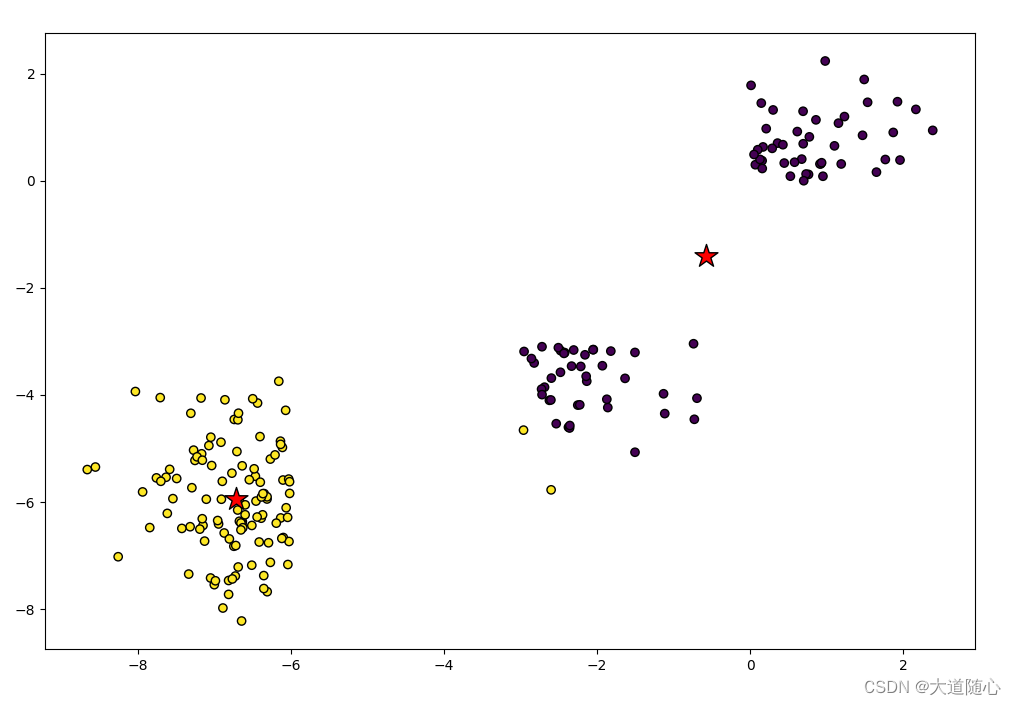
由于我们今天能够捕获的数据量之大,机器学习问题变得更加复杂。这就意味着训练极其缓慢,而且很难找到一个好的解决方案。这一问题,通常被称为“维数灾难”(Curseofdimensionality)。
降维(Dimensionalityreduction)试图在不丢失最重要信息的情况下,通过将特定的特征组合成更高层次的特征来解决这个问题。主成分分析(PrincipalComponentAnalysis,PCA)是最流行的降维技术。
主成分分析通过将数据集压缩到低维线或超平面/子空间来降低数据集的维数。这尽可能地保留了原始数据的显著特征。
梯度提升机(Gradient Boosting Machine)
定义
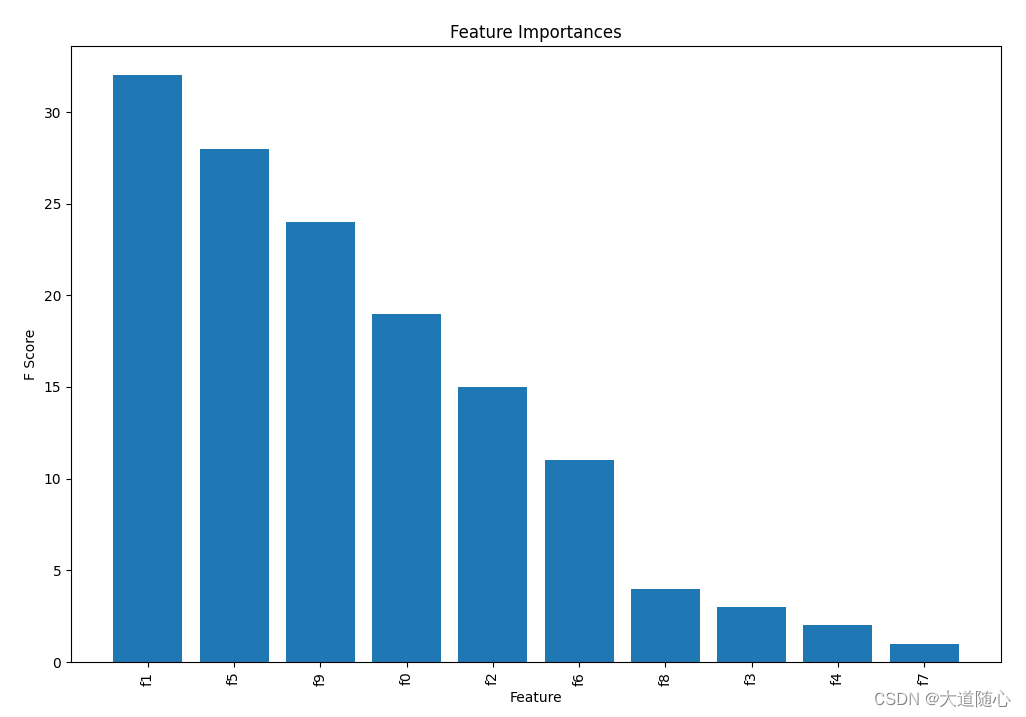
一种基于决策树的集成学习算法,通过迭代地添加新的决策树来优化预测结果。
特点
能够处理非线性关系、对异常值不敏感、易于调整参数。
应用
回归问题、分类问题等。
说明
初始化模型:将目标变量的平均值作为初始预测值。
迭代训练:通过不断迭代训练一系列基学习器(如决策树),对当前模型的残差进行拟合,得到下一轮的预测模型。
更新模型:将当前模型的预测结果与真实值进行比较,得到残差,然后将残差作为下一轮训练的目标变量,继续进行迭代训练。
终止迭代:当达到预设的迭代次数或者目标函数已经收敛时,停止迭代并得到最终的预测模型。

简单的展示示例
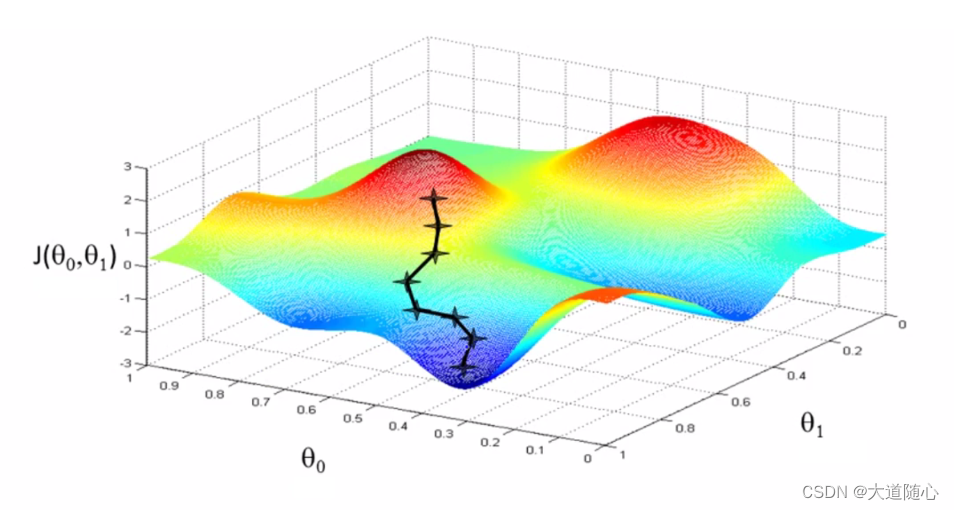
随机梯度下降(Stochastic Gradient Descent, SGD)
定义
一种优化算法,用于在训练过程中更新模型的参数。
特点
计算效率高、对大规模数据集友好、支持在线学习。
应用
深度学习、神经网络训练等。
说明
选择样本:在每次迭代中,随机选择一个样本或一小批样本(mini-batch)进行参数更新。
计算梯度:根据所选样本或mini-batch计算损失函数关于模型参数的梯度。
更新参数:按照负梯度方向更新模型参数,通常还需要乘以一个学习率(learning rate)来控制参数更新的步长。
重复迭代:重复以上步骤,直到模型参数收敛或达到预设的迭代次数。
集成学习(Ensemble Learning)
定义
通过组合多个学习器(如决策树、神经网络等)来提高预测性能的方法。
流行方法
Bagging、Boosting、Stacking等。
特点
能够降低过拟合风险、提高模型泛化能力。
应用
分类问题、回归问题等。
说明
集成学习(Ensemble Learning)是一种通过结合多个学习器(也称为基学习器或弱学习器)来解决问题的机器学习范式。其核心理念在于,通过构建多个基学习器,并让它们对输入数据进行独立的预测,然后采用某种策略将这些预测结果结合起来,以产生最终的预测结果。集成学习能够有效提高模型的性能,降低模型的泛化误差。
集成学习的基本思想可以概括为“多样性和投票”。即,通过构建多个基学习器,并让它们对输入数据进行独立的预测,然后通过某种方式(如投票法、加权投票法等)将各个基学习器的预测结果结合起来,产生一个最终的预测结果。
Bagging:如随机森林(Random Forest),通过在原始训练集的随机子集上构建多个基学习器,并将它们的预测结果结合起来。
Boosting:如AdaBoost、GBDT(Gradient Boosting Decision Tree)等,通过迭代地训练基学习器,并在每次迭代中调整样本的权重,以关注那些之前被错误分类的样本。
Stacking:通过将不同的基本学习模型进行级联,将前一层模型的预测结果作为后一层模型的输入,以产生最终的预测结果。
推荐系统算法
定义
用于预测用户可能感兴趣的项目或内容的算法。
流行方法
基于内容的推荐、协同过滤(如用户-用户协同过滤、物品-物品协同过滤)、深度学习推荐等。
特点
能够个性化地满足用户需求、提高用户满意度和忠诚度。
应用
电子商务平台、社交媒体、视频流媒体平台等。
说明
推荐系统算法是人工智能领域的一个重要分支,用于根据用户的历史行为、偏好等信息,向用户推荐可能感兴趣的内容或物品。以下是对几种常见的推荐系统算法的清晰归纳和介绍:
基于人口统计学的推荐算法
原理:根据系统用户的基本信息(如年龄、性别、地域等)发现用户之间的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户。
特点:易于实现,但可能忽略用户的具体行为或兴趣。
基于内容的推荐算法(Content-based Recommendations, CB)
原理:根据推荐物品或内容的元数据(如电影的类型、演员、导演等),发现物品之间的相关性,再基于用户过去的喜好记录,为用户推荐相似的物品。
特点:能够捕捉用户的个性化兴趣,但可能受限于物品元数据的丰富程度。
协同过滤算法(Collaborative Filtering, CF)
原理:通过分析用户之间的历史行为(如购买、浏览、评分等),找到相似用户或物品,进行推荐。
分类:
基于用户的协同过滤(User-based CF):分析各个用户对物品的评价,计算用户之间的相似度,然后基于相似用户的喜好推荐物品给当前用户。
基于物品的协同过滤(Item-based CF):分析各个用户对物品的浏览记录,计算物品之间的相似度,然后基于用户喜欢的物品推荐相似的物品给用户。
特点:应用广泛,效果好,但需要大量的用户行为数据。
基于流行度的算法
原理:根据物品的流行度(如点击量、购买量、分享量等)进行排序,将最流行的物品推荐给用户。
特点:简单直观,但缺乏个性化。
混合推荐算法
原理:结合上述多种推荐算法的优点,通过加权、切换、特征组合等方式,形成更准确的推荐结果。
特点:能够充分利用各种算法的优势,提高推荐的准确性和多样性。
基于模型的推荐算法:
原理:使用机器学习或深度学习模型(如矩阵分解、隐语义模型、神经网络等)来预测用户对物品的喜好程度,从而进行推荐。
特点:能够处理复杂的非线性关系,但需要大量的训练数据和计算资源。
基于上下文信息的推荐算法
原理:考虑用户所处的上下文环境(如时间、地点、天气等)进行推荐。
特点:能够提供更符合当前情境的推荐结果。
在实际应用中,推荐系统通常会根据具体的需求和场景选择合适的算法或算法组合。同时,随着技术的发展和数据的积累,新的推荐算法和策略也在不断涌现。
相关文章:
【人工智能】流行且重要的智能算法整理
✍🏻记录学习过程中的输出,坚持每天学习一点点~ ❤️希望能给大家提供帮助~欢迎点赞👍🏻收藏⭐评论✍🏻指点🙏 小记: 今天在看之前写的文档时,发现有人工智能十大算法的内容…...
)
webrtc客户端测试和arm平台测试(待补充)
一、关于API的使用研究 二、遇到的一些问题 1、snd_write Broken pipe 写音频数据到缓存不及时导致,codec没有数据可以播放。 alsa总结 WebRTC源码研究(1)WebRTC架构 WebRTC 中的基本音频处理操作...
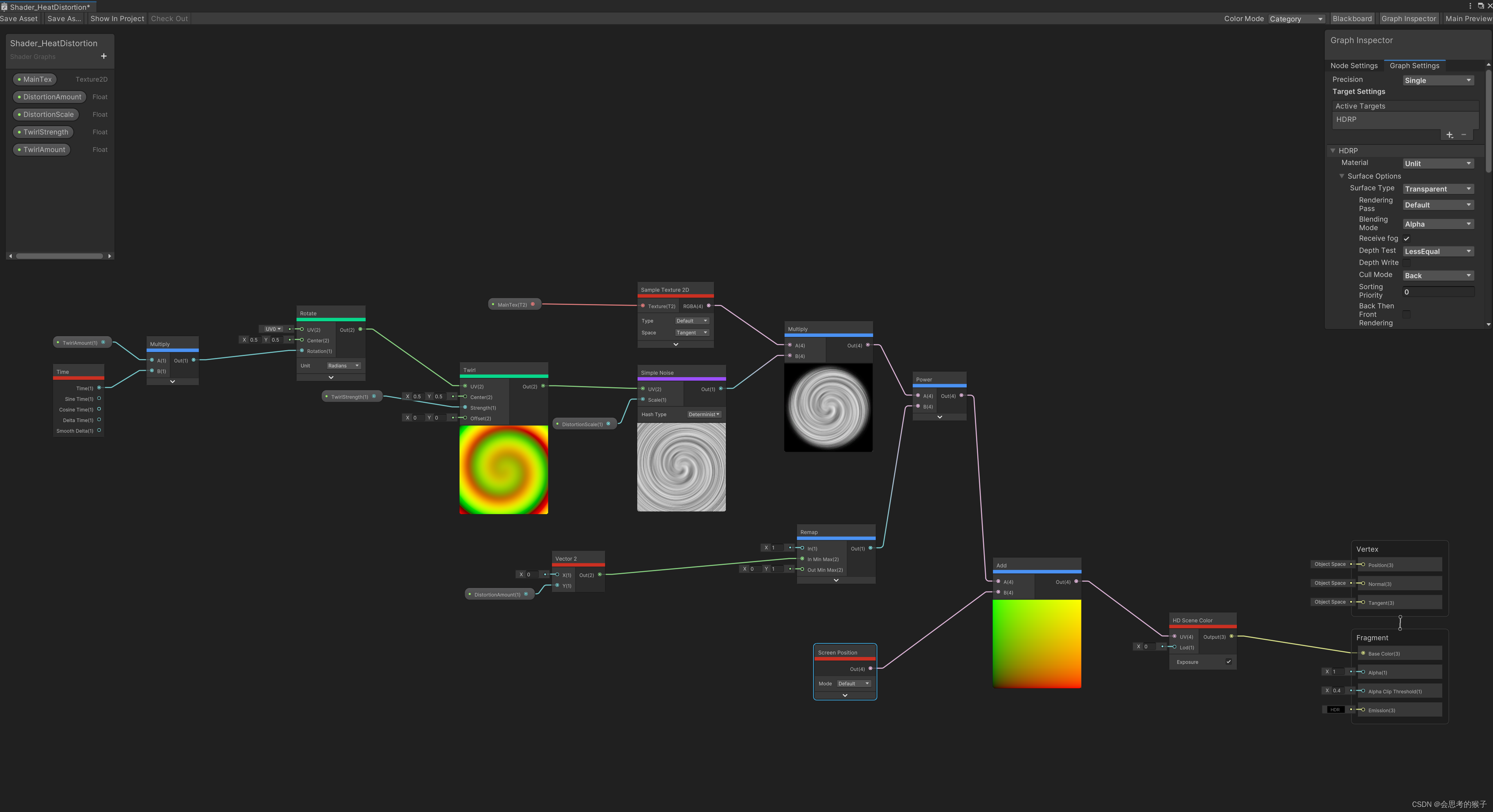
Unity ShaderGraph 扭曲
需要注意的是: HDRP ShaderGraph中 你不能扭曲UI,所以假如你要扭曲视频,请把视频在材质上渲染 播放,这样就可以扭曲视频了喔, ShaderGraph扭曲...
【应用启动框架AppStartup】)
鸿蒙Ability Kit(程序框架服务)【应用启动框架AppStartup】
应用启动框架AppStartup 概述 AppStartup提供了一种更加简单高效的初始化组件的方式,支持异步初始化组件加速应用的启动时间。使用启动框架应用开发者只需要分别为待初始化的组件实现AppStartup提供的[StartupTask]接口,并在[startup_config]中配置App…...
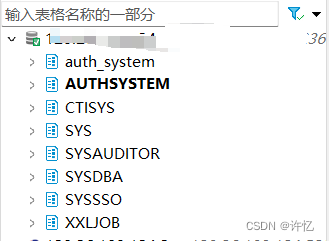
DBeaver添加DM8驱动(maven下载和jar包下载配置)
DBeaver 24.0.3添加DM8驱动 下载DBeaver下载DM达梦驱动下载 安装配置使用自带Dameng自行添加达梦驱动 因为最近公司项目有信创要求,所以下载了达梦数据库。使用自带的达梦管理工具不是很方便,于是换了DBeaver。 哼哧哼哧安装好后,创建数据库连…...
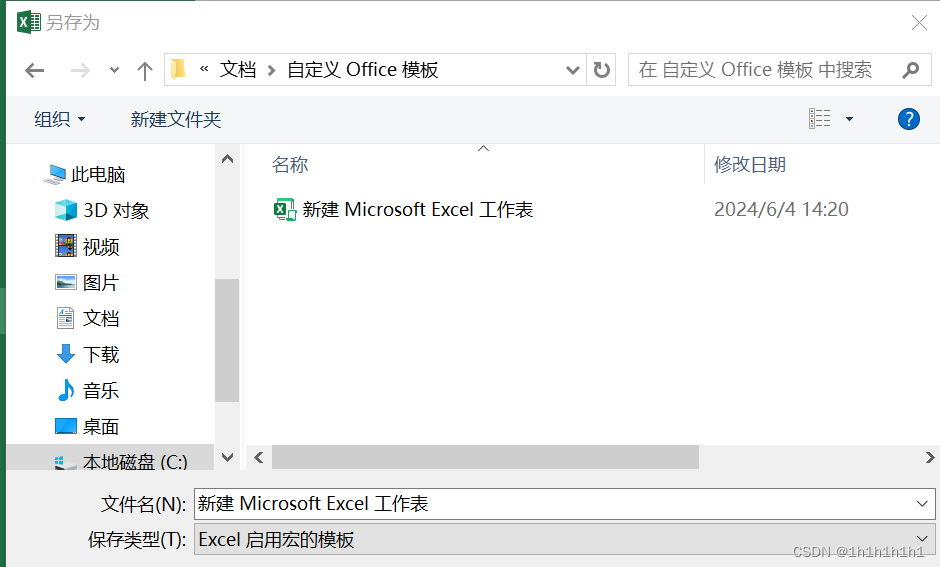
EXCEL多sheet添加目录跳转
EXCEL多sheet添加目录跳转 背景 excel中有几十个sheet,点下方左右切换sheet太耗时,希望可以有根据sheet名超链接跳转相应sheet,处理完后再跳回原sheet。 方案一 新建目录sheet,在A1写sheet名,右键选择最下方超链接…...
MySQL之查询性能优化(十)
查询性能优化 MySQL查询优化器的局限性 松散索引扫描 由于历史原因,MySQL并不支持松散索引扫描,也就无法按照不连续的方式扫描一个索引。通常,MySQL的索引扫描需要先定义一个起点和终点,即使需要的数据只是这段索引中很少数的几…...
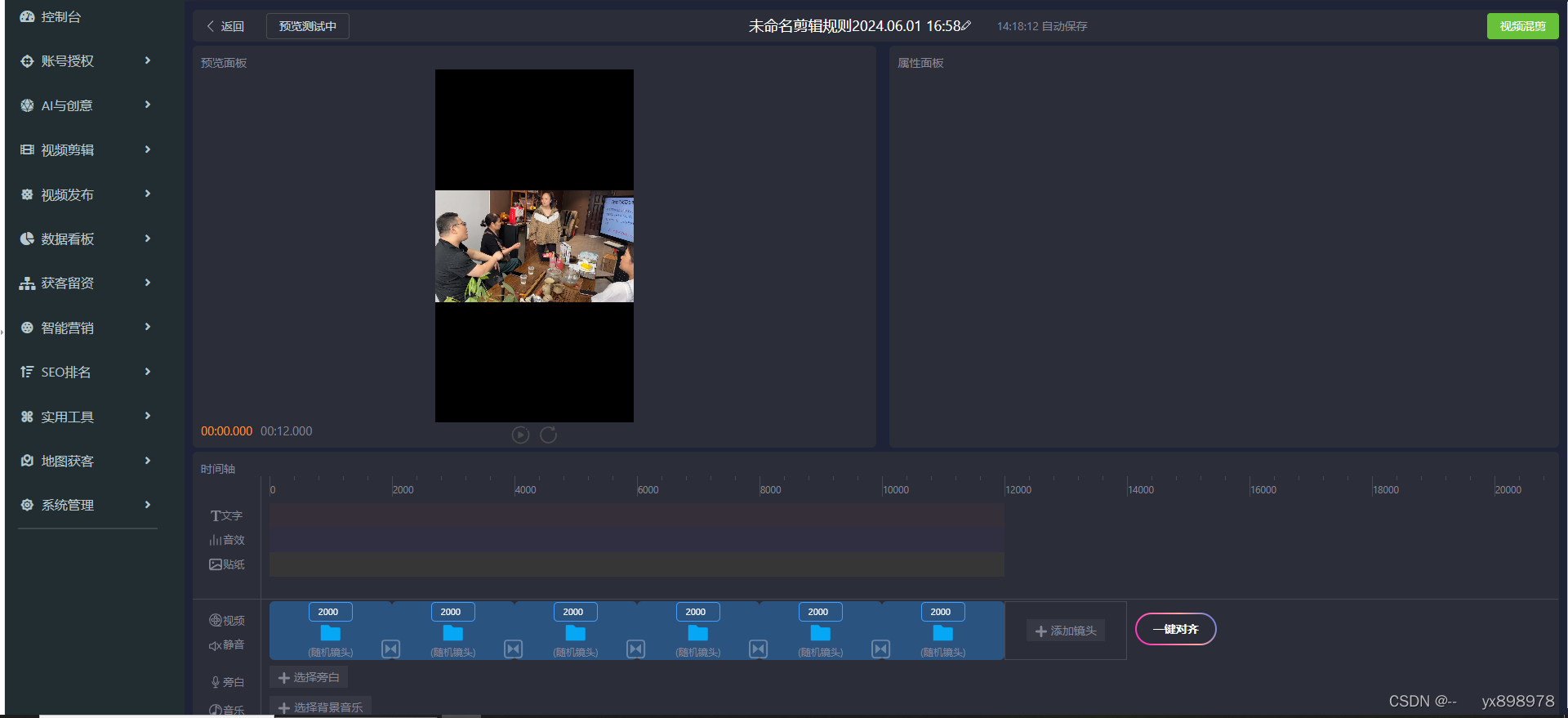
短视频矩阵源码----如何做正规开发规则分享:
一、什么是SaaS化服务技术开发? (短视频矩阵系统是源头开发的应该分为3个端口---- 总后台控制端、总代理端口,总商户后台) SaaS是软件即服务(Software as a Service)的缩写。它是一种通过互联网提供软件应…...

4. JavaScript 循环与迭代
JavaScript 中提供了这些循环语句: for 语句do … while 语句while 语句label 语句 跳出多级循环 var num 0; outPoint: for (var i 0; i < 10; i) {for (var j 0; j < 10; j) {if (i 5 && j 5) {break outPoint; // 在 i 5,j 5 …...
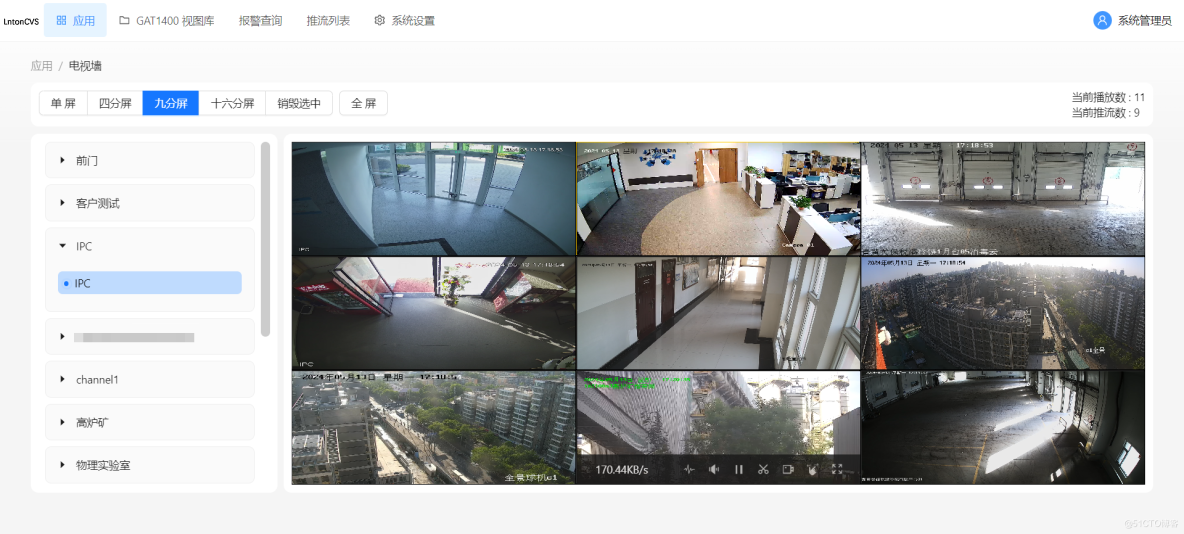
智能视频监控平台LntonCVS视频融合共享平台保障露营安全解决方案
在当今社会,都市生活的快节奏和压力使得越来越多的人渴望逃离城市的喧嚣,寻求一种短暂的慢生活体验。他们向往在壮丽的山河之间或宁静的乡村中露营,享受大自然的宁静与美好。随着露营活动的普及,露营地的场景也变得更加丰富多样&a…...

python如何画函数图像
通过图像可以直观地学习函数变化、分布等规律,在学习函数、概率分布等方面效果显著。下面我们尝试用Python的2D绘图库matplotlib来绘制函数图像。 下面我们来实现一个简单的函数: 首先,调用matplotlib库和numpy库 import matplotlib.pyplot …...
(从头到尾安装))
zeppelin(kylin的可视化界面安装)(从头到尾安装)
zeppelin(kylin的可视化界面安装) 1、zeppelin安装前的准备工作: 1、虚拟机安装配置好jdk, 2、虚拟机安装配置好Hadoop, 3、虚拟机安装配置好Hive 4、虚拟机安装配置了hbase 5、安装了kylin(麒麟) 6、下载了zeppelin…...

python词云生成库-wordcloud
内容目录 一、模块介绍二、WordCloud常用的方法1. generate(self, text)2. generate_from_frequencies(frequencies)3. fit_words(frequencies)4. generate_from_text(text) 三、进阶技巧1. 设置蒙版2. 设置过滤词 WordCloud 是一个用于生成词云的 Python 库,它可以…...
】)
鸿蒙开发接口数据管理:【@ohos.data.rdb (关系型数据库)】
关系型数据库 关系型数据库(Relational Database,RDB)是一种基于关系模型来管理数据的数据库。关系型数据库基于SQLite组件提供了一套完整的对本地数据库进行管理的机制,对外提供了一系列的增、删、改、查等接口,也可…...

Java返回前端Bigdecimal类型数据时“0E-8“及小数点多余0的问题
目录 问题描述: 解决方法: 重要代码: 问题描述: 项目中oracle数据库需要转换为mysql,Oracle中的表字段定义为number(36,16)类型的工具自动转换为mysql的decimal(36,16)。在Oracle数据库中,number(36,16)类型的字段,使用BigDeci…...

标题:深入探索Linux中的`ausyscall`
标题:深入探索Linux中的ausyscall(注意:ausyscall并非Linux内核标准命令,但我们可以探讨类似的概念) 在Linux系统中,系统调用(syscall)是用户空间程序与内核空间进行交互的一种重要…...

CorelDRAW2024发布更新啦!设计师们的得力助手
在数字化的今天,视觉设计已经成为我们生活中不可或缺的一部分。从手机界面到广告海报,从网页布局到包装设计,每一个细节都离不开设计师们的专业与创意。然而,面对日益增长的设计需求和不断提升的审美标准,许多设计师开…...
SpringMVC日期格式处理 分页条件查询
实现日期格式处理: springmvc能实现String类型和基本数据类型及包装类的自动格式转换,但是不能识别String和 日期类格式的自动转换。 实现方式: 1是在实体类上加上注解DateTimeFormat,识别String格式为“yyyy-MM-dd” 2使用自定义…...

蓝桥云课第12届强者挑战赛
第一题:字符串加法 其实本质上就是一个高精度问题,可以使用同余定理的推论 (ab)%n((a%n)(b%n))%n; #include <iostream> using namespace std; const int mod1e97; int main() {string a,b;cin>>a>>b;ab;int …...

LabVIEW储油罐监控系统
LabVIEW储油罐监控系统 介绍了基于LabVIEW的储油罐监控系统的设计与实施。系统通过集成传感器技术和虚拟仪器技术,实现对储油罐内液位和温度的实时监控,提高了油罐监管的数字化和智能化水平,有效增强了油库安全管理的能力。 项目背景 随着…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...
宇树科技,改名了!
提到国内具身智能和机器人领域的代表企业,那宇树科技(Unitree)必须名列其榜。 最近,宇树科技的一项新变动消息在业界引发了不少关注和讨论,即: 宇树向其合作伙伴发布了一封公司名称变更函称,因…...

StarRocks 全面向量化执行引擎深度解析
StarRocks 全面向量化执行引擎深度解析 StarRocks 的向量化执行引擎是其高性能的核心设计,相比传统行式处理引擎(如MySQL),性能可提升 5-10倍。以下是分层拆解: 1. 向量化 vs 传统行式处理 维度行式处理向量化处理数…...

java+webstock
maven依赖 <dependency><groupId>org.java-websocket</groupId><artifactId>Java-WebSocket</artifactId><version>1.3.5</version></dependency><dependency><groupId>org.apache.tomcat.websocket</groupId&…...

dvwa11——XSS(Reflected)
LOW 分析源码:无过滤 和上一关一样,这一关在输入框内输入,成功回显 <script>alert(relee);</script> MEDIUM 分析源码,是把<script>替换成了空格,但没有禁用大写 改大写即可,注意函数…...

鸿蒙APP测试实战:从HDC命令到专项测试
普通APP的测试与鸿蒙APP的测试有一些共同的特征,但是也有一些区别,其中共同特征是,它们都可以通过cmd的命令提示符工具来进行app的性能测试。 其中区别主要是,对于稳定性测试的命令的区别,性能指标获取方式的命令的区…...